作者:黄呈松,圣路易斯华盛顿大学博士生
在Deep Learning之前,我们在做传统机器学习,通过研究规律,写基于规则的代码来完成我们想要完成的任务。
在LLM之前,我们用深度学习来提取特征,设计网络来完成我们想要完成的任务
在LLM之后,我们似乎试图用LLM来解决所有的任务
但...我们真的达到了前两种范式的上限吗,还是人力有穷呢!
来自 Google、Meta、 UMD、UVA、WUSTL、UNC等研究机构用一个新兴的和LLM有关的方向,efficient-time scaling来证明,其实方法是对的,只是人力有限。
Claude Code 用 160 分钟、t40 ,干完了 TTS 圈研究员几年的活。
LLM前我们刷榜的方式是什么?
写一个简单的方法->看看测试效果->根据case study发现方法不够好的地方->优化方法,然后循环这个流程
那么新的范式呢?
让agent写一个简单的方法->让agent看看测试效果->让agent根据case study发现方法不够好的地方->让agent优化方法,然后让agent循环这个流程
文章里的TTS只是一个很小的例子,任何我们在deeplearning之前试图用rule-based 代码解决的问题都可以用相同的范式简单的实现,毕竟人类研究也不过是对这轨迹和结果调试(bushi

Github: https://github.com/zhengkid/AutoTTS
Homepage: https://zhengkid.github.io/AutoTTS-web/
ArXiv:https://arxiv.org/abs/2605.08083
Huggingface: https://huggingface.co/papers/2605.08083
代码、环境已经全面开源!欢迎大家讨论、引用、Star
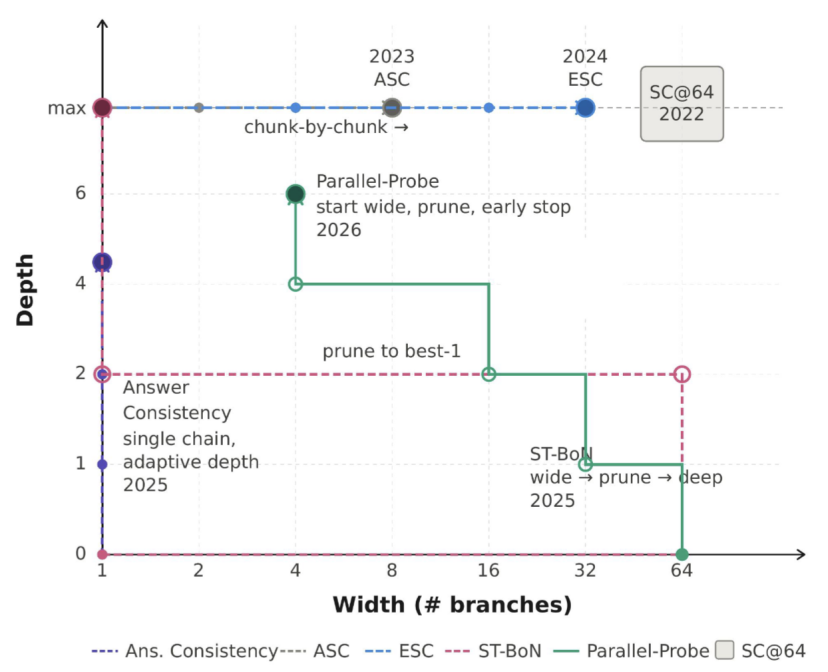
那张被忽视的面板
过去几年那一堆听起来风格迥异的 TTS 方法,本质上是同一个旋钮面板上的几个手调点位。这里面为了简化,我们以一个特殊的二维空间为例:
- 宽度——同一个题多采几条思路一起跑
- 深度——每条思路想多久才停
- 副旋钮——什么时候 probe 中间答案、什么时候剪枝、什么时候停、怎么聚合
SC@64是"宽度拉满、不剪枝、最后投票"。ASC在宽度上加自适应停止。ESC 在宽度上加了滑窗一致性早停。ST-BoN 先开宽、剪到一条再加深。Parallel-Probe 则是同时调整两个维度,深度早退,宽度剪枝。每个方法都是这个面板上的一个特殊的例子。
显然这是一个摆在明面上的搜索问题,被整个圈子集体错过了好几年。
换句话说——如果我们能把这个空间和对应的环境提前定义好,剩下的事是不是就不用人类手调了?是不是可以直接交给一个 frontier coding agent,让它在这个空间里搜?
这也进而揭示了AutoTTS真正想传达的范式:人的任务由设计算法,转到设计相应的搜索环境,而搜索任务通过 frontier coding agent 自动发现。
AutoTTS 怎么用 40 块钱搜的
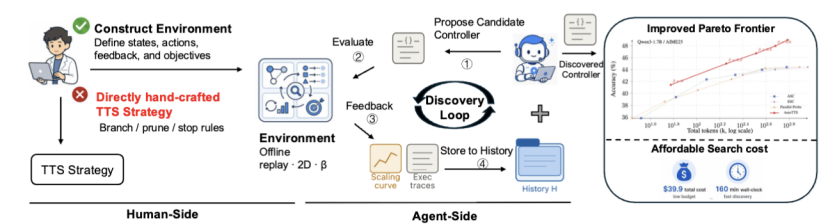
AutoTTS的整体机制是一个discovery loop:每一轮,一个 explorer LLM(论文里用的就是 Claude Code)读取历史 H——里面存着此前所有试过的 controller、它们的精度–成本曲线、以及每次评估的完整执行轨迹——然后直接编辑 method.py 里的 controller 代码,提出一个新版本;
这个新 controller 在搜索集上被评估,结果(精度、成本、轨迹)再写回 H。5 轮之后挑搜索集上表现最好的那个交卷。
这个 loop 听起来朴素,但能跑起来、跑便宜、跑出能泛化的策略,靠的是三个工程决策:
- 离线 replay 环境:让评估根本不调 LLM——否则光 5 轮 × 几十个 controller 的推理开销就远不止 40 美元,而且会很慢
- β 参数化:Agent 提出的算法往往都很复杂包含很多的超参数,比如warm up步数,阈值等,一方面这个空间很大,我们不一定能搜出来好的结果,另一方面即使搜出来也无法直接泛化到held-out测试集,且由于超参数多,也很难调参。
- 执行轨迹反馈:让 explorer LLM 知道上一轮错在哪——光给精度/成本数字它判断不出失败模式,下一轮就只能瞎试
下面一个一个讲。
1. 将 Test-Time Scaling 建模成离线 replay 环境中的算法搜索问题
搜索之所以贵,是因为每评估一个候选策略都要让 base LLM 真跑一遍推理。AutoTTS 把这件事拆成两步:先一次性预录好"推理素材库",再把 controller 搜索定义在这个素材库上。这样 controller 评估不再调 LLM。
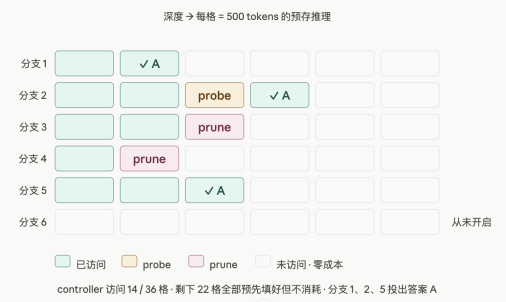
(a) 怎么收集 replay 数据
对每道题,预先用 base LLM 采 128 条独立推理轨迹,每条每 500 tokens 切一个"探针点"——存下该点之前的推理片段,以及如果停在这里、模型会给出什么中间答案。
每道题最终被压成一张矩阵:128 行(独立的思路)× 若干列(每列对应这条思路推到第 k 个 500 tokens 的状态)。所有真金白银的 LLM 调用都发生在这一步——而且只发生一次。
(b) 怎么 formulate 成算法搜索问题
有了这张矩阵,TTS 策略的设计就被改写成一个清晰的 MDP——controller 是一个 code-defined policy π,在每一步根据当前状态从合法动作集合里选一个执行。状态、动作、代价、目标的形式化如下:
- state (q, m, I, ℓ, Ω):当前题目 q、累计开过的分支数 m(含已被剪掉的)、当前活跃分支集合 I ⊆ [m]、每条分支走到第几格的深度向量 ℓ、目前为止读到的所有中间答案 Ω
- action:五种原子操作——BRANCH(开新分支,走到第 1 格) / CONTINUE(i)(把活跃分支 i 往前推一格)/PROBE(i)(读分支 i 当前格的中间答案,不推进深度)/PRUNE(i)(把分支 i 从活跃集合里拿掉,但已走过的深度仍计入成本) /** ANSWER**(停止,对已访问的格子做聚合)
- cost(s):所有分支累计走过的格数之和(包括被剪掉的分支的沉没深度)+ κ_probe × 已 probe 次数。论文里设 κ_probe = 0,即 probe 不计成本
- 目标:在任务分布 D 上最大化 E_{(q,y)~D} [{ŷ_π(q) = y} − γ · cost_π(q) ],γ 控制精度和成本之间的权衡
关键之处:每个动作的执行都是从预存矩阵里查表。BRANCH?读矩阵新行的第 1 格。CONTINUE?读这行的下一格。PROBE?取出该格存好的中间答案。零 LLM 调用、几乎不耗 token。
整个搜索目标因此被压成一句话——找到一个 policy,访问尽可能少的格子,但 ANSWER 时聚合出来的答案还是对的。
39.9美元的真正来源就在这里:不是 LLM 调用变便宜了,是controller评估根本不再调 LLM。
2. β 参数化 - 让搜索出来的算法更可控
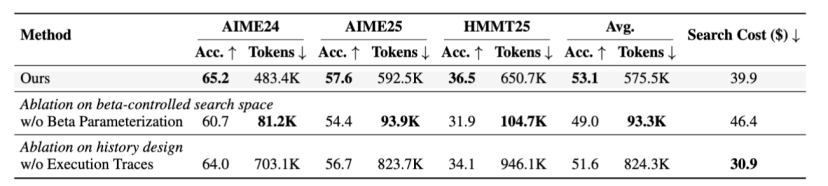
AutoTTS 的硬约束:每个 controller 只能暴露一个标量 β,所有内部超参必须是 β 的单调函数,映射本身让 LLM 自己设计。搜索空间从 10 维降到 1 维,扫一遍 β 自动描出一条 Pareto 前沿。消融验证:去掉 β 约束的版本 token 从 575K 跌到 93K,held-out 精度从 53.1 掉到 49.0。
3. 执行轨迹反馈:让 LLM 知道为什么错了
光给一个"精度 65%、用了 50 万 tokens"的 scalar,LLM 判断不出问题出在哪。AutoTTS 把每个 controller 的完整决策轨迹喂回去:每一步选了什么动作、看到什么 state、做了什么决定。LLM 像 debug 一样定位失败模式,下一轮做针对性改进。
搜出来的策略长这样:作者命名为 Confidence Momentum Controller (CMC),四个机制——基于 EMA 动量的停止、宽度–深度耦合 widening、对齐感知的深度分配、保守的分支放弃。
实验:
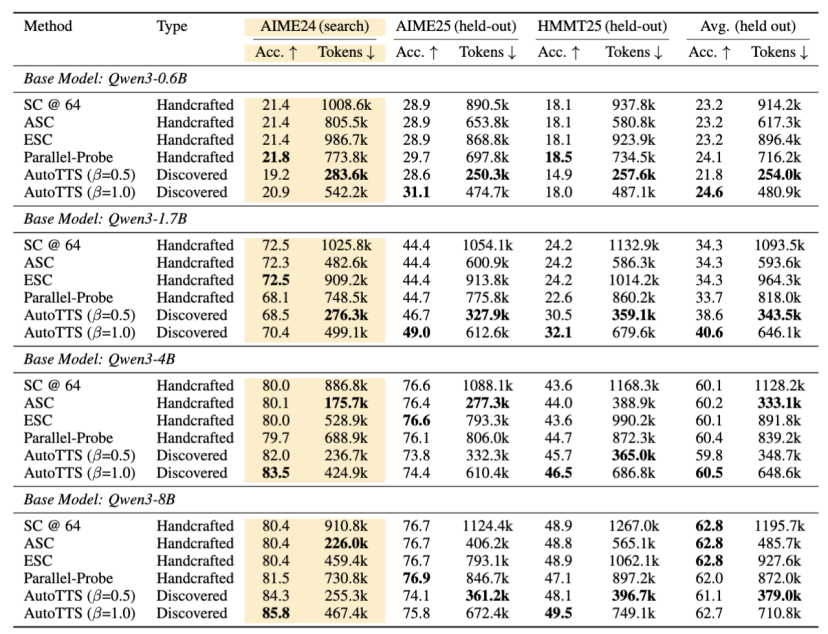
AutoTTS 在 4 个 Qwen3 模型(0.6B / 1.7B / 4B / 8B)× 3 个数学基准(AIME24 搜索集、AIME25 + HMMT25 held-out)一共 12 个组合上做了对比。
1.β=0.5:token 用量降 69.5%,精度几乎不动
跨 4 个模型的 held-out 平均,AutoTTS β=0.5 拿 45.3 的精度,SC@64 是 45.2——基本持平,但 token 用量从平均-933K 降到 ~282K。这是"省 70% 算力却不掉一分精度"的版本——一个 token 上严格优于 SC@64 的策略。
2.β=1.0:在 8 组 (model × held-out benchmark) 里有 5 组把所有手工 baseline 的峰值推上去
不只是更便宜,是把 Pareto 前沿整条往上抬。最典型的是 Qwen3-1.7B:AutoTTS β=1.0 拿到 held-out 平均精度 40.6 vs SC@64 的 34.3——6.3 个点的差距,同时 token 还少 40%。这种量级的提升单靠手工调参拿不到。
3.跨模型族 + 跨任务:CMC 不是 AIME 专用策略
这是整篇论文最值钱的实验之一。他们把在 Qwen3 × AIME24 上搜出来的同一个 controller,完全不重搜地丢到两个完全不同的设置:
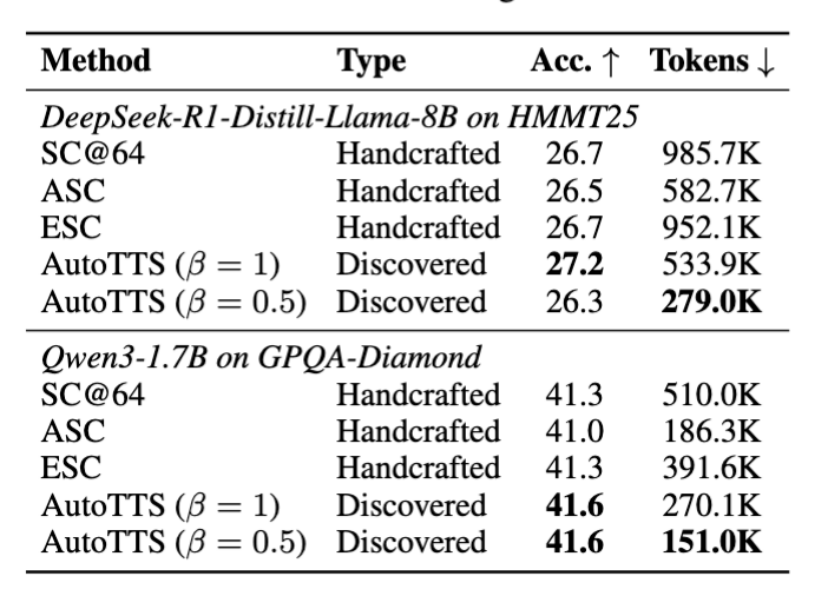
- 跨模型族——DeepSeek-R1-Distill-Llama-8B(Llama 系,蒸馏自 DeepSeek)on HMMT25:β=1 拿 27.2 精度 vs SC@64 的 26.7,token 从 985.7K 降到 534K
- 跨学科——GPQA-Diamond(研究生级科学,完全非数学)on Qwen3-1.7B:β=0.5 拿 41.6 vs SC@64 的 41.3,token 从 510K 降到 151K(70% 节省 + 精度还略高)
搜出来的 CMC 能跨模型族 + 跨学科泛化——这说明它学到的不是"AIME 题目的某些表面规律",是"长 reasoning 的通用结构规律"。
4.消融把第二层的设计验证了一遍
- 去掉 β 参数化:搜索集 token 从 575K 暴跌到 93K,但 held-out 精度从 53.1 掉到 49.0
- 去掉 execution traces:精度从 53.1 降到 51.6,token 反而暴涨到 824K——LLM 没了细粒度反馈只能瞎试,最后只能用"无脑加预算"对冲
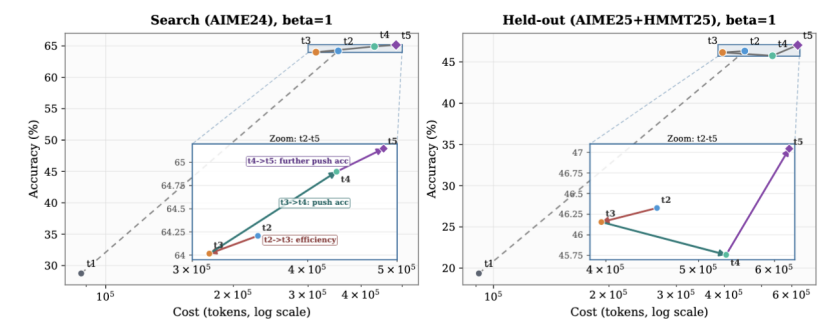
5.搜索过程的进化
5轮搜索里,LLM 第一轮提出的 controller 把 token 压得过死、精度崩盘;它从轨迹里看到这个失败模式,第二轮主动加预算;之后三轮在 efficiency 和 accuracy 之间交替微调,像一个真正的研究员在做 ablation。
结构化 vs 开放式
AutoTTS 想说的事,可能不止是 TTS。
最近auto research都在追求一件事:让 LLM 在尽可能开放的空间里自由探索。但 AutoTTS 用 40 块钱搞定的根本原因,恰恰是它一点都不开放——旋钮就那几个,β 压成 1 维,replay 把评估变成查表。结构化的代价是放弃自由度,回报是搜索本身变成可能。
沿着这个逻辑往前推——人类需要做的,是定义下一个 TTS:找出那些被掩盖在"风格各异的手工方法"底下、其实是一个干净搜索问题的领域。剩下的,交给 LLM 在这个结构化的环境里自己搜。