
随着大基础模型的崛起,视觉-语言-动作模型 (VLA) 展现出了极大的潜力,通过继承丰富的视觉理解和语言基础,为通用机器人策略学习提供了可扩展的途径。
然而,目前的VLA研究领域依然处于一种“原始汤 (primordial soup)”阶段——充满了各种天马行空的探索和设计,但缺乏清晰的架构。
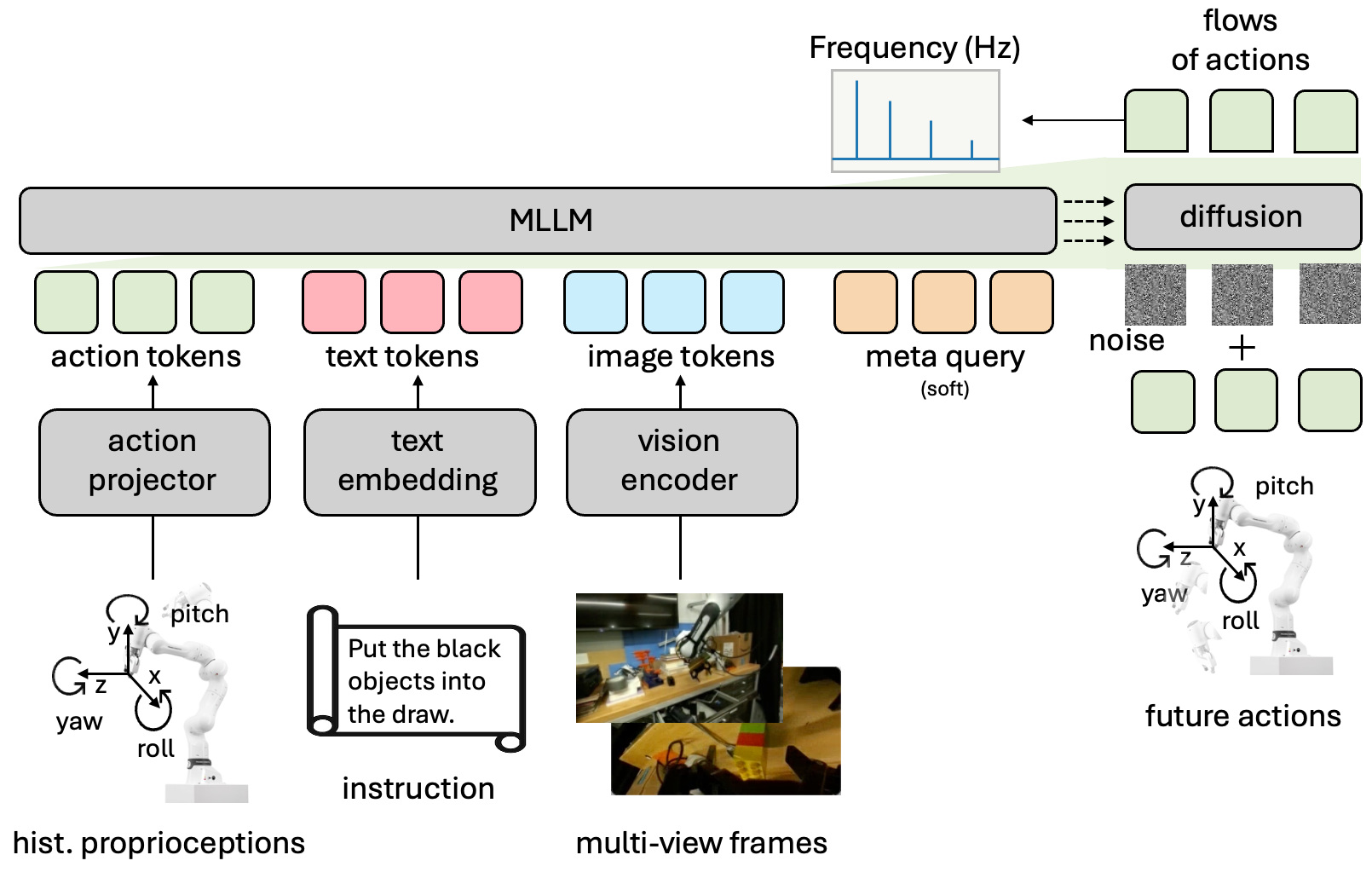
A组说自己的模型很强,取得了非常棒的性能,B组也说自己的模型达到了SOTA。但是由于各家在训练协议和评估设置上的不一致,我们其实很难辨别到底哪些设计选择才是真正起核心作用的。

为了给这个碎片化的设计带来秩序,我们决定回归本质:在统一的框架和评估设置下,从最基础的模型出发,全面重新审视VLA的设计空间。
论文:VLANeXt: Recipes for Building Strong VLA Models
链接:https://arxiv.org/abs/2602.18532
代码:https://github.com/DravenALG/VLANeXt
4月14日(周二)晚8点,青稞Talk 第120期,新加坡南洋理工大学 MMLab 博士生伍晓鸣,将直播分享《VLANeXt:12条设计准则,从入门到精通的 VLA 终极“配方”》。
MMLab@NTU联合中山大学推出VLANeXt,一份从入门到精通的VLA终极“配方”,12个维度带你从零构建高性能VLA!
分享嘉宾
伍晓鸣,MMLAB@NTU的一年级博士生,我以第一作者的身份在ICCV、ECCV、AAAI等国际会议发表了4篇论文,并且一共发表论文二十余篇,参与的方向有具身智能、视觉生成、模型轻量化等等。同时也多次担任顶会顶刊的审稿人,例如TPAMI,IJRR,CVPR,NeurIPS等。
主题提纲
VLANeXt:12条设计准则,从入门到精通的 VLA 终极“配方”
1、VLA 研究的“原始汤 (primordial soup)”困境
2、VLANeXt 结构设计: 12条关键设计准则
3、VLANeXt 真机部署及效果验证
4、AMA (Ask Me Anything)
直播时间
4月14日(周二)20:00 - 21:00