作者:钱泽中
原文:http://xhslink.com/o/7qoBKO5BfoI
前言
前两天ICML刚结束,合作的一个项目从3.25 rebuttal涨分到了3.75着实很厉害,这个paper主要做的事情是让world model从预测RGB改为预测Mask,然后增强了鲁棒性。他claim的点是减少了环境背景的影响:
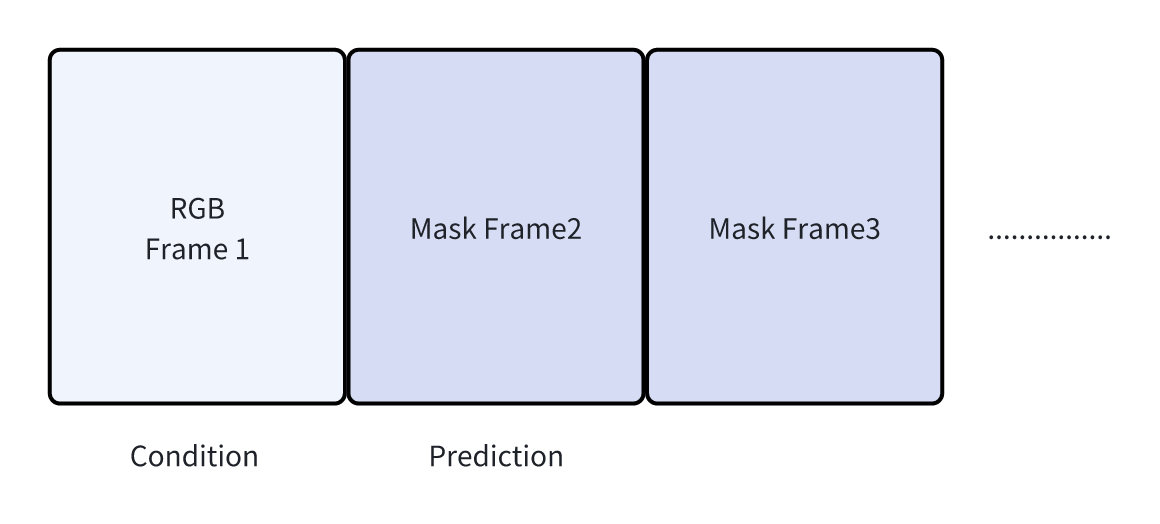
这时我不禁思考,所谓的减少环境背景的影响,实则是增加了对机器人本体、物体的一个权重,让后面的无论IDM,或者action head更容易关注到机器人的动态,并且让world model在预测未来时考虑的东西变得更少。
同时,除了简化,本质上还是让world model做了一个事儿:预测mask。相当于在简化背景的同时强制世界模型去做一个语义剖析的任务,比较类似multi-task learning。总结一下,鲁棒性更好的原因是:
- 只需要考虑机器人本体以及任务相关物体
- 做了一个mask语义的multi-task learning
除此之外,对于mask这个东西,是很好剪枝的,也就是说,我们可以通过一定的手段,让mask的预测更快(例如RGB有255,mask可能最多只有len(class)。所以预测mask latency< 预测RGB latency.
加速的小巧思:一路走向FastWAM的构想
既然预测mask<预测RGB,那么我们为了加速,可以进一步这么做:
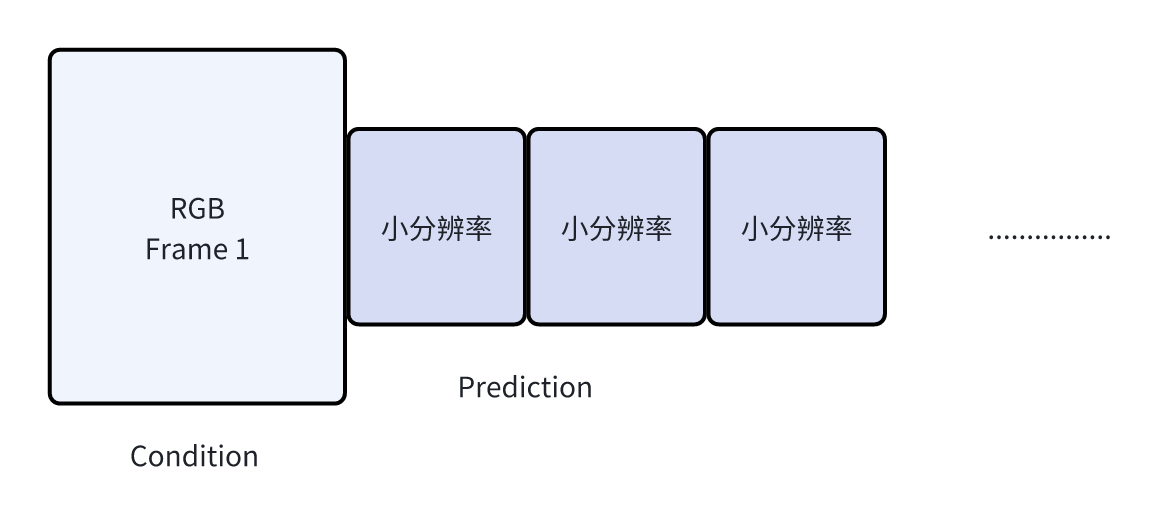
因为实际机器人在做决策的时候,我的预测帧=只给动作执行用,分辨率不用太高,让IDM/Actor看清机器人本体就行,RGB Frame=感知+决策,我需要看清condition里面桌子上物体具体是什么才可以规划动作。因此这个架构在信息层面是合理的。并且缩小分辨率可以加速。
那么进一步简化,我们还可以这么做:
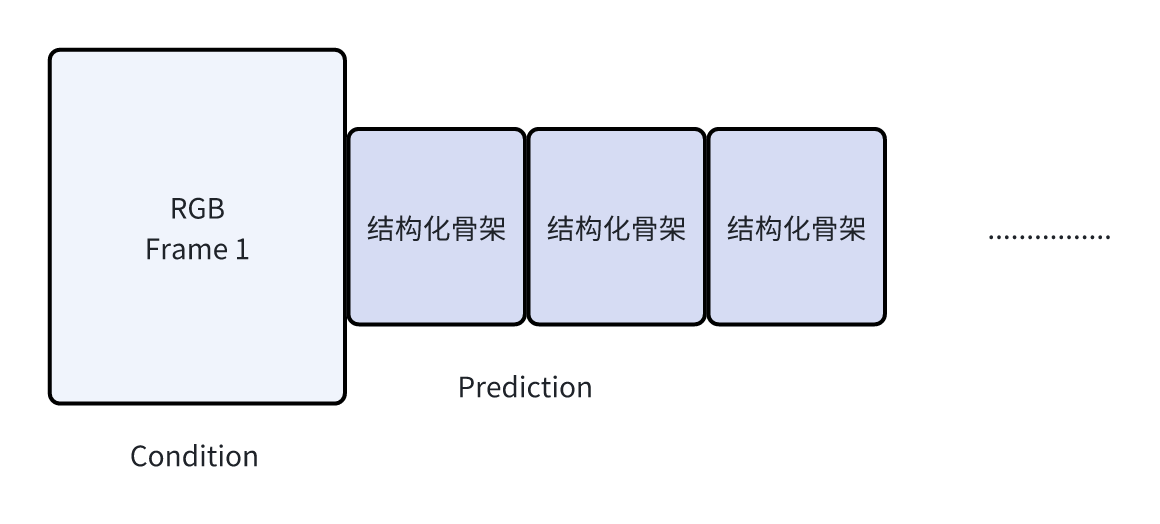
我们直接生成机器人的骨架,那么这样结构化的数据比pixel level的mask更能表征机器人的运动,并且开销还更小。
那么如果再进一步呢?
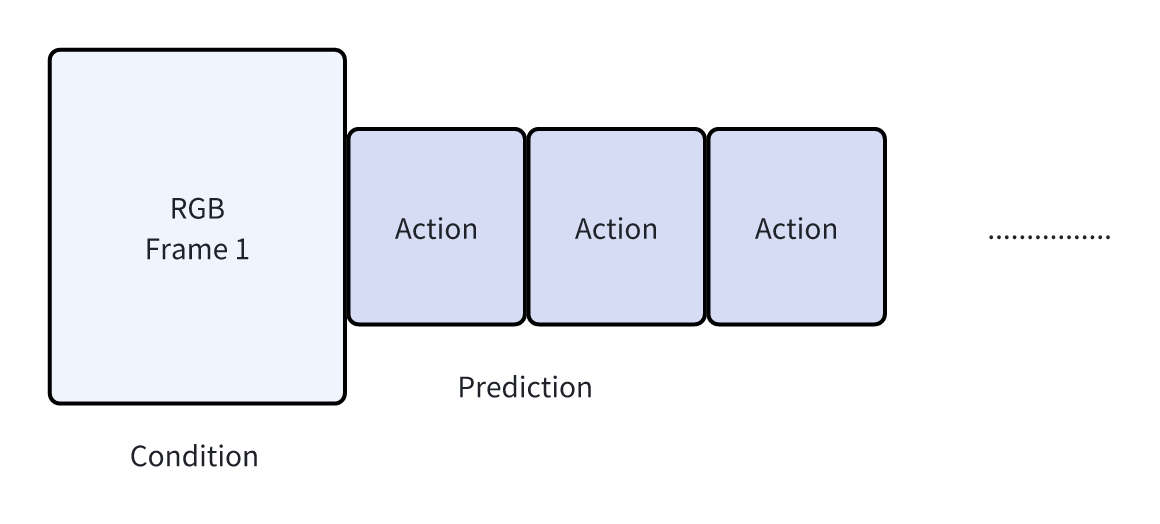
终于,我们加速到极致,推出了FastWAM的核心观点:我直接用MoT根据单帧RGB预测action,我并不是没有做world model prediction,而是world model prediction被直接结构化、抽象化,曾经的RGB变成了Action。最终达到了终极的加速目的。当然一路上损失了很多,损失了对语义的预测监督、Loss可能变得比较稀疏。
这个时候,细心的可能就会问了:哎呀哎呀,前面的都是video dit在做预测,你现在mot一下,用actor做了预测了,那不是本质上就不是world model prediction嘛?
我觉得应该从两点回答:
- 1.action这样小维度的预测,用整个video dit不值得,太大了,太重了,冗余信息太多了,比较浪费
- 2.不知道有没有注意到FastWAM的一个细节,action dit是由video dit插值得到的,这就意味着actor会继承video model的预测能力。
和Cosmos一对比:
| Cosmos-Policy | FastWAM | |
|---|---|---|
| Action head | 使用原生video backbone,把action当多视角。因为video backbone重,并且action backbone不独立,所以必须要repeat action来缓解梯度淹没 | 从video backbone插值小的action backbone,单独训练,无需repeat action,但是仍然在做预测。 |
Multi-Task Learning的小巧思:走向Cosmos-Policy
在复现cosmos-policy的时候,我训练出一个在robotwin上巨烂的结果:policy和羊癫疯一样,根本不去完成任务,而是只是在原地打转。我们再看回Cosmos Policy的主图:
-OwCS.png)
如果说Masked World Model是让模型做语义+动作的multi-task learning,Cosmos Policy就相当于强迫整个Video DiT去同时做action、proprio、rgb和value的multi-task learning,我在训练的时候没有用到value标签,据业内人反馈,用不用value差异很大,包括训练和推理时。
总之这么多变量的存在就让cosmos policy的video backbone在做一个巨大的multi-task learning。也是可以看出nvidia组很有野心,想要通过这个架构做一个物理世界的AGI backbone这样子。总之我觉得是合理的,但是不知道为什么cosmos-policy官方的post-train这么拉,不然真的比较愿意拿他去做很多后续工作。
总结
总之深入思考之后又是比较惊喜吧,从Masked world model能推出这么多经典paper的思路来,关于multi-task learning以及fast wam的思路显然都有一定trade-off,如何集百家之长或许是之后world action model的一个重要问题。