作者:Frankdark
https://zhuanlan.zhihu.com/p/2026908932694647597
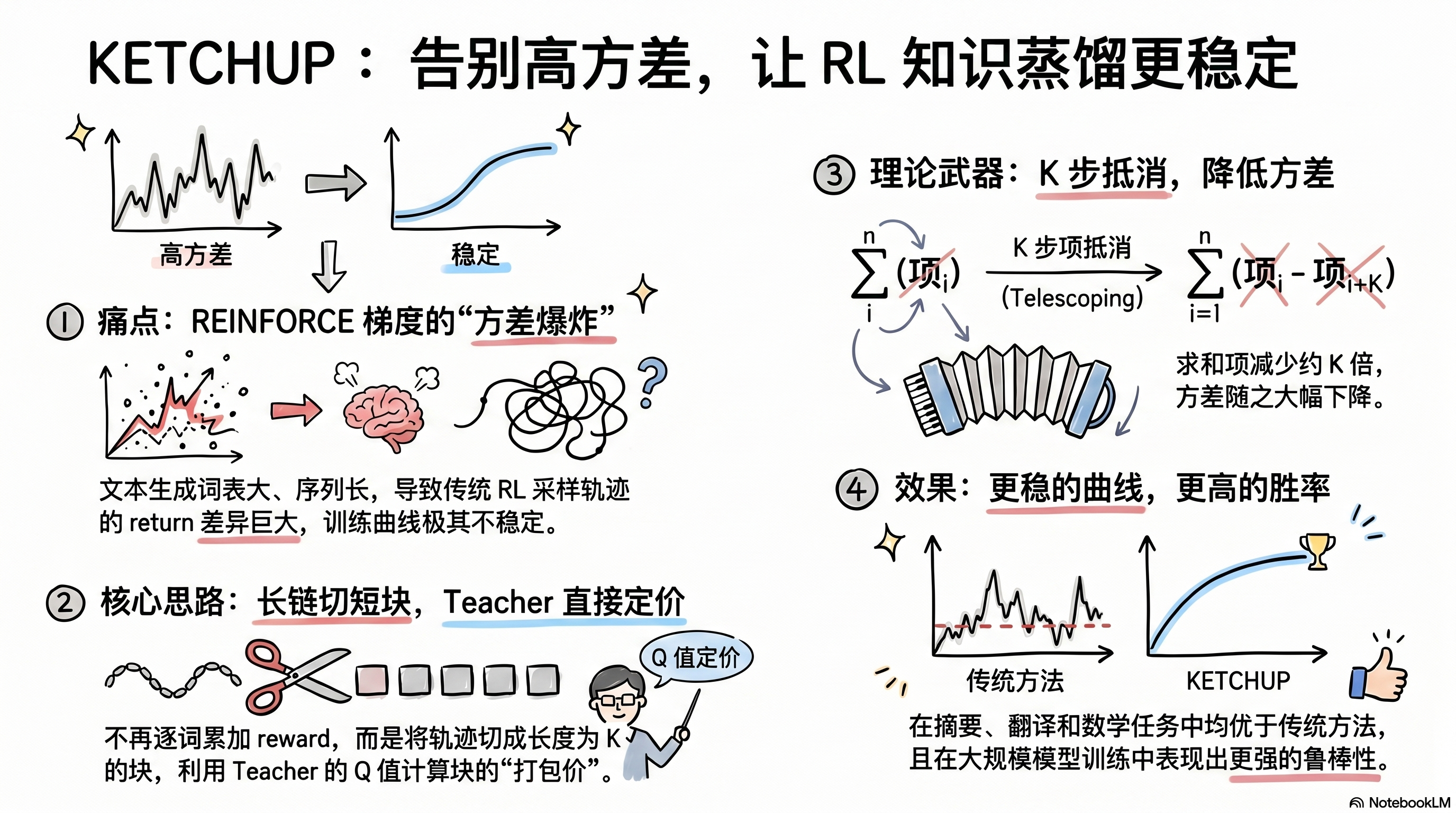
最近在做 RL-based knowledge distillation 的过程中,我们被一个老生常谈的问题折磨了很久:REINFORCE 的梯度方差太大,训练极其不稳定。
最终我们提出了一个基于 K-step return 的方法(叫 KETCHUP),比较有效地缓解了这个问题,工作发表在了 EACL 2026 Findings里面。
这篇文章想聊聊我们的动机和核心思路,尤其是理论层面的直觉,希望对做相关方向的同学有帮助。
背景:RL 做知识蒸馏,为什么会有高方差问题?
先简单回顾一下背景。知识蒸馏(Knowledge Distillation)大家都很熟悉了:用大的 teacher 模型指导小的 student 模型学习。传统的蒸馏方法(KL散度、SeqKD 等)本质上都是在让 student 去模仿 teacher 的输出分布。
但文本生成有个经典的 exposure bias 问题:训练时 student 是沿着 teacher 的 prefix 去逐词学习的,推理时却要用自己之前生成的 token 来做决策,这个 train-test mismatch 会导致 error propagation。
RL 提供了一种解决思路:让 student 自己去 explore(生成完整的序列),然后根据 teacher 给出的 reward 信号来更新策略。
Li et al. (2024) 的 LLMR 方法就是这个思路:通过 Bellman Optimality Equation 从 teacher 的 logits 中诱导出一个逐步的 reward function,然后用 REINFORCE 算法来训练 student。
问题在于,REINFORCE 本身就是出了名的高方差。它用 Monte Carlo 采样来估计梯度,而文本生成的 action space 是整个词表(几万甚至十几万 tokens),序列长度又不短,导致不同采样轨迹之间的 return 差异巨大。实际训练中,loss 曲线非常 noisy,学习过程极不稳定。
这就是我们要解决的问题。
核心思路:把长链条切成短块,用 teacher 来”直接定价”
我们的想法其实很朴素。
先说大白话版本:REINFORCE 的高方差来源于长序列的逐步累加。你采一条长度为 T 的轨迹,return 是 T 步 reward 的求和,每一步的 reward 都有随机性,累加起来方差自然就大了。
那能不能不逐步累加,而是把长序列切成若干段,每段直接用 teacher 给一个”打包价”?
这就是 KETCHUP 的核心思路。具体来说:
- Student 采样一条完整轨迹(长度为 T)
- 把轨迹切成若干个长度为 K 的 block
- 对于每个 block,我们不再逐步累加 reward,而是利用 teacher 的 Q-value 直接计算出这个 block 的”总 reward”
- 最后把所有 block 的总 reward 加起来,作为 policy gradient 的训练信号
这里的关键在于第 3 步:怎样用 teacher 直接给一个 block “定价”?
理论推导:从单步到多步的 Bellman 展开
直觉解释
回顾一下 LLMR 中的单步 reward 定义。它利用 Bellman Optimality Equation,把 teacher 的 Q-value 分解为:
直觉上说:一个 action 的 reward = 这个 action 本身的价值 − 下一个状态的最优价值。也就是说,reward 衡量的是”你选的这个 token 相比于你接下来能做的最好选择,差了多少”。
现在,如果我们把连续 K 步的 reward 加起来会发生什么?
展开每一步的 reward 定义后,你会发现中间的项会telescoping(逐项消去)——前一步的 \max_{a'} q(s_{t+i+1}, a') 和后一步的 q(s_{t+i+1}, a_{t+i+1}) 对消(假设 student 走的是最优路径),最终只剩下首尾两个 Q-value:
核心公式推导
当然,student 的 policy 不一定是最优的,所以上面的 telescoping 不是精确的,而是一个近似。我们用 \hat{G}_{t:t+K} 来表示这个近似的 block return:
其中 \hat{s}_{t+K} 是 student 实际走到的状态。然后,把整条轨迹的 return 表示为所有 block 的 return 之和:
最终的梯度更新公式:
为什么方差降低了?
直觉很简单:原始的 return G_t 是 (T - t + 1) 个随机变量的求和,而我们的 \hat{G}_t 只有 \lfloor \frac{T-t+1}{K} \rfloor + 1 个随机变量的求和。求和项少了大约 K 倍,方差自然就小了。
更正式地,在 iid 假设下(这是理论 RL 研究中常用的假设),我们可以证明:
证明的核心思路是分别展开 \text{Var}[G_t] 和 \text{Var}[\hat{G}_t]。原始 return 的方差为:
而 K-step return 的方差为:
其中 \sigma^2_{\mathcal{S},\mathcal{A}} 和 \sigma^2_{\mathcal{S}} 分别是 Q-value 和最优 Q-value 的方差。两者一比,方差大约降低了 K 倍。
当然,天下没有免费的午餐。方差降低的代价是引入了一定的 bias:因为 telescoping 的精确性依赖于 student 走最优路径这一假设,而 student 并不完全是最优的。
好消息是,bias 会随着 student 接近 teacher(即训练过程中 student 变好)而趋向于零。同时,较小的 K 值也意味着更少的近似项,从而更小的 bias。
完整的方差证明和 bias 分析可以参考原文的 Appendix A 和 B。
和已有方法的关系
KETCHUP 本质上可以被理解为一种 REINFORCE-with-baseline 的变体。如果你把 \hat{G}_t 和原始 G_t 做差,会得到一个 baseline term b_t。
和传统 baseline(比如 batch 内的 mean return)不同的是:我们的 baseline 是从 teacher 的 Q-value 结构中推导出来的,而不是从采样数据中估计的。这意味着它不依赖于 batch 的代表性,在文本生成这种巨大 state-action space 的场景下尤其有优势。
和 Actor-Critic 相比,我们也不需要额外训练一个 critic 网络来估计 value function。这个 baseline 是”免费”的——因为 teacher 已经提供了我们需要的一切(Q-value function)。这和 DeepSeek-R1 中避免学习 critic 的做法也有异曲同工之处。
值得一提的是,我们的方法和 N-step TD bootstrapping 看起来有点像,但本质不同:N-step TD 中的 N 是 rollout 长度,需要学习一个 parameterized value function;而我们的 K 是 inverse Bellman expansion 的深度,不需要任何额外的网络。
实验结果
我们在三个不同领域的文本生成任务上做了实验:
- XSum(摘要生成):约 22 万篇 BBC 新闻文章
- Europarl EN-NL(机器翻译):英语到荷兰语,约 117 万句对
- GSM8K(数学推理):约 8000 道小学数学题
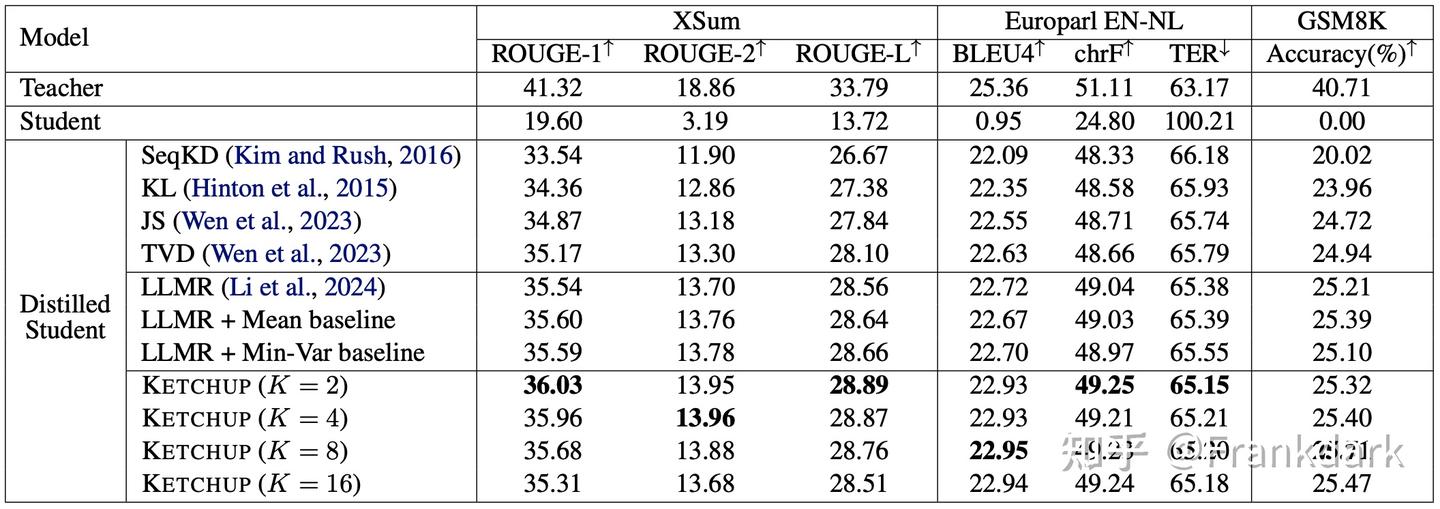
Teacher 用的是 FLAN-T5-XL(3B),student 用的是 T5-base(250M)。
主要发现:
1、KETCHUP 在所有任务上都优于 LLMR 和传统蒸馏方法。 在 XSum 上,KETCHUP (K=2) 的 ROUGE-1 达到了 36.03,相比 LLMR 的 35.54 有明显提升。在 Europarl 上,BLEU 从 22.72 提升到 22.95。在 GSM8K 上,accuracy 从 25.21% 提升到 25.71%。
2、传统的 variance reduction 方法(mean baseline、min-variance baseline)在文本生成场景下效果有限。 这验证了我们的判断:batch-based baseline 在大 action space 下不够 representative。
3、K 值需要适度选择。 太小方差减不够,太大 bias 太大。实验中 K \in \{2, 4, 8\} 普遍表现最好。
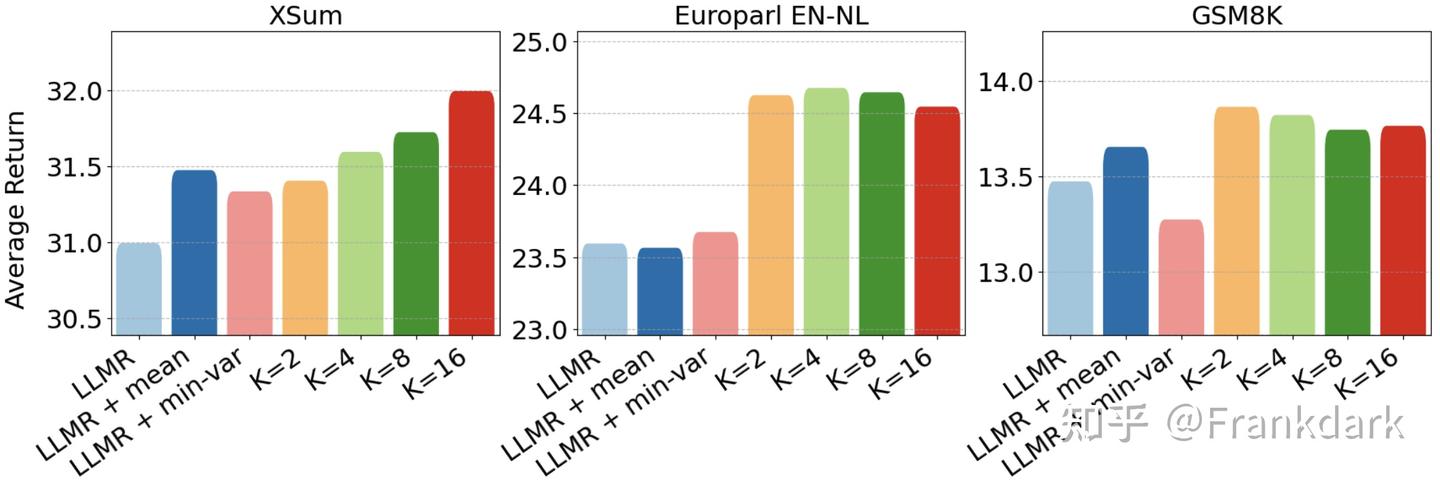
从 RL return 的角度看,KETCHUP 在所有任务上都达到了更高的 average return,说明我们的方法确实优化了 RL 的目标。
方差和 bias 的实证验证
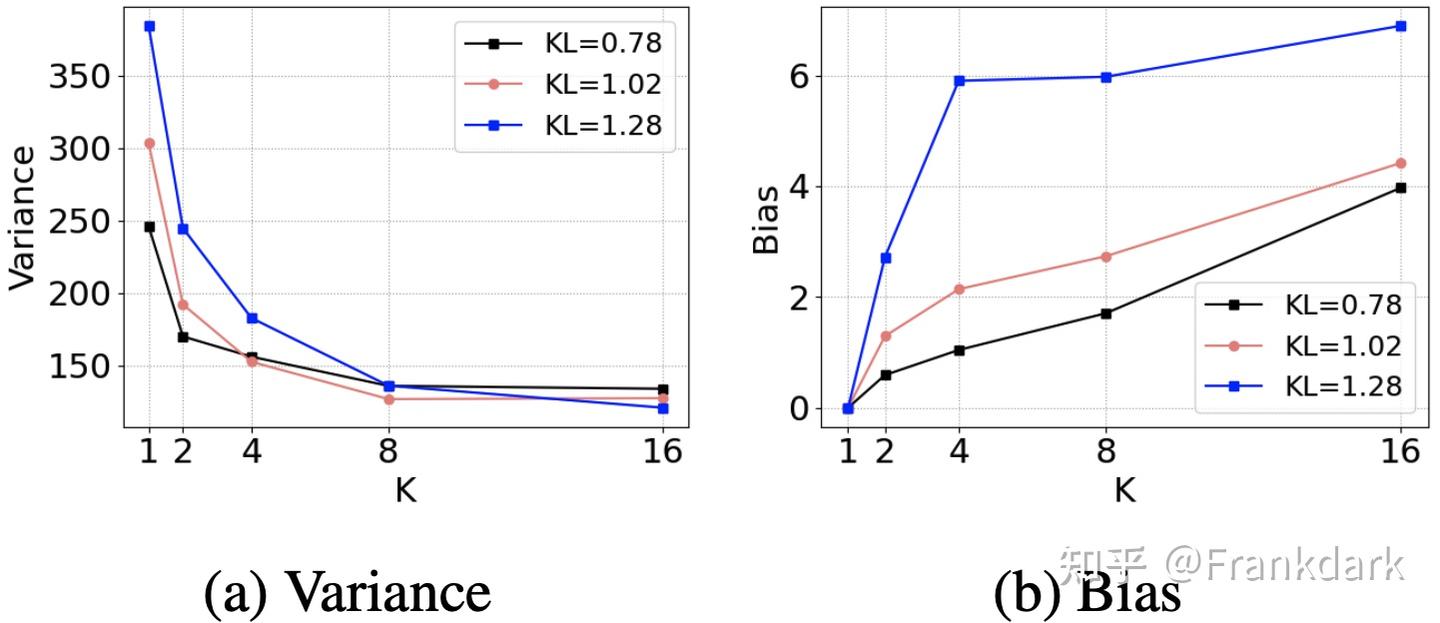
Figure 2 非常直观地展示了 bias-variance trade-off:随着 K 增大,方差急剧下降,bias 稳步上升。
而且当 student 初始化得越接近 teacher(KL 散度越小),bias 和 variance 都更低——这也说明了 pre-distillation 对 RL 训练的重要性。
不同模型规模的稳定性
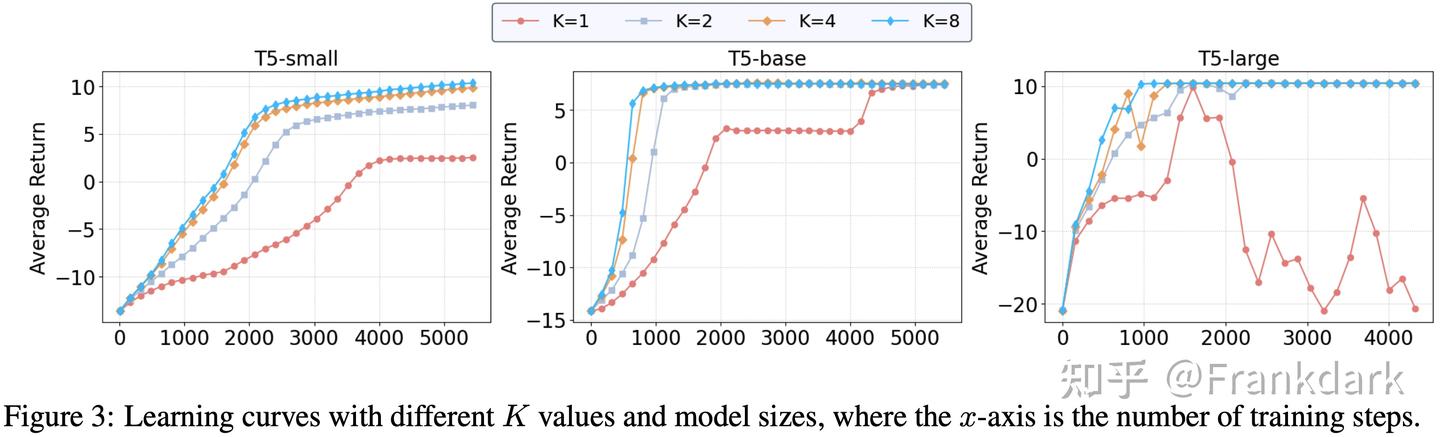
这张图特别有意思:LLMR( K =1)在 T5-large(800M)上训练时 learning curve 出现了明显的震荡和不稳定,而 KETCHUP 的曲线则平滑得多。
这和 RL 文献中的发现一致:大模型更容易过拟合有限的采样,导致训练不稳定。我们的方差缩减恰好缓解了这个问题。
LLM 评估
我们还用 Qwen2.5-72B-Instruct 做了 pairwise LLM evaluation,从 overall quality、informativeness、coherence 三个维度来评估。
KETCHUP 在 XSum 上的 overall 胜率达到 73.5%(对比 KL distillation),在 Europarl 上达到 58.8%,都是最高的。
一些个人思考
做这个工作的过程中,有几点感受比较深:
1. 文本生成的 RL 和传统 RL 的差异很大
传统 RL(比如 Atari)的 action space 小、state 是低维的,很多 variance reduction 技巧可以直接用。
但文本生成的 action space 是整个词表,state 是变长的 token 序列,这使得很多经典方法(比如 batch-based baseline)失效。需要结合文本生成本身的结构来设计方法。
2. Teacher model 其实提供了非常丰富的信息
在 KD 场景下,teacher 不仅给你 soft label,它的 logits 实际上就是一个 Q-value function。
我们的方法充分利用了这个结构——用 teacher 的 Q-value 来构造 baseline,而不是额外训练一个 critic。这种”免费”的 baseline 是 KD 场景特有的优势。
3. Bias-variance trade-off 是永恒的主题
我们的方法不是零 bias 的,但在实际训练中,适度的 bias 换来大幅的 variance reduction,效果是正面的。这和 TD learning、Actor-Critic 中的思想是一脉相承的。
如果你也在做 RL for LLMs 或者 knowledge distillation 相关的工作,欢迎交流讨论!