投机采样(Speculative Decoding)这两年几乎成了 LLM 推理加速的标配,但真正理解它的人不多。很多人停留在”小模型猜、大模型验”这一句话上,一到细节就懵:主模型 verify 的时候到底在算什么?为什么一次前向能验好几个 token?长上下文到底是帮忙还是帮倒忙?
这篇文章以 SGLang 里的 EAGLE-2 实现为例,把这些问题一个个拆开。读完你应该能回答:投机采样什么时候划算、draft 树是怎么长出来的、verify 那次前向的 query/KV/mask 分别是什么、为什么会”错位一位”、以及树形相对线性到底强在哪。
一、先回答最常见的困惑:投机采样什么时候划算?
投机采样的本质是一笔 交换:
用额外的计算量,去换更少的主模型前向步数。
这笔交换划不划算,只取决于一件事:你现在有没有”空闲的算力”可以烧。 而这又取决于系统处在哪种瓶颈下。
访存受限 vs 计算受限
LLM的 decode 阶段(逐 token 生成)有个特点:
- 小 batch / 低并发时:GPU 大部分时间花在”把模型权重从显存搬到计算单元”上,算力是空着的 —— 这叫访存受限(memory-bound)。
- 大 batch / 高并发时:足够多的请求把算力喂饱了 —— 这叫计算受限(compute-bound)。
投机采样的收益规律就此清晰:
| 场景 | 瓶颈 | 投机采样 |
|---|---|---|
| 低并发、延迟敏感、单/少路 | 访存受限,算力空闲 | ✅ 收益最大:一次验多个 token 几乎”免费蹭算力” |
| 高并发、吞吐饱和 | 计算受限,算力跑满 | ❌ 可能拖慢:额外候选直接抢占算力,被拒的 token 纯亏 |
所以工程上常见做法是按负载动态开关投机采样:低负载开、高负载关,而不是一刀切。
那”长上下文会不会反而降吞吐”?
这是个好问题,但答案不是简单的”会”。要拆成两股相反的力:
↑ 偏有利的一面
- 长上下文 → KV cache 巨大 → 同时能塞下的序列变少 → batch 天然变小 → 更可能停在访存受限区,这恰恰是投机采样的甜区;
- verify 时多个候选 token 共享同一份历史 KV 的读取(KV 只 load 一次,被多个 query 复用),把”读长 KV”这个最贵的开销摊薄了。
↓ 偏不利的一面
- verify 那一步的 attention 计算量随
候选数 × 上下文长度增长。短上下文时开销主要是固定的权重/MLP 部分;长上下文时 attention 的 FLOPs 占比迅速上升,于是每个被拒的候选浪费的算力变大; - draft 模型自己也要在长 KV 上做 attention,起草开销也涨;
- 系统从访存受限翻向计算受限的临界点提前到来。
结论:长上下文本身不必然降吞吐;真正决定方向的是 batch 大小 + 接受率。长上下文的作用是抬高了 verify/draft 的单步成本,侵蚀投机采样的安全边际。在接受率一般、又是大 batch 时,长上下文确实更容易把投机采样推到”净负”;但在小 batch + 高接受率下,长上下文仍可能是受益的。
| 维度 | 利于投机采样 | 不利 |
|---|---|---|
| batch / 并发 | 小 | 大(饱和) |
| 接受率 | 高 | 低 |
| 上下文长度 | 短~中 | 很长(抬高单步成本) |
| 瓶颈 | 访存受限 | 计算受限 |
二、EAGLE-2 总览:一张图看懂整个循环
EAGLE 系列的思路是:用一个极轻量的 draft 模型(通常就一层 Transformer + 复用主模型的 embedding和lm_head),基于主模型的 hidden states 来”猜”接下来的若干 token,然后让主模型一次性验证。
EAGLE-2 相对 EAGLE-1 的关键改进是:用 draft 模型的置信度分数动态构造一棵 draft 树,而不是用固定的树形。
SGLang 里的整体流程(对应 eagle_worker.py 的 forward_batch_generation):
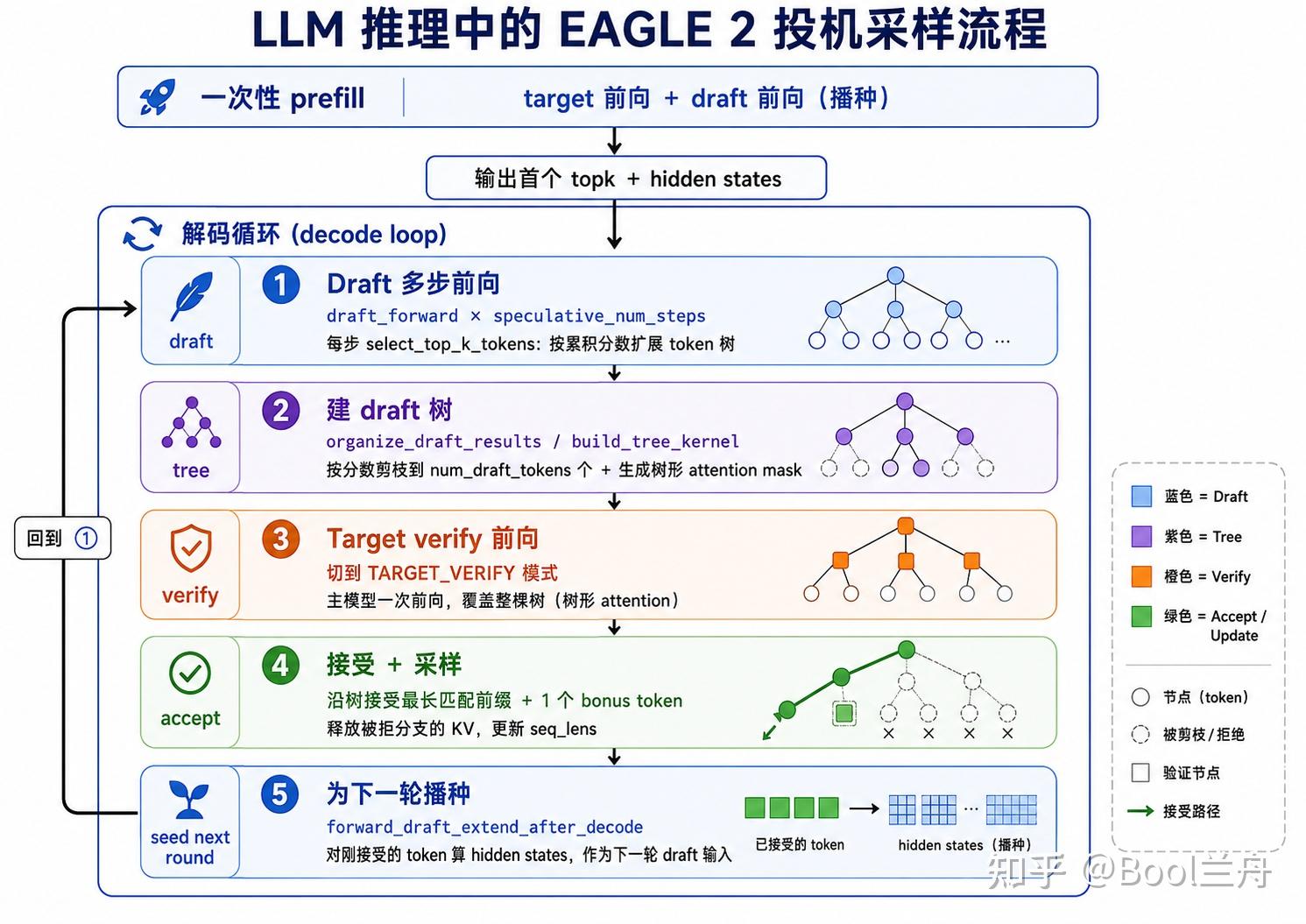
简单总结一下就是:draft 用小模型多步”长出”一棵按分数剪枝的候选树 → target 一次前向验整棵树 → 接受最长正确前缀 → 把接受结果重新播种,如此循环。
投机采样算法中最核心的两步:verify 和 accept 。
三、Draft 阶段:动态树是怎么长出来的
draft_forward(eagle_worker.py)会循环 speculative_num_steps 步,每步做三件事:
1.select_top_k_tokens:用累积路径分数(沿树路径的概率乘积)决定扩展哪些分支 —— 这就是 EAGLE-2”上下文感知动态树”的核心;
2.把每步的 score_list / token_list / parents_list 累积起来;
3.draft 模型只在 topk × bs 这一小批 token 上做一次前向,得到下一步的 topk。
跑完后,organize_draft_results 把所有候选按分数全局剪枝到 speculative_num_draft_tokens - 1 个(这个 -1 很重要,下文会解释),再由 build_tree_kernel_efficient 生成树形 mask、position、以及遍历用的索引,打包成 EagleVerifyInput。
两个关键超参先记住,后面调优会用:
speculative_eagle_topk:树每层有几个候选(树有多宽);speculative_num_steps:draft 走几步(树有多深);speculative_num_draft_tokens:剪枝后总共保留多少个候选节点(总预算)。
四、Verify 阶段:主模型一次前向,到底在算什么?
这是整篇最关键、也最容易误解的部分。我们一步步来。
4.1 “prefill 式前向”是什么意思
先回顾 attention 的本质:每个 token 算一个 query 向量 Q,去和它能看到的所有位置的 key/value(K/V) 做加权求和,权重 = softmax(Q·Kᵀ) 再叠 mask。
对比两种前向:
- decode 式前向(平时逐 token 生成):一次只送 1 个 query token,输出 1 个“下一个 token”分布。
- prefill / extend 式前向:一次送 N 个 query token,并行算出 N 个“下一个 token”分布。
verify 要在一步里检验几十个候选,显然得用后者 —— 一次前向吐出 N 个分布。这就是”prefill 式”的含义:多 query 并行,不是逐个。
4.2 query 是谁,KV 是谁
- query = 整棵 draft 树展平后的候选 token。每个候选都要算出”我后面该接什么”,所以每个都得当 query 送进去。
- KV = 历史(已缓存)+ 这些候选 token。
⚠️ 第一个困惑点:verify 不会重新 prefill 历史。 历史的 KV 早就缓存在主模型的 KV cache 里了。这次前向只把 draft 候选当作新 query 喂进去(类似一次只对新 token 的 extend),让它们去 attend 已缓存的历史 KV。
为什么候选也要进 KV?因为树里深层候选要 attend 它的祖先候选。比如候选 and(mat 的孩子)必须能看到 mat 的 K/V,才能算出”…the mat and 之后接什么”。而 mat 的 K/V 正是在这同一次前向里算出来的。
4.3 树形 mask:verify 的关键点
⚠️ 第二个困惑点:这里的 mask 不是普通的因果(下三角)mask,而是树形 mask。
如果用普通 prefill 的因果 mask,展平数组里靠后的候选会错误地 attend 到别的分支上靠前的候选,污染表示。所以 verify 换成树形 mask:
每个候选 query 只 attend “全部历史 + 它在树里的祖先链”,看不到兄弟、看不到别的分支。
拿一棵具体的树举例:mat / rug 是 depth1(根的两个孩子),and / on 是 mat 的孩子,soft 是 rug 的孩子。这张 custom_mask 长这样(✓=可 attend,·=被屏蔽):
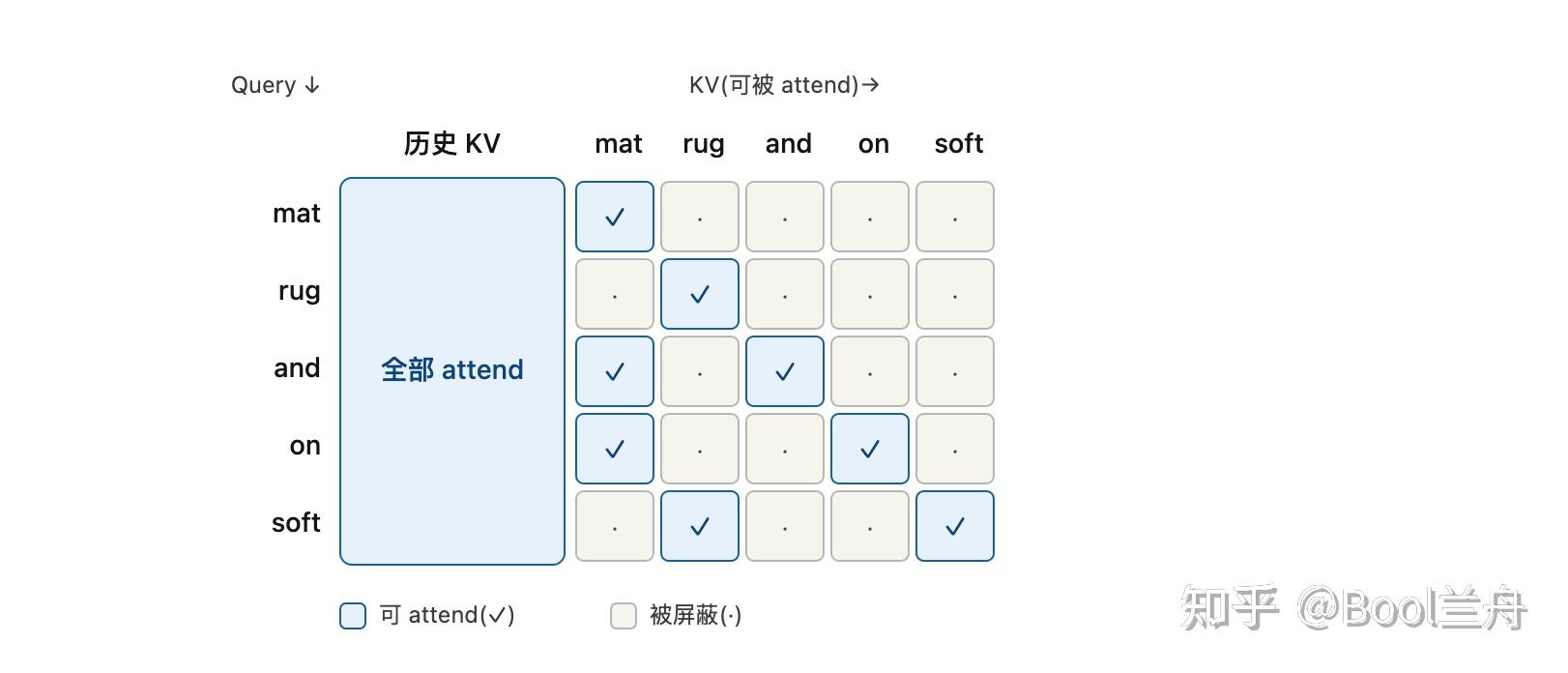
注意两个反直觉的地方:
soft(最后一行)不 attendmat、and(它们在展平数组里下标更靠前)—— 因为它们在另一条分支上。普通因果 mask 会让soft看到所有前面的 token,树形 mask 不会。and和on都 attendmat但互不 attend —— 它们是兄弟,各自代表mat之后的两种不同猜测,必须隔离。
每个候选拿到的 hidden state,因此等价于”假设只有它这一条路径是真序列”时该有的表示。这正是能在一次前向里、用一份共享的历史 KV,把整棵树所有路径都正确算出来的原因。
补一个常被忽略的点:每个候选还带一个 position id = 前缀长度 + 它在树里的深度。兄弟节点深度相同、position 相同。RoPE 用这个,保证每条路径的位置编码和”它真的是一条连续序列”时一致。
4.4 输出 logits 与”错位一位”
这次前向输出 [bs × draft_token_num, vocab_size] 的 logits。
⚠️ 第三个困惑点:logits 最后一维是词表大小 vocab_size,不是 hidden/embedding dim。 logits 是”下一个 token 在整个词表上的分布”。
还有最关键的错位一位(shift-by-one):
位置 i 处的 logits,预测的是”i 之后的下一个 token”,不是 i 自己。
所以:
- 第
mat行的 logits =P(下一个 token | …the mat); - 第
and行的 logits =P(下一个 token | …the mat and)。
verify 接受阶段就是拿这些分布去和 draft 树的子节点逐层比对。
五、接受逻辑:从线性链到树
5.1 先看最简单的线性情况(topk = 1)
当 speculative_eagle_topk = 1 时,每步只取概率最高的 1 个 token,树退化成一条线性链。这是理解接受逻辑最好的入口。
⚠️ 第四个困惑点(很多人会错):送进 verify 的 query 不是 num_steps 个,而是 num_steps + 1 个。
SGLang 建树的最后一步(eagle_utils.py)有这么一行:
draft_tokens = torch.cat((bonus_tokens.unsqueeze(1), draft_tokens), dim=1).flatten()
它把 bonus_tokens 拼在最前面。这里的 bonus_tokens 就是上一步已经确认的最后一个 token,作为这棵树的根。
为什么要 prepend 这个根? 因为要验证第 1 个草稿 d0,需要”d0 之前那个 token”位置上主模型的预测 —— 那个 token 就是根。没有它,d0 无从比对。
所以 topk=1、链长 num_steps 时:
- 草稿产出
num_steps个 token; - 送进 verify 的 query =
[根] + [num_steps 个草稿]=num_steps + 1个; - 因此
speculative_num_draft_tokens在 topk=1 下应配成num_steps + 1。
5.2 一个跑通的例子(topk=1, num_steps=3)
已确认最后一个 token = the(根)。草稿链:d0=cat, d1=sat, d2=on。 送进 verify 的 4 个 query = [the, cat, sat, on],位置 [L, L+1, L+2, L+3]。主模型一次前向后取每行 argmax:
| 位置 | 主模型 argmax | 比对对象 | 结果 |
|---|---|---|---|
| the(根) | cat | d0 = cat | ✅ 接受 cat |
| cat | sat | d1 = sat | ✅ 接受 sat |
| sat | the | d2 = on | ❌ 不匹配,停 |
| on | (未走到) | — | — |
产出 = [cat, sat] + bonus the(= sat 位置的预测)= 2 个 correct draft + 1 个 bonus = 3 个 token。
⚠️ 第五个困惑点:主模型 verify 时会”生成”新 token,而且最少产出 1 个。
注意上表里最后一位不比对任何草稿,它的 argmax 直接作为 bonus token。所以:
- 即使草稿全中,也会从最后一位多吐 1 个 bonus,单次 verify 最多产出
num_steps + 1个 token; - 即使一个草稿都没中,根位置也会产出 1 个 bonus(就是主模型本来该生成的那个 token)。
这也是投机采样输出分布严格等于主模型的根本原因 —— 最终吐出来的 token 全部来自主模型的分布,draft 只负责”猜”,猜错不影响正确性,只影响速度。
命名约定:含 bonus 的叫
accept_tokens,不含 bonus 的纯 draft 叫correct_drafts。
5.3 推广到树:长子 + 兄弟指针
树和线性的唯一区别:线性链每个节点只有 1 个孩子,树里每个节点有最多 topk 个孩子。
SGLang 用两个指针数组表示任意 n 叉树(经典的 first-child / next-sibling 编码):
retrieve_next_token[i]= 节点 i 的第一个孩子的下标(没有则 -1);retrieve_next_sibling[i]= 节点 i 的下一个兄弟的下标(没有则 -1);retrieve_index[i]= 第 i 个树节点对应到展平draft_token数组里的真实位置。
贪心 verify 的遍历逻辑等价于:
i = 0 # 根节点,直接接受
while True:
p = target_predict[i] # 主模型在节点 i 位置的 argmax(i 之后该接什么)
c = retrieve_next_token[i] # i 的第一个孩子
hit = -1
while c != -1: # 在 i 的所有孩子里横向找
if candidates[c] == p: # 哪个孩子的 token == 主模型预测
hit = c
break
c = retrieve_next_sibling[c] # 没中就试下一个兄弟
if hit == -1:
break # 没有孩子匹配 → 停,p 就是 bonus token
accept(hit)
i = hit # 命中 → 接受该孩子,下移
对比线性:那里每个节点只有一个孩子,内层 while 只跑一次 —— 所以线性是树的退化特例。树形唯一多出来的,就是那条 next_sibling 横向链:在同一深度的多个候选里,挑出与主模型 argmax 匹配的那一个。
5.4 一个树形例子(topk=2)
根 root 下挂两个 depth1 候选 A/B,A 再挂 C/D,B 挂 E:
root target 在 root 位置预测 → A
└─ A ← 接受 target 在 A 位置预测 → D
├─ C ← 查了不中
└─ D ← 命中,接受 D 是叶子 → 停,采出 bonus
B 分支、E 分支 未走到
对应的指针数组:
| 节点 | 下标 | next_token(长子) | next_sibling(兄弟) |
|---|---|---|---|
| root | 0 | 1 (A) | -1 |
| A | 1 | 3 © | 2 (B) |
| B | 2 | 5 (E) | -1 |
| C | 3 | -1 | 4 (D) |
| D | 4 | -1 | -1 |
| E | 5 | -1 | -1 |
接受过程:根接受 → 主模型要 A,沿长子指针到 A,命中接受 → 主模型在 A 位置要 D,先查长子 C(不中),沿兄弟指针到 D,命中接受 → D 是叶子,停;D 位置的预测作为 bonus。最终接受 root→A→D + bonus,num_correct_drafts = 2。
5.5 树形为什么比线性强?
注意一个关键事实:贪心 verify 最终只会接受一条路径(每个节点最多下移到一个孩子)。那为什么还要建树,而不是单纯一条更长的线性链?
因为树在每个深度都押了多个候选(
topk个),主模型的 argmax 只要命中其中任意一个就能继续。
上例 depth2 同时摆了 C 和 D,主模型想要 D 就能接住;线性链在那一步只能赌一个 token,赌错就停。也就是说:
- 线性:第 i 步接受概率 ≈ 单个草稿命中率 α;
- 树形(每层 topk 个):第 i 步接受概率 ≈ “topk 个候选里至少有一个命中”,显著更高 →** 平均接受长度
accept_length更长**。
代价是 verify 要算的候选从 num_steps 变成 num_draft_tokens(树更宽),attention 计算量更大 —— 这又回到第一节的结论:宽树在小 batch(访存受限)时近乎免费、收益大;大 batch(计算受限)时这些额外候选就成了纯开销。EAGLE-2 的动态剪枝就是为了把候选预算花在最可能被接受的分支上,而不是均匀铺满整棵满树。
5.6 采样模式(temp > 0)只换了”命中判据”
tree_speculative_sampling_target_only 走树的骨架完全一样,只是把贪心的”candidates[c] == argmax“换成拒绝采样:对每个孩子按 min(1, p_target / p_draft)(配合阈值)决定接受;一个孩子被拒就沿 next_sibling 试下一个;所有孩子都被拒,就从残差分布里采出 bonus。遍历结构不变,变的只是每一步”接 / 拒”的判定。
六、一个容易忽略的实现细节:draft 模型也存 KV cache
⚠️ 第六个困惑点:draft 模型会维护贯穿完整序列长度的 KV cache,但很小。
在 SGLang 里:
- draft 和 target 共享分配器和
req_to_token索引映射(保证 slot 编号、位置对齐); - 但物理 KV 缓冲是各自独立的 —— draft 存的是它自己那(通常)1 层 Transformer 的 K/V;
- 因此 draft KV 显存 ≈
(1 / target层数) × target KV,相对很小。一个几十层的 target 配单层 EAGLE draft,draft KV 大概只占百分之几。
什么时候写 draft KV:
- 接受之后:
forward_draft_extend_after_decode对刚接受的 token 跑 draft,把它们的 KV 正式落到 draft KV cache —— 这部分是”真实历史”,会一直留着; - draft 多步推测时:每步的 speculative token 也会临时写 KV,但这些是投机的,被拒分支对应的 KV 会被回退/释放,不进入长期历史。
七、关键参数与调优
| 参数 | 含义 | 调大的影响 |
|---|---|---|
| speculative_eagle_topk | 树每层候选数(宽度) | 接受长度↑,但 verify 计算量↑ |
| speculative_num_steps | draft 走几步(深度) | 单次最多接受 token 数↑,draft 开销↑ |
| speculative_num_draft_tokens | 剪枝后保留的总候选数(预算) | 接受率↑,verify 前向更重 |
调优心法:
1.低负载/延迟敏感:可以把树开大(topk、num_draft_tokens 调大),吃满空闲算力换接受长度;
2.高负载/吞吐优先:把树收小,甚至动态关掉投机采样;
3.接受率低时(draft 和 target 不够对齐):加大树的宽度往往比加深更有效,因为宽度直接提升”每层至少命中一个”的概率;
4.长上下文:警惕 verify 的 attention 成本膨胀,必要时收窄树。
八、常见困惑点速查(FAQ)
Q1:verify 用的是主模型还是 draft 模型? 主模型。draft 只负责生成候选,verify 一定是主模型来定夺。
Q2:verify 是把历史重新 prefill 一遍吗? 不是。历史 KV 已缓存,verify 只对 draft 候选做一次增量(extend / prefill 式)前向,让它们 attend 已缓存的历史。
Q3:一次 verify 怎么能并行验整棵树? 靠 custom_mask 这张树形掩码,让每个候选只看”历史 + 自己的祖先链”,一次前向就能正确覆盖所有路径。
Q4:logits 的第 i 行对应哪个 token? 位置 i 的 logits 预测 i 的下一个 token(错位一位),所以拿来比对的是 draft 的子节点,不是 i 自己。
Q5:主模型 verify 时会产出新 token 吗?至少几个? 会。接受的 token 和 bonus 全是主模型采出的。单次 verify 最少产出 1 个 token(bonus),最多 num_draft_tokens + 1 个。
Q6:为什么要在候选前面 prepend 一个”根”token? 那个根是上一步已确认的最后一个 token,用来给第 1 个草稿提供”它之前那个位置”的主模型预测,否则第 1 个草稿无从验证。
Q7:draft 模型也存全序列 KV 吗? 存,但因为通常只有 1 层,显存占比很小(约 target KV 的百分之几)。
Q8:树形最终只接受一条路径,那建树图什么? 图的是”每层多押几个候选,命中概率更高、接受链更长”。本质是用算力换接受长度,仅在算力有富余(访存受限)时划算。
九、小结
把 EAGLE-2 一整套串成一句话:
draft 小模型按分数”长出”一棵剪枝过的候选树 → 主模型用一次带树形 mask 的 prefill 式前向,为每条路径并行算出”下一个 token”的分布 → 沿”长子 / 兄弟”指针走树,用主模型的预测在每个节点的多个孩子里挑匹配项,命中就下移、不命中就停并采出 bonus → 把接受的结果重新播种,循环往复。
而它能不能加速,最终落在那笔交换上:有空闲算力(访存受限、小 batch、高接受率)时大赚,算力饱和(计算受限、大 batch)时反亏。 理解了这一点,你就知道投机采样不是”无脑开就快”,而是一个需要结合负载动态权衡的工具。
本文基于 SGLang 的 EAGLE-2 实现(python/sglang/srt/speculative/ 下的 eagle_worker.py、eagle_info.py、eagle_utils.py)整理。