作者:赖睿航,CMU CS Ph.D.
https://zhuanlan.zhihu.com/p/2045509863221064141

TL;DR
PithTrain 是一个精简、agent-native 的 MoE(Mixture-of-Experts)训练框架,整套实现约 1.1 万行 Python。其训练吞吐与成熟的生产级框架持平,同时显著降低了 AI coding agent 的使用成本。
在一组真实的针对训练框架的 agent 任务上,我们固定 agent 与任务、仅替换底层框架,观察到 PithTrain 最多可减少 62% 的对话轮数(turn)、节省 64% 的 GPU 时间。
我们把这种“agent 完成任务所需成本”的维度称为 agent-task efficiency。随着系统的构建与维护越来越多地交由 coding agent 完成,我们认为这一维度理应得到更多重视、与训练吞吐并重,成为一个值得认真优化的指标。
GitHub:https://github.com/mlc-ai/pith-train
Paper:https://arxiv.org/abs/2605.31463
英文博客:https://blog.mlc.ai/2026/06/01/pithtrain-compact-agent-native-moe-training-system
Hello 大家好!今天想给大家介绍我们组最近的一个工作 PithTrain。“Pith” 这个词本义可以指植物的髓部和柑橘类水果果皮底下白色的那一层,引申开来便有了“精髓、要点、本质”的意思。正如 pith 的意思所指,我们想做一个精简、agent-native,同时能够抓住 MoE 训练本质的框架。
事情要从去年开始说起。CMU Flame Center 在去年获得了一些珍贵的 GPU(当然了,跟业界相比自然还是少得可怜),刚好 @熊辰炎 老师有兴趣试试从头开始写一个训练框架。另一边,我们在 @陈天奇 老师这边过去几年一直深耕机器学习编译和 LLM 推理,在训练方面没什么经验,而这正好也是一个给我们试试水、探索 LLM 预训练背后究竟发生了什么的机会。于是,两边一拍即合,我们造训练框架的故事就这么开始了。当时我们觉得 MoE 模型会是今后大模型的主流,所以重心也都放在 MoE 模型的支持上。
初探训练框架的我们,自然要向能 “稳稳接住” MoE 训练的老前辈框架,Megatron-LM 和 DeepSpeed,学习一些先进经验。这些框架都相当成熟,经过多年的打磨和优化,对模型和特性的支持也很完善,有极致的性能,还有无数实际生产部署的经验加持。我们大概率会踩到的坑,这些框架背后的团队应该都曾踩过。
只是学的时候我们发现还是有一些地方比较麻烦。这些框架拥有庞大的代码库(大十几万行),繁多的抽象类和注册表,有时候还有一些核心功能被实现在 C++ 扩展里。
比如要找一个特性具体的实现机制,或者要看一个函数是在什么情况下被用到,仅仅是为了回答这些问题可能都要花很久去寻找答案。在去年那个时间节点,coding agent 远远没有今天这样的能力和普及程度,所以大多数时候我们都在践行“古法学习”和“古法编程”。
事实上,和很多小伙伴交流的时候会发现,大家多多少少都经历过类似的情况。
比如,拿到一个新集群的访问,本来想着赶紧把模型跑起来,结果第一周压根没训起来,全花在让框架先在这套环境上跑通这件事上。
再比如,今年 ML 顶会有人提出了个新架构,想拿来试试。于是一头扎进一个庞大的代码库,东改一处、西补一块,就为了让它还能跟已有的东西兼容,最后发现真正要改的其实没几行,可为了找到这几行、又不把别处弄坏,实际上动的代码远不止这么点。
而一年后的今天,coding agent 早已褪去了当年的青涩,从一个高级自动补全工具,长成了能真正搭把手的伙伴。修 bug、加功能、审代码、运维线上系统等等任务,coding agent 都已经样样精通。不少过去得靠资深工程师才敢碰的活,现在也开始放心交给它,而且 agent 的能力仍在不断提升。
而另一方面,前面提到的这些关于训练框架的麻烦事,虽然随着 coding agent 的进化在一定程度上变得简单了一些,但本质上依旧没有变。这些框架在设计之初并不是为了 agent 量身定制,而那些让人感到头疼的设计要素,对于 agent 而言仍是难关。
甚至有些时候,很多对人类专家很顺手的写法,到了 agent 这反而会造成一些新问题。比如很多模型复用相同一套 modeling 骨架,这对人或许很自然,可 agent 想搞清楚“这个调用点上到底跑的是哪段代码”,就得一个文件接一个文件地翻。
再比如那些用编译扩展写的算子 kernel,在榨取 GPU 最后一滴性能的同时,跨编程语言这一设计有时也会导致不清晰的报错信息,让 agent 在遇到报错时拿不到一行具体的 Python 代码来落脚,再加上在跨语言扩展里的每一次改动都可能需要重新编译一遍扩展。
其实这些也都不是框架的错。只是“为 agent 而生”的设计这件事,当年根本不是任何人的目标。而它究竟该长什么样,到今天也还没个标准答案。
与此同时我们意识到还有一个有趣的问题可能一直以来都没有被摆到台面上。大家评价一个训练框架好不好,基本都是在围绕吞吐量 tokens/s、MFU 展开讨论。可是在另外一个维度,对于一个框架“读懂它、跑起来、改下去”到底要花多少成本的讨论却鲜有耳闻。随着针对训练框架的开发任务越来越多地压到 agent 头上,这个问题似乎开始变得越来越有意思。
于是我们心里渐渐冒出一个很简单的问题:能不能有这么一个 MoE 训练框架——既不是只为“人来读、人来维护”而设计,而是让 agent 也能轻松理解、修改和演进,同时又不牺牲生产级的训练性能? PithTrain 就是我们顺着这个问题做出来的一次尝试。
从设计之初我们就开始追求双重效率(dual efficiency):一方面是不输生产级的训练吞吐,另一方面是更高的 agent-task efficiency (也就是让 coding agent 以更低成本理解、操作和扩展这套系统)。我们实打实地通过一些具体指标来衡量 agent-task efficiency:一个 session 跑了多久、用了多久 GPU、来回多少轮、每轮输入和输出的 token 数量。

PithTrain 是什么?
一句话概括,PithTrain 是一个端到端的 MoE 训练框架:给它提供一份已经 tokenize 好的语料之后,它可以自己处理从搭建分布式环境、启动训练,到最后导出 HuggingFace 能直接使用的 checkpoint 这一整套流程。
PithTrain 支持在 NVIDIA Hopper 和 Blackwell 上,用 BF16 或 FP8 训练 Qwen3-MoE、GPT-OSS 等这类模型。同时支持四种并行方式:流水线(pipeline)、数据(FSDP)、上下文(context)和专家(expert)。流水线并行我们用的是 DualPipeV schedule,能够实现 EP 通信与计算的 overlap。
整套系统分三层:最上面是应用层(训练循环),中间是引擎层(DualPipeV scheduler、优化器、checkpointing),最下面是算子层(一些 custom Triton kernel)。这三层目前全部加起来约 1.1 万行。
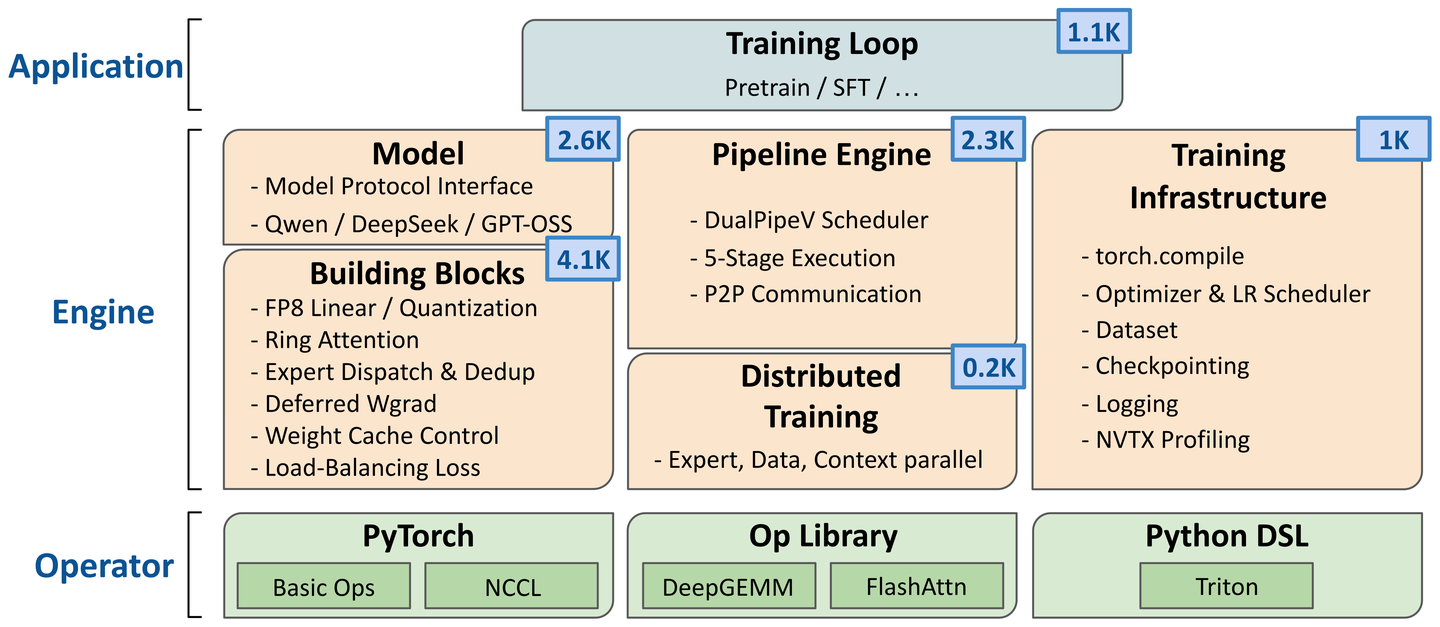
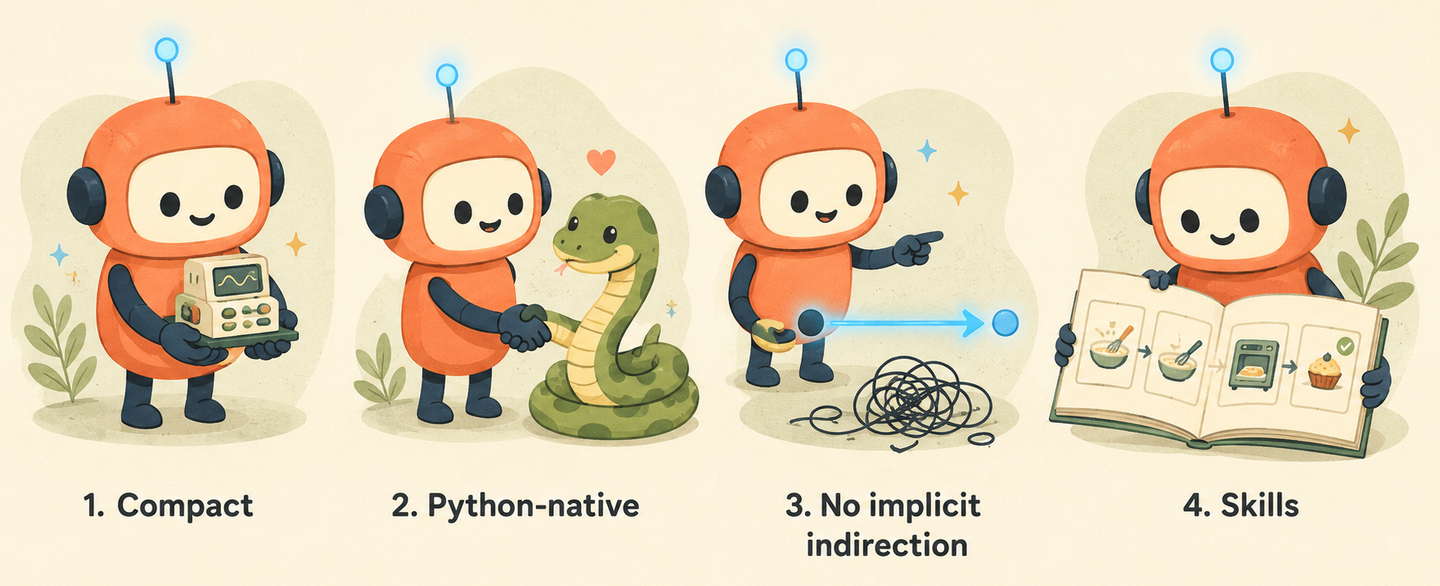
我们的四条 “agent-native” 设计原则
PithTrain 的设计围绕四条原则展开。实际上这四条里无论哪一条,单拎出来或许都说不上是个让人眼前一亮的新点子,但我们做的事情是把它们当成训练框架的“主要约束”来恪守,然后再去探究这么做是否有什么好处。
一、精简。
PithTrain 包含一个分布式 MoE 训练框架该有的功能,全部也就大约 1.1 万行,而相比之下成熟的生产级的框架动辄十几万行起步。
代码精简带来的好处非常直接:要搜的地方更少,要追踪的跨文件的依赖更少,改完代码之后要读多少才敢确认“改完整了”的地方更少。
还有一点尤其关键的是,如今 coding agent 基本支持 20 万到 100 万 token 的上下文窗口,代码足够精简意味着 agent 有能力在一个上下文窗口内把整个框架全读进来,一览无余,而不必反复 grep、四处摸索。
当然,随着进一步的开发,PithTrain 的代码库当然会渐渐扩大,但每新加一样东西,都得以这四条原则作为检验标准,配得上才能放进来。
二、Python-native。
PithTrain 整个栈都是纯 Python,因此 agent 自始至终只用集中在一门语言。报错的时候给出的是清晰的 Python traceback 而不会是来历不明的错误,也用不着停下来等编译扩展重新 build。
我们也用 Triton(今后还可以有其他 DSL)在 Python 里写了少数 kernel,这些 kernel 在训练中第一次跑到的时候会自动 JIT 编译。
三、不要 implicit indirection。
生产级框架习惯用 indirection 来拼装模型。比如存一个 callable、查一张 registry、运行时再拿字符串去解析,还有若干模型共用同一套 modeling 骨架。
复用固然省事,但代价是:单看一个调用点,往往很难说准它实际跑的是哪段代码。在 PithTrain 里我们采用直接调用,每个模型都老老实实待在 models/ 下专属于它的那个文件里,自成一体。这实际上是略微牺牲“跨模型复用”换来了“一个模型能在一处从头读到尾”的 tradeoff。
四、提供 agent skills。
很多人类开发者积累的经验和知识,coding agent 光靠读代码是读不出来的,比如多卡的 run 该怎么起、一条正常的 loss 曲线该长什么样、profile 怎么搞才干净…… 而 agent skill 作为一份简短的、用到时才即时加载的 playbook,是我们给 agent 传授经验的绝佳方式。
在 PithTrain 里这些反复要做的事和相关知识都被打包成了一组 agent skills,包括移植模型、profile 显存、跑 Nsight Systems trace、验证正确性等等。
而且每个 skill 最后都会落到一个具体的可执行的脚本上,给出一个明确的 PASS/FAIL 结果,而不是 agent 自信满满给自己打满分,到头来我们发现它跑错了。
设计层面的主要考量大致就是这些。接下来我们验证一下这些设计原则在一起到底会发生什么化学反应。
不输生产级框架的训练性能
代码再精简,跑得不快也是枉然。我们在一系列 MoE 模型上做了测试,覆盖单机、多机,H100、B200,BF16、FP8。
PithTrain 的吞吐都追平了成熟的生产级框架,在测过的所有配置里,我们与基准框架的差距不超过 1.4%,而这靠的全是大家耳熟能详的标准手段,没有任何黑魔法:DualPipeV 和 EP 的计算-通信 overlap、torch.compile、延迟计算 weight gradient、融合的 SwiGLU kernel、expert dispatch 去重,再加上跨 micro-batch 复用 FP8 权重等等。具体的逐项配置和性能的完整表格都在论文里。
PithTrain 在训练正确性同样有保证。在配置对齐的前提下,PithTrain 的预训练 loss 曲线能在几十亿 token 的尺度上与生产级框架保持一致。训练出来的模型在六个标准下游 benchmark 上的精度也都落在统计噪声范围以内(完整曲线和逐项数字同样在论文里)。PithTrain 训练输出的 checkpoint 导出成 HuggingFace 格式后,可以直接在 vLLM、SGLang、lm-evaluation-harness 里跑起来。
接下来,才是我们真正想聊的部分。
探索与衡量 agent-task efficiency
相比起只需要掐时间就能测的训练吞吐,agent-task efficiency 的测量明显“虚”得多。
如今有很多测试 coding agent 用的常规 benchmark(SWE-bench 之类),他们做法是把代码库固定、轮换不同的 agent,为的是给 agent 本身打分。
而为了检验训练框架本身的 agent-task efficiency,我们的做法刚好“相反”:维持 agent 不变、任务不变,每次只替换底下那套框架。
这样一来,agent 的表现之间的差异只可能是框架带来的差别,跟模型本身无关。我们固定使用 Claude Code(Opus 4.7),设计了三档大家会真的拿训练框架来做的任务:
- Understand (理解): 回答诸如“device mesh 是怎么搭起来的?”这类问题。Agent 不需要改动代码,只需要回答问题。
- Operate (操作): 把环境配好,让训练跑通、采集一条 routing trace、跑一份 profile 并报告跑得最慢的三个 kernel。
- Extend (扩展): 从头到尾移植一个全新架构(Differential Transformer、DynMoE、MoBA、MoE++),并对着论文核对结果。
值得注意的是,在我们的测试中每一个任务、在每一个框架上,agent 最终都顺利做完了,没有哪个中途挂掉。所以这儿关键问题其实不是 agent “能不能做完”(agent 这么强,怎么会做不完呢?),而是“为了做完所需要的成本是多少”。我们每个任务都跑了三遍然后取中位数,下面的数字都是越低越好。
Understand. 回答一个关于代码库的问题本质上是去找相关代码写在什么地方。对于精简而没有 implicit indirection 的代码库而言,寻找答案的过程相对来说比较简单:十二个问题问下来,agent 在 PithTrain 上得到正确答案的过程最多比在 Megatron-LM 上少花 67% 的轮数,而且每一轮的输入 token 也更少。Agent 在所有框架上所有问题都答对了。
Operate. 这一档里,agent 需要把系统真正跑起来并输出任务所要求的 artifact。在 PithTrain 上 agent 还会自己主动去取我们提供的 agent skill:比如“报出最重的几个 kernel”这个任务,不需要主动提醒它 skill 的存在,agent 自己也能够去触发 capture-nsys-profile 这个 skill。
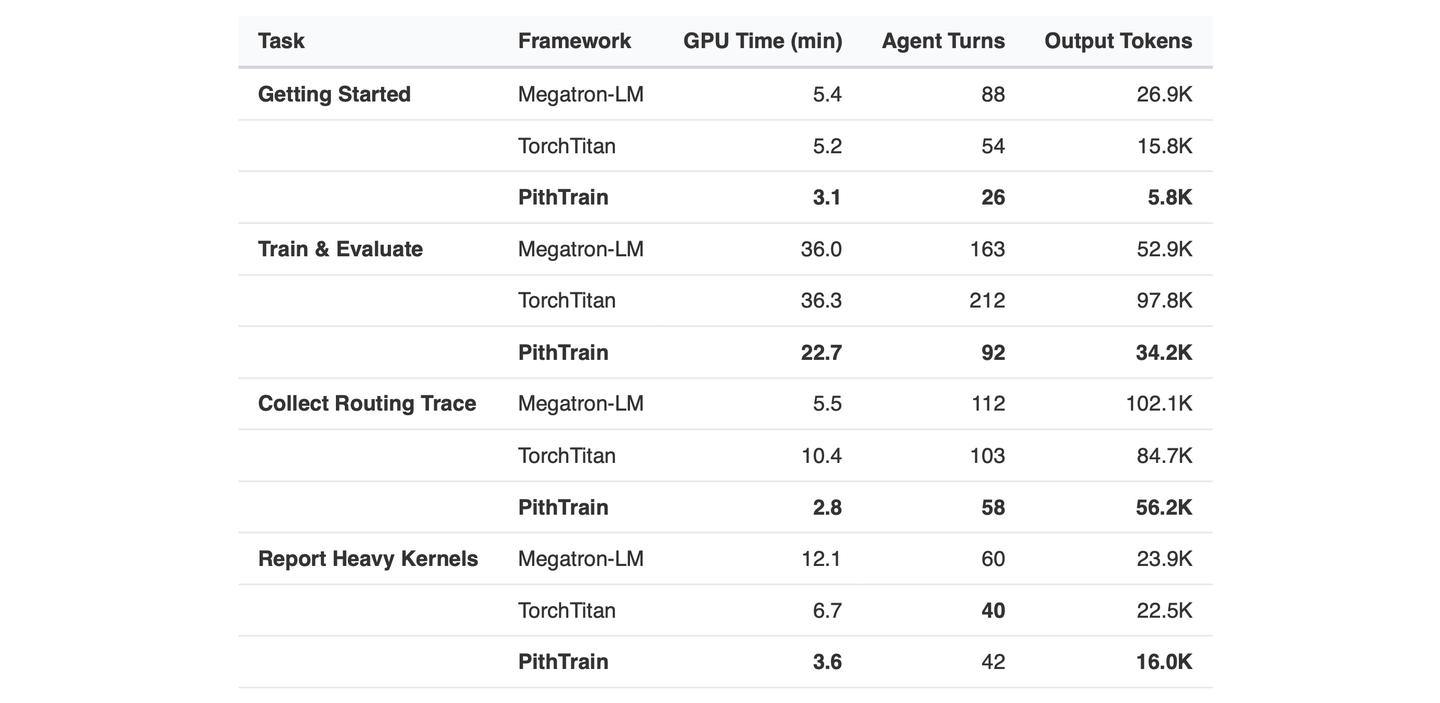
对于 “Getting Started” 这个任务,agent 在 PithTrain 所花的轮数从 88 轮降到了 26 轮。在这些任务上,agent 比在 Megatron-LM 上最多少用 70% 的轮数、少写 78% 的 token。这里一半要归功于代码精简,另一半要归功于那些被它自己调起来的 skill。
Extend. 最后这一档能够更全面地验证框架设计对 agent 行为的影响。移植一个新架构在本质上是一个重复“改代码、跑训练、理解报错、再改”这几个步骤的循环,每跑一次测试都要增加 GPU 时间,每一个没理解的报错,都可能让 agent 多尝试好几轮。
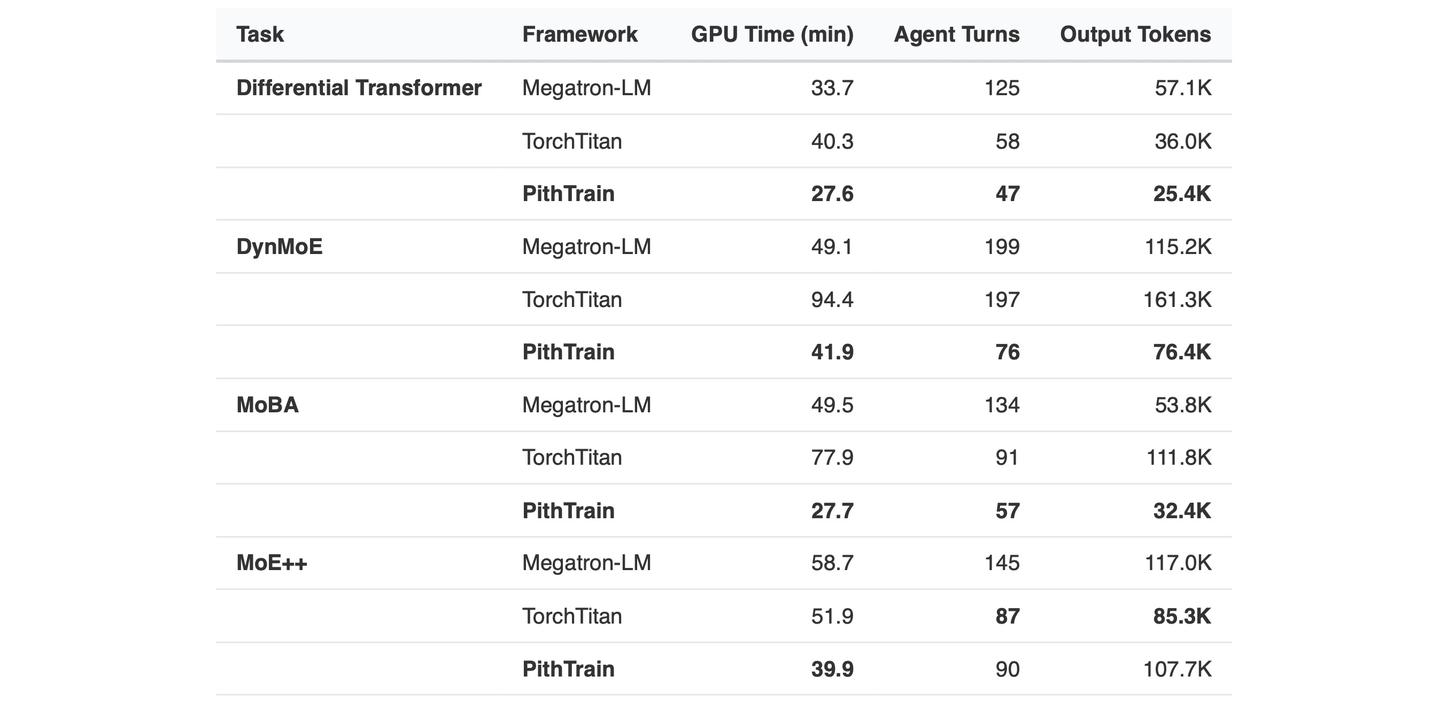
四个架构上,PithTrain 用掉的 GPU 时间都是最少的(比 Megatron-LM 最多省 44%,比 TorchTitan 最多省 64%);而在最难的 DynMoE 上,它比 Megatron-LM 少用了 62% 的轮数。主要的差距来源于在 agent 不断试错的这个过程中,框架出错在什么地方。
在 PithTrain 上,bug 通常就落在 agent 刚改过的那个文件里,报错也基本是一条直接点出哪一行的 Python traceback,debug 能够被控制在局部范围。
在更大的框架上,报错往往离实际改动的地方有一定距离,比如 agent 新加的一个 CLI flag 跟系统别处的一个设定撞了车,又或者错误是从某个编译好的 kernel 内部冒出来的,报错信息里一行 Python 都没有。
每当遇到这种情况,agent 都得先多花好几轮定位问题到底在哪儿,才能开始修,而一整个调试循环拉开的差距,大半都来自这里。
下面是一个具体的用 coding agent 实现 MoBA 的例子:在每个框架上,“editing” 都占据了 token 消耗的大头,但 PithTrain 的改动要小得多(4.7K token,Megatron-LM 和 TorchTitan 分别是 13.1K 和 22.2K)。
而光是 “exploring” 这一项,agent 在 PithTrain 上的 token 开销也相当少(2.2K,Megatron-LM 是 10.2K),这是因为在 PithTrain 里找到需要修改的地方和理解 traceback 能够少读很多代码。也正因为每一轮读得少,PithTrain 的单轮上下文长度在整段 session 里始终处在低位,而其他两个框架上的上下文长度则有更大幅度的增长。
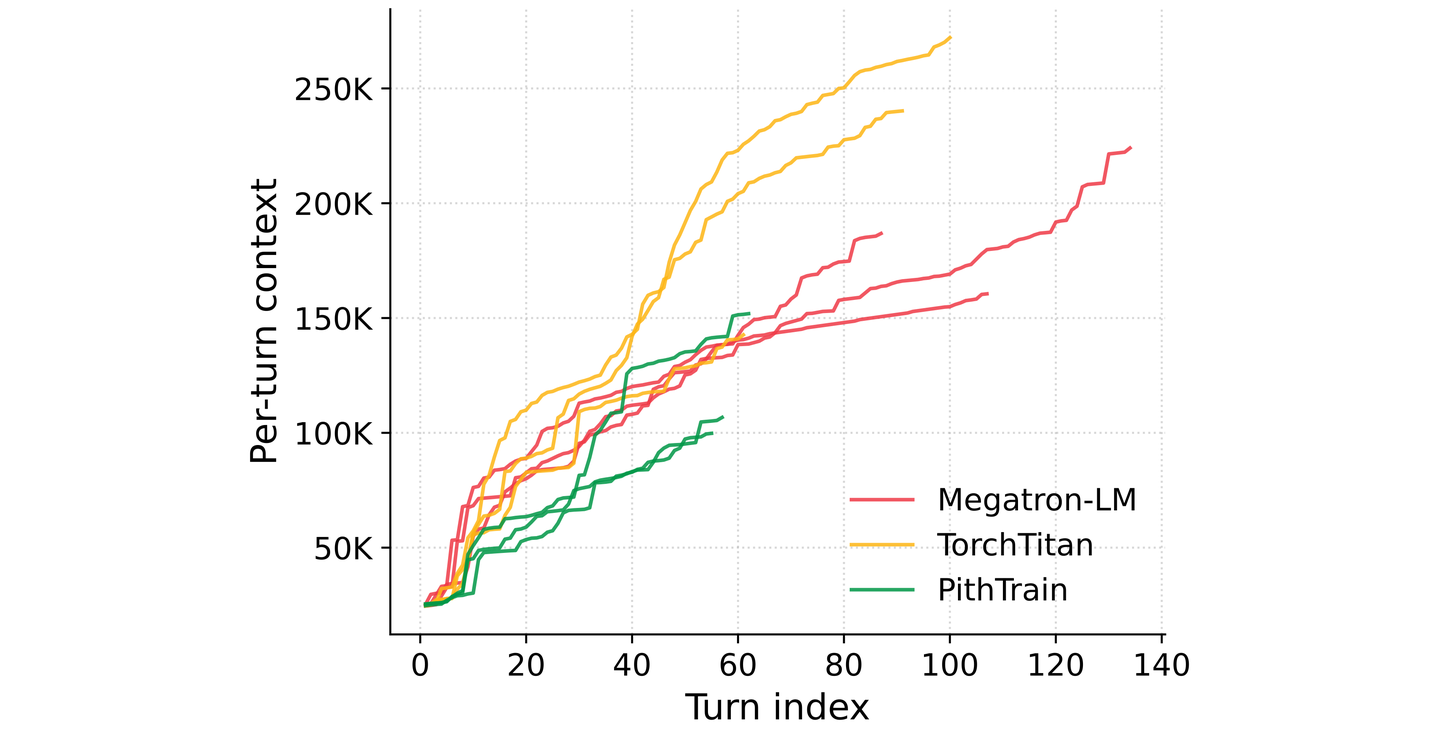
这三档任务最终都指向同一个结论:同样一个 agent,在 PithTrain 上通常用更低的成本把事情完成(更少的轮数、更少的 GPU 时间、更少的输出 token)。具体的细节都在论文里,包括每个任务的完整数字,外加一组 skills 开/关的对照实验(在 skill 对口的那些任务上,有 skill 的时候轮数能砍掉约 70%)。
上手玩一玩?
生产级框架经过多年打磨所具备的极致性能与完备能力,时至今日依然有无可替代的价值,这不容置疑。但随着越来越多系统开发的工作被 agent 接手,agent-task efficiency 这一第二维度的重要性也在不断浮上水面:
一个 agent 究竟要花多低的成本,才能读懂一个系统、跑起来、再改下去?实际上这两个维度并不矛盾:PithTrain 通过 1.1 万行 Python、四条设计原则,既追平了生产级的训练吞吐,又把 agent 与它打交道的成本压了下来。
此外,正因为有精简的代码,除了方便 agent 之外,PithTrain 也很适合给对 MoE 模型训练框架感兴趣的朋友用来弄懂 MoE 训练到底是怎么一回事,或者拿来快速验证一个想法。
最后我还想感谢所有超级给力合作者们!
最后也想特别感谢这一路一起折腾 PithTrain 的所有合作者:Hao Kang @haok1402、Haozhan Tang、Akaash Parthasarathy、Zichun Yu、@邵俊儒,以及老师 Todd Mowry、@熊辰炎、@陈天奇 的指导。这篇文章里提到的很多想法、设计、框架实现和实验结果,都是大家一起反复讨论、不断打磨出来的成果。
我们已经开源了代码,今后一段时间也会持续和开源社区一起开发 PithTrain。我们非常欢迎大家的反馈、讨论、issue 和贡献。对我个人而言,如果大家读完这篇文章能够想到“原来衡量一个系统还有这么个角度”,那这篇文章或许就已经发挥了它最大的价值。
附上快速尝试的代码:
git clone https://github.com/mlc-ai/pith-train && cd pith-train && uv sync
bash examples/build_tokenized_corpus/launch.sh dclm-qwen3
bash examples/pretrain_language_model/launch.sh qwen3-30b-a3b