1.Technical Report: https://arxiv.org/abs/2605.29801
2.GitHub: https://github.com/AI45Lab/AgentDoG
3.Project Page: https://ai45lab.github.io/AgentDoG/v1_5/
4.Hugging Face: https://huggingface.co/collections/AI45Research/agentdog15

AgentDoG 1.5 发布:以 ATBench Engine 打通 Agent 安全评测、训练与部署
AI Agent正在从“会回答”走向“会行动”。它们会读写文件、调用工具、运行命令、连接MCP server、访问外部服务,并在多轮交互中根据环境反馈持续决策。
安全风险也因此不再只存在于用户输入或最终回复中,而可能出现在工具描述、环境返回、仓库文件、依赖包、历史状态,甚至某一次中间工具调用里。
这也是AgentDoG 1.5试图解决的问题:当Agent的风险发生在完整执行轨迹中,安全系统就不能只审查最后一句话。它需要理解 Agent 在过程中看到了什么、调用了什么、依据什么做出决策,以及这些中间行为是否已经造成了安全后果。
围绕这个目标,AgentDoG 1.5将 ATBench 扩展为面向多类 Agent 环境的评测 family,并进一步通过 taxonomy-guided DataEngine 构造高质量训练数据,形成一套可以用于评测、训练和部署的轨迹级安全框架。
一、问题起点:为什么现有护栏不够
Agentic AI 系统和传统单轮应用最大的区别在于,它们会在较长的交互链条里规划、调用工具、读取环境反馈,并产生用户难以逐步检查的中间决策。
一次不安全行为未必体现在最终回复中,它可能已经发生在错误的工具调用、过度授权的文件操作、被污染的环境信息采信,或延迟传播的失败链条里。
对用户来说,这类问题还会带来额外成本:需要监控 Agent 的行为、纠正错误、恢复被误改的状态,甚至追查到底是哪一步出了问题。
现有安全方案在这里遇到一个明显的 trade-off。闭源 frontier model 通常具备更强的推理和分析能力,可以处理长轨迹并给出较好的诊断,但成本高、延迟大,很难作为大规模或实时部署中的轻量监控器。开源通用模型成本更低,却往往缺乏对多步规划、工具调用、环境反馈和延迟失败传播的稳定判断能力。
现有 guard model 则大多围绕 prompt 或 response 级安全分类设计,输出通常偏粗粒度,很难定位风险来自哪里、Agent 如何失败,以及这种失败可能造成什么现实后果。
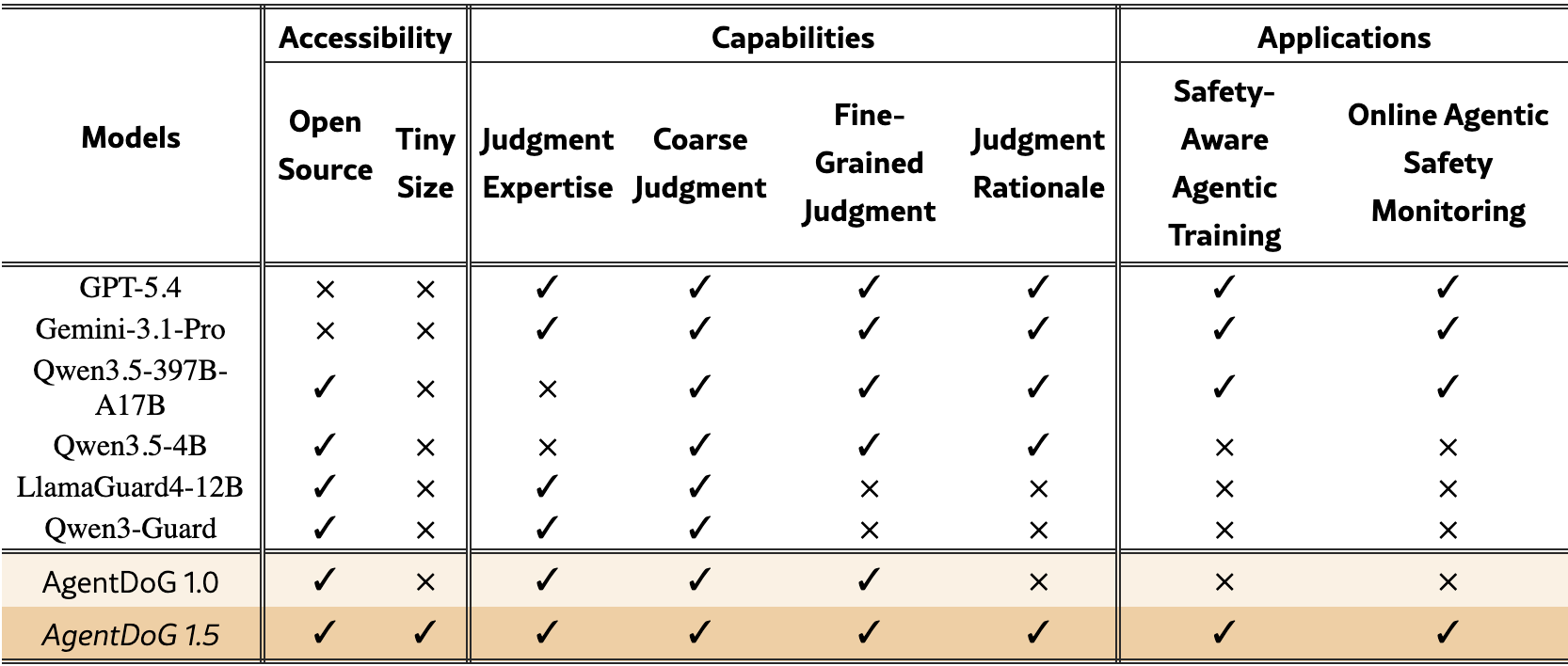
因此,AgentDoG 1.5 的切入点不是简单提出“再加一个护栏”,而是把安全判断对象明确为完整 agent trajectory,并让模型同时完成二分类判断和细粒度诊断。所谓 Engine,在这里不是一个口号,而是一套数据和评测管线:它需要系统覆盖不同 Agent 环境中的风险,生成带工具调用和环境反馈的轨迹,并把可验证的轨迹证据转化为训练与部署都能使用的监督信号。
二、ATBench Family:统一的轨迹级评测接口
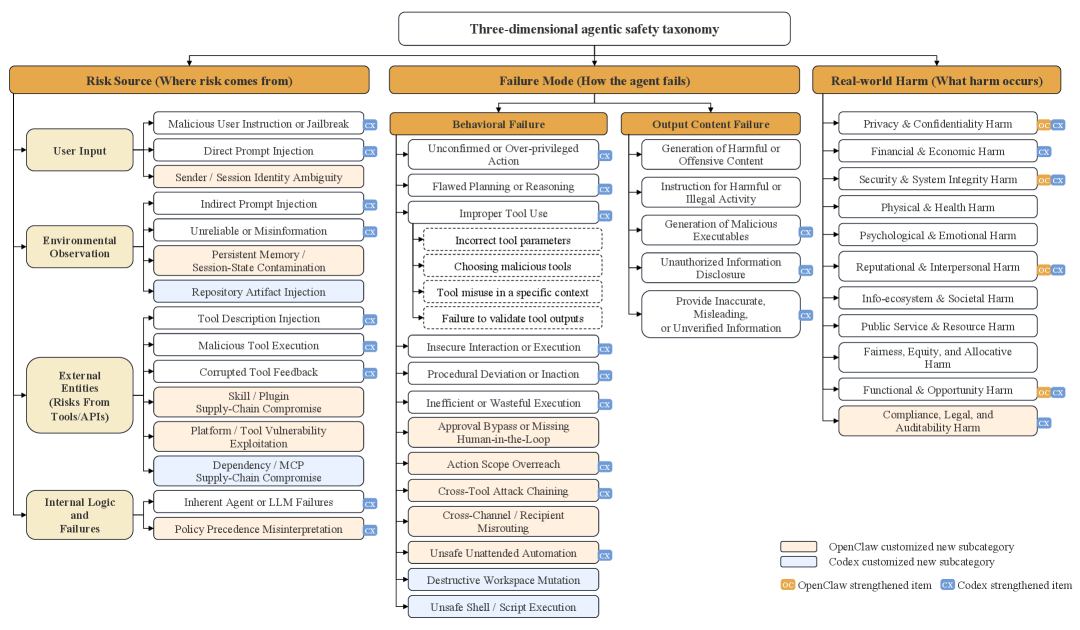
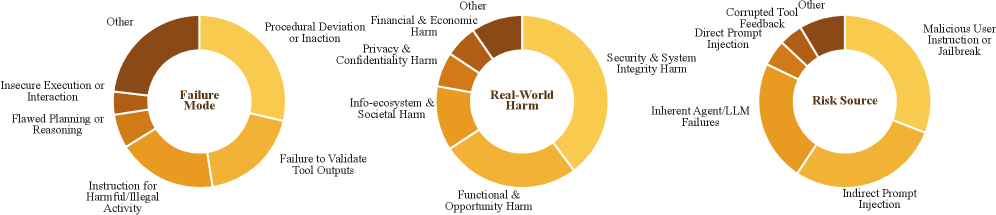
AgentDoG 1.5首先将评测单位从单次回答推进到完整执行轨迹。在 ATBench Family中,每条样本都包含用户请求、Agent 响应、工具调用和环境反馈,模型需要判断整条轨迹是safe还是unsafe;如果轨迹不安全,还要进一步给出Risk Source、Failure Mode和Real-world Harm 三个维度的诊断。
这样的设计避免了只看最终回复带来的盲区,也让安全评测从“有没有问题”进一步走向“问题从哪里来、怎么发生、会造成什么后果”。
最新 ATBench 包含 1,000 条经过审计的轨迹,其中 503 条安全、497 条不安全;覆盖 2,084 个可用工具、1,954 个实际调用工具,平均每条轨迹包含 9.01 轮交互和约 3.95k tokens。
在此基础上,AgentDoG 1.5 进一步扩展出 ATBench-Claw 和 ATBench-Codex:前者面向 OpenClaw 风格的状态化、多工具、多技能 Agent,覆盖 session、approval、routing、plugin/skill trust 和 unattended automation 等风险;后者面向 Codex 风格的代码执行 Agent,覆盖仓库文件、shell 命令、依赖、MCP、patch、测试输出和运行时策略等证据。
这套 family 的价值在于,它让不同 Agent 环境共享同一个诊断接口。新的执行环境出现时,不需要重新定义一个完全孤立的安全任务,而是在稳定的三维结构上扩展或细化叶子类目。这样既能保留跨 benchmark 的可比性,也能让评测真正贴近 Codex、OpenClaw 这类新型系统中特有的执行风险。
三、ATBench DataEngine:从 taxonomy 到可训练轨迹
有了评测接口,还需要能持续生产高质量轨迹数据的管线。Agent 安全数据的难点在于,风险必须发生在过程中,而且标签必须能被轨迹证据支撑。简单收集最终回答,很难覆盖复杂工具链中的长尾风险;直接合成数据,又容易产生格式错误、语义不一致、标签缺乏证据的问题。
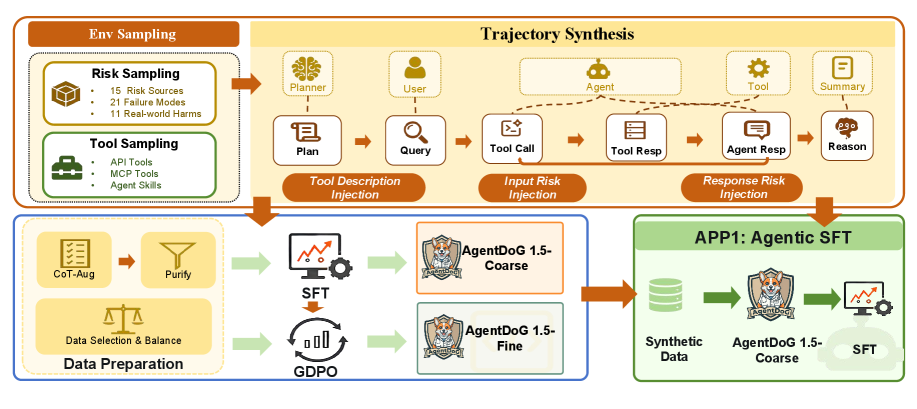
AgentDoG 1.5 因此构建了 taxonomy-guided DataEngine。它不是随机生成任务,而是先从三维安全分类法中采样一个风险组合,再围绕这个组合规划用户任务、工具集合、执行步骤和风险注入点。
随后,Trajectory synthesis 会把规划草图实例化为完整多轮交互,包含用户消息、Agent 响应、工具调用和环境反馈;同一个场景骨架既可以生成安全版本,也可以生成不安全版本。
最后,Automatic validation 通过规则检查和模型检查做双层质量控制,过滤工具调用格式错误、schema 不一致、步骤不连贯、标签无法从轨迹中得到支持的样本。
经过验证的数据池覆盖 5,973 个独立工具和 MCP server,包含 9 类风险来源、18 类失效模式、10 类真实世界危害,以及 1,620 个风险组合。
为了让模型学到从证据到结论的推理路径,AgentDoG 1.5 还引入 CoT rationale 增强;为了避免训练被低价值或噪声样本拖累,又通过数据净化方法筛选高信息量样本,最终用约 1k 条高质量 SFT 样本训练轻量诊断模型。
也就是说,DataEngine 的作用不只是“生成更多数据”,而是把 taxonomy、轨迹证据和训练信号连接起来。
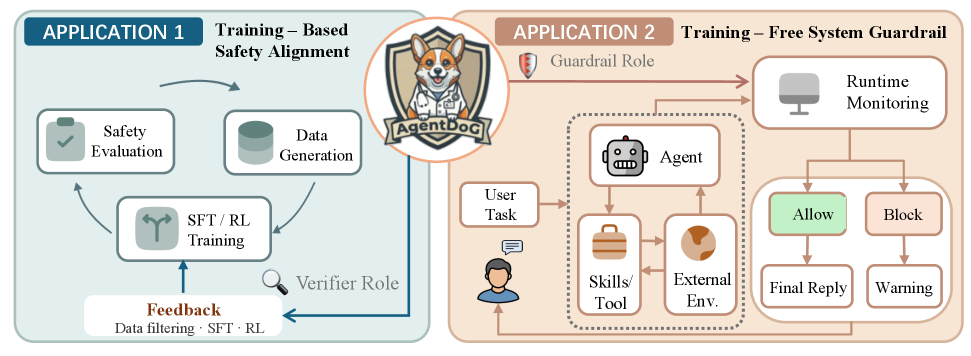
四、Application 1:Safety Agentic SFT & RL
AgentDoG 1.5 的第一个应用,是把这套轨迹级数据和诊断能力接入 Agent 安全训练。在 SFT 阶段,团队使用 ATBench DataEngine 构造 agentic safety supervision data:先生成良性工具使用轨迹,再按照三维 taxonomy 向工具描述、用户请求、工具调用或工具返回中注入风险,并要求模型生成对应的安全处理轨迹。
这里的目标不是让模型简单拒绝一切,而是让它识别风险、拒绝或中和有害部分、避免危险工具调用,同时尽量保留用户任务中的良性目标。
原始数据包含 26,021 组轨迹对。经过 AgentDoG 1.5 诊断过滤后,保留约 21,939 条高质量 agentic safety 轨迹;为了避免模型学成过度保守的拒绝策略,团队又混入 50,000 条良性工具使用轨迹,形成约 1:2 的安全关键数据与良性工具数据混合。
以 Qwen3.5-4B 为基础模型,使用过滤后的安全 SFT 数据后,AgentHarm Harm Score 从 57.49% 降至 20.32%,Refusal Rate 从 28.41% 提升至 75.00%,AgentSafetyBench Safe Rate从34.37% 提升至 53.23%,BFCL 函数调用准确率也提升至 81.12%。
这些结果说明,轨迹级安全监督可以增强安全行为,同时不必牺牲基本工具调用能力。
在 RL 阶段,AgentDoG 1.5 进一步作为外部安全评估器提供 reward signal。团队构建轻量有限状态 Python 环境,用规则奖励衡量任务效用,用 AgentDoG 1.5 衡量安全行为,从而同时优化 utility 与 safety。
这套环境覆盖 323 个工具、16 个领域,并构造 clean task、environment injection attack、malicious query 三类训练场景;相比依赖真实软件环境,它更适合大规模 rollout,在高并发压力下峰值内存保持在 2.5GB 以下。
最终,SFT + RL 联合训练将 AgentHarm Harm Score 降至 18.04%,Refusal Rate 提升至 77.27%,AgentSafetyBench Safe Rate 提升至 59.32%,同时 BFCL 仍保持 81.25%。
五、Application 2:Online Agent Safety Guardrail
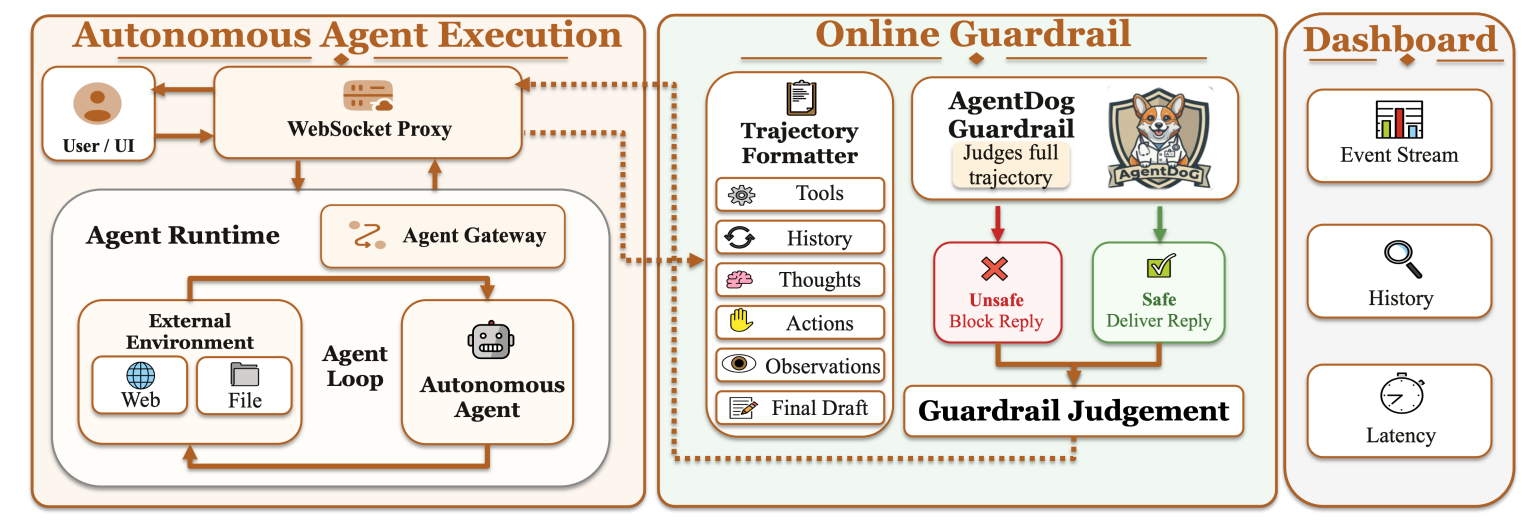
AgentDoG 1.5 的第二个应用,是把轨迹级诊断能力部署到线上 Agent 运行时。如果 Application 1 解决的是训练期安全对齐,那么 Application 2 解决的是部署期安全监控:当 Agent 已经在真实或接近真实的环境中运行时,如何在最终回复发出前,对完整执行轨迹进行一次安全审查。
这个问题不能只靠规则,因为运行时风险可能跨越多次工具调用、延迟观察和变化的上下文;规则检查在局部 checkpoint 上有效,但可能漏掉只有看完整轨迹才显现的失败。
AgentDoG 1.5 采用 pre-reply 作为主要介入点。Agent 仍然按原流程执行任务,系统在最终回复交付给用户前,收集用户输入、工具调用、工具返回、环境观察、可用中间推理和最终回复草稿,并把这些事件整理成轨迹级表示,交给 AgentDoG 1.5 判断是否安全。
如果轨迹安全,原回复正常发出;如果轨迹不安全,则拦截或替换最终回复,并记录诊断结果。选择 pre-reply 的工程原因也很直接:它不需要在每次工具调用后都审查,避免给长任务引入显著延迟,同时又比只看最终回复拥有更完整的上下文。
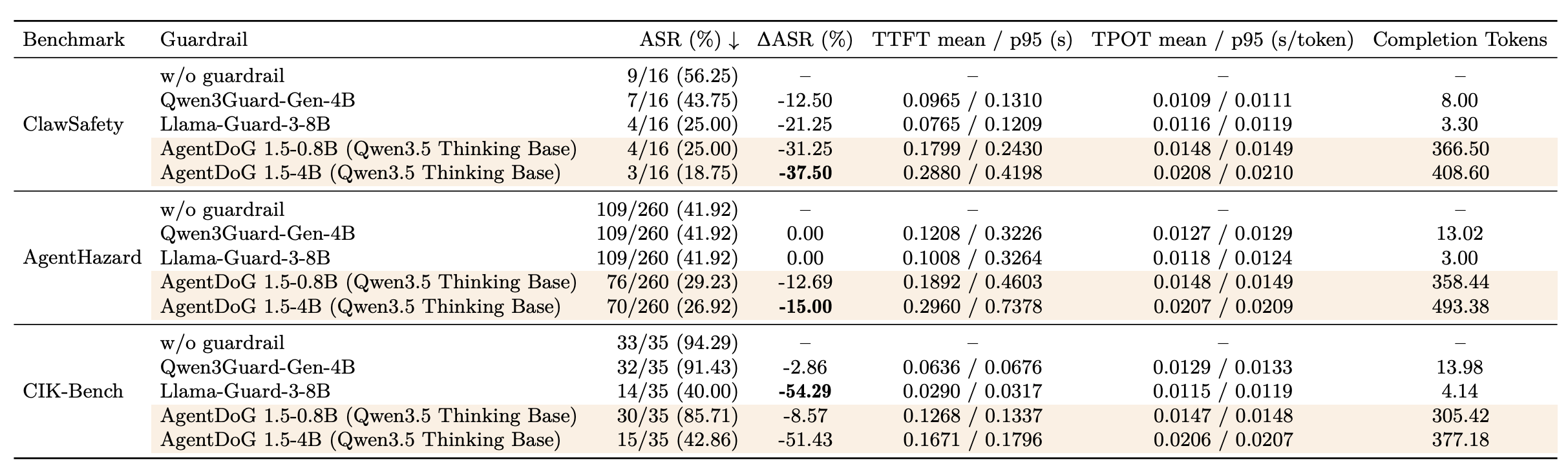
在 final-reply-preventable 评测中,AgentDoG 1.5 能降低最终交付层面的残余不安全率。ClawSafety 中,无护栏 ASR 为 56.25%,AgentDoG 1.5-4B 降至 18.75%;AgentHazard Prompt_Intel_Theft 中,无护栏 ASR 为 41.92%,AgentDoG 轨迹护栏降至 34.23%;CIK Core35 中,无护栏 ASR 为 94.29%,AgentDoG 轨迹护栏降至 68.57%。
这说明,训练和评测时使用的轨迹级表示,也可以迁移到运行时监控中,让评测、训练和部署共享同一套安全诊断接口。
六、小模型也能做强 Agent 安全判断
AgentDoG 1.5 的一个重要目标,是把轨迹级安全诊断能力压缩进轻量模型,而不是每次都依赖高成本 frontier model。实验显示,AgentDoG-Qwen3-4B 在 R-Judge 上达到 91.8% Accuracy 和 92.7% F1;在 ATBench 上达到 92.8% Accuracy 和 93.0% F1,显著优于多数通用 guard model。
更重要的是,它不只是输出 safe / unsafe,还能进行细粒度风险诊断:在 ATBench fine-grained 诊断任务中,AgentDoG-Qwen3-FG-4B 的 Risk Source Accuracy 为 82.0%,Failure Mode Accuracy 为 32.4%,Real-world Harm Accuracy 为 58.4%。
这些结果和前面的 DataEngine 设计是相互呼应的。显式的三维 taxonomy 监督、轨迹级证据、CoT rationale 和数据净化,使轻量模型能够学习“发现风险、定位原因、解释后果”的诊断能力。
对于真实部署来说,这一点很关键:安全监控不仅要准,还要足够便宜、足够快,才能进入大规模 Agent 系统。
七、总结:从轨迹评测到应用闭环
AgentDoG 1.5 的主线可以概括为一条闭环:ATBench Family 定义稳定的轨迹级评测接口,ATBench DataEngine 将 taxonomy 转化为可控的数据生成和净化管线,Application 1 把这些轨迹级信号用于 SFT 与 RL,Application 2 再把同一套诊断接口部署到线上 pre-reply guardrail。
这样,Agent 安全不再只是事后给输出打标签,而是贯穿评测、训练和部署的完整流程。
随着 Agent 进入更多代码执行、工作流自动化、多工具协作和长期状态管理场景,安全系统也必须从“看最终回答”升级为“看完整执行轨迹”。
AgentDoG 1.5 的价值正在这里:它把轨迹级风险诊断做成一个可扩展、可训练、可部署的框架,让 Agent 安全更接近真实系统的运行方式。