作者:还可以在找实习
https://zhuanlan.zhihu.com/p/2038002855374753895
欢迎关注我们关于异步 Agentic RL 的最新工作。本文聚焦一个在大规模 LLM 强化学习系统中非常基础、但经常被忽略的问题:当 rollout 和 training 异步解耦之后,PPO 类 off-policy correction 真正需要的 old logits,很多时候已经丢了。
论文:Missing Old Logits in Asynchronous Agentic RL: Semantic Mismatch and Repair Methods for Off-Policy Correction
链接:https://arxiv.org/abs/2605.12070
代码:https://github.com/millioniron/async_fixedic
这看起来像是工程细节,但它会直接影响 PPO 目标里两个本应彼此独立的校正过程:training-inference discrepancy correction 和 policy staleness correction。一旦 old logits 丢失,这两个过程就会被混在一起,导致本来语义清晰的 decoupled correction 失效。
围绕这个问题,我们系统分析了现有异步 Agentic RL 中的几类 off-policy correction 范式,讨论了三种精确恢复 old logits 的路径,并给出一种更低成本、更适合大规模训练的近似方案:PPO-EWMA。
我们的实验表明:在 Dense 和 MoE 两类 LLM 上,经过修正的 PPO-EWMA 在性能和系统开销之间取得了更好的平衡;而理想化的 Snapshot 方案则帮助我们验证了一个关键判断:问题的核心不是“要不要做 correction”,而是“你用来 correction 的 reference policy 到底是不是语义正确的”。
TLDR
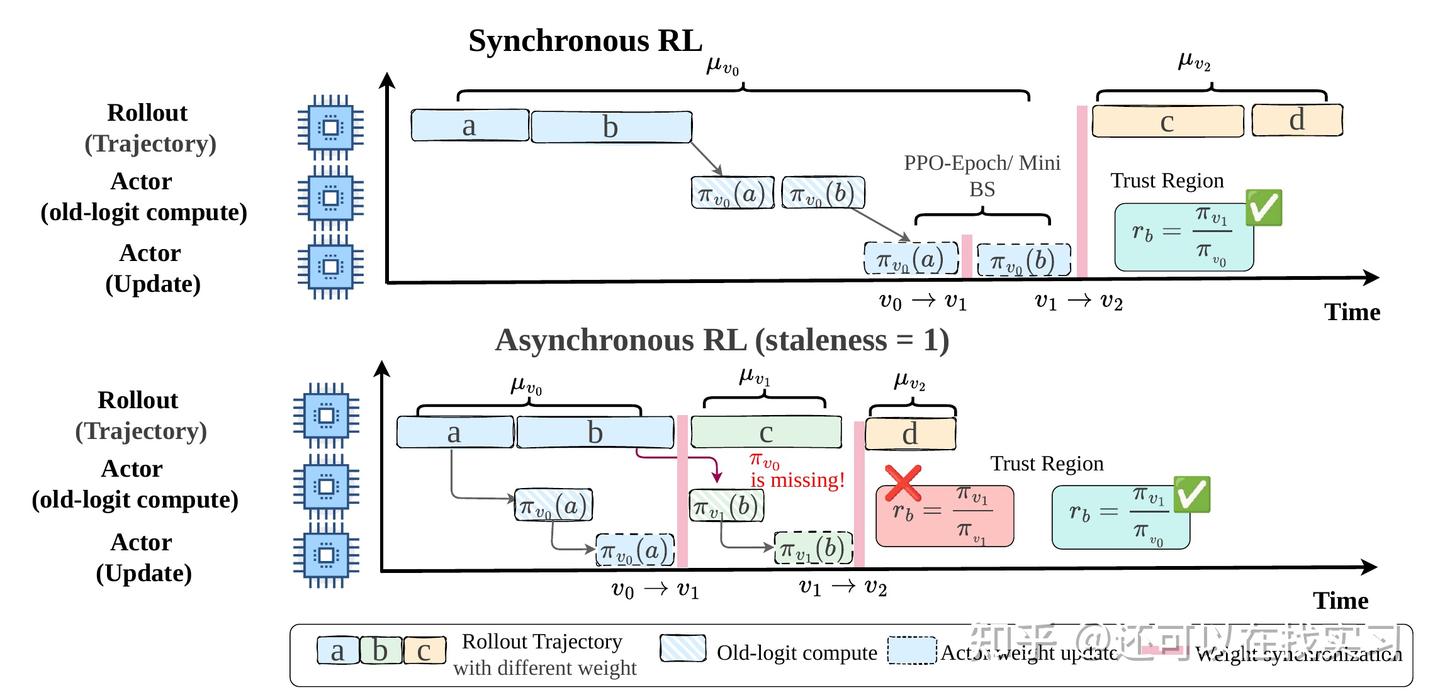
现代 Agentic RL 训练系统中,rollout 往往由 vLLM、SGLang 等推理引擎负责,训练则由 Megatron-LM、FSDP 等训练引擎负责。与此同时,为了提升吞吐,训练流程常常采用异步 rollout、延迟更新、partial rollout 等机制。
这会带来两个彼此不同的问题:
1、Training-Inferenc Discrepancy:即便 rollout 侧和 training 侧名义上使用的是同一个模型版本,二者的 token 概率仍可能因为 kernel、精度、量化、并行策略、MoE routing 等差异而不一致。
2、Policy Staleness:当数据真正送到 actor 更新时,生成这些样本的行为策略往往已经落后于当前训练策略。
理论上,这两个问题应该分别处理。理想情况下,总 importance ratio 应该分解为两个部分:一个用于修复 training-inference discrepancy,另一个用于约束 policy staleness。
但在真实异步系统中,这个分解依赖一个关键前提:你必须拿得到生成这些 token 时对应的 training-side old logits。
而我们的核心发现是:在异步 Agentic RL 中,这个前提往往不成立。old logits 的缺失会让 discrepancy repair 和 staleness correction 混杂在一起,破坏 decoupled correction 的原始语义。
为了解决这个问题,我们做了两件事:从系统角度分析三种精确恢复 old logits 的路径;从算法角度提出一个更适合异步窗口的 revised PPO-EWMA 近似参考策略。
在 Qwen3-4B 和 Qwen3-30B-A3B 上,我们发现 PPO-EWMA 能稳定优于常规 Decoupled PPO 和 Linear_prox,并在不少任务上逼近理想化的 Snapshot 上界。
研究动机:为什么异步 RL 里的 old logits 会成为核心问题?
PPO 类方法之所以稳定,一个重要原因是:它的 importance ratio 和 clipping 机制,默认你知道“这些样本到底是由哪个旧策略生成的”。
在同步或者近同步训练里,这件事通常不难成立。但在今天的大规模 Agentic RL 系统里,训练范式已经变了:
- rollout 和 training 被物理解耦
- rollout 队列可能跨越多个版本
- 一条轨迹可能是 partial rollout,甚至横跨多个参数版本
- actor 更新时,早先版本的 training-side logits 可能已经不可恢复
于是一个原本很自然的分解会失去语义前提:
- r_d:修复 training-inference discrepancy
- r_s:修复 policy staleness
表面上你还在做 decoupled correction,但实际上,你使用的 reference policy 已经不是“真正的 old policy”了。这就带来一个关键问题:
如果 reference policy 本身已经错位,那么基于它做出来的 discrepancy mask 和 PPO clipping,究竟还在约束什么?
统一视角:Off-Policy Correction 里其实有两类不同约束
本文的一个核心观点是,现有 PPO-style off-policy correction 可以放到一个统一视角下理解:它们都在试图约束两个东西,但这两个东西的语义不同。
第一类是 Discrepancy constraint。它关注 rollout 侧分布和 training 侧分布到底差了多少,用来过滤由于训练/推理不一致而导致的“数值上不可信”的 token。直觉上,这种约束应该围绕 1 对称,因为它和 advantage 正负无关。
第二类是 Staleness constraint。它关注当前策略和历史行为策略之间的距离,用来实现 PPO 意义下的 trust-region 约束,因此会天然带有对 advantage 符号敏感的 clipping 结构。
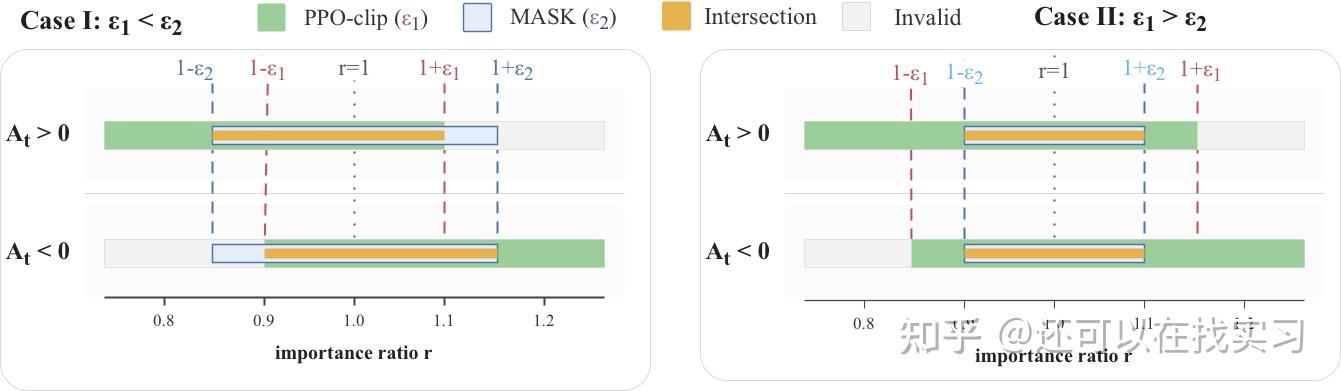
也就是说,这两类约束虽然都写在 ratio 上,但本质上不是一回事:一个是在修“训练/推理错位”,另一个是在控“策略更新幅度”。它们不应该被混成同一个 proxy ratio 去解释。
一个关键结论:Discrepancy Repair 不能替代 Staleness Correction
有些做法会倾向于认为,只要把 training-inference mismatch 控好,很多 off-policy 问题就能顺手缓解。但我们的分析表明,这个想法并不成立。
原因在于:discrepancy mask 通常是对称的,而 PPO clipping 通常是与 advantage 符号相关的非对称约束。即使二者数值上看起来都像“过滤异常 ratio”,它们也不是同一种约束,不能互相替代。
更糟的是,一旦 old logits 缺失,你就会被迫使用某个 proxy policy,同时把这两个不同目标都压到这个 proxy 上。最后得到的不是一个更干净的 correction,而是两个机制相互干扰:mask 会改变 clip 的有效工作区间,clip 也会影响被保留下来的 token 分布。
所以从这个角度看,异步 Agentic RL 真正的问题不是“off-policy correction 不够强”,而是:
你在做 correction 时,使用的 reference policy 语义已经不干净了。
如何精确恢复 old logits?三条系统路径
如果问题的根源在于 old logits 丢了,那么一个自然思路就是把它找回来。我们在文中讨论了三种可行路径。
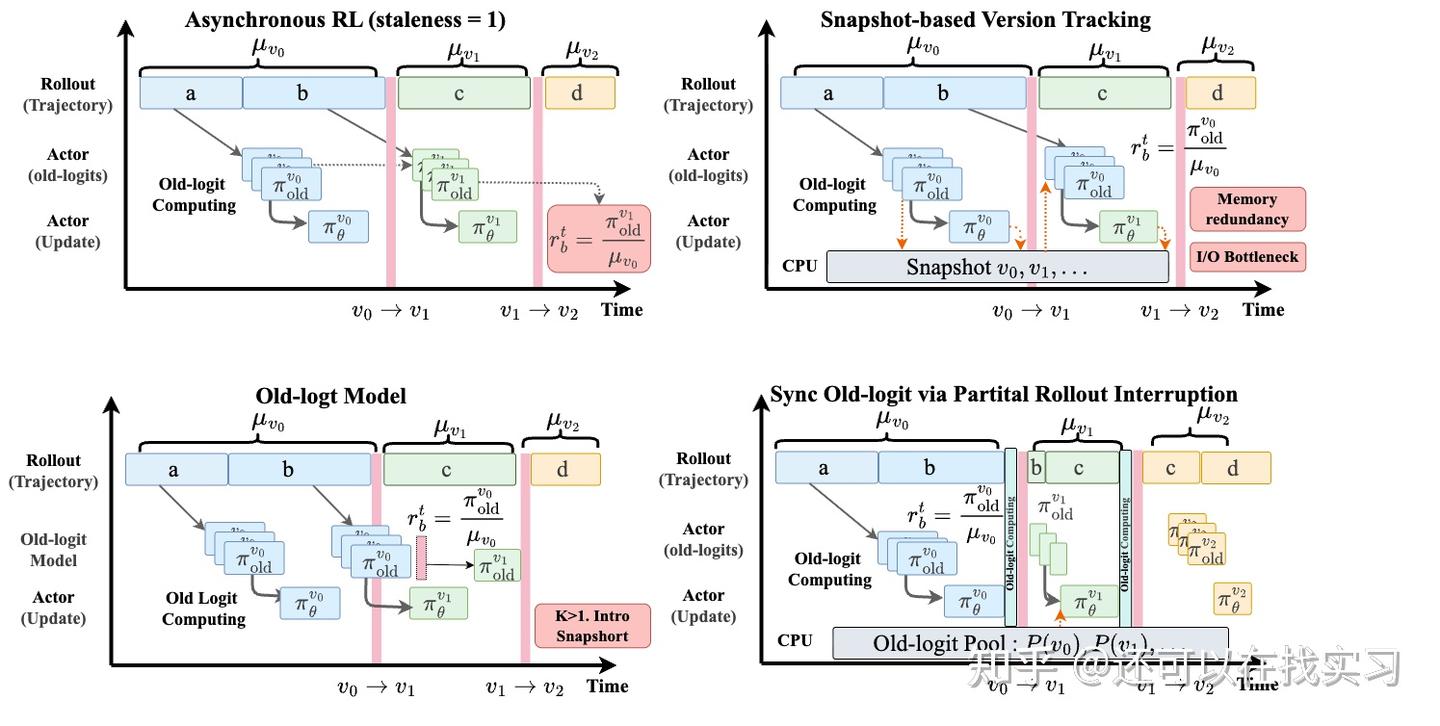
Snapshot-based version tracking 是最直接的方法:保存历史参数快照,并在训练时重新加载对应版本,显式恢复生成轨迹时的 training-side old logits。
这个方案语义最干净,也最接近理想状态。但它需要额外 CPU/host 内存,带来频繁版本切换;在 partial rollout 场景下,一条样本可能跨多个版本,进一步放大 I/O 和调度开销。
Dedicated old-logit model 是第二条路:单独维护一个用于计算 old logits 的模型,让主 actor 继续训练,同时把 old-logit computation 独立出来。它可以和训练阶段做一定 overlap,减少对主训练路径的阻塞,但需要额外模型资源和更复杂的资源分配。
Synchronization via partial rollout interruption 是第三条路:在某个版本真正消失之前,临时中断 rollout,回收 partial trajectory,用当前仍驻留的旧版本补算精确 logits。这个方案避免长期保存历史权重,但会引入同步 stall,破坏 rollout 并行性,并带来资源切换和调度扰动。
这三种方案都能更精确地解决问题,但它们指向同一个事实:精确 old-logit recovery 是可行的,但系统成本并不低。
低成本近似:为什么我们选择 Revised PPO-EWMA?
既然精确恢复太贵,一个更现实的问题就是:能不能找到一个近似 reference policy,它虽然不等于真实 old policy,但至少比现有 proxy 更合理?
我们的答案是使用 PPO-EWMA。
这里的核心想法并不是“假装恢复了 old logits”,而是构造一个更平滑、同时更接近异步版本窗口中心的参考策略 pi_prox,并用它同时承担 staleness correction 和 discrepancy repair 的参考。
相比简单的 Linear_prox,我们更强调两点。
第一,根据 staleness window 选择 EWMA 衰减系数。我们不是固定使用一个很大的经验衰减,而是让 beta_prox 和系统里的实际异步窗口长度对齐,使这个 proxy policy 更接近 rollout 数据所处版本区间的“中间位置”。
第二,加入自动 reset 机制。EWMA 虽然平滑,但也可能越积越旧。历史版本积累过多之后,pi_prox / mu_old 会越来越偏,导致 Train-Infer Mask 大量掉点,最后把训练搞崩。
因此我们持续监控 Train-Infer Mask 保留下来的 token 比例;当这个比例低于阈值时,直接把 EWMA reference reset 到当前 actor。
这个设计的本质是:平时让 EWMA 提供更平滑的参考,一旦 reference 漂得太远,就及时重心归位。这让 PPO-EWMA 既保留了低成本优势,又避免 proxy reference 长期失真。
实验设置:我们如何验证这个问题?
我们在两类代表性 backbone 上进行了实验:
- dense 模型:Qwen3-4B
- MoE 模型:Qwen3-30B-A3B
评测任务覆盖多个 Agentic benchmark,包括 tau^2-Bench 的 retail / airline / telecom,以及 VitaBench 的 in-store / delivery。
同时,我们显式控制异步训练中的最大版本间隔,使实验能更集中地观察 old-logit missing 会带来什么问题,以及 exact recovery 和 approximate reference 的差别到底有多大。
我们比较的主要方法包括 Decoupled PPO、Linear_prox、PPO-EWMA 和理想化精确 old-logit 恢复方案 Snapshot。
主要结果:PPO-EWMA 在性能和成本之间更平衡
整体实验结果非常清楚。
在 Qwen3-4B 上,PPO-EWMA 在多个指标上稳定优于 Decoupled PPO 和 Linear_prox:retail 上取得最好的 pass@4,VitaBench in-store 上取得最好的 pass@2,telecom 上达到并列最优。
在 Qwen3-30B-A3B 上,PPO-EWMA 依然保持优势:airline split 上表现最强,retail pass@4 上达到最优,telecom avg@2 和 pass@2 上也达到 practical methods 中的最优。
更重要的是,它在多个任务上已经开始逼近理想化 Snapshot 的效果。这说明:
即便拿不到真实 old logits,只要 reference policy 构造得更合理,依然可以恢复很大一部分 decoupled correction 的收益。
下表汇总了 dense Qwen3-4B 和 MoE Qwen3-30B-A3B 上的主要结果。Snapshot* 表示理想化的精确 old-logit recovery;加粗项表示同一 backbone 下 practical methods 中的最优结果。
| Backbone | Method | Retail avg/pass | Airline avg/pass | Telecom avg/pass | In-store avg/pass | Delivery avg/pass |
|---|---|---|---|---|---|---|
| Qwen3-4B | Decoupled PPO | 63.96 / 88.60 | 53.5 / 72 | 40 / 50 | 19.83 / 37 | 19.56 / 33 |
| Qwen3-4B | Linear_prox | 64.40 / 86.84 | 54 / 72 | 37.5 / 50 | 22.37 / 40 | 19.10 / 28 |
| Qwen3-4B | PPO-EWMA | 65.72 / 90.35 | 54 / 74 | 42.5 / 52.5 | 25 / 50 | 25.88 / 39 |
| Qwen3-4B | Snapshot* | 66.23 / 89.47 | 56 / 76 | 42.5 / 52.5 | 28.89 / 47 | 27.33 / 42 |
| Qwen3-30B-A3B | Decoupled PPO | 65.43 / 89.47 | 57 / 76 | 44.75 / 55 | 18.28 / 32 | 25.88 / 39 |
| Qwen3-30B-A3B | Linear_prox | 65.8 / 87.7 | 53.5 / 74 | 44 / 55 | 31.47 / 47 | 20.74 / 33 |
| Qwen3-30B-A3B | PPO-EWMA | 67.82 / 92.1 | 60 / 82 | 45 / 57.5 | 33.41 / 48 | 28.49 / 43 |
| Qwen3-30B-A3B | Snapshot* | 69.70 / 92.1 | 59 / 80 | 45 / 57.5 | 34.62 / 50 | 30.74 / 45 |
一个很有意思的结果:精确 old logits 确实更好,但真的更贵
我们还专门测了系统开销,结果也很有代表性。
对于 Snapshot,虽然校正最准确,但系统成本显著增加:4B 模型 CPU 存储约 40 GB,30B MoE 模型 CPU 存储约 76.4 GB,额外时间开销分别约为 25s 和 150s。
相比之下,PPO-EWMA 的资源代价要轻得多:4B 约 7.9 GB,30B 约 15.2 GB,额外时间分别约 8s 和 34s。
也就是说,Snapshot 更像是一个“理想上界”和分析工具,而不是最适合大规模生产部署的默认方案。
下表展示了精确 old-logit recovery 和 PPO-EWMA 的系统成本差异。Snapshot 语义更干净,但存储和恢复时间都显著更高;PPO-EWMA 则提供了更现实的性能-成本权衡。
| Metric | Snapshot 4B | Snapshot 30B | PPO-EWMA 4B | PPO-EWMA 30B |
|---|---|---|---|---|
| Switch latency (s) | 7 | 14.2 | 7 | 14.2 |
| CPU storage (GB) | 40 | 76.4 | 7.9 | 15.2 |
| Extra time (s) | 25 | 150 | 8 | 34 |
Dedicated old-logit model 的资源切分结果如下:
| Resource ratio | Old-logit (s) | Update (s) | Single (s) | Overlap (s) | Change |
|---|---|---|---|---|---|
| 1:2 | 243 | 272 | 305 | 284 | -6.8% |
| 1:3 | 243 | 206 | 237 | 254 | +7.17% |
单独维护 old-logit model 虽然可以部分 overlap 计算,但收益高度依赖资源切分比例,本身也需要更多系统支持,因此未必总是划算。这也是为什么我们最终更强调 PPO-EWMA 的 practical value。
阈值分析:为什么 mask 和 clip 会相互影响?
借助 Snapshot 恢复出来的精确 old logits,我们进一步分析了 discrepancy threshold 和 stale-policy threshold 的相互作用。
实验显示:更宽松的 discrepancy threshold 会保留更多 token,前期学习更快,但它也会放进更多偏差较大的 off-policy token,后期更容易不稳定;更严格的 threshold 前期更慢,但 retained-token dynamics 更平稳。
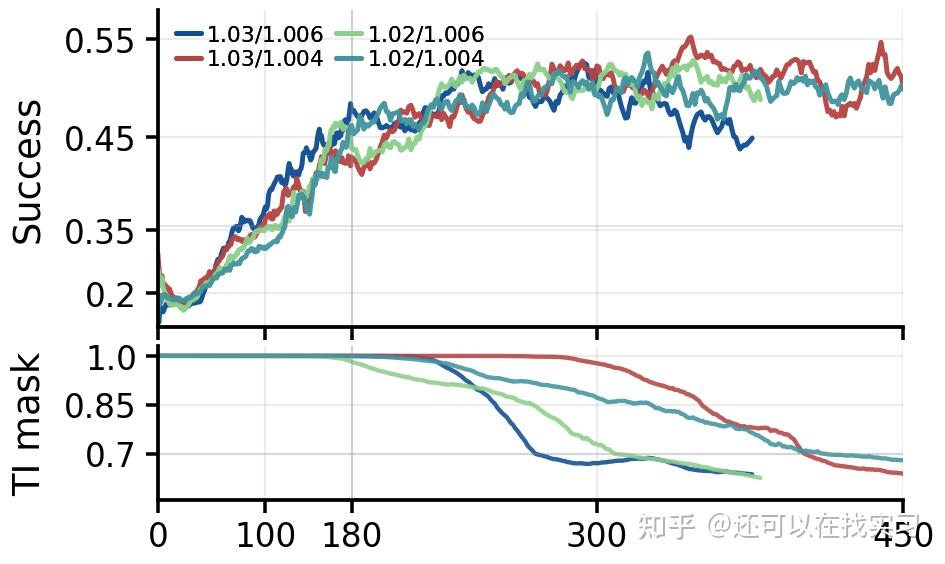
同时,mask 和 clip 并不是彼此独立的两个开关。在相同 discrepancy threshold 下,更宽松的 stale-policy threshold 会让更多问题 token 在早期存活,这反过来会把 Train-Infer Mask 拉低;后期 clip 变强之后,又会对剩余更新形成抑制,使 mask 恢复。
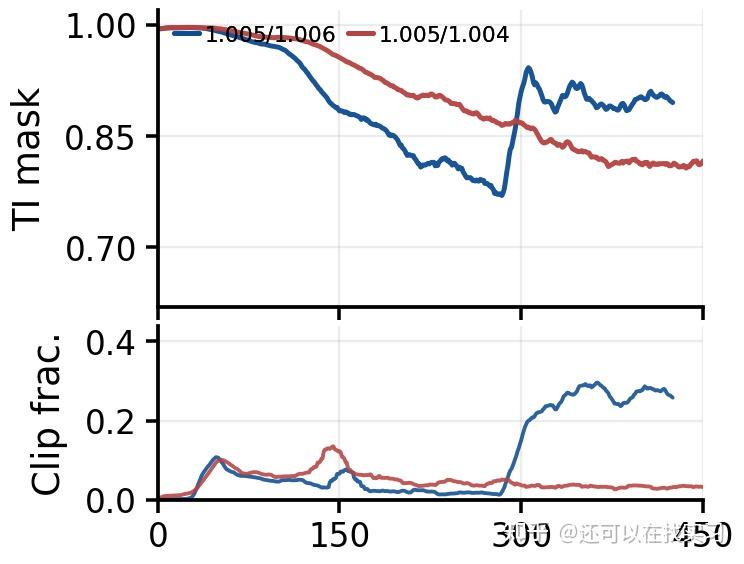
这进一步说明:当 reference policy 不准确时,mask 和 clip 的耦合会更复杂。
PPO-EWMA 消融:为什么自动 reset 很关键?
我们还专门分析了 PPO-EWMA 的训练动态,重点看了三个信号:task success、Train-Infer Mask 和 PPO-CLIP ratio。
结果表明,如果只用 EWMA 而不 reset,proxy reference 可能会逐渐漂移得太远,最终导致 Train-Infer Mask 崩掉。
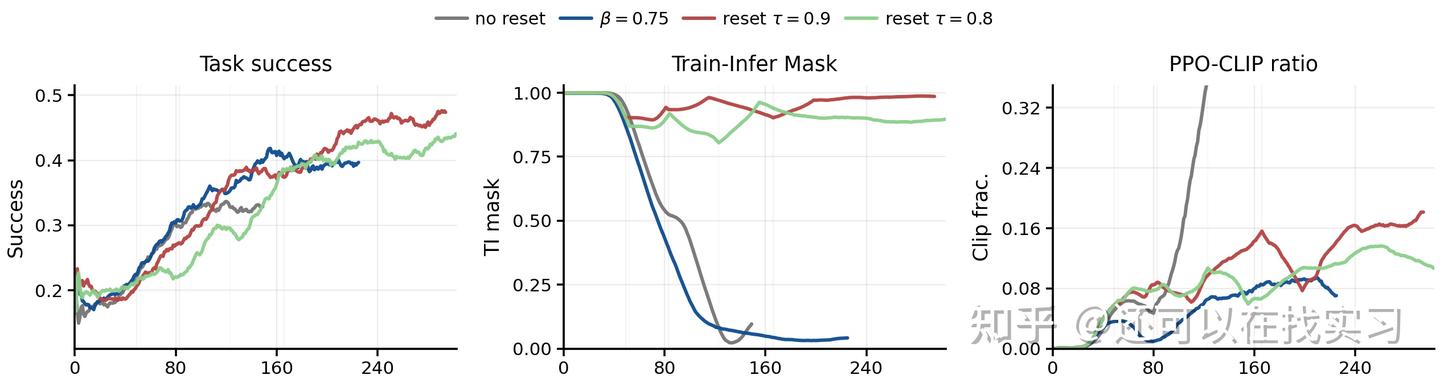
加入自动 reset 之后,只需要少量重置事件,就能把 reference 拉回合理区域,同时保住前期 EWMA 带来的优化收益。
这个结果非常符合我们的直觉:纯当前策略不够稳,纯历史平滑又可能过旧,合理的办法不是二选一,而是“平时做平滑,过旧时重置”。
这篇工作的核心观点
如果只用一句话概括这篇工作:
在异步 Agentic RL 里,真正被忽视的问题不是 off-policy correction 本身,而是你做 correction 时所依赖的 old logits 语义已经失真。
围绕这个问题,我们做了三件事:
1、给出一个统一视角,明确区分 training-inference discrepancy correction 和 policy staleness correction
2、指出异步系统中的 missing-old-logit problem 会破坏这种分解
3、从精确恢复和低成本近似两个方向,给出一套更系统的解决思路
总结与未来展望
本文关注的是异步 Agentic RL 中一个非常底层但关键的问题:old logits 缺失。
我们的分析表明,这个问题会直接破坏 decoupled off-policy correction 的语义基础。基于此,我们一方面讨论了三种精确恢复 old logits 的系统路径,另一方面提出了更适合实际大规模训练的 revised PPO-EWMA 方案。
实验结果说明:精确恢复 old logits 的确能提升 correction fidelity;但从性能-成本权衡来看,PPO-EWMA 是更现实、更易落地的方案。
未来仍有不少方向值得继续推进,包括更极端异步窗口下 reference policy 的构造、更复杂 partial rollout 场景中的 token-level version alignment、MoE routing replay 与 old-logit correction 的联合建模,以及面向真实工业训练栈的更轻量 old-logit infrastructure。
如果你也在关注异步 LLM RL、Agentic RL、MoE RL 或者 Off-Policy Correction,欢迎交流。