作者:朱翼
https://zhuanlan.zhihu.com/p/2056045172111177252
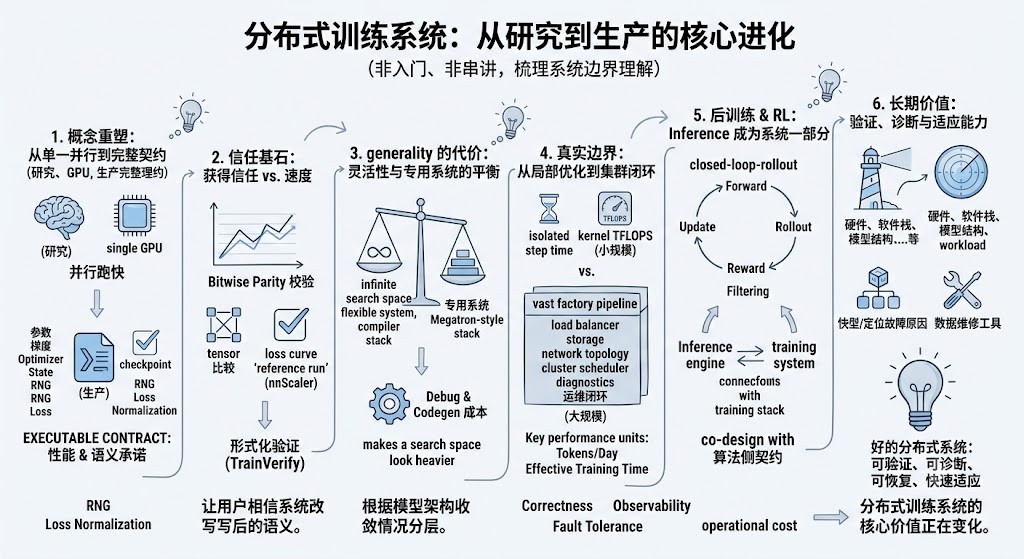
这篇文章来自我最近准备的一个技术分享。原本的主题是 “Distributed Training Systems: From Research to Production”。整理成博客时,我不想把它写成分布式训练入门,也不想做成论文串讲,更想借这个机会梳理一些自己这几年对训练系统边界的理解。
知乎上讲 DP、TP、PP、FSDP、ZeRO、Megatron、DeepSpeed 的文章已经很多了。我这篇更想讨论一些偏判断的问题:一个分布式训练系统从研究原型走向真实训练时,哪些问题会变得更重要?为什么一个看起来很自然的 general system,到了真实的大模型训练生态里会遇到边界?
我的背景大概是:早期参与过 OneFlow,后来主要参与 nnScaler / AutoDist 相关工作,也支持过一些公开模型项目的分布式训练。最近一段时间,我又接触了更多大规模训练、后训练和 RL workflow 相关的系统问题。下面很多判断都来自这些经历本身,也带有很强的个人视角。
1. 分布式训练不是把程序“并行跑快”这么简单
在单卡或单节点训练优化里,我们通常面对的是一个相对固定的训练程序:模型结构、参数、激活、梯度、optimizer state、checkpoint、loss 计算都在比较局部的上下文里。优化时,更多是在这个固定程序上做 kernel、memory、fusion、layout、batching 等局部改造。
分布式训练不太一样。它不是简单地把同一个程序放到更多 GPU 上跑,而是在改变程序状态的存在方式:
- 参数可以复制,也可以切分;
- 梯度可以 all-reduce,也可以 reduce-scatter;
- activation 可以重算、checkpoint、按 sequence/context 维度切;
- optimizer state 可以复制、shard、offload;
- RNG、data order、loss normalization、global norm、-checkpoint/resume 都需要保持训练语义。
所以所谓 parallelization plan,并不只是“用了 DP/TP/PP/EP/CP 哪几个名字”。一个真正可执行的 plan 至少要回答:
- 哪些 tensor 维度被切分?
- 每个时刻哪些 rank 拥有哪些状态?
- 通信在哪里发生?
- 哪些 tensor 被 materialize、recompute 或释放?
- checkpoint、resume、RNG、hook、global norm 是否还能保持同样语义?
我现在更愿意把 parallelization plan 理解成一个 executable contract:它既是性能方案,也是语义承诺。这个承诺一旦没有说清楚,系统后面就会遇到非常多 correctness 和 trust 的问题。
2. 为什么自动并行在 2022 年看起来很自然
我最早接触分布式训练系统时,一个很强的感受是:手动指定每个 operator 怎么切分,虽然表达能力很强,但对用户来说太痛苦了,而且也不一定能得到好的方案。
在 OneFlow 里积累的一些经验,让我觉得自动搜索并行策略是一个很自然的方向。2022 年左右,大模型还没有像 ChatGPT 之后那样成为主流叙事,但模型规模已经开始明显变大,V100/A100 这类 GPU 的显存也很有限,算法研究者也开始有 scale 的需求。换句话说,分布式训练的需求已经出现了,只是当时很多人还没有把它看成今天这么核心的问题。
AutoDist 最初的想法比较直接:给定一个模型和硬件环境,profile 计算和通信开销,然后搜索一个比较好的并行执行方案。优化目标主要有两个:
- 搜得快;
- 搜得好。
这件事和 Alpa 一类系统在方向上有相似之处:把分布式并行策略看成一个优化问题,然后用 profiling、cost model 和启发式搜索来降低搜索成本。在 research setting 下,这个方向很干净,也很有吸引力。
后来 AutoDist 被集成进 nnScaler。nnScaler 更像一个分布式训练 compiler stack:前端 capture PyTorch program,中间做图变换和 plan generation,后端生成可以执行的 PyTorch 分布式代码。
我们当时比较相信 PyTorch 生态,觉得如果一个系统能紧密集成 PyTorch,而不是要求用户迁移到一个全新的框架里,它的实际价值会更大。
这个判断我现在依然觉得是对的。但后来真正困难的地方,远不止“怎么找到一个快的 plan”。
3. 从 research system 到真实训练,最难的是获得信任
做系统的人很容易首先关心速度:step time 降了多少,memory 省了多少,能不能 scale 到更多卡。但从模型和算法用户的角度看,第一优先级往往不是快,而是:你这个系统是不是对的?
这件事听起来简单,但在分布式训练里非常难。
理论上,用户当然希望系统能做到 bitwise parity:同样输入、同样环境、同样随机种子,换成分布式执行后结果完全一样。但真实情况会复杂很多:
- floating point 累加顺序会变;
- 一些 kernel 本身不是 deterministic 的;
- deterministic mode 可能带来明显性能损失;
- NCCL collective 的 channel 和实现细节可能影响结果;
- profiler 看到的性能可能受软件版本、shape、硬件状态影响;
- 神经网络本身会掩盖一些错误,小错误可能很多 step 之后才在 loss curve 或 eval 上体现出来。
早期做 nnScaler 时,我们在实践中更多依赖经验性的 parity testing:tensor/value comparison、短程 loss curve、和 reference run 对齐、再交给用户做更大规模验证。这个做法并不完美,但它很接近很多训练框架在实践中的测试方式。
后来我逐渐意识到,正确性不是一个附属 checklist,而是一个值得单独研究的问题。nnScaler 生成了分布式执行计划和可执行程序,但用户真正需要的是“我为什么应该相信这个程序”。这个思考也自然引向了后面类似 TrainVerify 这样的工作:把分布式训练正确性从工程经验推进到更形式化的验证问题。
这也是我从 nnScaler 里学到的最重要一课:分布式训练系统不是能跑、能快就够了,它必须让用户相信它改写后的执行仍然保持了训练语义。
4. 灵活性不是免费的
相比 FSDP、Megatron、DeepSpeed 这类系统,nnScaler/AutoDist 的一个吸引力在于更大的搜索空间和更强的 generality。理论上,搜索空间越大,就越可能找到适合某个模型和硬件环境的更好方案。
但后来我越来越觉得,灵活性不是免费的。
更大的搜索空间意味着:
- 需要生成、测试、解释更多 plan;
- graph transformation 和 runtime 状态更多;
- codegen 出错的方式更多;
- parity 和 verification 的 case 更多;
- 用户在遇到问题时更难判断问题在哪里。
在 research paper 里,generality 往往是一个优点。但到了真实训练中,generality 的成本会非常具体地落到 dev、debug、verification、user support 上。一个系统如果什么都想支持,很可能最后每一层都只能支持到“不够让人放心”的程度。
这并不是说 general system 没有价值,而是要问清楚:在哪些场景里,generality 真的值得为它付出成本?
我现在倾向于认为,nnScaler 这类系统最适合的场景是:
- 模型结构还在快速变化;
- 用户不想手写复杂的并行策略;
- 系统能从模型语义中推导或搜索出正确执行;
- workload 相对静态,shape 和 control flow 不会频繁破坏 compiler assumption。
一旦模型架构逐渐收敛,或者主流训练都围绕少数硬件/软件栈展开,专用系统的性价比就会变高。比如 LLaMA-like 模型、MoE 模型、特定 long-context 方案,如果已有 Megatron-style stack、FSDP、verl 或专门 trainer 能比较稳定地支持,用户未必愿意为了 general compiler stack 付出额外学习和调试成本。
5. 真实大规模训练会把系统边界继续推宽
如果说 nnScaler 让我看到 compiler/trainer 层面的复杂性,那么最近接触更多大规模训练后,我的另一个感受是:分布式训练系统的边界会被真实 workload 不断推宽。
在更大规模下,训练系统不再只是一个 framework 内部问题。它会牵涉到:
- storage 和 dataloader 吞吐;
- checkpoint save/load 和 resume 成本;
- cluster scheduler;
- 机器验证、维修和重新放回资源池的 pipeline;
- 网络拓扑、collective performance 和 straggler;
- fault tolerance;
- logging、metrics、profiling 和 diagnostics;
- inference engine;
- model architecture 和 training algorithm 的 co-design。
这时候优化目标也会变化。小规模时,我们很自然地看 step time、某个 kernel 的 TFLOPS、某个 layer 的 profile。大规模时,更重要的单位可能变成一次 long-running training campaign:
- tokens/day;
- effective training time;
- failed job 的恢复成本;
- debug turnaround;
- 训练过程中遇到异常时定位真实原因的速度。
MegaScale、Robust LLM Training Infrastructure、FALCON、XPUTimer、SuperBench、L4 这些公开系统工作,之所以值得看,不只是因为它们报告了大规模集群经验,而是因为它们把“训练系统”这个概念从框架内部扩展到了集群、网络、诊断和运维闭环。
6. 后训练和 RL 让 inference 也变成 training system 的一部分
另一个变化来自 post-training 和 RL。
传统 pretraining 很容易被想象成一个相对干净的 loop:forward、backward、update,最多再加 checkpoint 和 evaluation。但在 RL/post-training 里,训练往往变成一个闭环:
- rollout;
- environment;
- reward;
- filtering;
- training;
- evaluation;
- 再继续 rollout。
这时候 inference engine 不再只是训练结束后的 serving 组件,而会直接影响训练效率。比如 rollout routing、load balance、prefix-aware routing、speculative decoding、MTP 这类技术,都可能变成 training system 的一部分。
更麻烦的是,一些系统优化并不是语义中性的。比如 async RL 从系统利用率角度很诱人,但从算法角度可能引入 staleness 和 off-policy effect。如果没有和算法侧一起 co-design,很容易出现“系统上跑得更满了,但训练目标其实变了”的问题。
这类问题给我的启发是:在后训练/RL 场景里,系统优化不能只问“能不能更快”,还要问“是否保持了算法契约”。
7. Fault tolerance 会成为训练系统本身的问题
随着预训练规模继续变大,机器故障不是异常,而是常态。
现有很多训练 stack 本质上还是同步训练:一个 rank 出问题,整个 job 就可能 hang、fail 或被迫 restart。checkpoint/restart 是必要能力,但如果训练规模足够大、训练时间足够长,restart cost 本身就会显著影响 effective training time。
所以更理想的方向不是“假设机器不坏”,而是让 fault tolerance 变成分布式训练设计的一部分。例如 FT-HSDP 这类工作讨论的方向,就是在大规模同步训练里尝试隔离失败 replica,让健康 replica 继续前进,并在恢复后重新加入。
这和传统意义上的“运维可靠性”不完全一样。到了足够大的训练规模,fault tolerance 本身就是训练系统的语义和性能问题。
8. 现在最有价值的能力可能是 verification / testing / diagnostics
大规模训练难的一个原因是整个 stack 都在快速演进:
- GPU 和网络设备在变;
- CUDA、NCCL、PyTorch、Transformer Engine、Megatron 在变;
- 模型架构在变:MoE、long context、MLA、MTP、新 attention 变体;
- workload 在变:pretraining、post-training、RL、online generation、inference-heavy loop。
这些变量组合起来,使得“直接复用别人的经验和代码”变得有风险。即使一个方案在别人的模型、硬件、软件版本和集群拓扑上有效,也不代表在自己的环境里仍然有效。
因此,我越来越觉得 verification、testing、diagnostics 的价值被低估了。
一个好的诊断系统,应该尽量低成本地回答:
- 是模型实现问题,还是训练框架问题?
- 是 kernel 问题,还是通信问题?
- 是数据问题,还是 checkpoint/resume 问题?
- 是少数机器 fail-slow,还是整体配置不合理?
- 是性能波动,还是 correctness drift?
很多时候,大规模训练最贵的不是某次失败本身,而是失败之后不知道为什么失败。系统如果能更快定位真正的问题,就能显著提高工程效率。
这也是我认为未来训练系统长期有价值的方向之一:不是只生成一个 plan,而是让训练过程更可验证、可诊断、可恢复。
9. Scaling 仍然有效时,训练系统市场会分层
最后说一个更偏判断的观点。
只要 scaling law 在前沿区间继续有效,frontier pretraining 就会继续往更大模型、更大数据、更大计算资源上推。能完整参与 frontier pretraining loop 的组织会越来越少,因为它不只是需要 GPU,还需要数据、算法、工程、稳定性、集群、诊断和长期训练经验。
但这不意味着开源模型或中小模型会消失。更可能出现的是分层:
- 头部组织训练越来越大的 flagship model;
- 同时 release 一些小 dense model,用于端侧、开发者生态、research community;
- release 一些 efficient/flash variant,用更低 serving 成本覆盖更多场景;
- 偶尔 release 大 MoE 或开放权重模型,作为生态入口。
这种分层会反过来影响训练系统。
如果公开模型架构逐渐收敛,比如大部分是 LLaMA-like backbone,加上一些 attention、MoE、long-context、MTP 等局部变化,那么为某个具体架构写专用 trainer 或改已有 stack 的成本会下降。现在 coding agent 也会进一步降低 glue code、adapter、baseline trainer 的开发成本。
这会压缩 pure generality 的价值空间。一个系统如果只强调“我能支持更多模型”,可能不如以前有说服力。因为很多时候,用户可以基于一个公开 baseline 很快改出能跑的版本。
但这并不意味着训练系统没有价值。恰恰相反,真正难的部分会继续存在:
- parity;
- checkpoint/resume;
- long-running stability;
- fault tolerance;
- communication performance;
- diagnostics;
- fast adaptation to real workloads。
所以我现在的判断是:general distributed training system 的价值不会消失,但它的价值函数会变化。持久的价值可能不在于“自动生成一个并行方案”本身,而在于能否让复杂训练过程正确、可诊断、可恢复,并且能快速适配真实 workload。
10. 对做 research 的一点启发
这篇文章不是想说某一种系统路线一定对,或者某一种路线已经没有价值。我更想表达的是:做系统研究时,需要非常敏感地观察需求信号和生态变化。
2022 年左右,自动并行是一个非常自然的问题,因为模型结构更多样,用户手写分布式策略的成本很高,硬件显存又是明显约束。到了今天,如果模型架构、硬件栈、训练流程都发生变化,那么同一个系统方向的价值也会变化。
对研究来说,这不一定是坏事。它只是提醒我们:
- 不要只问一个系统能不能做得更 general;
- 也要问 generality 在什么场景里真的有价值;
- 不要只看性能数字;
- 也要看 correctness、observability、debuggability、operational cost;
- 不要只研究一个 isolated layer;
- 也要理解它上下游的真实约束。
我个人现在更相信这样一种判断:
分布式训练系统的核心价值,正在从“找到一个高效并行方案”,扩展到“让复杂训练过程可验证、可诊断、可恢复、可持续演进”。
这个判断肯定不完整,也可能有偏差。如果你在做大规模训练、后训练、推理系统、集群调度、网络、checkpoint、验证或诊断,欢迎补充不同的观察。