原文链接:https://yannx1e.github.io/IW-OPD/
论文作者:Yan Xie, Sijie Zhu, Tiansheng Wen, Bo Chen, Yifei Wan
摘要
在线蒸馏(On-Policy Distillation, OPD)之所以受到关注,是因为它结合了两个有用的要素:学生模型在自己的 rollouts 上进行训练,而教师模型则对这些 rollouts 提供密集的 token 级反馈。这也是 OPD 成为稀疏奖励强化学习在语言模型后训练中的自然替代方案的原因。
在本文中,我们研究一个不那么显而易见的问题:一旦获得了密集的教师反馈,这些反馈在响应的哪些位置才是真正有用的?OPD 的效果不仅取决于我们收集了多少学生 rollouts,还取决于教师信号是否落在了能够继续引导学生走向更好推理的位置上。
我们发现了一种强烈的位置效应。学生 rollouts 中的早期 tokens 往往比晚期 tokens 携带更有用的监督信号。随着学生继续生成,其前缀可能会偏离教师的高概率推理区域。教师仍然会被查询,但现在它需要在可能并非自己生成的前缀条件下对 tokens 进行评分。因此,密集监督并非自动地等价于同等有用的监督。
我们将这种现象称为 OPD 中的位置偏差(position bias)。为了进一步诊断这个问题,我们进行了对照研究,并发现了两个有趣的现象:
- 早期 token 监督驱动着 OPD 的性能;
- 师生差距在 OPD 训练后基本持续存在。
为了理解这一现象,我们从约束优化的视角重新审视 OPD。然后我们推导出该约束下的最优策略,并用该最优解来解释为什么与教师兼容的前缀应该获得更多权重。IW-OPD 就是基于这一原则设计的:保留密集的 token 级 OPD 信号,但加强对仍然看起来与教师兼容的前缀的重视程度。
一、监督信号花在了哪里
设 \pi_\theta 为学生模型,\pi_T 为教师模型。对于一个 prompt x 和一个由学生采样的响应 y = (y_1,\ldots,y_T),标准 OPD 在学生自己的 rollout 分布上最小化一种 reverse-KL 风格的目标函数:
在策略梯度实现中,这给出了一个 token 局部的优势:
OPD 对每个采样的响应 token 应用 token 级损失,一种自然的实现是对这些损失进行均匀平均。这很简单,但它假设教师信号在各个位置上同等有用。在引入加权规则之前,我们先问一个更基本的实证问题:如果我们在同一个学生响应的不同部分上进行训练,效果是否相同?
二、位置偏差
我们从一个简单的干预开始:在保持模型、数据和训练设置不变的情况下,使用来自响应不同部分的 tokens 训练 OPD 变体。
- Prefix-30:仅对响应前 30% 的 tokens 应用 OPD
- Suffix-30:仅对响应后 30% 的 tokens 应用 OPD
- 标准 OPD:使用所有有效的响应 tokens
这个实验是刻意粗糙的;其目的是测试位置本身是否具有可衡量的影响。
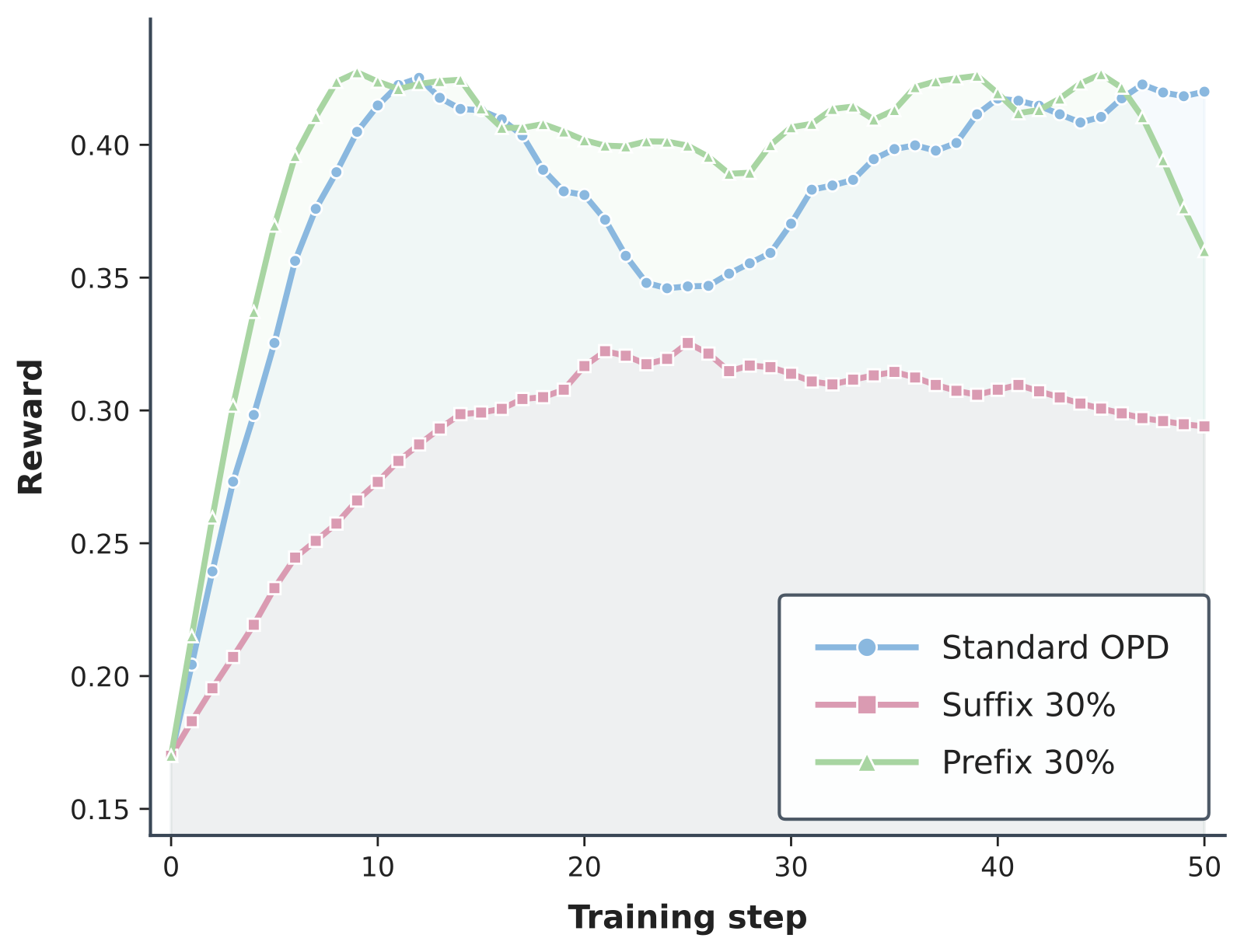
相同数量,不同位置。在这个对照实验中,Prefix-30 与完整 OPD 相当或超过后者,而 Suffix-30 学习效果很差。这表明密集监督的数量并不是全部——监督的位置同样重要。
这一结果揭示了 OPD 中一种依赖于位置的效应。早期和晚期 tokens 不可互换:它们是在不同的前缀分布下采样的,训练它们可能导致不同的结果。我们将这种现象称为位置偏差。
这一结果并非"早期 tokens 总是更好"的简单表述。更好的解释是:早期 tokens 更有可能在教师分布仍然对改善学生推理路径有意义的前缀下被评分。晚期 tokens 则以学生的全部已有生成为条件。如果学生已经离开了与教师兼容的区域,后缀可能在局部可预测,但对纠正早期漂移的全局作用较小。这与最近对推理更新的分析有松散的联系,这些分析发现某些 tokens 或位置具有不成比例的影响,例如关于高熵分叉 tokens、关键 token 训练以及将推理 tokens 与 boilerplate tokens 分开的工作。
下一个问题是:为什么会出现这种位置效应?以下诊断探查了晚期位置是简单地因为"更晚",还是因为以变得与教师不那么兼容的前缀为条件。
三、偏差背后的诊断
诊断一:强教师能否从学生前缀中恢复?
我们对两个模型都以学生生成的前缀为条件,然后测量最终到达正确答案的概率。这并不直接训练模型;而是探查该前缀是否仍然是教师指导的有用状态。
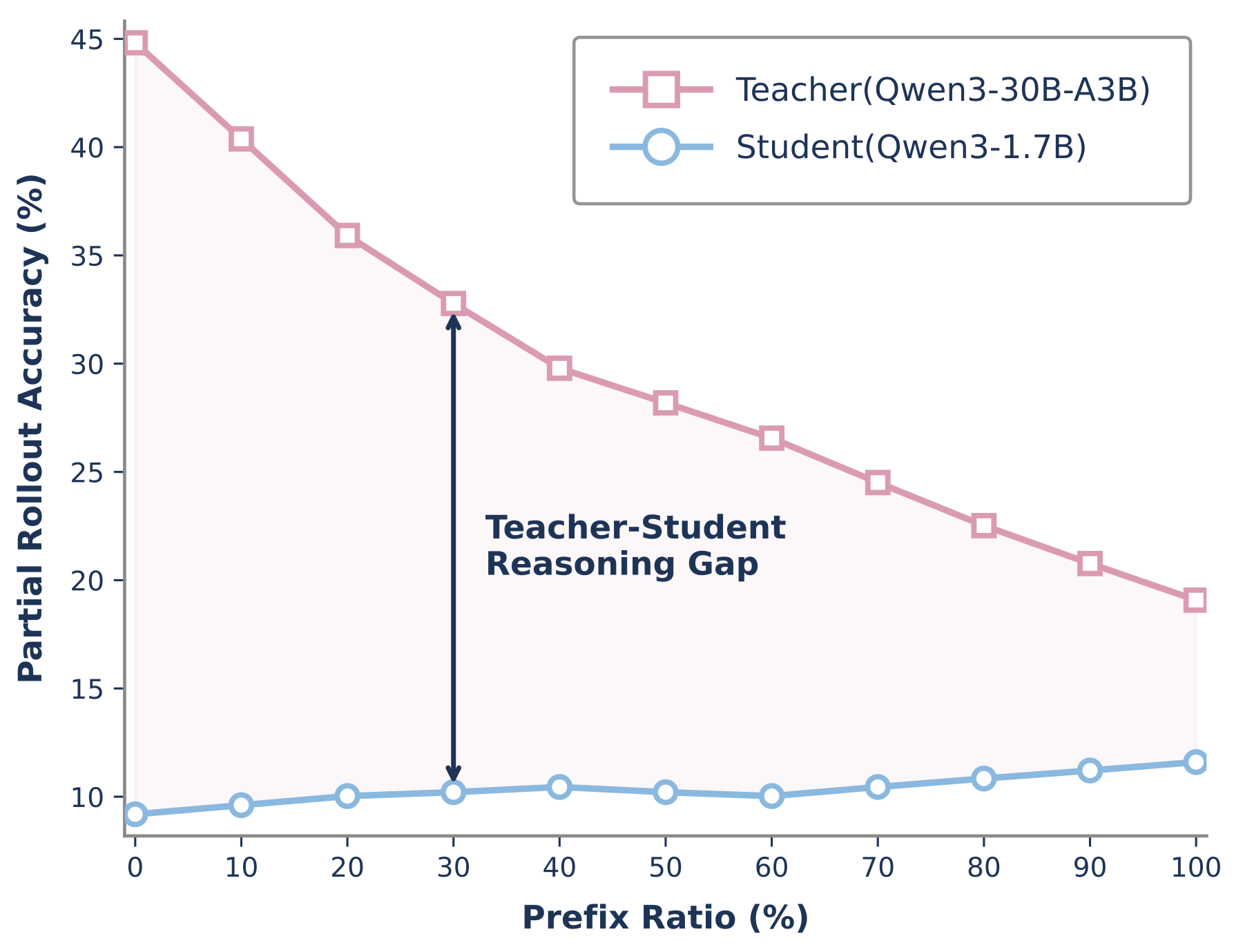
师生延续差距。教师从更高的延续准确率开始,但其恢复能力随着学生前缀的增长而下降。较长的学生前缀可能将上下文拉向即使教师也较少有机会到达正确答案的区域。
这张图是我们的解释的核心。OPD 在学生的前缀上查询教师,而不是在教师自己的理想前缀上。在响应早期,教师通常仍能识别出一条通往正确解的路径。后来,在学生做出了足够的局部选择之后,同一个教师被要求从一个可能编码了不同计划的上下文继续。监督仍然是密集的,但它与我们希望更新做出的纠正对齐程度较低。
诊断二:训练过程中师生 KL 能否自我修复?
如果师生 KL 能被降低到足够低的值,OPD 训练本身可能逐渐修复前缀漂移问题:随着训练的进行,后期的学生前缀将变得与教师更加兼容。因此,该诊断测试 OPD 是否能够自行修复这种不匹配。如果 OPD 只是在将学生一直移动到教师分布,我们预期 KL 会持续缩小趋近于零。然而,平均 KL 在早期下降后趋于平稳。
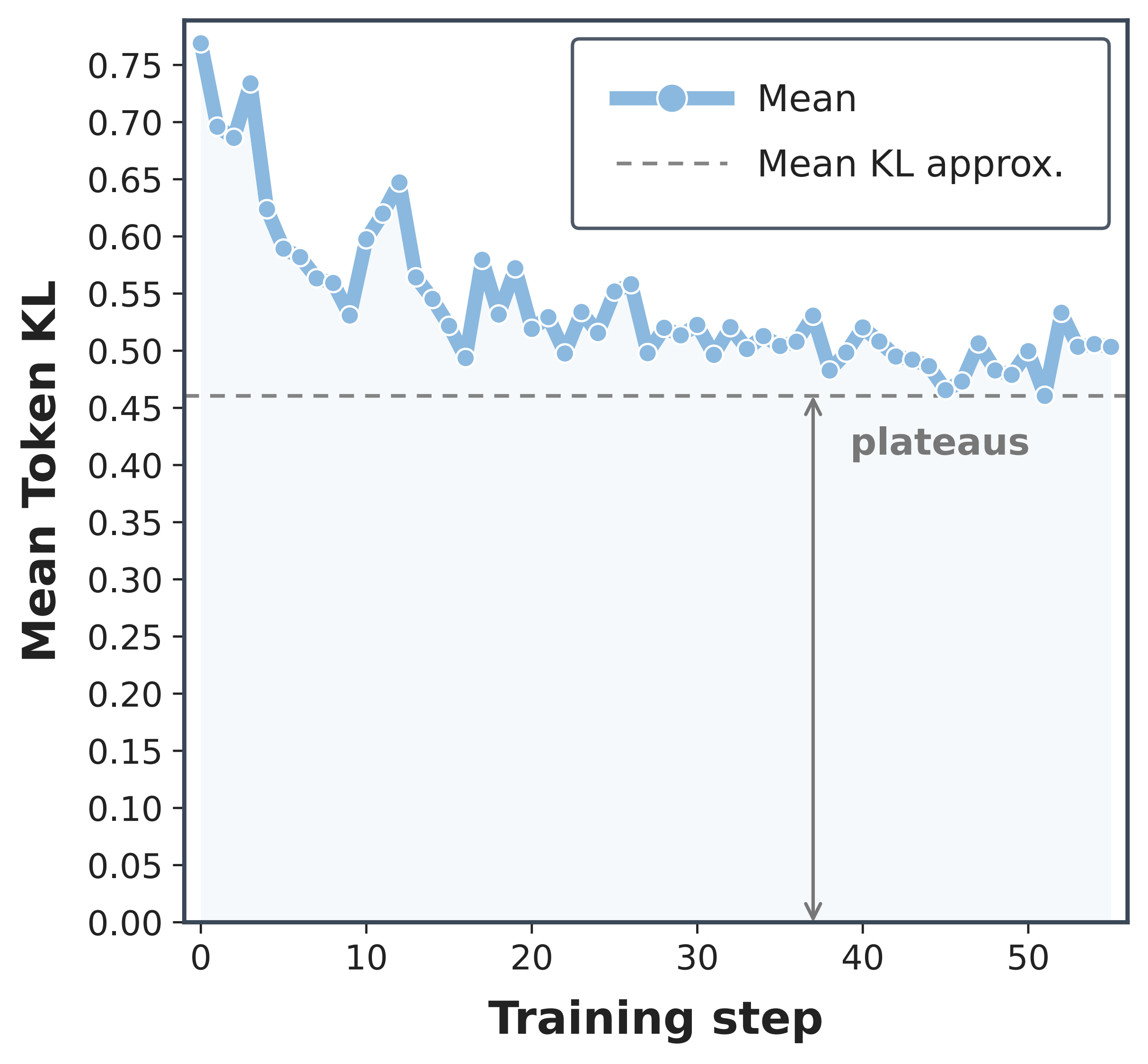
KL 降低是局部的。Mean token-level KL 在训练早期下降,但留下了一个非零的残差。在我们的诊断中,即使在性能饱和后,这种降低也是有限的。
这个 plateau 表明,OPD 更应被视作一种局部策略更新,而不是无约束的教师匹配。这对位置偏差很重要:当更新只能将学生移动有限的距离时,不同的 token 位置可以具有不同的杠杆作用。
诊断三:残差不匹配是否局限在响应的很小一部分?
不是。Token-level KL 在训练后即使跨越广泛的相对位置仍然是非零的。
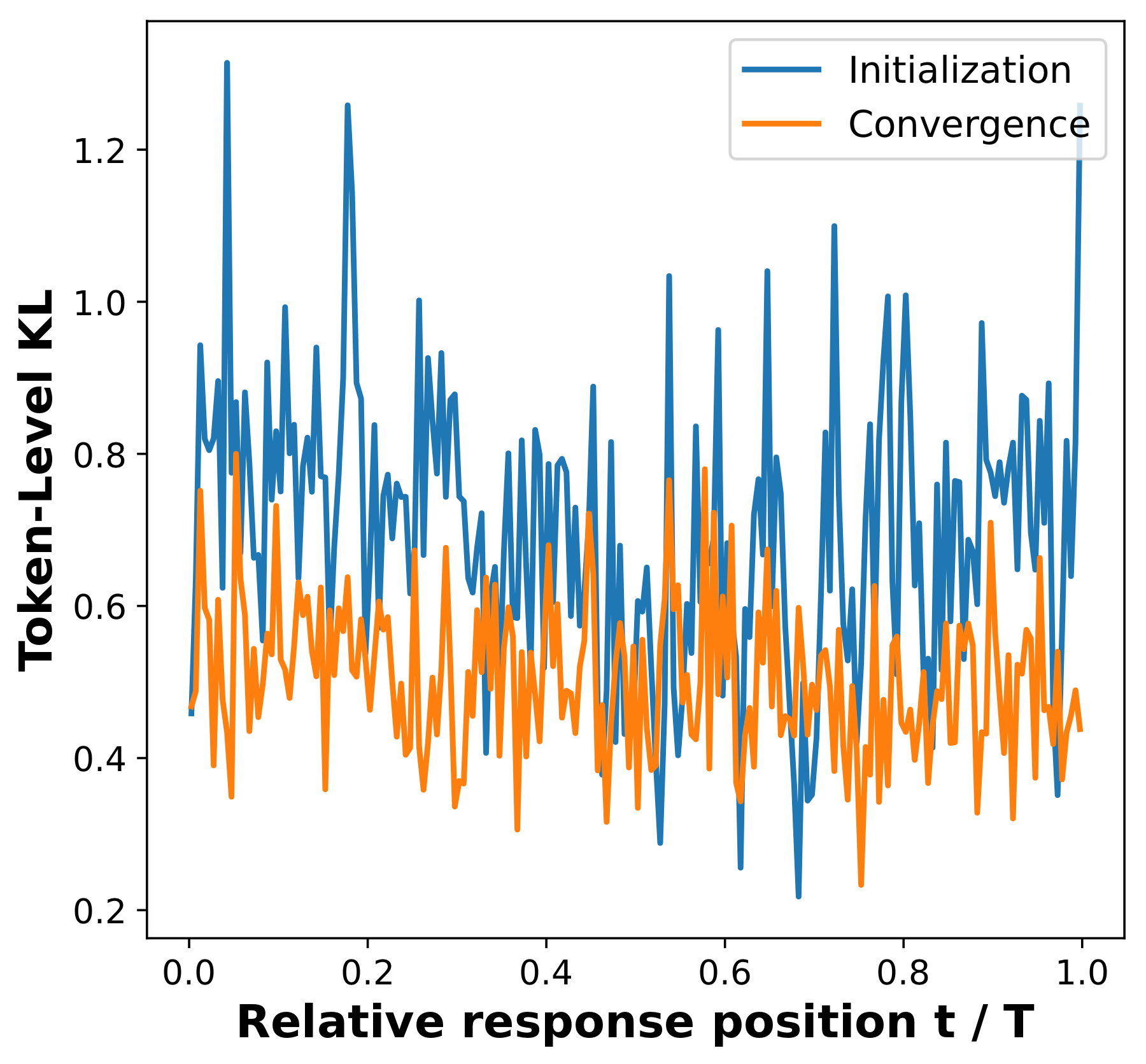
跨位置的残差不匹配。OPD 提高了与教师的一致性,但它并没有消除整个 rollout 中师生间的不匹配。因此,均匀加权继续对具有不同前缀质量的位置进行平均。
诊断四:前缀似然的可视化
沿着学生采样的 rollout,前缀在学生模型下自然保持相对较高的似然(这是由采样构造决定的)。但在教师模型下,相同前缀的似然下降得更快。这是上面延续结果在分布层面的版本。
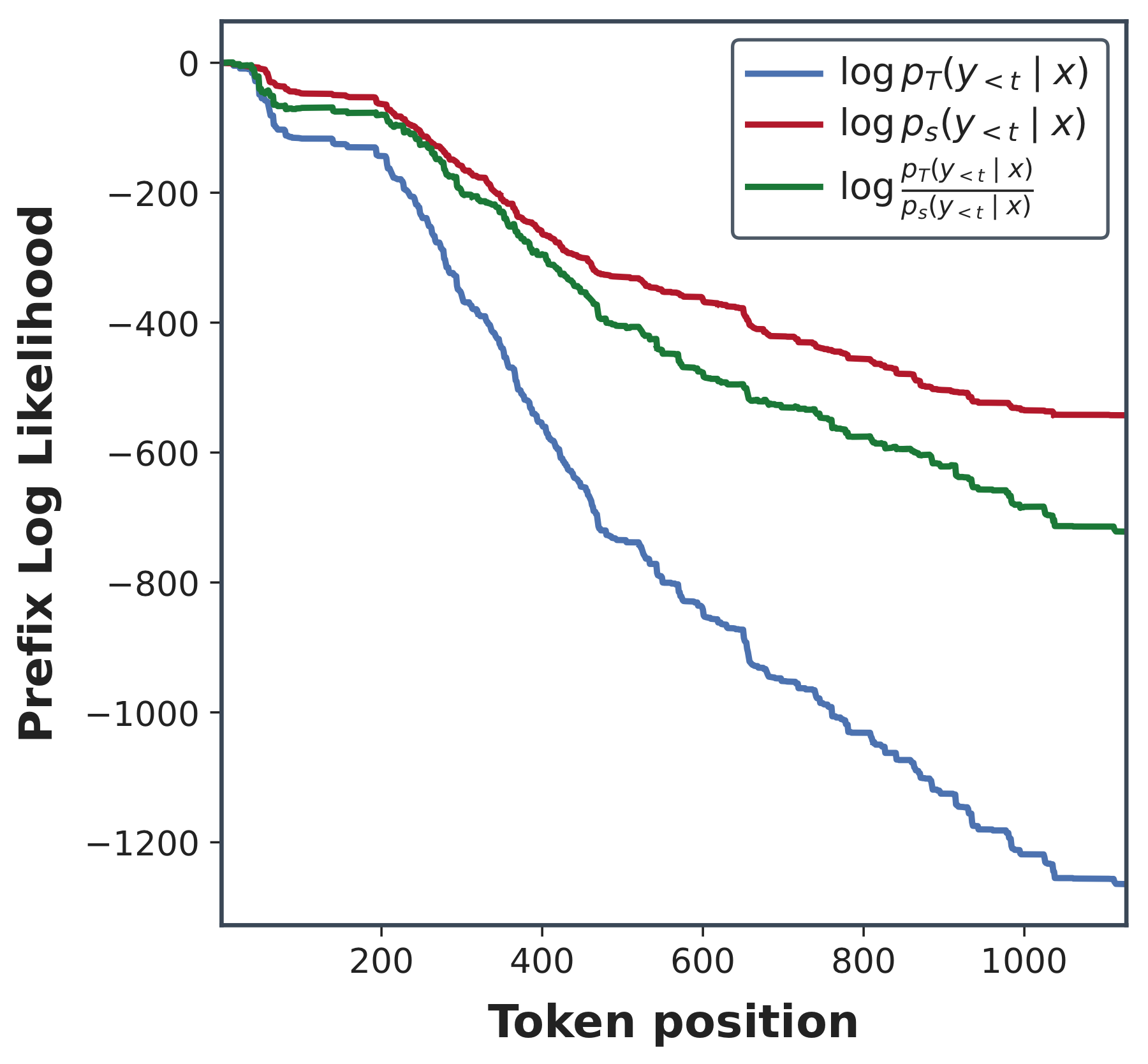
对数似然空间中的前缀漂移。教师-学生前缀似然比倾向于随着学生生成的前缀增长而缩小。这促使我们使用前缀兼容性(而不仅仅是 token 位置)作为重加权的单位。
综合来看,这些诊断说明了为什么位置偏差对蒸馏质量很重要。我们不仅仅是在随机位置有噪声监督,而是一种结构化的不匹配:晚期 tokens 更可能以与教师不太兼容的前缀为条件,而均匀 OPD 继续在它们身上花费相同名义上的 token 权重。
四、有限预算视角
这些诊断促使我们采用有限预算视角,我们将其作为解释所观察到的位置偏差的分析工具。我们不问如果学生可以随意移动,什么分布会匹配教师;而是问在当前学生周围的一个小 KL 球内,什么分布最接近教师:
这里 \rho 是有效的局部更新预算。这个视角与信任域和近端策略优化思想有关,如 TRPO 和 PPO:单次更新可以改进策略,但不能将学生的分布任意替换为教师的分布。
在非平凡状态下,教师位于学生的局部 KL 球之外。在共同支撑下,约束最优解有闭式解:
该约束下的最优解为观察到位置偏差提供了解释。最佳局部可达目标不是教师本身,而是向教师下更可能的轨迹倾斜的学生分布。这种倾斜正是教师-学生似然比。
这并不意味着后缀 tokens 是无用的。它意味着均匀 token 加权不是有限预算投影所隐含的分配规则。随着学生的改进,较长的前缀变得与教师兼容,晚期 tokens 可以再次接收更有用的监督。
五、从投影到 IW-OPD
局部投影识别出可达的教师对齐分布 q_\theta^\star。但我们在 OPD 期间实际观察到的数据是从当前学生 \pi_\theta 采样的。这种不匹配正是重要性加权进入的地方。类似的分布校正思想出现在策略优化和偏好优化工作中,如 GSPO 和 DPO,尽管我们在这里的用途具体来说是 OPD 的前缀级分配规则。
OPD 只能优化当前学生策略周围的一个局部区域。在约束优化视角下,OPD 能达到的最佳策略是 q_\theta^\star,它使用似然比衡量的师生差距来重新加权基础学生策略 \pi_\theta。从早先的分析中,只有具有相对较高似然比的 tokens 才能提供有意义的 OPD 学习信号,因为其他 tokens 被采样的概率非常低。基于此,我们使用投影的教师对齐策略作为学习目标,强调高概率、与教师兼容的样本:
由于投影停留在局部 KL 球的边界上,正 KL 项分解为一个固定的局部预算项加上在 q_\theta^\star 下的期望。这是一个三行步骤,将有限预算视角转化为重要性加权目标:
问题在于我们在 OPD 期间不是从 q_\theta^\star 采样,而是从 \pi_\theta 采样。测度变换用重要性权重重写了期望。在轨迹层面,主论文中的似然比是 r_\theta(y)=\pi_T(y)/\pi_\theta(y),投影目标诱导的密度比为:
对于 token 级 OPD,相关的因果对象是前缀。遵循主论文的符号,相应的归一化前缀比为:
这给出了一个在从 \pi_\theta 采样的 rollouts 上的 token 级目标:
其半梯度具有与 OPD 相同的策略梯度形式,但具有重要性加权的优势:
这就是 OPD 优势在 IW-OPD 中重新出现的原因。该推导没有引入新的 token 损失;而是改变了乘以通常 OPD 策略梯度信号的系数。直观上,均匀 OPD 将观察到的学生分布视为期望的局部目标。IW-OPD 问的是如何将观察到的分布纠正向局部可达的教师对齐分布。具有高教师-学生似然比的前缀获得更多权重;积累了师生漂移的前缀获得较少权重。
六、实用的代理目标
上述前缀比目标给出了一个清晰的分配原则,但直接在有限的在线训练中使用 \tilde r_t 是不稳定的。实用的 IW-OPD 权重遵循论文的四步修改:使用对数缩放比、修正符号取消、在 rollouts 内归一化、以及将结果与标准 OPD 插值。在这些修改之前,\alpha 的消融显示为什么仅控制锐度是不够的。
首先,直接前缀比加权是脆弱的,因为前缀概率在 tokens 上相乘。即使有指数 \alpha,系数在 rollout 增长时也可能变得过于尖锐。第一个消融询问调整后的 \alpha 是否足够。
配套可视化逐 token 地考察了相同问题。它促使了下面的第一个变换:对数空间视图暴露了我们希望实用代理避免的广泛下行趋势和局部反弹。
问题:原始 r_t 前缀比配合正确的指数是否能工作? 大的 \alpha 值使权重过于尖锐并损害训练;非常小的值使权重平坦化,行为更接近标准 OPD。这表明 r_t 作为分配原则是有用的,但作为字面的训练系数是脆弱的。
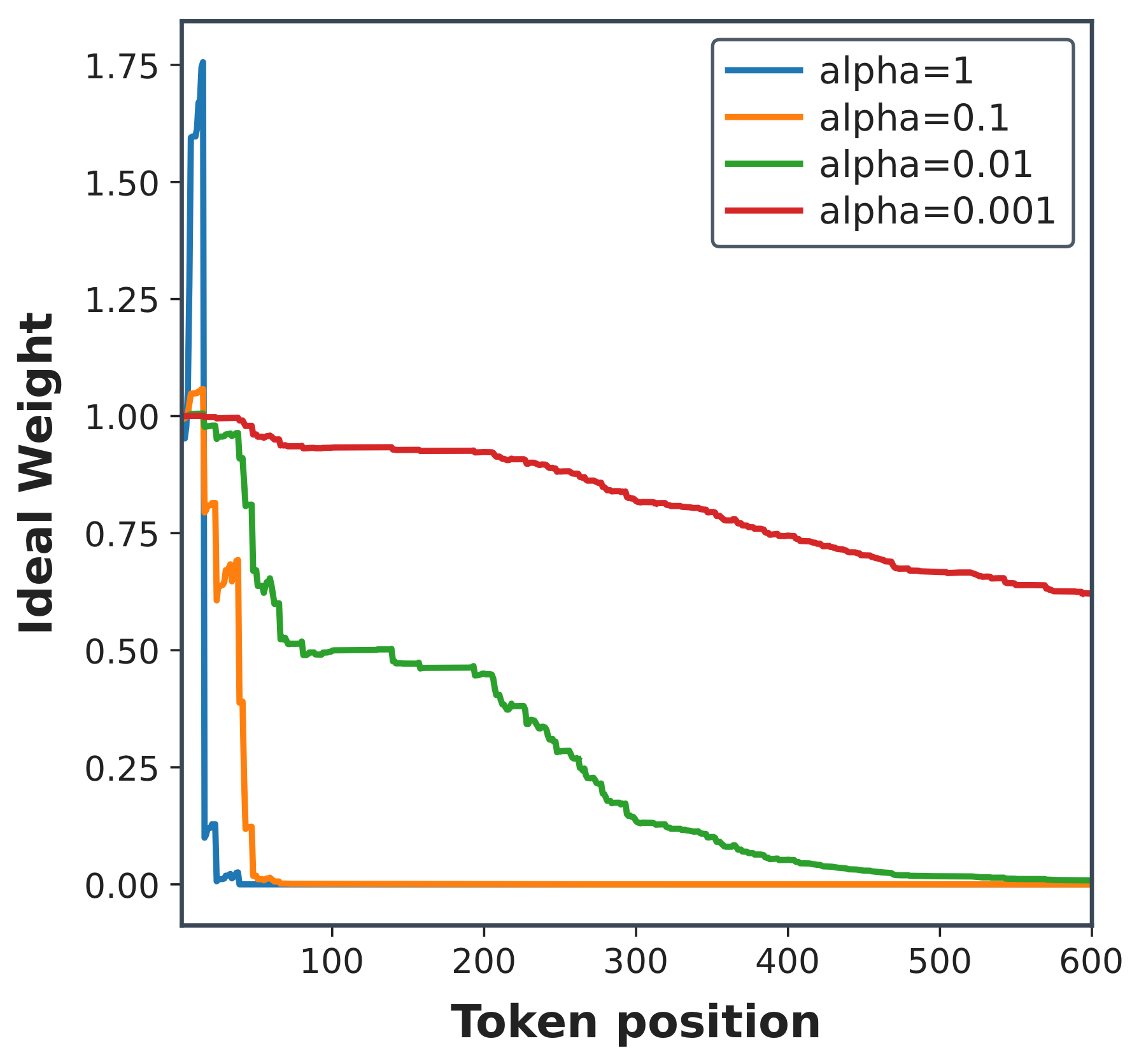
问题:符号化的基于 r_t 的权重逐 token 做什么? 广泛的下行趋势与位置偏差直觉相符,但出现了局部反弹,因为符号化的对数概率差距可以相互抵消。这使得字面的前缀比作为更新系数是不稳定的。
I. 对数缩放
与其操作概率比的乘积,不如在对数空间中进行工作。令 A_k^{\mathrm{OPD}}=\log \pi_T(y_k\mid y_{<k})-\log \pi_\theta(y_k\mid y_{<k}),对数缩放的前缀分数为:
对数空间形式在数值上更清晰,但它暴露了另一个问题。累积是有符号的:正负 token 差距可以相互抵消,因此前缀分数可能在前缀已经穿过多个师生不匹配后反弹。
II. 修正正优势取消
由于 rollout tokens 是从学生采样的,师生对数差距在这些 tokens 上经常为负。偶尔教师比学生分配更高的概率,产生抵消累积负前缀差距的正项。我们通过将每个 token 级不一致转换为非正的累积差异来减少这种取消:
问题:前缀差异应该是有符号的还是无符号的? 无符号版本在这个消融中表现更好。结果支持这样一种观点:两种方向的不一致都应该计为前缀漂移,而不是允许正负差距相互抵消。
III. 归一化
符号修正使差异在 rollout 上单调,但它的规模仍然可能在不同样本间差异很大。因此我们在每个 rollouts 内部进行归一化,将序列开头映射到接近 1,将积累更大不匹配的前缀映射到接近 0:
IV. 与 OPD 插值
归一化后,序列末尾 tokens 可能收到非常低的权重。IW-OPD 不是移除密集监督,而是将归一化前缀分数与标准 OPD 进行插值:
直观的形式很简单:积累师生不一致较少的前缀收到更大的乘数,而已经积累了许多不一致的前缀回落至接近标准 OPD。这个设计选择很重要。IW-OPD 不是从晚期 tokens 移除密集监督。它保持标准 OPD 作为底限,detach 权重,并将额外的梯度预算分配给更兼容的前缀。在我们的主要实验中,我们使用 \gamma=0.5,而 \gamma=0 精确地恢复标准 OPD。
实现草图
- 采样 prompts 并在线策略生成学生 rollouts
- 在采样的响应 tokens 上评估学生和教师的 log probabilities
- 从师生 log-probability 差距计算标准 OPD advantage
- 计算独占累积无符号前缀差异并转换为 \tilde r_t^{\mathrm{norm}}
- 使用相同的裁剪 PPO 风格目标进行训练,用 A_t^{\mathrm{IW\text{-}OPD}} 替换 A_t^{\mathrm{OPD}}
delta_t = abs(logprob_teacher_t - logprob_student_t)
norm_r_t = 1 - exclusive_cumsum(delta_t) / sum(delta_t[:-1])
iw_weight_t = 1 + gamma * norm_r_t
advantage_t = stop_gradient(iw_weight_t) * opd_advantage_t
该方法不需要标准 OPD 之外的额外教师评估。它改变了已经计算出的信号的分配。
七、实验
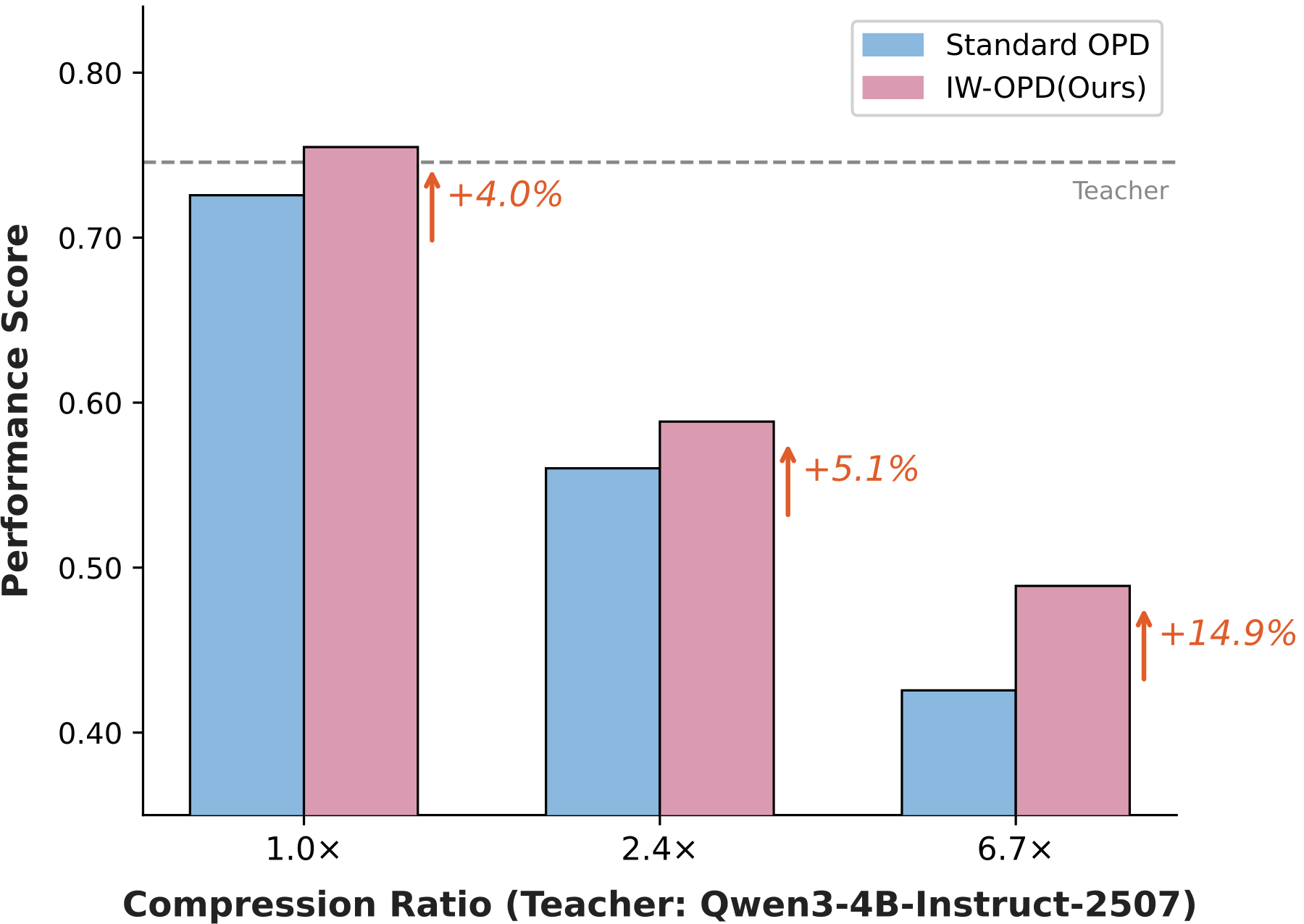
我们在同家族和跨尺度蒸馏上评估 IW-OPD。学生模型为 Qwen3-4B、Qwen3-1.7B 和 Qwen3-0.6B。教师模型包括 Qwen3-4B-Instruct-2507(更大重叠设置)和 Qwen3-30B-A3B-Instruct-2507(更小重叠设置)。我们还报告了 Qwen3-235B-A22B 到 Qwen3-30B-A3B 的实验。
训练使用 DeepMath 问题(难度至少为 6,约 57K prompts)和 Eurus-RL-Code(约 25K prompts)。数学在 AIME 2024、AIME 2025 和 HMMT 2025 上以 mean@32 准确率评估。代码在 HumanEval+ 和 MBPP+ 上评估。比较结果在三个随机种子上的平均。
Step-10 结果
Step-10 检查点测试样本效率:在相同的训练设置和早期更新预算下,重加权是否能更好地利用教师信号?在两种教师环境下,IW-OPD 在 step 10 时在每个学生规模上都领先于标准 OPD。
表:训练 step 10 的早期检查点。Avg 是 AIME24、AIME25、HMMT25、HumanEval+ 和 MBPP+ 在我们结果表上的平均值。
| Teacher | Student | OPD₁₀ AIME25 | IW-OPD₁₀ AIME25 | Delta |
|---|---|---|---|---|
| Qwen3-30B-A3B | Qwen3-4B | 42.4 | 49.3 | +6.9 |
| Qwen3-30B-A3B | Qwen3-1.7B | 20.2 | 23.2 | +3.0 |
| Qwen3-30B-A3B | Qwen3-0.6B | 14.1 | 15.8 | +1.7 |
| Qwen3-4B | Qwen3-4B | 45.7 | 46.7 | +1.0 |
| Qwen3-4B | Qwen3-1.7B | 24.7 | 25.9 | +1.2 |
| Qwen3-4B | Qwen3-0.6B | 17.1 | 19.0 | +1.9 |
最大的早期收益在 Qwen3-30B-A3B 到 Qwen3-4B 的设置中,AIME25 在 step 10 提高了 6.9 分。我们将其解释为 IW-OPD 改变学习效率的证据,而不仅仅是最终检查点。结果仍然受限于所测试的模型家族和任务;它并不意味着普遍的 step 减少。
Qwen3-30B-A3B teacher
30B-A3B teacher 是我们主要实验中较小重叠的设置。在这种情况下,学生更经常离开与教师兼容的区域,因此如果有限预算解释是正确的,前缀加权应该是有用的。
表:从 Qwen3-30B-A3B-Instruct-2507 蒸馏。数学结果为 mean@32 准确率(%);代码结果使用 HumanEval+ 和 MBPP+。
| Student | Method | AIME24 | AIME25 | HMMT25 | HE+ | MBPP+ | Avg |
|---|---|---|---|---|---|---|---|
| Qwen3-4B | OPD | 55.3 | 48.0 | 27.1 | 77.2 | 69.1 | 55.3 |
| Qwen3-4B | IW-OPD | 57.5 | 49.7 | 28.7 | 78.7 | 70.9 | 57.1 |
| Qwen3-1.7B | OPD | 34.6 | 28.7 | 15.5 | 64.6 | 53.7 | 39.4 |
| Qwen3-1.7B | IW-OPD | 35.5 | 29.5 | 16.4 | 65.2 | 55.0 | 40.3 |
| Qwen3-0.6B | OPD | 11.0 | 17.8 | 7.1 | 29.6 | 28.7 | 18.8 |
| Qwen3-0.6B | IW-OPD | 11.5 | 19.3 | 8.0 | 32.5 | 31.9 | 20.2 |
IW-OPD 在这种环境下改进了所有三个学生的最终平均值。收益在不同规模上并不相同,这与我们的观点一致:相关变量是有效前缀重叠,而不是单纯的模型规模。
Qwen3-4B teacher
4B teacher 设置具有更大的student-teacher重叠。这是一个有用的检验,因为如果 IW-OPD 仅在学生非常远离教师时才有效,收益可能会消失。在某些情况下收益变小了,但它们在报告的学生中保持为正。
表:从 Qwen3-4B-Instruct-2507 蒸馏。教师和一些学生共享更多规模/家族重叠,但 IW-OPD 仍然改进了报告的平均值。
| Student | Method | AIME24 | AIME25 | HMMT25 | HE+ | MBPP+ | Avg |
|---|---|---|---|---|---|---|---|
| Qwen3-4B | OPD | 56.5 | 46.3 | 24.4 | 76.3 | 67.8 | 54.3 |
| Qwen3-4B | IW-OPD | 58.7 | 46.7 | 25.0 | 77.9 | 68.2 | 55.3 |
| Qwen3-1.7B | OPD | 34.0 | 26.4 | 13.7 | 61.5 | 53.7 | 37.9 |
| Qwen3-1.7B | IW-OPD | 35.2 | 27.1 | 15.3 | 62.8 | 54.9 | 39.1 |
| Qwen3-0.6B | OPD | 11.8 | 17.1 | 2.8 | 29.8 | 33.3 | 19.2 |
| Qwen3-0.6B | IW-OPD | 13.6 | 19.0 | 6.1 | 31.6 | 35.7 | 21.2 |
Qwen3-235B-A22B teacher
我们还评估了从更强的 Qwen3-235B-A22B teacher蒸馏到 Qwen3-30B-A3B。这个设置并不是为了穷尽地描述非常大的teacher,而是检查相同的前缀加权思想是否在小学生设置之外仍然有用。
表:从 Qwen3-235B-A22B-Instruct-2507 蒸馏到 Qwen3-30B-A3B。IW-OPD 改进了该表中所有报告的基准。
| Student | Method | AIME24 | AIME25 | HMMT25 | HE+ | MBPP+ | Avg |
|---|---|---|---|---|---|---|---|
| Qwen3-30B-A3B | Base | 28.4 | 23.4 | 15.2 | 77.8 | 69.5 | 42.9 |
| Qwen3-30B-A3B | OPD | 69.5 | 56.7 | 38.4 | 82.1 | 71.3 | 63.6 |
| Qwen3-30B-A3B | IW-OPD | 70.8 | 58.9 | 40.5 | 83.5 | 73.7 | 65.5 |
在这些设置中,我们做出的声明是温和的:IW-OPD 在我们评估的环境中一致地改进了标准 OPD,模式与有限预算前缀兼容性解释一致。我们不声称相同的收益必须在每个模型家族、任务或训练方案中成立。
八、前缀加权与奖励设计是正交的
IW-OPD 改变了已经计算的 OPD 信号如何在各位置间分配,因此它不依赖于特定的 advantage 或奖励设计。例如,ExOPD(Yang et al., 2026)将 OPD 重构为具有 KL 约束的强化学习问题,分离出奖励项,并通过缩放该奖励与固定超参数 \lambda 来改进探索。
由于 IW-OPD 提供前缀级重要性权重,我们可以通过使奖励规模依赖于前缀来将其应用于 ExOPD 之上,例如用 IW-OPD 权重调制 \lambda。我们称这种组合为 IW-ExOPD。这个实验的目的比特定的 ExOPD 基线更广泛:它测试前缀级重要性加权是否可以补充另一种 advantage 或奖励修改方法。
表:使用 Qwen3-30B-A3B-Instruct-2507 作为教师在小学生-教师重叠下的蒸馏结果。数学结果报告为 mean@32 准确率(%)。带下标 (10) 的方法在训练 step 10 评估。每组学生中粗体表示最佳结果。
| Student | Method | AIME24 | AIME25 | HMMT25 | HE+ | MBPP+ | Avg |
|---|---|---|---|---|---|---|---|
| Teacher | — | 74.7 | 62.8 | 44.2 | 86.6 | 75.1 | 68.7 |
| Qwen3-4B | Base | 23.1 | 21.4 | 10.0 | 75.3 | 64.5 | 38.9 |
| Qwen3-4B | OPD | 55.3 | 48.0 | 27.1 | 77.2 | 69.1 | 55.3 |
| Qwen3-4B | ExOPD | 57.9 | 50.1 | 31.7 | 78.9 | 70.2 | 57.8 |
| Qwen3-4B | IW-ExOPD | 59.4 | 51.7 | 32.0 | 80.1 | 71.0 | 58.8 |
| Qwen3-1.7B | Base | 13.4 | 11.0 | 6.8 | 59.6 | 52.5 | 28.7 |
| Qwen3-1.7B | OPD | 34.6 | 28.7 | 15.5 | 64.6 | 53.7 | 39.4 |
| Qwen3-1.7B | ExOPD | 37.6 | 31.8 | 16.8 | 67.2 | 55.0 | 41.7 |
| Qwen3-1.7B | IW-ExOPD | 38.9 | 33.2 | 18.3 | 68.5 | 57.4 | 43.2 |
IW-ExOPD 改进了 Qwen3-4B 和 Qwen3-1.7B 学生的 ExOPD。这表明前缀级重要性加权与 ExOPD 的奖励缩放机制是互补的,而不是仅与 vanilla OPD 绑定。
九、消融实验
消融实验隔离了三个设计选择:前缀选择是否应该适应每条轨迹,差异应该是有符号还是无符号,以及加权项是否应该替换 OPD 或在其上分配额外预算。
表:不同变体的 AIME25 相对于 OPD 的提升。
| Variant | AIME25 | Delta vs. OPD |
|---|---|---|
| Standard OPD | 43.3 | 0.0 |
| Amplify fixed prefix | 43.7 | +0.4 |
| Manual curriculum | 44.8 | +1.5 |
| Cumulative-share (ours) | 48.9 | +5.6 |
| Signed accumulated discrepancy | 45.9 | +2.6 |
| Unsigned accumulated discrepancy | 48.9 | +5.6 |
| Ideal weight only | 42.1 | -1.2 |
| Ideal weight with OPD blend | 43.9 | +0.6 |
| Surrogate weight only | 46.2 | +2.9 |
| Surrogate with OPD blend | 48.9 | +5.6 |
固定前缀基线表明 IW-OPD 不仅仅是早期 tokens 的硬编码偏好。手工设计的课程帮助有限。更强的结果来自于将边界适应每条轨迹自己的差异轨迹。
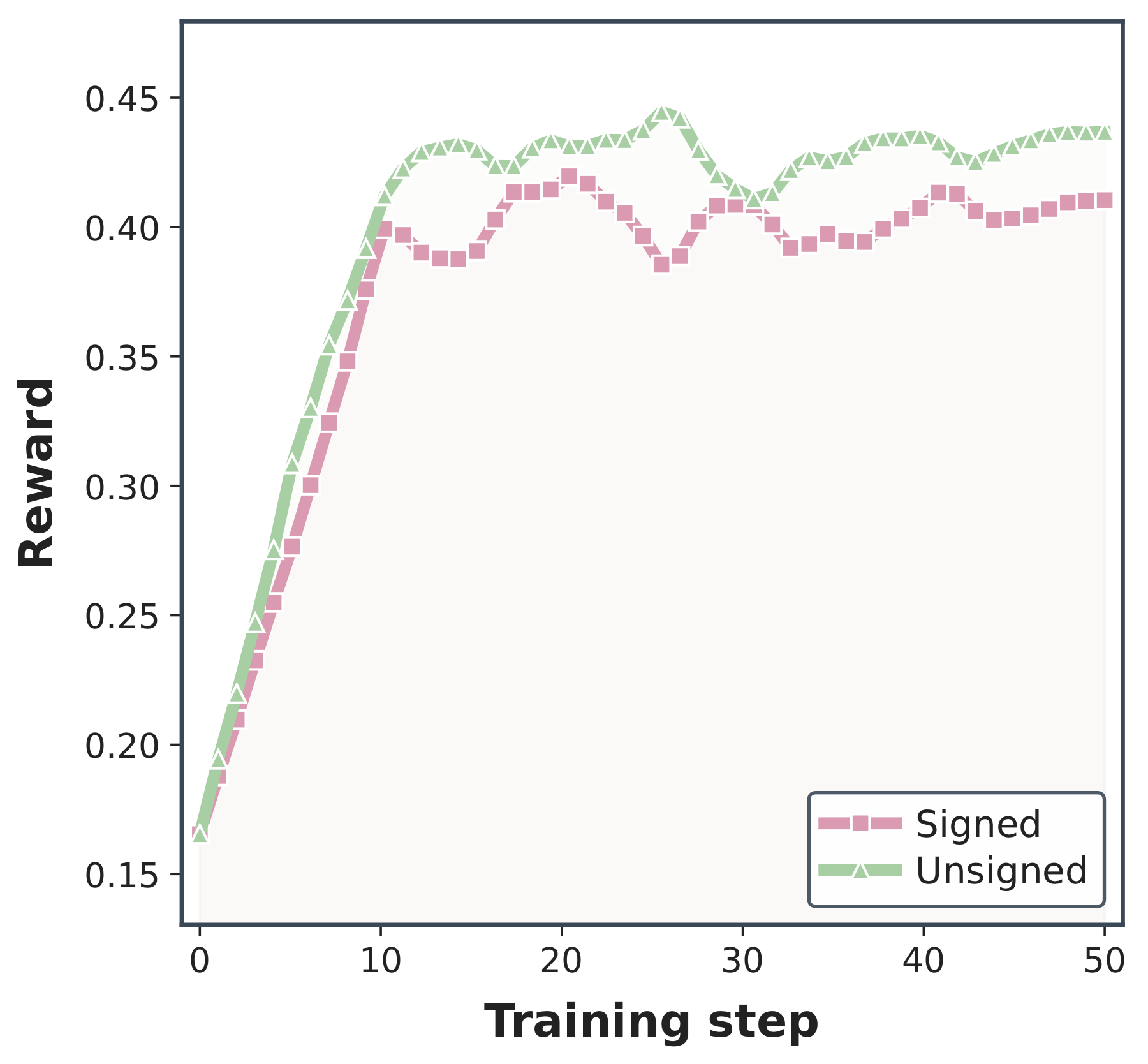
有符号与无符号的比较显示了为什么取消很重要。如果学生和教师沿着前缀在两个方向上都不一致,有符号和可能使前缀看起来不那么漂移。无符号统计量将每次不一致视为前缀已远离共享区域的证据。
最后一组显示了为什么我们将 OPD 保持为底限。实用代理作为标准 OPD 上的额外预算效果最好,而不是作为密集监督的替代品。
十、讨论
我们的工作与 OPD 方法如 GKD 和 MiniLLM 相关,以及与监督学生访问状态的实用方案(如 Thinking Machines Lab post)相关。它还与 token 选择性和课程蒸馏有关,包括 token 级自适应训练和 token 级课程学习,这些方法询问哪些示例或 tokens 值得更多权重。区别在于我们专门关注学生自己的长推理 rollouts 内部的不对称位置偏差:即使在单个响应内,早期和晚期 tokens 也可能不是同等有用的监督目标。
这项工作的关键见解是 OPD 监督在学生生成的轨迹上并非均匀可靠。这创造了一种不对称的位置偏差:教师监督在 rollouts 靠近开始处往往比靠近结尾处更有用。这种偏差并非 OPD 独有。它也可能出现在涉及两个自回归序列模型的许多方法中,例如从当前策略采样但向新策略更新的在线策略强化学习。这个问题在 OPD 中特别明显,因为师生分布差距是事先未知的,因此我们无法预定义它们的轨迹在哪里保持兼容。
这也凸显了序列优化中更广泛的张力。许多理论目标在序列级自然定义,包括本文使用的约束投影视图。然而,在自回归模型中直接优化序列级目标往往不稳定。长轨迹的序列级似然比可能具有高方差。标准 OPD 已经通过忽略梯度的 return-to-go 部分在实践中使用 token 级代理。IW-OPD 遵循相同的理念。由于它需要估计前缀级序列差异,它使用更平滑的累积差异代理,而不是精确的似然比。如何稳定地估计和优化更忠实的序列级目标仍然是一个重要的开放问题。
十一、结论
主要教训是 OPD 的密集监督仍然存在分配问题。当学生采样自己的长 rollouts 时,后期的前缀可能偏离教师分布。然后均匀 token 加权将部分有限更新预算花在教师反馈不太可操作的环境中。
我们的有限预算视角将其转化为一个局部投影问题。可达的教师对齐目标通过教师-教师似然比对学生样本进行重加权,这自然地导致前缀重要性权重。IW-OPD 使用累积无符号前缀差异和 detached 额外预算乘数实现了这个想法的一个稳定版本。
该方法刻意很小:它使用与标准 OPD 相同的教师 log probabilities,只改变 token advantage 规模。在我们的实验中,这种分配变化改进了所报告的师生设置中的早期学习和最终性能。