
在人工智能的发展进程中,我们正见证从纯粹的聊天机器人向能够执行实际任务的计算机使用智能体(Computer-Use Agents) 的范式转移。

OpenClaw-RL 是第一个通过对话自动训练工业级 Agent 的强化学习(RL)库,旨在让模型在真实的交互中实现自我进化。
一、 核心理念:随处部署,从交互中学习

OpenClaw-RL 的核心在于将真实的交互转化为训练信号。
- 随处部署:用户可以将 OpenClaw 部署在笔记本电脑、私有服务器或云端。
- 自动进化:只要模型由 RL 服务器托管,它不仅会回应用户,还会持续收集轨迹、提取反馈并更新模型。
- 私密设计:由于支持全栈自托管,数据和优化闭环完全由用户的反馈驱动,保证了隐私性。
二、 异步架构:Slime 与 Tinker
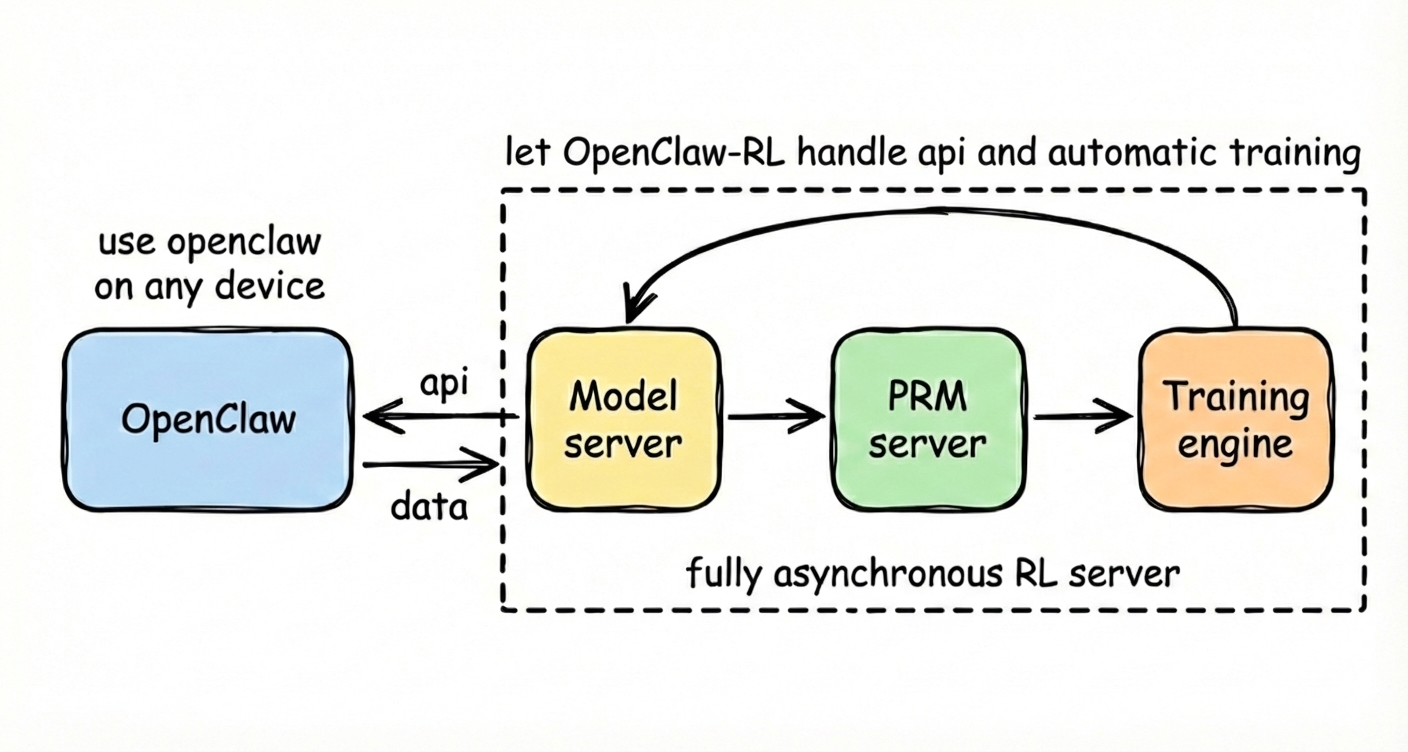
为了确保学习系统不影响产品响应速度,OpenClaw-RL 构建了一套全异步 RL 框架。
- 深度解耦:该框架将 OpenClaw 应用、策略推理、打分/判断模型(PRM/Judge)以及训练工人(Workers) 彻底分离,互不阻塞。
- 训推一体:采样(Rollout)、评分和梯度更新并发进行,保证了后台训练不会影响前台的模型推理响应。
- 灵活方案:针对“有卡没钱”的用户,支持基于 Slime 的异步框架;针对“有钱没卡”的用户,支持 Tinker 的自动部署。
三、 优化算法:Hybrid RL 的双重驱动
OpenClaw-RL 提出了一种**混合强化学习(Hybrid RL)方法,结合了 GRPO 和在线蒸馏(On-policy Distillation, OPD)**的优势。
1. 二元奖励(Binary Reward):提供覆盖度
该方法将自然产生的用户或环境反馈转化为标量奖励 r \in \{-1, 0, +1\}。
- 特点:极易收集,无需人工标注即可提供密集监督。
- 局限:信号较粗糙,只能告诉模型好坏,不能指明改进方向。
2. 在线蒸馏与事后提示(OPD with Hindsight Hints):提供精确度
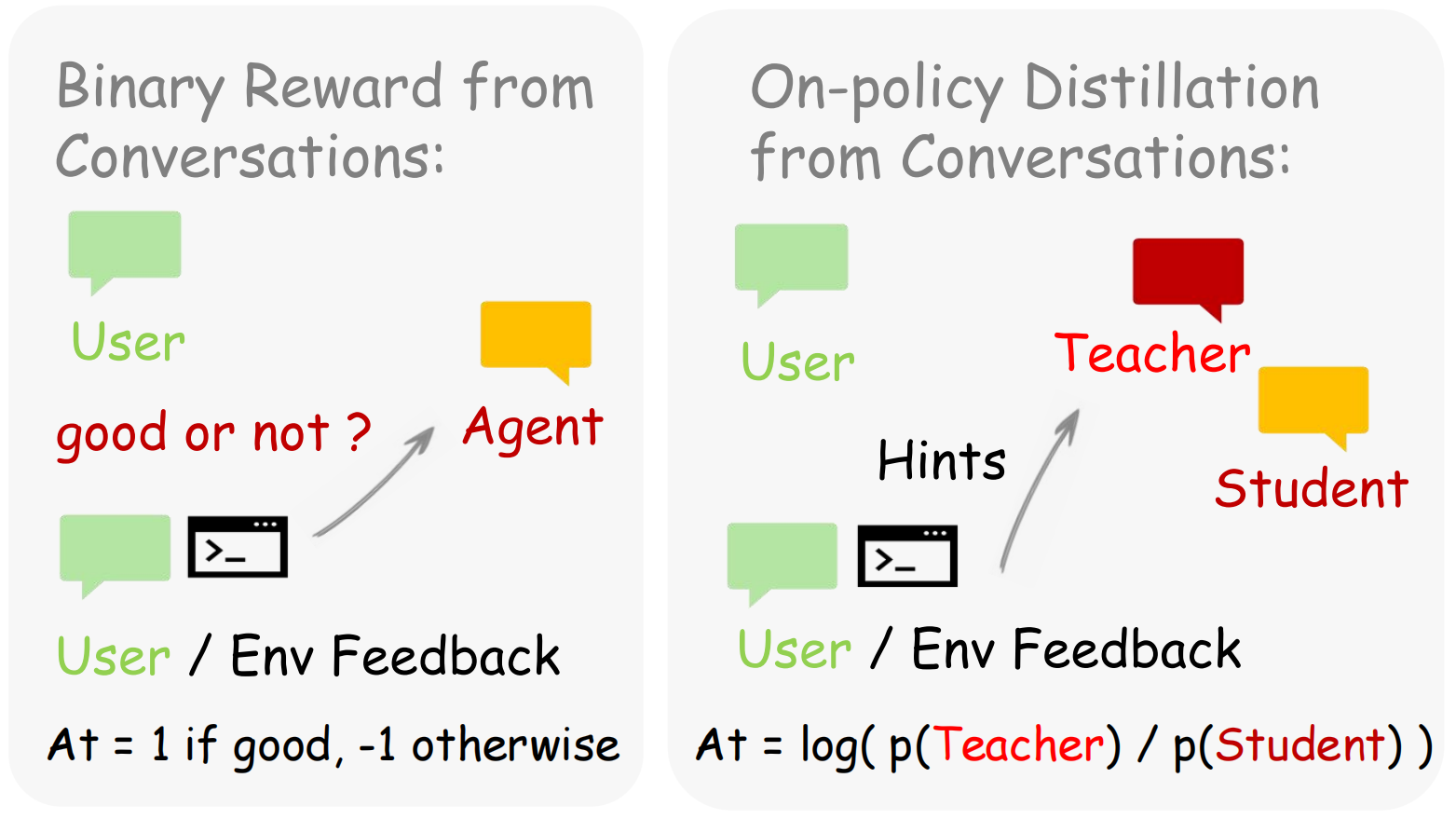
判断模型会从下一个状态中提取文本形式的事后提示(Textual Hindsight Hints)。
- 机制:将描述模型应如何改进的简短提示附加到原始 Prompt 中,形成教师分布,引导学生模型学习。
- 优势:信号更丰富且具方向性,能实现 Token 级别的定向引导。
3. 实验证明:1 + 1 > 2

实验显示,二元 RL 提供覆盖度(Coverage),而 OPD 提供精确度(Precision)。
- 仅二元 RL:16步更新后评分仅为 0.23。
- 仅 OPD:16步后达到 0.72。
- 混合方法(Combined):兼具早期覆盖与后期精确引导,评分高达 0.81。
四、 通用智能体 track:迈向真实生产力
除了个人助手优化,OpenClaw-RL 还支持大规模可扩展的 Computer-Use Agent 基础设施。
1. 四大真实应用场景
- 终端智能体(Terminal):读取文件、执行命令,涵盖 DevOps 和数据处理流。
- GUI 智能体:通过浏览器、视觉布局进行交互,像人类一样使用电脑。
- 软件工程智能体(SWE):在代码仓库上运行,实现诊断、编辑和验证的闭环。
- 工具调用智能体(Tool-call):依靠 API 访问和计算扩展能力。
2. 集成奖励(Integrated Reward)
针对长时程(Long-horizon)任务,OpenClaw-RL 引入了集成奖励,公式为:
R_t = O_{\tau} + \frac{1}{m} \sum_{i=1}^m r_t^{(i)}。
它将最终的**结果监督(Outcome)与分步的过程奖励(Process)**相结合,让每一步都能获得局部进度信息。实验证明,这种方式在工具调用(0.30 vs 0.17)等场景中显著优于仅使用结果奖励。
五、 未来路线图
OpenClaw-RL 的长期目标是推进个性化且实战有用的智能体。
- 个人智能体路径:深化从个体用户交互模式中学习的能力,提升推理效率。
- 通用智能体路径:扩展到更广泛的能动强化学习(Agentic RL)基础设施。
论文:OpenClaw-RL: Train Any Agent Simply by Talking
链接:https://arxiv.org/abs/2603.10165
代码:https://github.com/Gen-Verse/OpenClaw-RL
3月31日(周二)晚8点,青稞Talk 第117期,芝加哥大学博士生王胤杰,将直播分享《OpenClaw-RL: 结合 GRPO + OPD,在使用中自适应变强的龙虾》。
分享嘉宾
王胤杰,芝加哥大学二年级博士生,近期在普林斯顿大学 AI Lab 实习,曾毕业于中国科学技术大学少年班学院。我的研究方向聚焦于大语言模型、智能体及其强化学习方法。开源代表作涵盖了不同应用场景的强化学习框架,包括面向智能体的 OpenClaw-RL和RLAnything,代码生成框架 CURE,以及扩散语言模型强化学习框架 dLLM-RL。我的第一作者论文发表于 NeurIPS、ICLR 等国际会议,并在 NeurIPS 2025 获得 Spotlight。
主题提纲
OpenClaw-RL: 结合 GRPO + OPD,在使用中自适应变强的龙虾
1、OpenClaw 架构拆解
2、LLM + RL 的痛点,为什么你的龙虾“越用越笨”?
3、OpenClaw-RL:GRPO + OPD,在交互中持续优化
4、系统工程现实及实验评估
5、AMA (Ask Me Anything)
直播时间
3月31日(周二)20:00 - 21:00