痛点与破局
RL 训练过的人都知道那种感觉——跑了三天 GRPO,token 消耗是 SFT 的十几倍,最后一看提升,几乎为零。
问题出在哪?Reward 信号太稀疏,credit assignment 做不到 token 级,rollout 全错时梯度直接归零。
但 SFT 也有自己的软肋:推理时遇到没见过的分布,模型容易"自信爆棚",错得离谱。
2025 年下旬,Thinking Machines Lab 给出了一个折中方案——On-Policy Distillation。学生在自己的轨迹上接受 teacher 的分布监督,既保留了 on-policy 的零 exposure bias,又多了 token 级的密集信号。
这个思路出来后,社区迅速跟进。近半年有 9 篇工作值得关注,大致可以分成三个方向。
一:让训练更稳定
这一派的核心问题是:on-policy distillation 动不动就训练崩溃,怎么修?
Veto:用几何空间解决崩溃问题
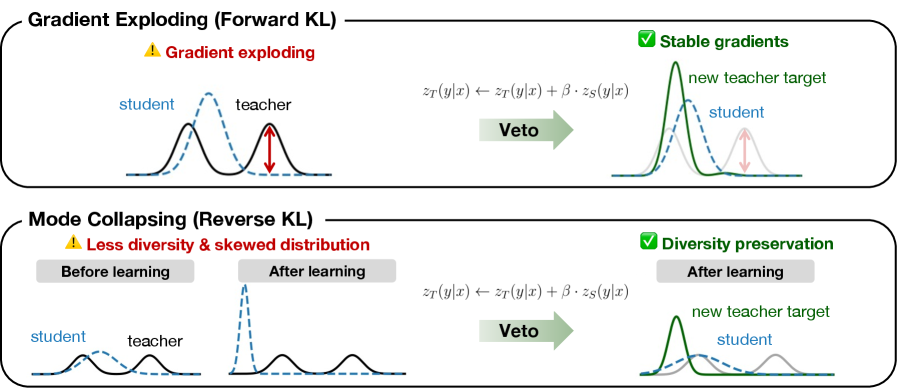
论文:Stable On-Policy Distillation through Adaptive Target Reformulation
链接:https://arxiv.org/abs/2601.07155
标准做法是用 KL 散度来衡量 student 和 teacher 的差距,但两个极端都很麻烦:
- Forward KL:梯度在"学生无知、老师自信"的位置爆炸,量级冲到 10⁶,训练秒崩
- Reverse KL:mode-seeking,只学老师最确定的那条路,多样性归零
Veto 的做法很巧妙——不在数据层 mixing,而是在 logit 空间里做插值。用一个参数 α 在 teacher 和 student 之间做几何平均,作为新的优化目标:
这个 α 其实是个旋钮。在 forward KL 场景下压制梯度爆炸,在 reverse KL 场景下控制熵正则强度,在"学得像"和"学得多"之间找平衡。
核心结论:训练不稳定的根因不在数据质量,而在于散度目标本身的几何特性。改一个参数,两种问题同时消解。
EOPD:高熵位置额外加 Forward KL
论文:Entropy-Aware On-Policy Distillation of Language Models
链接:https://arxiv.org/pdf/2603.07079
EOPD 团队用 Qwen3-8B→1.7B 做蒸馏实验时发现,teacher 产生的 token 中有 18.5% 处于高熵区,但学生训练完后只保留了 6.8%。
高熵区恰是推理的关键分叉点——学生在这些位置坍缩,直接导致输出多样性骤降。
解法是按 token 级熵动态切换散度目标:
- 熵低 → 用 reverse KL,快速稳定
- 熵高 → 叠加 forward KL,保护 teacher 的分布形态
基准测试提升明显,且模型越大增益越高:
| 模型 | Avg@8 提升 | Pass@8 提升 |
|---|---|---|
| Qwen3-0.6B | +1.16 | +1.37 |
| Qwen3-1.7B | +0.99 | +2.39 |
| Qwen3-4B | +1.80 | +5.05 |
大模型在复杂任务上这个问题更严重,所以受益也更大。
REOPOLD:把 RL 的工程技巧搬进来


论文:Scaling Reasoning Efficiently via Relaxed On-Policy Distillation
链接:https://arxiv.org/pdf/2603.11137
这篇有两个贡献:一是证明了带 stop-gradient 的 on-policy distillation,在数学上等价于 on-policy policy gradient。也就是说,teacher-student 的 log-likelihood 比值天然就是 token 级 reward。
二是基于这个等价性,把 RL 里的成熟技巧搬了过来:
Reward clipping:不裁采样比,直接裁 reward 值本身,防止极端负值主导梯度。
熵引导采样:用 token 级熵做信息密度代理,只在熵排名 top-p% 的 token 上算梯度,低信息量位置直接跳过。
两阶段训练:前期模仿 SFT 行为鼓励探索,后期切到熵掩码聚焦高不确定性 token。
效果:AIME-25 上 Pass@1 约 32–34%,样本效率比 ProRL、Still-3-1.5B 等方法高 6.7–12 倍。
二:自己当自己的老师
前面总需要一个更强的外部 teacher。这四篇换了条路:用模型自身做 teacher,通过注入特权信息构造监督信号。
OPSD:同一模型,加个答案就变 teacher

论文:Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
链接:https://arxiv.org/pdf/2601.18734
核心观察:当模型"看到"正确答案时,它能倒推出高质量的推理过程。利用这个特性可以做角色分离:
- Teacher:同一模型,条件是"问题 + 正确答案"
- Student:同一模型,条件只有问题
两者在 student 自己采样的轨迹上做 KL 散度最小化。
关键是效率:OPSD 把生成长度上限设为 1,024 tokens,GRPO 用的是 16,384。结果两者精度持平,但 OPSD 的 token 消耗只有 GRPO 的 1/8 到 1/12。
| 属性 | SFT | GRPO | OPSD |
|---|---|---|---|
| On-policy | ✗ | ✓ | ✓ |
| 密集 token 级监督 | ✓ | ✗ | ✓ |
| 低采样成本 | ✓ | ✗ | ✓ |
| 不依赖外部 teacher | ✓ | ✓ | ✓ |
同时具备三个优点,GRPO 和 SFT 都做不到。
SDFT:自蒸馏做持续学习

论文:Self-Distillation Enables Continual Learning
链接:https://arxiv.org/abs/2601.19897
灾难性遗忘是 LLM 持续学习的老大难问题。RL 需要显式 reward,SFT 本身是 off-policy 的,遗忘严重。
SDFT 把专家示例变成 in-context 特权信息,让模型用 ICL 能力构造 on-policy 学习信号:
- Teacher:见过示例后的条件分布
- Student:没见过示例的基础分布
数学上可以证明这等价于隐式 IRL——reward 被编码在 teacher 的 log probability 里,不需要单独训练 reward 模型。
实验设计是依次训三个任务:工具使用 → 科学问答 → 医疗问答。结果 SFT 每次学新任务就忘掉旧的,SDFT 三个任务训完后性能基本不下降。
SDPO:环境反馈本身就是信号
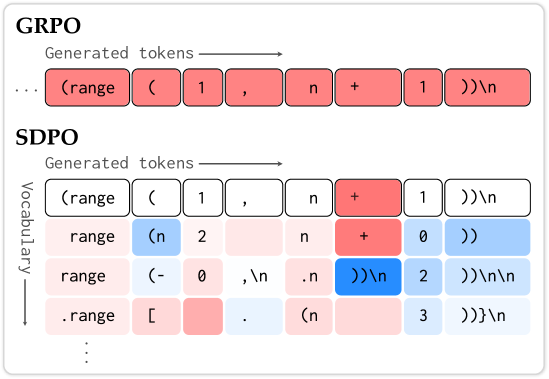
论文:Reinforcement Learning via Self-Distillation
链接:https://arxiv.org/abs/2601.20802
GRPO 只用一个标量 reward(0/1),代码报错的一大段文字信息全丢了。
SDPO 的做法:让模型看到错误反馈后,重新评估自己之前的输出。
- Student:原始生成 πθ(a|s)
- Self-teacher:看到反馈 f 后重新打分 πφ(a|s,f)
每个 token 的 advantage 就是这两个分布的 log prob 差值。额外开销只有 +5.8%(重算 log prob,不重新生成)。
最终效果:
- 达到同等精度需要的生成次数减少 4 倍
- Olmo3-7B 在化学任务上,30 分钟达到 GRPO 5 小时的水平
- 回答长度比 GRPO 短 3–7 倍,精度还更高
OPSDC:想得越多错得越多,压缩反而提升精度
论文:On-Policy Self-Distillation for Reasoning Compression
链接:https://arxiv.org/abs/2603.05433
反直觉的一幕:o1、DeepSeek-R1、Qwen3 这些模型在简单问题上也会生成几千 token 的内部独白。大量 token 是不必要的,更糟糕的是——它们还是错误的来源。
论文证明,把推理链从 n 压缩到 m 个 token,准确率提升比例与 (n/m)² 成正比,是指数级改善。
OPSDC 不需要正确答案也不需要 reward,只需要一个"请简洁"的指令。Teacher 是带指令的同一模型,Student 是不带指令的版本。每隔 K 步同步一次权重,渐进压缩。
实验结果:
- 30K token 预算下,推理 token 减少 40–58%,准确率反而高了 10–16 个百分点
- 自适应压缩:简单题压缩 56–58%,难题只压 35%——模型自己判断该用多少力
三:从文本延伸到更多场景
OPCD:把 prompt 里的人类经验烧进模型参数

论文:On-Policy Context Distillation for Language Models
链接:https://arxiv.org/abs/2602.12275
很多人花大量时间做 prompt engineering,或者积累了一批高质量的历史解题记录。问题是这些信息只存在于 context 里,一旦清空就没了。
Context Distillation 想做的事:把这些信息永久写入模型参数。
之前 off-policy 的方案有两个问题:exposure bias(训练和推理分布不一致)和 forward KL 的幻觉问题。
OPCD 用 on-policy 方式解决:student 生成轨迹,teacher 带着 context 在这条轨迹上评分,用 reverse KL 更新。
跨尺寸蒸馏的结果很有意思:直接把 8B 的经验注入 1.7B/4B 的 context 里,性能反而下降;但用 OPCD 把 8B 经验蒸馏进参数,显著提升。
| 模型 | 基线 | In-Context | Off-Policy CD | OPCD |
|---|---|---|---|---|
| Llama-3.1-8B-Instruct | 68.4% | 72.2% | 75.2% | 76.7% |
| Qwen2.5-7B-Instruct | 46.4% | 52.6% | 58.5% | 62.3% |
某些情况下甚至超过了 in-context 本身。
Video-OPD:视频时序定位任务上的 on-policy distillation

论文:Video-OPD: Efficient Post-Training of Multimodal Large Language Models for Temporal Video Grounding via On-Policy Distillation
链接:https://arxiv.org/abs/2602.02994
Temporal Video Grounding(TVG)任务:给视频和自然语言问题,输出时间段 [t_start, t_end]。
GRPO 在这任务上有两个短板:每条轨迹只有一个 0/1 reward,信号极度稀疏;多 rollout 带来的视觉上下文计算成本很高。
Video-OPD 用 32B teacher 对 8B student 做 token 级评分。每个 token 的 reward 考虑正确性和时序邻近性。Teacher 只评分不生成,保证 on-policy 特性。
加上两个训练策略:
- TRPV:用 ground-truth IoU 过滤 teacher 不可靠的预测
- DBTP:优先训练 teacher-student 分歧最大的样本
| Benchmark | GRPO | Video-OPD |
|---|---|---|
| Charades-TimeLens | 27.6 | 32.4 |
| ActivityNet-TimeLens | 32.1 | 35.8 |
| QVHighlights-TimeLens | 41.5 | 50.4 |
平均提升 17%,在精细时间对齐上增益最大。超过了 GPT-4o、GPT-5、Gemini-2.0-Flash,接近 Gemini-2.5-Flash。
写在最后
on-policy distillation 解决的是一道经典难题:如何同时获得 RL 的零 exposure bias 和 SFT 的密集监督。
落地速度比想象中快。小米的 MiMo 系列、Hugging Face 的"Unlocking On-Policy Distillation for Any Model Family",都已经在用了。
趋势很明显:更强的 teacher、更低的算力门槛、自蒸馏不需要外部模型。这个方法后续会越来越实用。