一、 引言:大模型强化学习算法的演化格局
近年来,以 OpenAI 的 o1 系列、DeepSeek 的 R1,以及 Qwen 系列模型为代表,大语言模型在数学证明、代码生成等长链路推理任务中展现出更强的稳定性与推理深度。
在这一背景下,面向大语言模型的强化学习(RL for LLMs, RL4LLM)逐步成为后训练对齐阶段的核心技术路径。
相较于早期主要依赖监督微调或直接偏好优化(DPO)的方案,RL4LLM 通过直接围绕结果正确性或任务完成质量构建优化目标,能够提供更贴近最终能力表现的训练信号,并被广泛认为与思维链推理能力的形成密切相关。
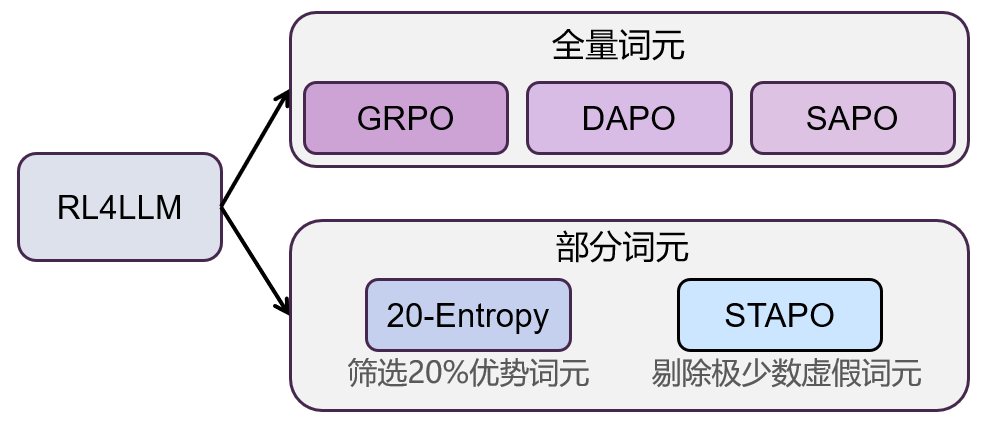
在以GRPO为代表的策略梯度方法奠定技术基础后,围绕 大模型强化学习的方法逐步展开并形成清晰的演进路径。为了更系统地梳理这一脉络,本文采用“参与优化的词元范围”作为划分视角:
一类方法对生成序列中的全部词元进行优化,强调全局一致性建模;
另一类方法仅利用筛选词元的优化信号,以降低干扰并提升训练稳定性。
依据这一标准,现有方法可概括为“全量词元优化(Full-Token)”与“部分词元优化(Partial-Token)”两大方向。
演化路径
为了方便后续公式的理解,我们在此统一全局符号:
- x 为输入的问题或提示(Prompt)。
- y_i 为模型生成的第 i 个回复序列,|y_i| 为其长度。
- y_{i,t} 为第 i 个回复中的第 t 个词元(Token)。
- \pi_\theta 与 \pi_{\theta_{\text{old}}} 分别表示当前策略与旧策略。
- \rho_{i,t}(\theta) = \frac{\pi_\theta(y_{i,t}|x, y_{i,<t})}{\pi_{\theta_{\text{old}}}(y_{i,t}|x, y_{i,<t})} 表示新旧策略生成该词元的概率比值。
- \hat{A}_i 表示序列级别的优势函数(Advantage)。
- G 表示针对同一输入进行组采样时得到的候选回复数量。
- \epsilon(以及后文的 \epsilon_{\text{low}}, \epsilon_{\text{high}})表示策略更新中的裁剪阈值。
二、 全量词元的迭代与打磨
全量词元优化的核心逻辑是 “利用所有输出词元” 进行策略更新。这一路线以 GRPO 为代表性起点,逐步演进至 DAPO、GSPO 与 SAPO,整体目标是在保证优化强度的同时持续提升训练效率与梯度稳定性。
1. GRPO(轻量化破局)
GRPO示意图
论文:DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
链接:https://arxiv.org/abs/2402.03300
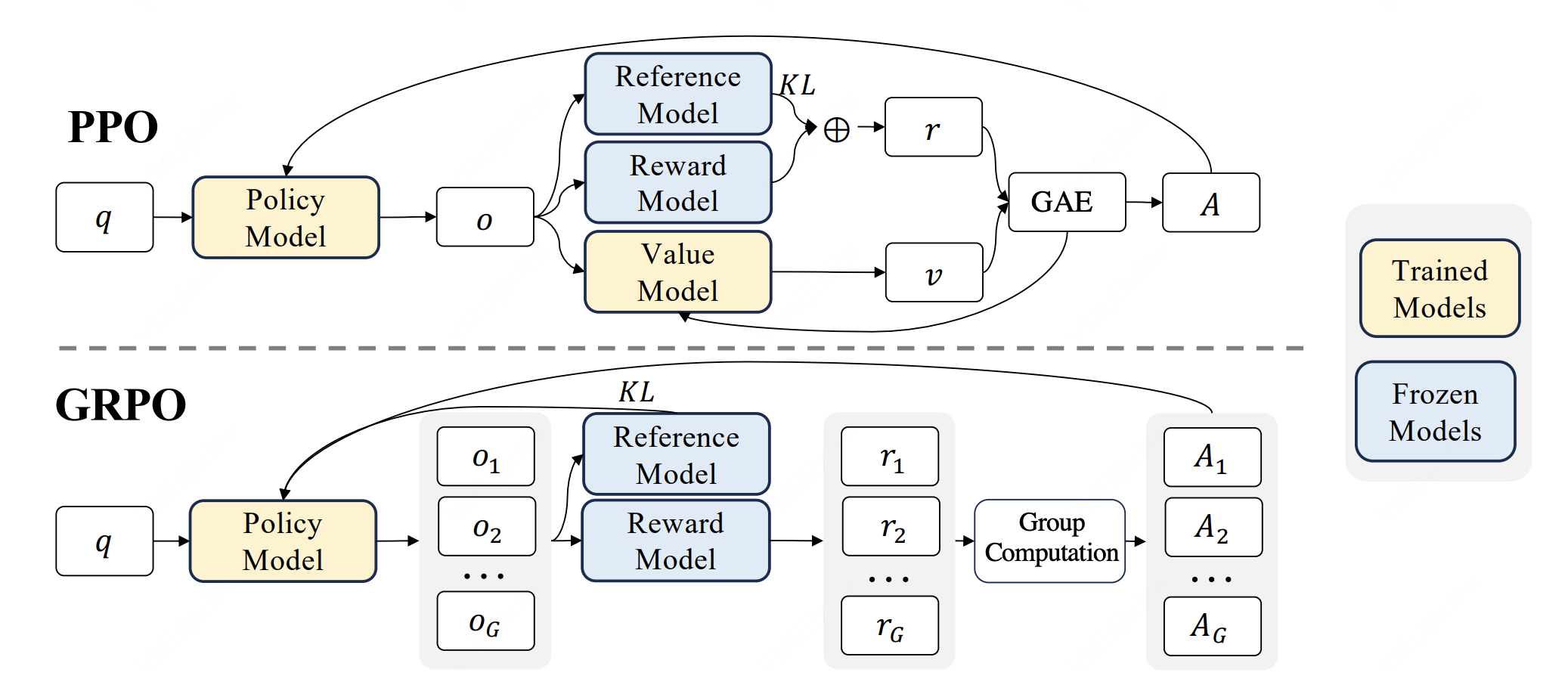
简介:GRPO 是当前极具代表性的破局者。自算法问世以来,受到了国内外大量的关注。
核心创新点 :以往大模型在强化微调时需要额外的网络进行价值或奖励的评估,而该算法采用组采样(Group Sampling)机制和规则的奖励函数,最核心的贡献在于去掉了传统的 Critic 模型,大幅降低了显存占用。
优化目标:
该算法的代价是好坏样本的覆盖极度依赖 Rollout 阶段的组内采样数量 G,采样效率较低,整体训练震荡不稳定,。
2. DAPO(策略精细化)
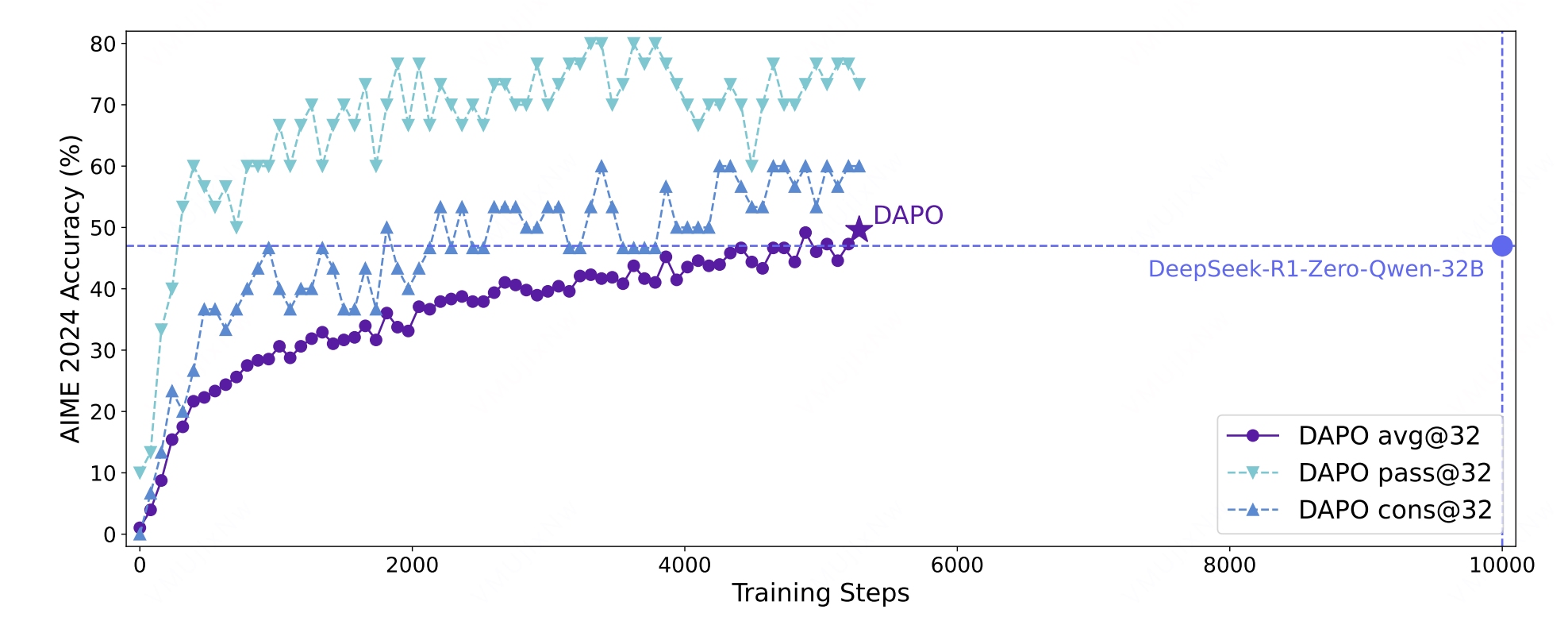
DAPO效果图
论文:DAPO: An Open-Source LLM Reinforcement Learning System at Scale
链接:https://arxiv.org/abs/2503.14476
简介:DAPO 在 GRPO 的基础上进行了多维度的精细化改良,从三个方面对GRPO进行了改进。
核心创新点:算法引入了全局 token 系数进行归一化,稳定了因组内长度差异带来的梯度波动,并采用了非对称裁剪(\epsilon_{\text{low}} 与 \epsilon_{\text{high}})克服训练过程中熵坍塌的现象,此外算法还采用动态采样(丢弃奖励值为全0或全1的无效样本)提升效率,并加入了对输出长度的软惩罚机制。
优化目标:
3. GSPO(序列级视角)
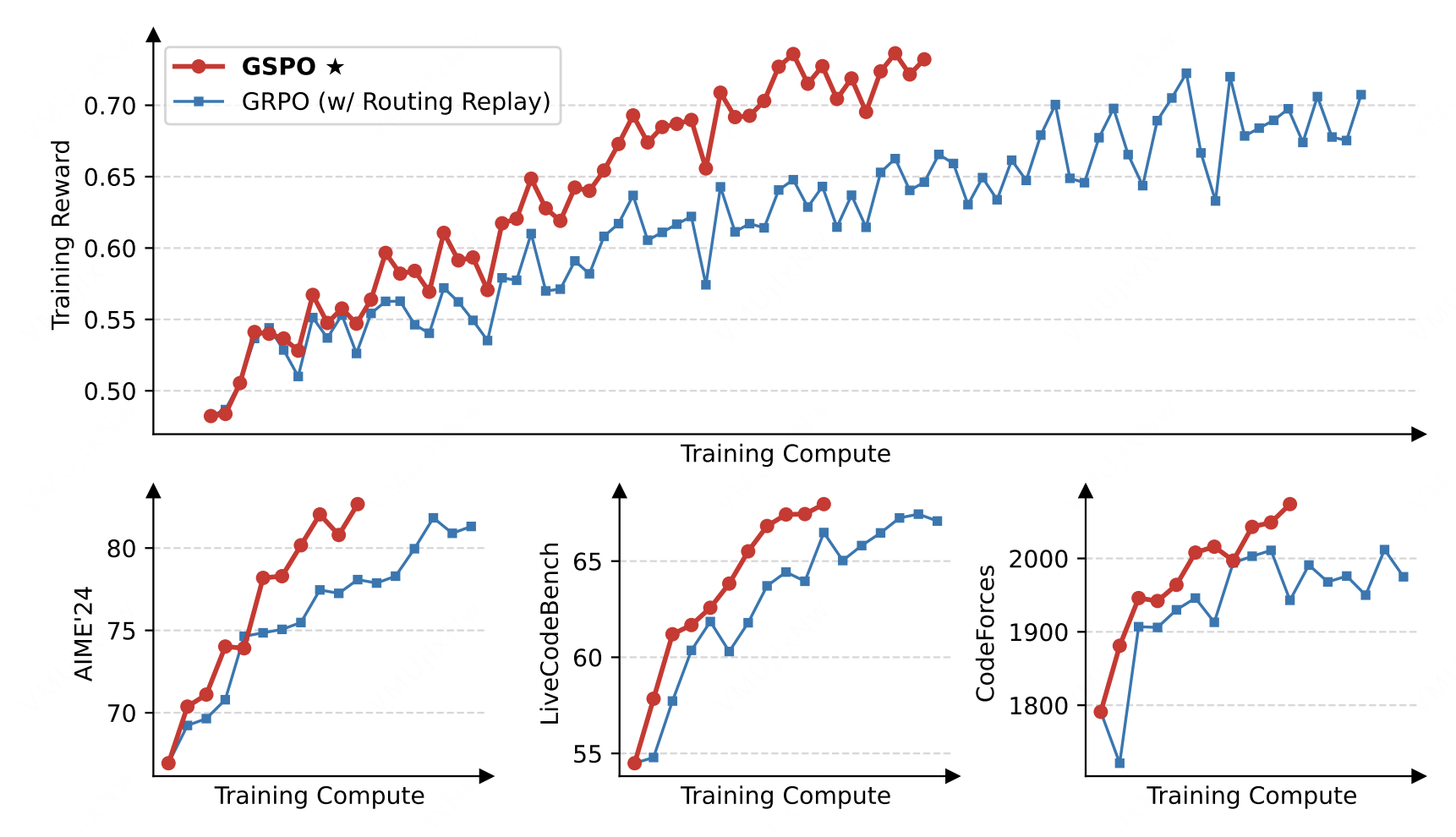
GSPO效果图
论文:Group Sequence Policy Optimization
链接:https://arxiv.org/abs/2507.18071
简介:GSPO算法主要针对MOE模型训推不一致的情况而进行的改进。
核心创新点:GSPO 的改进聚焦于重要性采样系数。它将token-level概率替换为整条句子的sequence-level概率,从而克服单个token造成的训练不稳定:
优化目标:据此,GSPO 可写为将原有 token 级比值 \rho_{i,t}(\theta) 替换为序列级比值 s_i(\theta) 的目标:
这一改进与预训练阶段困惑度(PPL)下降的趋势更一致,并能有效缓解 MoE 模型中 Rollout Engine 与 Model Engine 的专家路由不一致问题。
4. SAPO(软信任域)
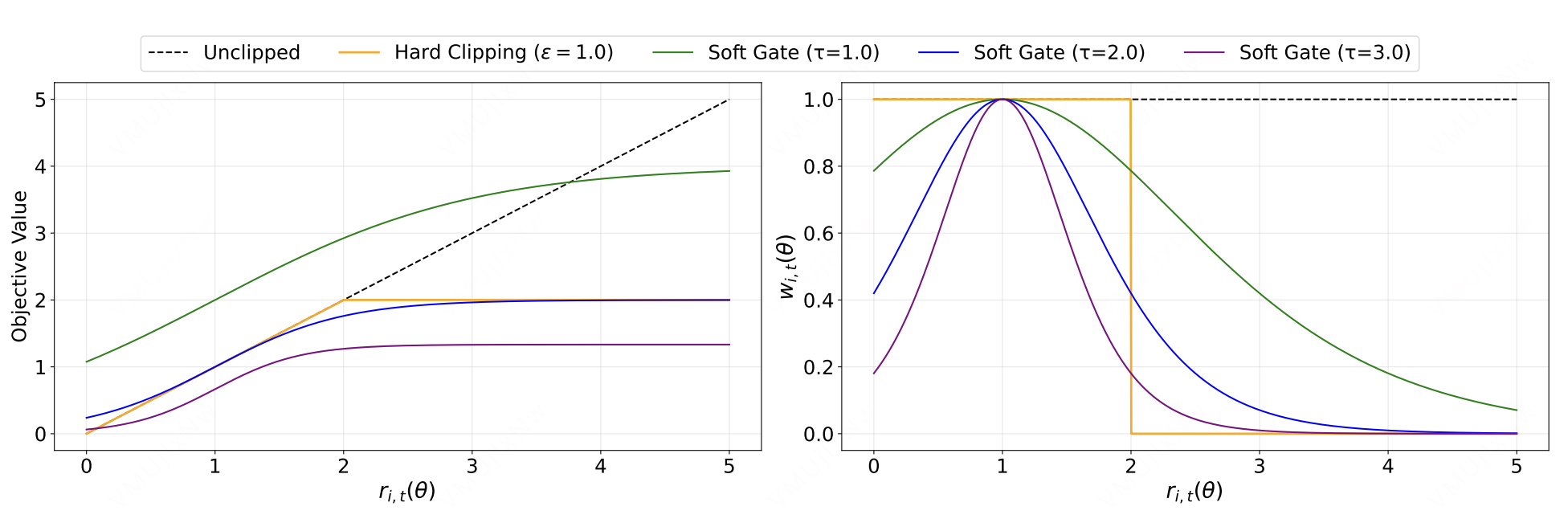
SAPO中软门控机制示意图
论文:Soft Adaptive Policy Optimization
链接:https://arxiv.org/abs/2511.20347
简介:SAPO通过修改Ratio的硬截断机制,平衡模型的利用和探索。
核心创新点:SAPO 摒弃了生硬的 Clip 截断操作,转而引入了 Token 级别的软信任区域(Soft Control):
其中通过为正负 token 设计非对称的温度参数(当优势大于0时使用 \tau_{\text{pos}},否则使用 \tau_{\text{neg}}),实现了颗粒度更细致的更新控制。
优化目标:
三、 部分词元的聚焦与筛选
虽然全量词元算法在不断打磨局部的平滑与稳定,但学术界开始思考一个本质问题:一条回复中的所有 token 都对策略更新同等重要吗?究竟哪些token对训练起到决定性作用?
实际上,许多基础的连接词提供的梯度信息极低,而某些看似合理实则致幻的 token 则会引入严重的破坏性噪声。这就催生了 部分词元优化(Partial-Token) 这一前沿分支,即不再让所有词元参与 Loss 计算,而是使用指示函数 \mathbb{I}[\cdot] 进行进一步筛选。
1. Beyond the 80/20(路径优化)
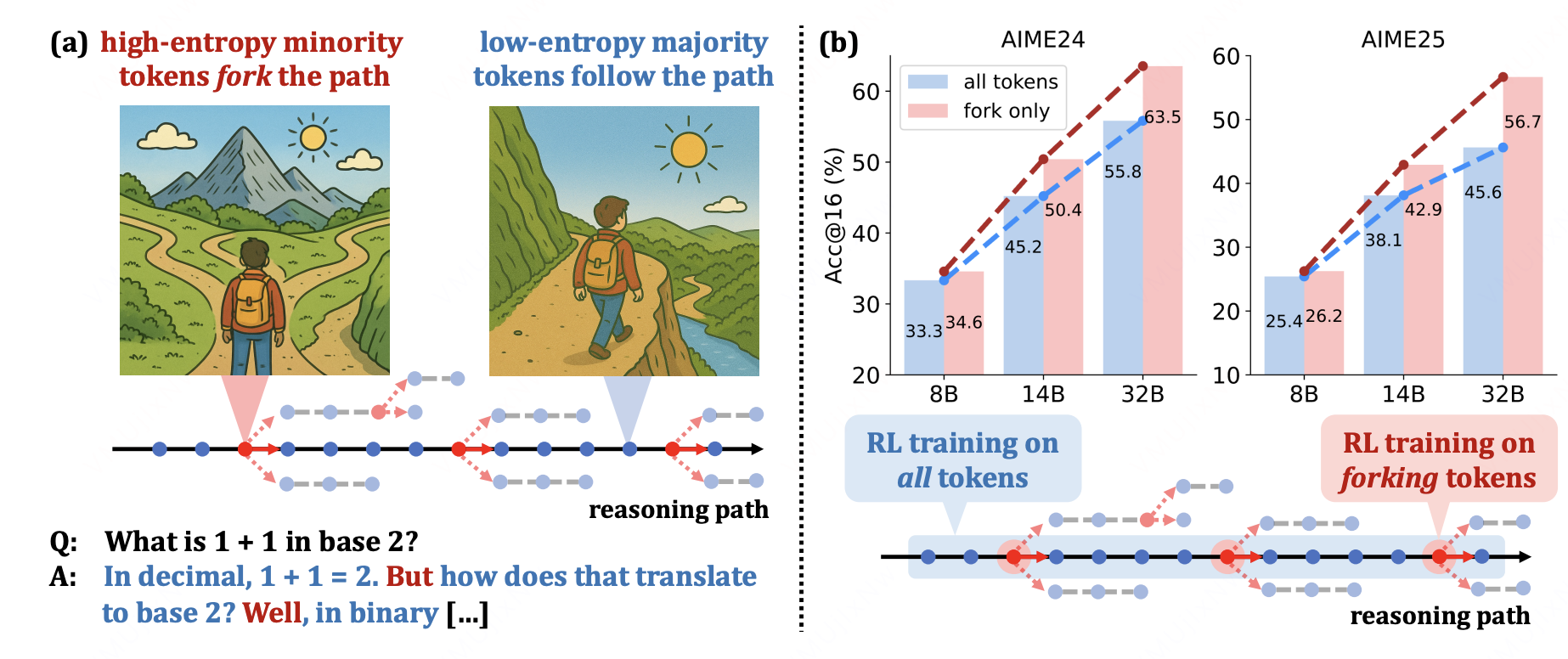
Beyond the 80/20示意图
论文:Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning
链接:https://arxiv.org/abs/2506.01939
简介:Beyond the 80/20(20-Entropy )的核心思想是“按信息量分配更新预算”,抛弃以往token全量参与训练的思想。
核心创新点:其创新点在于:并非所有词元都提供同等有效的学习信号,低信息量词元往往会稀释梯度。为此,该方法先计算词元熵 \mathcal{H}_{i,t},再通过阈值 \tau_\rho 构造筛选掩码,仅保留高熵词元参与策略更新。
优化目标:
这种“先筛选、后优化”的机制能够提升有效梯度密度,将训练算力集中到对生成质量影响更大的关键位置,从而在相同预算下获得更稳定的优化信号。
2. STAPO(去伪存真)
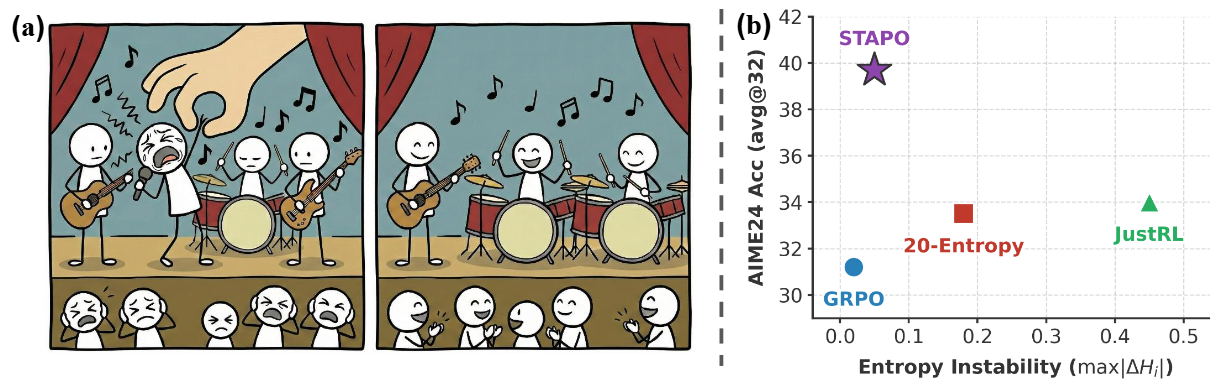
STAPO示意图
论文:STAPO: Stabilizing Reinforcement Learning for LLMs by Silencing Rare Spurious Tokens
链接:https://arxiv.org/abs/2602.15620
简介:相较于单纯只关注高熵优势词元,清华大学团队最新工作——STAPO 走了一条更为巧妙且精准的路线。它的核心在于:剔除极少数会导致训练崩溃的虚假词元(Spurious Tokens),只去除0.01%的token就能取得SOTA的效果。
核心创新:STAPO 首次明确提出“虚假词元”概念:虽然最终奖励为正(会被进一步强化),但梯度范数大,低熵低概率的有害词元。STAPO因此提出了虚假词元剔除机制(Silencing Spurious Tokens, S2T):
其中,\tau_p 与 \tau_h 分别为概率阈值和熵阈值。该判据对应“低概率 + 低熵 + 正优势”三元条件:当序列整体是正确回答但局部词元同时落入低概率(偶然)、低熵(高度自信)区域时,S2T 将其视为潜在虚假词元并置零,以避免其主导后续梯度更新。
优化目标:
这篇新工作给我们的启示是STAPO 就像一把精准的手术刀,在不破坏句子整体连贯性的前提下,精准剥离极少数的虚假词元(仅0.01%),实现了策略熵稳定性和收敛性能的综合提升,达到同类算法的SOTA性能。
四、 总结与展望
总体而言,RL4LLM 的方法演化正从“全量统一更新”走向“按词元贡献精细分配更新”的新阶段:
前者以 GRPO、DAPO、GSPO、SAPO 为代表,持续优化训练稳定性与效率;
后者以 20-Entropy 和 STAPO 为代表,通过对高价值词元的聚焦与对虚假词元的抑制,进一步提升了有效梯度密度、策略熵稳定性与收敛表现。
这种从“全量覆盖”向“精细筛选”的范式演进,正成为提升模型训练效率与逻辑推理连贯性的关键。