作者:董子斌
https://zhuanlan.zhihu.com/p/2006493733990981927
1. 主流 VLA 架构以及为什么我们需要 action tokenizer
不得不承认 physical intelligence 依旧是 VLA 实践灯塔之一,自从 \pi_{0.5} 和配套 Knowledge Isolation 的架构提出,各大厂和实验室推出新 VLA 模型也大差不差延续了这一经典范式——VLM 拼接 Action Expert,KV cache 传递 perception 信息。
打断补充:最近 NVIDIA 的 DreamZero 和蚂蚁的 Lingbot-VA 都在从 video generation model 出发探索新的架构可能性,这些都非常好,我都充满敬佩和好奇并且看好。但是本文让我们先暂时关注在 \pi_{0.5},不做其他讨论。
\pi_{0.5} 的出现很可能是因为大家都发现 diffusion models(或者严格来讲 flow-matching models)训练 objective 提供的监督信号太弱,很难将前端的 VLM 训好,导致很弱的指令跟随/图片理解能力。这一点在 \pi_{0.5} 前传之 Knowledge Isolation 和我上一篇工作 Cocos 都有讨论。
与之相对,遵循 VLM 原本自回归框架进行训练却很好地保留了 VLM 的先验知识,模型有更好的指令跟随表现,这一点在 VLA0 和 VLM2VLA 中都有讨论,我们在自己的真机实验中也发现自回归 VLA 充分训练后 zero-shot 表现确实会更好。
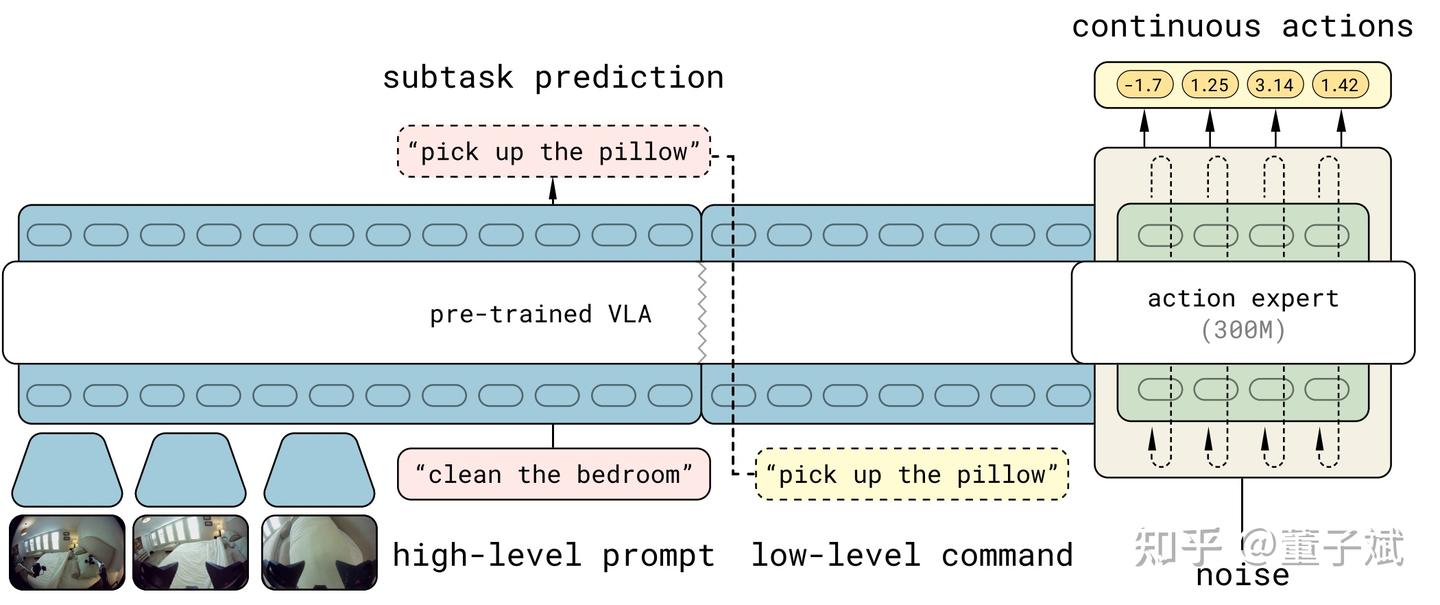
这是否说明我们要拥抱自回归范式呢?可能也很困难,自回归需要离散化,Token budget(一条动作序列所使用的 token 数量)越多,action 精度越高,但是自回归成本也越高,延迟增长;Token budget 越少,自回归成本越低,延迟降低,action 精度也下降。
所以 \pi_{0.5} 是一个很聪明的做法,action token 作为 VLM 的监督信号提高模型具身理解能力,diffusion loss 梯度不会流入 VLM 专注 action translation。
不知道大家最开始看 \pi_{0.5} 的时候有没有出现过这样的问题(很可能是没有的,我得承认这块是我自己愚笨了),为什么要让模型有两个预测 action 的出口,为什么要让 action token 之前的 KV cache 传递信息给 action expert。
我觉得这是一种极为关键的“分层”设计,我们可以这样看待问题:
- 动作空间是 \mathcal A,每一个连续的 action(后面均用 action 代指固定长度的 action chunk)A 被 tokenizer 编码成 token budget n 的 action tokens C
- 然后被有损解码回 \hat A,因为编解码损耗,可能所有子空间 \mathcal A_C 中的 A\in\mathcal A_C 都会被编码成相同的 C,解码出相同的 \hat A,那么实际上整个动作空间就被切分成一个个子空间 \mathcal A = \bigcup_{C_i} \mathcal A_{C_i}
- VLM 学习的 action tokens 构成的概率分布就是一个被“量化”的行为策略 P(\hat A)=\int_{\mathcal A_C}p(A){\rm d}A(严格来说应该是 condition 到 vision-language 上的条件分布,这里为了方便略去了)
- 当 VLM 被训练好之后,一旦 prefix 的视觉语言信息 (V,L) 被输入,策略分布 \pi(\hat A) 就已经被完全确定,自回归预测就是对该分布进行采样
- 得到的是 \hat A,diffusion model 做的事情就是 refine 这个“被量化”的分布
- 还原最初的动作分布 \mathcal A,denoise 得到的是 A。
这种意义上看 diffusion model 就已经完全是一个 translator 了。
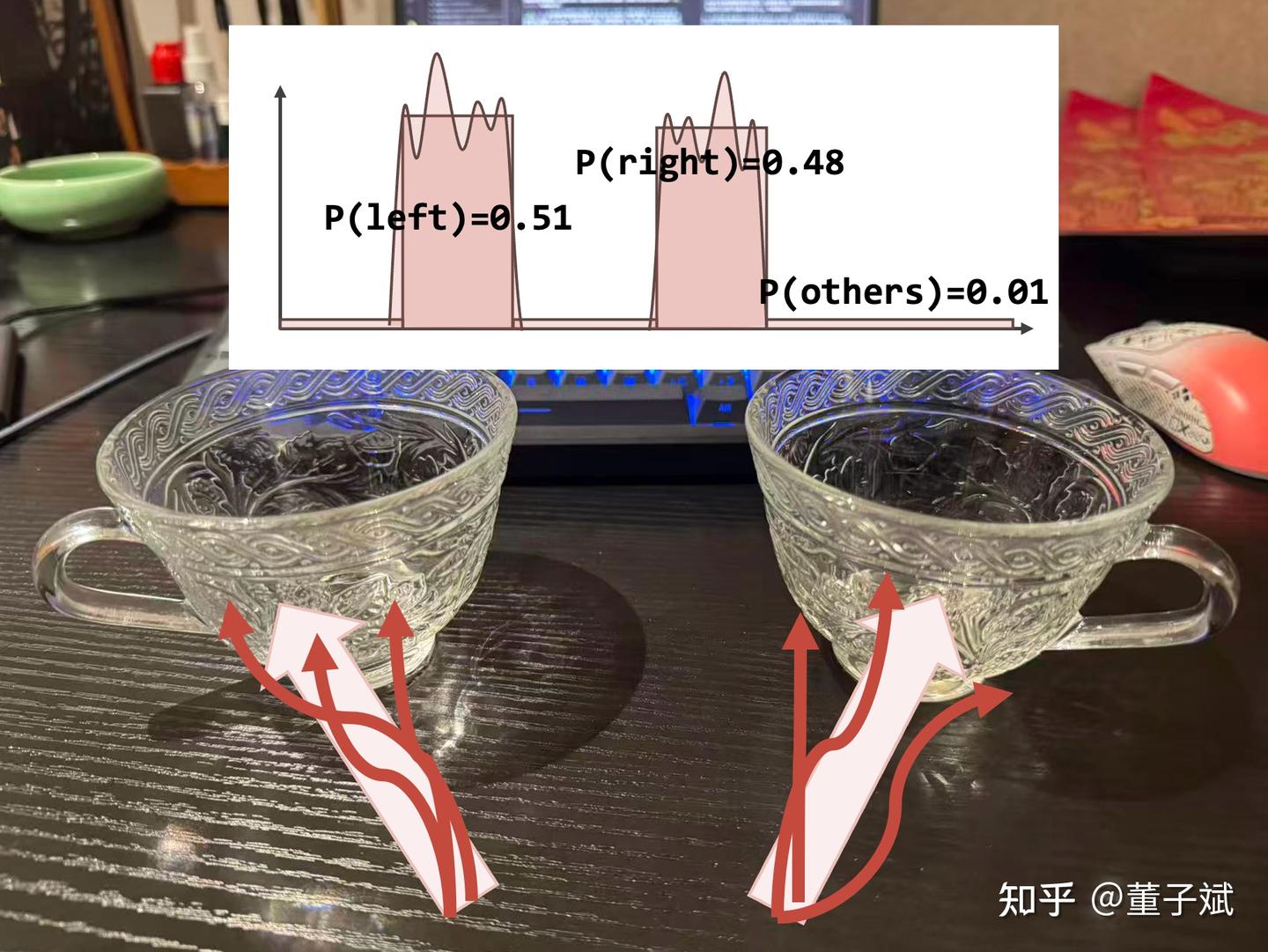
这个表述是为了准确描述我的观察角度,这里可以有一个更加直观的理想例子(上图,顺手拍的面前的玻璃杯)。
如果 VLA 训练极其理想,语言指令是抓住一只玻璃杯,那么有可能数据集中所有向左侧杯子伸手的动作都被分割到一个子空间,并且累积概率是 0.51。
所有向右侧杯子的被划分到一个子空间,累积概率 0.48,所有其他子空间的累积概率总共是 0.01,具体抓取的动作可能在数据集中存在一些噪声,或者操作手癖,呈现出多样的细微差异,因此实际上的行为策略分布应该是深色曲线包围的部分,这部分由 diffusion model 来负责建模。
于是对于 VLM 侧,他只需要学会根据视觉语言信息来找出 2 个占据绝大部分概率的 main parts,不需要建模复杂的多样化的控制信号,diffusion model 侧不需要深入理解视觉语言,根据分块的量化的概率分布 refine 出保真度更高的动作分布即可。
足够理想的情况两侧分而治之各司其职各显所长,自回归提供了充分的 VLM 监督信号,diffusion model 用 flow matching 和 多次 reflow 的加速技术提高动作采样效率,那么就把原先的矛盾解决掉了。
因此 action tokenizer 越来越重要,连 diffusion action expert 都在引入离散 action token 作为监督信号,而且 well-design 的 action tokenizer 能够对动作空间做更好的子空间划分,同时提高感知侧和动作生成侧的表现。
2. 几种 action tokenization 方式
现在的主流方式有哪些呢?我大致区分为非数据驱动类,半数据驱动类,和数据驱动类。
非数据驱动
最常用的是分 bin,将动作空间按照上下界均分切成 S 份,等价于量化;另一种是直接将 action chunk 用 Python list 表示,转化成 string,直接让 VLM “说” 出来。
这类方法没有注入任何或者相当少的先验知识,全靠 VLM 自己悟,最致命的是 token budget 相当高,当动作维度和 chunk size 稍微增加,就已经是无法承受的 latency。
半数据驱动
这里特指 FAST,我会认为主要方法是对 DCT 系数做量化,数据驱动只是发生在 BPE 这个锦上添花的压缩方法上,对于大部分其他的 tokenization 方式也可以额外套一个 BPE 进一步提高压缩率。
FAST 在实际使用时的槽点很多,例如需要精准预测才能正确解码等,但是表现效果相当稳健。
数据驱动
这里特指 VQ 类方案,基本就是对 action 数据训练了一个 VQ-VAE,目前这类方法的创新主要也都体现在把其他 VQ-VAE tricks 迁移到 action tokenization 上,并且大部分表现不佳。
3. 早期的探索与尝试
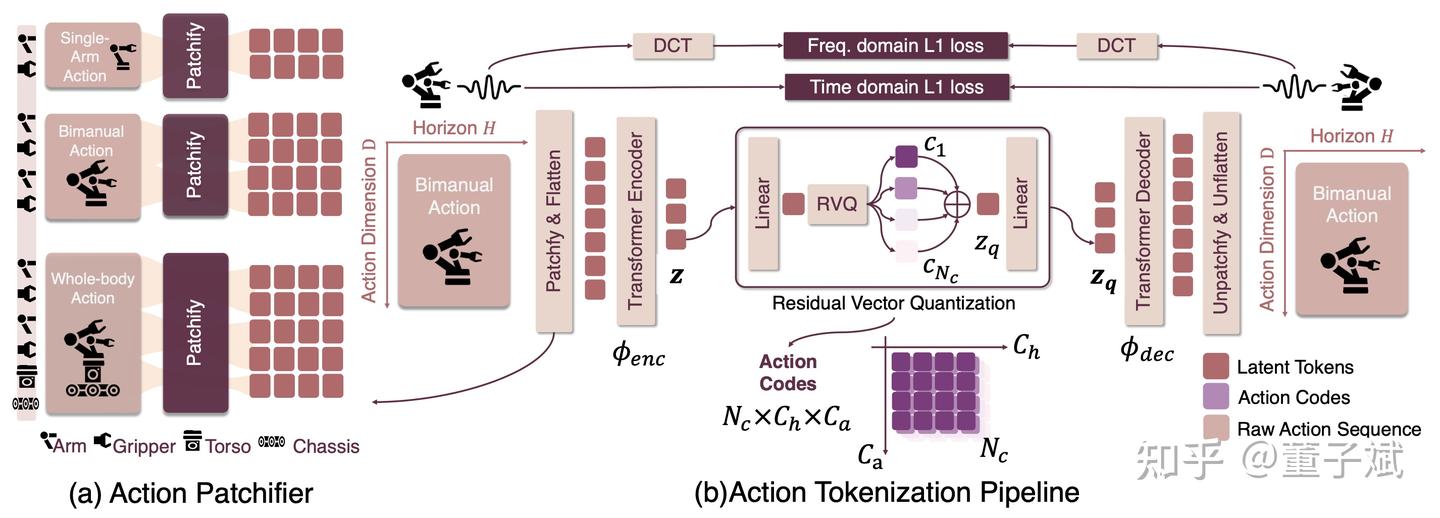
如果我们真的希望语义级别的子空间划分性能,那么数据驱动一定是最具潜力的,相对粗暴地将 VQ 类方案表现不佳的原因归咎于这些方法的 VQ model 设计得“太糙了”,于是有了在 FASTer 这篇工作中的初步尝试:
我们考虑到 action 不同维度的物理意义的异同关系,设计了 action patchifier 把 action chunk 打成一个个语义信息更合理的 patch;
我们 VLM 预测动作的时候遵循一种 course-to-fine 的方式,于是使用 Residual VQ(RVQ),以及低维投影 lookup,dead code 重置等等提高 codebook 利用率的方式;
我们希望模型在时域频域上都有很好的建模,于是同时优化时域和频域的 L1 loss。效果的确非常好,相比之前的 VQ 类方法有了质的飞跃,压缩率无与伦比,重建精度相当高。
但是就我个人而言反而是更加的迷茫,我还是无法回答 what makes for good action tokenizers,究竟应该如何设计 action tokenizer 呢?难道我们就是把前沿的 VQ 方法一个一个迁移到 action 上面调好超参就完了吗?
在那之后的探索几乎是根据结果反推设计的过程,我们反复观察 FAST 和 VQ models 在操作任务中的表现,分析性质,讨论哪些更合理,然后以此引导设计。结果仍然很迷茫,仿佛陷入了 VQ 设计的怪圈,提出的改进我们也不知道是否直接指向 VLA 性能,反而完全站在 VQ 的角度设计自编码器了。
事情的转机是某天我突然换了一个角度看待问题,如果我们站在 VLA 的角度思考问题呢?如果我不在乎 VQ model 还是什么别的,我就是要让 VLA 去预测一些 tokens C 呢?那么训练目标就是:
可以写成
于是问题就变成了我们要给 VLA 训练找一个代理目标(proxy target),VLA 明明需要学的是分布 P(A|V,L),我们非要给他替换成 P(C|V,L),C 由我们自己设计。
那么前提条件当然是 C 可以充分反映 A,这样 D_{KL}(P_{\text{data}} || P_{\theta}) 就是误差允许范围内的一个有效的对真实目标的近似,剩下的 H(C | V, L) 就给我们留下了操作空间。
这一项一直都被我忽略了,因为数据集一定下来,他就是个常量了,没有影响,但我们实际上在做训练以前的事儿,我们在“篡改”数据集,所以这一项实际是被 tokenizer 设计所掌控的,可以想象如果 H(C | V, L) 非常高(非常类似的视觉语言信息,对应的 token 缺变来变去),那么梯度反复拉扯,对训练效率是个很大的损害。
我们立即可以从这里入手,着手思考我们的 action tokenizer 应该如何设计了,为了避免陷入 VQ model 的怪圈,我们不以生成模型的指标作为衡量,直接拿它训练 VLA,具身 benchmark 成功率来比拼。

4. 三个角度,四个设计
我们进一步链式法则拆解,分析出三个出发角度,为 Tokenizer 设计提供方向:
4.1 编码熵:如果动作没骤变,token 请你别乱切
Artifact Entropy。实践情况中 H(C|A) 其实是 0,因为编码器固然是一个确定性模型,但是并不影响我们幻想存在一些环境噪声,然后把这一项理解成一种“鲁棒性”的概念,
假如说 token budget 是 n,我们不希望两个 action 明明肉眼看上去没有明显的差别,作用效果也一样,结果对应的 n 个 tokens 一大半都不相同,这对于 VLM 来说就是不稳定的监督信号,训练效率可见会降低。
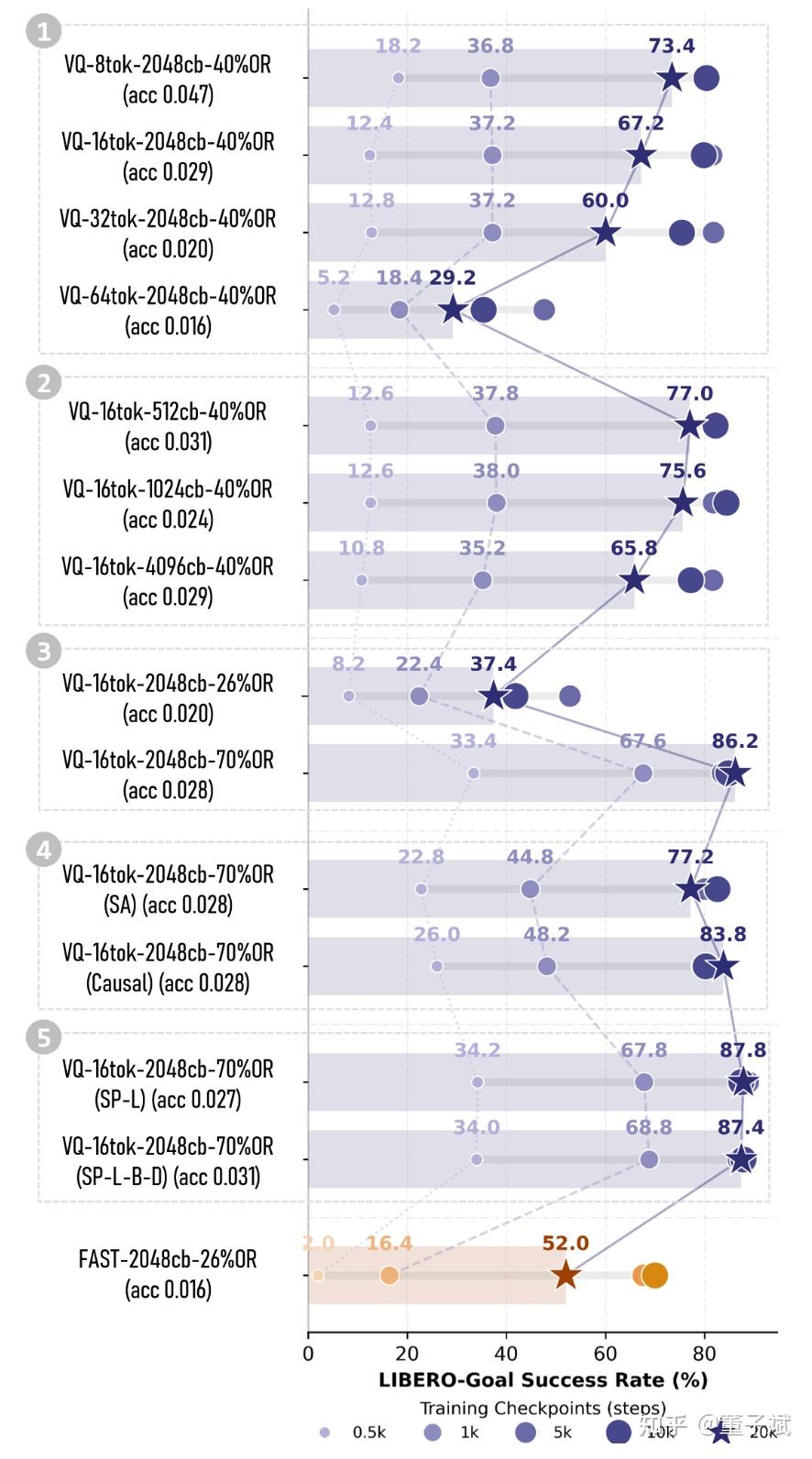
为了方便统计,我们用 Overlap Rate (OR) 作为观测指标,他表示相邻动作(A_{0:H}和A_{1:H+1})编码后的 token 序列的重叠率。实验中发现,直白训练一个朴素 VQ-VAE, OR 往往很低(<30%),拓扑不稳定。
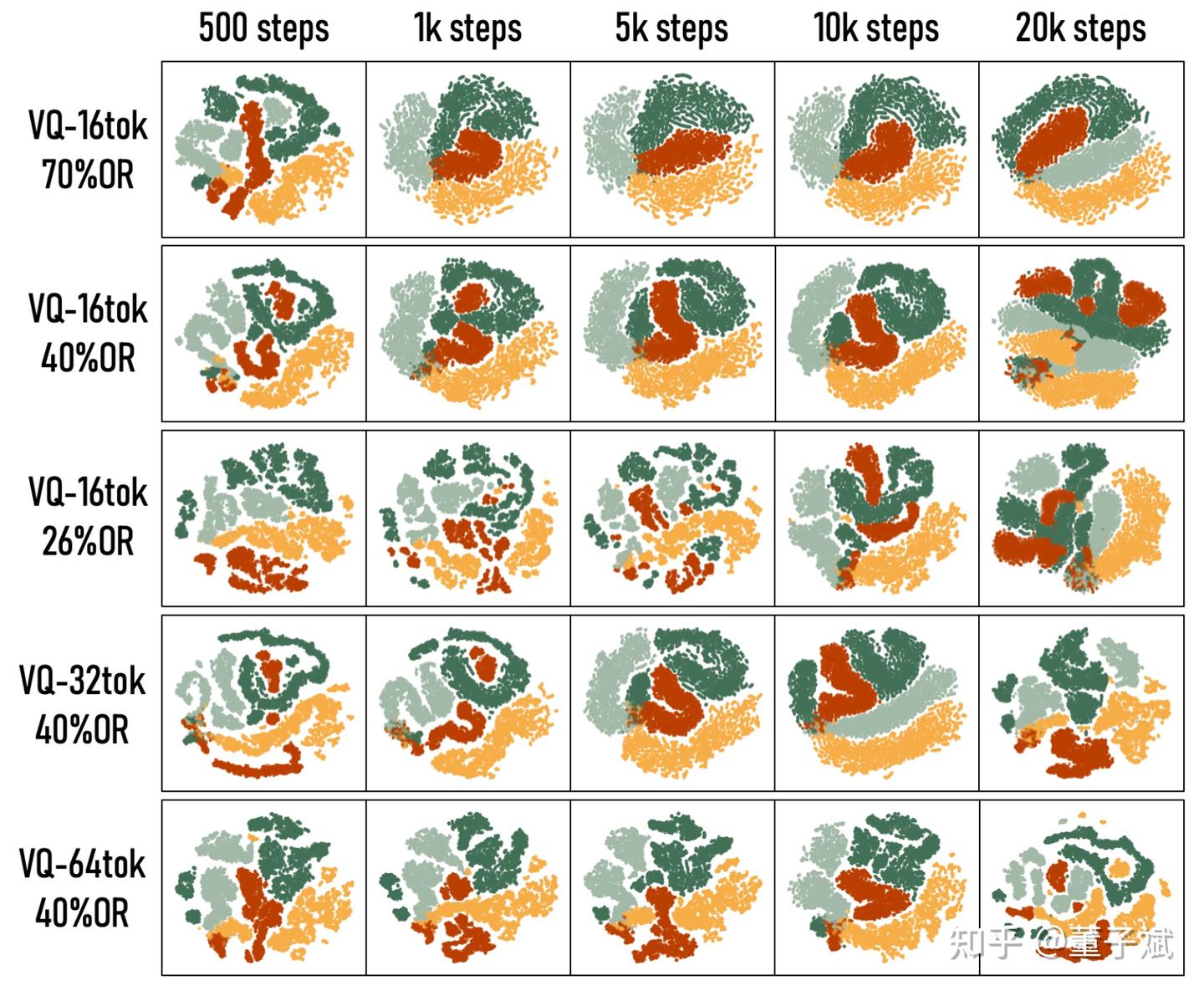
下面的图可视化了 VLA 的 action 「[BOS]」 token 对应的输出 embedding 的 tsne 图,tokenizer 是在完整的 LIBERO 数据集训练的,图中的 4 种颜色表示随机的 4 个 LIBERO 任务的数据,见前三行的图,我们发现高 OR (70%) 的设置让 VLA 在训练早期(500 steps)就能形成清晰的聚类,而低 OR 则是一团散沙,在训练后期(20k steps)高 OR 依然维持稳定的聚类,而低 OR 已经出现过拟合了。
见性能对比图的 Block 1 和 3,高 OR 也显著提高了训练早期的 VLA 表现,并且抑制了训练后期 VLA 的过拟合。(这里提高 OR 是通过对 action 做对比学习实现的,正样本是 action + 小高斯噪声,负样本是 batch 中的其他 action,但是这种方法训练并不是很稳定,下面的章节会提出替代方案,效果相同。)
 ""[BOS] token 对应的输出 embedding 的 tsne 图,tokenizer是在完整的 LIBERO 数据集训练的" />
""[BOS] token 对应的输出 embedding 的 tsne 图,tokenizer是在完整的 LIBERO 数据集训练的" />
4.2 Codebook 别太大,够用就行
Capacity I(C;A) 直觉上会觉得,词表越大、token 越多,重建越准,VLA 效果越好。但这一项的确是 H(C|V,L) 的增量。如果 Capacity 过大,Tokenizer 会倾向于编码动作中的高频噪声。
对于 VLM 而言,它需要去拟合这些与 (V,L) 无关的随机噪声,这不仅浪费了模型容量,还导致了严重的过拟合,见上方 tsne 图的 245 行。在消融分析实验中(性能对比图的 Block 1 和 2)我们的确发现提高 token budget 和 vocabulary size,重建误差是降低了,但 VLA 的成功率反而下降了。
这再次印证 action tokenizer 的目标不应该是极致的重建,而是构建一个利于 VLA 学习的流形。
4.3 对比学习齐上阵,模态对齐全拉满
I(C;V,L) 是我们需要最大化的 Perceptual Alignment。如果 C 和 V, L 的互信息很高,意味着 VLM 可以更容易地从视觉语言特征映射到动作 token。
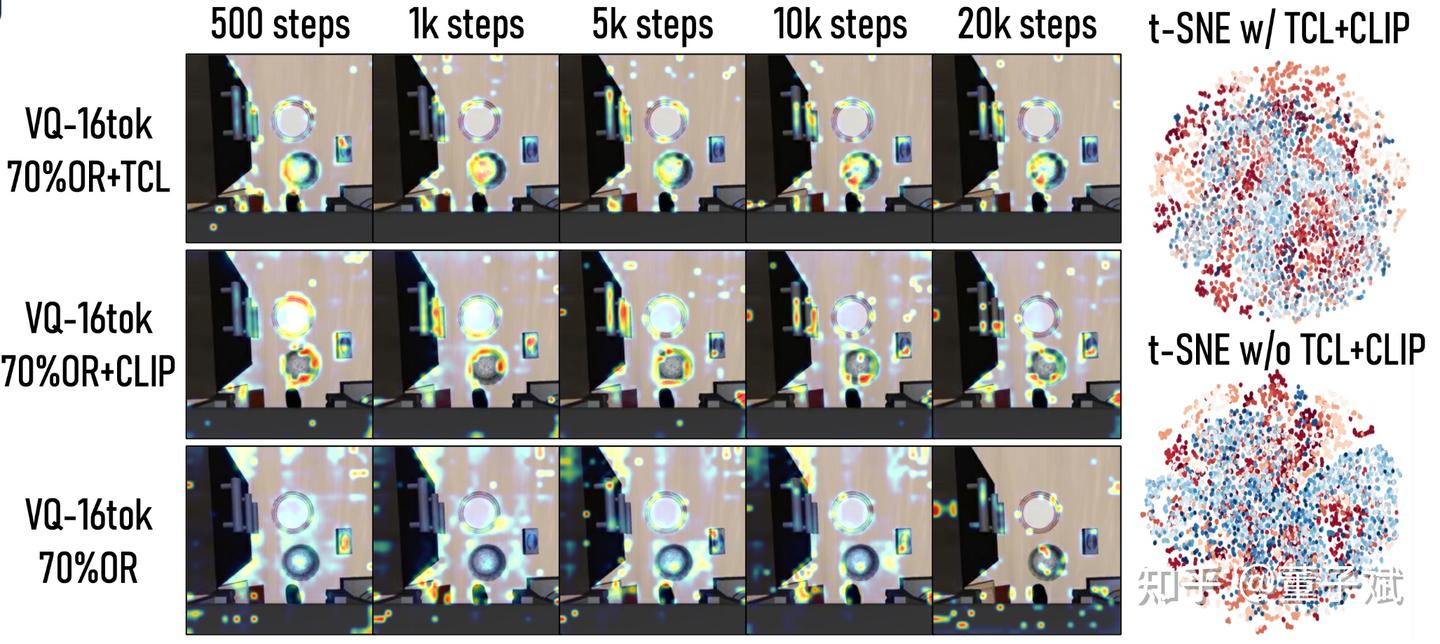
我们加入了两个很直白的对比学习 loss 强行注入关联。那我们肯定都会好奇这俩对比学习对 tokenizer 的影响是相同的吗?
我们可视化了单独用这两种 loss 训练的 tokenizer 再训练的 VLA 的 attention map,直观感受上是视觉对比的 attention map 更加宽泛,语言对比的 attention map 更加集中具体,具体 VLA 跑分还是两者结合最佳。连特征的 tsne 图都感觉更紧凑了呢。另外这两个对比学习 loss 都能够提高 OR,相比对 action 信号加噪的对比学习,训练更加稳定。
4.4 Token 之间要独立,相关关系不保留
这部分设计涉及到了 Residual Grammar。很多工作(包括 FASTer 的尝试)会在 Tokenizer 网络内部引入 Self-Attention (SA) 或额外加一个 Causal Mask,来建模 token 间的依赖关系。
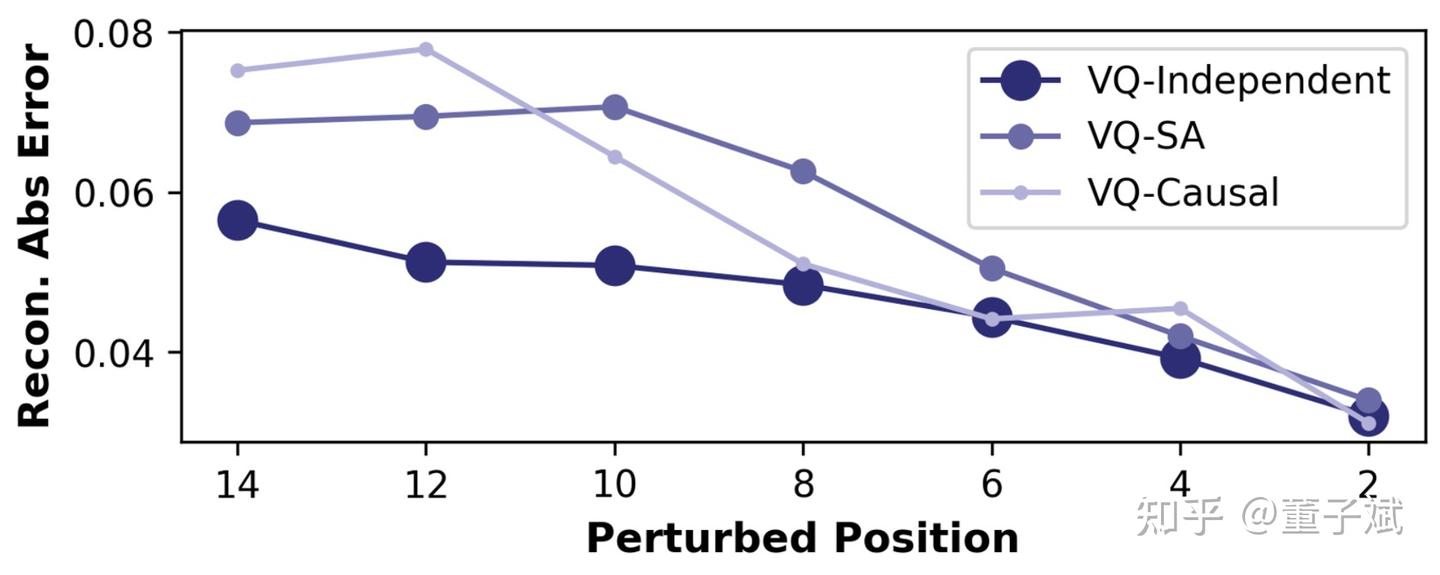
但在 VLA 训练中,我们发现这可能成为一种累赘。如果 token 之间存在强依赖,一旦 VLA 在推理时预测错了一个 token,错误会一直传递下去,导致整个动作畸变。我们做了一组扰动实验:在推理时人为干扰第 k 个 token,然后继续自回归,观察后续重建误差。
结果显示,Independent 结构(仅使用 Cross-Attention 的 Perceiver)的鲁棒性远超 SA 和 Causal 结构。见性能对比图的 Block 4,independent 结构 VLA 表现会更好。
5. 工程设计
以上就是换一种方式建模问题给我们的 insights,但在实际落地时,我们还需要解决两个棘手的工程问题:跨模态数据的异构性和精度与稳定性的权衡。
5.1 Soft Prompt
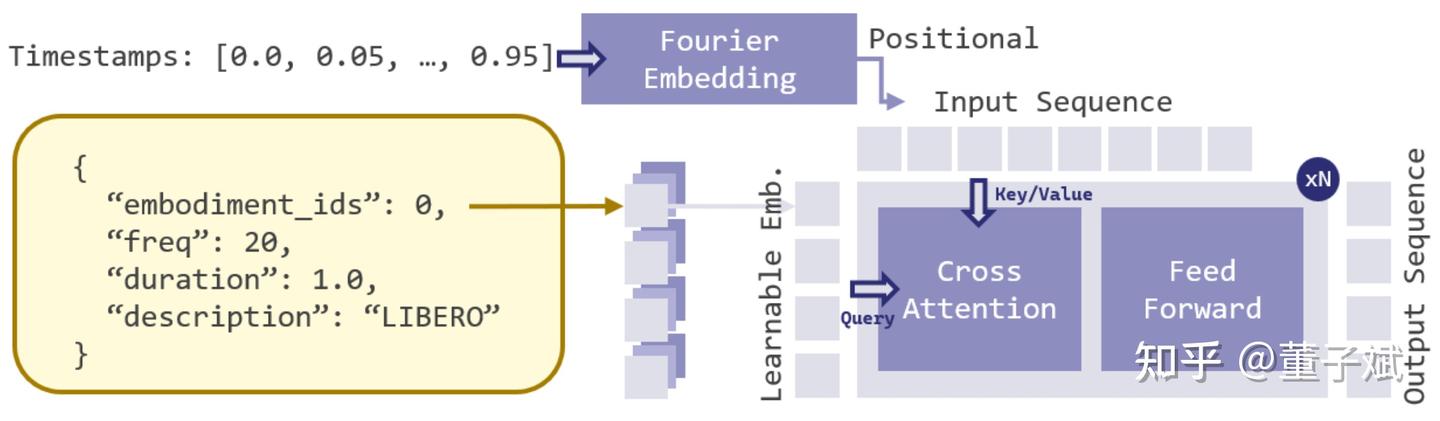
为了训练比较通用的 action tokenizer,我们需要混合 LIBERO, BridgeData, DROID 等多个数据集。这些数据的控制频率(5Hz - 30Hz)和机械臂构型各不相同。如果直接暴力混合,Tokenizer 很难学。
为了提高 cross-embodiment 的 transfer,我们为每个数据集(或者说机械臂构型)分配一个入口的 learnable embedding,将控制频率和动作时长通过傅里叶特征编码(Fourier Embedding)作为 positional encoding 注入 。
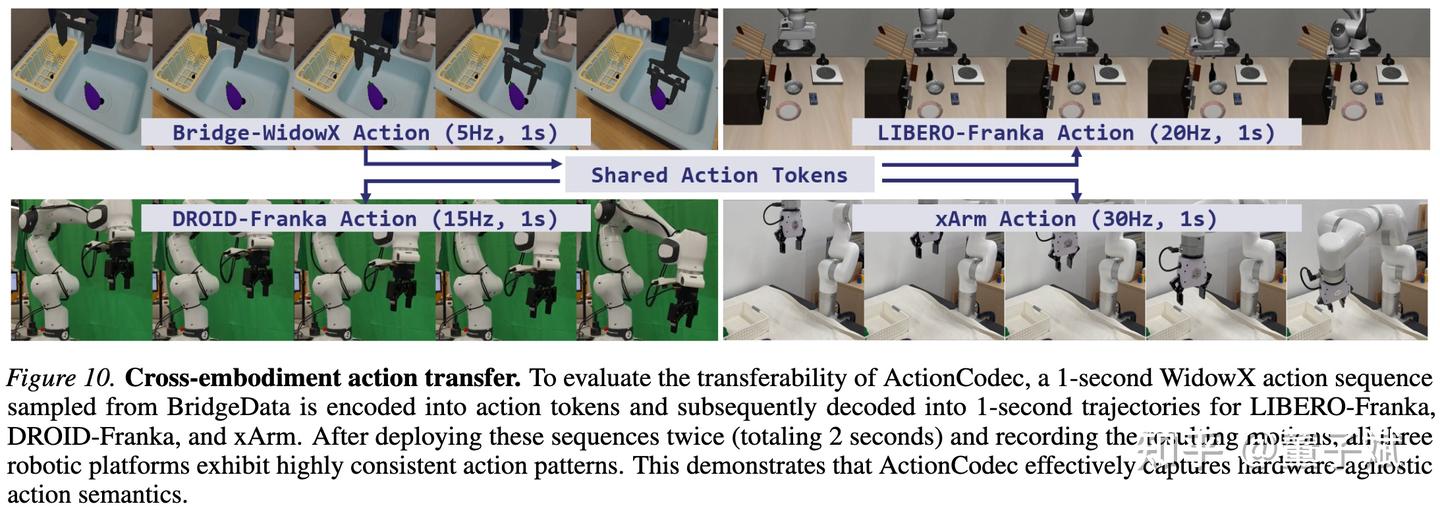
我们发现这种方式让 action tokenizer 可以在同一个 latent space 内处理异构数据,甚至支持 zero-shot 的跨机器人行为迁移(例如在 xArm 上执行用 WidowX 数据训练的动作)。
5.2 RVQ post training
这个东西是真的好用。
我们在实验中发现,我们越想改善 tokenizer 的性能(高 OR 等),重建精度就越迅速变差,虽说重建精度已经被钉死认为不那么重要了,但是越高的重建精度还是代表了更多的操作空间来换性能。能不能既要又要呢,我们发现 RVQ Post-training 的两阶段训练是真的太好用了:
- Stage 1 (VQ Training):先训练一个标准的 VQ Tokenizer,优化前面分析的所有 objectives。目的是把 OR 拉高,把 latent space 的拓扑结构定下来,让 VLA 好学。重建精度差一些没关系。
- Stage 2 (RVQ Refinement):冻结 Encoder 和第一层 Codebook(保持 VLA 的分类目标不变),然后在其后追加残差层进行训练,只优化重建 objective。
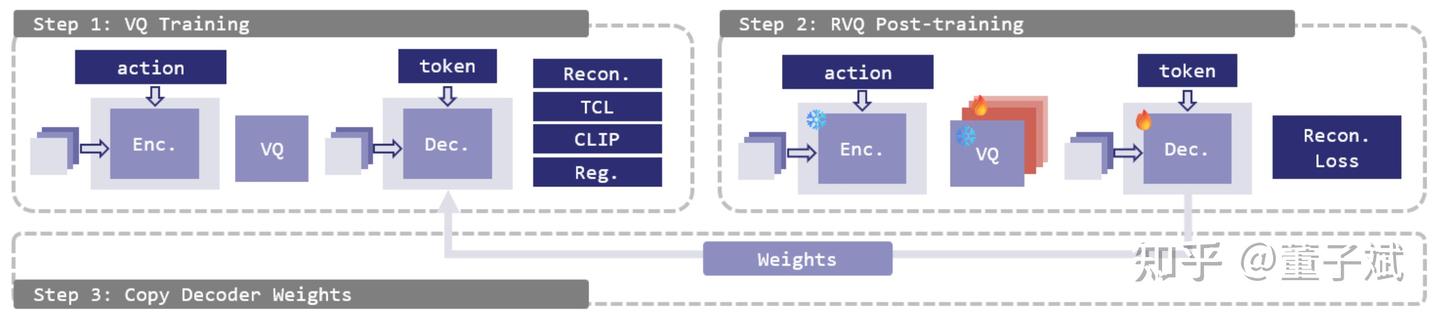
如果只训练第一阶段的 VQ(OR 能轻易拉到 70%),重建精度不如人意,如果精度过低了,会破坏 VLA 的分布拟合目标,效果也会不好;如果第一阶段直接用 RVQ,那么哪怕加了那些辅助 loss,OR 会上升极其艰难 (小于 30% 甚至 20%),tokenizer 性能难以提高。这个设计莫名其妙解决了矛盾,我们用三层 RVQ,第一层 OR 依然是 70%,第二层和第三层能到 60%、40% 这样子,重建损失对半砍。
那么可能也会忧虑,这么做的代价是 token budget 也翻了三倍,那不是成本也增加了吗?
但是我们其实 freeze 住了 encoder 和第一层 codebook,所以第一层编码 tokens 和 RVQ post training 之前是完全一样的,只有 decoder 进行了进一步优化,如果我们把 RVQ post training 的 decoder weights 直接 copy 回 VQ training 的模型,就能发现重建精度竟然也提高了很多很多!编码侧没有任何损失。这简直就是 free lunch 了。
6. 实验验证,Tokenizer 拼四种范式
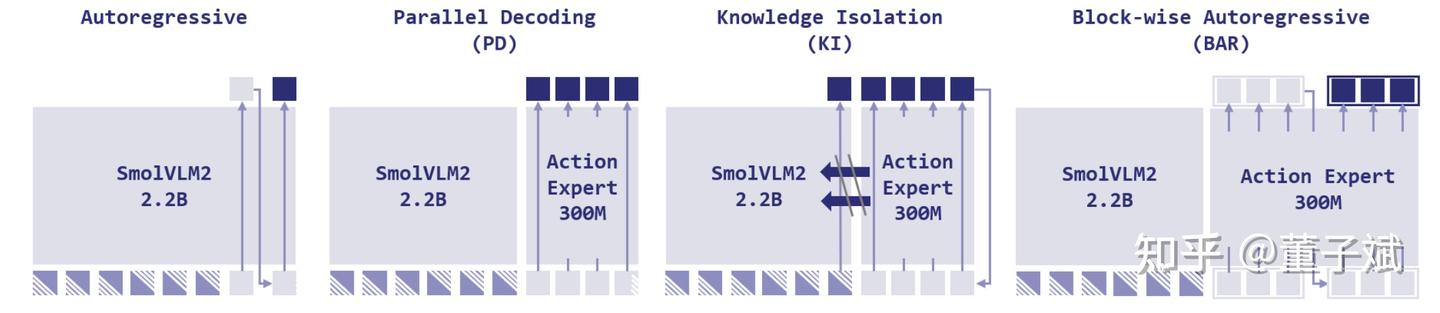
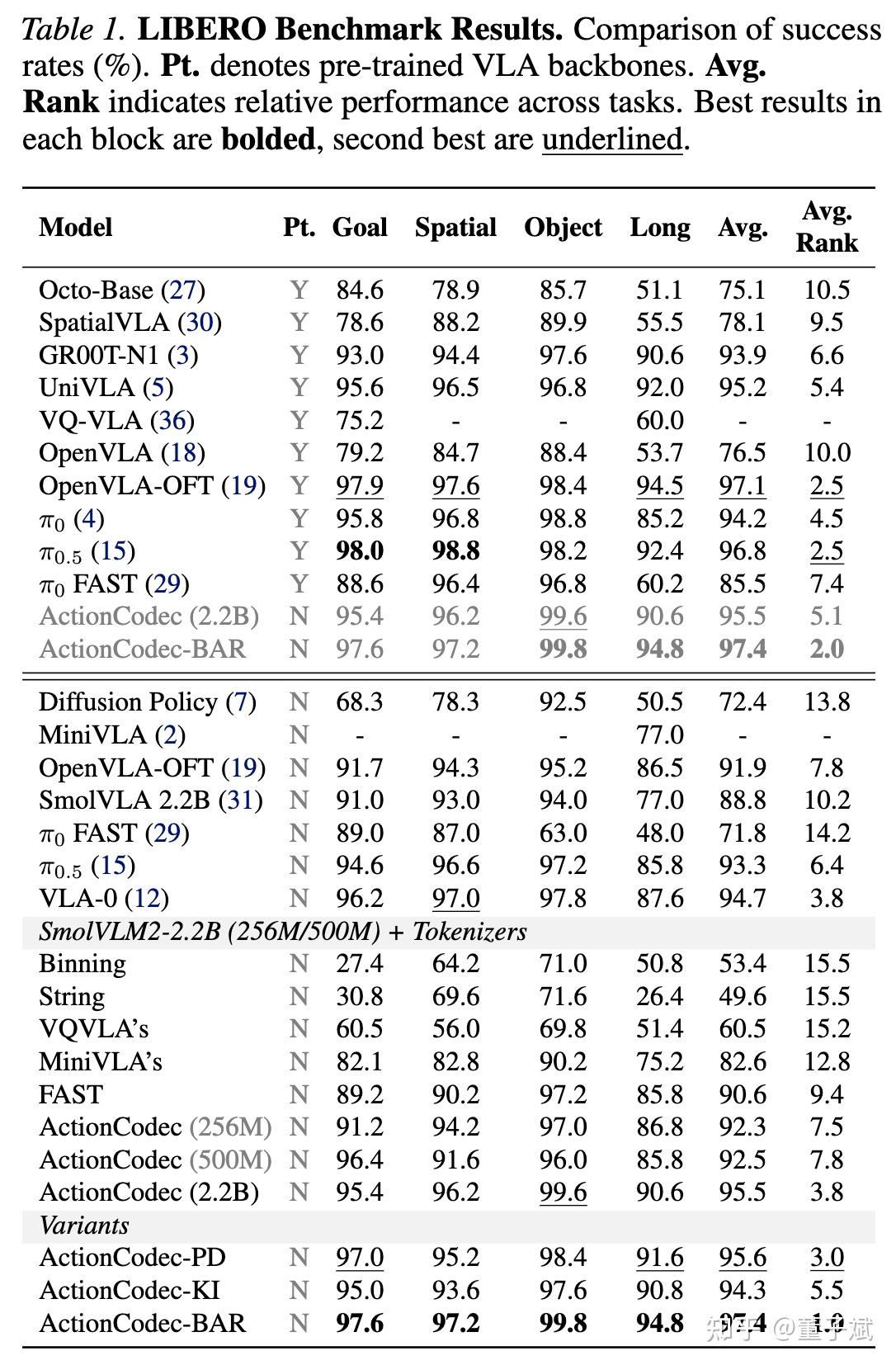
结合以上所有的 design choice + 两个工程性的优化,我们把模型命名为 ActionCodec,感觉朗朗上口也意义纯粹。为了验证 ActionCodec 的有效性,我们将 ActionCodec 嵌入到四种主流 VLA 范式中:
- Autoregressive (AR):标准自回归,类似于 \pi_0\text{FAST} 的做法。
- Parallel Decoding (PD):类似 OpenVLA-OFT,但是输出不是直接解码成动作,而是依然输出 logits,依概率采样 tokens。只 forward 一次所以非常快速。
- Knowledge Isolation(KI):类似 PI05,Action Expert 是一个 flow matching model。
- Block-wise Autoregressive (BAR):类似于 FASTer,结合 RVQ 的分块自回归,并行预测第一个 Codebook 的 tokens,然后以此作为输入预测 第二个 Codebook 的 tokens,以此类推。如果只预测第一个 Codebook 的 tokens,那么等价于 PD。
结果令人振奋:
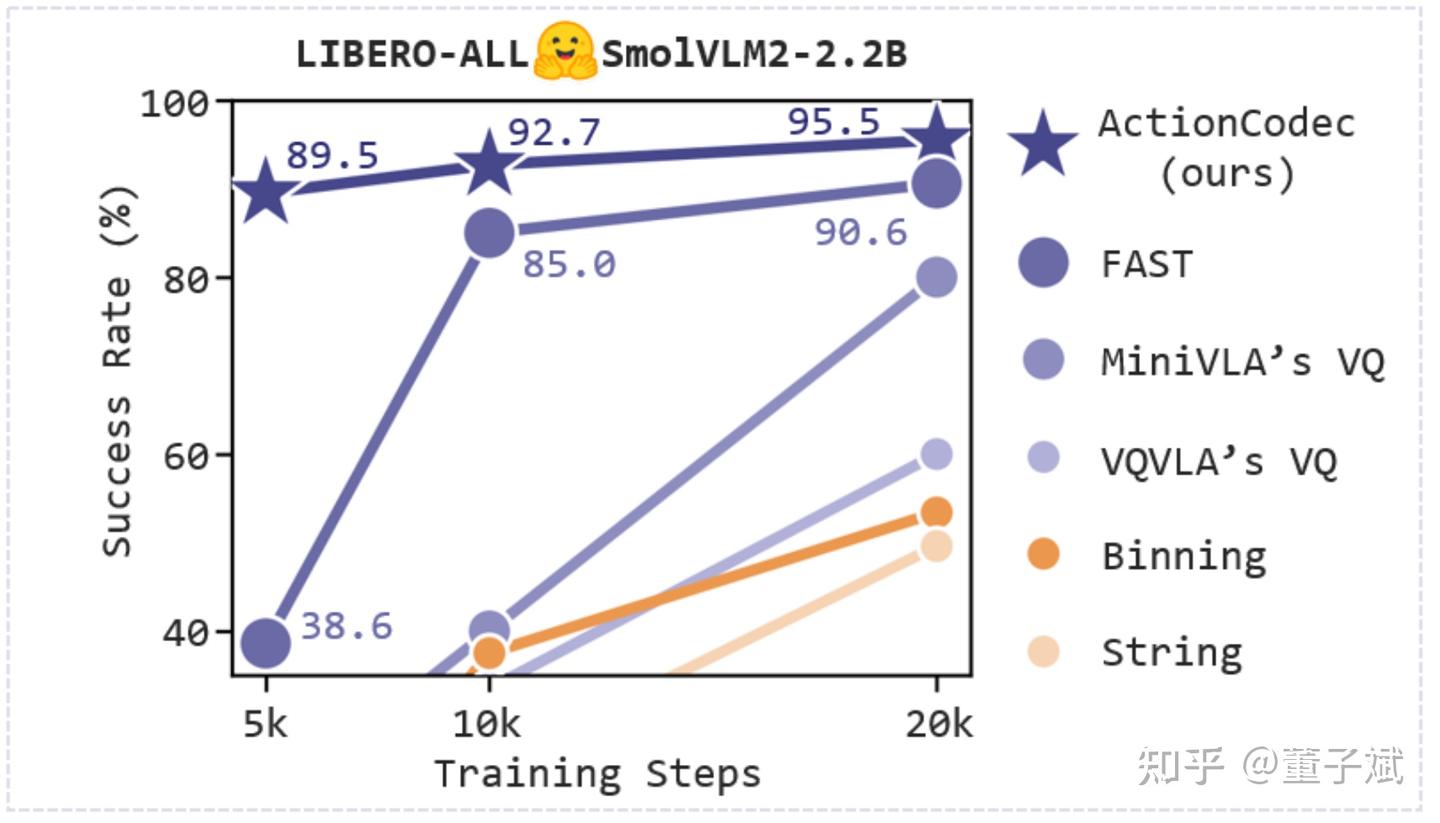
快速总结:
- 训练效率极高:在 LIBERO 上,SmolVLM2-2.2B + ActionCodec 仅 5k 步就达到了 89.5% 的成功率,而同期的 FAST Tokenizer 只有 38.6%。
- 朴素推理效果好:哪怕是当做 VLM 用,朴素自回归预测 action tokens,也能到 95.5% 跑分;使用更小的 SmolVLM2-256M/500M 也能上 92%,相比 SmolVLA 有了显著的提升。
- 和不同的 VLA 范式结合依然好用:无论是 PD,KI,还是 BAR,性能都十分可观,尤其是 RVQ post training 版本结合 BAR,达到了 97.4%。在 Simpler-Bridge benchmark 上这个组合也达到了 65.2%(120 次测试平均)
除此以外还有更多真机实验,消融实验,实验细节分析,放在 paper 中这里不展开一一列举了,希望多分享 insights,少打广告。
7. 总结,感想,和自我批判
ActionCodec 这个工作我自己挺满意的,也是给硕士生涯画上一个满意的句号了。我相信大家都看到了 action tokenizer 的重要性,哪怕我们不信任自回归架构,它也可以帮助我们把海量真机数据转化为 VQA 任务来训一个更直接适合于具身任务的 VLM backbone。相比于盯着 ActionCodec 模型本身,我可能会觉得那几条 design choices 是更有意义的事情:
- 现在的时序对比和 CLIP 的辅助 loss 真的是最好的方式吗? 为了提高 OR 和 视觉语言互信息,肯定有更多的方式也能做到,肯定有更鲁棒更漂亮的方法。
- VQ-VAE 一定是最好的形态吗? 我愿意相信 data-driven,但是 VQ 也仅仅是其中的一种方式;甚至于如果我们认可本文开头我对 PI05 架构的理解,那么 action tokens 也并无必要能解码还原 action 信号,他只需要提供更好的监督信号来帮助 VLM 学习,这个角度布清文大佬的 UniVLA 的 LAPA 式的做法可能才是更正确的方式。
- Perceiver 架构真的非常灵活,他能把不同频率,不同长度,不同构型的机器人数据全部编码到一个统一长度的 discrete latent space,这对于 cross-embodiment 有非常大的帮助,实验中我们也发现保持 tokens 之间的相关性独立很重要,那么如何改进架构提高重建效果,如何保持 tokens 不但独立而且特征提取正交,也很有意义。
arxiv 在传,代码模型都是现成的稍微整理整理就发,但是大年初一我相信没有人愿意看 paper,没有人想下载模型,但是刷刷短文看点轻松愉快的 insights 想想思路肯定是很愉快的。耶✌
Arxiv: https://arxiv.org/abs/2602.15397