作者:一木不
原文:https://zhuanlan.zhihu.com/p/2004306938188537902
关于On-Policy的工作,我感觉大部分在卖概念,没有太本质上的创新,比如一会说On-Policy Distillation是SFT、一会说是RL,但感觉不如就叫它Distillation好了。
比较公认的点是:
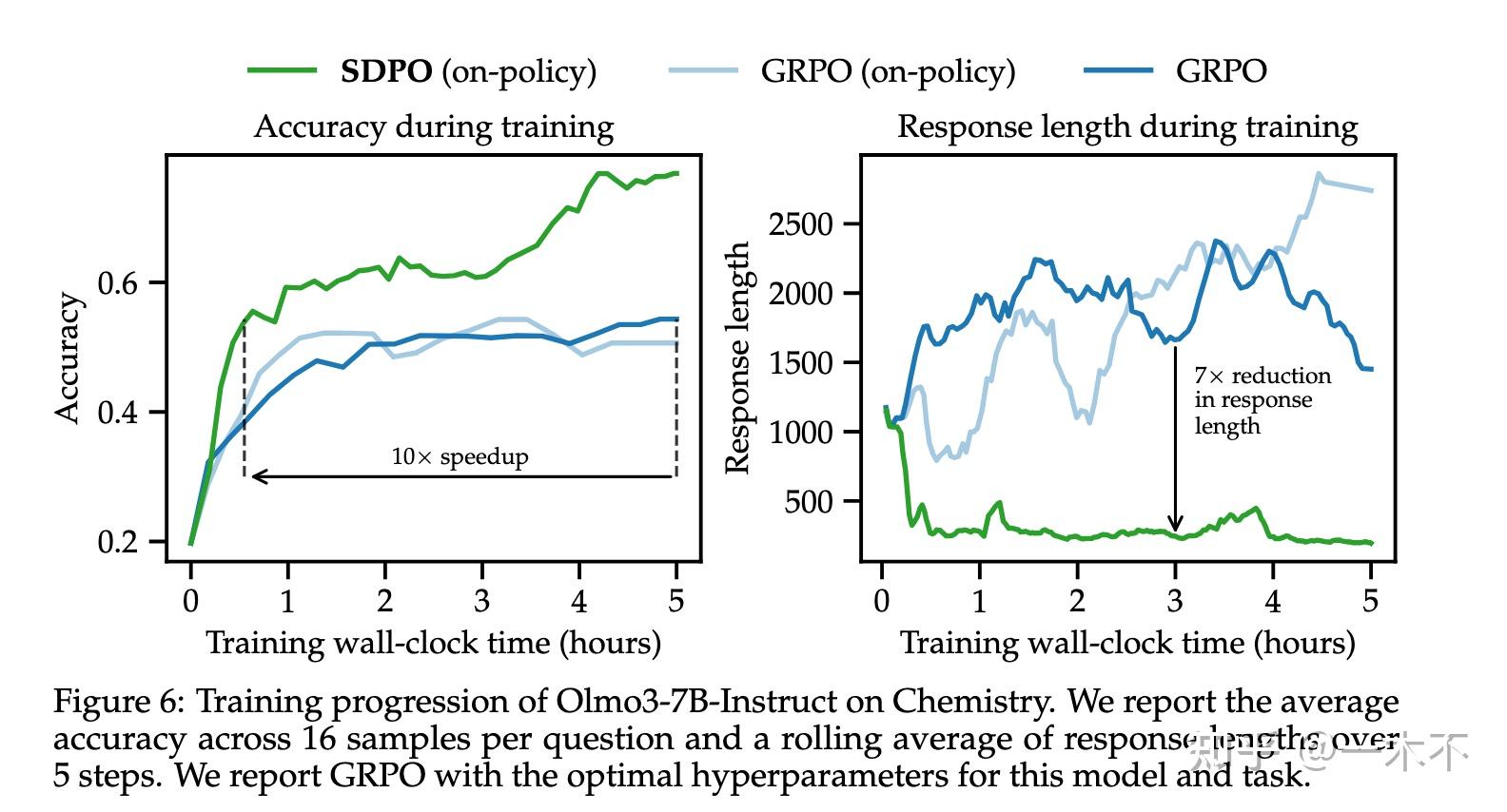
- On-Policy Distillation相较于GRPO提示性能的同时,避免了过多的Aha Moment
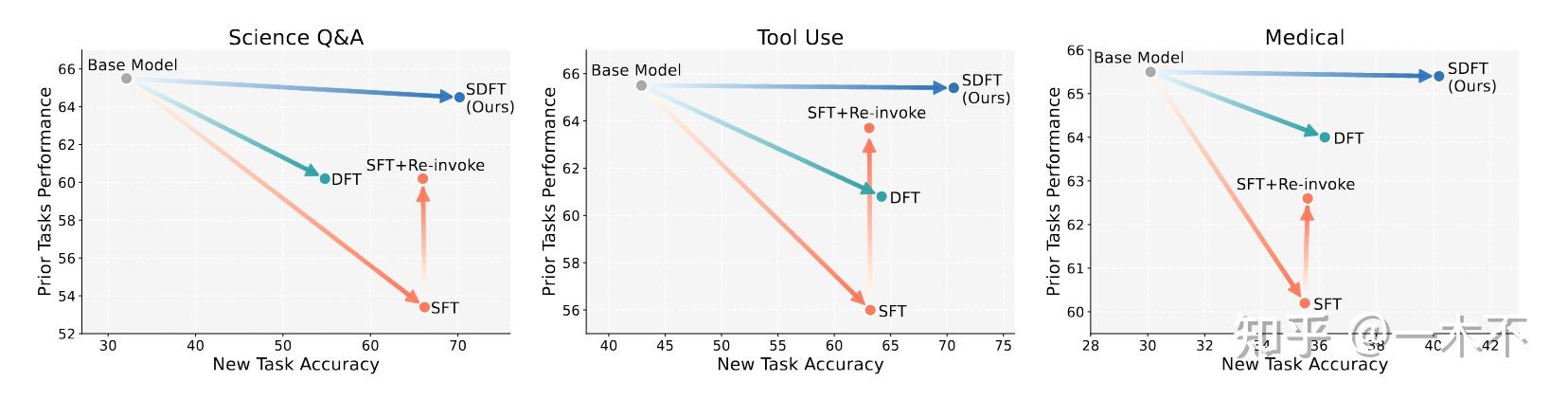
- On-Policy Distillation可以缓解灾难性遗忘
- On-Policy Distillation天然适合与GRPO结合,提供token-level的密集奖励信号
- On-Policy Distillation的难点是获取Teacher模型,Self-Disitlltion即使用Policy模型当作Teacher模型被验证为可行的
- On-Policy Distillation的实现兼容RL,所以直接在RL框架上比较容易开发
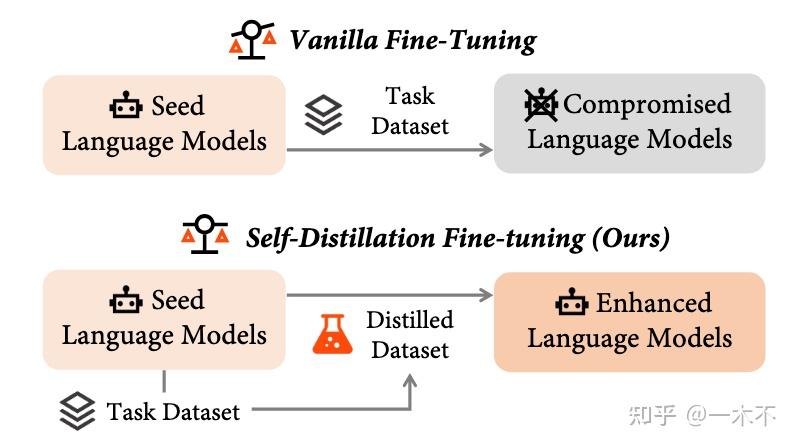
本文重点介绍On-Policy/Self-Distillation (OPSD),即使用Policy本身当作Teacher模型。
1. On-Policy Distillation的目标及梯度
On-Policy Distillation旨在最小化学生策略 \pi_\theta与教师策略 \pi_{\text{teacher}}在学生策略自身生成的轨迹分布上的KL散度:
其中KL可以是Reverse KL,也可以是Forward KL,[1-2]中是Reverse KL,[3]中是Forward KL。
对于ForwardKL其梯度可以推导为:
对于Reverse KL其梯度可以推导为:
可以发现其实和RL的目标很相似,都有\nabla_\theta \log \pi_\theta(y_t' \mid x, y_{<t}),只是前面所有的加权不一样。RL加权的是Reward或者Advantage。
2. On-Policy Self-Distillation
Self-Distillation旨在用Policy充当Teacher模型:
其中sg(\cdot)代表stop gradient,f代表额外知识,\theta'可以通过\theta获得。
On-Policy Self-Distillation的关键在于Teacher构造OPSD中Teacher构造方式和MoCo、SimCLR、DINO、SigLIP等有相似之处。
- 需要引入额外的知识,以来In-Context Learning能力
- Policy model在不断更新,Teacher模型的参数要相对稳定一点
这两点就是后面实现细节要讨论的。
3. 实现细节
3.1 如何引入额外的知识
目前看到的有下面两种方式:
方法一:直接把Ground-Truth透露给Policy模型参考

方法二:来源于环境的反馈

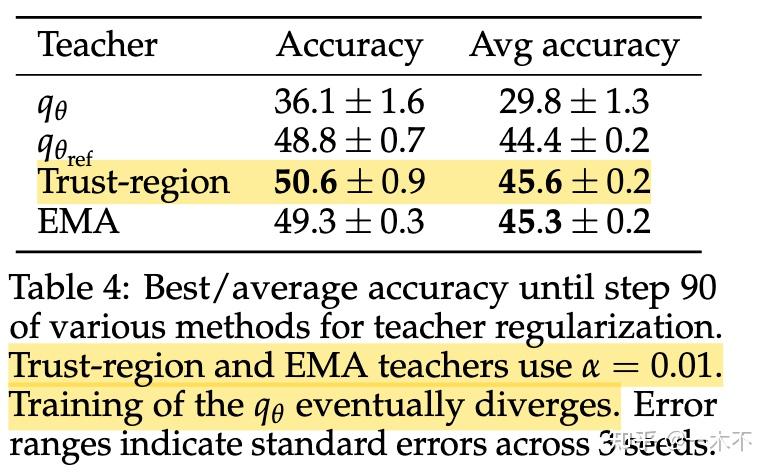
3.2 Teacher模型参数如何确定
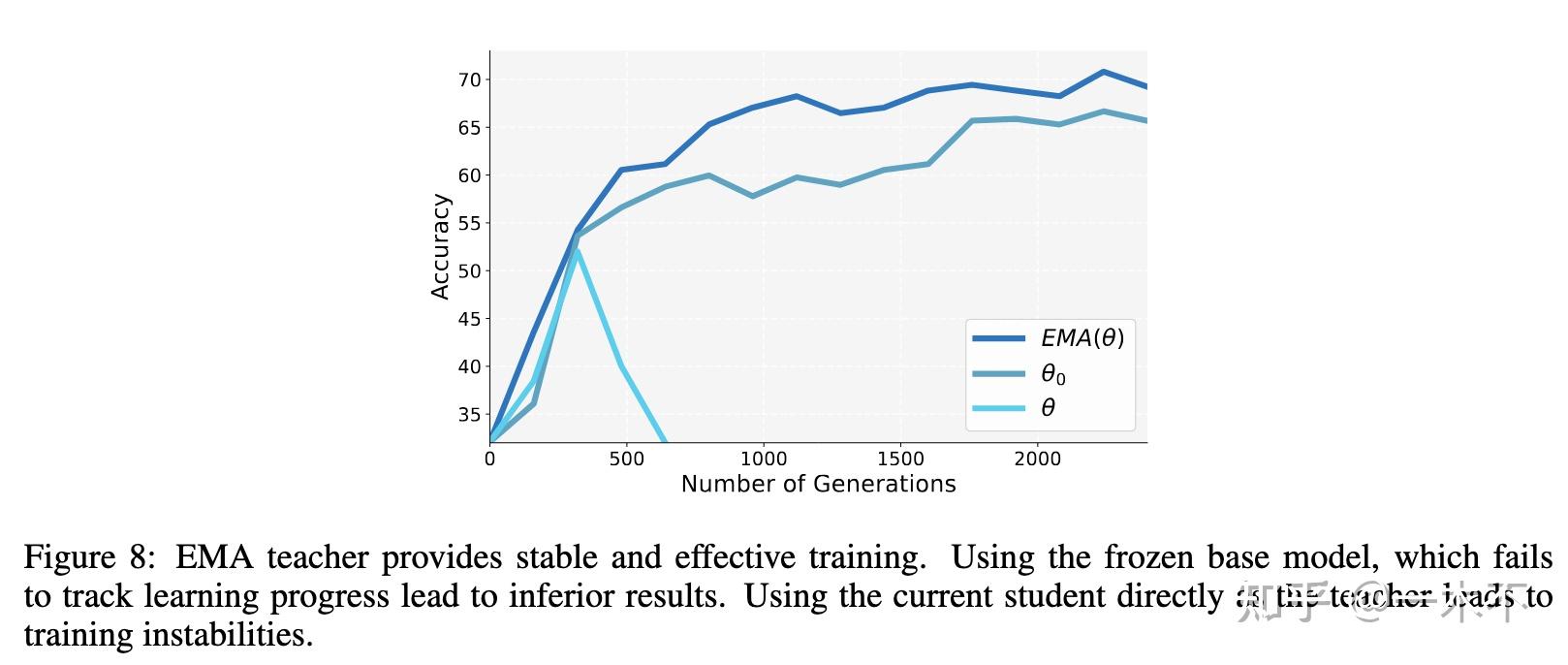
- 直接使用原本的frozen模型前期可以,后面就崩溃了
- Teacher模型一直使用Policy模型也是可以的,但效果不如EMA
- Trust-region和EMA效果差不多,都是为了获得更稳定的Teacher, 避免随着优化过程剧烈变化
Trust-region的更新策略为:
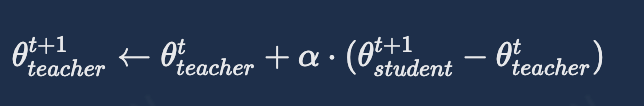
4. On-Policy Self-Distillation的优点
4.1 缓解灾难遗忘
Self-Distillation Bridges Distribution Gap in Language Model Fine-Tuning这篇工作比较早研究了,但是当时On-Policy概念还没有火。
4.2减少Aha Moment

4.3减少Train-Test Gap
提前在train-time暴露学生模型test-time的分布,缓解暴露偏差。
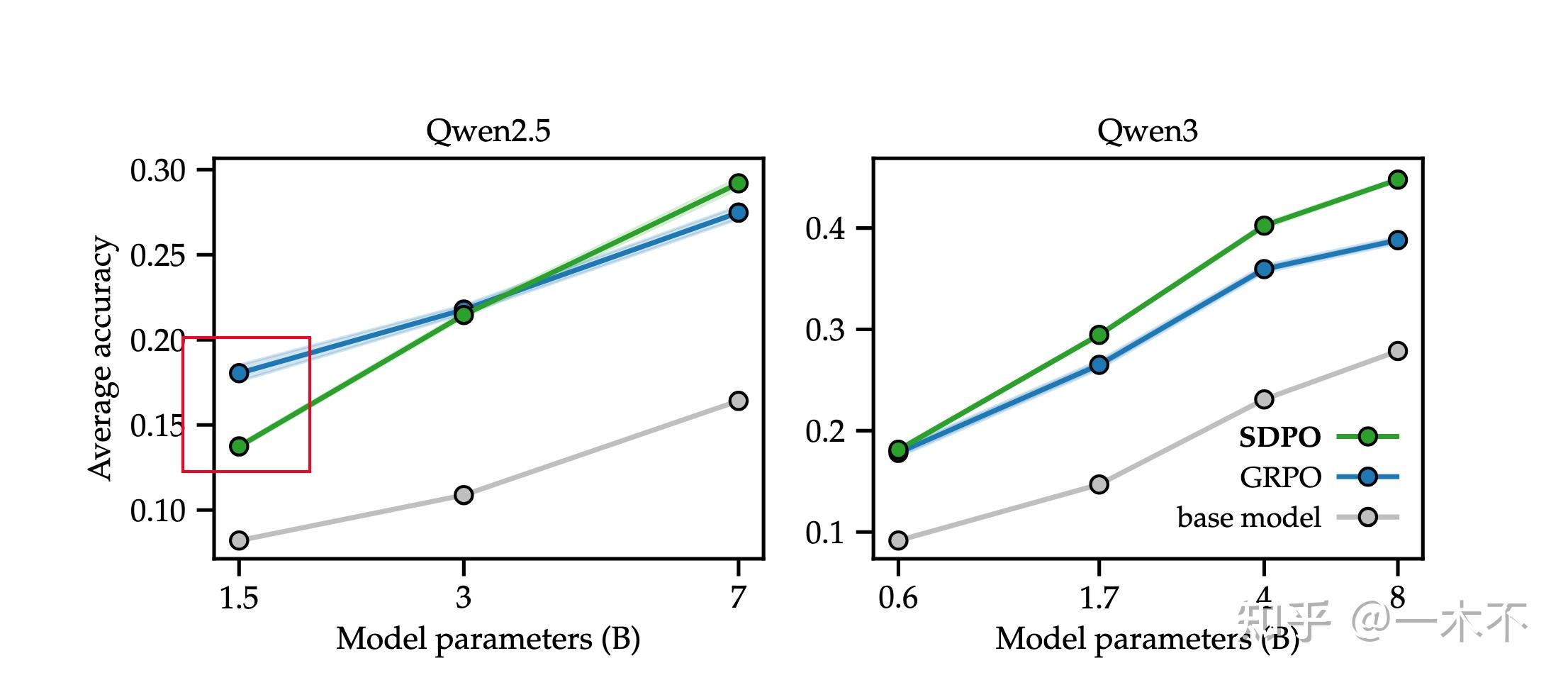
5. Scaling On-Policy Self-Distillation
正常来说,模型尺寸越大,超过GRPO越多。因为模型越大,in-context leanring能力通常越强。
Reference
[1] Reinforcement Learning via Self-Distillation
https://arxiv.org/html/2601.20802
[2] Self-Distillation Enables Continual Learning
https://arxiv.org/html/2601.19897
[3] Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
https://arxiv.org/html/2601.18734