去年有次组会,师弟和我说在复现一些Thinking with Images工作的时候,发现interleaved images是错的/被丢掉了,模型的表现也不会受到影响。另外,有些模型在实际上没有执行工具的时候也会幻觉说执行了工具。考虑到我们之前发现llm4math里有答案正确过程不对的情况,vision这边可能也有类似的现象。
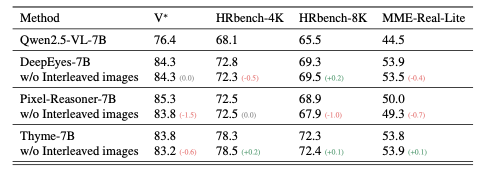
于是我们拎出来一些比较成功的Thinking with Images工作,比如pixel-reasoner/deepeyes/thyme(恭喜他们都中了三大会),把interleaved images丢掉,也就是抑制visual tool/code输出的结果,发现在benchmark上的表现其实影响比较小。
这些前沿的工作的setting也比较统一,都是从Qwen2.5VL-7B-Instruct做rl训出来的,可以看到丢掉interleaved images的影响相比于它们和base model的差距是很小的。
我们又去把它们正常推理的attention rollout画出来,看看模型在回答的时候主要attend到了哪些位置:

这个例子是V*的第一个sample,其实就比较有意思(不是因为有炸鱿鱼)。首先是可以看到模型还是更多在attend input image,然后其实模型在有interleaved images之前就已经得到答案了(这里的顺序是先有input image+query,然后是thinking,接着是interleaved image,最后是answer)。
模型通过观察整个场景是一个食品摊,所以推断出手套的材料应该是常见可以用来接触食物的,这样就直接得到橡胶这个答案了。类似的现象其实之前被广泛地报告过,不过大多数是说这样容易产生幻觉,比如我很喜欢的一个例子:

这个例子是问接收器是什么牌子的,可以看到虽然模型是能attend到正确的位置的,但是还是错误地回答成罗技,这可能是因为训练语料里面罗技接收器出现的频率比别的牌子高太多了。所以当模型的先验match事实时,这个先验是能够帮助模型的推理的,但如果不match事实,就会产生大家经常report的幻觉。
回到Thinking with Images,如果interleaved images起到的作用不大,那么有没有可能是更好的先验(如前面所说,Thinking with Images模型大多是rl训过的)使性能提升了呢?要验证这一点,可以不带interleaved images做训练。
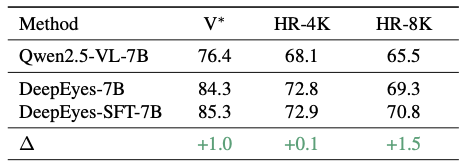
我们用deepeyes rl的数据来跑了一下纯文本sft,发现是可以match性能的。arXiv2511.22586报告过用纯文本rl也可以match性能,我当时看到觉得比较impressive,不过他们没强调这个结果。
至此我们认为,interleaved images的作用是小的,而更好的先验是很有用的(但什么是好hh?)。但为什么o3也要做Thinking with Images(让我们承认大多数人做这个方向的原因就是o3)?或者说,人看不清图片的时候就放大,cropping/zooming对vlm真的没用吗?
比较容易想到,因为input image会被patchify,cropping近似于把含有object的那几个patch复制一份而已。而zooming,只要object的scale不是太离谱,总会被训练的distribution cover住的。有文章就报告说scale对比较新的VLM的影响是不大的:
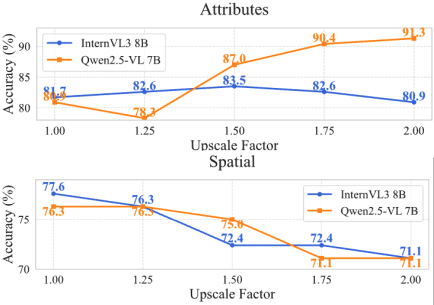
那么perception benchmark的困难主要在于long-context,而不是物体太小。long-context是说会有一堆无关的image token,如果先验不好的话,text token也是干扰项。
于是从context management的角度来说,我们应该引入好的context(含object的crop),同时避免引入干扰/没用的context(产生tool/code的那些文本token就不太好)。
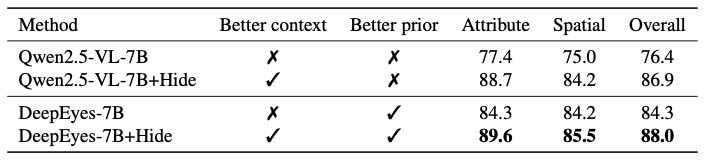
最后,一个比较理想的用cropping/zooming的方法就是Vicrop(arXiv2502.17422)/Hide(arXiv2510.00054)这样只引入含有object的crop的方法(它们都是training-free只利用attention的)。前面我们提到rl-based方法可能是通过更好的先验work的,那么把它们和更好的context一起用,也可以得到更好的效果:
接下来做什么。 很多前沿的组都已经去做cropping以外的工具调用了,比如deepeyesv2(arXiv2511.05271v2)会调用image search之类的。一个容易想到的原则是如果一个tool会提供一些外部信息,那么就有可能是有用的。不过对我来说更有意思的可能是一些纯vision的反馈,拿来做molmo2(arXiv2601.10611)那种video tracking之类的任务。
另外带反馈的pointing或者更广泛的说grounding其实听起来更有趣一点,我之前也做了点尝试(arXiv2509.23746),不过感觉应该做到general的任务上去。
主要是search感觉和纯文本的search没有太大的区别,而那些看着像data augmentation的tool感觉更应该让基座的人训练的时候对数据做一下就行了。