作者:Xiaoyang Li, Weixun Wang and Yancheng He | Project Leader: Weixun Wang | March 5, 2026**
本文英文名称:Save, Load and Learn: Boosting Agentic LLMs via Rollback-basedCurriculum Learning
1. 引言
在技术报告《Let It Flow: Agentic Crafting on Rock and Roll》中,我们提出了Rollback-based Curriculum Learning(报告中称为“Chunk-Level Initialized Resampling”),以应对Agentic RL在长时域、超高难度任务中面临的挑战。受篇幅限制,技术报告仅涵盖部分方法,许多关于这一方案的设计细节与实践考量尚未展开说明。
本文将全面阐述 Rollback-based Curriculum Learning 的框架细节(以下简称Rollback),涵盖核心算法、理论动机、实践中的细节以及多种实用变体,从而帮助大家更好地在实际训练中使用这一方法。在此过程中,我们将解答三个核心问题:
- Rollback是什么?(What)
- 为什么Rollback至关重要?(Why)
- 如何在实践中应用Rollback?(How)
若您对我们的智能体(Agent)训练流程的其他部分感兴趣,请参阅我们的技术报告及博客:
技术报告:https://arxiv.org/pdf/2512.24873
博客:The Bitter Lesson Behind Building Agentic RL in Terminal Environments
https://www.notion.so/The-Bitter-Lesson-Behind-Building-Agentic-RL-in-Terminal-Environments-2eaddd45837f80c9ad2ed6a15ef3c1a1?pvs=21
2. 基于Rollback的课程学习(What)
2.1 定义
Rollback是一种适用于长程、多轮Agentic任务的课程学习框架。该方法以验证成功的参考轨迹为基础,将中间状态作为检查点(Checkpoint)构建时序课程。训练将会从接近终点的检查点开始,随着模型能力提升逐步回溯(Roll-Back) 到更早的检查点,直至智能体(Agent)能从原始初始状态可靠地端到端完成任务。
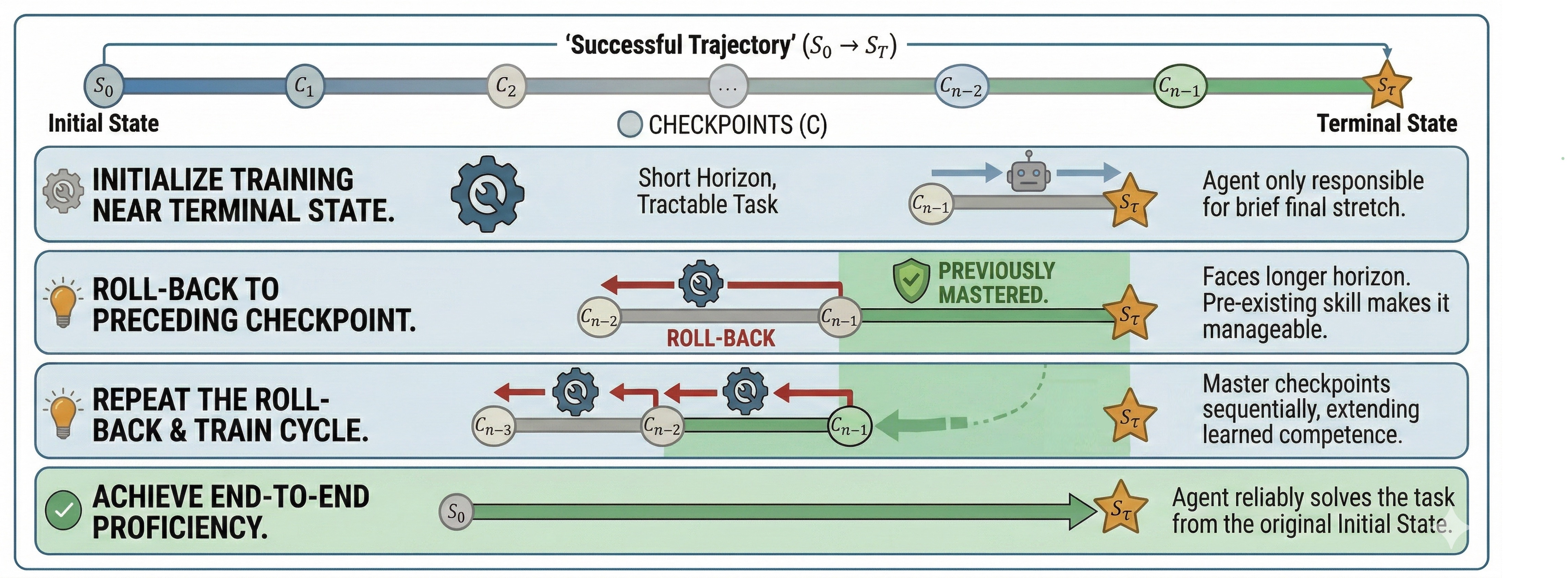
2.2 核心算法
Rollback的核心算法流程如下:
1.确定成功轨迹。 找到一条在目标任务上验证通过的成功轨迹,并在这条轨迹上找到模型难以完成的子任务,在这些子任务之前设置检查点。
2.在最后一个检查点开始初始化训练。 从最接近最终状态的检查点启动轨迹生成(Rollout),根据最终的奖励信号更新模型参数。由于此检查点距离终点最近,Agent只需完成任务的最后阶段,所以这个检查点对应的后续子任务最少,最容易成功。
3.回溯至前一检查点。 当Agent掌握当前检查点后续所需的技能后,回溯至前一检查点。此时Agent所需完成的子任务变多,待交互轮次变长。但是因为在之前的训练中已经掌握后续子任务的处理逻辑,模型仍然具备完成任务并获取正向信号的可能性。
4.重复“训练-回溯”直至端到端成功。 从最后一个检查点逐步往前回溯,每次迭代都有效提高Agent完成后续任务的能力。最终当生成的起点到达原始轨迹起点且Agent可以持续完成整个任务时,循环终止。
2.3 理论分析
通过这种方式,Rollback算法将一条成功的参考轨迹变成了一系列循序渐进的课程学习路径。直观而言,检查点距终点越远,Agent需要完成的剩余子任务越多,所需的交互轮次越长。因此从这些中间检查点出发完成任务按照检查点从后往前自然形成了难度递增的课程。
并且,一个关键点在于这种课程序列具有自我强化的特性:每次Agent攻克一个检查点,都可以有效降低前序检查点的难度——因为它已掌握后续部分环节的处理能力。Rollback通过逐段增强和累计Agent的能力,直至覆盖完整任务过程,使模型最终掌握从起点开始的完整端到端工程能力。
3. 动机与灵感(Why)
3.1 任务规模化导致正向奖励消失
随着大语言模型(LLMs)日益具备的Agent能力,人们的期望已从“完成单个任务”转向了“端到端交付”,即Agentic Engineering。这要求Agent必须规划流程、调用工具、读写文件、执行命令、解析故障并进行迭代。这有时需要数十甚至数百轮与环境的交互。 为满足这些需求,训练过程中使用的实例必须在子任务的数量和难度上同步扩展。然而这种扩展模式给基于强化学习的Agent能力优化带来了显著挑战,我们将在下文详细剖析。
3.1.1 长周期任务上成功率的崩溃
随着任务时长与复杂度增加,Agentic任务的两种特性迅速显现:
- 一步之差足以颠覆全局。 系统级任务需要连续正确的决策链,单次失误便会悄然使整个轨迹失效,导致前后投入的计算资源全部浪费。
- 失败率以乘法叠加。 即便单个子任务的可靠性尚可,但当操作序列拉长时,整体成功概率将呈指数级衰减。
最终,在这些高难度任务上,模型端到端的成功经历将成为例外,而不是常态。
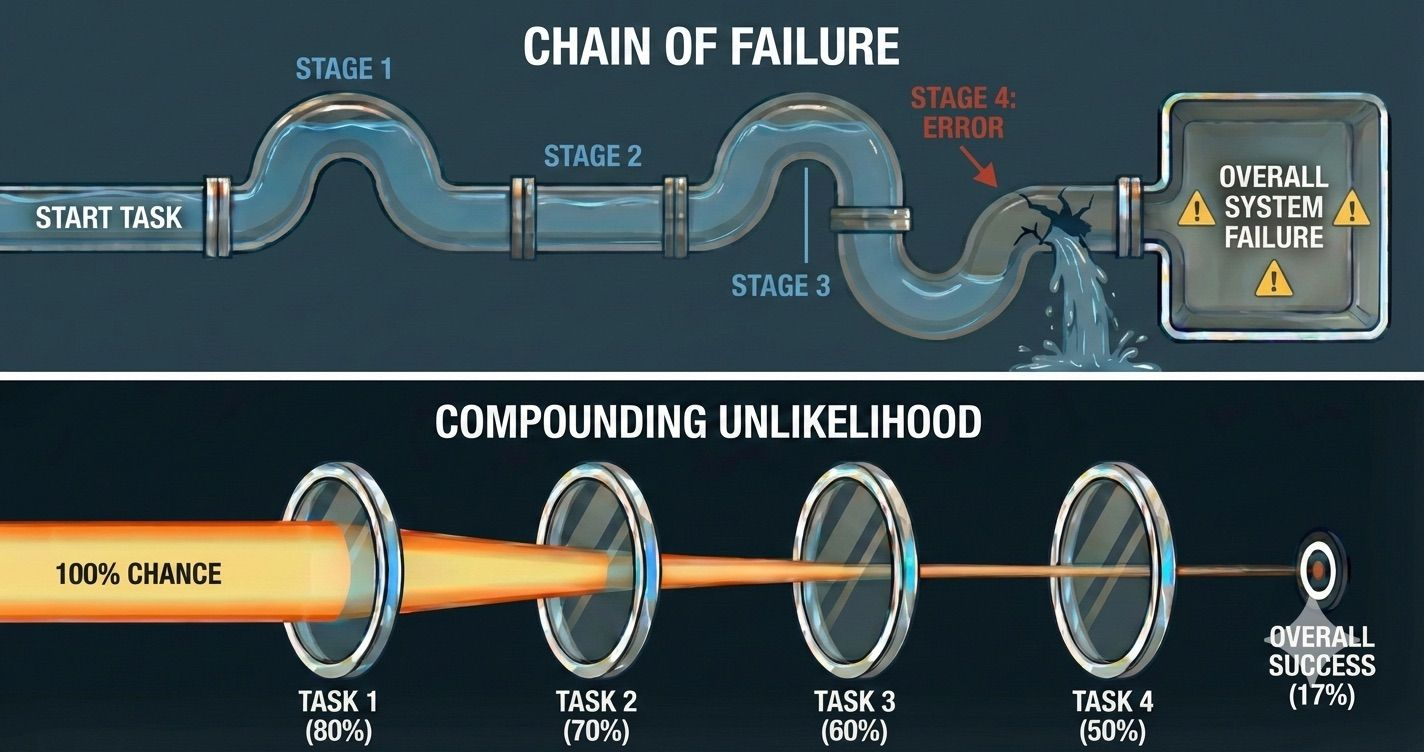
3.1.2 Agentic任务的稀疏奖励
当成功轨迹稀缺时,精细化、有信息量的奖励信号对与引导模型的探索与学习至关重要。遗憾的是,多数Agentic任务仅在最终阶段进行评估(例如单元测试是否通过)。实际上,即使想要为每个独特的任务设计并验证精细化奖励函数,其高昂的成本以及难以规模化的特性也会让研究者和工程师们望而却步。
这种稀疏性极大影响了训练中的奖励分配。一次端到端的失败意味着整个轨迹获得负奖励并且模型除了知道"在某处失败"外得不到任何有效的训练信息。这导致失败前后所有宝贵进展(如前期环境设置和后期调试尝试)最终都会被浪费。
⚠️
最终不可避免的结果是:训练过程中Agent必须执行大量推演来积累成功案例,从而强化轨迹中的正确动作。这使得复杂Agentic任务的RL训练极度低效且昂贵。
3.2 游戏设计中的启示
让我们转向游戏领域——这个对RL研究者而言既熟悉又友好的领域。为避免重复失败带来的挫败感,游戏设计师通常精心设计各种机制来减少无效的重复,帮助玩家将练习聚焦于最困难的环节。
3.2.1 用检查点保存中间状态
在魂系游戏中,玩家常需击败大量杂兵才能挑战强力BOSS。如果每次失败都需重走前置流程,这将使游戏过程变得枯燥且阻碍玩家学习对战BOSS的技巧。
篝火机制通过在BOSS战前设置检查点解决了这一问题。每次失败后,玩家将在篝火处重生,从而跳过重复的跑图环节,快速对战BOSS。这使得玩家可以始终聚焦于练习难点。

🤔
同理,如果我们在Agentic任务的交互轨迹的中间状态设置检查点,就可以控制模型生成/交互的起始位置,从而跳过前缀阶段的生成过程,直接把环境初始化到在尚未掌握、需要学习的任务前。
3.2.2 先练习后半段,再练习前半段
在《超级马里奥制造2》的长距离、高难度关卡中,玩家通常在前半段屡屡受挫,根本见不到后半段的关卡,更无从练习。好不容易凭借一定运气完成了前半段,也往往因为疏于练习而在后半段光速失败。
为了解决这一问题,地图创作者往往设置了传送门或者管道,让玩家可以直接进入后半段并练习相关技巧。当玩家熟练掌握后,再从前半段开始尝试。这确保了玩家一但能通过前半段,就有很大概率可以通关游戏,大大降低了完整通关的练习难度。

练习门允许玩家直接练习后半段,从而避免在前半段反复失败。(由Gemini辅助生成)
🤔
同理,如果我们可将Agentic环境重置至中间状态,让模型优先练习任务后半段。这能缩短子任务数量和交互轮次,更容易达成最终的成功,从而提高获得正向奖励的概率。然后再从头开始训练时,由于已经熟练掌握了后半段,模型也更容易端到端完成任务。
基于这两点洞察,我们确定了Rollback的核心逻辑:引入检查点,沿成功轨迹从后向前训练Agent。通过先掌握后期较易的后缀部分,再逐步向前推进延长任务长度,Rollback有效构建了循序渐进的课程学习逻辑,缓解了直接端到端生成的成功率极低所导致的正向信号匮乏的问题。
3.3 思想实验
为深入理解Rollback的重要性,可以尝试下面这个简单思想实验
假设任务由n个顺序子任务构成,每个子任务独立且成功的概率均为p。当且仅当所有n个子任务都完成时,才获得正向奖励。设模型需要m次获取正向奖励才能掌握子任务(使其成功率达100%)。我们的最终目标是让模型熟练掌握整个任务。
- 端到端生成:一次生成完全成功的轨迹的概率为p^n。于是模型平均需要\frac{m}{p^n}次尝试才能收集到m个正向奖励信号,从而将所有的子任务成功率提升到100%。
- Rollback:模型从最后一个子任务开始训练并逆向回溯。每个子任务平均需\frac{m}{p}次尝试才能收集到m次正向奖励。掌握全部n个子任务的总成本仅需\frac{mn}p尝试。
这意味着使用Rollback的模型掌握整个任务所需的生成次数是端到端生成的\frac1{np^{n-1}}倍!对于n=8, p=\frac12且任意m的情况,相当于生成成本只需要原先的\frac1{16}。
4. 实践中的Rollback(How)
4.1 真实Agentic环境中的挑战
尽管Rollback在概念上极具吸引力且效果显著,但在实际训练环境中部署该方法还需要许多实践细节。
4.1.1 复位至可解的中间状态
在真实Agentic环境中,检查点的引入面临着不小的挑战。因为这些检查点必须既正确又易于恢复:一方面手动构建的中间状态难以扩展,且容易遗漏隐藏的先决条件,导致检查点无效或不可解;另一方面,在涉及工具调用的环境中可靠地将环境重置到检查点并非易事。动态的外部依赖和某些环境副作用使得静态保存环境文件的操作方式不仅成本高昂,并且往往十分脆弱且不可预测。
🔑 解决方案
我们摒弃手动设计中间状态并通过静态快照恢复的做法,转而通过重放成功的参考轨迹的历史动作来重置环境。此方法将复现相同的工具调用和副作用,使Agent进入可靠的中间状态。该状态因构造过程而有效,且具有可解性——专家轨迹已证明任务可从该点精确完成。
注:某些情况下,重放成功轨迹仍可能导致重置失败(例如不可重放的副作用)。可通过预过滤来缓解:训练前对每条轨迹进行端到端重放,剔除无法可重复地验证成功的轨迹。
📌真实Agentic任务示例:时效性OTP认证
设想一个需要短时效一次性密码(OTP)的部署任务。在运行 deploy.sh前,Agent必须调用内部OTP API获取新密码(有效期约60秒),并将密码写入本地文件 ./.deploy_otp供部署脚本读取。
静态环境快照会恢复已过期的OTP文件导致认证失败。而动作重放技术通过重新执行"请求OTP→解析响应并写入密码"的前缀操作,能在当前条件下获取有效OTP,使重置过程具备对时间敏感的外部服务的鲁棒性。

4.1.2 定位真实的瓶颈位置
另一个实际难题在于如何将检查点精确定位到真实的难点之前。在Agentic任务中,手动定义的“困难”环节并不可靠:某些对人类专家看似简单的操作可能正是Agent悄悄犯错导致运行失败的节点。这些故障点高度绑定特定环境和特定模型,因此手工设置的检查点很少能在不同任务或训练阶段通用。
当检查点设置不当且远离实际的失败步骤时,Rollback会因重复执行多余的前缀操作而浪费算力。此外,过早的检查点可能同时覆盖过多瓶颈,最终还是会导致正向奖励稀疏。
🔑 解决方案
我们不采用预先估算步骤难度,而是通过从终点逆向逐步回溯轨迹并实时监测当前位置成功率,在训练过程中动态定位当前模型的瓶颈。一旦成功率跌落到阈值以下,即表明模型在当前状态处于以下情况之一:a)缺乏执行某个子任务的所需技能;b)无法稳定执行后续的多个子任务。
这种基于成功率的瓶颈检测机制,规避了人类对"难度"的主观预设,能够精准定位当前任务与模型的真实失败点,确保在最精确且采样效率最高的位置进行设置检查点并进行重置。
📌真实Agentic任务示例: run.sh 路径陷阱
设想一个编码任务:用户要求在仓库的根目录保存一个脚本文件 ./run.sh作为入口。Agent可以正确实现功能、通过测试甚至生成有效脚本,却将其保存至 ./scripts/run.sh而不是 ./run.sh导致最终没能通过验证。
若在普遍认为“硬核”的环节(如规划、编码、调试)前手动设置检查点,将缺少在真正失败的脚本路径设置这一环节的检查点。因此每次失败后的重试,都需要从较远的位置初始化,反复重新生成冗长的前缀路径,最终才抵达这个微小却致命的错误。更糟的是,由于检查点过于靠前,可能会隐含捆绑多个下游瓶颈,大大增加了子任务难度,导致正向奖励稀疏且学习速度减缓。
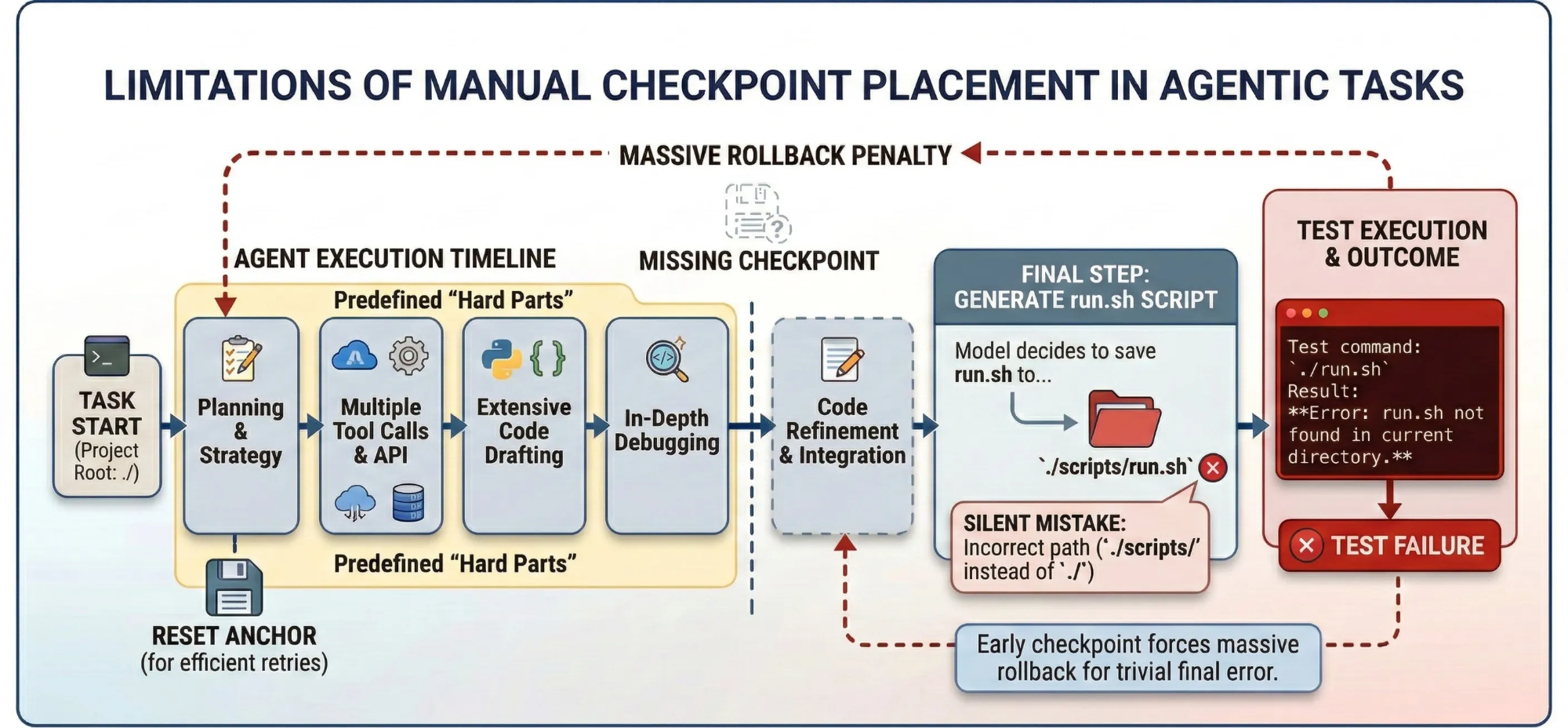
4.1.3 参考轨迹的来源
获取正确的成功轨迹通常不会特别困难。但在任何实际的Rollback落地中,这都是不可避免的重要步骤,并且其中存在若干值得探讨的实践细节。实际应用中,此类轨迹主要来自三个来源:
自行生成
通常在任务生成时,我们会预先用待训练模型运行生成多条轨迹确认任务难度。在此过程中,模型偶尔会取得成功,我们可保留这些罕见的成功轨迹。
专家模型
在目标模型初始成功率接近为零的困难任务中,可借助更强大的通用模型(或专用工具使用型Agent)生成初始解法。这通常是启动Rollback的最快速途径。
人工设计
对于涉及安全、脆弱或需要专业领域知识的任务,工程师也可手动构建成功轨迹并进行验证。
参考轨迹的两大特性值得关注:
更短更简洁的轨迹通常更有效,但无需一开始就追求完美。
通常更简洁的轨迹可以通过缩短交互轮次来加速学习。但最短不一定最好:激进地移除所有出错的工具调用,也可能扼杀了早期的探索和试错行为(如尝试调用第三方库来确认是否需要安装依赖)。这些尝试往往是任务前期采集环境信息的关键环节。
轨迹具有可替换性。
随着训练推进,模型自身常会生成更优解法。系统可定期汰换参考轨迹集,用新的轨迹替换旧轨迹,使参考轨迹与当前能力保持同步。
4.2 实用Rollback策略(Sequential Rollback)
在实际的智能体训练环境中,我们具体采取以下步骤:
1.从终止状态附近开始。
回放专家成功轨迹中的动作,将环境重置至最接近终态的状态。
2.逐步回溯重置点。
沿专家轨迹逐步将起始状态前移。在每个候选重置步骤中,生成多次并计算模型的完成成功率。
3.通过成功率下降识别瓶颈区域。
当成功率跌破设定阈值时停止回溯。该点即真实的瓶颈区域,标志着模型实际失败的位置。
4.在瓶颈状态进行训练
在当前状态多次重置并生成,利用环境反馈更新模型,直至模型恢复高成功率。
5.重复回溯
重复相同的回溯-训练循环,直至模型能端到端完成完整任务。
这是Rollback最简洁直接的实现方式,我们称为Sequential Rollback。尽管结构简单,该流程已经足以应用在Agentic RL中,用于解决模型无法生成成功的端到端轨迹的高难度任务上的训练问题。通过将训练锚定在选定的重置点反复生成和迭代,并在能力提升时才向前逐步回溯,Sequential Rollback在极端稀疏奖励环境下也能利用课程实现有效学习。
📊基于回溯的课程学习(Sequential Rollback)的有效性
我们在极具挑战性的任务上开展RL实验。在此任务中,模型的端到端直接生成的初始成功率为0%。三幅子图分别展示了Rollback的核心机制及其有效性。
维持正向训练信号(左)
在始终从初始状态展开的传统RL采样方法(Baseline)下,轨迹成功率始终为零,既无正向奖励也无学习信号。Sequential Rollback则将Agent重置到参考轨迹的中间状态,使其一直有机会完成任务来获取正向奖励并进行优化。值得注意的是,训练成功率曲线中的急剧下降意味着模型抵达了真实任务中的瓶颈区域。
渐进式回溯(中)
该曲线展示了基于Sequential Rollback的课程学习过程。训练始于任务末端的检查点——此时完成任务更容易。随着模型逐步掌握所需的子技能,重置点逐步前移,起点到检查点的前缀逐渐缩短,意味着留给模型的部分变长,任务难度增加。
测试阶段的端到端能力提升(右)
相较于基础RL,Sequential Rollback显著提升了端到端测试成功率,使Agent能够在极端困难任务中进行RL训练——即便一开始模型完全无法完成这个端到端任务。
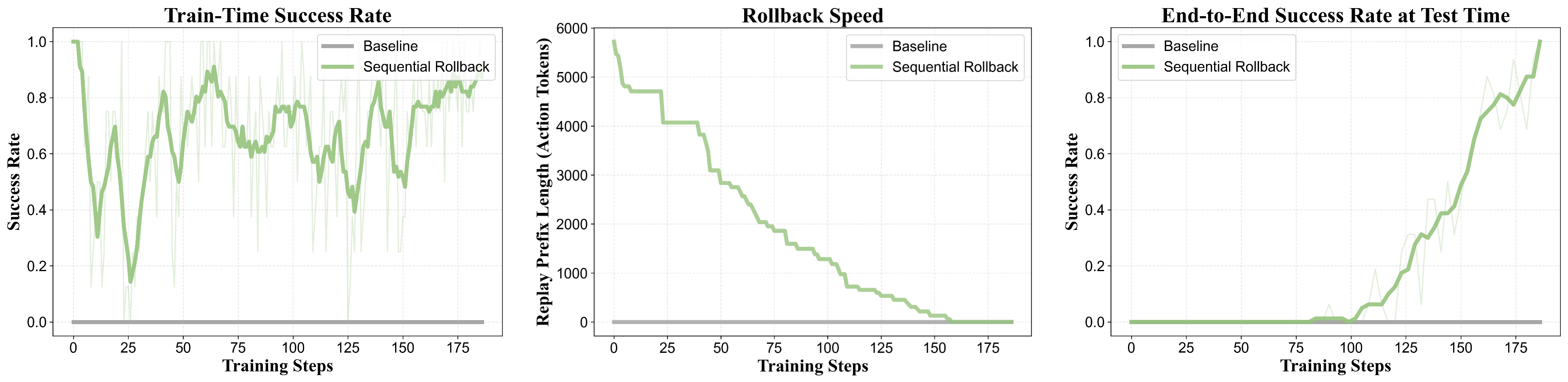
5. Rollback的变体
5.1 启发式步长加速Rollback
在多数情况下,固定为1的回溯步长过于保守——当模型表现良好时,无需探测每个中间状态。Heuristic Sequential Rollback是Sequential Rollback的一种自然扩展:不采用固定步长,而根据当前状态的成功率启发式地动态调整在stepk处的回溯步长\delta。
当成功率\hat{p}_k远高于阈值\theta 时,可一次性跳过多个步骤以加速进程;当成功率较低时,则减速至单步回溯,以更精细地定位瓶颈。
5.2 利用并行加速训练
假设真实瓶颈位于轨迹起点附近。此时Sequential Rollback与Heuristic Sequential Rollback都无法提供直接的捷径:模型必须从后向前遍历整条轨迹才能发现瓶颈,无论这些中间状态的难度如何。
与其从终点开始顺序探测状态,不如在轨迹上均匀设置多个起始点。每个起始点独立执行Sequential Rollback流程,从而能同时发现轨迹不同区域的瓶颈。我们称之为Parallel Rollback。
然而这种方法存在明显的成本代价。从多个中间状态并行启动生成会成倍增加资源使用。若保持总Batchsize不变,每个并行的采样数量都会减少,将会降低整体训练效率。 此外,从轨迹的早期状态启动的Sequential Rollback仍可能面临稀疏奖励——因为模型尚未熟练掌握后续部分。
尽管这一方法目前看起来并不实用,但是提供了一种无视轨迹长度快速定位瓶颈区域的思路,为后续的优化提供了基础。
5.3 解耦搜索与学习
为了缓解并行加速带来的速度与成本的跷跷板,我们选择解耦搜索与学习这两个阶段:
1.搜索:从多个初始状态并行启动生成,根据每个位置的生成成功率快速识别瓶颈区域。
2.学习:将生成和学习的预算集中于瓶颈状态进行聚焦训练。
3.循环:解决当前瓶颈后,在当前状态之前的轨迹上重启并行搜索,并重复以上过程。
这种将搜索和学习解耦开来的方法(Search-Learn Rollback)通过交替进行并行搜索和学习,逐步缩小搜索空间,确保训练过程中生成预算始终用在最关键的地方。这种方法很好地平衡了Parallel Rollback中关于训练资源和训练速度的博弈,实现了效率和成本的兼顾。
在Search-Learn Rollback中,各个阶段都有充分的设计与优化空间。下文提供一种具体实现这一算法的伪代码,从而让我们的描述更具体,算法更清晰:
📌 详细伪代码
Algorithm: Search-Learn Rollback
─────────────────────────────────────────────────────────────────────
Input:
τ* : expert success trajectory [s_0, s_1, ..., s_T]
N : total rollout budget per instance = 8
N_anchor : number of search anchors = 8
N_probe : rollouts per anchor during search = 1
θ_high : upper success rate threshold = 0.5 ~ 0.75
domain : current search domain = [0, T]
Output:
A model capable of completing the full task from s_0
─────────────────────────────────────────────────────────────────────
function SEARCH-LEARN-ROLLBACK(τ*, domain):
while domain is not fully resolved:
── Phase 1: SEARCH ──────────────────────────────────────────
// Uniformly place anchors across current search domain
anchors ← UNIFORM_SAMPLE(domain, N_anchor)
// Probe each anchor with a single lightweight rollout
for each anchor s_k in anchors:
p̂_k ← ESTIMATE_SUCCESS_RATE(τ*, s_k, n_rollouts=N_probe)
── Phase 2: SELECT CHECKPOINT ───────────────────────────────
// Scan from start to end: find first anchor where p̂ > 0
s_i ← first s_k in anchors (0 → T) where p̂_k > 0
if s_i == None:
// Model fails everywhere in the domain
// No reliable footing found — reset to the end
s_c ← s_end
else:
// Anchor at s_i
// to gradually bridge toward the failure region
s_c ← s_i
── Phase 3: LEARN ───────────────────────────────────────────
// Concentrate full rollout budget at selected checkpoint
repeat:
LAUNCH_ROLLOUTS(s_c, n_rollouts=N)
UPDATE_MODEL()
p̂_c ← ESTIMATE_SUCCESS_RATE(s_c, n_rollouts=N_probe)
until p̂_c ≥ θ_high
── Phase 4: RESTRICT ─────────────────────────────────────────
// s_c is now resolved; shrink search domain to its left
domain ← [0, index(s_c) - 1]
📊不同Rollback变体对比
为更直观展现不同Rollback变体相对于基础Sequential Rollback的加速效果,我们在实验中对比了各变体在同一个高难度任务集上的训练情况,以端到端测试成功率随训练进行的变化趋势。
结果表明,Heuristic Sequential Rollback与Search-Learn Rollback均显著加速了训练进程。其中Search-Learn Rollback表现略优,这也许可以归功于其并行搜索机制相较于人工设定的启发式规则更加的可靠。
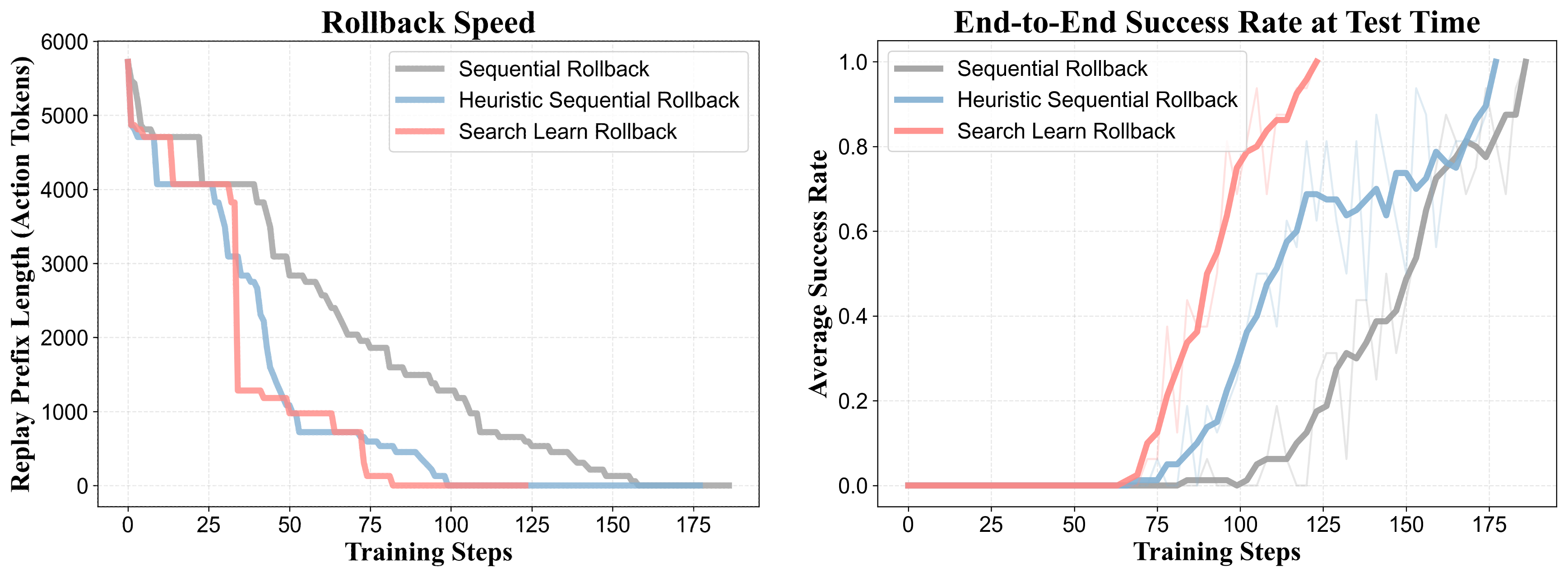
注 本对比未纳入Parallel Rollback ,因其实证表现欠佳:在同等成本预算下,学习速度过慢。
6. 补充说明
当模型在关键子任务中成功率持续为零时,Rollback仍可能失败,这种情况通常归咎于模型缺乏必要知识或工具使用经验。此时强化学习无法提供学习信号,因为交互过程永远无法达到成功状态。
实际应对方案是采用参考轨迹的专家行为进行模仿学习(如在相关动作上应用SFT),直接教会模型正确的动作并将模型成功率拉升。当模型能从该状态偶尔成功时,即可回归Rollback方法,以确保鲁棒性与泛化能力。
7. 总结
本文提供了关于Rollback算法的全面详解:核心算法、设计动机,以及在真实智能体环境中实现该算法的关键工程考量。 从宏观层面看,Rollback通过成功的参考轨迹构建了时序课程:训练始于接近终点的检查点(剩余路径最短,成功概率最高),随着模型可靠性提升,起点逐步回溯至更早检查点,直至Agent能从原初始状态端到端完成任务。
Rollback之所以重要,在于它使强化学习能在长时限、高难度Agentic任务中可行——通常模型在这类任务的初期成功率极低,奖励极其稀疏。通过优先聚焦部分子任务进行学习,并逐步扩展待解决的任务长度Rollback减少了前缀阶段的重复生成与失败,使模型能从靠后的中间状态完成任务,从而显著提升正向训练信号的密度。
在介绍了如何在真实环境中使用Rollback后,我们还探讨了多种变体。尽管这些变体在优化空间和设计选择上仍有很大提升余地,但它们都共享同一个根本目标:提高采样和学习效率,将有限的生成和训练预算分配给最关键的地方。
English Version:https://warm-pajama-44a.notion.site/Save-Load-and-Learn-Boosting-Agentic-LLMs-via-Rollback-based-Curriculum-Learning-687a76d7970e831a91c501bafd9c7b2b
ROLL TEAM:https://wwxfromtju.github.io/roll_team.html
技术报告: https://arxiv.org/pdf/2512.24873
模型: https://huggingface.co/FutureLivingLab/iFlow-ROME
框架:
1.RL训练框架: https://github.com/alibaba/ROLL
2.沙盒环境管理: https://github.com/alibaba/ROCK
3.Agent框架: https://github.com/iflow-ai/iflow-cli
Benchmarks: https://github.com/alibaba/terminal-bench-pro