

MLA能够在MHA/MQA之间等价切换,使其在训练推理时都能保持高效。然而MLA是针对H100进行设计的,对于H20这一类计算瓶颈的显卡,推理效率不如GQA。
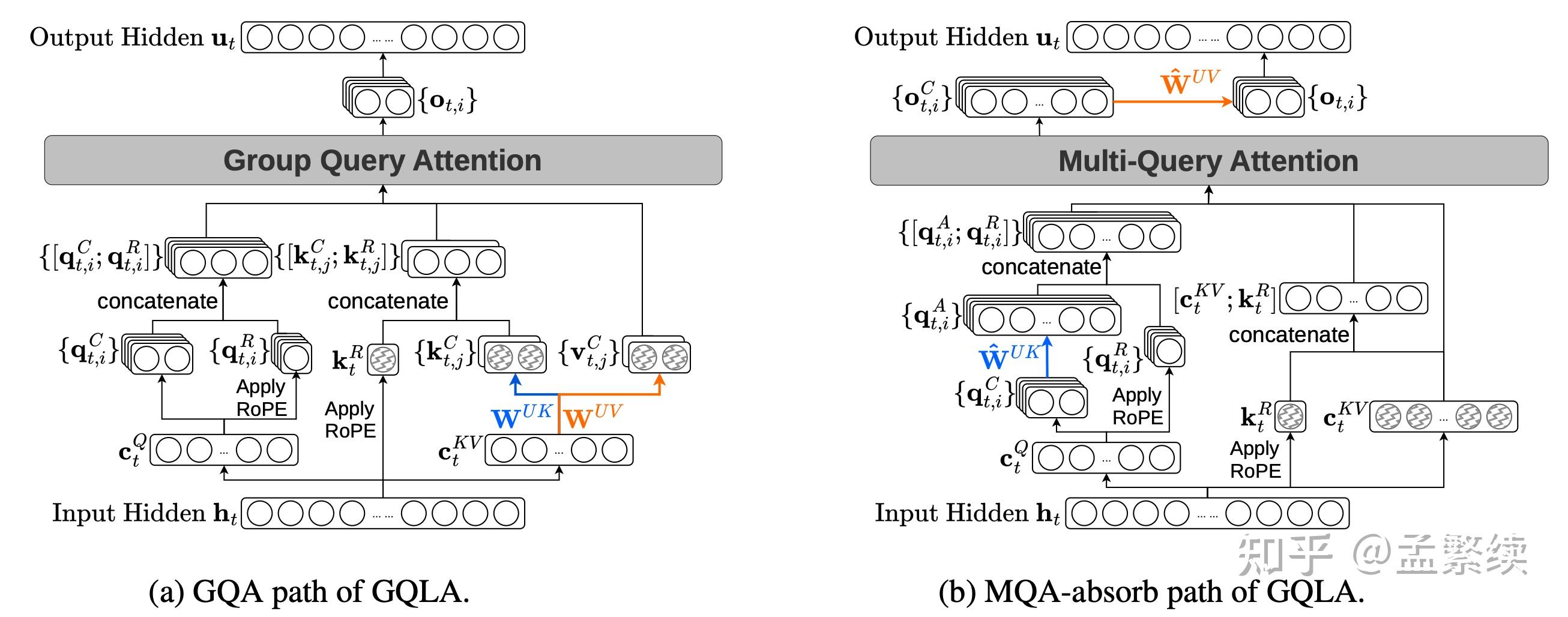
本文提出GQLA的设计,在GQA/MQA之间等价切换。对于H100用MQA减少KV Cache;对于H20用GQA减少计算量。允许一个预训练模型同时能在旗舰卡和入门卡都达到最优的推理速度。
一人独作 GQLA!挑战 DeepSeek 的 MLA、DSA
无需从头训练,进一步提出MLA/GQA低损失转GQLA的方法,以允许通过少量训练恢复模型效果。
6月16日(周二)晚8点,青稞Talk 第 132 期,北京大学博士、小红书REDstar基模组员工孟繁续,将直播分享《从 MLA 到 GQLA:无需从头训练,硬件自适应高效注意力机制》。
分享嘉宾
孟繁续,北京大学博士,腾讯青云实习生,小红书REDstar基模组员工。研究方向为高效模型结构推理和训练方法,以第一作者身份发表顶会论文7篇。代表作TransMLA (NeurIPS 2025 Spotlight) 被蚂蚁Ling-2.5-1T大模型使用,大幅减少预训练开销;代表作PiSSA (NeurIPS 2024 Spotlight)被peft等多个万star开源项目收录。
主题提纲
从 MLA 到 GQLA:无需从头训练,硬件自适应高效注意力机制
1、从 MLA 看大模型架构的硬件挑战
2、GQLA 核心架构:分组查询潜在注意力
3、H100/H20 硬件自适应部署
4、TransGQLA:实现“零成本”模型架构转换
5、探索 Sparse GQLA & AMA (Ask Me Anything)环节
直播时间
6月16日(周二)20:00 - 21:00