作者:孟繁续
https://zhuanlan.zhihu.com/p/2039637653314856841
文章链接:https://huggingface.co/papers/2605.15250
代码链接:https//github.com/MuLabPKU/TransArch
GQLA的前作:TransMLA被蚂蚁百灵2.5-1TB参数大模型使用,从2.0的GQA结构转为MLA结构,大大节省了预训练的token数。
Ling 2.5 Lightning Attention+MLA混合线性架构改造实践
我为什么会想写一篇一人独作的文章?
当我开始做模型结构设计之后,有很多想法想要验证。但是精力和能力有限,因此都是挑自己目前最有可能做出来的想法来推动。
这次的GQLA也是一年前的idea,这一年期间,每次碰到MLA、DSA存在什么缺点,频频想到这个idea。
不过总是有更紧急的事情要做,有多方的诉求要去协调。终于最近短暂的卸下了对导师、对公司、对同学的责任 - 我即将毕业,也从陪伴我读了研究生和博士生的腾讯优图离职了。
比起利用这段空档期出去玩玩,我更想做一些更有意思的事情。于是就有了这篇文章。
至于为什么是一个人完成?因为我能自由支配的时间窗口很短。所以本文完全没有做任何实验,仅仅是把我的idea给细化了一下,讲清楚了motivation和方法的优缺点。
未来这一方法能否scaling上去,结合真实硬件的表现如何,还需要同新的合作伙伴一起完成。当前这个时代,团队力量压倒一切,个人研究者的生存空间越来越小了。
作为一个科研乐子人,我最初很想搞个噱头。但是在真的在写这篇文章的时候,越写越满意。
这篇文章做了什么?MLA只适合计算能力很强,访存是显著瓶颈的硬件(如H100),而GQLA不仅在H100上能发挥出同样的性能,在H20这种计算能力受限的硬件上,也能达到完美的计算-访存平衡。
计算强度
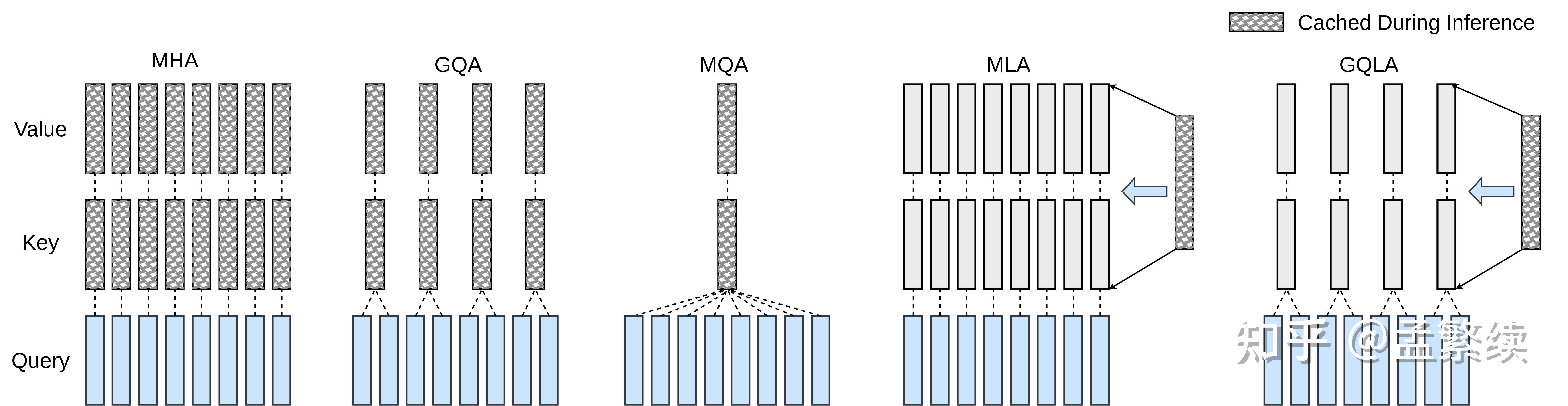
现代大语言模型(LLM)的预训练和预填充阶段受限于计算量大小;自回归解码受限于键值(KV)缓存访存:每生成一个新 token,都必须从片外内存读取整段历史的键和值。因此,如何平衡计算和访存是一个重要课题。MLA 的一个核心设计是:它训练好的权重支持两条数学等价的执行路径:
1.在训练和prefill阶段,潜在向量被还原为按头切分的 K、V,注意力以类 MHA 的形式计算——这是计算受限路径,可以减少计算量。
2.在解码阶段,K、V 的上投影矩阵被"吸收"进查询投影和输出投影,注意力直接在潜在向量上计算,呈类 MQA 形式——这是访存受限路径,可以最小化 HBM 流量。
计算强度的计算公式为 计算强度=\frac{计算量}{访存量} 。在 NVIDIA H100 上,BF16 Roofline 的拐点(ridge point)大约在 295 FLOPs/byte。在典型配置 ( h_q, d_h, r_{kv}, d_h^R)=(128, 128, 512, 64)、单token 解码s_q=1下,MLA 的吸收 MQA 路径计算强度为
FLOPs/byte,正好压在拐点之下,几乎榨干了硬件可达的吞吐。然而一旦开启 Multi-Token Prediction (MTP) 让 s_q \ge 2,I_{\text{MQA}}就会翻倍——s_q = 2时 I_{\text{MQA}}\approx484,跳到 H100拐点之上,MLA-absorb在 H100 上也会变成compute-bound,MTP 的理想2\times吞吐增益缩到 \sim 1.22\times.换句话说,MLA在H100上的"完美Roofline"只对s_q = 1成立。
MLA 的三个硬件缺点:
MLA在H100、单token解码、不开MTP这三个条件全部成立时近乎完美;但只要其中任何一个被打破,它就会从 Roofline 上掉下来。
具体地说,MLA 把自己结构性地锁死在 MQA-absorb 路径一条路 I_{\text{MQA}}\approx484 径上,由此引出三个互相独立、又彼此耦合的缺点:
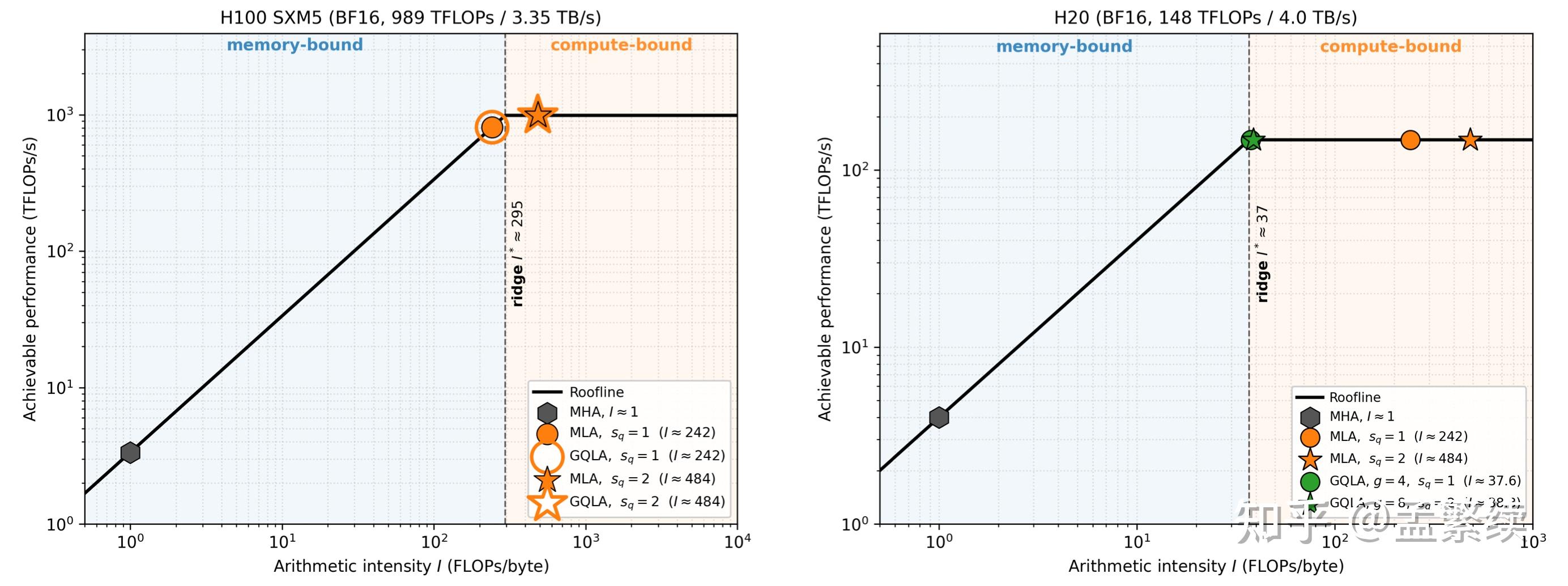
缺点 1(硬件耦合): MLA 是为 H100 这种"算力相对带宽更富余"的卡定制的,对 H20 这类"算力相对带宽更稀缺"的卡不友好。MLA 的优势锚定在 H100 的"计算/带宽"比例上:H100 拐点 \sim 295 ,MLA 工作点 \sim 242 ,正好压在拐点之下。
但 H20 保留约 4 TB/s 的 HBM 带宽,BF16 算力只有 148 TFLOPs,拐点下移到 \sim 37 FLOPs/byte——MLA 工作点 \sim 242 远高于 H20 拐点 \sim 6.5\times,解码变成 compute-bound。
MLA 在 H20 上结构上只剩 MQA-absorb 一条路径:所有 h_q 个查询头都要为"宽度为 r_{kv} + d_h^R 的潜在向量"付出全部 FLOPs,单步 15.42\,\mu\text{s}、吞吐 65 K tok/s,比同卡上GQLA的GQA路径慢 \sim 3.4\times。
缺点 2(TP 不友好): MQA-absorb 路径不支持沿头/组轴的张量并行。吸收形式下所有查询头共享同一份潜在 KV,做张量并行时必须把这份KV在每张卡上复制一遍。
MLA 在推理时因此只剩下数据并行和序列并行两条路——这对常见的 4–8 卡 H20 节点而言是一个相当尴尬的约束。
缺点 3(MTP 不友好): 开 MTP 后 MLA 在 H100 上也跌出 Roofline。Multi-Token Prediction (MTP) 让每步解码 s_q\ge2个token,是 DeepSeek-V3 默认开启的功能。
但 MLA 的工作点关于s_q线性翻倍——s_q = 2时,跳到 H100 拐点 \sim 295 之上,MLA-absorb 在 H100 上也变成 compute-bound,MTP 的理想 2\times 吞吐增益缩到 \sim 1.22\times,H20 上则是雪上加霜——本就 compute-bound的MLA用时随s_q 线性翻倍,MTP吞吐增益为0。
换句话说,MLA 在 H100 上的"完美 Roofline"只对 s_q = 1 成立,且 MTP 在 H20 上对 MLA 完全无效。
GQLA:一并解决 MLA 的三个缺点
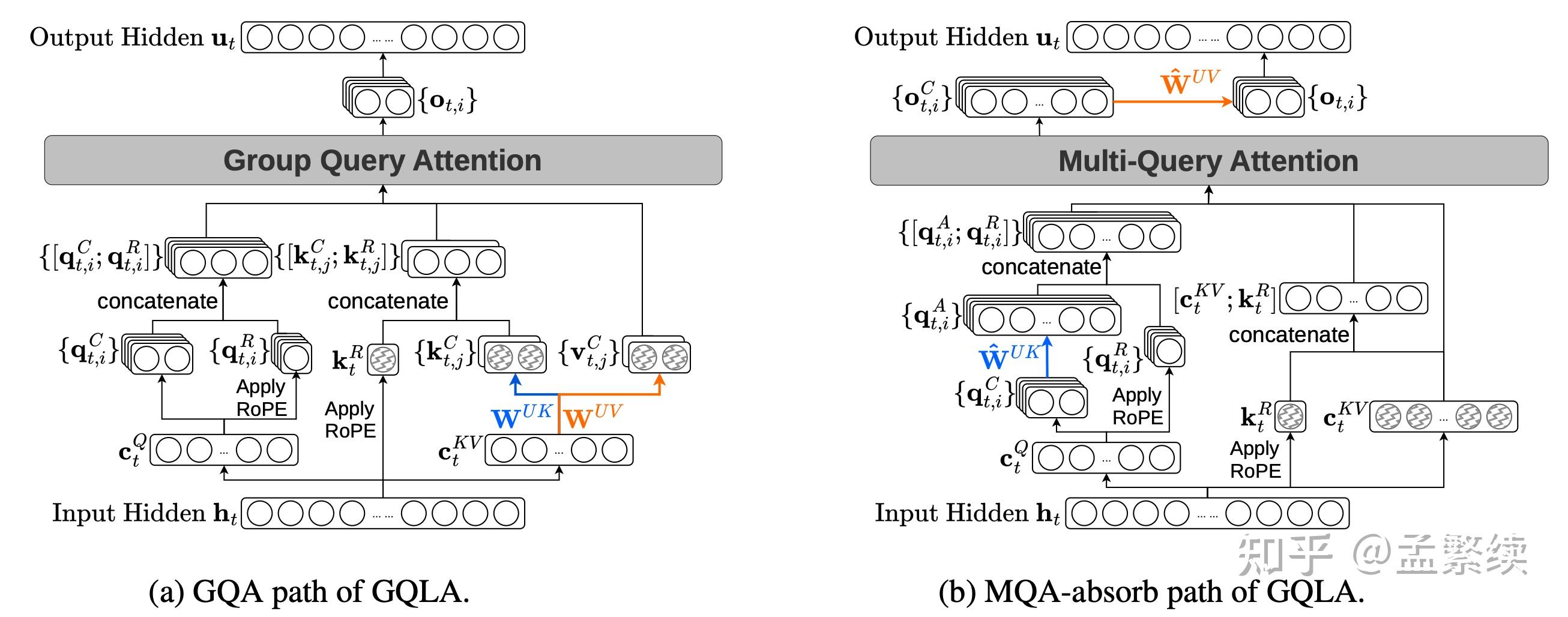
我提出MLA的一个简单变体,称为 分组查询潜在注意力(Group-Query Latent Attention, GQLA)(参见图 1 最右;以及图 2)。
GQLA 保留了 MLA “将键和值联合压缩到低秩潜在空间”的设计,但上投影仅按 g 个组索引(而不是像 TransMLA那样进一步复制到全部 h_q个查询头)。这样得到的训练权重在算法上同时支持两条数学等价的解码路径,每条路径对应一种自然的缓存内容:
MQA-absorb 路径(与 MLA 共用):缓存潜在向量\mathbf{c}^{KV}与共享 RoPE 键\mathbf{k}^R,每 token仅r_{kv}+d_h^R个元素;把上投影 W^{UK}, W^{UV}吸收进查询/输出投影后,全部h_q个查询头直接对潜在向量做注意力——正是MLA在H100上飞起来的工作点。
GQA 路径(仅GQLA可用):缓存按组展开后的g个K_C, V与共享 RoPE 键,每token共 2 g d_h + d_h^R 个元素(结构上接近一个标准 g 组 GQA 模型,仅多出 d_h^R 个共享 RoPE 元素);解码走标准 GQA,无需在每步展开潜在向量。
对应到上一节的三个缺点——
| MLA 的缺点 | GQLA 的解决方案 |
|---|---|
| ① 硬件耦合:H100 友好、H20 不友好 | 部署时按硬件挑路径:H100 走 MQA-absorb 路径贴 H100 ridge;H20 走 GQA 路径贴 H20 ridge。 |
| ② TP 不友好:MQA-absorb 不支持沿组轴的 TP | GQA 路径的 g 组结构与标准 GQA 一样,原生支持沿组轴的 g 路零冗余张量并行(g = 8 直接覆盖常见的 8 卡 H20 节点)。 |
| ③ MTP 不友好:MLA 在 H100 上开 MTP 跌出 Roofline,在 H20 上 MTP 吞吐 0 增益 | g = 8 配合 s_q = 2正好把计算强度推到 38.8 贴近 H20的拐点 37,MTP 在 GQA 上给出接近理想的 2倍加速。 |
最佳配置:h_q = 128,\ g = 8(即 128 个查询头、8 个 KV 组),加 1 个 MTP 头。 这一组训练权重同时是两类硬件的 Roofline 最优工作点:
- H100 部署:选 MQA-absorb 路径,关闭 MTP 跑 s_q = 1,I_{\text{MQA}} \approx 242 压在拐点 \sim 295 之下,单步 attention 2.82\,\mu\text{s},与 MLA 工作点一致;
- H20 部署:选 GQA 路径,开 MTP 跑 s_q = 2,I_{\text{GQA}} \approx 38.8 压在拐点 \sim 37 上,单步 attention 9.06\,\mu\text{s} 同时饱和带宽与算力。
两边共用同一组权重和同一个 MTP 头,无需重训,也无需修改 kernel(MQA-absorb 路径复用 MLA-absorb kernel,GQA 路径复用现成的 GQA kernel)。
MLA 由于结构上没有 GQA 路径这个退路,在 H20 上必然 compute-bound(缺点 ①)、TP 受限(缺点 ②)、MTP 失效(缺点 ③);GQLA 这一组配置一次性把三个缺点都消掉。
TransGQLA:避免从零预训练
从零预训练一个 GQLA 模型代价高昂。我们因此扩展TransMLA 得到TransGQLA——对于预训练好的MLA模型,通过TransMLA第一步进行多头合并,然后做低秩压缩,就能很轻易的得到GQLA。
我将GLM-4.7的20个kv head每5个相邻head压缩成一个head,得到qk head数为20:4的GQLA,不进行任何训练时,仅损失4.7%的表现。还可以把预训练好的 GQA 模型转换为 GQLA 模型。
复用了 TransMLA 全部阶段(头合并、RoRoPE、FreqFold、平衡后低秩压缩),仅在头合并阶段做了一处定向的修改:让上投影按”组”而不是按”查询头”做索引,从而让转换后的模型同时保留 GQA 与 MQA-absorb 两条数学等价的前向路径,进而支持按硬件二选一的部署。在 LLaMA-3-8B 上,TransGQLA效果与 TransMLA 保持一致。根据TransMLA的微调实验可以预期将MLA、GQA转换为GQLA也能够用很少训练量恢复模型的效果。
| Model | Tokens | Avg. | MMLU | ARC | PIQA | HS | OBQA | WG |
|---|---|---|---|---|---|---|---|---|
| GLM-4.7 | 20T | 69.14 | 73.82 | 69.00 | 88.00 | 70.00 | 38.00 | 76.00 |
| MLA→GQLA | 0 | 64.45 | 60.82 | 63.86 | 78.18 | 73.04 | 41.60 | 69.22 |
| LLaMA-3-8B | 15T | 63.84 | 46.20 | 65.75 | 80.47 | 76.20 | 45.60 | 68.82 |
| GQA→GQLA | 0 | 54.13 | 36.38 | 52.84 | 73.83 | 64.34 | 37.00 | 60.38 |
| GQA→MLA(sft) | 30B | 63.39 | 46.18 | 66.30 | 80.30 | 76.33 | 45.00 | 66.22 |
Sparse GQLA
DSA把”按 token 决定的 top-k 稀疏”加在 MLA 上,但稀疏 attention 的 MMA tile 要求每对共享 KV 头至少有 16 个查询头才能填满,因此稀疏 MLA 被结构性锁死在 MQA-absorb 路径,并且在 H20 上承担过高的计算开销。
GQLA 在典型配置 h_q / g = 16 下 GQA 路径正好对齐 MMA tile,因此稀疏 GQLA 可以在 H20 上走稀疏 GQA 路径训练和解码,在 H100 上仍可走稀疏 MQA-absorb 路径——稀疏与稠密下的”硬件挑路径”规则保持一致。
结论
我们指出了 MLA 的三个互相耦合的硬件缺点——(i) 仅对 H100 这类算力强卡友好,对 H20 这类算力削弱卡不友好;(ii) MQA-absorb 不支持沿注意力头的张量并行;(iii) 开 MTP 后 H100 上也跌出 Roofline、H20 上 MTP 吞吐 0 增益——并提出 分组查询潜在注意力(GQLA)一并解决这三点。
GQLA 对 MLA 的修改极小:上投影按组而不是按头索引,由此训练权重就同时支持两条数学等价的解码路径——
- MQA-absorb 路径:紧凑潜在缓存,cache 只有原 GQA 的 \sim 1/4;
- GQA 路径:按组展开缓存,cache 与原 GQA 量级相同(仅多 d_h^R 个共享 RoPE 元素)。
最佳配置:h_q = 128,\ g = 8(128 个查询头、8 个 KV 组),加 1 个 MTP 头——同一套权重对应两个 Roofline 最优工作点:
- H100 + MQA-absorb 路径 + s_q = 1:I_{\text{MQA}} \approx 242 压在 H100 拐点 \sim 295 之下,单步 attention 2.82\,\mu\text{s},与 MLA 工作点一致 → 解决缺点 ①;
- H20 + GQA 路径 + s_q = 2:I_{\text{GQA}} \approx 38.8 压在 H20 拐点 \sim 37 上,单步 9.06\,\mu\text{s} 同时饱和带宽与算力,MTP 给出 \sim 1.91\times 吞吐 → 解决缺点 ① + ③;同时 GQA 路径沿 g = 8 组轴原生支持 \le 8 路零冗余 TP → 解决缺点 ②。
两边复用同一组训练权重和同一个 MTP 头,部署时只需把 KV cache 一次性”压缩 / 展开”,无需重训、无需自定义 kernel(MQA-absorb 路径复用 MLA-absorb kernel,GQA 路径复用 GQA kernel)。
GQLA 也很自然地扩展到细粒度稀疏注意力:GQA 路径下”查询头/KV 组”比 h_q / g = 16 恰好对齐 Tensor Core 的 MMA tile,稀疏 GQLA 可以在 GQA 路径下训练和解码,而稀疏 MLA 在每张卡上都被结构性地锁死在稀疏 MQA-absorb 路径上。
为了避免从零开始预训练,我们提出了 TransGQLA——一套通过对 TransMLA 流水线做单一定向修改、把预训练好的 GQA 权重转换为 GQLA 模型的方案。根据 TransMLA 的训练轨迹推测仅需 \sim 60B token 的持续预训练就能恢复原始的常识推理精度。
我们希望 GQLA 能为同时面向旗舰与入门级推理卡的团队提供一个高效的 MLA 替代方案。
写在最后
尽管TransGQLA能够快速将现有GQA/MLA模型转换成MLA,但是GQLA能否取代MLA,被广泛使用,还要看分组的方式表达能力是否足够scaling上去。
稀疏GQLA相对DSA的算力节省能否体现出训练推理加速?另外H20卡的市占率是否能够撑到GQLA被训练出来的那一天?国产显卡是否是GQLA应用的一个重要场景?
接下来,我将会在小红书来回答这些问题,欢迎加入我们,一起训练新的Dots模型。