
大模型后训练会带来一个很现实的系统问题:模型会不断产生新版本。一次强化学习实验、一个产品功能、一个客户、一组评测结果,都可能对应一种新的模型行为。基础模型本身又非常大,动辄万亿参数规模。系统如果把每种行为都保存成一份完整模型,再分别加载和部署,成本会很快失控。
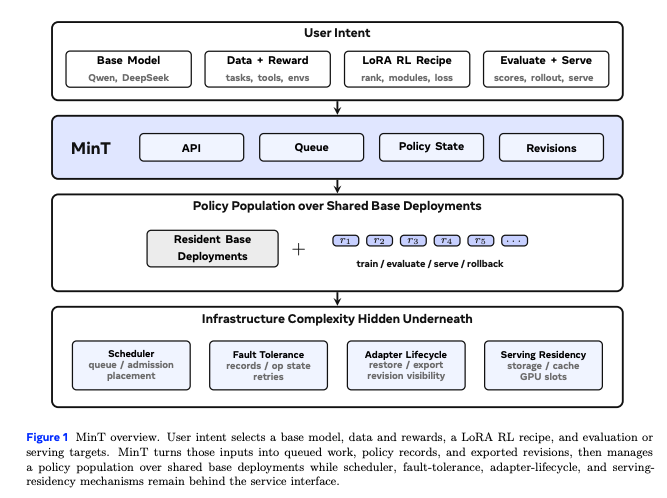
MinT 是一套面向这个问题的大模型后训练和在线服务系统。它的目标是让少数昂贵的基础模型,承载大量持续变化的模型行为。
MinT 把基础模型常驻在训练和推理集群里,每次后训练得到的变化用一个小得多的 LoRA 适配器保存。这个适配器可以理解成挂在基础模型上的能力版本:它记录某次训练学到的行为,之后可以被评测、选择、加载到服务系统中。
论文:MinT: Managed Infrastructure for Training and Serving Millions of LLMs
链接:https://arxiv.org/pdf/2605.13779
代码:https://github.com/MindLab-Research/mindlab-toolkit
这套系统从三个方向扩展。Scale up 关注模型能做到多大,MinT 验证到 1T 级总参数模型。Scale down 关注每次训练结果进入服务时要搬多少数据:LoRA适配器只有基础模型权重体积的约 3%。Scale out 关注版本数量能做到多大,MinT 支持百万级可请求版本目录,同时只让当前真正需要的少量适配器占用 CPU 和 GPU 资源

6月2日晚8点,青稞Talk 126期,Mind Lab 研究科学家陆逸文,将直播分享《MinT: 面向百万级 LoRA 策略的训练与推理基础设施》。
包括:当后训练让模型行为不断分叉时,怎样用 LoRA 适配器、版本记录、训练到服务的交接机制和多级缓存,把大模型系统从“部署少数完整模型”扩展到“服务海量轻量模型行为”。
分享嘉宾
陆逸文,Mind Lab Research Scientist,Head of Infrastructure,清华大学博士。当前兴趣包括大模型后训练基础设施、agentic RL、具身智能。主导 MinT 项目,关注如何把 LoRA 从参数高效微调方法提升为可训练、可评测、可推理的大规模基础设施。
主题提纲
MinT: 面向百万级 LoRA 策略的训练与推理基础设施
1、后训练为什么会让模型行为不断分叉
2、MinT 如何用 LoRA 适配器管理这些行为
3、MinT 的三个扩展维度:Scale up、Scale down、Scale out
4、大规模 LoRA 服务中的缓存和加载问题
5、AMA (Ask Me Anything)环节
直播时间
6月2日(周二)20:00 - 21:00