作者:张曜程,朱圆恒,赵冬斌@中科院自动化所
研究背景
智能体在训练过程中往往面临几个核心瓶颈,标注数据昂贵、奖励信号稀疏,以及长程任务中的信用分配困难。自博弈(Self-Play)提供了一条很有吸引力的路径:模型可以自己生成问题、自己学习解决问题,从而减少对外部训练数据的依赖。然而,现有自博弈方法大多只利用最终答案是否正确作为稀疏奖励进行优化。虽然这种方式能够推动模型的自我提升,但是稀疏的监督信号使得学习效率相对低下。
我们重新审视自博弈的任务生成过程,并提出一个关键观察:自博弈在构造训练任务时,不仅能生成问题和答案(QA),还天然产生了一个高质量但被忽略的中间产物:问题构造路径(Question Construction Path, QCP)。
在搜索场景中,Examiner 为了构造一个准确且可验证的问题,通常需要从答案或事实证据出发,经过多轮搜索、筛选与推理,逐步反向构造出问题。因此,QCP 记录了任务从证据到问题的生成逻辑,可以被视为一条反向求解路径。然而,由于QCP 不等同于 Student 解题时可直接模仿的专家轨迹,因而难以直接作为监督微调(SFT)的数据使用。现有自博弈工作通常会丢弃这一高质量中间产物,只保留最终的QA数据。
与此同时,自蒸馏(Self-Distillation)研究表明,同等规模但拥有特权信息的Teacher模型可以为Student采样的轨迹(rollout)提供密集监督,从而缓解稀疏奖励和信用分配的难题;然而,现有方法中特权信息的常见来源包括成功的推理轨迹、专家演示和先验知识。这些特权信息往往依赖人工专家、强模型或额外数据构造,使得自蒸馏难以大规模的扩展。
基于上述观察,我们关注一个核心问题:自博弈过程中天然产生的问题构造路径,是否可以作为自蒸馏所需的高质量特权信息?
我们的回答是肯定的。QCP 清晰的展示了问题的构建逻辑,天然包含了丰富的过程信息。因此,QCP可以作为Teacher模型的额外上下文,通过自蒸馏为Student提供Token级的密集监督。换言之,自博弈不仅能够自动生成训练任务,还能够以低成本、大规模的方式为自蒸馏提供高质量特权信息。
.png)
.png)
.png)
.png)
-HteY.png)
.png)
.png)
因此论文提出 π-Play (Privileged Information Self-Play),一个结合自博弈与自蒸馏的多智能体自进化的框架,与其他自进化的框架对比如图 1 所示。在π-Play中,Examiner 负责生成任务及其问题构造路径,Teacher 利用 QCP 作为特权上下文为 Student 提供 Token级监督,而 Student 则在密集反馈下持续提升自身搜索与推理能力。通过 Examiner、Teacher 和 Student 的协同进化,π-Play将稀疏奖励的自博弈变成了一个带有密集反馈的协同自进化过程,在无需外部标注或更强教师模型的情况下,实现了更高效、可扩展的大模型自进化。
论文链接:https://arxiv.org/abs/2604.14054
项目链接:https://github.com/zhyaoch/pi-play
工作概述
在训练过程中 π-Play 采用交替优化的自进化流程,如图 2 所示,算法的训练流程如图 3 所示。每一轮中,Examiner 根据当前 Student 的能力生成难度适中的任务及其 QCP。Teacher 读取 QCP,并基于这一特权上下文为 Student 提供 token 级监督。Student 则结合结果奖励和 Teacher 指导进行优化。随着 Student 能力提升,Examiner 会继续生成更具挑战性的任务,从而形成一个不断升级的自进化课程:
- Examiner:生成训练任务及其 QCP,并根据 Student 的表现调节任务难度。
- Teacher:访问 QCP 作为特权上下文,为 Student 提供 token 级密集监督。
- Student:仅看到训练任务本身,在结果奖励和 Teacher 的监督下共同优化。
Examiner训练损失
Examiner 会生成包含问题、答案和问题构造路径的三元组
。为了控制任务难度,Examiner会根据Student的回答成功率获得难度奖励:
其中
为指示函数。如果所有采样回答$$\{o_i\}^n_{i=1}$$都正确,则说明问题过于简单;如果所有回答都错误,则说明问题可能太难。只有当问题处于适中难度时,Examiner 才会获得更高奖励。基于这一反馈,Examiner 会不断优化自己生成的任务,使其更加适配 Student 当前的能力边界:
其中
和$${\pi_\theta^S}$$分别为Examiner和Student模型,$$A_{i,h}$$是基于难度奖励计算得到的归一化优势。
Student训练损失
Student 负责学习如何高效地解决任务,它的优化信号由两部分组成。一方面,Student 通过最终答案是否正确获得结果奖励,通过使用GRPO损失进行优化。另一方面,它通过自蒸馏学习 Teacher 提供的 Token 级的监督,从而缓解传统自博弈中信用分配的难题。
其中
为Teacher模型,自蒸馏部分的损失如下所示:
在这一过程中,Teacher 可以访问问题构造路径
,因此能够基于更丰富的上下文对 Student 提供可靠的监督,帮助 Student 判断每一次搜索和推理的生成是否合理。值得强调的是,Teacher是与 Student 相同尺寸的模型,因此 π-Play不需要依赖更强教师模型或人工构造的特权信息。
Teacher优化函数
为了使Teacher模型能够在利用特权信息的基础上做出更准确的搜索动作,同时避免 Teacher 与 Student 之间产生过大的策略偏差。论文采用了一种轻量的方式来对Teacher进行优化,即使用 Student 参数
的指数滑动平均(EMA)来更新 Teacher的参数$$\psi$$,
Examiner训练损失
Examiner 会生成包含问题、答案和问题构造路径的三元组
。为了控制任务难度,Examiner会根据Student的回答成功率获得难度奖励:
其中
为指示函数。如果所有采样回答$$\{o_i\}^n_{i=1}$$都正确,则说明问题过于简单;如果所有回答都错误,则说明问题可能太难。只有当问题处于适中难度时,Examiner 才会获得更高奖励。基于这一反馈,Examiner 会不断优化自己生成的任务,使其更加适配 Student 当前的能力边界:
其中
和$${\pi_\theta^S}$$分别为Examiner和Student模型,$$A_{i,h}$$是基于难度奖励计算得到的归一化优势。
Student训练损失
Student 负责学习如何高效地解决任务,它的优化信号由两部分组成。一方面,Student 通过最终答案是否正确获得结果奖励,通过使用GRPO损失进行优化。另一方面,它通过自蒸馏学习 Teacher 提供的 Token 级的监督,从而缓解传统自博弈中信用分配的难题。
其中
为Teacher模型,自蒸馏部分的损失如下所示:
在这一过程中,Teacher 可以访问问题构造路径
,因此能够基于更丰富的上下文对 Student 提供可靠的监督,帮助 Student 判断每一次搜索和推理的生成是否合理。值得强调的是,Teacher是与 Student 相同尺寸的模型,因此 π-Play不需要依赖更强教师模型或人工构造的特权信息。
Teacher优化函数
为了使Teacher模型能够在利用特权信息的基础上做出更准确的搜索动作,同时避免 Teacher 与 Student 之间产生过大的策略偏差。论文采用了一种轻量的方式来对Teacher进行优化,即使用 Student 参数
的指数滑动平均(EMA)来更新 Teacher的参数$$\psi$$,
-zFIN.png)
-hYNP.png)
-ctJa.png)
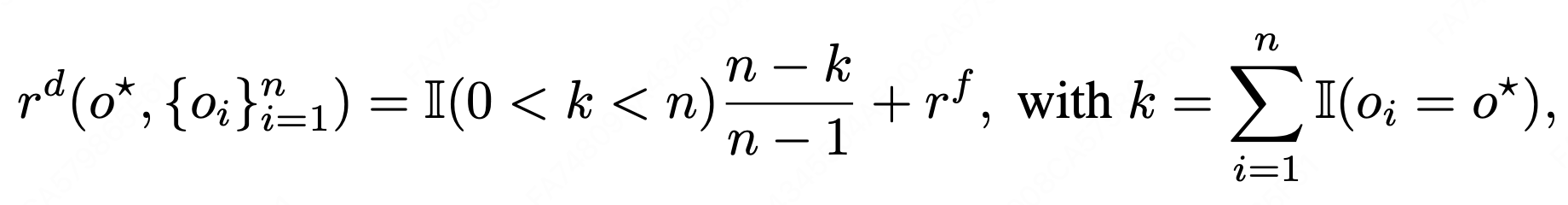
-tnRr.png)
实验结果
实验在 Qwen3-4B、Qwen3-4B-Instruct 和 Qwen3-8B 上进行,覆盖 NQ、TriviaQA、PopQA、HotpotQA、2WikiMQA、MuSiQue 和 Bamboogle 等多个问答测试基准。
表 1 的实验结果表明,π-Play 在多个模型和问答基准上均取得稳定提升,整体超过 ReAct、Search-R1、SQLM* 和 Dr.Zero 等基线。在不依赖外部训练数据的情况下,π-Play 甚至超过了部分完全监督的搜索智能体,说明 QCP 驱动的自蒸馏能够有效提升自进化效率。
与传统自博弈相比,π-Play 以约 2–3× 的速度达到相近或更优性能,显著提升了自进化效率,如图 4 所示。表 2 的消融实验结果表明,完整 QCP 明显优于只提供标准答案 (w/ GT) 以及提供部分QCP (w/ Partial QCP) 作为Teacher特权上下文,验证了 QCP 可提供有效的特权监督。