
6月6日上午10点,青稞Talk 129 期,青稞社区邀请到中国人民大学高瓴人工智能学院博士生董冠霆,来直播分享《从 ARPO,到 AEPO,再到 Agent-World:探索通用智能体训练的可行路径》。
本次分享将主要围绕三篇通用智能体强化学习论文展开,沿着"智能体强化学习 → 多环境强化学习"的脉络层层递进,从探索静态环境的智能体强化学习,到动态环境与智能体协同进化范式,并展望通用智能体训练的可行路径。
ARPO:智能强化策略优化
在可验证强化学习(RLVR)的推动下,大语言模型在单轮推理任务中已展现出不俗表现。然而在真实推理场景中,LLM往往需要结合外部工具进行多轮交互,现有RL算法在平衡模型的长程推理与多轮工具交互能力方面仍存在不足。
为此,我们提出了全新的Agentic Reinforced Policy Optimization(ARPO)方法,专为多轮交互型LLM智能体设计。

论文:Agentic Reinforced Policy Optimization
链接:https://arxiv.org/abs/2507.19849
代码:https://github.com/RUC-NLPIR/ARPO
ARPO的核心原理是鼓励策略模型在高熵工具调用轮次中自适应地进行分支采样,从而有效地协调步级工具使用行为。

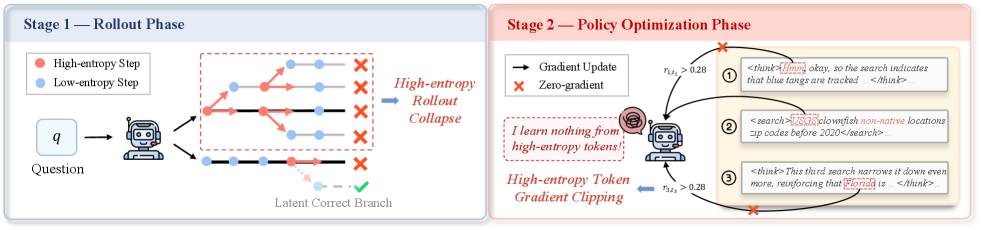
- 如图(左)所示,LLM在收到每一轮工具调用反馈后生成的初始令牌始终表现出高熵值。这表明外部工具调用会显著地给LLM的推理过程引入不确定性。
- 如图(右)所示,我们验证了ARPO在13个数据集上的性能。值得注意的是,采用ARPO的Qwen3-14B在Pass@5测试中表现出色,在GAIA数据集上达到61.2%,在HLE数据集上达到24.0%,同时在训练过程中所需的工具调用次数仅为GRPO的一半左右。
AEPO:智能体熵平衡策略优化
论文:AgenticEntropy-Balanced Policy Optimization
链接:https://arxiv.org/abs/2510.14545
在智能体强化学习的快速发展中,如何在探索与稳定之间取得平衡已成为多轮智能体训练的关键。主流的熵驱动式智能体强化学习(Agentic RL)虽鼓励模型在高不确定性处分支探索,但过度依赖熵信号常导致训练不稳、甚至策略熵坍塌问题。
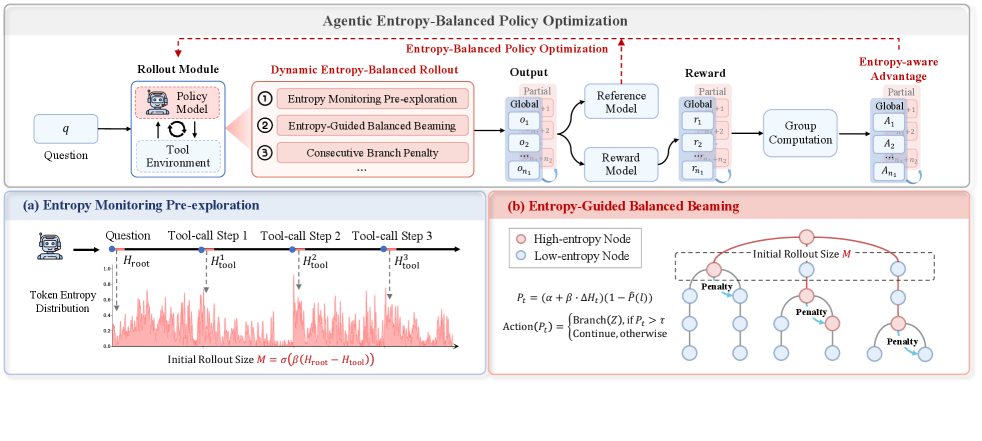
AEPO包含两个核心组件:
- 动态熵平衡滚动机制,通过熵预监控自适应地分配全局和分支采样预算,同时对连续的高熵工具调用步骤施加分支惩罚,以防止过度分支问题;
- 熵平衡策略优化在熵裁剪项中插入停止梯度操作,以保留和适当地重新缩放高熵标记上的梯度(熵裁剪平衡机制),同时结合熵感知优势估计,优先学习高不确定性标记(熵感知优势估计)。
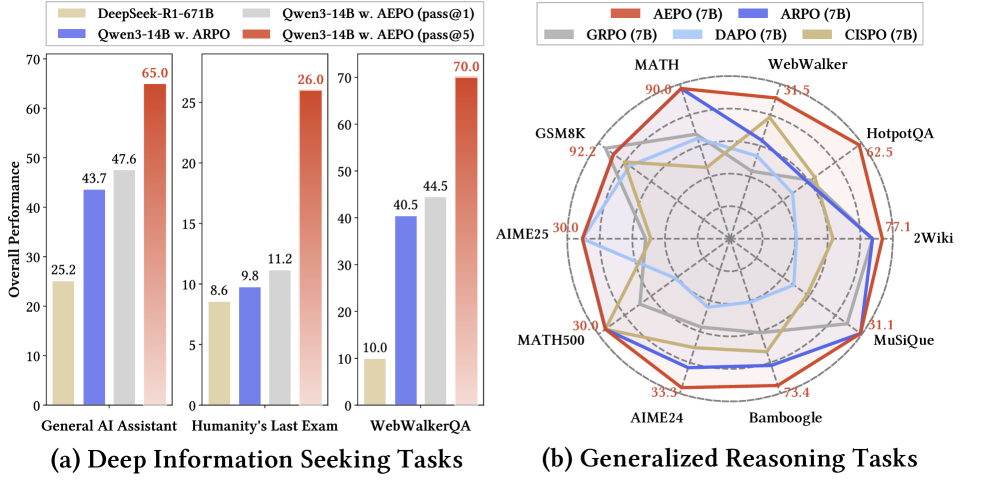
实验结果表明,AEPO 在14个跨领域基准上显著优于七种主流强化学习算法。特别是深度搜索任务的Pass@5指标:GAIA (65.0%), Humanity’s Last Exam(26.0%), WebWalkerQA (70.0%)。在保持训练稳定性的同时进一步提升了采样多样性与推理效率,为通用智能体的可扩展强化训练提供了新的优化范式。
Agent-World:让智能体与环境协同进化
论文:Agent-World: Scaling Real-World Environment Synthesis for Evolving General Agent Intelligence
链接:https://arxiv.org/abs/2604.18292
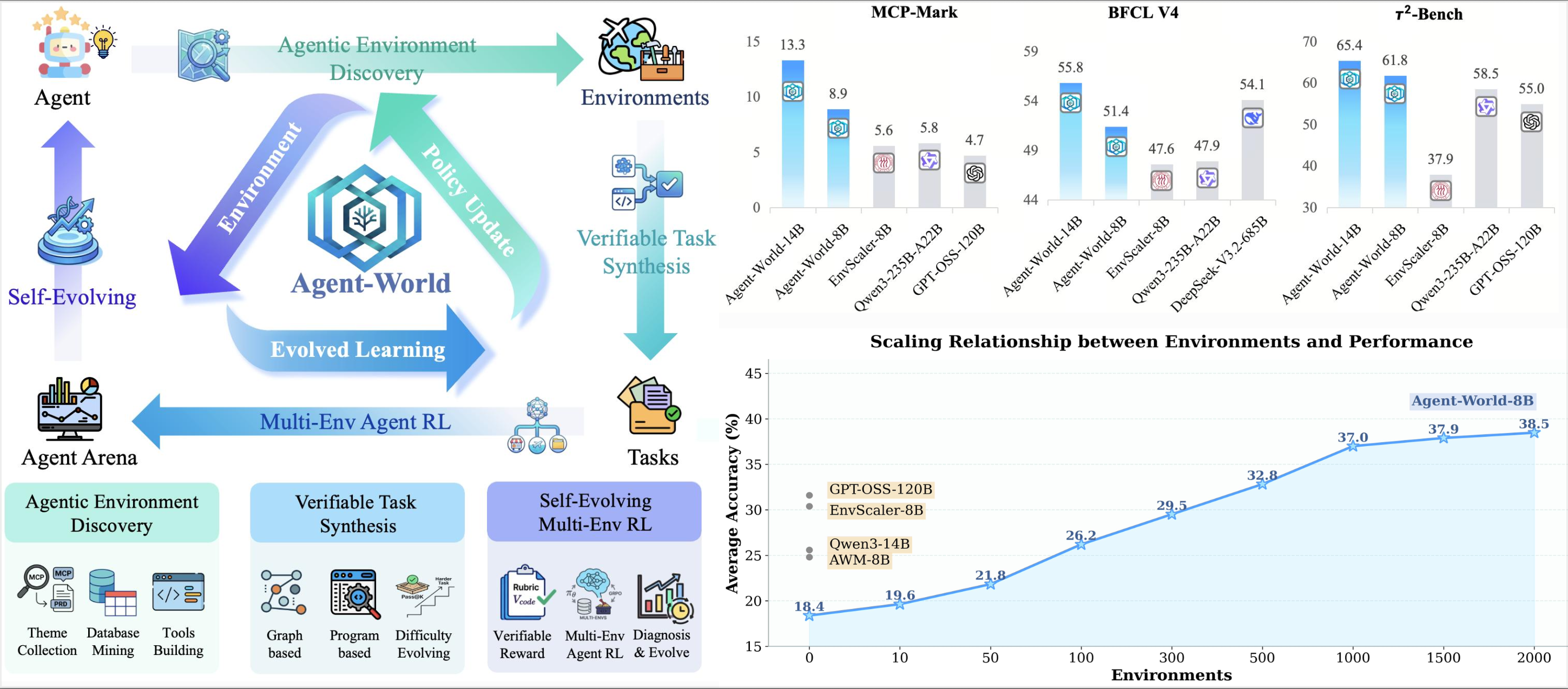
随着 MCP、Agent Skills 以及各类 Harness 的快速演进,大模型已经能够便捷地调用成百上千种外部工具。然而,在多工具协同、复杂状态管理和长程交互等真实任务中,智能体的能力短板依然明显。
为弥合这一差距,业界陆续提出了多种环境扩展方法,试图复刻订票系统、外卖平台、Notion 等真实世界交互场景。但这些探索始终面临两方面瓶颈:
- 环境扩展侧:人工搭建环境难以兼顾规模与覆盖面;自动合成环境又往往真实性不足。
- 训练算法侧:即便训练环境不断增加,一旦智能体面对全新场景,如果缺乏持续学习能力,泛化表现仍然难以保证。
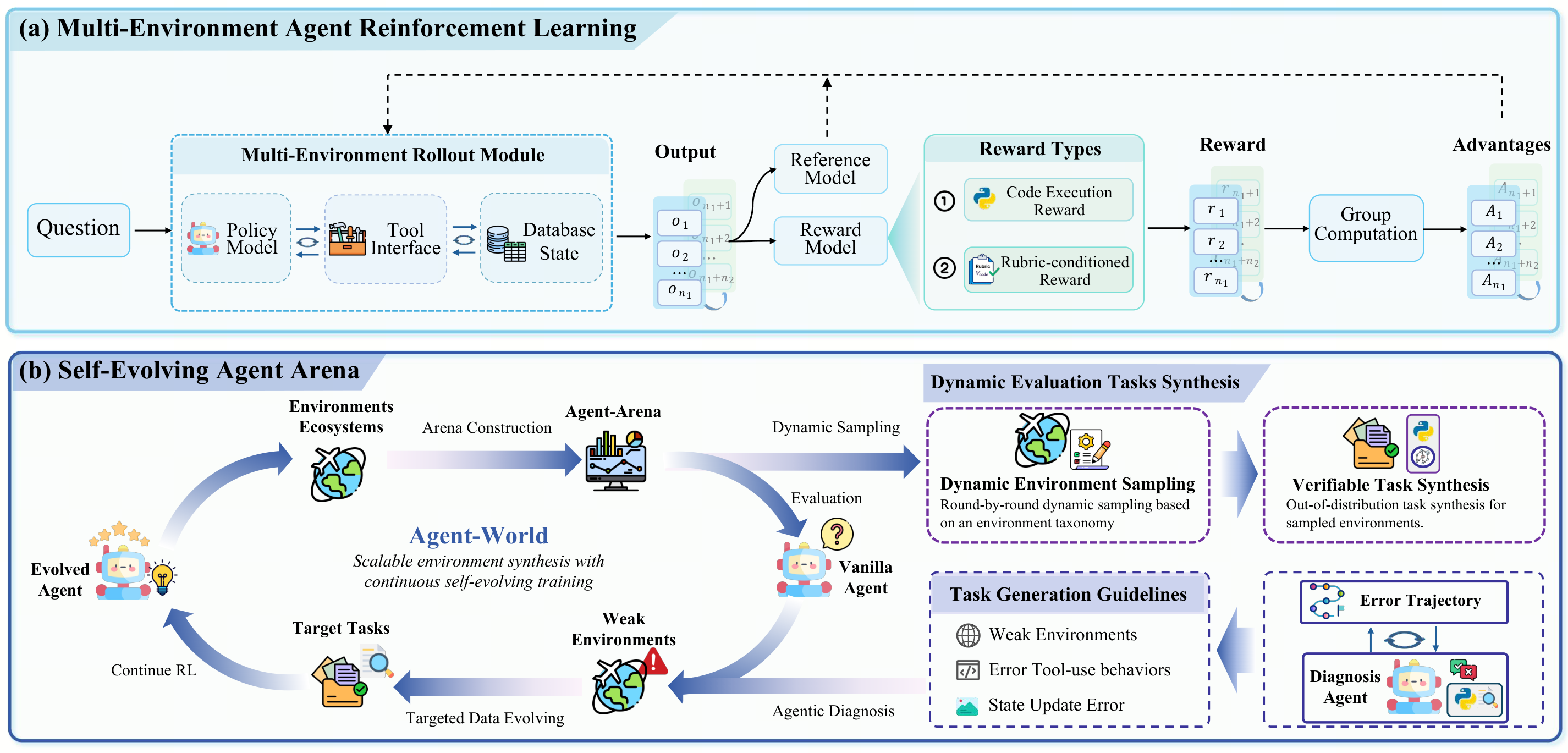
为打破这一困局,来自中国人民大学和字节跳动的研究团队提出了一个非常新颖的技术方案:Agent-World。它面向通用智能体构建训练场,首次将“智能体环境探索”与“持续自进化训练”深度耦合,形成智能体与环境协同进化的闭环。
分享嘉宾
董冠霆,中国人民大学高瓴人工智能学院博士在读,导师为文继荣教授与窦志成教授。他的主要研究方向为通用智能体训练。以第一/共同第一作者身份在 ICLR、NeurIPS、ACL 等国际顶级会议发表论文 10 余篇;其代表工作包括 Agent-World、ARPO、AUTOIF、Search-o1、Webthinker等,受到国内外研究者的广泛关注。
谷歌学术引用量 1 万余次,个人 GitHub 项目累计获得星标超 9000 余枚,并在字节跳动 Seed、阿里通义千问、快手快意大模型等核心基座大模型团队实习。曾获首届腾讯青云奖学金,国家奖学金、北京市优秀毕业生等荣誉,并入选国家自然科学基金青年学生基础研究项目 (博士生)、中国科协青年人才托举工程博士生专项计划资助。
主题提纲
从 ARPO,到 AEPO,再到 Agent-World:探索通用智能体训练的可行路径
1、Agentic RL 的定义与概述
2、ARPO :专为多轮交互型 LLM 智能体设计的RL策略
3、AEPO:面向多轮智能体的熵平衡强化学习优化算法
4、Agent-World:利用大规模合成环境训练“通用智能体”
5、探讨通用智能体训练的可行路径
直播时间
6月6日(周六)10:00 - 11:00