作者:wxzhou
https://zhuanlan.zhihu.com/p/2044873485688861958
本文仅使用大模型进行润色,并努力去除 AI 味,部分图片使用 gpt 生成。
1. 引言
先抛出一个问题:以典型 GQA 架构为例,在 LLM 推理的 Decode 阶段,Attention 耗时与 Batch 内总 Token 数是否总能呈现近似线性关系?
对于经常接触底层算子优化的同学,这个问题并不难回答。但对于不太关注底层实现的读者而言,这里仍有必要展开说明。
答案可以分成两种情况:
- 负载均衡时:如果 GPU 各 SM 之间的任务分配较为均匀,DecodeKernel 的执行耗时通常可以近似看作与 Token 总数成正比。这里的 Token 总数主要对应需要搬运的 KV Cache 数据量。
- 负载不均时:如果 Batch 内不同请求的历史序列长度差异显著,部分 SM 长时间忙碌而部分 SM 提前空闲,Kernel 耗时就不再稳定服从 Token 总数的线性规律。
实验观察也印证了这一点:
- 当 Decode Batch 内部请求长度较为均匀时,近似线性规律在不同 BatchSize 下基本成立
- 当 Decode Batch 内部请求长度不均匀时:
- 在 FlashInfer(仅考虑 SM80)后端,当 BatchSize 超过某一阈值后,线性规律会明显失效
- 在 FlashAttention-3(FA3)后端,该线性规律通常仍可保持近似成立。
Decode Batch 内部负载不均问题
在批次内部,各序列的输入长度 q_len=1,但历史序列长度 kv_len 可能存在显著差异。且每个请求的 Query 需要与其所有历史序列长度(KV)进行计算。因此,请求序列的注意力计算耗时天然存在差异。进入底层执行后,这些计算需要映射到线程块 CTA,再分配到具体的 SM 上。CTA 之间的任务量存在差异,导致 SM 间负载不均衡,影响 kernel 整体耗时。
因此,分析 Decode Batch 内部负载不均,不能只看 Batch 内总 Token 数,还要看这些 Token 在底层被组织成了多少任务,以及这些任务能否在 SM 之间均匀执行。
阅读本文,你将了解到:
- Decode Batch 内部如何划分各序列的 Attention 任务 (第二章)
- FlashInfer 后端在 Batch Size 超过阈值时,Decode 负载不均问题为何会显著 (第三章)
- FlashAttention-3 后端如何缓解 Decode 负载不均 (第四章)
还会了解到一些其他知识:
- 为何在 Decode 阶段,基于 FlashInfer 后端做 profilingTrace 抓到的仍是 PrefillKernel;
- 为何在 Hopper 架构下,SGLang 默认选择 FA3 作为 MHA/GQA 注意力后端,而非 FlashInfer
2. Decode Batch 的 Attention 任务划分
Decode Batch 进入 Attention Kernel 后,首先会被拆成一组可调度的计算任务。任务粒度决定了后续负载不均如何产生。
2.1. Attention 的 M/N 分块
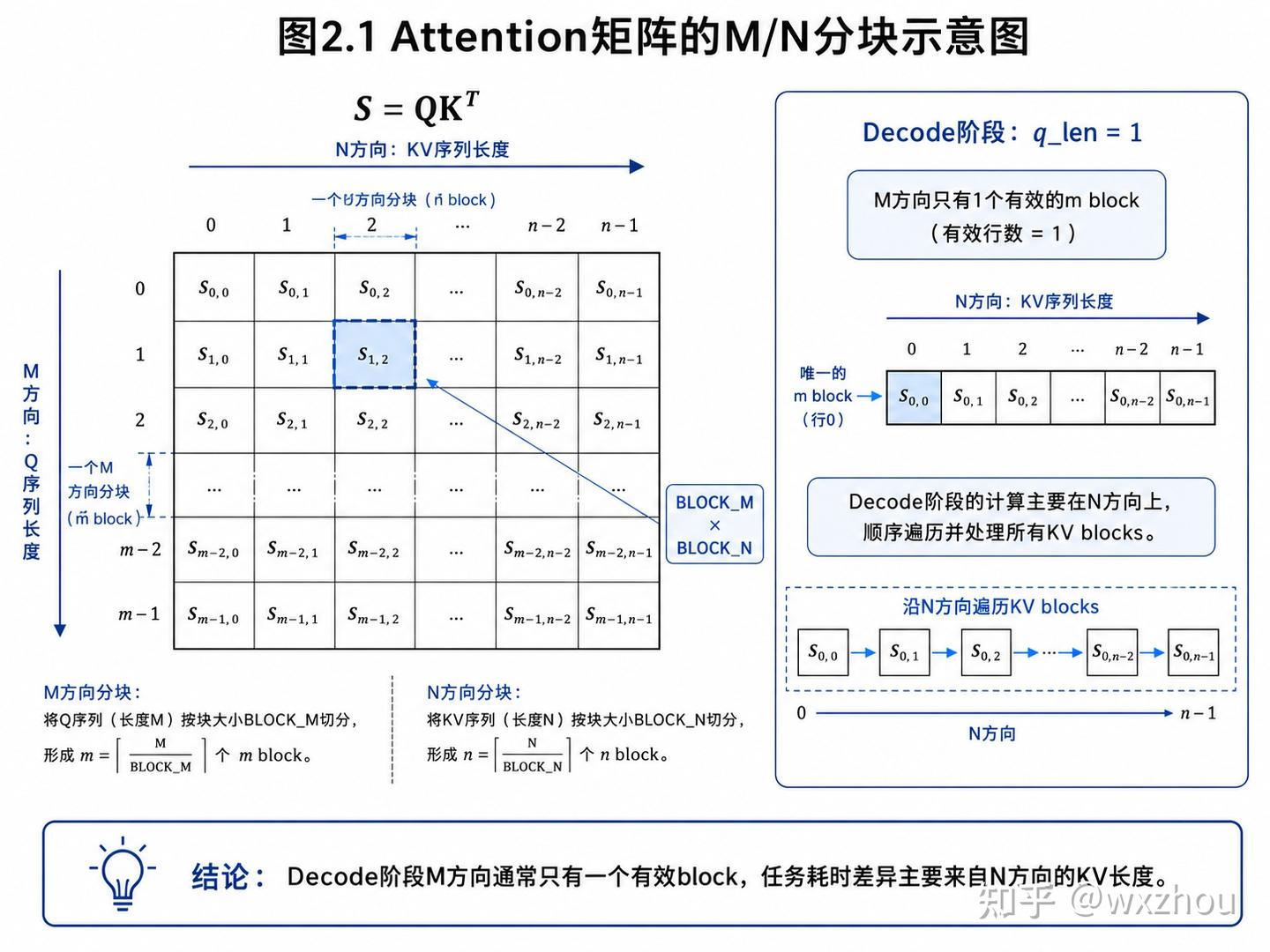
以 FlashAttention 为代表的实现,并不会显式生成完整 Attention 矩阵,而是按 M/N 方向分块计算 S = QK^T,并在片上完成 softmax 更新和输出累积。
在 Decode 阶段,忽略 Batch 维度后,单个请求、单个 head 上的张量形状为:
Q_{b,h}: [1, D]
K_{b,h}: [kv_len, D]
V_{b,h}: [kv_len, D]
此时:
S_{b,h} = Q_{b,h} K_{b,h}^T
S_{b,h}: [1, kv_len]
其中,D 表示 head_dim,kv_len 表示该请求已有的历史 KV 长度。
FlashAttention 对 S 的分块主要发生在两个方向。其中 M 方向为 Q 序列方向,N 方向为 KV 序列方向。每个块大小为[BLOCK_M, BLOCK_N]
某个请求在这两个方向上的 block 数量大致为:
num_m_blocks = ceil(q_len / BLOCK_M)
num_n_blocks = ceil(kv_len / BLOCK_N)
BLOCK_M 和 BLOCK_N 的取值受到数据类型、head_dim 以及底层 GPU 的影响。常见实现中,BLOCK_M 常见取值包括 128 等,BLOCK_N 常见取值包括 128、176 等。
Decode 阶段 q_len 通常为 1,因此 num_m_blocks 通常为 1。不同请求的任务差异主要来自 N 方向,也就是 kv_len 差异。
基础 Attention 任务
考虑到 Attention 计算任务可以在请求维度、头维度,以及 M 维度上并行处理,我们可以定义一个基础 Attention 任务:固定某个请求、某个 Q head 或 KV head、某个 m block 后,由一个线程块(CTA)或 work tile 负责完成的一段 Attention 计算。
任务粒度为:(m_block, request, head)
对于 decode 阶段,M 方向通常只有一个有效 m block,即 m_block = 1
单个基础任务的执行过程可以概括为: 对于某个 request、head 和 mblock,在任务内部顺序遍历该请求的所有 KV tile。kv_len 越长,需要遍历的 KV tile 越多,任务耗时也越长。
PackGQA 优化
进一步考虑 GQA 架构。GQA 中,Q head 数量通常大于 KV head 数量,可表示为:
H_q = G * H_kv
其中,同一组 Q head 共享同一个 KV head,也会读取同一份 KV Cache。若 Attention 任务按(m_block, request, q_head)组织,同一组 Q head 会分别发起计算,并重复读取同一个 KV head 对应的 KV Cache,带来额外显存带宽开销。
因此,更常见的做法是按(m_block, request, kv_head)组织任务。在一个任务内部,同时处理该 KV head 对应的一组 Q head,使这些 Q head 共享同一份 K/V 读取。
在 Decode 阶段,单个 Q head 对应的矩阵乘为:[1, D] × [D, BLOCK_N]
PackGQA 将同一 KV head 对应的 G 个 Q head 合并到 M 方向,对应的矩阵乘变为:[G, D] × [D, BLOCK_N]
这样既能复用同一份 KV 读取,也能提高 tile 内部的有效计算密度。
不过,G 通常仍小于 BLOCK_M。因此,即使启用 PackGQA,Decode 阶段在 M 方向上通常仍只有一个有效 mblock。PackGQA 并不会从根本上改变 Decode 阶段 M 方向并行度有限的特点。
结论:
- Decode 阶段 q_len 通常为 1,M 方向通常只有一个有效 mblock
- 在未做 SplitKV 时,基础任务可近似理解为(mblock, request, head),任务内部沿 N 方向遍历 KV tile
- GQA 下 PackGQA 通常按 kv_head 组织任务,但 G 通常仍小于 BLOCK_M,因此不会改变 Decode 阶段 M 方向并行度不足这一特点
因此,Decode Batch 内部的基础任务量差异,主要来自不同请求在 N 方向上的 kv_len 差异。
2.2. SplitKV: 沿 N 方向补充 Decode 并行度
Decode 阶段 M 方向通常只有一个有效 mblock,因此 Decode 阶段的基础 Attention 任务数可以近似表示为:num_tasks ≈ batch_size × kv_head
其中,num_kv_heads_local 表示当前 GPU 上的本地 KV head 数。对于 TP 并行场景,单卡 KV head 数量会进一步减少,因此小 batch 下的基础任务数可能明显小于 SM 数量。
此时,一个基础 Attention 任务可以近似理解为:(m_block, request, kv_head)
这些基础 Attention 任务通常由 CTA 或 work tile 承载,并进一步被调度到 GPU 的 SM 上执行。为了充分利用 GPU 计算资源,我们希望任务数至少能够覆盖足够多的 SM。但在 decode 阶段,在小 batch 场景下,或者模型开启 TP 后单卡上的 kv_head 数量变少时,batch_size × kv_head 可能明显小于 SM 数量,导致大量 SM 无法被充分利用。
FlashDecoding 正是沿这一思路引入 SplitKV:当 request 和 head 维度提供的任务数不足时,继续沿 KV 序列方向补充并行度。
开启 SplitKV 后,原本需要遍历完整 KV 序列的基础任务,会被拆成多个连续 KV 区间。不同任务分别处理不同区间,最后再归并 partial attention 结果。
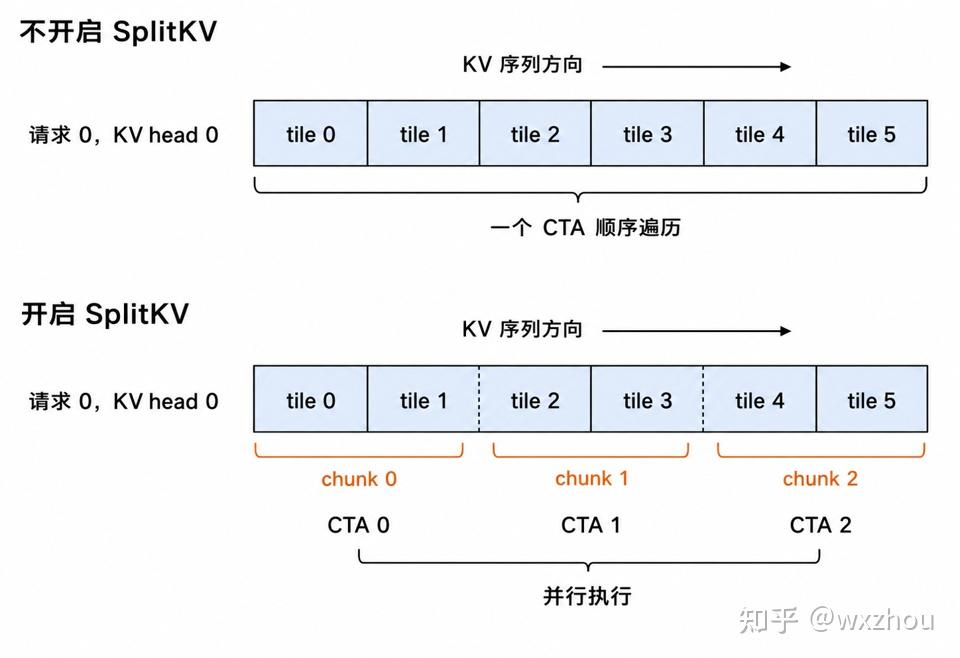
开启 SplitKV 后,基础 Attention 任务在逻辑维度上可以扩展为:
(m_block, request, kv_head, split_idx)
若第 b 个请求的 KV 方向被切成 num_splits[b]份,则单张 GPU 上的任务数可写为:
num_tasks = Σ_b (num_m_blocks[b] × num_kv_heads_local × num_splits[b])
在 Decode 阶段,num_m_blocks[b]通常为 1,因此近似为:
num_tasks ≈ num_kv_heads_local × Σ_b num_splits[b]
其中,num_kv_heads_local 表示当前 GPU 上的本地 KV head 数。
SplitKV 有两层作用。第一,增加任务数,使小 batch 场景下的 CTA 数量更容易覆盖 SM;第二,拆开长 KV 请求,避免少数长任务拖住 Kernel 尾部。
不过,SplitKV 优化存在额外的开销。由于每个 split 只得到局部 attention 结果,后续通常还需要额外的归并步骤,将多个 partial 结果合成为最终输出。这会带来额外 kernel 开销或同步开销,具体形式取决于后端实现。
因此,SplitKV 通常不会无条件开启。当基础任务数已经足够覆盖 SM 时,后端可能关闭 KV 方向切分,以避免归并开销。对于长度分布较均匀的 Batch,这一策略通常是合理的;但当 Batch 内部存在少量超长请求时,关闭 SplitKV 会使长请求重新变成少数重任务,进而造成 Kernel 尾部等待和 SM 负载不均。
2.3. FlashInfer 中的 Attention 任务映射
2.3.1. 逻辑任务与 CUDA Grid 组织
在不开启 SplitKV 时,FlashInferdecode 阶段的逻辑任务可近似表示为(request,kv_head)。每个任务处理一个请求的一个 KVhead,并在任务内部完成该 KVhead 对应的一组 Qhead 计算。因此,逻辑任务数约为 batchsize * num_kv_heads_local。
从逻辑上看,这些任务可以组织成一个二维 Grid:一个维度是请求,另一个维度是本地 KVhead。在经典非 persistent 路径中,每个 Grid 格子通常对应一个 CTA。
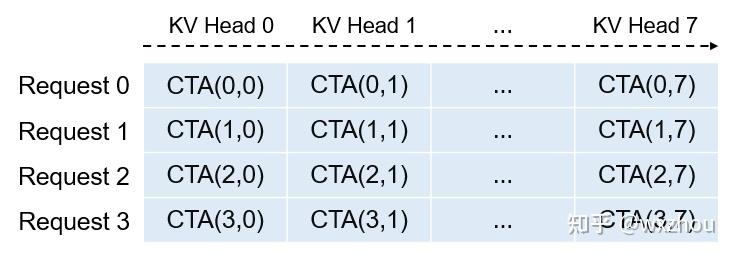
FlashInfer 内部有两类相关路径。二者的物理 CUDA Grid 形式不同,但在普通 decode 且不开启 SplitKV 时,对应的逻辑任务都是(request, kv_head)。
CUDA core 路径
经典 CUDA core Decode Kernel 使用二维 Grid:
dim3 nblks(padded_batch_size, num_kv_heads);
可以简化写成:grid = (batchsize, num_kv_heads_local)
Tensor core 路径
开启 Tensor Core 后,decode 请求会复用 Prefill-style Kernel。该 Kernel 使用三维 Grid:
dim3 nblks(padded_batch_size, 1, num_kv_heads);
因此,物理 Grid 可以简化写成:grid = (batchsize, 1, num_kv_heads_local)
在不开启 SplitKV 时,两条路径对应的逻辑任务数相同,主要区别在于 CTA 内部如何处理一组 Q head:
- CUDA core 路径:一个 CTA 内部通过线程组织处理该 KVhead 对应的一组 Q head;
- Tensor core 路径:将这组 Qhead 打包到 M 方向,使用 MMA 完成更密集的 tile 计算。
2.3.2. SplitKV 对任务映射的影响
开启 SplitKV 后,一个请求的 KV 序列会被划分为多个连续区间,交由不同的 CTA 执行。因此,基础 Attention 任务的粒度变为:(request, kv_head, split_idx)
例如,若 request=0 在 kv_head=0 上的 KV 序列被切成 3 段,则原来的一个任务(request=0,kv_head=0)会扩展为 3 个 split 任务,对应 split_idx=0、1、2。
这些任务可以被独立调度。每个任务只处理自己负责的 KV 区间,但在区间内部仍然按照 KV tile 顺序遍历。
在逻辑上,SplitKV 增加了一个新的维度 split_idx。但 FlashInfer 没有专门增加一个物理 Grid 维度,而是将(request, split_idx)展平为一个 work item:
work_item = flatten(request, split_idx)
因此在开启 SplitKV 后,CUDA core Decode Kernel 的 Grid 可以近似写成:
grid = (num_work_items, H_kv_local)
其中,num_work_items = Σ_b num_splits[b]
假设有 3 个请求,分别被 split 为 3 份、1 份、2 份,则 Grid 排布可以表示为:

可以看到,SplitKV 增加了 Attention 任务的数量,以求打满 SM。
在 Kernel 内部,会通过元数据索引再将 work_item 还原为(request, split_idx).
当基于 Tensor core 路径时,FlashInfer 会复用 prefill kernel,物理 Grid 组织会变成:
grid = (num_work_items, 1, H_kv_local)
对于这里讨论的普通 decode 场景,两条路径对应的逻辑任务数相同,区别仍在 CTA 内部的计算组织方式。
2.3.3. 线程块执行和 SM 分配
CTA 发射后,由 GPU block scheduler 动态分配到不同 SM 上执行。
不开启 SplitKV 时,每个 CTA 需要遍历对应请求的完整 KV 历史。kv_len 越长,CTA 内部处理的 KVtile 越多,执行时间也越长。当 Batch 内部长度差异较大时,短请求 CTA 较早结束,长请求 CTA 继续运行,Kernel 尾部便容易被少数长任务拖住。
SplitKV 将长 KV 序列拆成多个可独立调度的任务。一方面,它增加了 CTA 数量;另一方面,它减小了单个 CTA 的工作粒度,使长请求更容易被分散到多个 SM 上执行。不同 split 产生的局部 Attention 结果,最终再通过 merge 操作合并。
因此,SplitKV 是否开启,不只影响并行度,也直接影响长短请求混合时的尾部任务长度。
2.4. FA3:Persistent Kernel 下的动态任务调度
2.4.1. Persistent Kernel 与 work tile
FA3 将 q_len 或 kv_len 不一致的 batch 视为 varlen batch。本文讨论的 decode batch 虽然 q_len 通常为 1,但不同请求的 kv_len 可能不同,因此也会进入 varlen 路径。
当调用方传入变长序列元数据后,FA3 会进入 varlen 路径,并根据 GPU 架构选择对应 scheduler。在 Hopper 架构下,varlenbatch 通常会进入 VarlenDynamicPersistentTileScheduler。
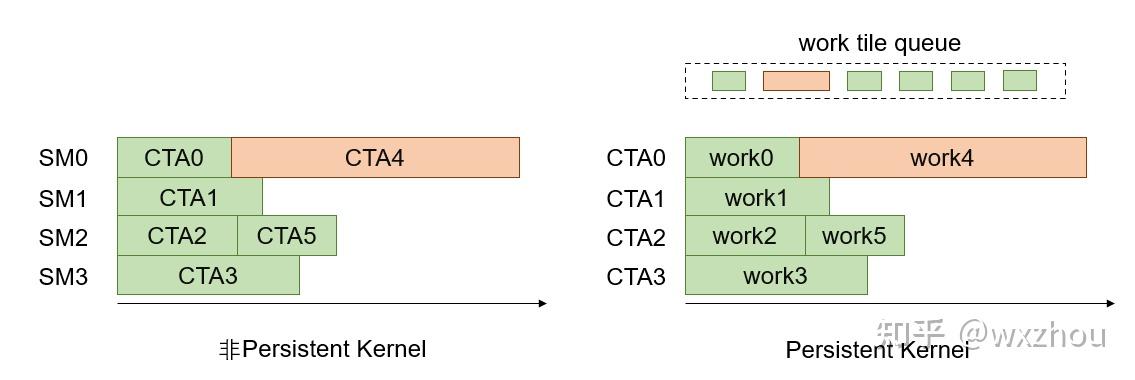
此时,CUDA 采用 Persistent Kernel 模型,而非 FA2 或 FlashInfer(SM80)采用的普通 Grid 模型。
普通 Grid 模型中,CTA 通常在 kernel launch 时与任务绑定,任务完成后退出。Persistent Kernel 则启动一组常驻 CTA。每个 CTA 完成当前 work tile 后继续领取后续 work tile,直到任务队列耗尽。
在 Hopper 架构下处理 varlen batch 时,FA3 会启动一组 persistent CTA,使其持续从 scheduler 领取 worktile。基础 Attention 任务会被编码成连续的 work tiles,由 scheduler 动态派发到 CTA 上。
一个 work tile 可以近似理解为:
(m_block, virtual_batch, kv_head[, split_idx])
其中,virtual_batch 是 FA3 在 varlen 路径中用于调度的 batch 编号。如果开启 SplitKV,还会多出一个 split_idx 维度。
在 decode+GQA 场景下,q_len 通常为 1,M 方向通常只有一个有效 mblock。因此,不考虑 SplitKV 时,一个 work tile 仍可近似理解为一个请求、一个 KV head 和一个 mblock。
区别在于,FA3 不会在 kernel launch 时把每个任务静态绑定给某个 CTA,而是让 persistent CTA 持续领取 work tiles。这使 FA3 的任务执行更接近动态队列模型。短任务完成后,对应 CTA 不会直接退出,而是继续领取后续 worktile,从而减少尾部空闲。
2.4.2. varlen decode 中的任务准备与动态派发
在 varlen decode 路径中,FA3 会先运行 prepare kernel,为后续 persistentscheduler 生成调度信息。
prepare 阶段主要完成三件事:
- 计算每个请求的工作量;
- 根据请求长度决定是否需要沿 KV 方向拆分任务;
- 调整请求的调度顺序,让较重任务优先执行。
在本文关注的 non-local decode 路径中,prepare kernel 会按照切分后的 KV 工作量对请求排序,使较重任务更早进入调度序列。排序不会改变真实请求编号,而是生成一组调度用映射:virtual_batch->real_batch。virtual_batch 只是排序后的逻辑下标,执行前仍会映射回真实请求。
在 prepare 阶段结束后,进入到 scheduler 的调度阶段。
可以将待处理的 work tiles 想象成一个逻辑任务队列。scheduler 使用连续递增的 tile_idx 表示待处理任务,再结合 prepare 阶段生成的调度信息,将其解码为:(m_block, virtual_batch, kv_head[, split_idx])
每个 persistent CTA 首先根据自己的 blockIdx.x 处理一个初始 work tile;随后,再通过全局计数器领取后续任务。较早完成任务的 CTA 可以继续领取更多的 work tile,保持忙碌。
3. FlashInfer 中的阈值现象与负载不均
3.1. 为什么 Decode 会出现 Prefill Kernel
使用 SGLang+FlashInfer 时,一个容易困惑的现象是:明明处于 Decode 阶段,profiling trace 中却可能看到 BatchPrefillWithPagedKVCacheKernel。这通常与 FlashInfer 的 use_tensor_core 路径选择有关。
在 GQA+PackGQA 路径下,QK^T 可近似看作[G, D]×[D, BLOCK_N]。其中,G 对应同一 KV head 下打包的 Q head 数量。FlashInfer 可以选择 CUDA core SIMT 执行,也可以选择 Tensor Core MMA 执行。
- use_tensor_core=False 时,FlashInfer 使用专门的 decode kernel,通常由 CTA 内部的不同线程组处理这些 Q head。
- use_tensor_core=True 时,FlashInfer 会复用 batch prefill paged kernel,通过 Tensor Core MMA 完成计算。
因此,profiling trace 中看到 prefill kernel,并不意味着语义上进入了 Prefill 阶段。它仍然是在做 q_len=1 的 Decode,只是 Tensor Core 路径复用了 prefill kernel 实现。
对小 M 矩阵乘而言,TensorCore 的 tile 利用率和额外组织开销可能抵消其峰值算力优势;当 M 维度变大后,MMA 路径通常更容易发挥优势。
因此,SGLang 在基于 FlashInfer 作为 Attention 后端时,采用了这样的逻辑:
- 对于 FP8 KV cache,显式设置 use_tensor_core=True
- 对于 BF16 KV cache 且 G >= 4,显式设置 use_tensor_core=True
- 其他情况,设置为 False
由于 CUDA core 路径和 Tensor core 路径使用不同的 kernel 组织方式,后续 SplitKV 启发式判断和阈值位置也会不同。
3.2. 阈值现象观察
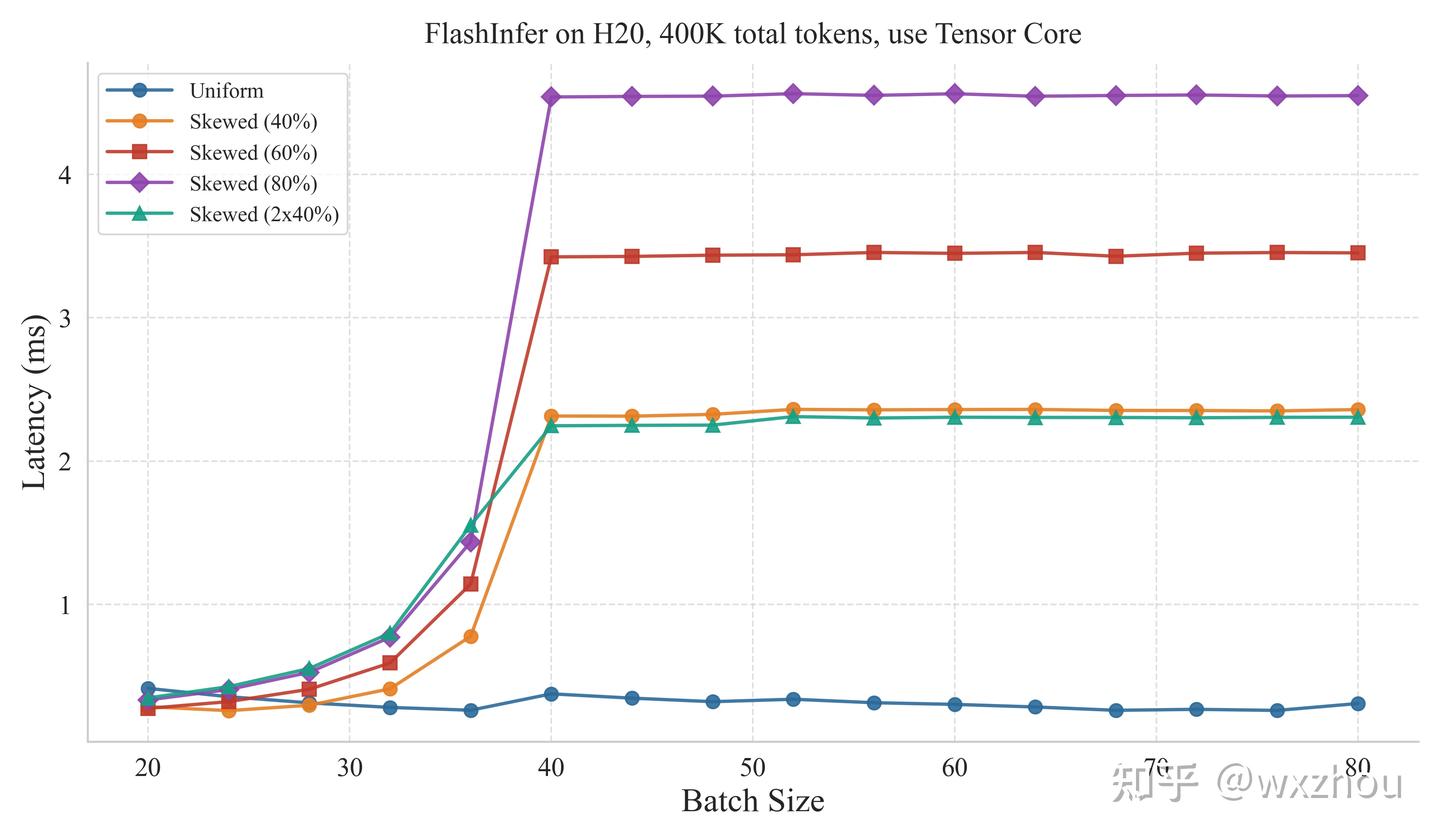
实验控制 Batch 内 Total Tokens 相同,并设置五类 kv_len 分布:Uniform、Skewed40%、Skewed60%、Skewed80% 和 2×40%。其中,Skewed 表示 Batch 内存在一条极长请求,其长度占 TotalKVTokens 的对应比例;2×40% 表示存在两条长请求,分别占 TotalKVTokens 的 40%。
扫描各 batchsize,测量 FlashInfer Attention 算子的耗时情况。
实验代码基于 FlashInfer 的 bench_batch_decode.py 修改,并在每次测量前重新 plan。
参照 Qwen3-30B-A3B 的 GQA 配置:32 Q head,4 KVhead,dtype 为 BF16
结果如图所示:
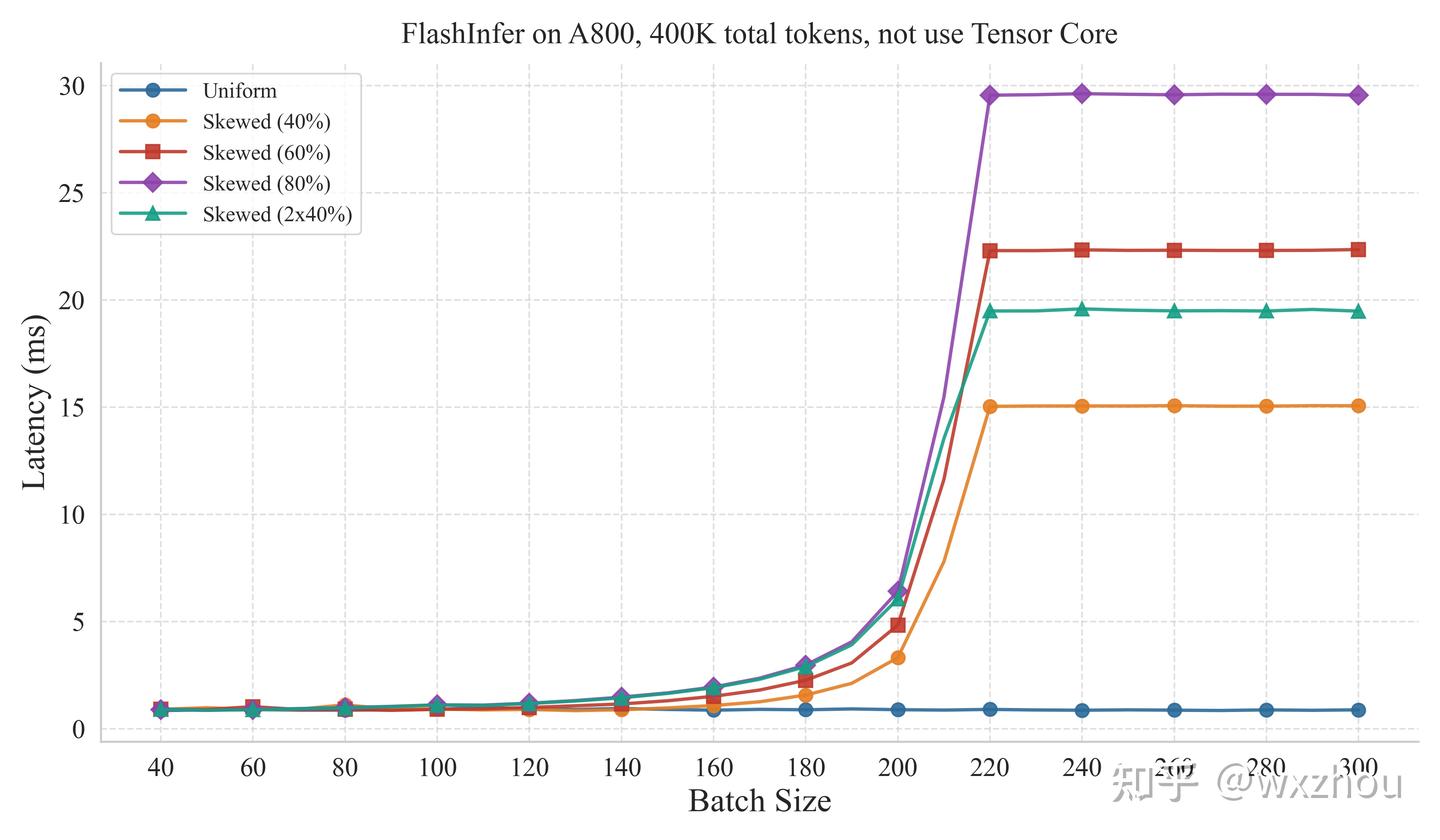
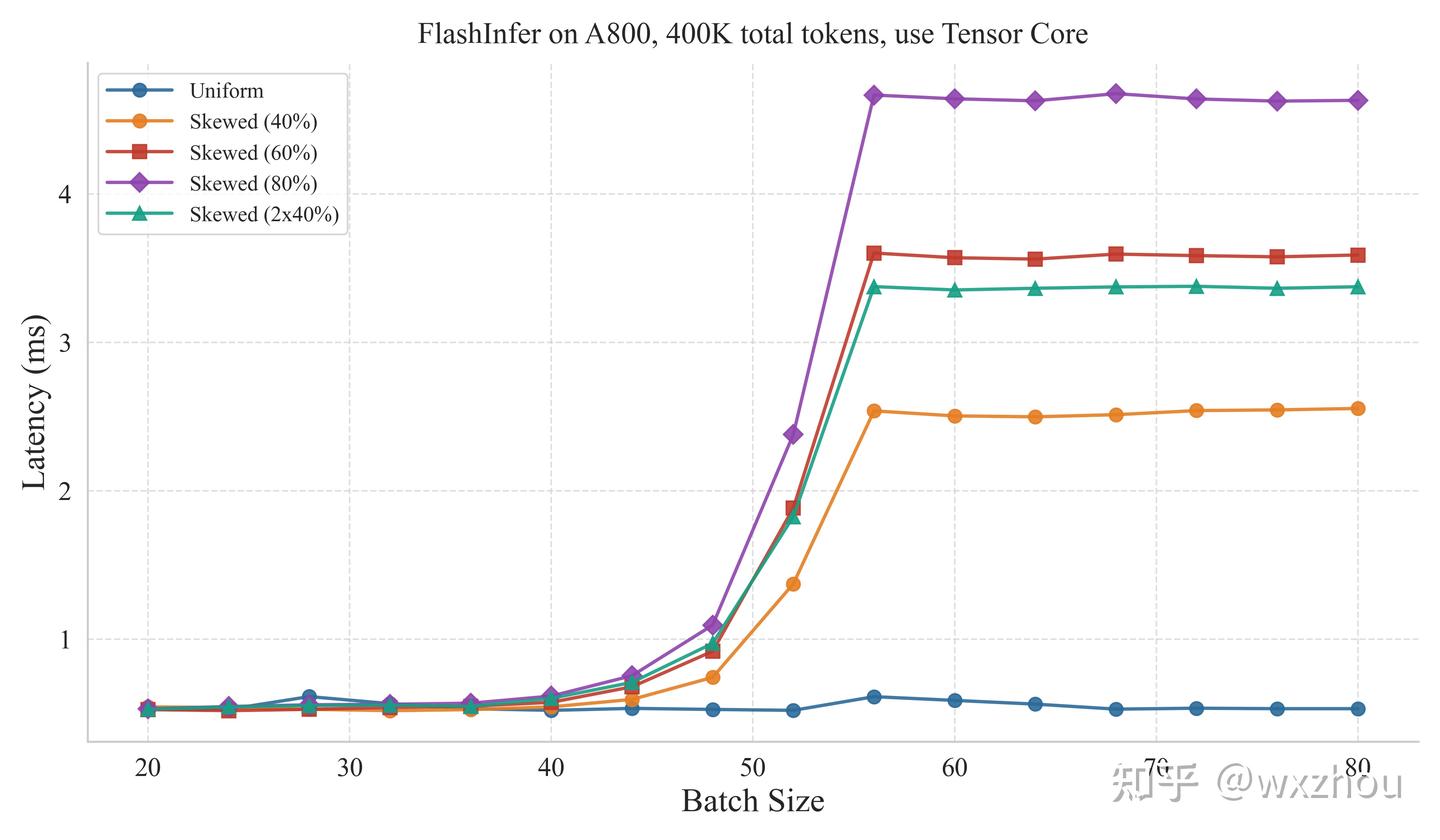
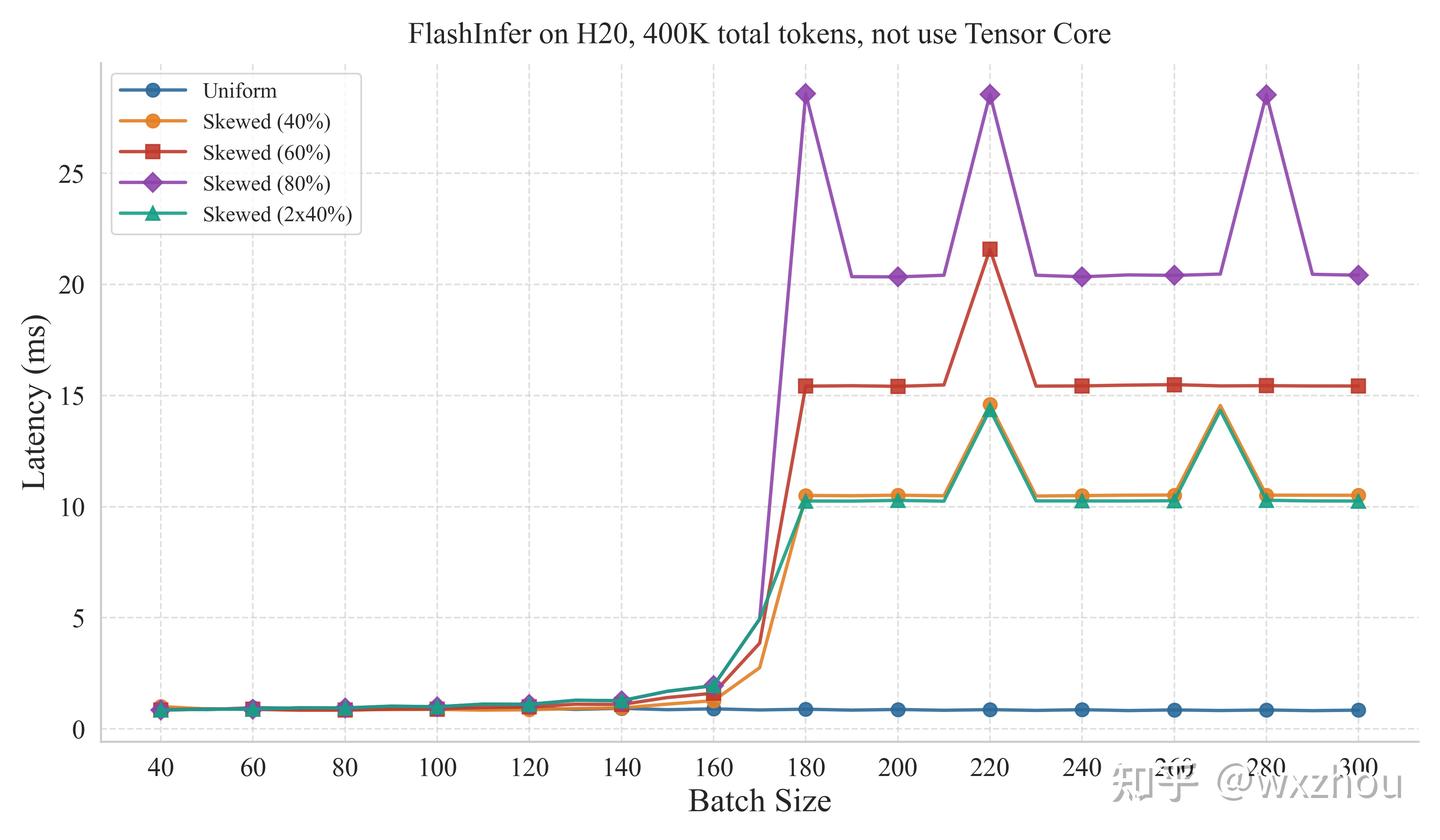
实验结果显示
- 当 Batch 内部 kv_len 分布不均时,FlashInfer 在特定 BatchSize 后出现明显耗时拐点。
- CUDA core 路径的阈值较高,Tensor core 路径的阈值较低。
- 进入阈值后,Kernel 耗时开始明显受最长请求长度影响。
这表明,FlashInfer 的 Decode 耗时在阈值前后存在两种状态:阈值前,任务数量和 SplitKV 策略基本能够掩盖长度差异;阈值后,少数长请求更容易退化为尾部重任务,进而拉长整个 Kernel。
3.3. 阈值现象的成因:SplitKV 启发式关闭
前面的实验现象可以从 FlashInfer 的 SplitKV 启发式策略中得到解释。当 BatchSize 超过一定阈值后,FlashInfer 会认为基础任务数已经足够覆盖 SM,从而关闭或减少 KV 方向切分。此时,长请求不再被拆成多个 split 任务,容易重新形成尾部重 CTA。
3.3.1. CUDA core 路径
CUDA core Decode 路径主要根据 SM 数量、单个 SM 可驻留 CTA 数量,以及当前 GPU 上的本地 KV head 数估计基础任务是否已经足够。
代码中首先通过 occupancy API 得到每个 SM 可以同时驻留的 CTA 数量:
cudaOccupancyMaxActiveBlocksPerMultiprocessor(
&num_blocks_per_sm, kernel, num_threads, smem_size);
max_grid_size = num_blocks_per_sm * num_sm;
随后判断:
if (batch_size * gdy >= max_grid_size) {
split_kv = false;
}
其中,gdy 等于当前 GPU 上的 KV head 数量。
因此,可以将 CUDA-core Decode 路径的判断近似理解为:
如果条件成立,基础任务已经足以覆盖 Kernel 的并行执行容量,FlashInfer 会关闭 SplitKV。
对应的 batch size 阈值可以粗略写成:
3.3.2. Tensor core 路径
Tensor core 路径下,Decode 计算通常复用 Prefill Kernel。该路径不再通过 occupancyAPI 估计 residentCTA 数量,而是采用更固定的并行度目标。当前实现中,每个 SM 的 CTA 目标数量可近似看作 2。
在普通 Decode 场景下,可以近似理解为:
同样在超过此阈值时,FlashInfer 会关闭 SplitKV 优化。
这意味着,在相同 num_SM 和 H_kv_local 下,Tensorcore 路径的 SplitKV 关闭阈值主要由 2×num_SM 决定。若 CUDA core Decode Kernel 的 resident_CTAs_per_SM 大于 2,则 CUDA core 路径的阈值自然更高。
因此,FlashInfer 中观察到的 BatchSize 阈值,本质上来自 SplitKV 启发式策略对任务数量的判断。阈值前,长请求可以通过 KV 方向切分生成更多 split 任务;阈值后,后端认为基础任务数已经足够,SplitKV 被关闭或减弱。对于长度分布均匀的 Batch,这一策略通常没有明显问题;但在长短请求混合时,少数长请求会重新变成少数重 CTA,最终拉长 Kernel 尾部。
4. FA3 如何缓解 Decode Batch 负载不均
4.1. 实验观察
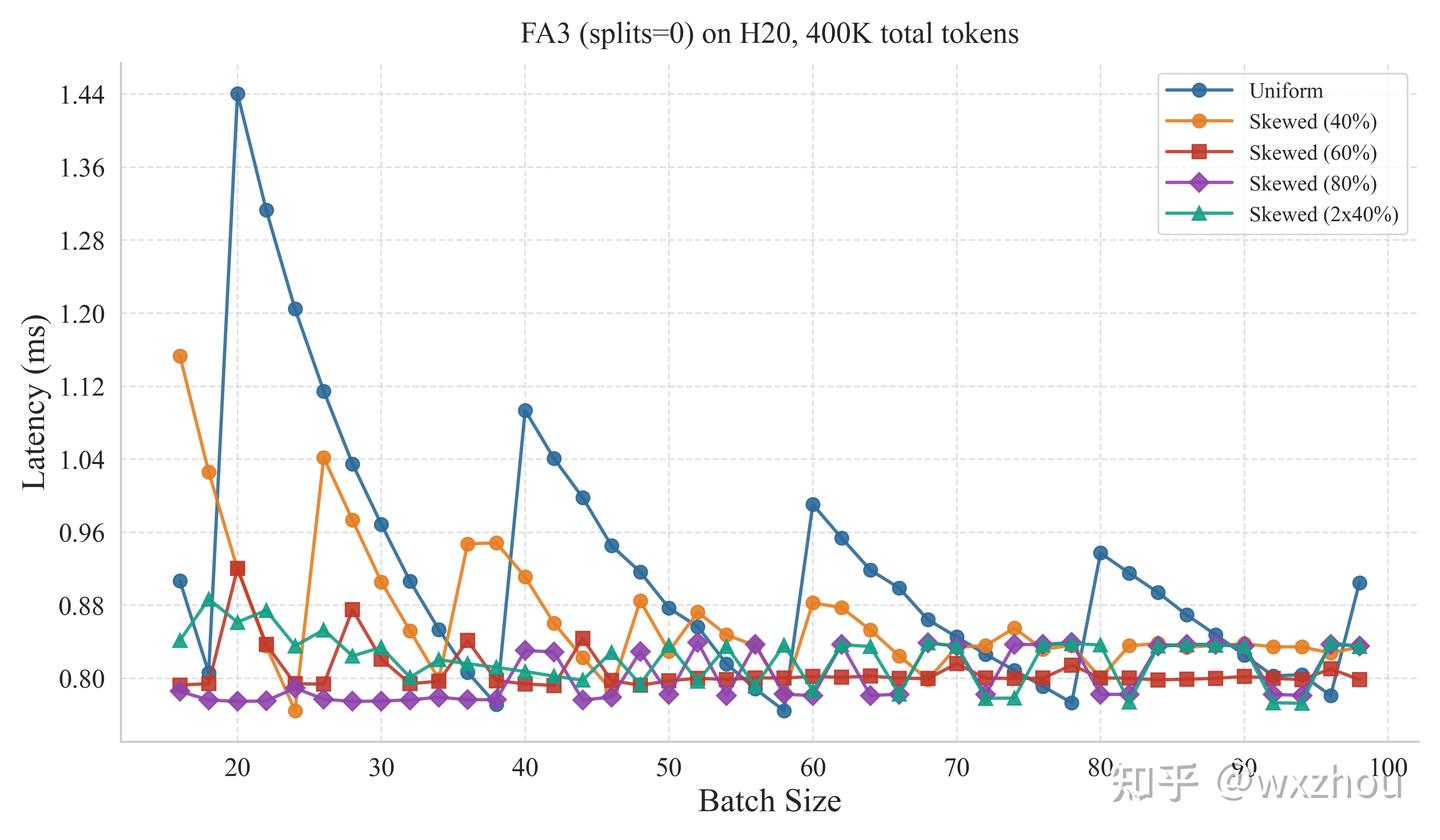
为观察 FA3 对长短请求混合场景的处理效果,我们在 H20 GPU 上复用前文实验设置,并比较两种配置:
我们比较了两种 FA3 配置:
- splits=1:切分块数为 1,等价于关闭 SplitKV
- splits=0:交由 FA3 自主决定 SplitKV 的开启
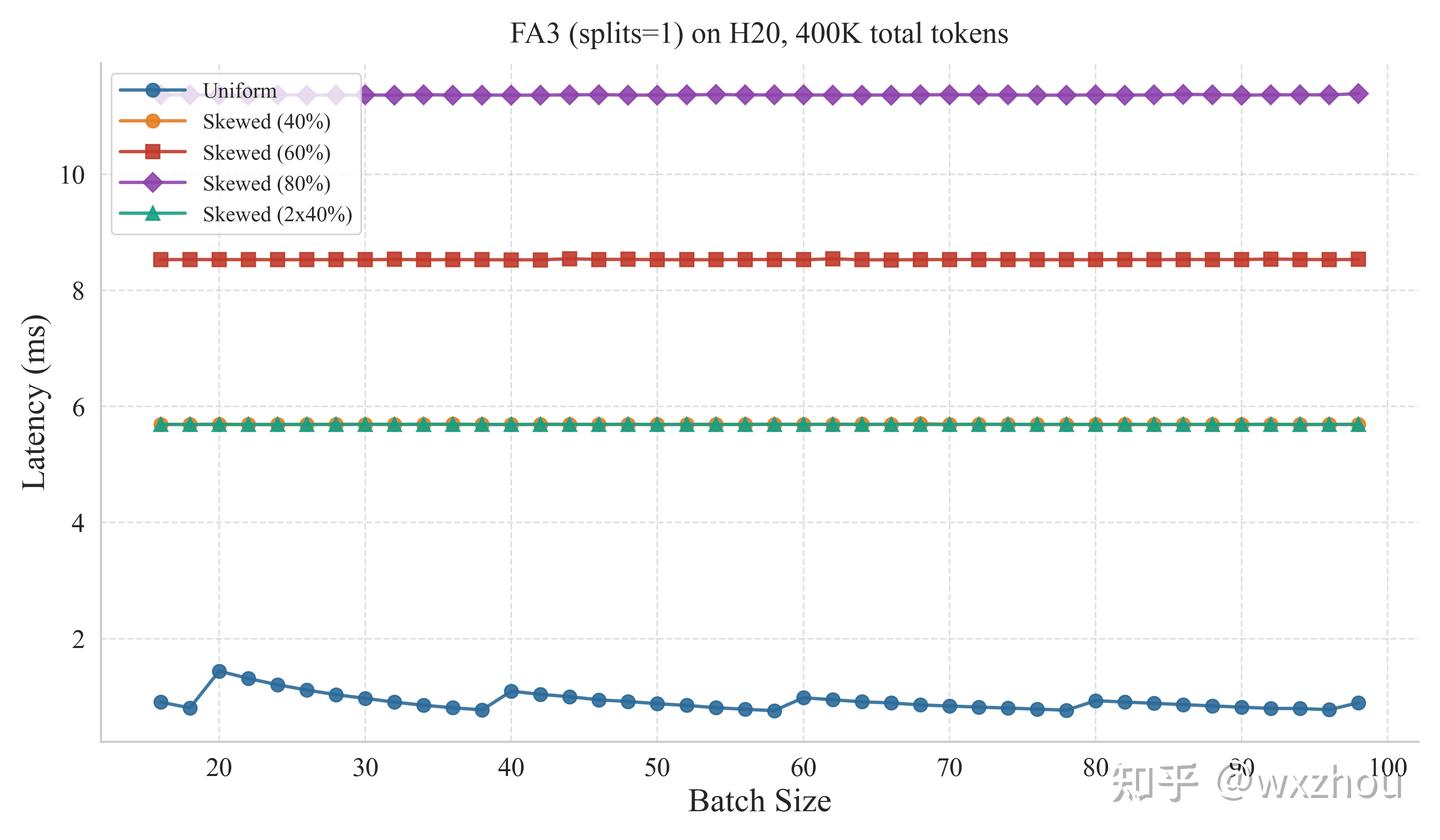
实验结果显示,splits=1 时,Kernel 耗时随最长序列增长明显上升。这说明,仅依靠 persistent kernel 和重任务优先调度,仍难以完全消除单条长请求带来的尾部任务。
splits=0 时,长短请求混合场景下的 Kernel 耗时整体更稳定,说明 FA3 的动态 SplitKV 能够有效拆分长请求。不过,在长度较均匀的 Batch 中,耗时反而可能出现波动。这类现象可能与 SplitKV 带来的 wave quantization 问题有关。
对 FA3 的 SplitKV 造成的 wave quantization,已有文章进行了探究,并得出在 batch 内请求长度比较平均的情况下更容易出现的结论。
FlashAttention 性能优化:decode 阶段序列切分策略优化
https://zhuanlan.zhihu.com/p/1962752334410003777
4.2. FA3 的负载均衡机制
实验结果表明,persistent kernel 只能改善任务派发方式,不能改变单个 work tile 内部的工作量。如果某个长请求始终不被切分,它仍然可能形成尾部任务。因此,FA3 缓解负载不均的关键,还在于动态 SplitKV 如何生成更均匀的 work tile。
下面仅讨论 Hopper 架构下 varlen decode 路径中的相关逻辑。
4.2.1. 静态 split 上限
当调用者设置 splits=0 时,FA3 会先通过 num_splits_heuristic(...)计算 num_splits_static。该值不是每个请求的实际 split 数,而是后续 dynamic split 可使用的静态上限。返回 1 表示不允许进一步切分。
这里主要关注四个变量:total_mblocks 表示基础 worktile 数量估计,num_SMs 表示可用 SM 数量,num_n_blocks 表示 N 方向 block 数,num_m_blocks 表示 M 方向 block 数。在 decode+PackGQA 场景下,num_m_blocks 通常为 1。
相关代码逻辑如下:
if (total_mblocks >= 0.8f * num_SMs) {
int const size_l2 = 50 * 1024 * 1024;
if (
size_one_kv_head > size_l2
&& num_m_blocks >= num_SMs * 2
&& !is_causal_or_local
) {
return std::min(
(size_one_kv_head + size_l2 - 1) / size_l2,
max_splits
);
} else {
return 1;
}
}
if (num_n_blocks <= 4) {
return 1;
}
总结为流程图是:
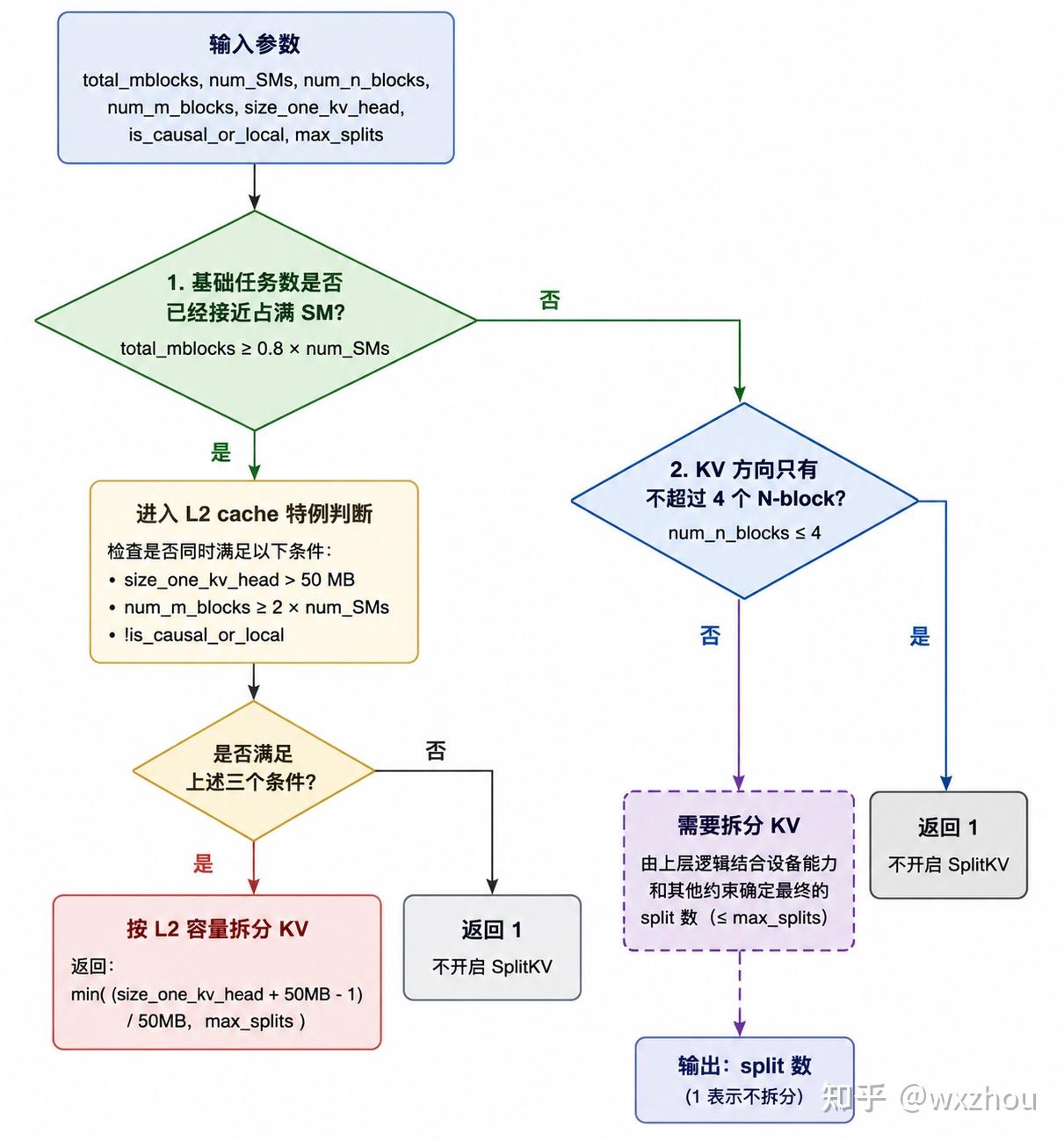
如果按真实 batch 计算 total_mblocks,较大 BatchSize 很容易进入 total_mblocks >= 0.8num_SMs 分支。此时,由于 decode 场景下 num_m_blocks 通常为 1,无法满足 L2 特例中的 num_m_blocks >= 2num_SMs,函数往往会返回 1,也就是不开启 SplitKV。
但这并不是 varlen 路径下的实际行为。varlen 路径下,FA3 并不使用真实 batch 计算 total_mblocks。代码中会假设 batch=1:
int total_mblocks =
(params.num_splits_dynamic_ptr ? 1 : params.b)
* params.h_k
* num_m_blocks;
这样做的目的,是避免真实 BatchSize 较大时过早关闭 SplitKV。也就是说,varlen 路径中的第一层 heuristic 更像是在给 dynamic split 计算上限,而不是直接根据当前 BatchSize 决定是否关闭 SplitKV。
因此,varlen 路径的 total_mblocks 很难满足 total_mblocks >= 0.8f * num_SMs 的外部判断条件。
之后,FA3 会枚举候选的 num_splits,并估算每一种拆分方案对应的 wave 利用率。
n_waves = total_mblocks × num_splits / num_SM
efficiency = n_waves / ceil(n_waves)
当任务数略微超过一个 wave 边界时,少量任务会落入下一个 wave,利用率下降。FA3 不会简单选择 split 最多或利用率最高的方案,而是选择达到最佳利用率一定比例的最小 split 数,以减少 partial 输出、额外访存和 combine 开销。
因此,第一层 heuristic 的作用,是为后续 dynamic split 提供一个兼顾 wave 利用率和 split 开销的上限。对于 varlen decode,它不会因为真实 Batch Size 较大而过早关闭 SplitKV。
4.2.2. 逐请求 dynamic split
对于 varlen decode,FA3 还会在 prepare 阶段计算每个请求的实际切分数 num_splits_dynamic[b]。
首先,FA3 计算每个请求的 N 方向 block 数:
num_n_blocks[b]=ceil(kv_len[b]/kBlockN)
然后估计每个 SM 应承担的 block 数量。对于 decode+PackGQA,num_m_blocks[b]通常为 1,H_schedule 可近似理解为本地 KVhead 数:
total_blocks=Σ_b num_n_blocks[b]
blocks_per_sm=ceil(total_blocks×1.1×H_schedule/num_sm)
最后,根据单个请求的 N 方向 block 数和 blocks_per_sm 计算实际 split 数:
num_splits_dynamic[b]=clamp(ceil(num_n_blocks[b]/blocks_per_sm),1,num_splits_static)
例如,当 blocks_per_sm=16 时,num_n_blocks=8 的请求不会切分,而 num_n_blocks=80 的请求会被切成 5 份。
得到 num_splits_dynamic[b]后,长请求会被展开为更多 work tile。non-local 路径还会按切分后的工作量重新排序,使较重任务更早进入调度序列。随后,persistentscheduler 通过连续递增的 tile_idx 动态派发任务。
需要注意,FA3 的 per-request dynamic split 也有 batchsize 上限。当前实现要求整个 batch 由单个 prepare CTA 覆盖。由于一个 warp 最多处理 31 个请求、一个 CTA 最多包含 32 个 warp,单个 prepare CTA 最多覆盖 31×32=992 个请求。超过该范围后,prepare kernel 需要多个 CTA,不同 CTA 之间无法直接通过 shared memory 汇总全 batch 的 total_blocks,代码会退化为 num_splits_dynamic[b]=1。
因此,FA3 并非没有 batchsize 阈值,只是 varlen decode 路径下的阈值远高于 FlashInfer 前文讨论的启发式阈值。在常见 serving 场景和本文实验范围内,该限制通常不会触发,极长请求仍能被拆成多个 work tile。
5. 小结
Decode Batch 内部负载不均,本质是请求长度差异在底层任务划分中被放大。对于 Decode Attention 而言,q_len 通常为 1,M 方向并行度有限,主要任务来自 request、KVhead 和 KV 序列方向。当长 KV 请求没有被进一步切分时,它会形成少数重 CTA,最终拉长整个 Kernel 尾部。
FlashInfer 中的阈值现象,核心来自 SplitKV 启发式策略。当 Batch Size 超过一定范围后,后端会认为基础任务数已经足够覆盖 SM,从而关闭或减少 KV 方向切分。这个判断在长度分布均匀时通常合理,但在长短请求混合时,会使少数超长请求重新成为尾部重任务,导致 SM 间负载不均。
FA3 能够缓解这一问题,关键在于 varlen 路径下的 SplitKV 不会随着 Batch Size 增大而轻易关闭。它会为长请求保留 per-request dynamic SplitKV,将长 KV 请求展开为更多 work tile。persistent kernel 进一步通过动态领取 worktile 减少尾部空闲,但真正改变任务量分布的,仍然是对长请求的动态切分。
因此,在分析 Decode Attention 性能时,除了关注 Batch Size 和 Total Tokens,还需要关注 Batch 内部的长度分布。尤其是在长短请求混合的场景下,最长请求是否被有效切分,往往会直接影响 Kernel 尾部耗时。
附录:为什么 SGLang 在 Hopper 架构的 MHA 后端不用 FlashInfer
依据 FlashInfer 原本的设计,在 Ampere 架构上应该走 FA2 路径,在 Hopper 架构上应该走 FA3 路径。
经过实验测试发现,FlashInfer v0.6.1 在 BF16 Dtype 上,BatchPrefillWithPagedKVCacheKernel 的 FA3 后端性能不如 FA2 的,即出现了性能退化
在 SGLang 社区(#17411 issue)与 FlashInfer 社区(#2400 issue)已经有相关 issue 指出了这一现象。
针对这一现象,一些 pr 提出了暂时的解决办法:
- FlashInfer 社区 #2530 pr,在 non-fp8 时,将后端选择直接设定为 FlashInfer 的 FA2 路径
- SGLang 社区 #17425 pr,设置 Hopper 架构的默认 Attention 后端为 FlashAttention-3
- SGLang 社区 #18364 pr, 在 Hopper 架构下,如果显式设置用 FlashInfer 作为后端时,把 auto 的路径选择设置为 FA2 路径
最后,感谢宫鹏宇、刘兴元、顿时同学的讨论与帮助~