作者:jzx
原文:https://zhuanlan.zhihu.com/p/2043283053787841480
TL;DR:SwiGLU 是目前大模型的标配激活函数,但它在低精度训练中会产生严重的数值不稳定问题。我们设计了一个新激活函数 PowLU,用更平缓的增长曲线替代 SwiGLU 的二次爆炸,从 Scaling Law再到千亿模型上都验证了其有效性,不仅解决了 Loss Spike,性能还略有提升。
技术报告地址:
PowLU: An Activation Function for Stable Pre-Training of LLMs
https://arxiv.org/abs/2605.25704
SwiGLU 的"甜蜜烦恼"
如果你做过大模型训练,一定对 SwiGLU 不陌生。这个激活函数现在是 LLM 领域的"标配"—— 从 Llama 开始,DeepSeek 用它、GPT 用它,几乎所有主流模型都在用。所有的选择都共识了一件事情:SwiGLU 通过门控机制增强了模型的表达能力,在各类下游任务上都表现优异。
但我们在训练 Ling 系列模型的过程中,发现了一个 SwiGLU 的隐藏痛点:当输入值变大时,它的输出会近似于x^2的二次增长。
这是什么概念?想象一下,当你在训练一个百层的万亿参数模型,SwiGLU 的二次放大效应会将模型训练过程中的一些异常值(Outliers)逐层放大,这些异常值最终可能会超出精度的表示范围(尤其是在 FP8 甚至更低精度的训练中),结果就是——训练不稳定、Loss Spike、甚至训练崩溃。
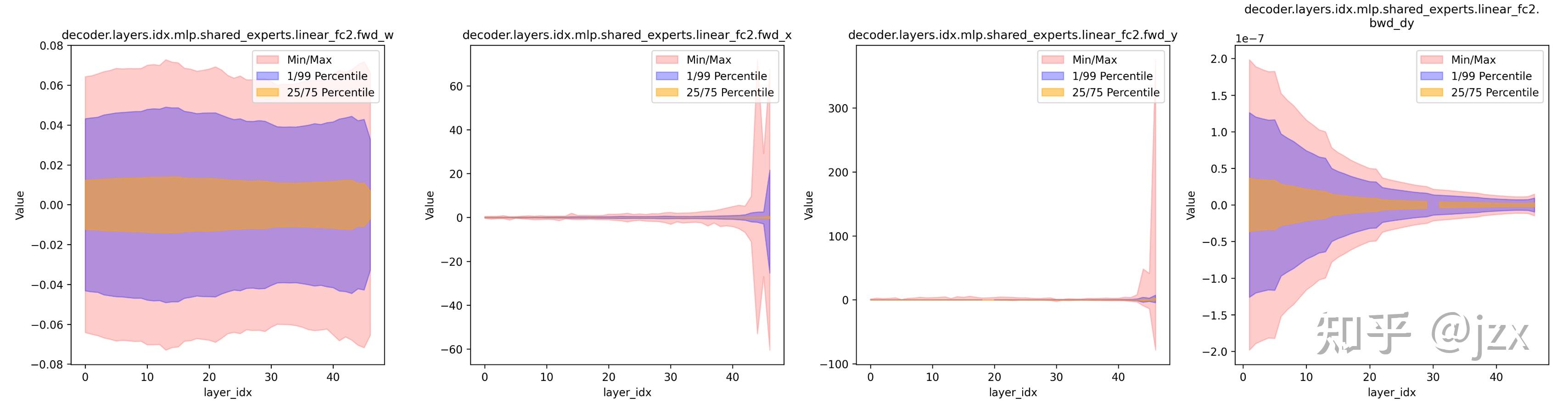
上图是我们实际训练过程中遇到Loss Spike时的模型数值分布,可以看到 SwiGLU的激活输出和导数中红色部分(Outlier值域)随输入增大和层数增多而迅速膨胀,这正是训练中各种不稳定现象产生的根源。
PowLU 的诞生
不幸的是我们在 Scale 训练模型的大小的时候,遇见了难以解决的 Loss Spike 问题;一些常规的手段,例如跳过数据、梯度裁剪等都无法解决;我们也尝试过一些业界的解决方案,比如 SwiGLU-Clip(GPT-OSS,DeepSeekV4,Step-Fun)——直接给激活值加个截断。
这个方案一定程度上推迟了 Loss Spike 的发生,但是同时也面临另外一个问题:一旦超过阈值,信息就直接丢失了。此外,在哪些层进行 Clip?Clip 的值是多少?都必须根据经验和实际情况进行判断,否则非但不能解决 Loss Spike 问题,反而会导致模型表达能力变弱,性能下降。
我们希望找到一个更优雅的方案:既能限制输出范围,又能保持非线性表达能力。于是 PowLU(Power Linear Unit)诞生了。
公式长这样
\text{PowLU}(x) = \begin{cases} x \cdot x^{\frac{m}{\sqrt{x}+1}} \cdot \text{sigmoid}(x) & x > 0 \\ \ x^2 \cdot \text{sigmoid}(x) & x \leq 0 \end{cases}
看起来比SwiGLU复杂一些?其实核心改动只有一处:在正半轴,我们用\sqrt{x}+1替代了指数的衰减因子。
当然,在实际的训练中为了让 PowLU 更符合当前LLMs的训练范式(即激活函数的输入X会被线性映射成两个X_1和X_2 ),PowLU 正半轴的实际计算会被修改为
三个关键设计
第一,\sqrt{x}让衰减更平缓
当x增大时,指数部分\frac{m}{\sqrt{x} + 1}会趋近于0,激活函数逐渐退化为线性。但\sqrt{x}比x增长慢得多,所以这个退化过程被放慢了——模型既能享受非线性的好处,又不会被二次爆炸困扰。
第二,分母+1保证可微性
如果没有这个+1,当x趋近于 0+ 时,\frac{m}{\sqrt{x}}会趋向无穷大,数值直接爆炸。这个改动确保了函数在 x=0+处的可微性,让训练更稳定。
第三,保留 Sigmoid 增强非线性
Sigmoid 函数的引入不是多余的——它进一步增强了非线性,确保模型有足够的表达能力。
直面难题
PowLU 原理介绍到此为止,我们直接来看看它是否能解决我们的问题:
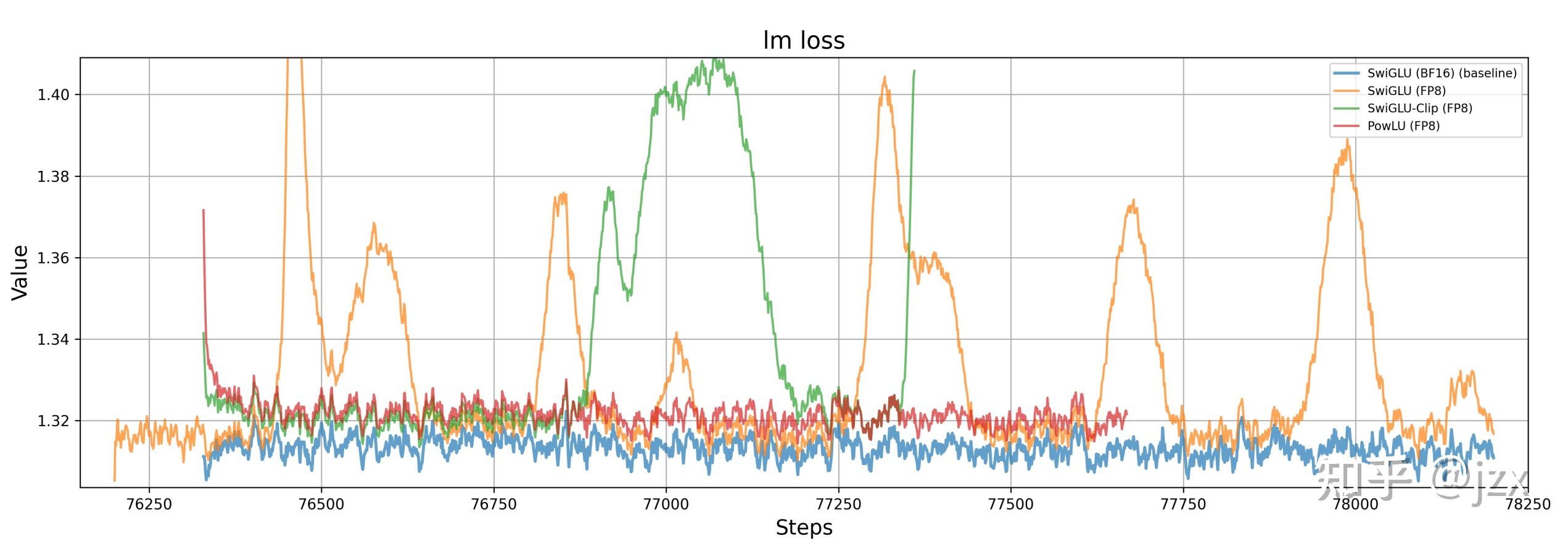
这张图记录了我们在实际训练过程中遇到的真实 Loss Spike 问题:
- 橙色(SwiGLU-FP8):用FP8训练 SwiGLU 作为 baseline,出现了明显的 Loss Spike,并且跳过数据以及梯度裁剪都无法解决
- 绿色(SwiGLU-Clip-FP8):从 SiwGLU 切换到 SwiGLU-Clip(Clip值为7),SwiGLU-Clip 延迟了 Spike 的出现,但仍未能避免
- 红色(PowLU-FP8):从 SwiGLU 切换到 PowLU,始终保持平滑稳定的 Loss 曲线,稳定在1.32左右
- 蓝色(SwiGLU-BF16):从 FP8 切换到 BF16 高精度训练,扩展了模型的表达范围,Loss 稳定
PowLU 的红色曲线完美符合我们想要的结果。
从 Scaling Law 到千亿参数
从解决实际问题的角度来看,PowLU 无疑是成功的,它缓解了训练中的出现的 Outlier,避免了训练中出现的不稳定现象。然而其他问题随之而来,对于模型训练它是否会影响最终的效果?虽然有训练稳定性的提升却会牺牲掉模型的使用体验?为了回答这些疑问,我们从 Scaling Law 的验证出发,再到更大的千亿参数模型上进行完整的验证并得出结论——PowLU 在效果上也不弱于 SwiGLU。
Scaling Law 验证
在大规模训练之前,我们先用26M到368M激活参数的小模型做了 Scaling Law 实验:
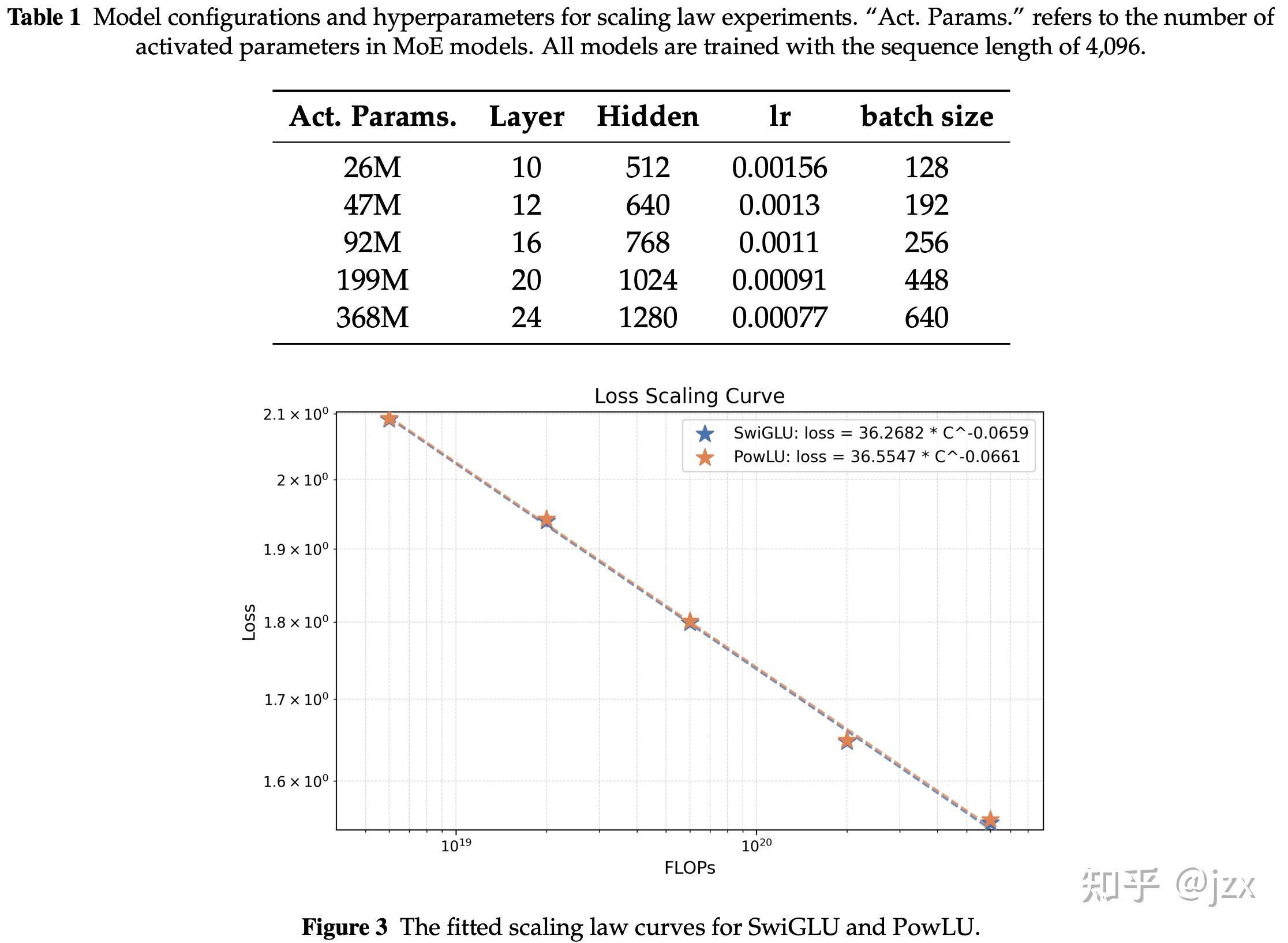
好消息是:PowLU和SwiGLU的拟合曲线几乎完全重合。这说明PowLU在不同规模模型上的性能趋势与SwiGLU一致,具备良好的规模可扩展性。
7.9B和124B模型验证
进一步的我们在一个 7.9B 以及 124B 的模型规模上分别训练了 600B 和 800B Token,对 PowLU 进行了验证:
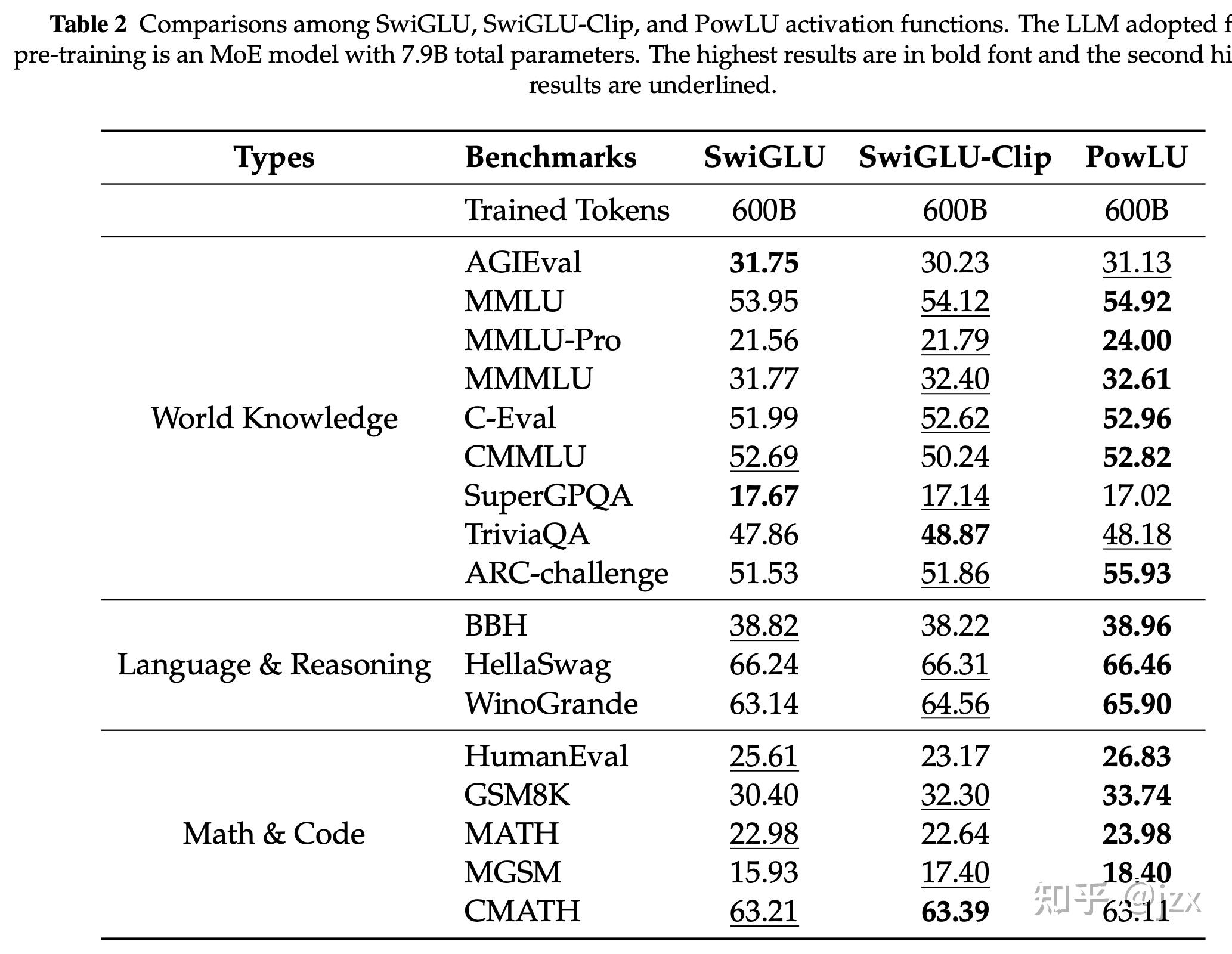
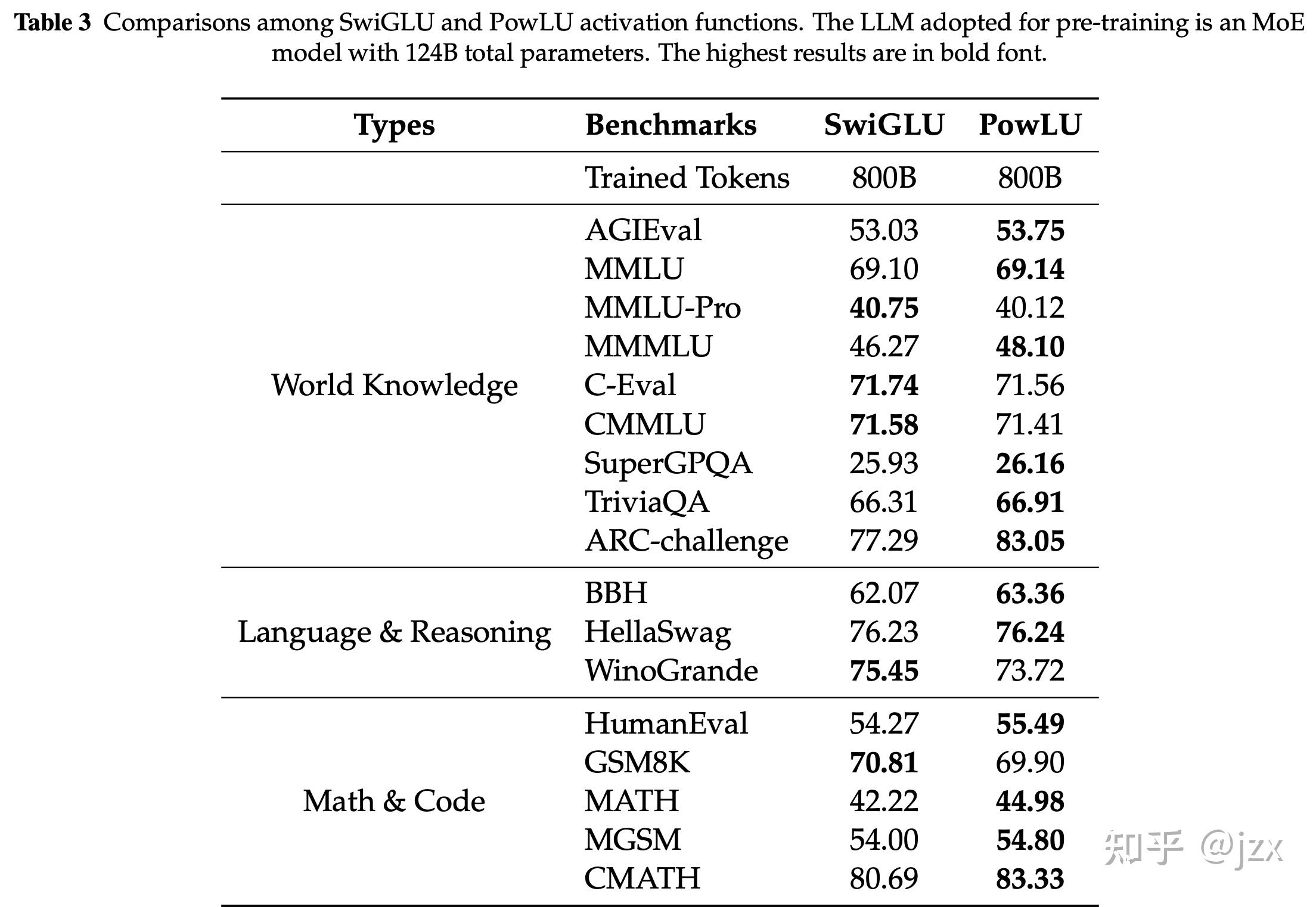
结果也让我们惊喜,在17个评测基准的整体表现,PowLU 优于或持平于 SwiGLU 和 SwiGLU-Clip。
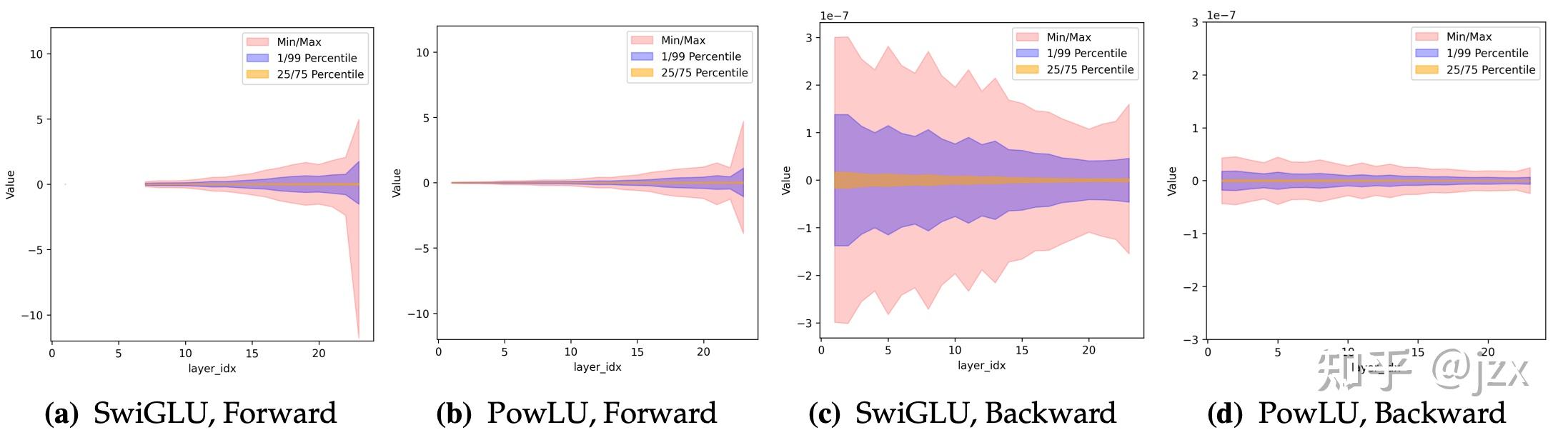
稳定性:PowLU如何解决Loss Spike?
最后我们还有一个疑问🤔,PowLU 如何解决的 Loss Spike 这一切是否和模型中的异常值有关系——这可能是 PowLU 最直观的优势体现。为了回答这个关键的问题,我们对 SwiGLU 和 PowLU 中的模型状态进行了进一步的可视化分析——以前文中提到的异常 Loss Spike 为例,模型在 Loss Spike 前后的数值分布出现了明显的变化,我们也从这一点入手分析了 SwiGLU 和 PowLU 在数值分布上的情况。
Routed Experts
Shared Experts
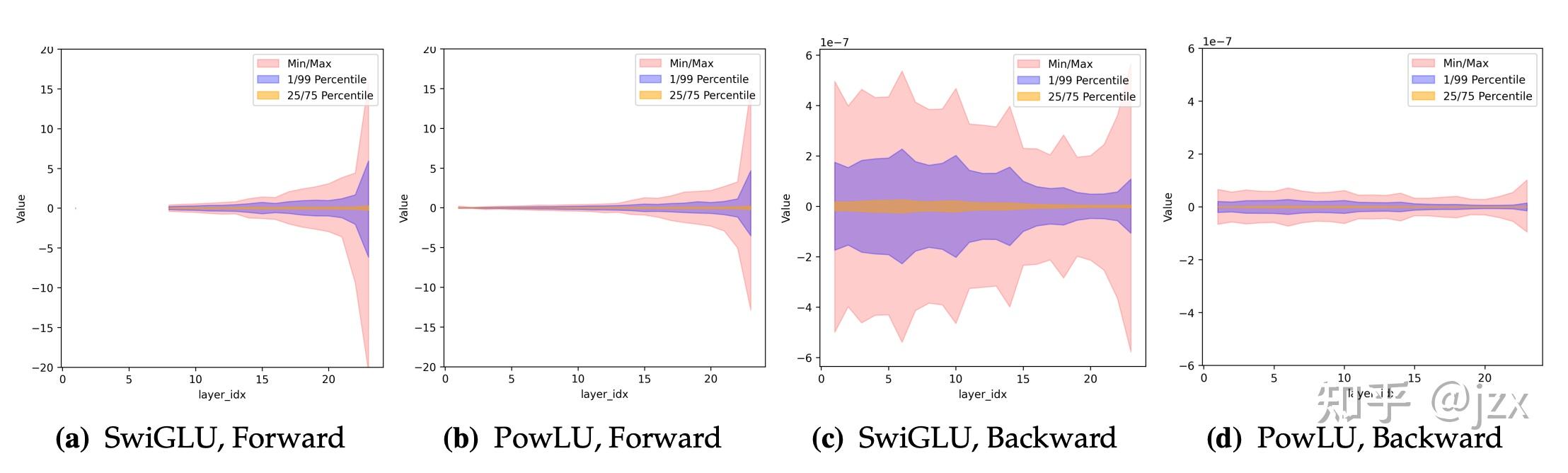
这两张图展示了同样Scale模型训练同样 Token后,激活函数输出激活值的数值分布情况。SwiGLU显示出明显的红色宽带延伸到极高的最大值,而 PowLU 的分布更加集中——PowLU 成功压缩了数值的动态范围,大幅减少了极端异常值。
一些碎碎念
做PowLU的过程中,我们最深的体会是:大模型和低精度训练时代,数值稳定性可能比表达能力更重要。SwiGLU 的设计很巧妙,但它诞生时模型规模还在几十B的大小,也并没有出现 FP8/FP4 这些低精度训练场景。二次增长的特性在当时不是问题,但在目前更深更大更低精度的训练中就成了瓶颈。
PowLU 的出发点很简单:在保持非线性的同时,把数值增长"压"下来。随着大模型训练进入FP4/FP8低精度时代,数值稳定性将成为一个越来越关键的议题。我们认为 PowLU 的设计思路——约束数值范围的同时保持非线性——可能会成为未来激活函数设计的重要方向。
当然,PowLU也不是那么完美,为了维持前段的非线性,我们引入了独立的超参数m,这引入了额外的复杂度,我们也在进行实验尝试能否去掉这个超参数,或直接给出最佳的m配置。
如果你也在做大模型训练,欢迎大家试试 PowLU。