如果说过去很多稀疏化方法一直在问“如何更好地剪掉权重”,那么 RT-Lynx 给出的答案是:对于 Diffusion Transformer,真正适合半结构化稀疏的对象可能不是权重,而是激活。

论文标题:RT-Lynx:Putting GEMM Sparsity in the Right Place for Diffusion Models
论文链接:https://huggingface.co/papers/2605.26632
01.从一个反直觉的现象说起
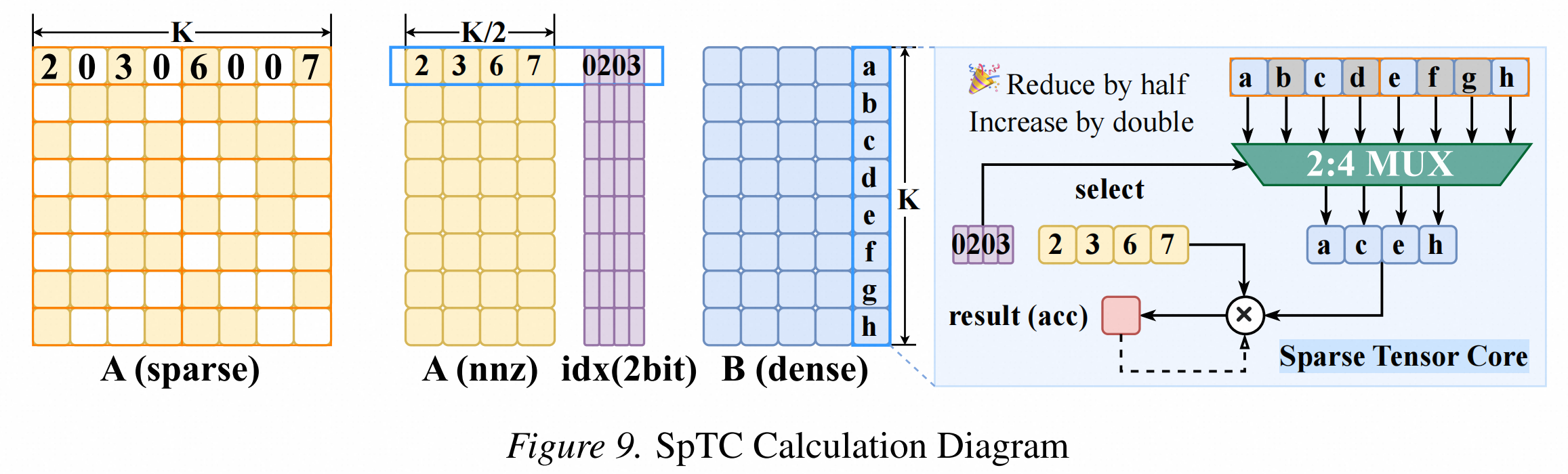
2:4 半结构化稀疏在 LLM 中已经被广泛研究:每 4 个连续元素中只保留 2 个非零值,从而降低 GEMM 计算量,并利用NVIDIA Sparse Tensor Core加速。
DiT的主要瓶颈同样来自大量Linear/GEMM,因此一个自然问题是:能不能把 LLM 中常见的权重稀疏方法直接迁移到扩散模型上?RT-Lynx的实验给出的答案很明确:不行。
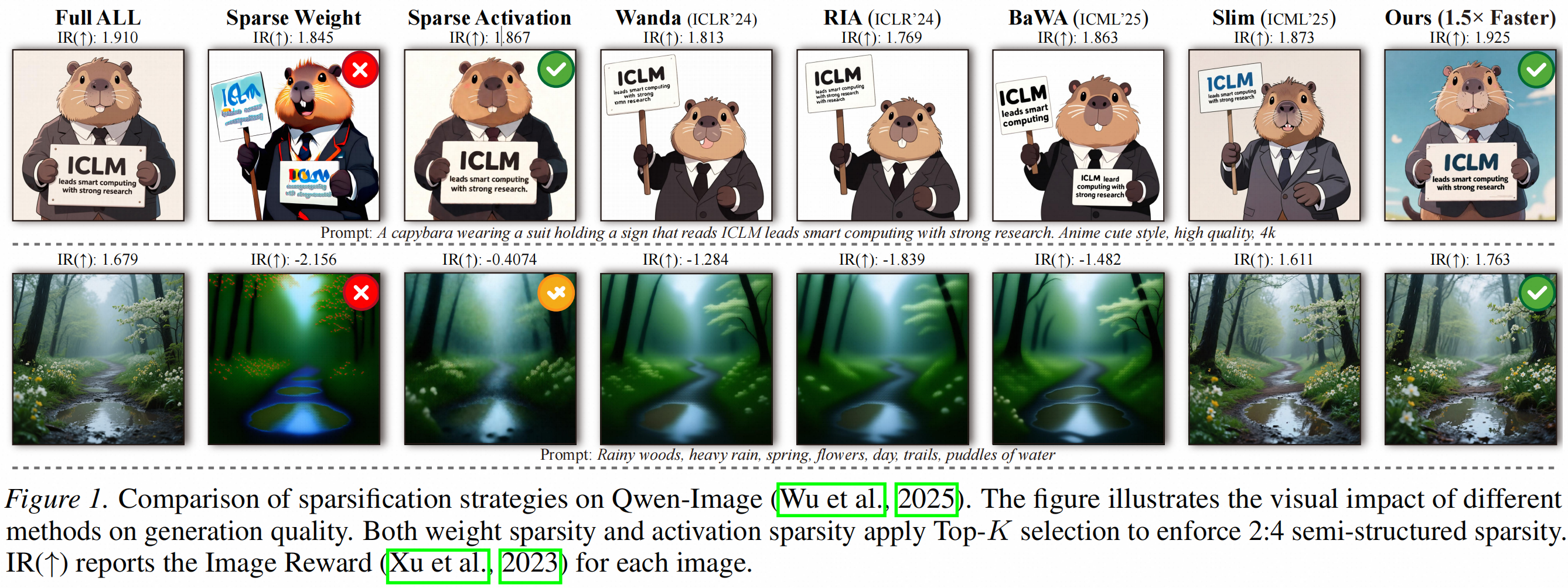
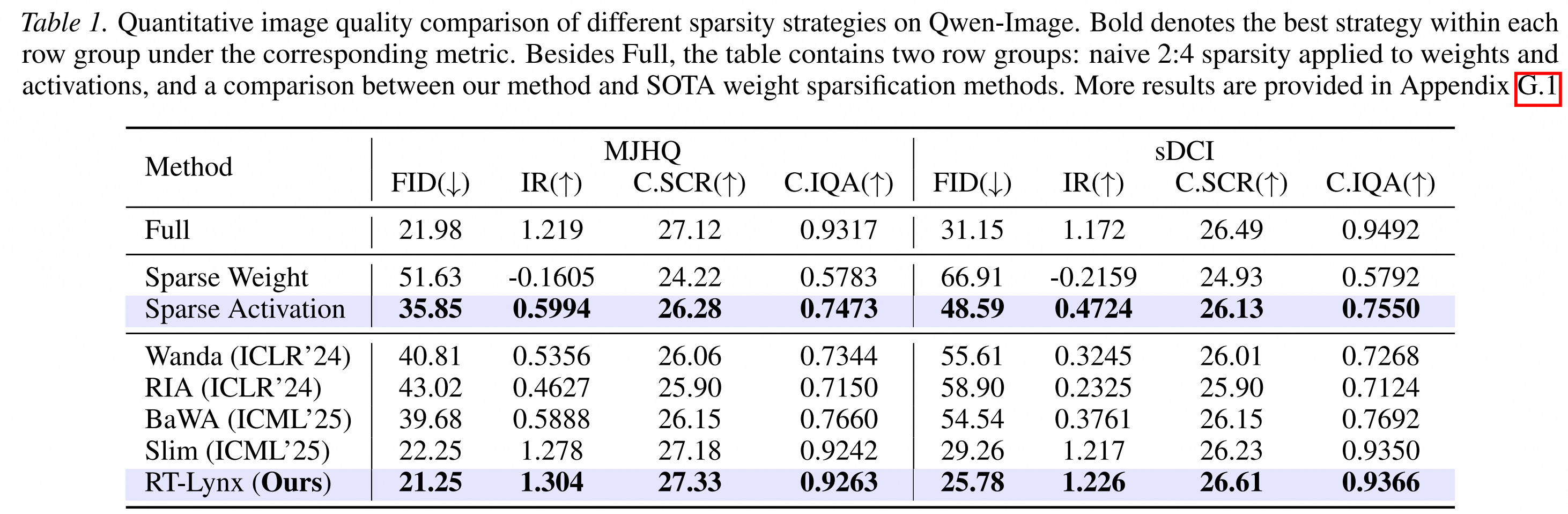
在Qwen-Image,直接做Sparse Weight会使MJHQ FID从21.98恶化到51.63,Image Reward从1.219掉到-0.1605。
即使使用Wanda、RIA、BaWA等权重稀疏方法,生成质量依然明显下降。相反,RT-Lynx对激活做稀疏后,MJHQ FID达到 21.25,Image Reward达到1.304,质量接近甚至略优于dense baseline。
这说明,DiT 并不是不能稀疏,而是不能沿用“剪权重”的默认路径。
02. 为什么是激活?
RT-Lynx 发现,DiT 的权重并没有天然适合 2:4 稀疏的结构。以 Qwen-Image 的 MLP.Down 层为例,权重分布近似高斯,非零值分布广泛,并不像“本来就接近稀疏,只需要整理一下”。
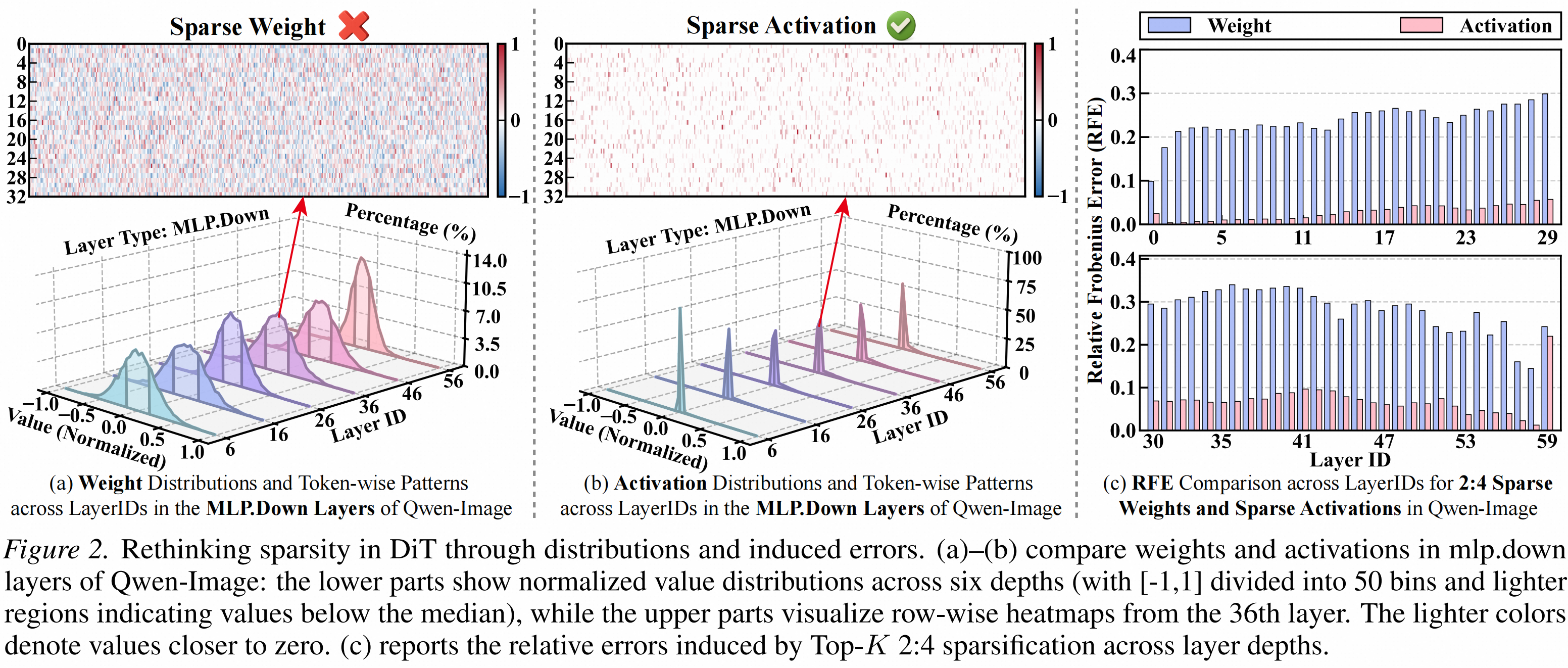
换句话说,权重承载的是模型已经学习到的生成能力。强行剪掉,损失的很可能不是冗余,而是能力本身。激活则不同。DiT 的 token-wise activation 天然具有稀疏性。每个 token 往往只对应少数语义概念,因此不会均匀激活所有通道。
所以二者的差别在于:剪权重,可能是在删除模型能力;剪激活,更像是在删除当前输入下接近无效的响应。因此,RT-Lynx将Linear层的计算从静态权重稀疏:Y = X W_s^T转向动态激活稀疏:Y = S(X) W^T,其中S(X)表示运行时生成的 2:4 稀疏激活,最终实现稀疏化范式的转移。
03. RT-Lynx 如何避免掉点?
直接对激活做Top-K稀疏仍然会损伤图像质量,因为一些低幅值激活也可能包含边缘、纹理、毛发等细节信息。为此,RT-Lynx设计了三类补偿。
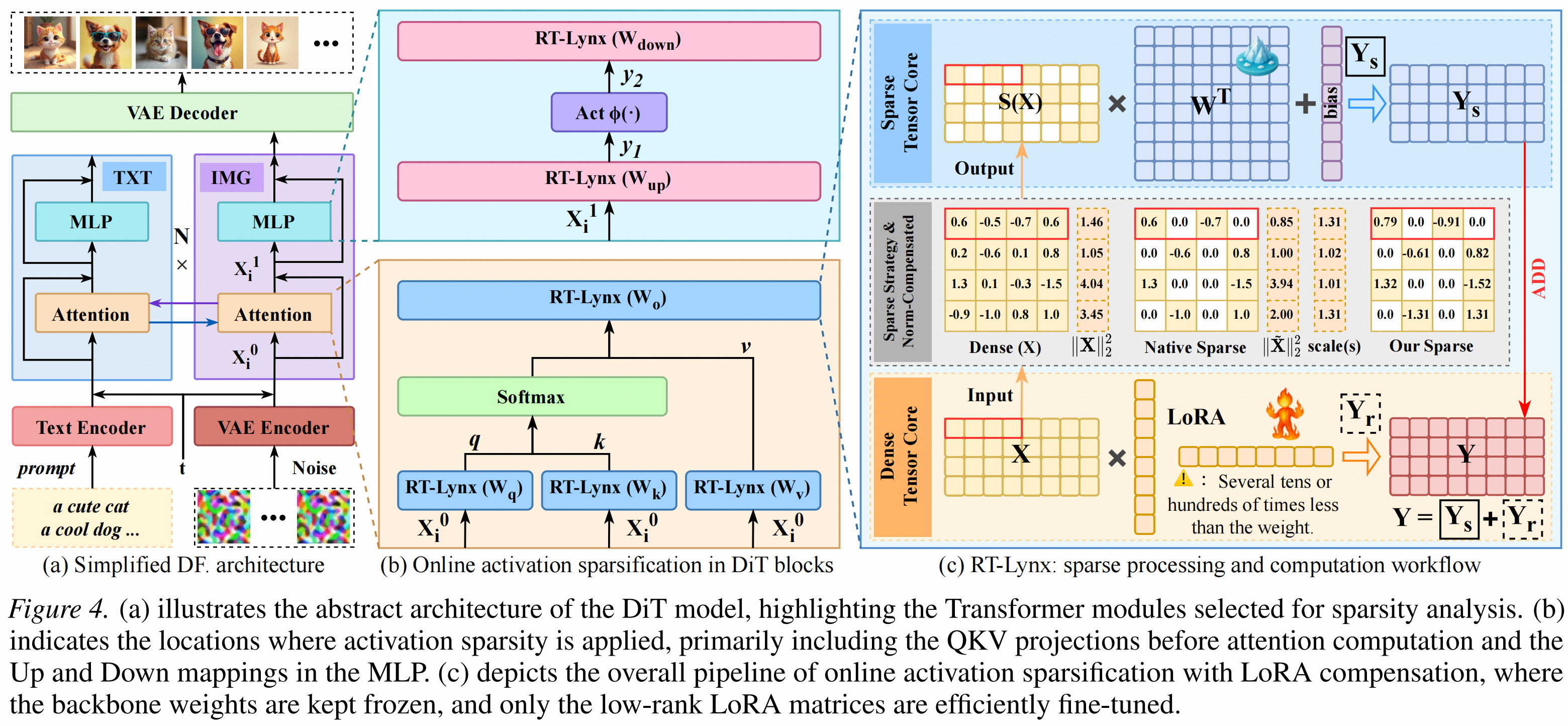
1.Norm Compensation。Top-K 会降低激活整体幅值,因此 RT-Lynx 对稀疏后的激活做重缩放,把整体能量补回来。在 Qwen-Image 上,仅加入这一步,就能把 MJHQ FID 从 35.85 改善到 25.28。
2.LoRA Compensation。范数补偿解决整体幅值问题,LoRA 分支则用于补回被剪掉的细粒度残差信息。主干权重保持冻结,只训练轻量 LoRA。加入后,MJHQ FID 进一步恢复到 21.25,达到 dense baseline 水平。

3.Selective Layer Skipping。对于 FLUX.1-dev 和 Z-Image 中较敏感的 single-stream path,RT-Lynx 会在部分层上跳过稀疏化,避免局部误差放大。
这套设计的核心不是“尽可能多地稀疏”,而是在质量和速度之间找到稳定平衡。
04. 真正难点在系统实现
激活稀疏比权重稀疏更难部署。权重只需要离线剪一次,而激活必须在每次推理时在线生成稀疏模式。
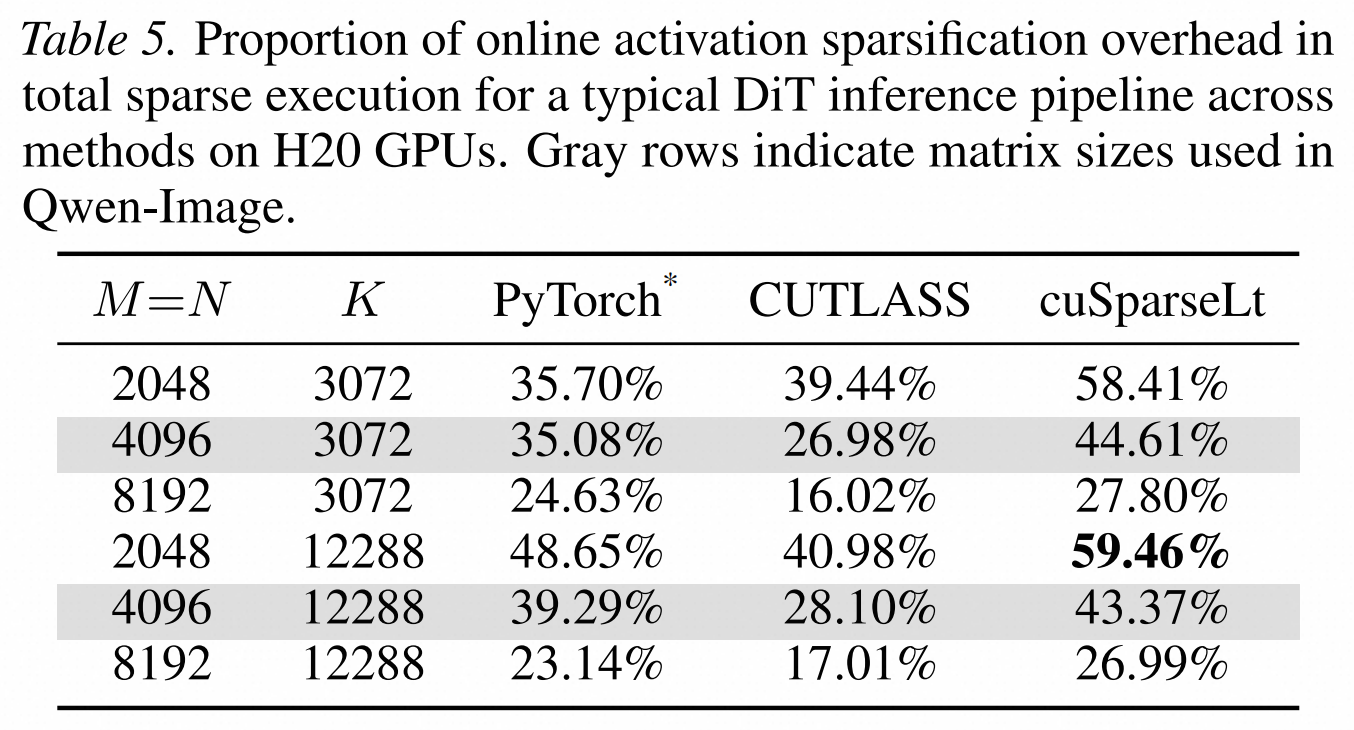
如果实现不当,在线稀疏化的开销会抵消Sparse Tensor Core的收益。论文指出,传统实现中的online activation sparsification开销可超过 40%,最高接近 59%。
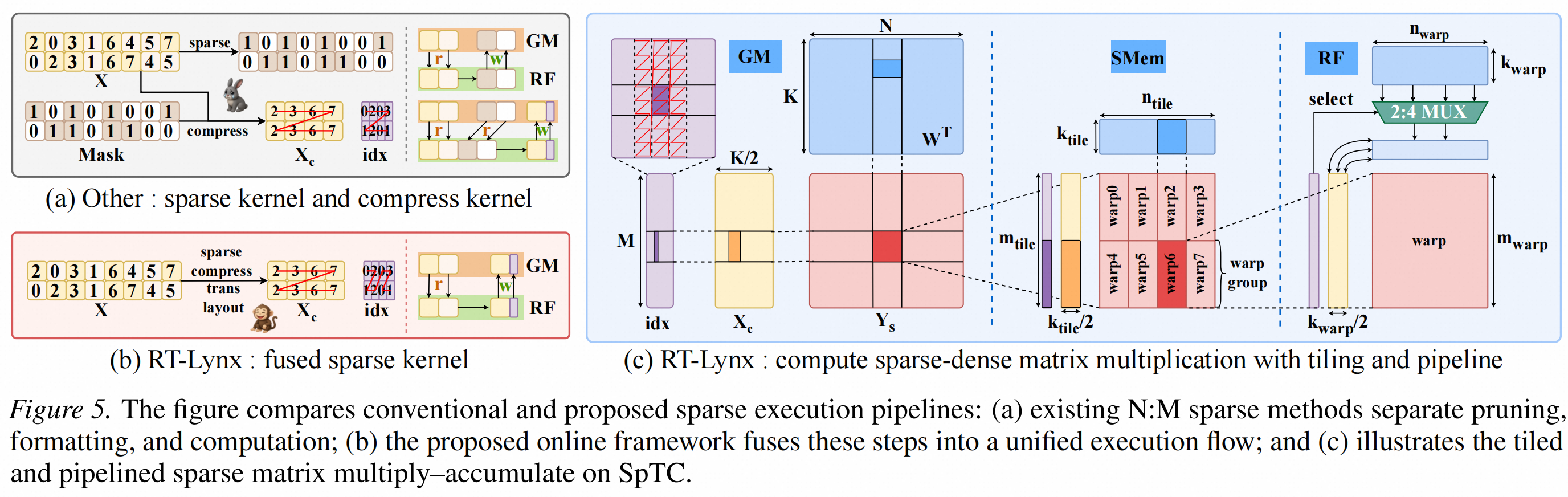
RT-Lynx的关键系统贡献,是把2:4pattern 判断、Top-K 选择、激活压缩,Sparse Tensor Core layout 生成、sparse GEMM 和 LoRA 残差计算融合进 CUDA kernel。这样可以避免中间张量反复写回,让动态激活稀疏真正变成一个低开销的推理路径。
05. 效果如何?
质量上,RT-Lynx 明显优于 Sparse Weight、Wanda、RIA、BaWA 等权重稀疏方法,也优于同样引入 LoRA 思路的 Slim。

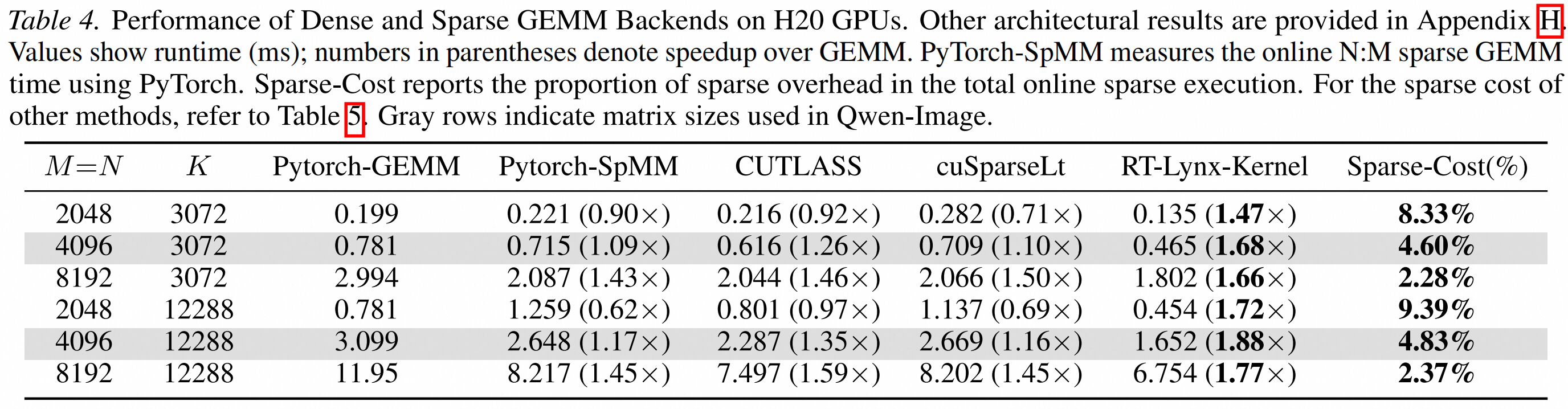
速度上,在 H20 GPU 上,RT-Lynx-Kernel 相比 dense GEMM 最高达到 1.88× 加速,并将在线稀疏化开销控制在 10% 以内。
端到端推理中,RT-Lynx 在 Qwen-Image、FLUX.1-dev 和 Z-Image 上都带来稳定收益:Linear 层平均加速 1.43× 到 1.55×,整体端到端加速约 1.2×。例如 Qwen-Image 的单步生成时间从 0.75s 降至 0.62s。
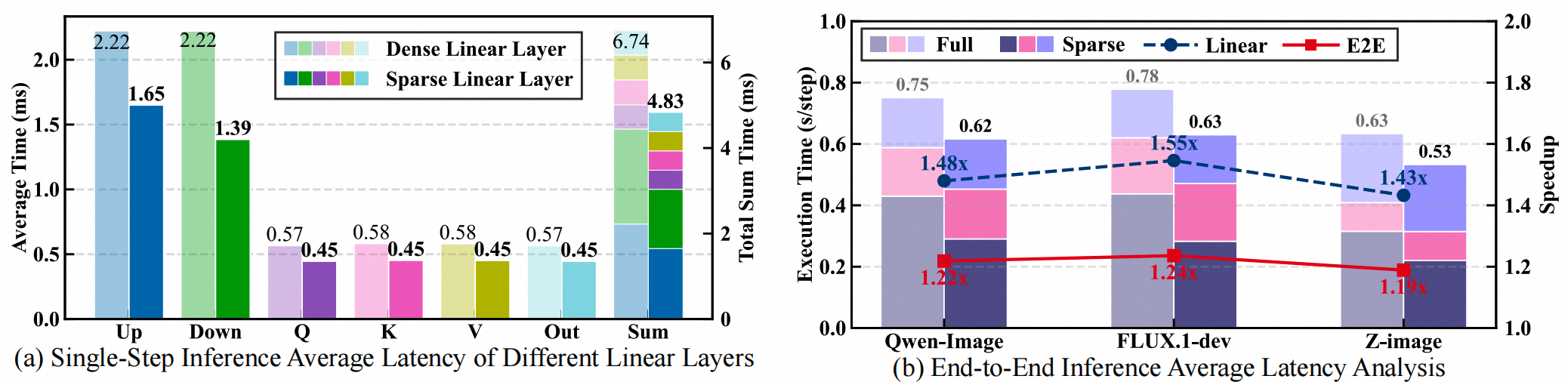
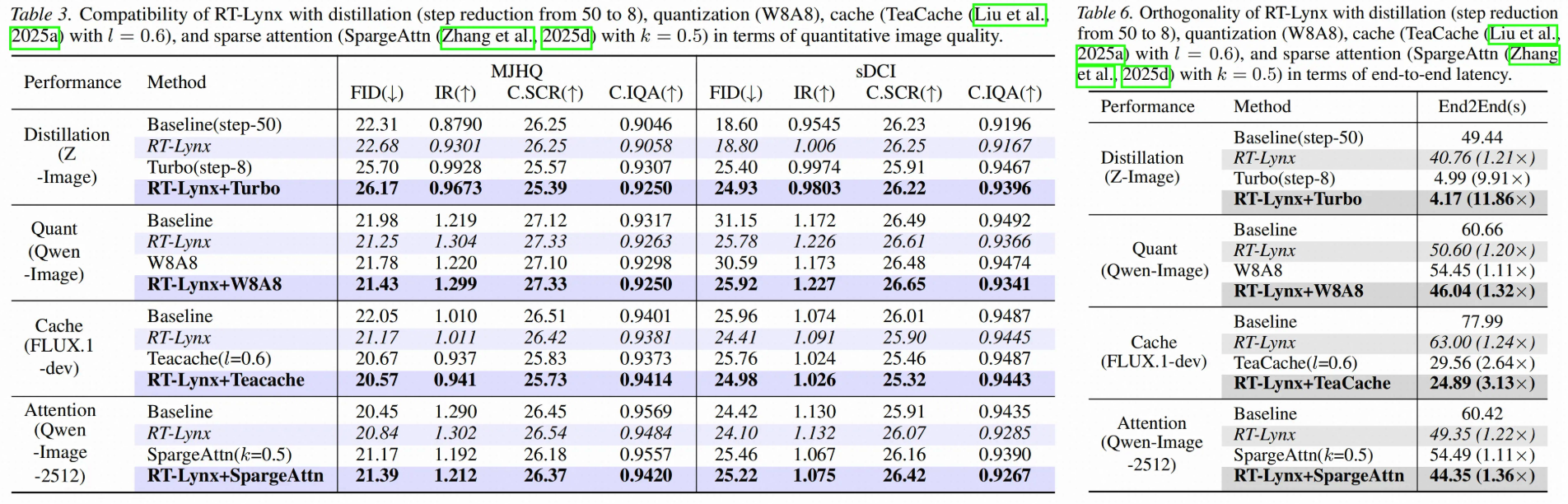
更重要的是,RT-Lynx 不依赖减少 diffusion step,也不改变生成流程,而是直接加速 DiT 中最核心的 Linear/GEMM 计算,因此,可以与其他加速方式兼容,实现更近一步的加速。
06. 结语
RT-Lynx 的核心观点很清楚:
扩散模型不是不能稀疏,而是稀疏性应该放在 activation 上,而不是 weight 上。
权重承载模型长期学习到的生成能力,强行剪掉容易破坏模型;激活反映当前输入下的动态响应,天然存在大量接近零的通道,更适合半结构化稀疏。
在此基础上,RT-Lynx 通过范数补偿、LoRA 残差修复、敏感层跳过和融合 CUDA kernel,让 activation sparsity 同时满足质量保持和实际加速。这篇工作的意义不只是提出了一个新的 DiT 推理加速方法,更重要的是为扩散模型的半结构化稀疏提供了一个更合理、更可部署的方向。
团队介绍
RTP-LLM 是阿里巴巴智能引擎团队自研的高性能大模型推理引擎,支持了淘宝、天猫、高德、饿了么等核心业务的大模型推理需求。智能引擎源自阿里巴巴搜索、推荐和广告技术,是阿里 AI 工程领域的先行者和深耕者。团队专注于 AI 工程系统的建设,主导建立了大数据 AI 工程体系 AI・OS,持续为阿里集团各业务提供高质量的 AI 工程服务。
RTP-LLM 项目已开源,欢迎交流共建: https://github.com/alibaba/rtp-llm