
大模型 Agent 这两年很火。
大家一提到“提升 Agent 能力”,第一反应通常是:换更强的模型、做微调、上强化学习、继续训练。
但我们最近一直在想一个问题:
如果 Agent 表现不好,问题真的一定出在模型本身吗?
很多时候,答案可能不是。
因为Agent并不是一个只会聊天的LLM。
它还要理解环境、调用工具、执行动作、接收反馈,并在多轮交互中持续决策。
也就是说,Agent 不只是模型本身,更是一套运行时系统。
Agent 的问题,很多时候出在“接口”上
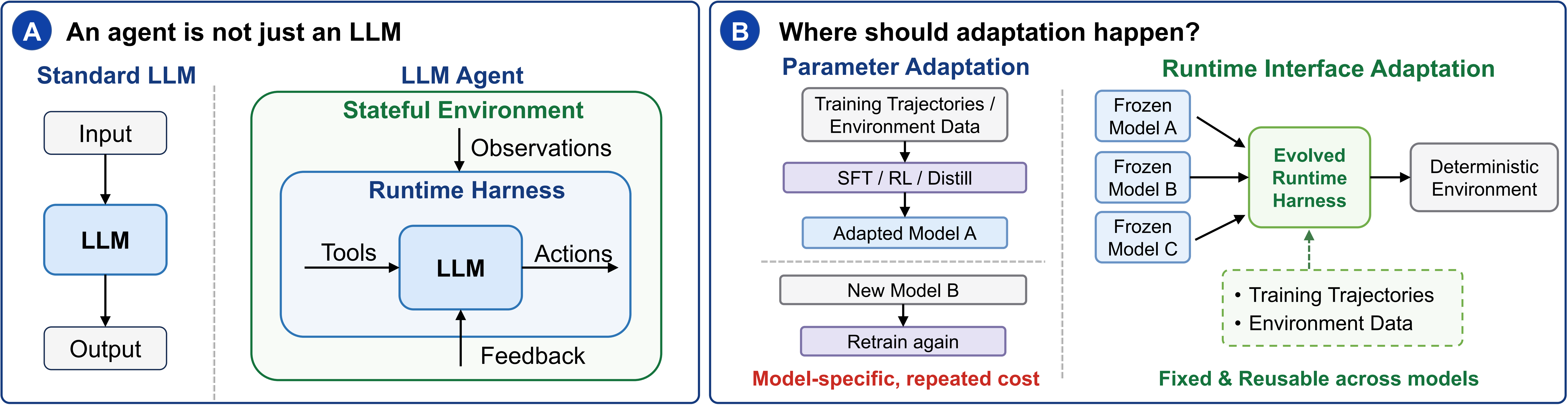
在很多垂直领域任务中,Agent失败未必是因为“不会”,而可能是因为“没接好”。
比如:
- 明明知道该做什么,却没有按环境要求正确执行;
- 理解了任务意图,但动作没有成功落地;
- 收到了错误反馈,却没有及时调整;
- 在长任务里反复绕圈,最后耗尽预算。
所以我们提出了一个不同的思路:
Adapting the Interface, Not the Model.
不急着改模型,而是先适配模型与环境之间的运行时接口。
这也是我们这项工作的核心出发点。
LIFE-HARNESS:给 Agent 加一个“运行时辅助系统”
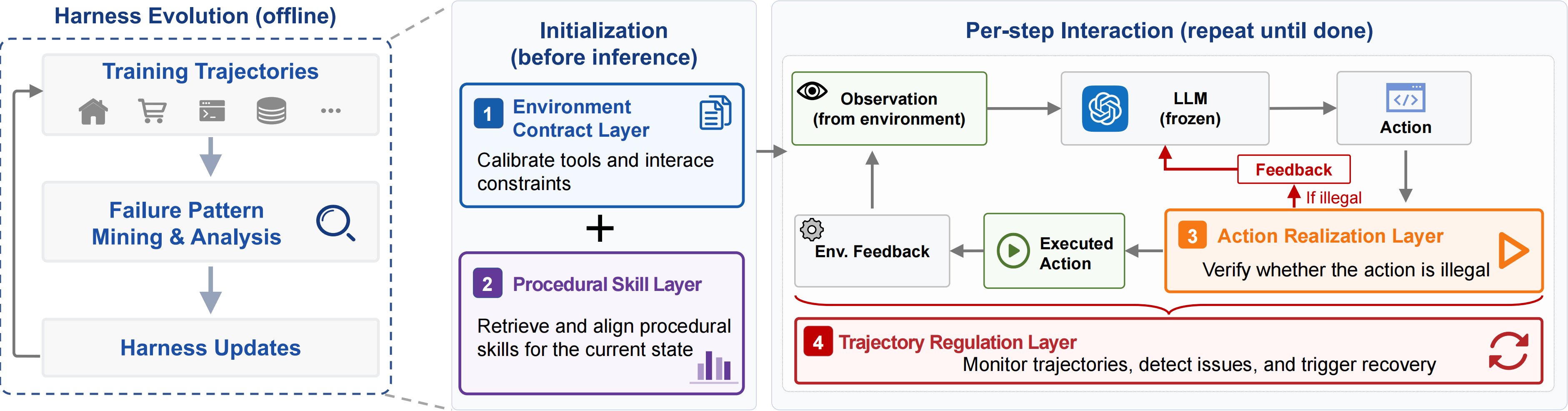
基于这个想法,我们提出了 LIFE-HARNESS。
你可以把它理解成:
在不修改模型参数的前提下,给 Agent 加上一套运行时辅助系统。
它不改变模型权重,也不改变评测环境,而是从训练轨迹中总结那些反复出现的失败模式,再把这些经验变成测试阶段可复用的干预机制。
整个框架分成4层,分别作用在Agent生命周期的不同阶段:
1. Environment Contract Layer
在任务开始前,先把环境规则讲清楚。
包括:这个环境怎么交互、哪些操作要注意、什么样的回答才是有效的。
它相当于先帮模型“读懂规则”,避免一上来就走偏。
2. Procedural Skill Layer
很多垂域任务其实都有稳定的“做事套路”。
这层会从训练轨迹中提炼出这些可复用的过程经验,并在新任务开始时提供给模型。
它就像给模型一份简明的任务攻略:
遇到类似任务时,可以参考过去成功的做法。
3. Action Realization Layer
模型想对了,不代表动作一定能顺利执行。
这一层会在动作真正交给环境之前,检查它是不是可执行的,并修正一些常见的格式问题。
它关注的是:
模型想做的事,能不能真正落到环境里。
4. Trajectory Regulation Layer
有些问题不是出在某一步,而是出在整条轨迹里。
比如反复尝试、持续停滞、陷入循环,或者快到步数上限了还没有收敛。
这层会监控轨迹状态,并在必要时给出纠偏提示,把 Agent 拉回正确方向。
实验结果:不改模型,依然能明显提升
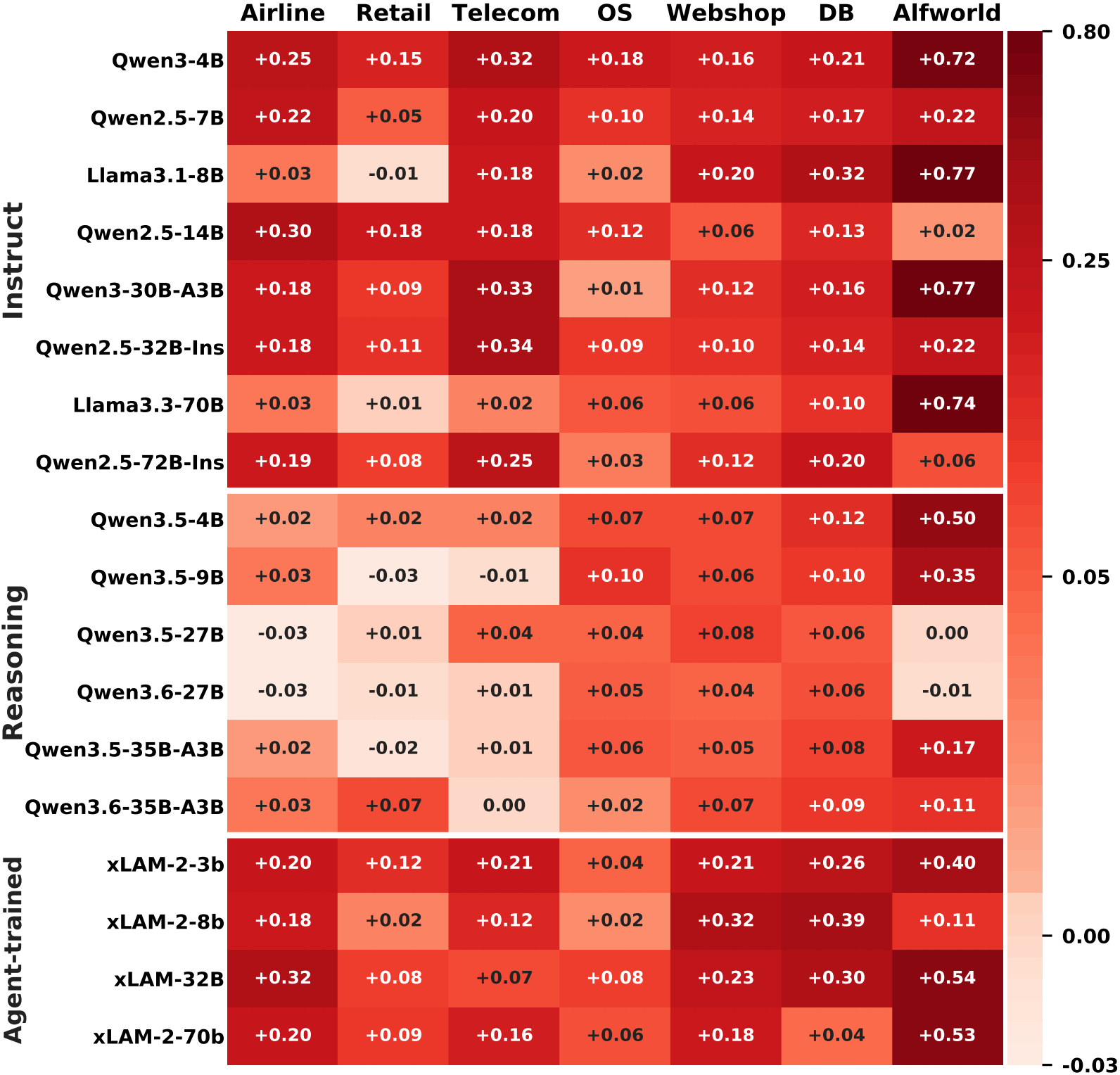
我们在3个benchmark, 7个 Agent 任务基准上,对18 个不同模型做了系统评估。
结果显示:
LIFE-HARNESS 在 116 / 126 个 model-environment 设置中带来提升,平均相对提升达到 88.5%。
更重要的是,这套harness的演化只使用了一个模型的训练轨迹,但最终能够迁移到另外17个模型上。
这说明它学到的并不是某个模型的“个人习惯”,
而是很多 Agent 环境里都普遍存在的稳定规律:任务规则、常见错误、执行模式,以及恢复策略。
这意味着什么?
这项工作的意义,不只是“又做出了一个更强的 Agent”。
它更重要的启发是:
提升 Agent,不一定只能靠重新训练模型。
在很多规则明确、流程稳定的垂域任务里,真正的问题可能不是模型能力不够,而是模型和环境之间的接口没有被很好地适配。
相比重新训练一个模型,优化运行时 harness 往往:
- 成本更低
- 迭代更快
- 对模型绑定更弱
- 更容易迁移到不同 backbone
这也说明,Agent 的能力不只存在于模型参数里,
也存在于它与环境交互的那套运行时系统中。
总结
我们提出的 LIFE-HARNESS 想回答一个很直接的问题:
能不能不改模型,只通过优化 runtime harness,就让 Agent 做得更好?
实验结果表明:在确定性、规则明确的垂域任务中,这是完全可行的。
所以,当一个 Agent 表现不佳时, 也许第一步不该总是“继续训练模型”,而是先问一句:
这个问题,真的需要改模型吗?
还是只需要把模型与环境之间的接口适配好?