开源链接
📄 Paper: https://arxiv.org/abs/2606.07229
🔥 Daily Paper: https://huggingface.co/papers/2606.07229
💻 Code: https://github.com/ddlBoJack/MMAE
🤖 Dataset: https://huggingface.co/datasets/BoJack/MMAE
🎬 Demo Video: https://youtu.be/6At5nTWhlXI
过去一年,多模态生成模型正在快速进入“可编辑”的时代。
图像编辑(Nano-banana2 等代表模型)已经跨过了从“生成一张图”到“按指令精修一张图”的阶段,而以 Gemini-Omni 为代表的视频编辑模型也开始围绕人物、场景、动作和镜头语言构建更统一的交互范式。
视觉世界里,高质量编辑体验正在变成新一代模型能力的标志。
但在另一个同样重要的模态里,情况并没有那么乐观。
音频编辑,尤其是面向真实世界的通用指令式音频编辑,仍然缺少一套足够全面、足够细致、足够可靠评测基础设施。
为此,上海交通大学、 上海创智学院、南洋理工大学、腾讯混元团队、天津大学、数搭国际数据开源社区、北京大学、复旦大学等机构联合提出 MMAE: A Massive Multitask Audio Editing Benchmark,一个面向通用指令式音频编辑的综合评测基准。它覆盖 Sound、Music、Speech 以及多种混合音频场景,构建了系统化的任务 taxonomy,并将开放式音频编辑任务拆解为 客观可验证的 rubric-based 评测细则,用于诊断模型在 Instruction Following 和 Context Consistency 两条轴线上的真实能力。

一、问题起点:为什么音频编辑需要新的 benchmark
音频编辑看起来像是一个已经存在很久的任务。
传统音频处理里有降噪、分离、增强、变声、音高调整、混音等成熟方向;生成式音频模型也已经可以生成语音、音乐和环境声。可是,当任务从“单点处理”变成“自然语言驱动的通用编辑”时,问题就变得复杂得多。
用户不会只说某个具体的原子指令,而更可能说:
“把这段音频里的背景音乐提取出来。”
“把雨声换成海浪声,但保留说话人的声音。”
“把这段男声变得更低沉,同时不要改变说话内容。”
“先删掉狗叫声,再把背景音乐调得更柔和一点。”
“根据音频内容推理出需要保留和修改的部分。”
这些指令背后,其实隐藏着几层长期被低估的挑战。
第一,音频天然具有高度混合性。
与视觉对象相对清晰的空间边界不同,Speech、Music、Sound 往往以叠加形式共同存在于同一段音频中。编辑某个目标成分时,模型不仅需要定位目标本身,还需要理解其与其他音频元素之间的关系,避免局部修改对整体声场造成连锁影响。
第二,音频编辑任务本身包含复杂的理解与推理要求。
用户给出的往往只是简洁的自然语言指令,但其背后可能隐含目标定位、内容理解、属性约束、上下文保留以及多步编辑等复杂要求。模型需要同时具备音频感知、指令理解、语义推理和高保真生成能力,才能正确完成编辑目标。
第三,音频编辑存在天然的“修改—保留”矛盾。
编辑系统既需要准确执行用户要求的修改,又需要尽可能保持其余内容不受影响。修改不足意味着指令未被完成,修改过度则会破坏原有上下文。一切音频编辑任务都要在这两种目标之间寻找平衡。
第四,现有评测方法难以刻画这种能力。
传统音频编辑评测长期依赖CLAP分数、频谱距离、音质分数或相似度等指标。然而对于通用音频编辑而言,这些指标往往无法回答真正关键的问题:
- 模型是否正确理解了用户意图?
- 目标修改是否被准确执行?
- 非目标内容是否被完整保留?
- 多轮编辑后上下文是否依然一致?
- 在复杂混合场景中,模型究竟是在完成编辑,还是在重新生成一段看似合理的新音频?
MMAE 正是围绕以上问题构建。

二、MMAE Taxonomy:系统刻画通用音频编辑空间
MMAE 的核心出发点之一,是为通用音频编辑建立一套系统化的任务分类体系。
现有音频编辑研究大多围绕单一任务展开,例如内容编辑、声音替换或源分离等。然而真实世界中的音频编辑远不止于此:不同音频模态之间相互混合,不同编辑操作往往需要组合执行,任务本身还可能包含多轮交互、多步推理以及复杂约束。
为了系统覆盖这一能力空间,MMAE从模态(Modality),Complexity和操作类型(Operation) 三个维度构建统一 taxonomy。
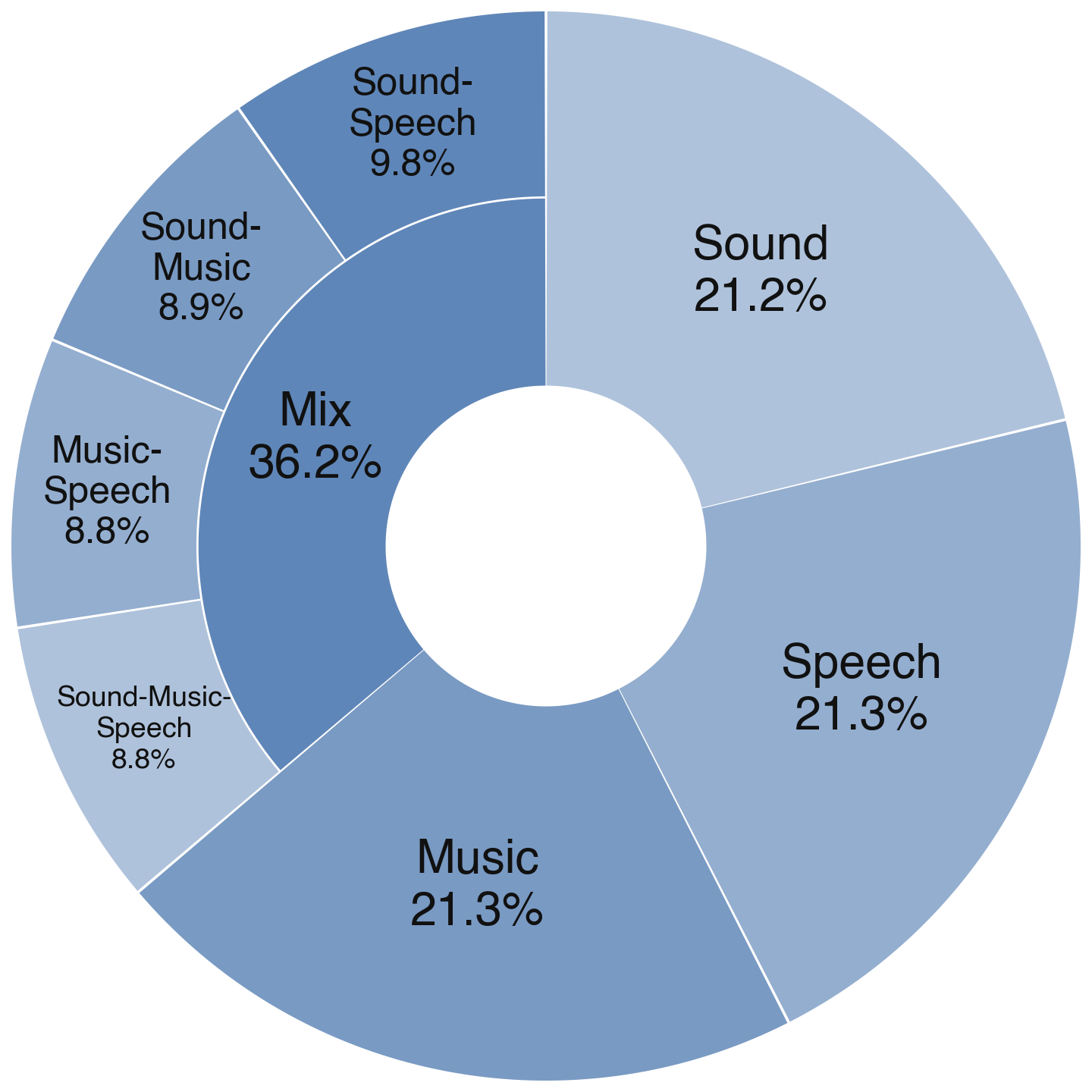
1. 七大音频模态:覆盖从单一模态到复杂混合场景
在模态维度上,MMAE 系统覆盖 Sound、Music、Speech 及其混合形态,共计 7 类音频模态。
这一设计使评测能够从单一模态编辑扩展到更接近真实应用场景的混合模态编辑任务,并分析模型在不同模态组合下的能力边界与泛化性能。
例如,同样的编辑操作在纯 Speech 场景中可能相对简单,但在 Speech-Music-Sound 混合场景中,则需要模型同时处理多个语义层次和声学成分之间的相互影响。
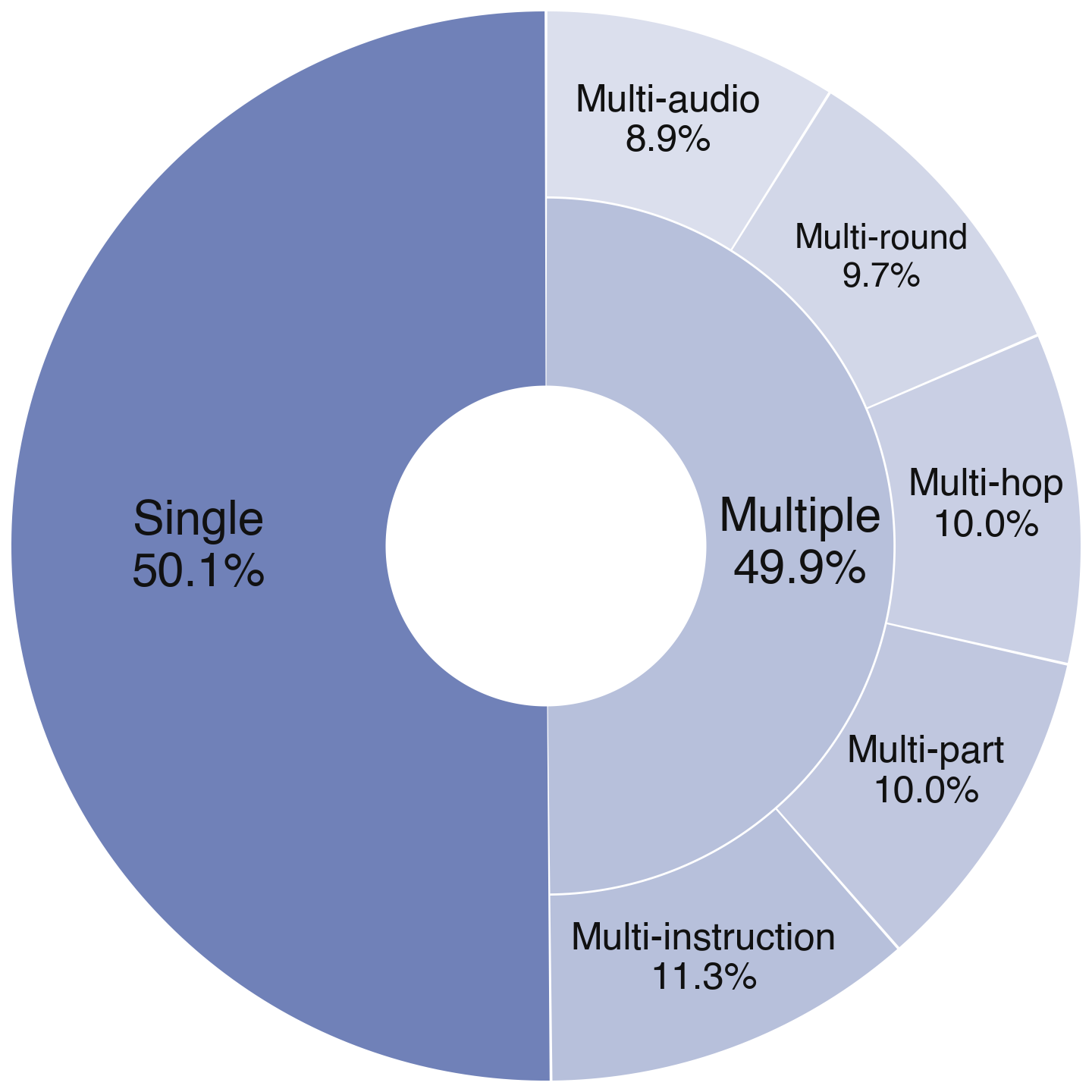
2. 六级任务复杂度:从基础编辑到多轮推理
在复杂度维度上,MMAE 构建了覆盖六个层级的任务谱系。
从单一简单指令到多主体、多指令、多源输入、多轮迭代以及多跳推理驱动等高难度编辑,系统刻画任务复杂性的增长过程。
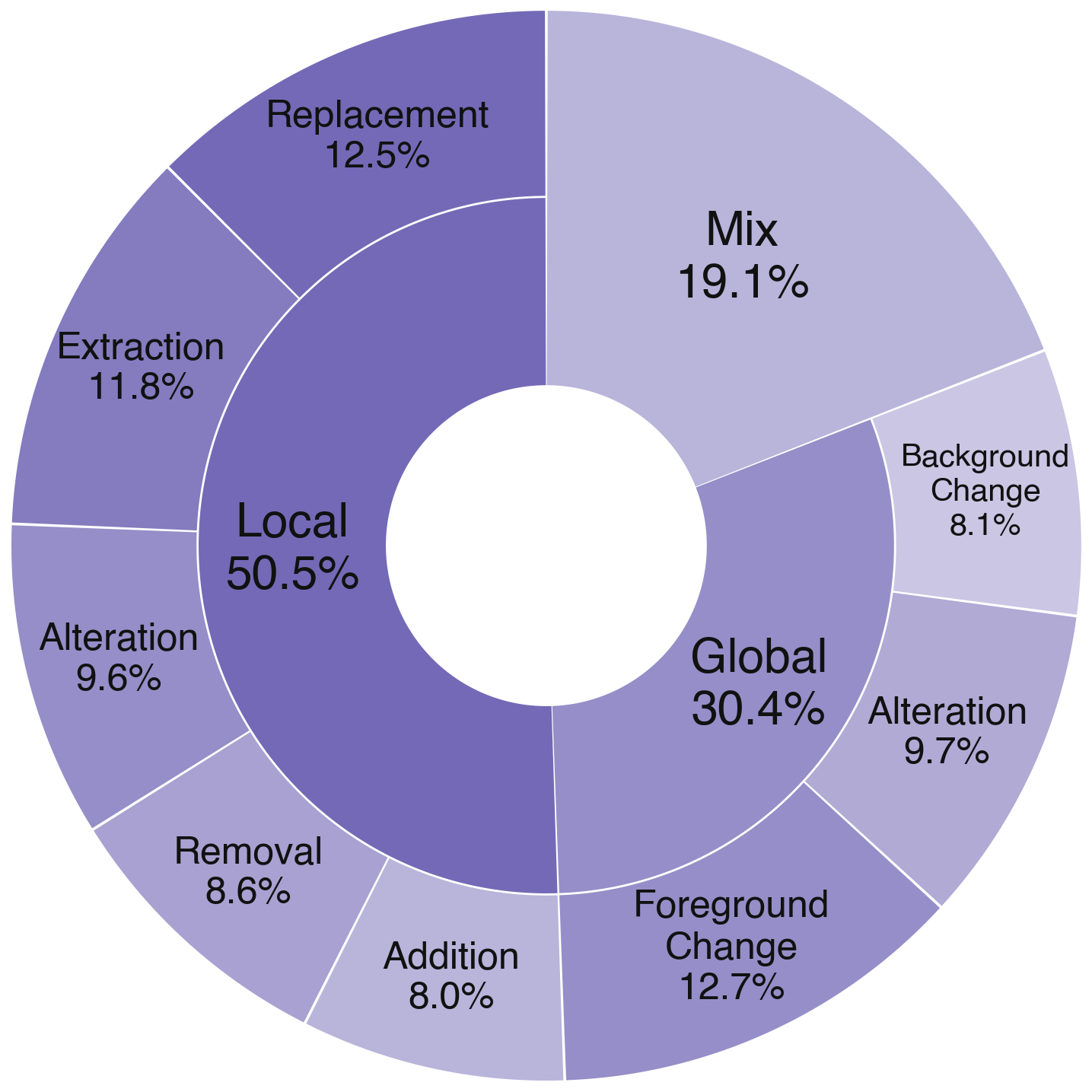
3. 八类编辑操作:细粒度拆解音频编辑能力
在操作维度上,MMAE 将通用音频编辑划分为八类核心操作,覆盖局部与全局层面的增加、删除、修改、提取以及属性控制等编辑行为。
这一划分不仅保证 benchmark 对主流音频编辑场景的覆盖度,也使评测结果能分析反映出模型的底层能力。
三、从开放式任务到可验证 Rubric:MMAE 的核心评测范式
音频编辑最大的评测难点,是输出空间高度开放。
同一个指令可能存在多个合理结果。比如“把背景音乐调小一点”,不同模型可能选择不同的响度变化,只要人声清晰、音乐音量下降但仍然存在、整体听感自然,都可以被认为是正确的。
如果只依赖一个标准答案,就会误伤合理编辑;如果只依赖主观打分,又会引入评审偏差和不可复现性。
MMAE的解决方案是 rubric-based evaluation。
它将每个开放式编辑任务拆解为多个客观、可验证的细则。每个细则都对应一个清晰问题:某个目标是否完成,某个上下文是否保留,某种不该出现的伪影是否被引入。
这套设计的好处在于,它把“听起来对不对”进一步拆解成可诊断的原子判断。
例如,对于一个删除背景狗叫声、保留人声和环境声的任务,rubric 可以分别检查:
- 狗叫声是否被移除;
- 说话人内容是否仍然清晰;
- 说话人的音色是否没有明显变化;
- 背景环境是否没有被错误清空;
- 是否产生新的噪声、断裂或伪影;
- 整体音频是否保持自然连续。
这样一来,评测不再只是一个笼统分数,而是一组可解释的行为证据。
四、双轴卡尺:Instruction Following 与 Context Consistency
MMAE 的另一个核心设计,是将音频编辑能力拆成两条独立评测轴线:
Instruction Following和 Consistency。
Instruction Following:该改的有没有改
Instruction Following 衡量模型是否正确执行了用户指令。
- 如果用户要求删除雨声,模型是否真的删除了雨声?
- 如果用户要求提取音乐,输出是否主要包含音乐成分?
- 如果用户要求调整语速、音高或情绪,目标属性是否发生了正确变化?
这条轴线关注的是“编辑目标是否达成”。
Consistency:不该动的有没有保留
Consistency 衡量模型是否保留了上下文中不应被修改的内容。
- 如果只要求删除背景噪声,人声内容是否仍然完整?
- 如果只要求改变音乐风格,旋律主体是否还在?
- 如果多轮编辑中修改了某个局部,之前正确完成的部分是否被破坏?
这条轴线关注的是“编辑边界是否稳定”。
这也是音频编辑和普通音频生成最大的区别之一。编辑不是从零生成,而是在已有上下文中精确动刀。一个真正可靠的音频编辑模型,必须同时做到“改得准”和“留得住”。
MMAE 通过双轴评测,把这种能力差异显式暴露出来。
五、客观裁判:用高性能 MLLM 进行多轮投票评测
为了让 rubric-based evaluation 可以规模化执行,MMAE 使用高性能多模态大模型(例如 Qwen3-Omni)作为 judger。
评测时,judge model 会根据音频输入、编辑指令、模型输出和对应 rubric,对每条细则进行判断。每个 rubric 会收集多次有效 judge 响应,通过多轮投票降低偶然误判和单次评审偏差。
这套评测机制兼具两个优势。
- 一方面,它比传统信号指标更接近真实语义编辑目标,能够判断复杂音频场景中的内容、属性和上下文一致性。
- 另一方面,它又比完全人工主观评分更容易复现和扩展,可以支持大规模模型比较、taxonomy 分析和细粒度错误诊断。
也就是说,MMAE 并不是简单用一个黑箱 judger 替代人类评审,而是用 rubric 将评测目标拆分成一个个 judger 可评测的原子问题(rubric),再通过多轮投票把每个局部判断稳定下来。
六、MMAE 数据构建:人类与 Agent 协作的五阶段管线
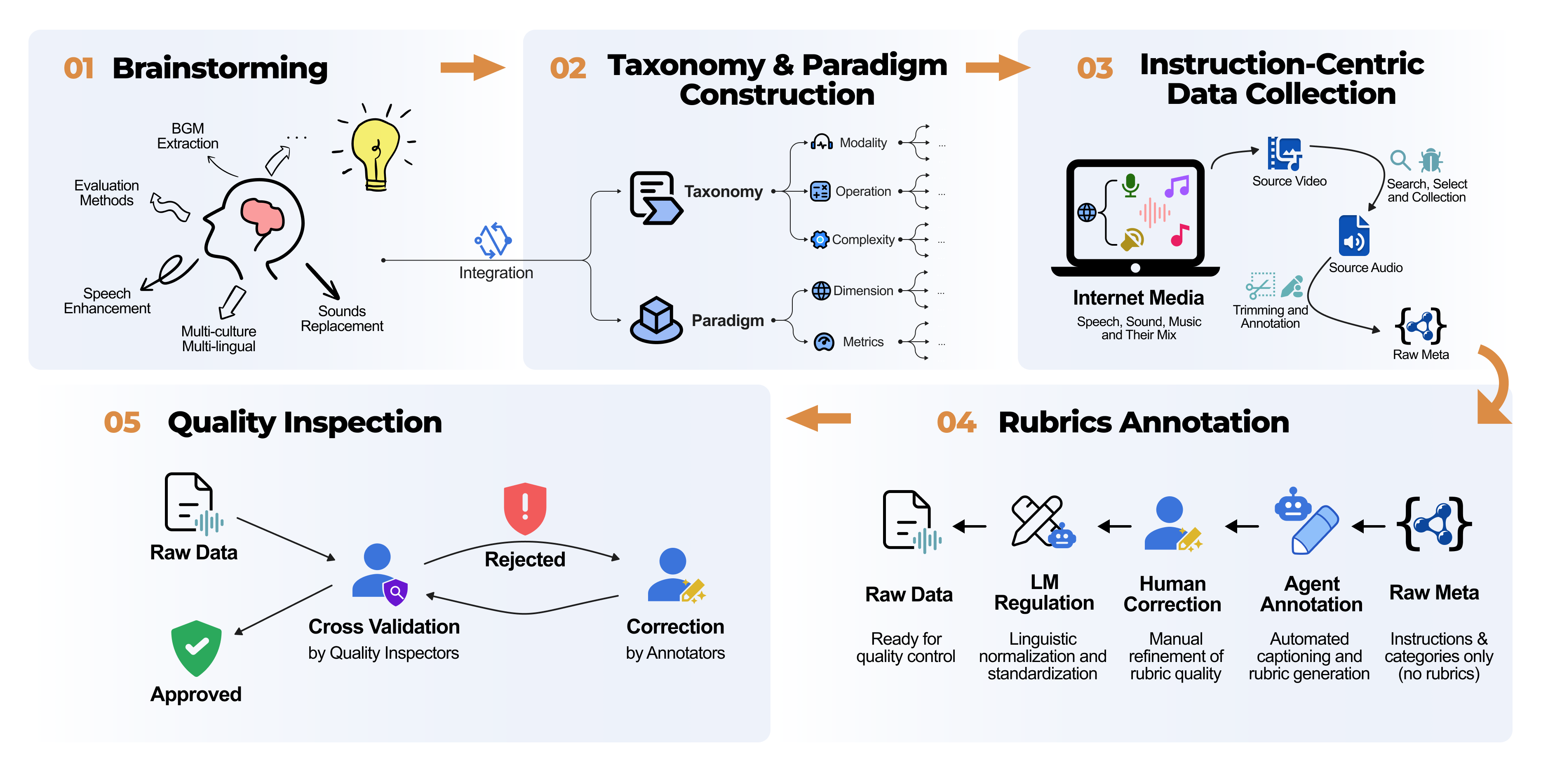
为了构建高质量的 Benchmark,MMAE 设计了一套人机协同的数据构建流程,共包含五个阶段:
1.Brainstorming:围绕真实世界音频编辑场景进行任务设计与需求收集;
2.Taxonomy & Paradigm Construction:构建覆盖模态、复杂度与操作类型的统一任务分类体系;
3.Instruction-Centric Data Collection:采集高质量音频样本,并围绕自然语言编辑指令组织任务;
4.Rubrics Annotation:为每个任务设计细粒度评测细则,将开放式编辑目标拆解为可验证标准;
5.Quality Inspection:对音频质量、指令合理性、标注一致性和评测规则进行全面审核。
整个流程结合人工审核与自动化辅助,确保数据在覆盖范围、任务多样性以及评测可靠性上的质量。
最终,MMAE 构建了包含 2,000 个高保真音频编辑样本 和 17,741 条可验证 Rubric 的大规模测试集。
七、测评发现:音频编辑距离“Banana 时刻”还有多远?
MMAE 的实验结果揭示了一个非常直接的结论:
当前音频编辑模型距离真正通用、可靠的指令式编辑仍然很远。
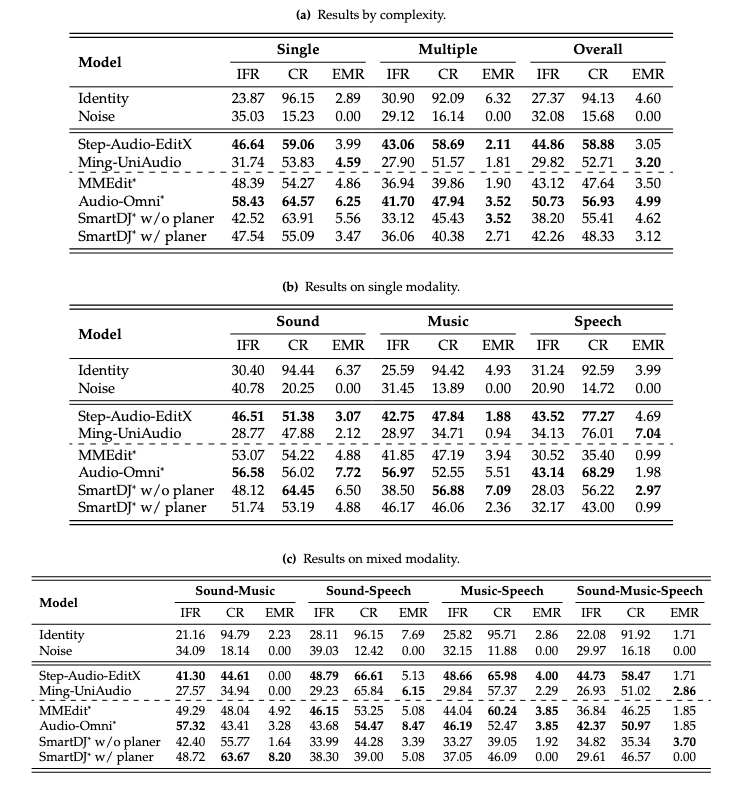
1. 完美执行率全线崩塌
MMAE 使用 Exact Match Rate,简称 EMR,衡量一个样本中所有关键 rubric 是否全部满足。
这个指标非常严格,也非常符合真实使用体验,因为在真实编辑任务中,用户往往不接受“整体还行但错了一点“。
实验发现,顶尖模型在 MMAE 上的整体 EMR 无一例外低于 5%。在复杂混合模态下,EMR 甚至直接掉到 0%。
这说明,很多模型虽然可以在平均分上看起来“还不错”,但要做到每个关键要求都不出错,仍然非常困难。
2. 高平均分不等于可靠
MMAE 还发现一个很有趣的现象:
一些“全能型”模型在平均分上较高,但由于小错不断,EMR 反而输给某些局部“专家型”模型。
这说明平均分会掩盖可靠性问题。
一个模型可能在大多数 rubric 上都拿到不错分数,但每个样本里总会漏掉一两个关键要求。对 benchmark 来说,它看起来不差;对用户来说,它就是“不稳定”。
这也是 MMAE 强调 EMR 的原因。
通用音频编辑不只是追求平均性能,而是追求任务级可用性。一个真正可用的编辑模型,必须减少这种“每次都差一点”的失败模式。
3. Agent Planner 并不总是帮忙
随着 Agentic workflow 的流行,一个自然想法是:能不能让外部 planner 先拆解音频编辑任务,再调用模型逐步完成?
MMAE 对现有模型的评测结果显示,Planner的确可能带来轻微的Instruction Following 提升。也就是说,规划器能帮助模型更好地理解要做什么。
但问题在于,多轮串联也会引入新的失败链条。每一步输出都会成为下一步输入,一旦前面出现指令偏差或原子性修改错误,后续步骤会继续放大这些问题。最终,Consistency 反而遭到严重破坏。
这说明,音频编辑中的 Agent 化并不是简单“多规划几步”就能解决。对于音频这种连续信号,长期一致性、指令精确性和原子操作可靠性本身就是核心挑战。
八、如何使用 MMAE 评测你的音频编辑模型
MMAE 目前已全面开源并提供了完整的评测接口。
开发者可以将自己的音频编辑模型在 MMAE 的测试数据上进行推理,并按照指定格式保存预测音频路径。随后,使用评测脚本调用 Qwen3-Omni judger,对每个 rubric 进行多轮评估,并输出多层级结果:
results.jsonl:每个 rubric 的详细 judge 结果,包括多次响应、选择、分数和原始输出。per_sample.json:每个样本的 Instruction Following、Consistency 和 Exact Match 结果。taxonomy.json:按照模态、难度、操作类型和交叉维度聚合后的分析结果。
最终不仅可以得到一个总体分数,还可以定位模型在哪类音频、哪种复杂度、哪种操作上失败。
九、为什么 MMAE 对下一代音频编辑重要
MMAE 的价值不只是提供一个排行榜。
它更像是一套面向通用音频编辑模型的诊断基础设施。
对于模型研究者来说,MMAE 可以帮助回答:模型到底缺少什么能力?是听不懂指令,还是保不住上下文?是不会处理混合模态,还是在多轮任务中误差累积?是局部编辑失败,还是全局属性控制不稳定?
对于系统开发者来说,MMAE 可以帮助比较不同 pipeline。比如单模型端到端编辑、Planner + Editor、多模型级联、检索增强编辑、分离后编辑再混合等方法,究竟哪种更可靠。
对于整个社区来说,MMAE 试图建立一个长期可扩展的评测范式:用 taxonomy 保证覆盖度,用 rubric 保证可验证性,用双轴指标保证诊断性,用 MLLM judger 多轮评测保证规模化和稳定性。
视觉编辑已经进入“香蕉时代”,音频编辑也需要自己的 ”Banana Benchmark 🍌“。
欢迎大家阅读论文、试用 benchmark、给 GitHub 点点 Star,也欢迎在 HuggingFace Daily Paper 为 MMAE Upvote。