作者:banana
原文:https://zhuanlan.zhihu.com/p/2039735648421163598
OPD相关的论文这几个月每周冒出好几篇,剧本和当年xPO(DPO 之后)、xGRPO(GRPO 之后)几乎一样,大家围着它做排列组合。本文试图对近期这一波工作进行初步梳理——哪些工作是同一个问题换说法、哪些是动了不同的模块。
AOPD:把 advantage 切成正负两半分别处理
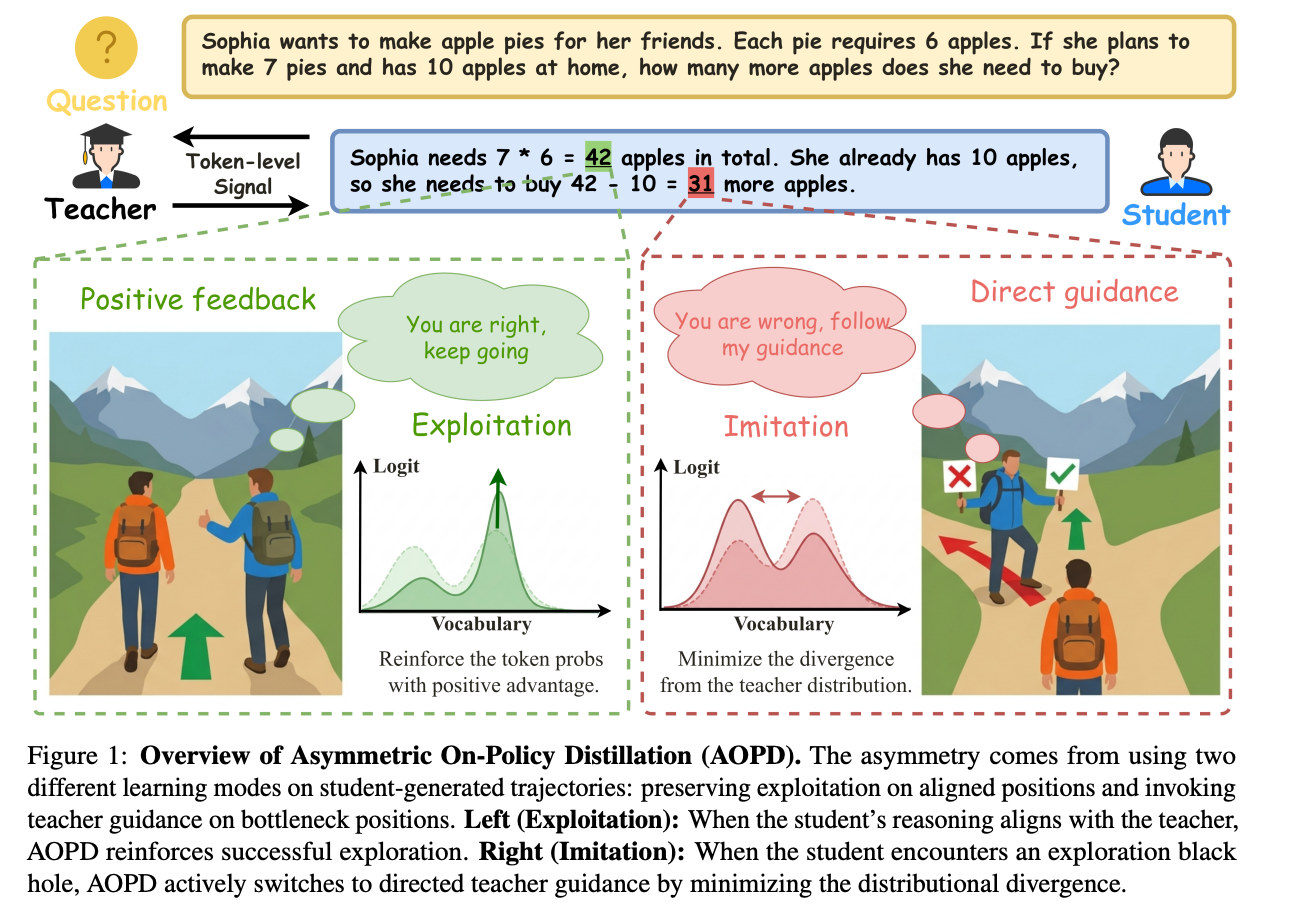
AOPD 的视角很直白。GRPO 的 policy gradient 在不同 advantage 区域 SNR 差别巨大:零 advantage 区域梯度消失,负 advantage 区域是高方差噪声,正 advantage 区域才是真正可信的学习信号。
所以作者按 advantage 符号切两段——正 advantage 保留 policy gradient(exploitation),非正 advantage 换成直接的KL散度最小化(imitation)。实验上 strong init+4.09%、weak init+8.34%。
SOD:在 tool-use agent 上把信号衰减做出来
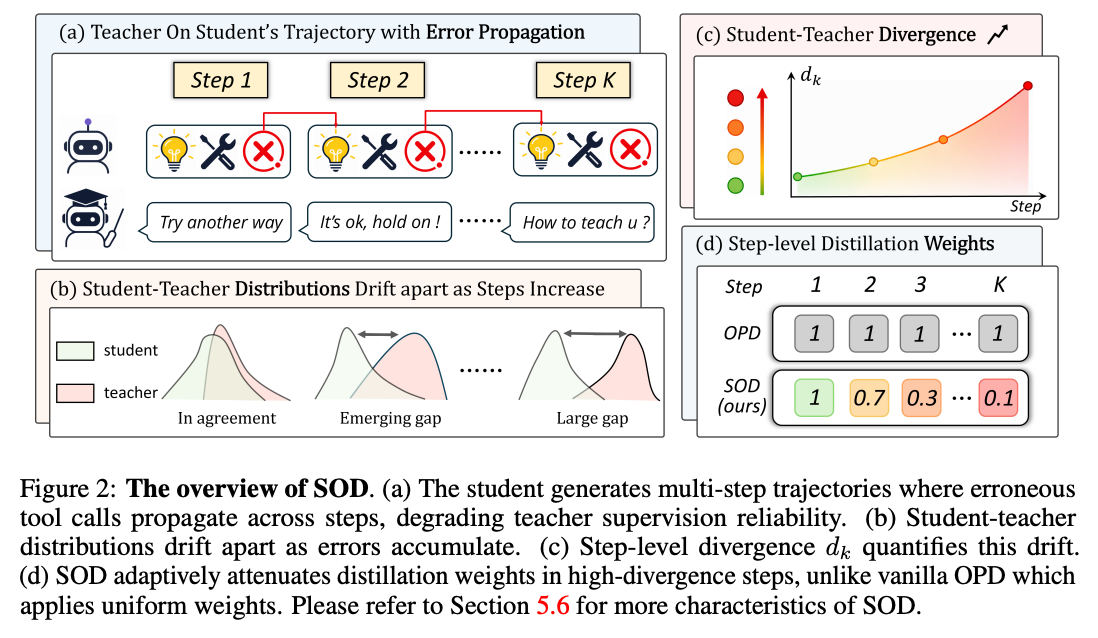
Hy 这篇 SOD 关心一个非常具体的失效模式——tool-call 场景下,一个 hallucinated tool 调用会让后续轨迹彻底污染,teacher在被污染的状态上给的 supervision全是噪声,vanilla OPD 因为是 token-level uniform 影响会很大。
它的解法是把轨迹按 tool observation 切成 K+1 个 step,每个 step 算一个散度分数d_k =\frac{1}{|I_k|}\sum |\log\pi_\theta-\log\pi_T|,然后用比值d_k/d_{k+1}做自适应权重w_k:student越走越偏(divergence 上升)时把teacher信号衰减,重新对齐时再恢复。
本质上是给teacher supervision加了一个"信任度门"。
效果上,0.6B 学生在 AIME2025 拿 26%,是首个 sub-1B 做到这个水平的模型,相对 OPD +20.86%。
ROPD:质疑"OPD 必须是 logit 匹配"
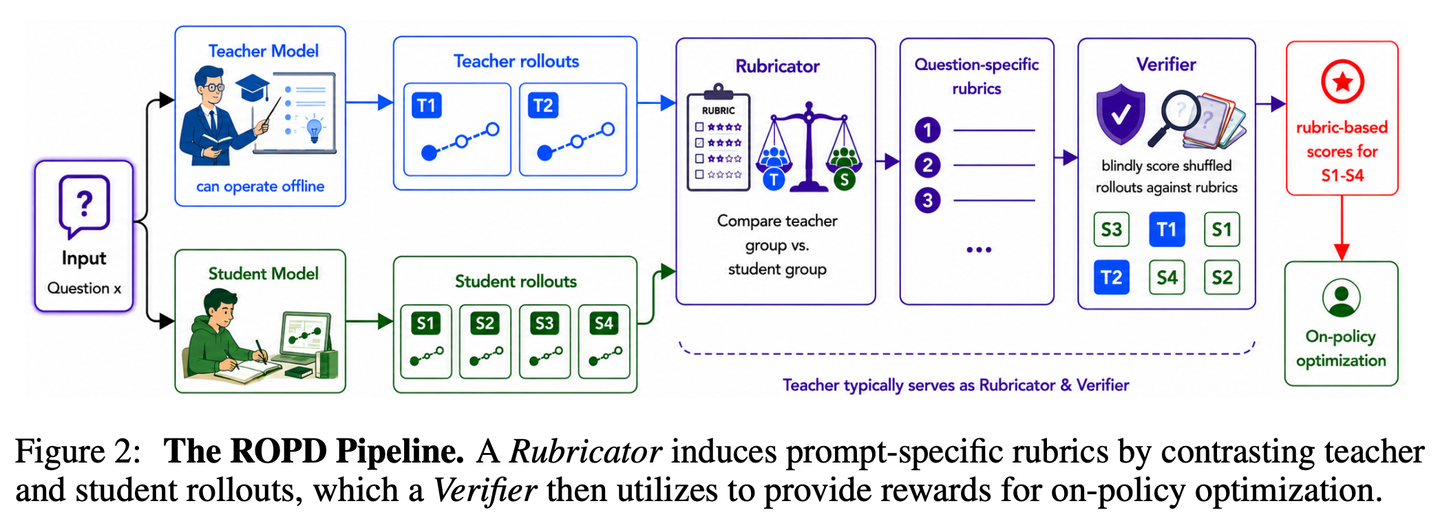
NUS + 腾讯的 ROPD 在打破 OPD 的一个隐含假设——teacher 信号必须是 logits。
它的做法分两步。对每个 prompt,对比 4 条 teacher 回答和 8 条 student 回答,用 LLM 生成 4-12 条带权重的评分项;然后让 LLM 在每条 student rollout 上按这些 rubric 打 0/1,加权得分直接喂 GRPO 当 reward。
整个流程不需要 teacher logits,所以 GPT-5.2 这类纯黑盒 teacher 也能蒸馏。
关键的数字是 AUC——rubric reward 在预测最终 correctness 上 AUC 0.90,teacher logits AUC 只有 0.35(基本随机)。换句话说,当 teacher 给的 logit 信号 AUC 接近随机时,再去优化 reverse KL 是缘木求鱼。
10× 样本效率、6.3× wall-clock 加速。它把 OPD 名字里的 "distillation" 必须是 logit 匹配这件事质疑了。
Apple Unmasking OPD:揭示很多 token 的梯度本就是噪声
Apple 这篇 unmasking 工作 回答"OPD 到底什么时候 work、什么时候不 work"。
- 在 student 失败的轨迹上,teacher 信号cosine alignment~0.05,显著正向
- 在student已经成功的轨迹上,alignment ≈ 0.001,几乎正交——白白浪费梯度预算
- token级方差极大(std~0.83),同一条路径里 alignment 在正负之间反复横跳
- 只保留 positive alignment 的 token,能用 52% 的 token 拿到 10-15× 的有效信号
它提出了一个"comprehensibility 假设"——梯度信号只有在 student 能 parse 时才有用。0.6B 小模型用 self-distillation 比用 32B 外部 teacher 好 2-3×;1.7B 用同家族 8B teacher 又能反超;复杂数学题上 summarized teacher trace 反而坏事,因为小模型读不懂压缩后的论证。
Uni-OPD:把 token-level 和 trajectory-level 拧到一起
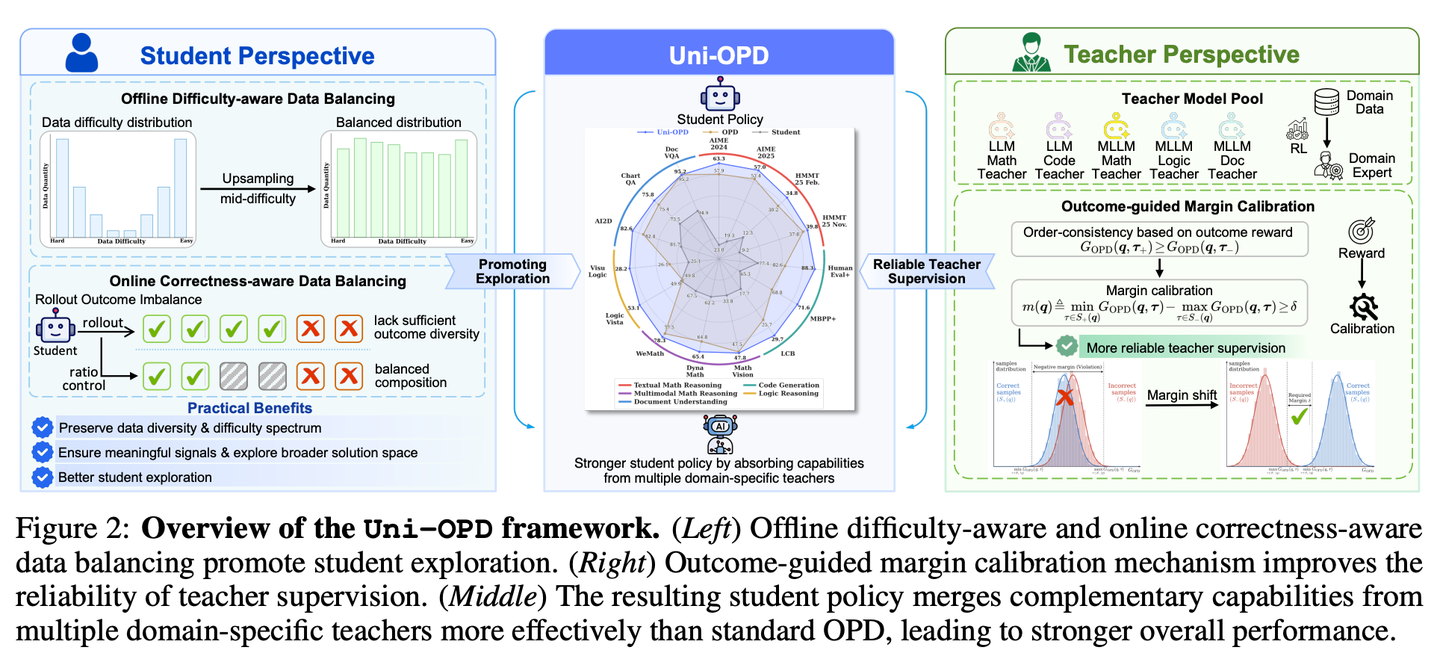
Hy的Uni-OPD 指出 vanilla OPD 的一个隐藏 bug——token 级 reverse KL 加起来未必跟最终outcome一致。比如 student 写了一条错答案但 token 模式很像 teacher 高频区,trajectory-level 的 distillation return 反而比对的那条还高。
它的修复是 outcome-guided margin calibration:定义轨迹级回报G_{\text{OPD}}(q,\tau)=\frac{1}{|\tau|}\sum_t\log\frac{\pi_T}{\pi_\theta},要求它跟 outcome reward 序保持一致——m(q)=\min_{\tau_+} G-\max_{\tau_-} G\geq\delta。
如果不满足,对正确轨迹的 G 加 \lambda(q)=\delta - m(q) 直到 margin 修复。
外加从student/teacher双视角的数据均衡(offline difficulty+online correctness balancing)。multi-teacher 也支持,30B → 4B/30B → 1.7B 都有 +1.5~+3 pt 增益。
本质上是把 OPD 跟 RLVR 桥接起来,让 token 级 KL 不再"自说自话",而是接受 trajectory 级 outcome 的监督。
Lightning OPD:把 on-policy 换成 on-distribution
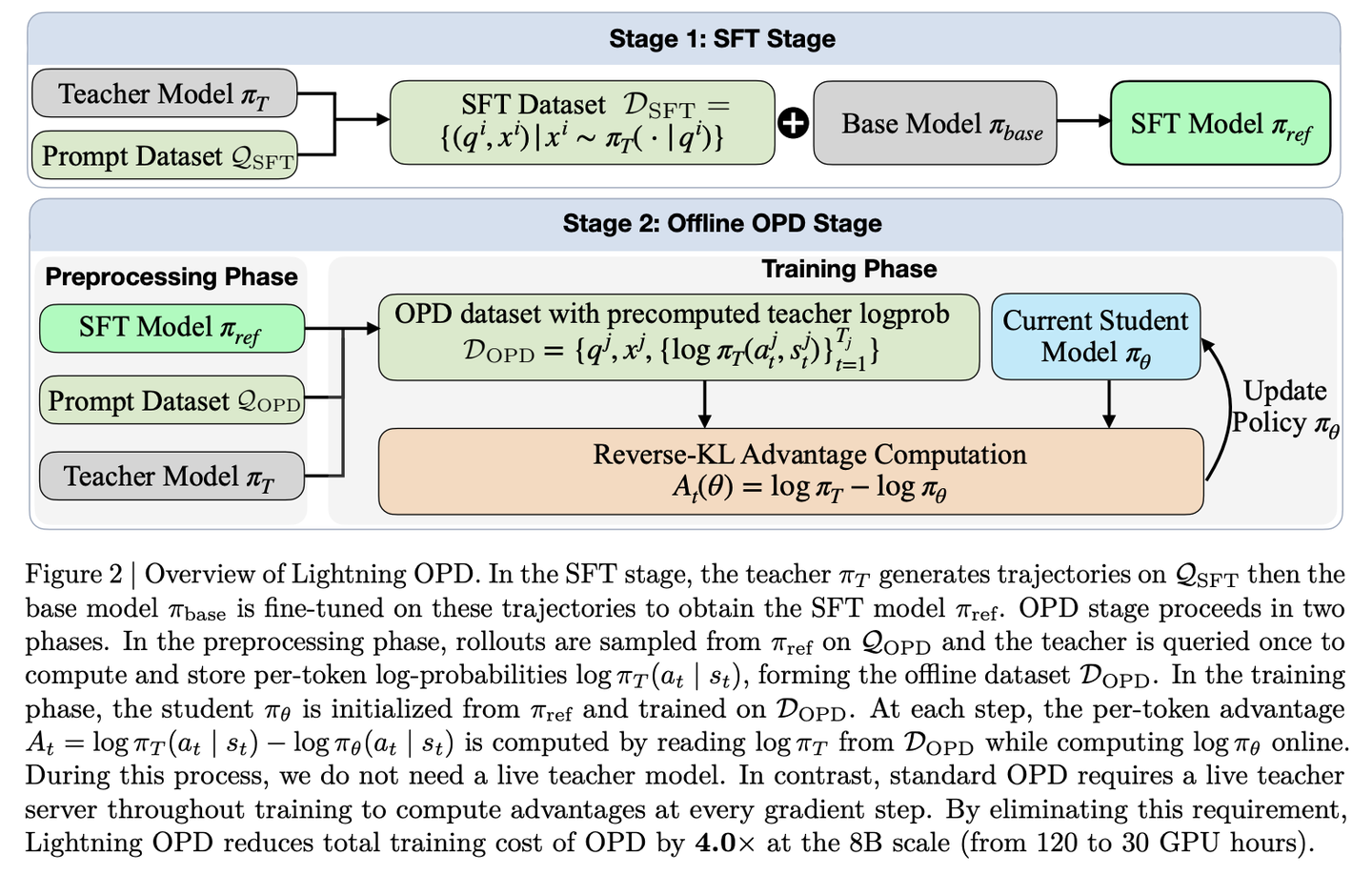
Lightning OPD 的洞察——OPD 真正贵的不是 KL 计算,是 teacher inference。所以他们证明了一个定理:只要 SFT 阶段和 OPD 阶段用同一个 teacher,那么把 teacher 在 SFT rollout 上的 logits 预先算一次缓存下来,跟在线 OPD 共享同一个最优解(gradient bias 可控)。
收益是 4× 算力节省,Qwen3-8B 30 GPU·hr 拿 AIME24 69.9%。
严格意义上这就不再是 "on-policy",而是 "on-distribution that the teacher saw"——但工程上极有价值。这个 trick 几乎跟其他所有 xOPD 正交,可以直接叠加到任何方法上。
OPSDL:长上下文场景下让模型"短的自己"教"长的自己"
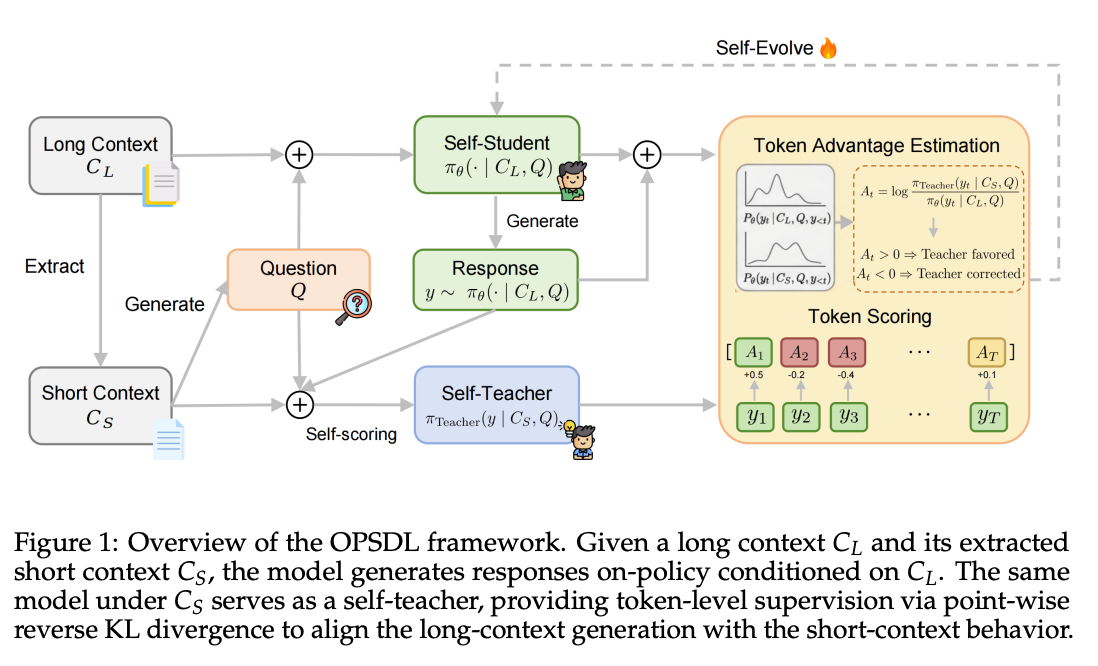
百度的 OPSDL 解决的是一个特定场景的问题——模型在长上下文里 rollout 时容易被无关信息干扰,但同一个模型在短上下文里其实是可靠的。所以与其找一个外部长上下文 teacher(贵且未必更好),不如让模型自己来当老师:student 在完整长上下文里 rollout,但抽出真正相关的短上下文片段,让模型在那个短上下文里给自己 supervision。
它本质上是 self-distillation 加上一层 privileged information——privileged 的不是答案、不是更多 context,而是"被精简过的、模型能更好处理"的 context。机制上和 Apple 那篇 comprehensibility 假设互相印证:teacher 信号好不好用,关键看 student 能不能 parse;模型自己的短上下文版本是它最能 parse 的 teacher。
Self-Distilled Reasoner:把 self-distillation 作为 RLVR 替代品
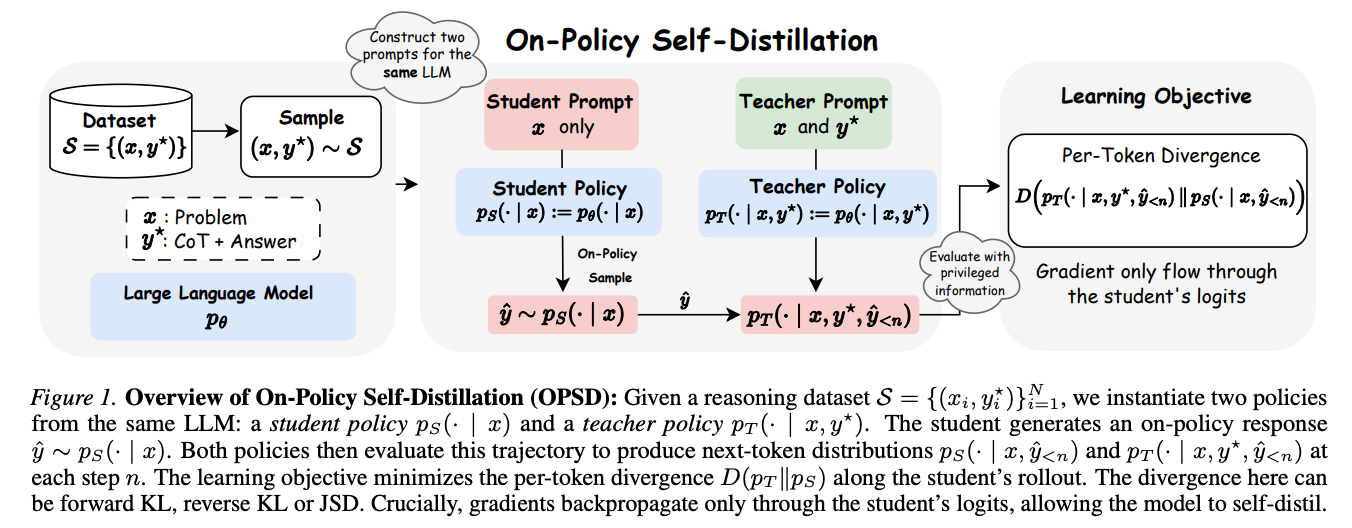
Self-Distilled Reasoner(UCLA+Meta)是把 OPSD(On-Policy Self-Distillation)这个名字正式立起来的工作。它的设定很干净——同一个模型实例化两份策略:teacher 看到 questionx加privileged informationy^star(已验证的推理轨迹或 ground truth),student 只看到x,两份策略共享同一份权重。
student 自己 rollout,再让两份策略在 student 的轨迹上各打一次概率,最小化每个位置的散度
梯度只回传给 student 那一侧。
它有两个值得专门记下来的发现。
第一是 forward KL 在这个设定下反而胜出。 前面所有外部 teacher 的 OPD 都用 reverse KL,理由是 mode-seeking——避免小 student 被强迫覆盖大 teacher 那些它根本表达不出来的 mode。Self-Distilled Reasoner 的 ablation 显示在 self-distillation 设定下 forward KL 在 per-token 监督上更稳。
原因也不绕:teacher 和 student 共享同一份权重,capacity gap 这件事根本不存在;teacher conditional 不过是 student conditional 在 PI 加持下被 sharpen 过的版本,它给 student 提起来的每一个 token 都是 student 本来就能表达、只是没注意到该提的。这种情况下你恰恰希望 student 把 mass 铺到每个被 PI 抬起来的 token 上,mode-covering 才是你想要的行为。
同一组 ablation 还顺手验证了 full-vocab logit distillation 比 sampled-token policy gradient 更稳——这跟 DeepSeek V4 选 full-vocab 的工程结论是一致的。
第二是 per-token KL clipping 的必要性。 文章发现 stylistic token(标点、连接词这种)的 per-token divergence 显著高于真正承载推理的 token,不做clipping就会被这些噪声主导。简单\min(\ell_{n,v},\tau)的逐token截断让训练稳定、且能在百步内快速收敛。
效果上,OPSD 在多个数学推理 benchmark 上比 GRPO 拿到 4-8× 的 token 效率,且超过 off-policy distillation。把它跟SDPO/RLSD 一起看,能看出 self-distillation 这一支跟外部 teacher 那一支其实从一开始就走的是不一样的路——它根本不是"教师角色解构"的一种替代实现,而是另一根树枝:让同一个模型在不同信息条件下相互校准。
SDPO:第一篇把自蒸馏接到 RLVR 上
RLVR(Reinforcement Learning with Verifiable Rewards)有个老问题——奖励信号稀疏,几千 token 的轨迹最后只给 0/1,根本不知道是哪几个 token 真正起了作用。这就是经典的信用分配难题。
SDPO 提出的解法是:让同一个模型同时当 student 和 teacher。teacher 多看到一些 privileged context——具体来说,是学生自己写出来的某条正确 rollout——然后用这个 teacher 在每个 token 位置上的概率作为更可靠的信号,给 student 提供 token 级反馈。
数学上,loss是 logit 级 KL 散度 \text{KL}(P_T|P_S),加到 GRPO 的 surrogate loss 上,在所有 rollout(不管对错)上都 apply。
它的核心隐喻是"用完成态反过来教过程态"——既然这条路最终走通了,那么在已知它会走通的条件下反推每一步的概率,就比在不知道结局的情况下硬猜要靠谱。
SRPO:让教师只在学生犯错时出手
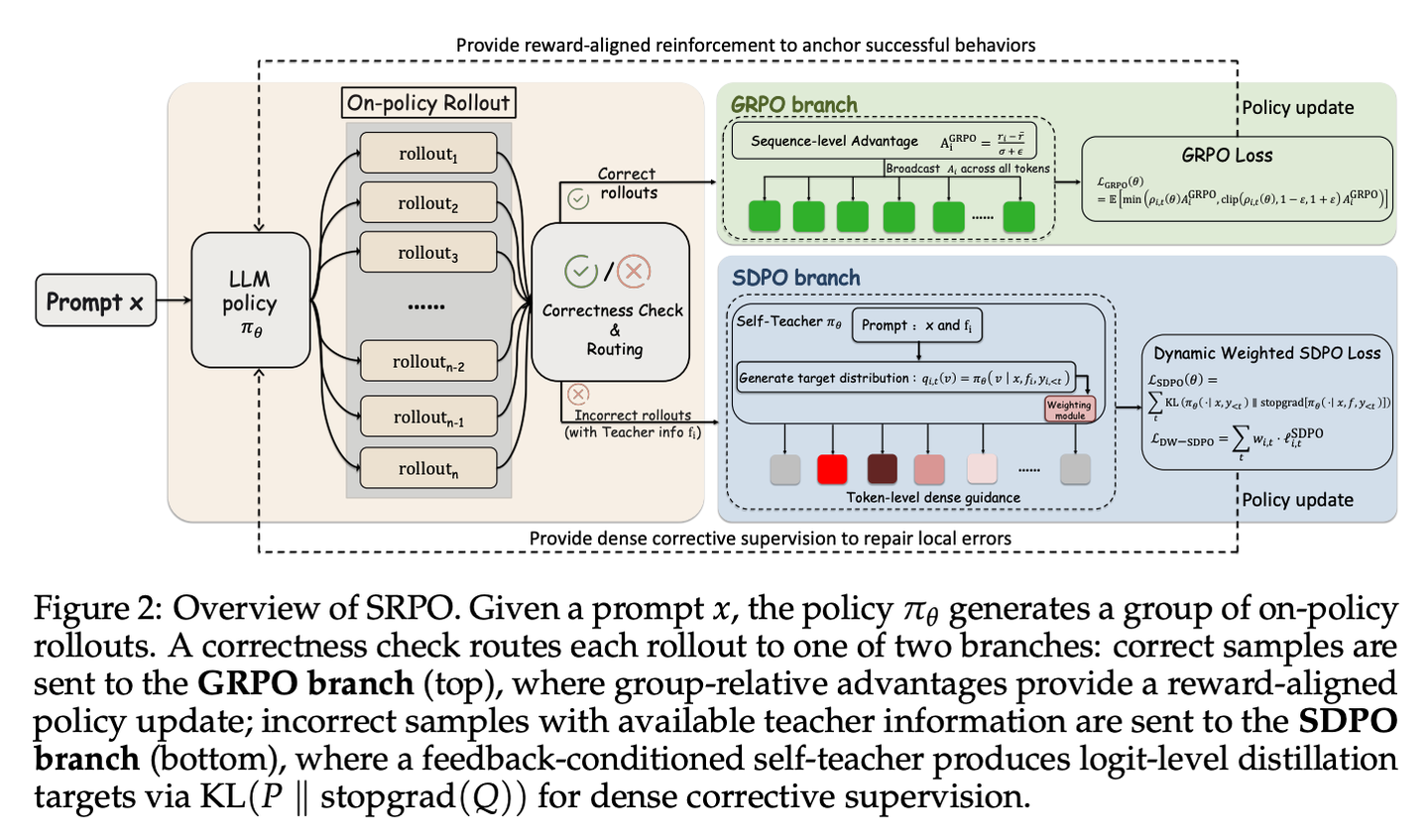
SRPO 在 SDPO 基础上加了 sample routing。teacher 看的还是正确 rollout、loss 还是 logit KL,唯一的改动是:只在错误轨迹(reward = 0)上用 SDPO loss,正确轨迹(reward = 1)退回 vanilla GRPO,再配一个 entropy-aware 的动态权重。
直觉很朴素——学生做错的时候才需要老师指,做对的时候让学生自己跑。这个设计原则朴素归朴素,但已经预示了一件事:teacher 在 RLVR 里不是越多越好,至少在成功轨迹上它的边际价值是可疑的。SRPO 自己没把这个上升到一等设计原则,但后面 RLRT 把这个直觉推到了极致。
RLSD:让教师变成更新幅度的调节器
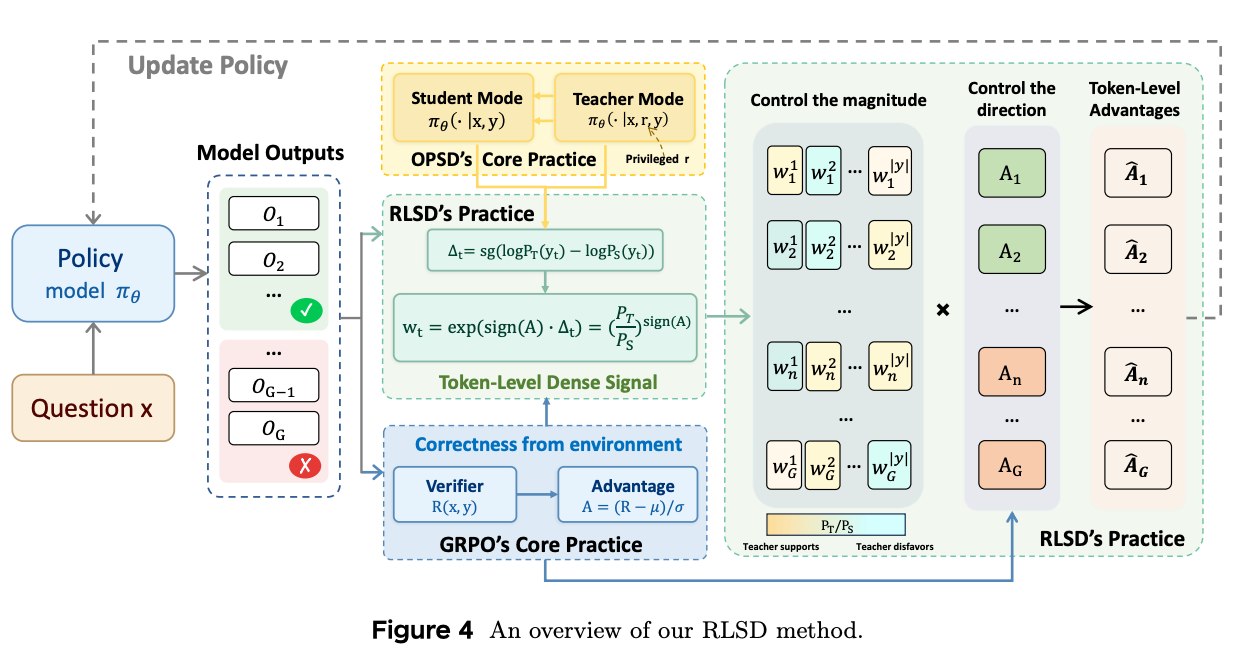
RLSD 换了一种完全不同的写法。teacher 的 privileged context 不再是某条 rollout,而是 ground-truth answer——让 teacher 在"知道标准答案"的条件下重新对每条轨迹的每个 token 打概率。
更彻底的是,loss也不用 KL了——它直接把师生token概率比 P_T/P_S 当作 advantage 上的 per-token weight。
具体形式是A_t\cdot\text{sign}(A)\cdot (P_T/P_S),verifiable reward 决定 update 方向,teacher 只决定 magnitude——每个 token 该被加权多少。
RLRT:第一次把 update direction 反过来
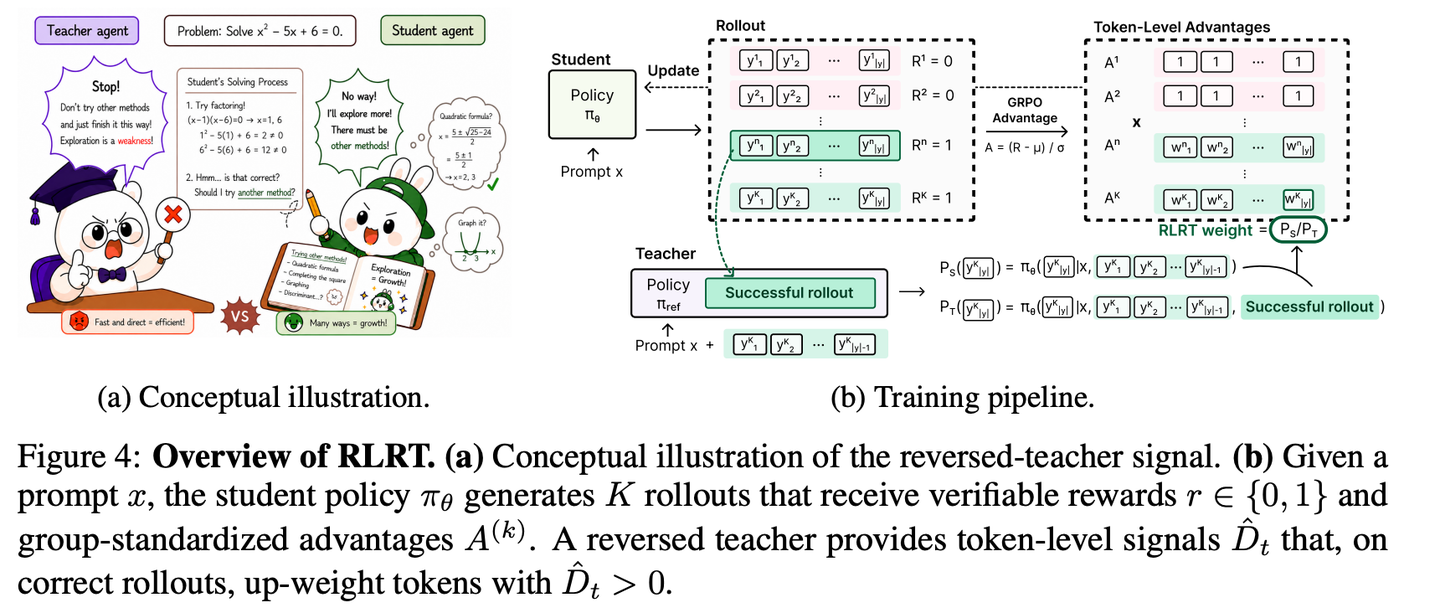
RLRT 的反转特别值得品。它把 RLSD 的 token 权重分子分母对调(变成 P_S / P_T),并且只在正确轨迹上 apply,错误轨迹完全退回 vanilla GRPO。
从「在所有轨迹上奖励教师偏好的 token」变成「在成功轨迹上奖励学生偏离教师选的 token」。仅仅这么一个翻转,Qwen3-4B-Base 在6个数学 benchmark 上比 GRPO +18%。
它的论据是 information asymmetry。teacher 多看了ground truth,会偏向标准解法;如果student在某个关键位置选了一个反常识但走通了的token(比如先试一个看似不优雅的路径,最后绕回正确答案),teacher 因为多看到了标准解法,根本不会选这个token——它会选课本里的标准做法。
RLSD会把"教师偏好的标准token"加权、把"学生自己摸出来的反常识 token"压低,每次成功后都磨掉一点学生独有的多样性。RLRT 反过来——这些位置上的 self-driven 选择是金矿,必须重点强化。
它还把"信息不对称"这个概念做了一个精细的拆解。位置级不对称\bar{D}_t =\text{KL}(P_S|P_T)用来识别 critical positions——哪些 token 位置上师生分歧最大;token级不对称 \hat{D}_t=\log(P_S/P_T) 用来识别在被采样的 token 上差异指向哪边——正数代表学生选了教师没选的(self-driven),负数代表教师选了学生没选的。
RLRT 重点强化的就是"高\bar{D}_t位置上\hat{D}_t为正"的那些 token——critical position 上的 self-driven exploration。
附带一笔,nrehiew 那篇 blog 还做了个对照实验:用 SFT teacher 和RL teacher分别去做 OPD,两个student表现几乎一样、都略超自己的teacher。on-policy 采样的价值>teacher 本身的能力——这件事跟 RLRT 的方向是一致的:教师的绝对水平没那么重要,重要的是教师起到的"信号"作用。
RLCSD:用对错对比抵消蒸馏信号里的风格漂移
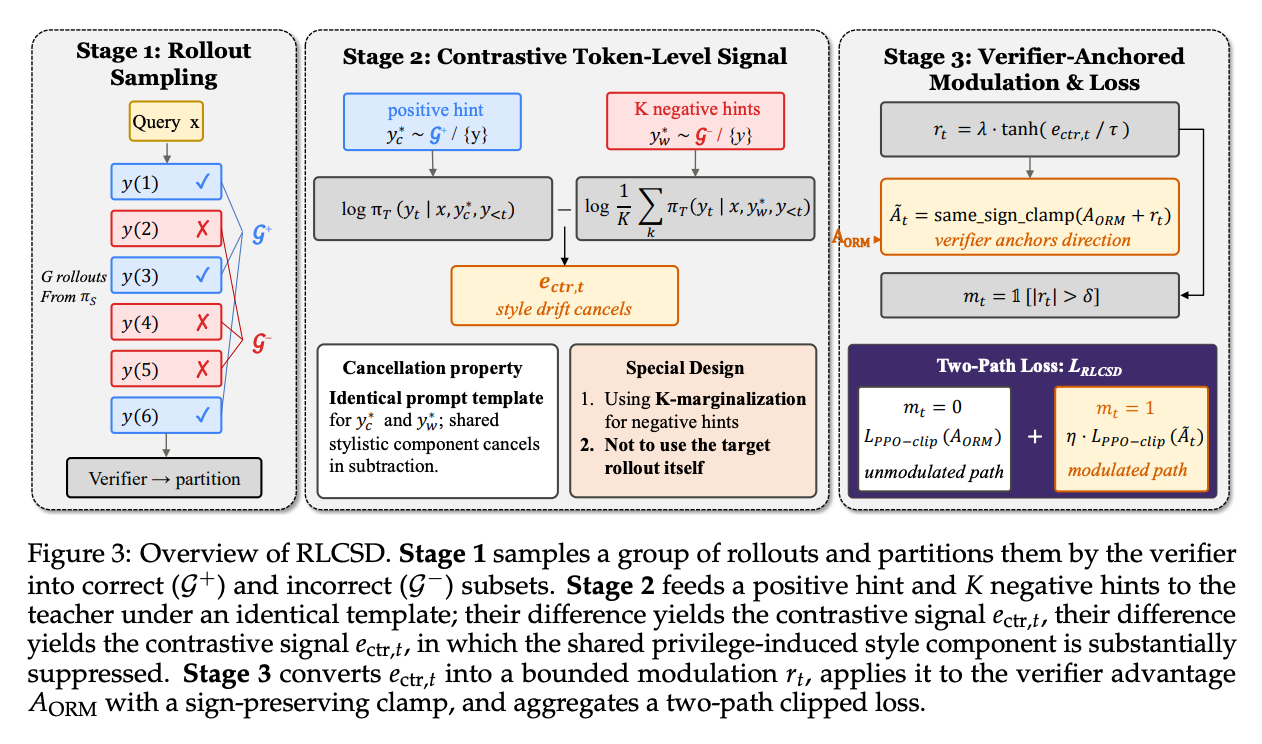
RLCSD(清华,2026.06)跟 RLSD/RLRT 是同一支——都让模型拿自己 group 里的 sibling rollout 当 privileged context,再用师生信号去调 GRPO 的 advantage。但它先抓出了这条线一个一直没被正面命名的病。
它管这个病叫 privilege-induced style drift。OPSD 让teacher看一条正确解再回头给student打分,问题是 teacher 看了答案之后倾向于写得更直接、更短,于是师生那个gap信号的大头压在style token上——"Wait"、"Therefore"、格式符号这类,而不是真正承载推理的数字和算符。
论文给的数字很直观:style token 上的信号均值 0.263,task token只有 0.083,差了3倍。后果就是前面几篇各自踩过的坑——OPSD/SDPO/SRPO会entropy 爆炸然后collapse,RLSD会过早把 response缩短。
Many Faces那篇说的"student 推理时幻觉性地引用参考答案",跟这里其实是同一个privilege leakage的两个侧面:一个表现成幻觉,一个表现成风格污染。
它的解法很巧——既然"看了提示就会发生的风格偏移"跟提示对不对无关,那就拿一条错的提示来做对照。把一条incorrect rollout也包成一模一样的"参考解"模板喂给teacher(连"正确答案"的标注都照写),算一遍gap;再用正确提示算一遍 gap;两者相减。
模板逐字节相同,所以两边共享的那部分风格漂移在相减里直接抵消,剩下的才是真正跟"这条提示对不对"有关、也就是跟任务有关的信号:
(student 那一项在相减中被消掉了。)两个细节也值得记:负样本取 K=4 条求平均,免得单一错误类型把信号带偏;正负提示都从 sibling 里取、但绝不用 target rollout 自己当提示,否则会自指地过度自信。
拿到这个干净信号之后,它接 GRPO 的方式跟RLSD/RLRT一脉相承——信号只调 magnitude 不决定方向:先 tanh 压到有界区间,再mask出信号强的那20-30% token,再做一个sign-preserving 的 clamp 保证调制不会把 verifier 定下来的方向翻过去(跟RLSD的sign isolation是同一个原则),最后正常 token 和被调制token分两路各自归一化(不然那20-30% 会被稀释回 vanilla GRPO)。
teacher就是student每10 步刷新一次的快照,不需要外部模型、不需要 logits 白盒、也不需要对齐词表。
效果上,Qwen3的1.7B/4B/8B加Olmo-3-7B,在AMC23/AIME24/AIME25和 Knights-and-Knaves 上一致超过GRPO和 OPSD/SDPO/SRPO/RLSD,逻辑推理的 OOD 设定(训练没见过的角色数)提升尤其大;更关键的是训练曲线稳得跟GRPO 一样,不再 collapse、也不缩长度。作者还顺手验证了"对比"是个通用插件——把它接到 OPSD、RLSD 上都能再涨一截。
最后那个 cross-model 的延伸值得记一笔。同样的 task/style 分解在跨模型蒸馏上也成立:用per-token KL ranking一看,风格离得远的 Qwen3-4B-Instruct teacher把KL质量压在了行文和LaTeX上,风格更近的 GRPO teacher 才压在数字和算符上。于是出现一个反直觉的结果——单独看更强的Instruct teacher,蒸出来的student反而比用那个稍弱、但风格更近的teacher差。
这跟Apple的comprehensibility假设、nrehiew那个"on-policy采样 > teacher能力"、Many Faces 的"RLVR-adapted teacher不用更强只要更近"是同一个方向的又一个佐证:决定蒸馏好坏的常常不是 teacher 绝对强不强,而是它跟 student 贴不贴。
SDAR:多轮 agent 场景下,把 OPSD 从主目标降级为门控辅助项
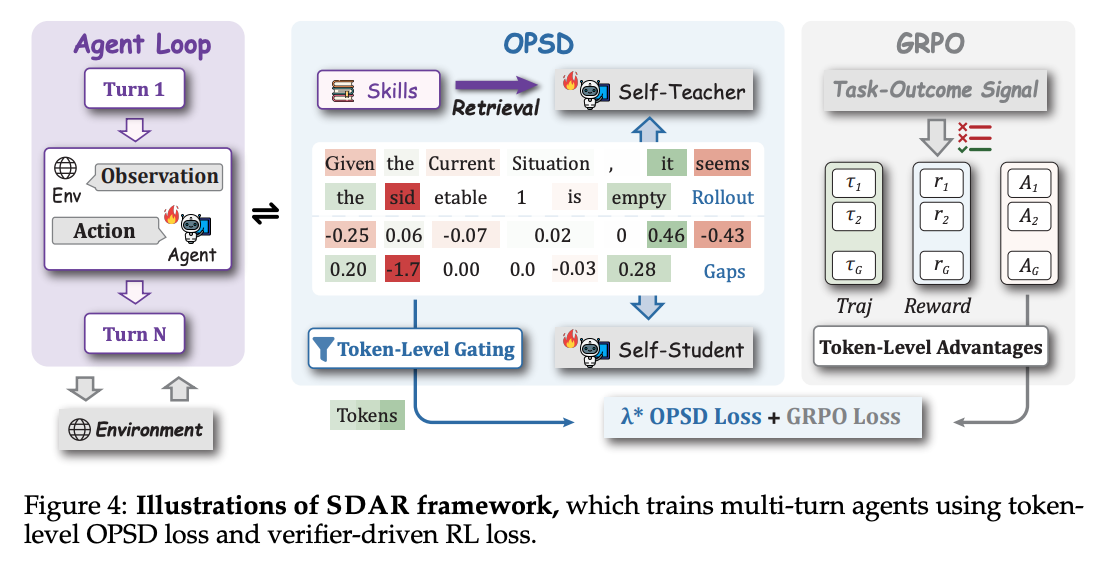
SDAR(浙大+美团+清华,2026.05)切的是又一个具体场景——多轮 agent。它先指出一个观察:把 OPSD 直接套到多轮 agent 训练上会塌,原因有两层。
一是 multi-turn instability——每一轮的输出会变成下一轮的 context,错误会跨轮复利,导致 teacher 在污染上下文上的 supervision 不稳定;这其实跟 SOD 在 tool-use 场景下看到的"轨迹被污染"是同一类问题,只是从单轮工具调用扩到了多轮交互。
二是asymmetric trust in privileged guidance——teacher 用的 privileged context 经常是 skill-conditioned(比如检索回来的相关技能片段),如果检索本身就不完美,teacher 给出的"否定信号"(拒绝某个 token)就未必可信,可能只是检索没召回到、不是真的错。
它的解法是把 OPSD 从主目标降级为门控辅助项,RL 仍然是主优化目标。具体做法是把 detach 之后的 token 级师生差距过一个 sigmoid 门——
- teacher endorse(正向 gap)的 token,门打开,蒸馏信号被加强
- teacher reject(负向 gap)的 token,门关小,软性衰减——而不是按 vanilla OPSD 一刀切对称地处理
这个对称性的破坏挺关键。前面 RLSD/RLRT 那条线的"对称性破坏"发生在 reward 维度(按 r=0/r=1 路由),SDAR 的破坏发生在 teacher 信号本身的极性维度(按 endorse/reject 路由)。
在 ALFWorld、WebShop、Search-QA 三个 agent benchmark 上比 GRPO +7~+10pt,且明显比 naive GRPO+OPSD 更稳。
多轮场景下教师信号的可靠性比单轮更脆弱,所以"对教师该听多少"这件事必须做得更细。
Many Faces of OPD:把"OPSD 何时 work、何时塌"问到底
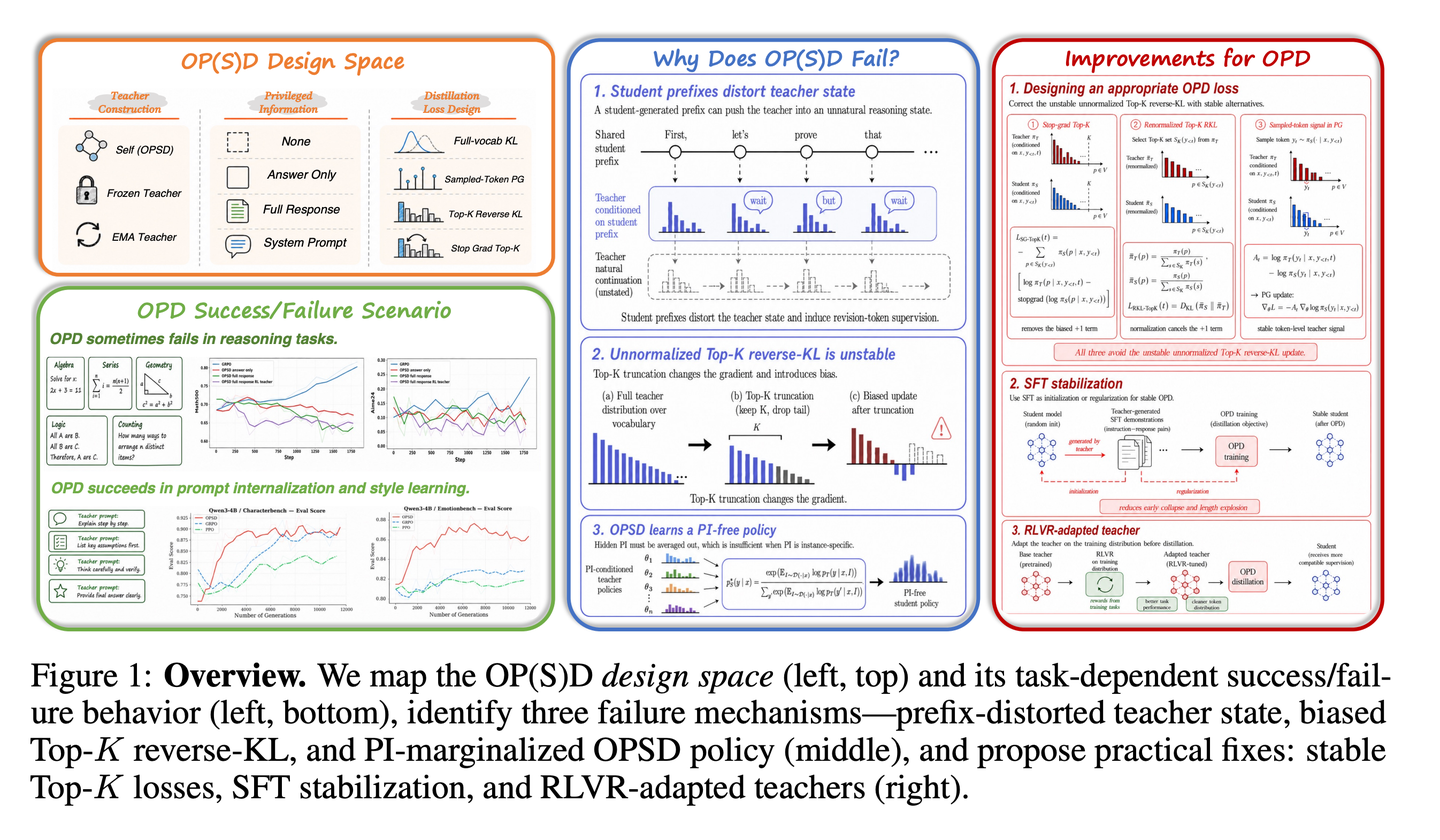
UIUC+人大+北大这篇 Many Faces of On-Policy Distillation(2026.05)做的是一件 self-distillation 这条线长期缺的事——把"OPSD 什么时候 work、什么时候不 work"系统地拆开来回答。
它的核心论断是 OPSD 的 student 在数学上学到的不是任何一个具体的 PI-conditioned teacher,而是所有 PI 上的边际聚合策略
这个聚合策略在不同 PI 结构下命运截然不同。
当 PI 是 shared-rule(系统提示词、风格指令、对齐偏好这种"对一类问题都成立的潜在规则"),聚合恰好就是你想让 student 内化的那条规则。OPSD 在 CharacterBench、EmotionBench、system prompt 内化这类任务上显著超过 GRPO 和 PPO,sample efficiency 也更高——这跟 Self-Distilled Reasoner 在数学推理上跑赢 GRPO 4-8× 是同一条逻辑链,PI 提起来的是一个跨样本共享的潜在规律。
当 PI 是 instance-specific(具体某道题的 ground truth、某份特定文档),聚合等于把各题各异的解题路径硬拍成一个糊。OPSD 在 Math500/AIME24 / AIME25 上全线失败——无论用 answer-only 还是 full-response 当 PI 都不涨。
最有意思的失败模式是:student 在 inference 时会幻觉性地说出"如参考答案上所言"——它学到的不是解题能力,而是"有 GT 在条件里"这件事的统计痕迹。
这一点其实是 self-distillation 这条线一直存在但没被正面命名的隐患——直接把 ground truth 当 PI 去做 OPSD,几乎一定引入幻觉,因为 student 部署时根本到不了那个"有 GT"的条件分布。
RLSD 后来"用 sign(A) 决定方向、PI 概率比只决定 magnitude"是在缓解这个问题,RLRT 把方向反过来则是更彻底的解决——既然 GT 让教师偏标准解法,那 student 在那些位置该学的不是 imitate 而是 explore。
文章还顺手给了三个工程 fix:stop-gradient TopK reverse KL 修 OPSD 优化梯度的 bias,RLVR-adapted teacher 用 student 的分布做 RL 把 teacher 拽近(而不是去拽更强的外部 teacher),以及 SFT-stabilized student 防止 collapse。
其中 RLVR-adapted teacher 那一条特别值得记下来——teacher 的 benchmark 分数甚至不需要更高,只要分布跟 student 更贴,蒸馏效果就更好。
这跟 nrehiew blog 那个"on-policy 采样的价值>teacher 能力"的对照实验在精神上是同一件事,只不过这里是从 teacher 端做适配,那里是从 student 端的 sampling 做适配,两端都在朝"分布对齐>绝对能力"那个共同方向收敛。
TrOPD:给 reverse-KL 估计量画一个信任区域
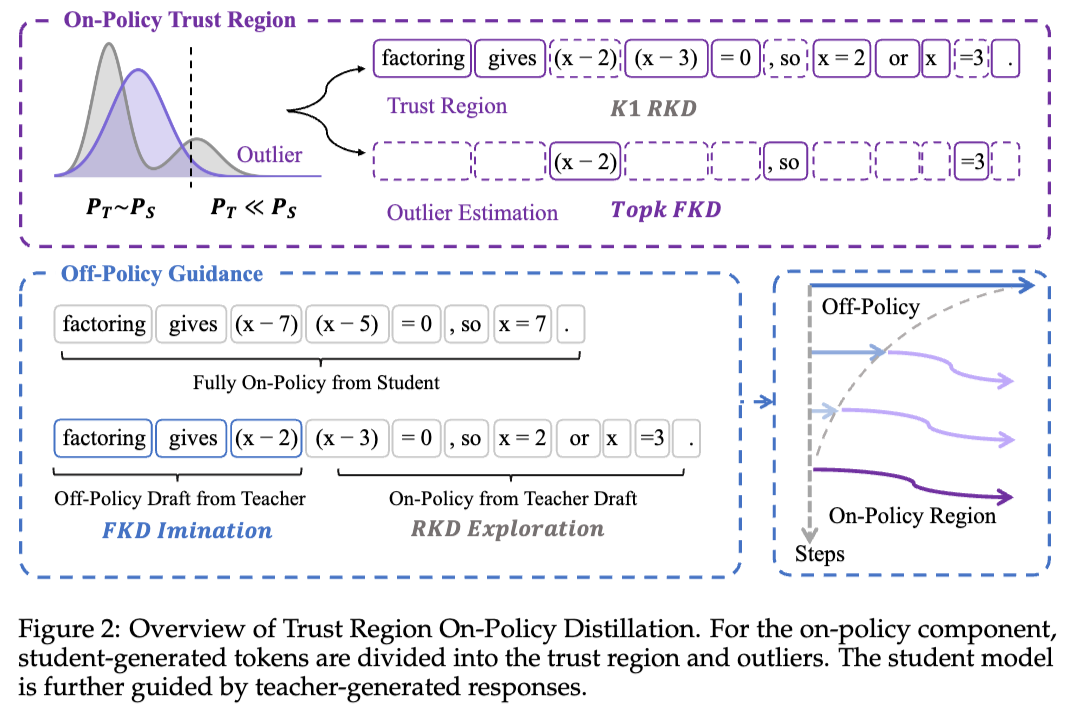
TrOPD 针对的是 vanilla OPD 一个很底层的工程兼数值问题。为了省显存,长推理任务上的 reverse KL 一般不算全词表,而是用 K1 这个无偏估计量-\mathbb{E}_{x\sim\pi_S}[\log(\pi_S/\pi_T)],把显存从 O(n\cdot k) 压到 O(n)。
但当师生分布差很远时,student 采出来的 token 在 teacher 那里概率极低,policy gradient\frac{1}{\pi_S(x)}\log\frac{\pi_T(x)}{\pi_S(x)}会冲向-\infty——巨大的梯度 outlier 直接把训练搞崩。
它的解法是借了 speculative decoding 的思路定义一个信任区域P_{\text{trust}}(x) = \min(\pi_T(x)/\pi_S(x),\, 1)。teacher 认可(\pi_T \geq \pi_S)的 token 完全信任、照常走 reverse KL;teacher 不认可的 token 落到 outlier 区,按概率被划出去。
对 outlier 区它没有简单丢弃,而是换成 forward KL——从teacher的 top-k 视角反过来给监督-\sum_{v\in V_k^T}\pi_T(v)\log\frac{\pi_T(v)}{\pi_S(v)}。
这一步是 ablation 里收益最大的(比单纯 masking 好~2 个点),原因也直观:outlier区恰恰是师生分歧最大的地方,直接mask掉等于把最有信息量的监督也一起扔了,而forward KL能在那里安全地做 imitation。
另外它还叠了一个off-policy头——轨迹前缀由 teacher 生成、student 接着续写,前缀部分用 forward KL 模仿,再用cosine schedule 把off-policy 长度退火到零,训练末期回归纯on-policy。
这跟Lightning的"用 teacher 见过的分布"、TRB 那类 warmup 思路是同一个母题——早期student太弱、自采样质量差,先借 teacher 的手扶一把。
数学/代码/通用域上比OPD、EOPD、REOPOLD都强,单域 +3 个点左右。作者也顺手验证了它跟 AOPD 正交,叠起来还能再涨。
异同:差异点其实就几条
把上面这些工作横向铺开看,差异点可以提炼成几个问题——每篇论文的设计都是在回答这几个问题里的某几个。
关于 loss 怎么写——是 reverse KL(vanilla/SDPO/SRPO),是token概率比当 advantage weight(RLSD/RLRT),是按 advantage 符号切两段 RL/KL(AOPD),是按信任区域在 reverse-KL 和forward-KL之间切换(TrOPD),是rubric reward喂GRPO(ROPD),是把outcome reward拿来约束 trajectory-level KL 序(Uni-OPD),还是把 OPSD 整体降级成 sigmoid 门控辅助项(SDAR)。
关于教师信号怎么来——是 white-box logits(vanilla 大多数),是black-box rubric/verbal(ROPD),是 self-distill privileged context(SDPO/RLSD/RLRT/SDAR),是同一条query下正确与错误sibling rollout 的对比(RLCSD),还是模型自己的不同 mode(OPSDL)。
关于哪些 token 或 sample 该被加权——是均匀(vanilla),是按 advantage 符号(AOPD),是按step divergence(SOD),是按师生概率比划信任区域、把 outlier单独处理(TrOPD),是按 teacher endorse/reject 极性(SDAR),是用对错对比抵消风格漂移、把信号集中到 task token(RLCSD),是只在 r=0(SRPO),是只在 r=1(RLRT),还是按 teacher-student alignment 的 cosine 过滤(Apple )。
关于教师拉学生的方向——绝大多数工作都是把 student 往 teacher 拉,RLRT 第一个反过来;Apple 用诊断告诉我们其实有些token上根本不该拉,因为信号本身是负价值的;TrOPD则提醒了第三种情况——有些 token 不是不该拉,而是 reverse-KL 这个估计量在那里数值上就会爆,得换个方向(forward KL)去拉。
关于算力/数据效率——是在线 sampling(默认),是 offline cache(Lightning),还是 self-distill 不需要外部 teacher(OPSDL/RLVR 自蒸馏整条线)。
关于 PI 的结构——self-distillation 这一支还多一根隐藏轴:你喂给 teacher 的 privileged information 是 shared-rule(系统提示词、风格指令、对齐偏好这种跨样本共享的潜在规律),还是 instance-specific(具体某道题的 GT、某份特定文档)。
Many Faces of OPD给出的实验结论是这两种PI 在 OPSD下命运截然不同——前者 student 学到的是聚合后的规律本身、是好东西;后者聚合等于把不同解题路径硬拍成糊,反而引入幻觉。
这也解释了为什么RLSD/RLRT/RLCSD 要在喂GT(或正确 rollout)当PI这件事上反复想办法:RLSD动magnitude、RLRT 动方向、RLCSD干脆拿错误提示做对照把 PI 带来的风格污染减掉——三种都是在跟 instance-specific PI 的副作用搏斗,只是下手的位置不同。
这些维度不正交,但绝大多数论文每篇只动一两根——所以读 OPD paper 时一个简单的 sanity check 是:这篇真正动的是哪个模块?
一些思考
从这一波工作中能看出一条隐藏的演化主线。
vanilla OPD 默认教师全程上手把手——你写一个 token,我给你打一次分;Apple 的诊断说很多时候它在帮倒忙,因为成功轨迹上 alignment 几乎是噪声;SOD 说它该有信任度门,越走越偏的时候要减少话语权;TrOPD 说它的话甚至有时在数值上根本没法听,得换个方向才接得住;ROPD 说它的 logit 信号 AUC 还不到 0.5,干脆别用,换个rubric.
Lightning 说它根本不用全程在场,离线缓存一份就够;SRPO 说它在学生做对的时候该闭嘴;RLCSD 说它给的信号里混了一层跟对错无关的风格腔调,得拿"它在错误提示下会怎么说"做对照减掉;SDAR 说它的拒绝信号本身就未必可信,得软性衰减;RLRT 说成功时它该退场到只剩"标记哪些 token 是学生自己做的"这一鉴别功能,更新方向甚至要跟它的偏好相反。
到 RLRT 这里,"教师"这个词已经几乎是反讽了——它只负责告诉学生"什么不是你的",而 reward 负责告诉学生"什么是对的",两个信号一拼,学生独有的探索能力被精准放大。这一波 xOPD 表面上是各种 loss 变种竞赛,底下那条主线其实是——我们正在学习"教师"这个概念在 student 学习过程里到底该出现在哪些位置、以什么强度、起什么作用。
把 self-distillation 这一支也接进这条主线会发现一个更深的东西。Self-Distilled Reasoner 把"教师"和"学生"压成同一份权重的两份条件分布——所谓"教师"不过是"学生在 PI 加持下被 sharpen 过的自己"。Many Faces of OPD 进一步证明,OPSD 的 student 在数学上学到的甚至不是任何一个具体的 PI-conditioned teacher,而是所有 PI 上的边际聚合。
所以"教师角色解构"还能再推一步——从"教师该不该出场、什么时候出场",推到"教师本来就不是一个外部的人,而是学生在更好信息条件下的一个版本,它的价值取决于 PI 是不是一条跨样本的共同规律"。
当 PI 是 shared-rule 时,"在更好信息下的自己"就是那条规律的化身,蒸馏即内化;当 PI 是 instance-specific 时,"在更好信息下的自己"是个永远到达不了的状态,蒸馏即幻觉。
这件事如果从机器学习里跳出来看一下,其实跟人类教育学里争论了一百年的问题是同构的——教师到底该承担一个什么样的角色,学生究竟是如何学习的。
建构主义那一派会说,老师真正能做的不是把知识灌进去,而是搭一个脚手架让学生自己构建认识;激进一点的 unschooling 会说连脚手架都不该有,最好的学习是学生自己摸出来的;而传统课堂模式默认的是老师该提供标准答案、学生该精确复刻。
OPD 这一波从 vanilla 到 RLRT 的演化,几乎是把这个争论在算法层面又重新跑了一遍——从"老师即标准答案",到"老师只在学生卡住的时候出手",再到"老师只负责识别哪些是学生自己做出的选择,越是它不看好的、学生还走通了的,越要被珍视"。
Many Faces of OPD 那个 shared-rule vs instance-specific 的二分也对得上教育学里的另一对老问题——通则和具体例子哪个更值得教。
系统提示词、风格规范、价值观这种跨场景的共同规律,灌下去学生能内化成自己的;而某道题的标准解法、某份具体文档这种 instance-specific 的内容,硬蒸只会让学生学到"标准答案在我视野里"这件事的统计假象,部署时靠不上还会幻觉。
这是一个非常漂亮的呼应,而且暗示了一件事——如果教育学这一百年的争论没有给出唯一的答案,那 post-training 这个领域大概率也不会有唯一的"对的方法",更可能的格局是教师角色的多种配置在不同任务、不同学生能力、不同信号可靠度、不同 PI 结构的场景下各擅胜场。
OPD 会是终局吗?我的判断是不会,但它揭示的视角会是终局的一部分。
OPD 真正的贡献其实不在"反向 KL + 学生采样"这个特定的 loss 形式,而在它揭示了一个更底层的认识——post-training 的 teacher signal 不应该是静态的,它应该跟着 student 当前的状态、能力、置信度、对错动态调整。
类比一下,DPO 之后的所有 xPO 最后没有谁笑到最后,但它们共同推动了一个更深的认识——preference learning 不需要显式的 reward model。OPD 这一波最后大概率也是这样——"教师信号必须动态、必须自适应、必须接受 student 状态信息"这件事会成为下一代 post-training 的常识基础。
Reading List
| Paper | 链接 | 必读? |
|---|---|---|
| Thinking Machines OPD blog | thinkingmachines.ai/blog/on-policy-distillation | ⭐⭐⭐ 入门 |
| A Survey of OPD for LLMs | arXiv 2604.00626 | ⭐⭐⭐ 全景 |
| Apple Unmasking OPD | arXiv 2605.10889 | ⭐⭐⭐⭐ 诊断 |
| Many Faces of OPD | arXiv 2605.11182 | ⭐⭐⭐⭐ OPSD 何时 work 的诊断 |
| RLRT (Rebellious Student) | arXiv 2605.10781 | ⭐⭐⭐ 教师角色翻转 |
| RLCSD | arXiv 2606.11709 | ⭐⭐⭐ 对比抵消风格漂移 |
| Self-Distilled Reasoner | arXiv 2601.18734 | ⭐⭐⭐ OPSD 源头工作 |
| SDAR | arXiv 2605.15155 | ⭐⭐⭐ 多轮 agent 自蒸馏 |
| TrOPD | arXiv 2606.01249 | ⭐⭐⭐ 信任区域 + outlier 处理 |
| SOD | arXiv 2605.07725 | ⭐⭐⭐ tool-use Agent |
| ROPD | arXiv 2605.07396 | ⭐⭐⭐ 信号源解放 |
| Lightning OPD | arXiv 2604.13010 | ⭐⭐⭐ offline 缓存 |
| Uni-OPD | arXiv 2605.03677 | ⭐⭐ dual-perspective |
| AOPD | arXiv 2605.06387 | ⭐⭐ 非对称 |
| OPSDL | arXiv 2604.17535 | ⭐⭐ 长上下文自蒸馏 |
| SDPO / SRPO / RLSD | arXiv 2601.20802 / 2604.02288 / 2604.03128 | ⭐⭐ RLVR 自蒸馏支线 |
| SFT, RL, and OPD(nrehiew blog) | http://nrehiew.github.io/blog/sft_rl_opd | ⭐⭐ on-policy 采样 vs teacher 能力 |
持续更新中 ... ...