作者:虚无
原文:https://zhuanlan.zhihu.com/p/2048769202819949265
TL, DR
LLM Pretraining是模型能力的主要来源。模型的能力一般会随着pretraining loss的降低而单调提升。
那么,pretraining loss相同,模型能力就一定相同吗?
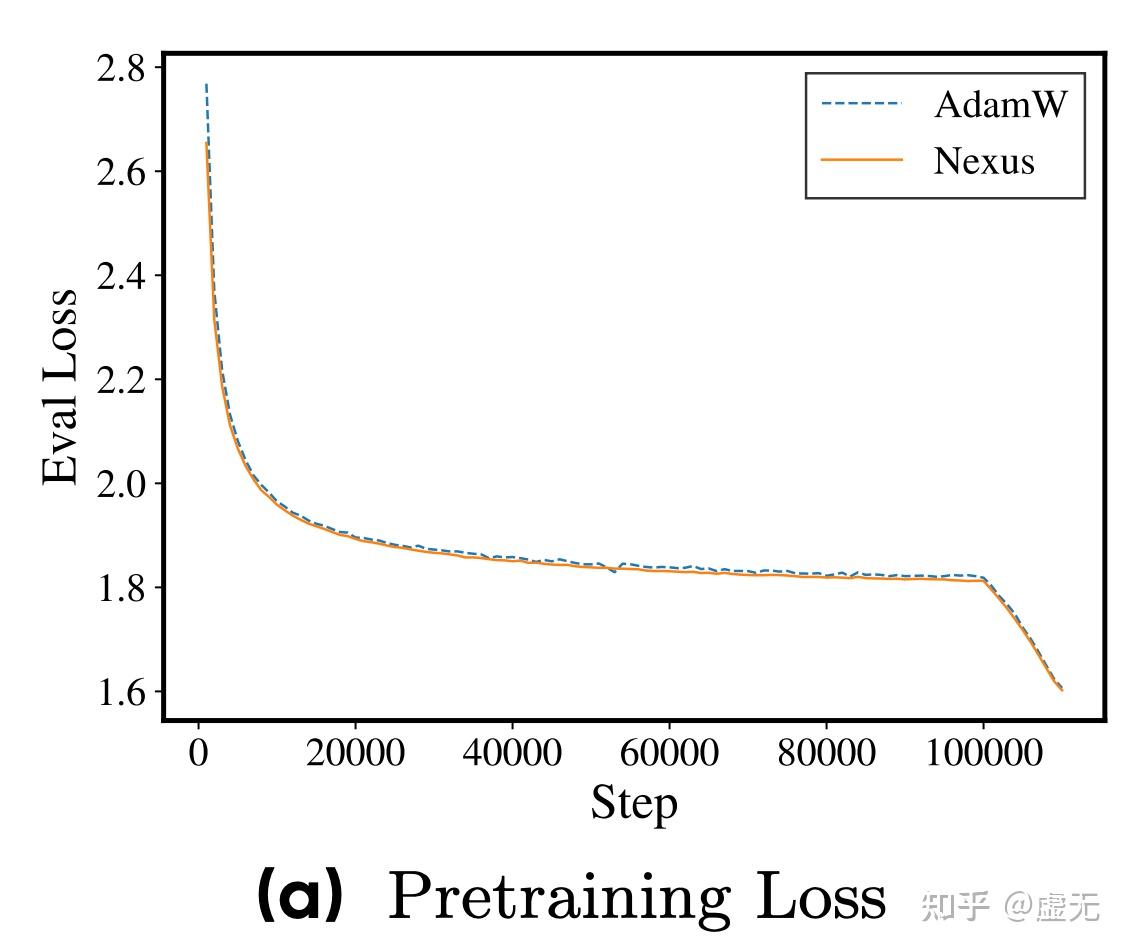
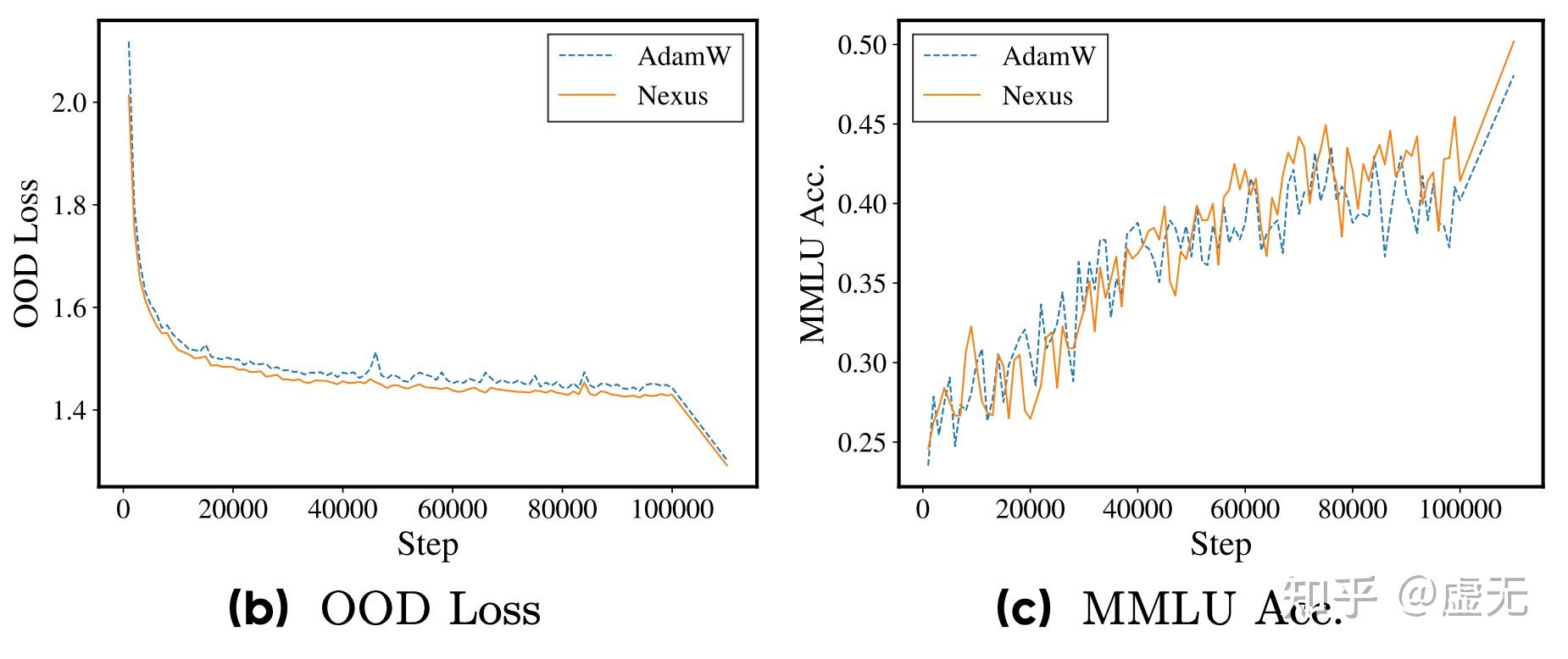
Nexus regularization实现了这样一个效果。它的pretraining loss和adam几乎一模一样(只有千分位的差别,我们一般认为0.005以下的loss差别完全不显著):
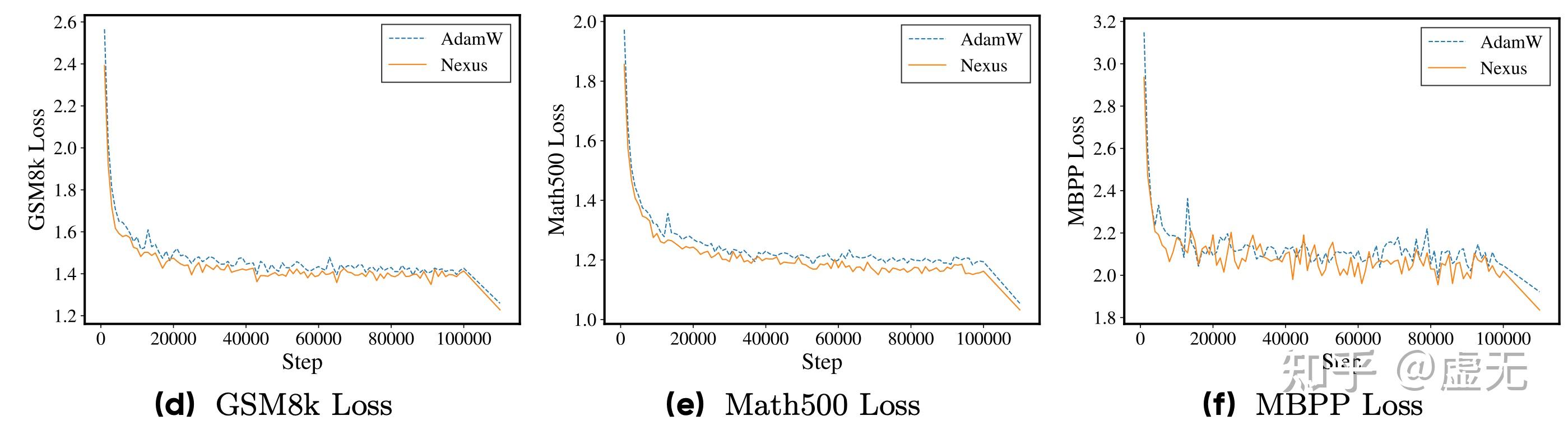
而downstream loss却远远低于AdamW,能看到downstream loss和baseline之间有一个明显的gap:
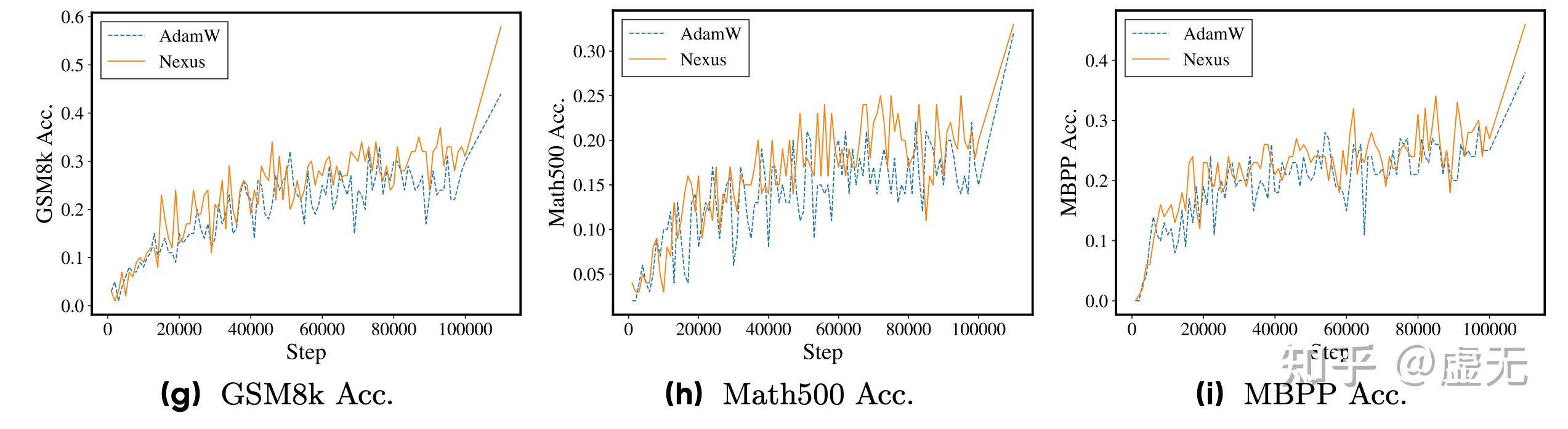
因为downstream loss降低了,所以downstream benchmark也和baseline有一个非常明显的差别。例如GSM8k提升了15%,Math500提升了8%,HumanEval提升了4%:
因此,pretraining loss相同,并不代表模型下游能力就相同。即使pretraining loss已经不下降了,我们仍然可以通过加入regularization(e.g., 我们的nexus regularization,或者 sharpness-aware minimization)实现上图“Same Pretraining Loss, Better Downstream task”的效果。

1. 虚假的Motivation:为什么要进行这项研究
(这里motivation不是我的motivation.... )
在过去的LLM Pretraining中,大家一般尽可能多的从互联网上收集数据进行清洗,然后进行scaling。但是,一些研究表明,我们会在2027-2028年用完互联网上所有的数据:
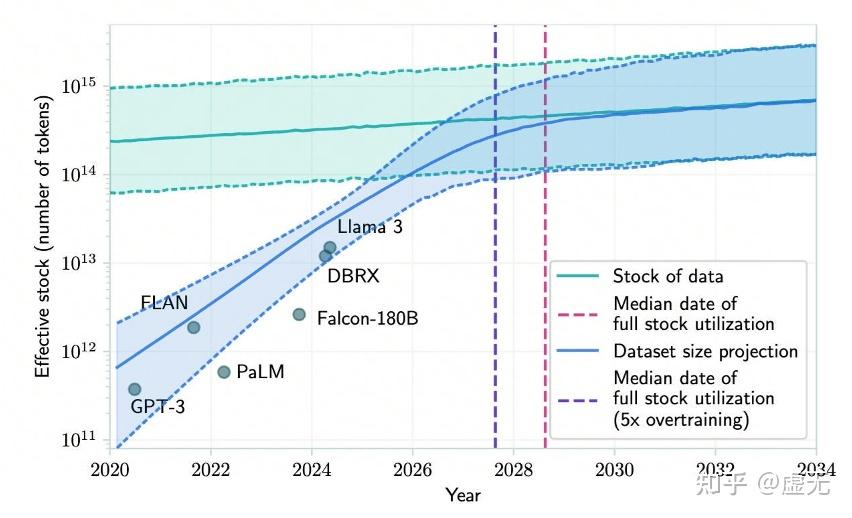
那么当我们把所有的互联网文本数据用完之后,应该怎么去提升模型能力呢?难道我们提升能力只能靠降低在人类数据上的loss吗?pretraining loss一样,模型能力一定就一样吗?除了降低pretraining loss之外,还有什么方法提升模型的能力呢?
2. 真正的motivation:除了0阶的pretraining loss外,还有什么和泛化性相关呢?
我们关心的模型能力,本质上是我们在pretraining set上得到 {\theta}_{\text{train}}^* \in \arg\min_{{\theta}} \mathcal{L}_{\text{train}}({\theta}) 之后,关心它在下游任务 \mathcal{T} 上的表现。我们可以发现这取决于3项:
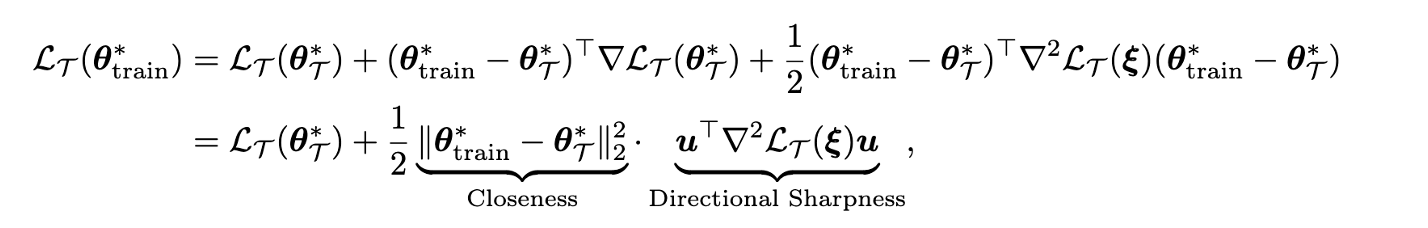
1.Intrinsic Loss \mathcal{L}_{\mathcal{T}}({\theta}^*_{\mathcal{T}}) , 即下游任务的minimizer在下游任务的loss function上的loss。
2.Closeness,即pretraining set minimizer和downstream set minimizer离的有多近,也是本文的研究对象。
3.directional sharpness。在pretraining set minimizer和downstream set minimizer连线上,loss landscape平不平。可以注意到
所以我个人认为,最重要的sharpness是这个特定方向上起决定性泛化作用的sharpness,而大家通常用的sharpness metric,如hessian的2-norm/F-norm,是在minimize这个决定性方向的sharpness上界。
因此,loss landscape在这个特定方向上越平坦:
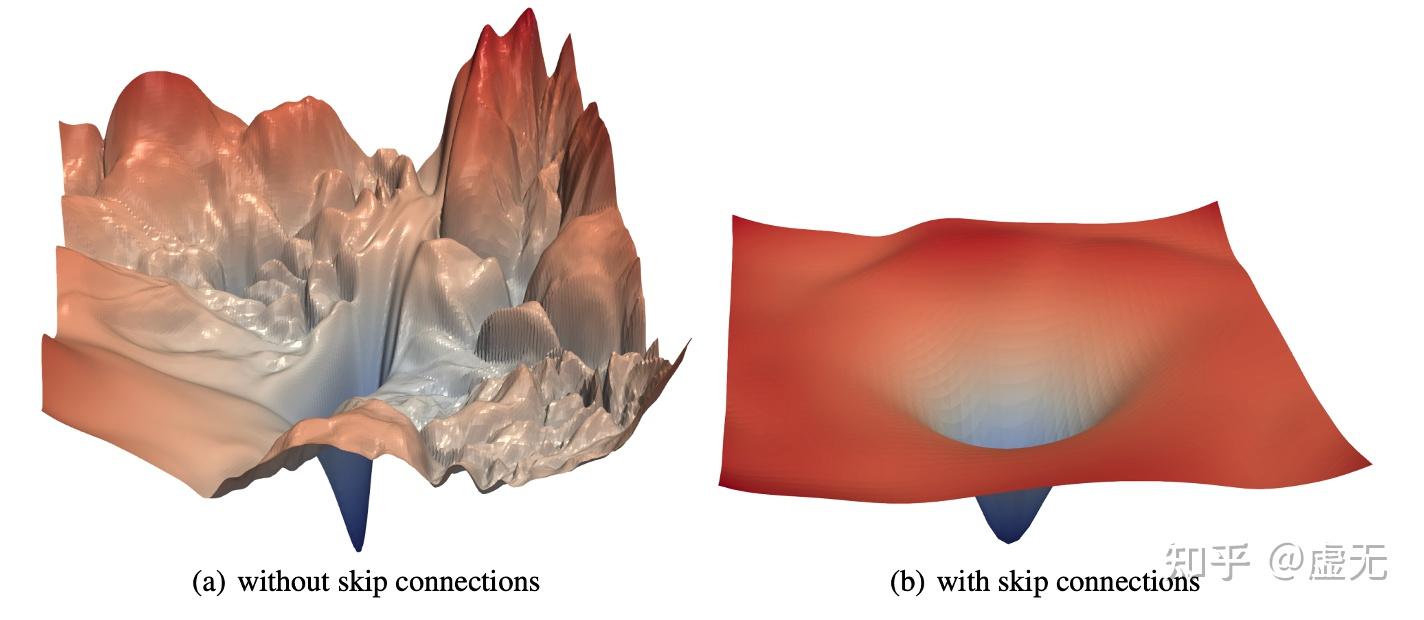
且pretraining set minimizer距离downstream越近(或者说他们的loss landscape越近):
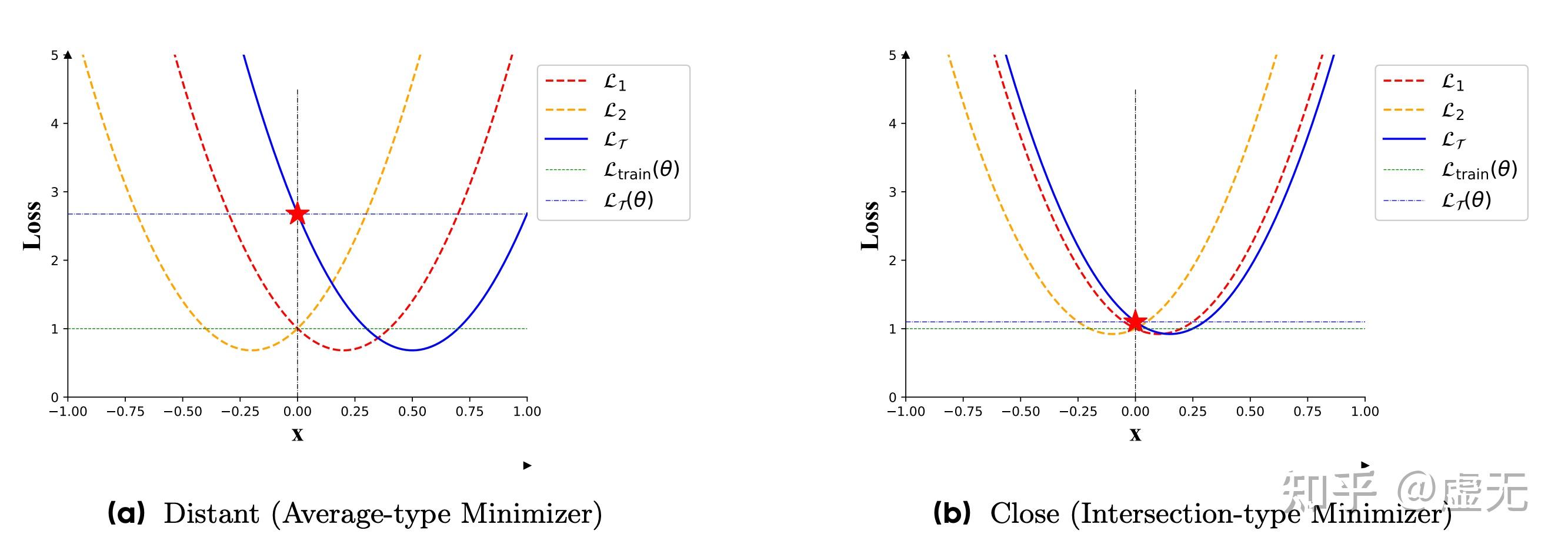
那么模型就会具有更好的泛化性。
上图是个很有意思的图。可以看到,pretraining loss \mathcal{L}_{\text{train}}({\theta}) = \frac{1}{2}(\mathcal{L}_1({\theta}) + \mathcal{L}_2({\theta})) 。
在(a)和(b)中,pretraining loss都是1,但是downstream loss却天差地别。因此我们可以认为,在pretraining loss相同的情况下,landscape的closeness/sharpness,对模型的下游任务起非常重要的作用。
你可能觉得上图只是我故意把图画成这样。但实际上是这样的:我们随机initialize一个task set,\{\mathcal{L}_1, \mathcal{L}_2, ..., \mathcal{L}_K\}
每个loss function都是quadratic function。我们随机sample一些作为pretrain set,随机sample一些作为downstream set。上图便是以这种方式画出来的。而且只要满足这种方式,那么generalization error一定正比于 closeness:
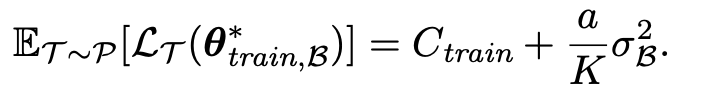
这里有两个假设:
1.loss function是quadratic(或者说,在某些特定方向上长得比较像quadratic)。
2.pretraining set和downstream set是独立的采样出来的。(注:这不是说pretrain set和downstream set是i.i.d.的。他们之间是o.o.d.的,只是他们是i.i.d.的从某个task set中sample出来的)
因此,只要你觉得loss function在你的脑海中长得像quadratic function,那可能优化closeness就会在相同的pretraining loss下,提升模型的能力。
3. 优化closeness:gradient similarity
那么,怎么才能优化我们的training set closeness\frac{1}{K}\sum_{k=1}^K\|{\theta}_{\text{train}}^* - {\theta}^*_{k}\|^2_2呢?总不能真的每次去寻找\theta_k^*然后再计算MSE loss吧。
我们再盯着这个图看看:
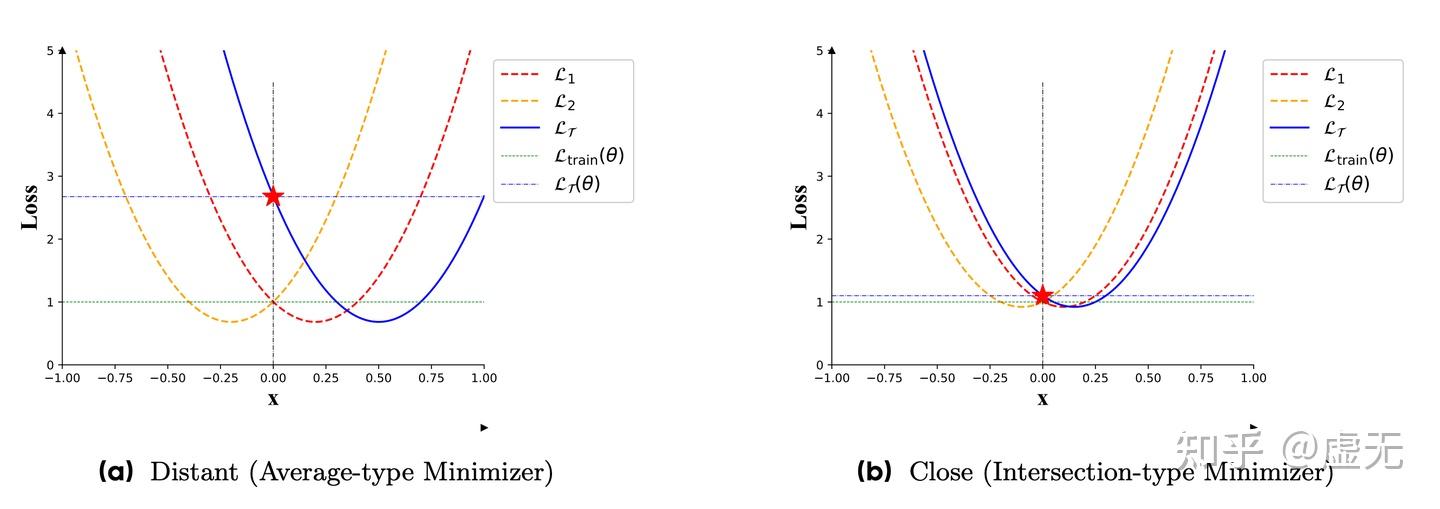
我产生了一个intuition:比如说我们现在优化到了某个点\theta 。如果这个时候,各个loss function的梯度\{\nabla \mathcal{L}_1, \nabla\mathcal{L}_2, ..., \nabla\mathcal{L}_K\}方向是相同的,那么意味着他们的极小值点也倾向于在一块。如果各个loss function梯度都不一样,那么就意味着他们极小值点也不在一起。
因此,似乎我们只要沿着gradient similarity 高的trajectory进行优化,就可以实现optimize closeness了。
更general的来说,这个intuition在二次函数上是完全正确的。即,如果每个函数都是二次函数(或者在关键方向上比较像二次函数),那么优化gradient similarity就是在优化closeness(即下式取等):
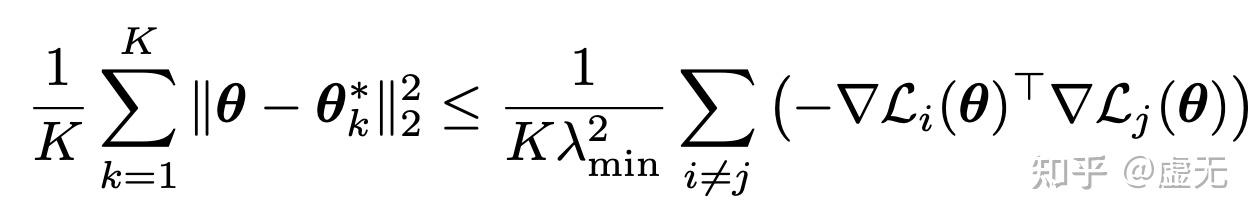
同时,gradient closeness也可以让我们直观理解为什么closeness会实现“same pretraining loss, better downstream task”。下面的式子只是简简单单的一个一阶泰勒展开:

可以看到,pretraining set和downstream set的gradient similarity,就代表着在pretrain set做一步GD,在downstream set的loss下降了多少,即,gradient closeness就代表了泛化性。
因此,我们如果能优化gradient similarity,就很可能得到更好的泛化性。
当然你可能会质疑,我们无法优化pretraining set和downstream set的gradient similarity,而只能优化pretrain set内部的gradient similarity。这不一定能泛化到downstream set。
但我想argue的是,pretrain set自己内部的data互相gradient similarity至少是必要条件。如果pretrain set自己内部的data互相gradient similarity都不高,又怎么能提升pretraining set和downstream set的gradient similarity呢?
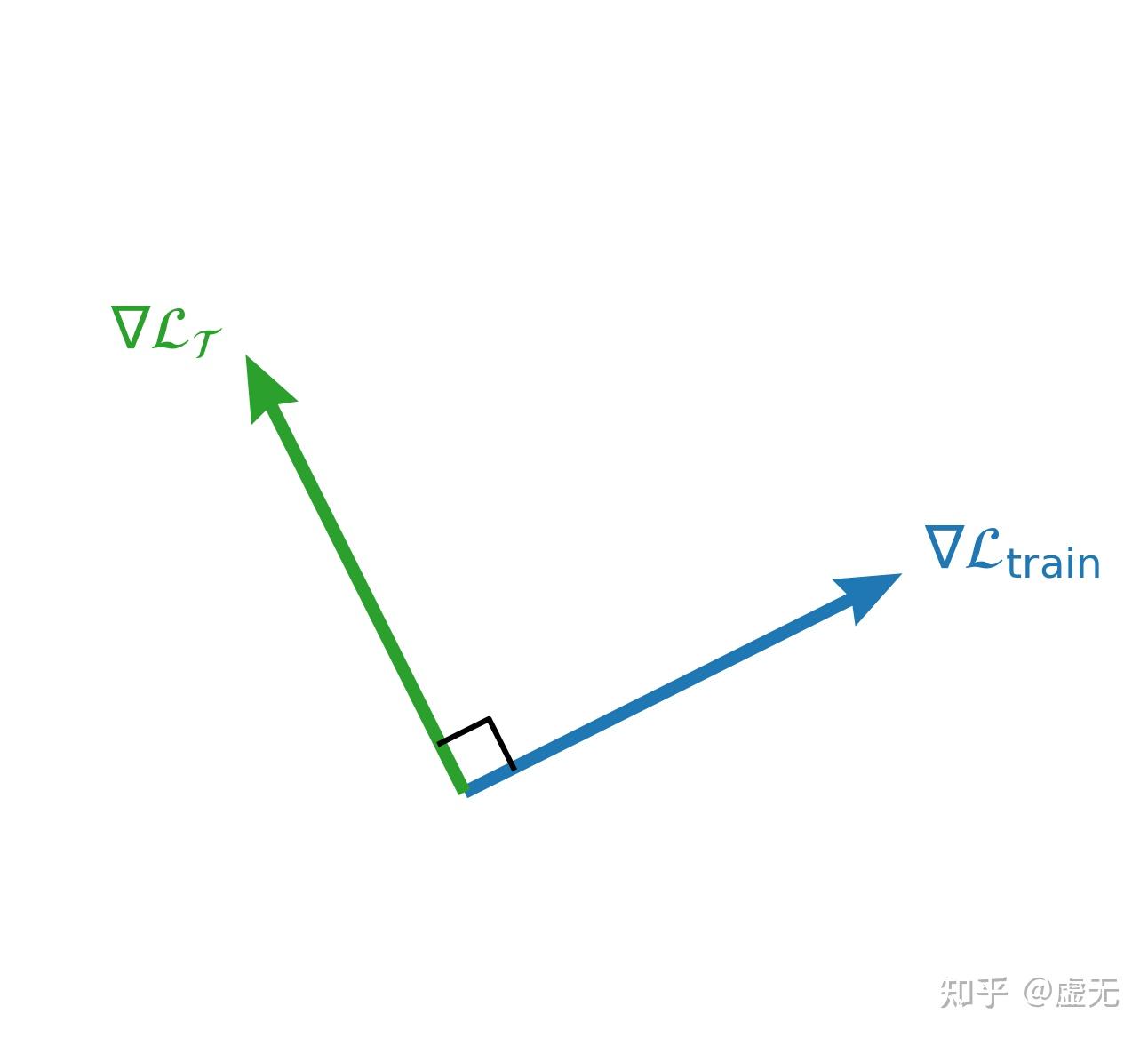
很多研究都表明,pretraining set随便sample两个1M token的batch,产生的梯度几乎是正交的。既然pretrain set自己跟自己的梯度都不像,又何谈让pretrain set和downstream set梯度像呢?
因此,想到这里,我觉得如果能强行把pretrain set内部的gradient similarity大幅度提高,那么一定会在training dynamic上有巨大改变,而且我expect会实现“Same Pretraining loss, better downstream task”
4. 优化gradient similarity:Nexus regularization
优化gradient similarity需要求gradient similarity的导数:
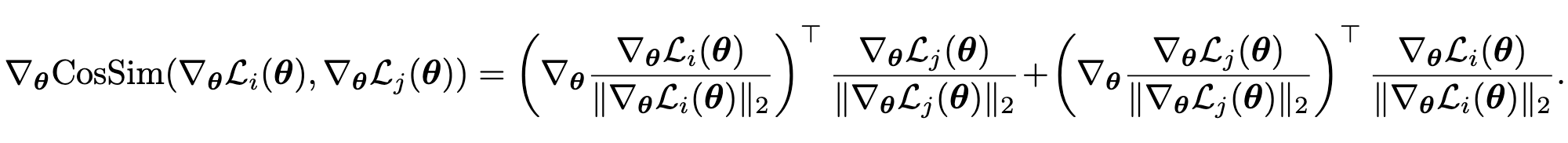
为了避免计算hessian-vector(or jacobian vector) product这种需要二阶导的东西,我们想了个nexus algorithm。我们还是以只有两个loss function \mathcal{L}_{\text{train}}({\theta}) = \frac{1}{2}(\mathcal{L}_1({\theta}) + \mathcal{L}_2({\theta})) 的情况举例。
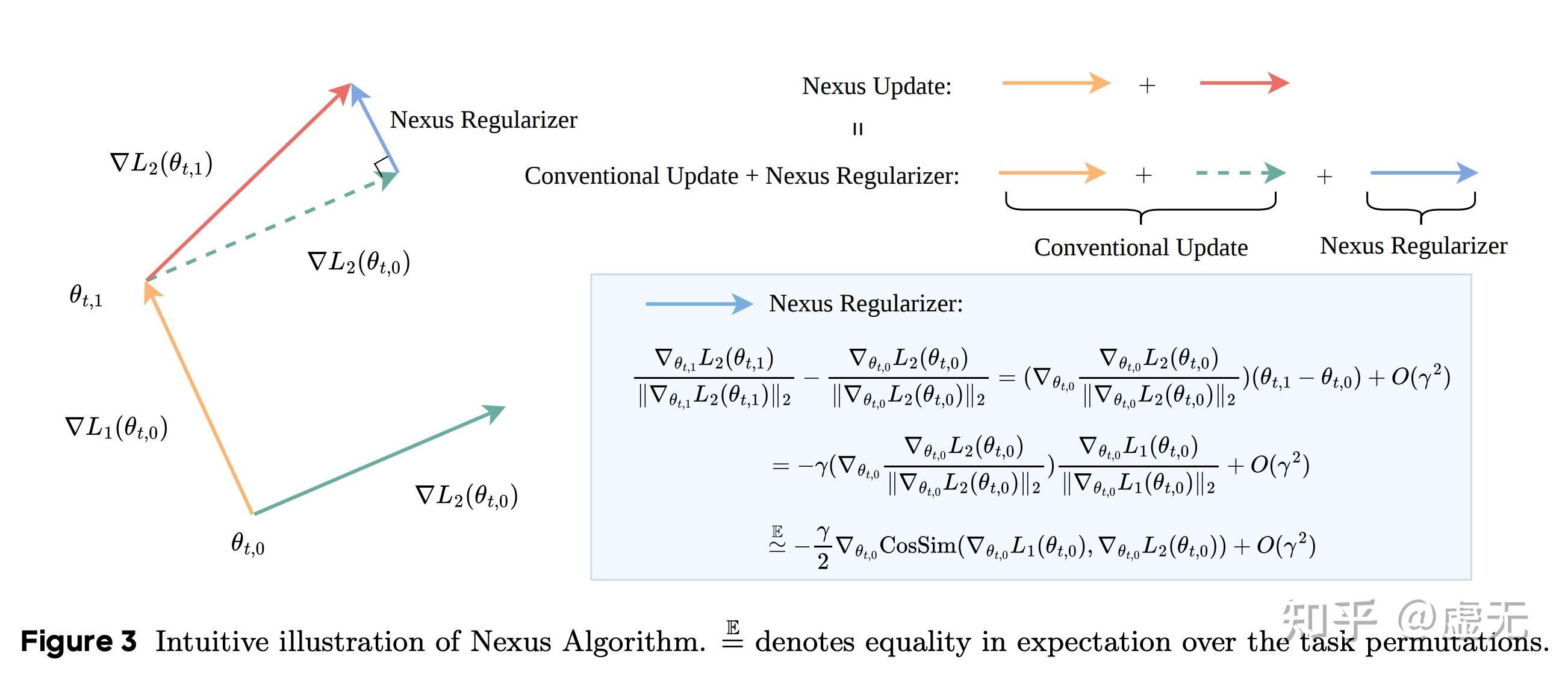
对于正常的训练,我们会同时计算 \nabla L_1 和 \nabla L_2 并求和。因此,我们走的是实际上是黄线+绿线。
对于nexus pipeline,我们是先计算 \nabla L_1 ,然后立刻用SGD进行update(注:只能是SGD,不能带动量,否则不work)。随后,我们在update后的点计算\nabla L_2.然后,我们把模型回退到一开始的\theta_{t, 0},并用我们所计算的两个梯度的和进行update。因此,我们走的实际上是黄线+红线。
那么新算法相比之前有什么区别呢?黄线+红线 和 黄线+绿线的差刚好是nexus regularizer,而nexus regularizer,刚好就是gradient similarity的梯度。因此,该方法可以优化gradient similarity。
在实际过程中,我们其实不需要修改training pipeline。我们只需要简单加2-3行代码。正常的pretraining流程如下:

1.每次backward,进行gradient accumulation
2.到了gradient accumulation step之后,进行update
而Nexus pipeline如下:
1.每次backward完之后,立刻用SGD update(注:只能是SGD,不能带momentum,否则不work)
2.等到gradient accumulation step之后,再把全部update当作pseudo gradient,塞进之前的optimizer里,进行update。
这样修改,实际上优化的是两个相邻batch之间的gradient similarity。这样完全不需要修改任何超参数,也不增加任何forward backward的次数,可以无痛融合到pretraining pipeline中。
这样的方法想要work,取决于非常重要的一点,即“两个相邻batch之间的gradient similarity本身要很低,而我们把它强行变高,因此才会有所不同”。
我们来举三个例子
failure mode 1: BS65536,切分成两个32768的mini-batch. 但是两个32768的mini-batch之间本来gradient similarity就是1,因此不能带来任何正则作用。
failure mode 2: BS=1024,切分成1024个BS1的mini-batch。本质上是在优化任意两个样本之间的gradient similarity,正则化的随机性过大,导致完全没有任何意义
typical mode:BS=1024,切分成两个BS512的mini-batch,或者4个BS256的mini batch。这样才会起作用。
因此,这样的adaption只是恰好符合了pretraining “相邻两个batch gradient similarity低”的特性。如果你的数据集不符合这样的特性,直接使用Nexus算法可能就没有任何用,可能需要重新调整一下gradient accumulation steps。
5. 实验验证
5.1 Setting
我们用Seed-OSS的数据集进行pretraining。这是一个非常nice的数据集,他稳定、没有任何benchmark泄漏、数据质量高(所以小模型上也能得到不爆0的benchmark)。缺点就是这数据集并不开源。。。

对于超参数,我们采用的是Kaiyue Wen的 Fantastic Pretraining Optimizers and Where to Find Them 的超参数。这里的超参数是kaiyue爆搜出来的,调整任何一个超参数(甚至包括epsilon)都会使得速度变慢,因此是绝对的optimal speedrun超参数。
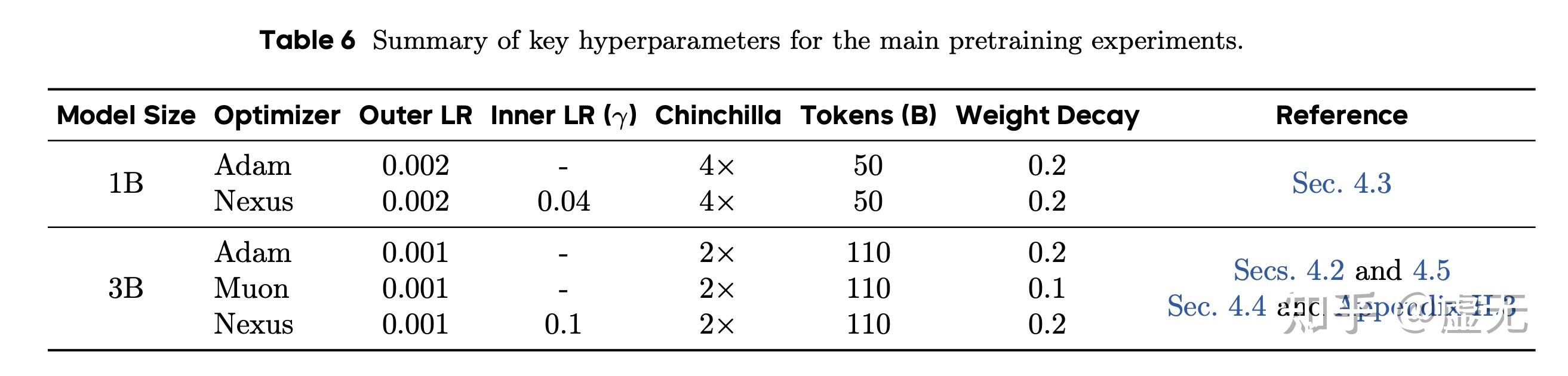
Nexus这里只有一个额外超参数,那就是inner LR \gamma 。注意这个inner LR还有另外一层含义,即loss和regularizer的比值也是差不多 1: O(\gamma) 。因此,我们肯定希望 \gamma 越大越好。但是如果 \gamma 太大,则会导致regularizer主导,从而loss不下降。因此,我们调参的核心原则就是,“把 \gamma 尽可能开大,只要不影响pretraining loss”
5.2 实验结果
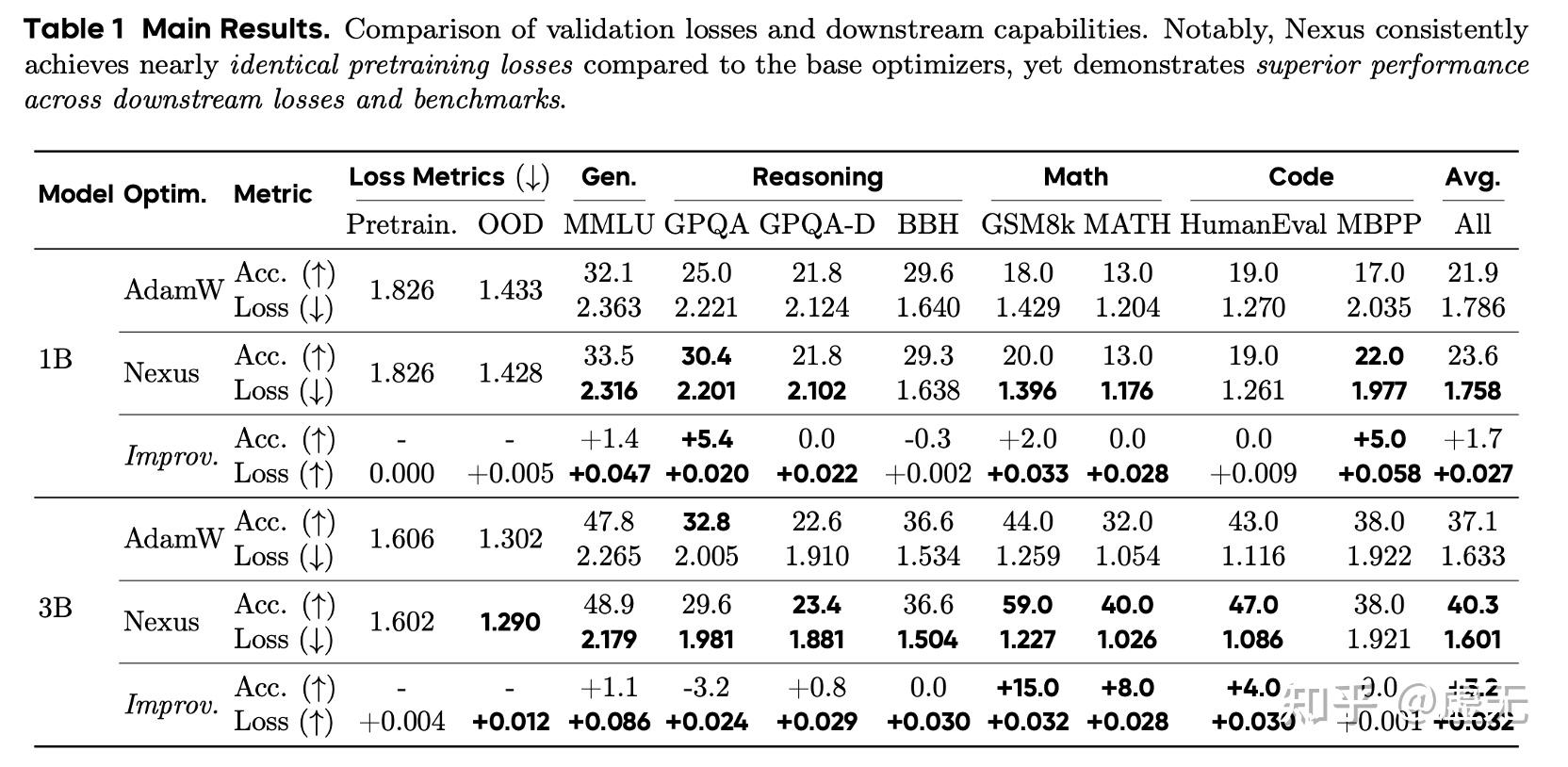
可以看到,Nexus基本完全没有改变pretraining loss,但是却大幅度提升了downstream loss & benchmarks.
由此可见,implicit bias matters,closeness & flatness matters。
当然我还是更喜欢看training curve而不是看表,因为看training curve可以更明显的看到这个趋势:
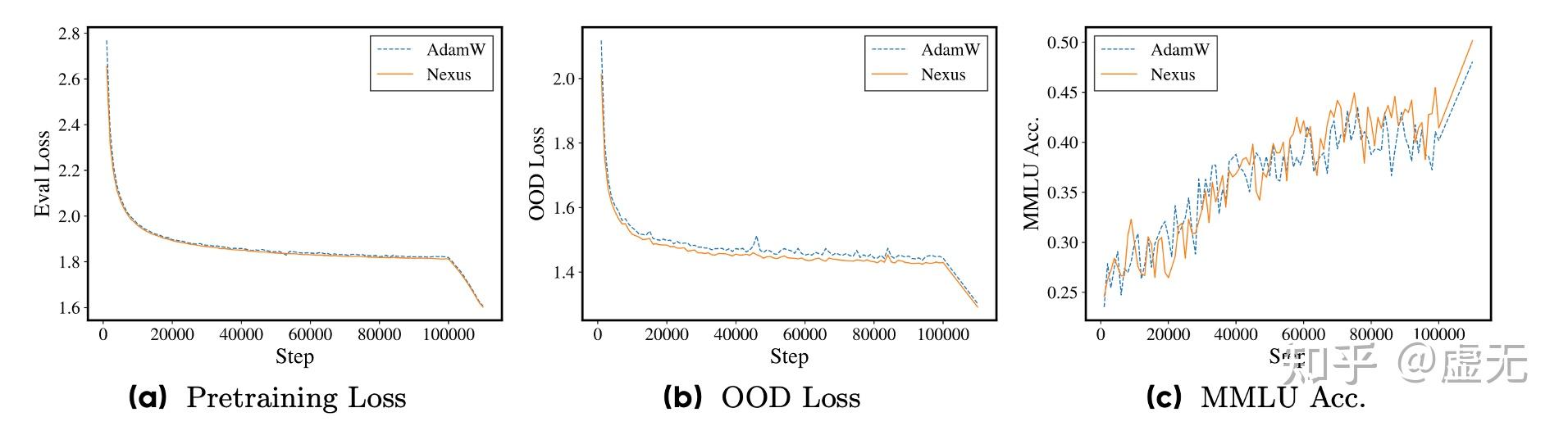
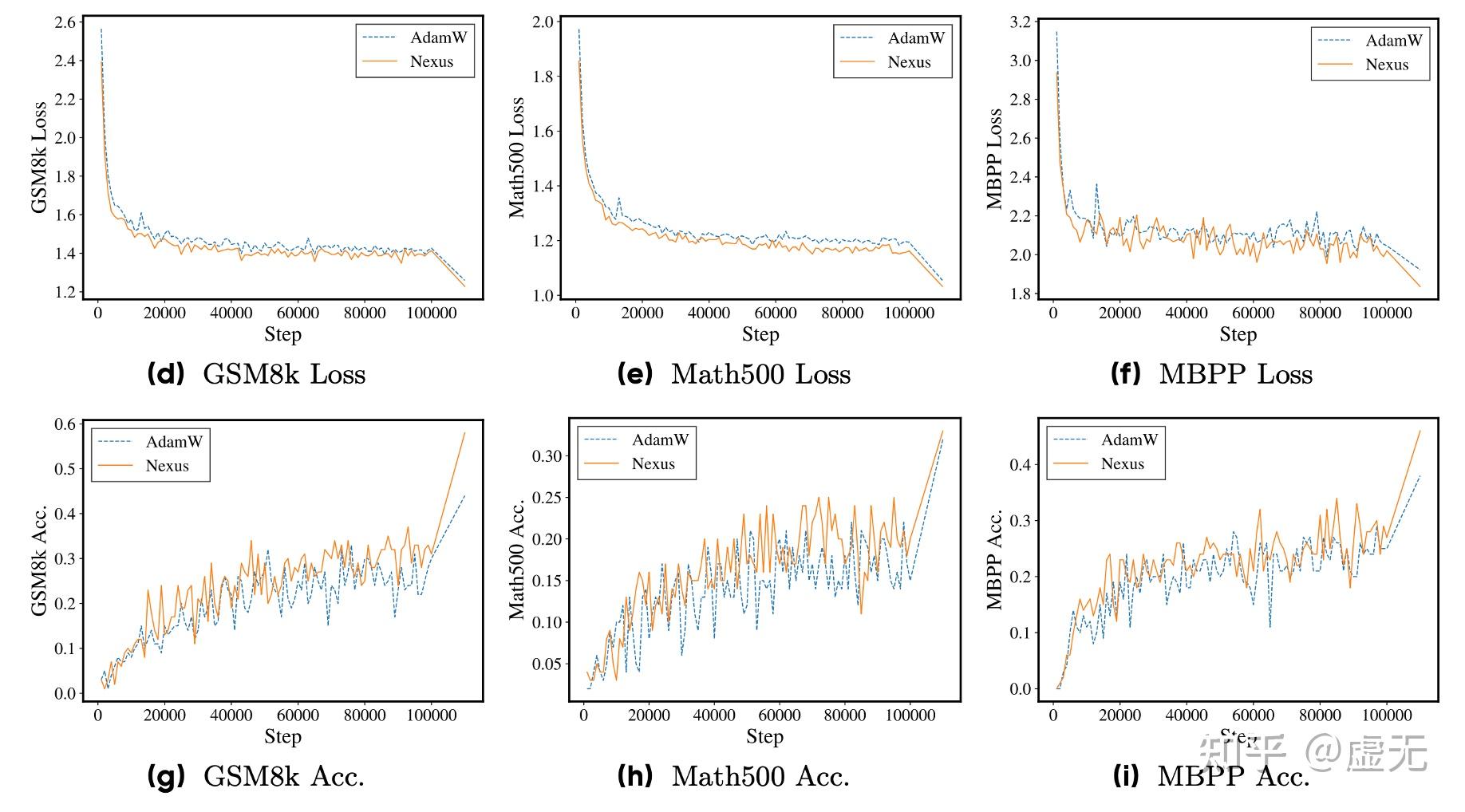
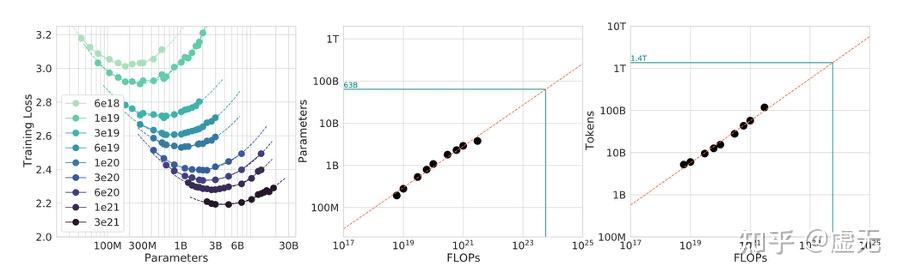
5.3 Scaling Law
现在我们考虑一个方法,一定要考虑scaling law这个维度。因为如果一个方法随着model size的增加,越来越塌缩到baseline,那么就是没必要的。
因此,只有这个方法能
1.改变scaling law的截距
2.改变scaling law的斜率(当然我指的是把斜率变好,而不是变差)
才值得被应用。
那么closeness到底会不会随着模型scale的增加而塌缩到baseline呢?如果你比较熟悉flatness literature的话可能已经预测到这一类方法的结果了。因为大家研究implicit bias,都是在"zero training loss" or "over-parameterization"下研究的:


因为当且仅当你的模型足够大,compute足够多,你才能在不影响pretraining loss优化的情况下进行flatness/closeness的优化。而且如果0阶的pretraining loss已经完全优化不动了,那么起作用的,必然只有1阶 2阶的flatness/closeness了。这个时候,他们才会大有作为。
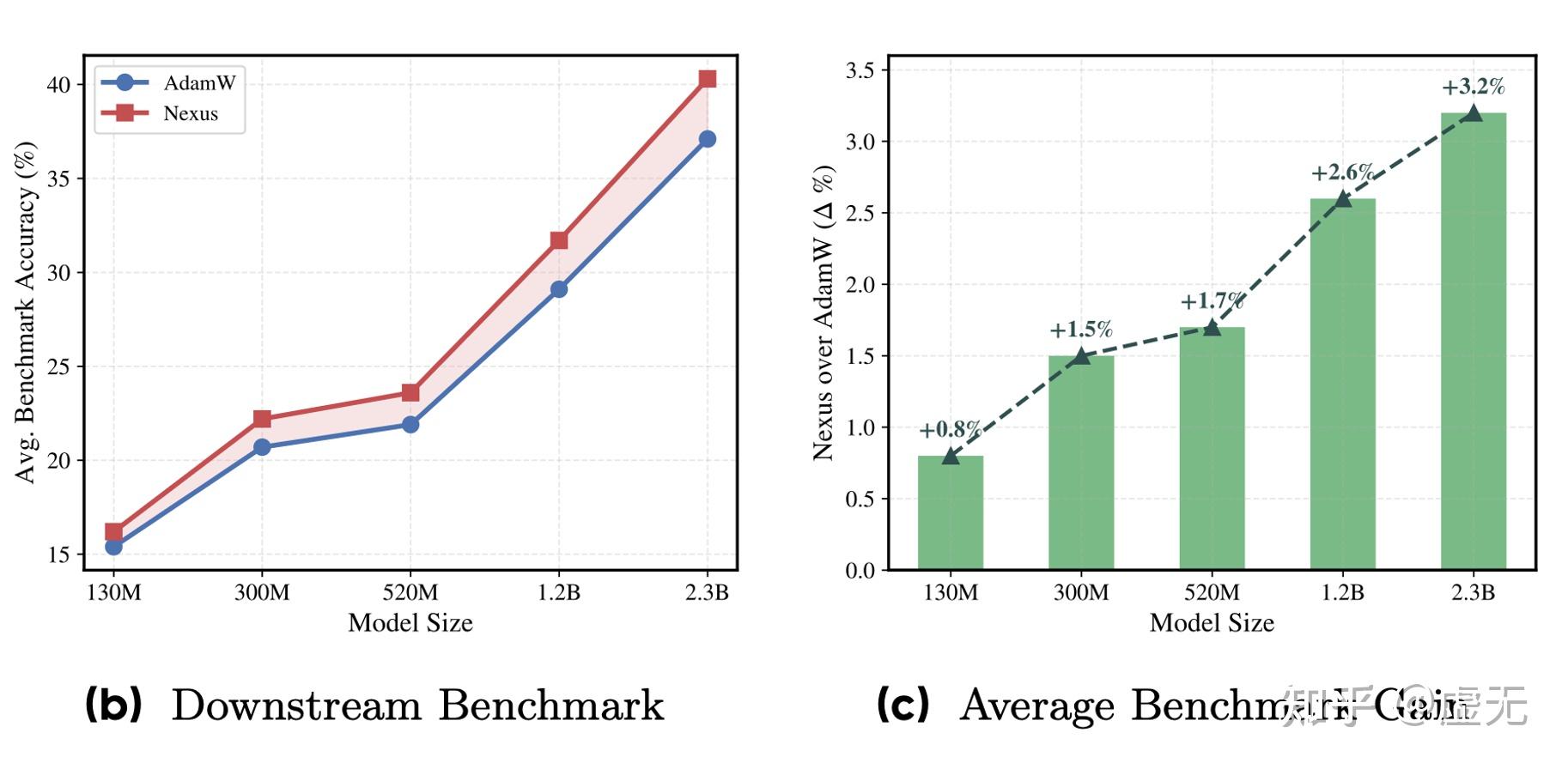
实验结果也的确如此,随着model size的增加,Nexus相比baseline Adam的增益越来越大。
这些实验都是一次跑出来的,完全没有进行任何调参,因此可信度非常高。
一个非常好玩的事情:我一开始使用的是130M的模型进行研究,当时我不仅尝试了closeness,还尝试了flatness,但是都没有看出相比于baseline有什么区别。因此,implicit bias在这种小模型上基本是不起作用的。
如果你是在这种scale的模型下研究implicit bias,那可能会非常不幸,观察不到任何现象。
随后我换到520M模型上,发现flatness和closeness都能有明显的“Same Pretraining Loss, Better Downstream Task”的效果了QwQ.
论文中还有许多其他实验!这里就不再写啦!
6. Limitation
非常不幸的是,该方法在Muon下完全不work。如果你还是把 \gamma 设置为0.1,即以 10:1 的比例进行loss和regularizer的优化,并把近似梯度塞进Muon里,则会发现,pretraining loss完全优化不动了,pretraining loss就会差出0.05:
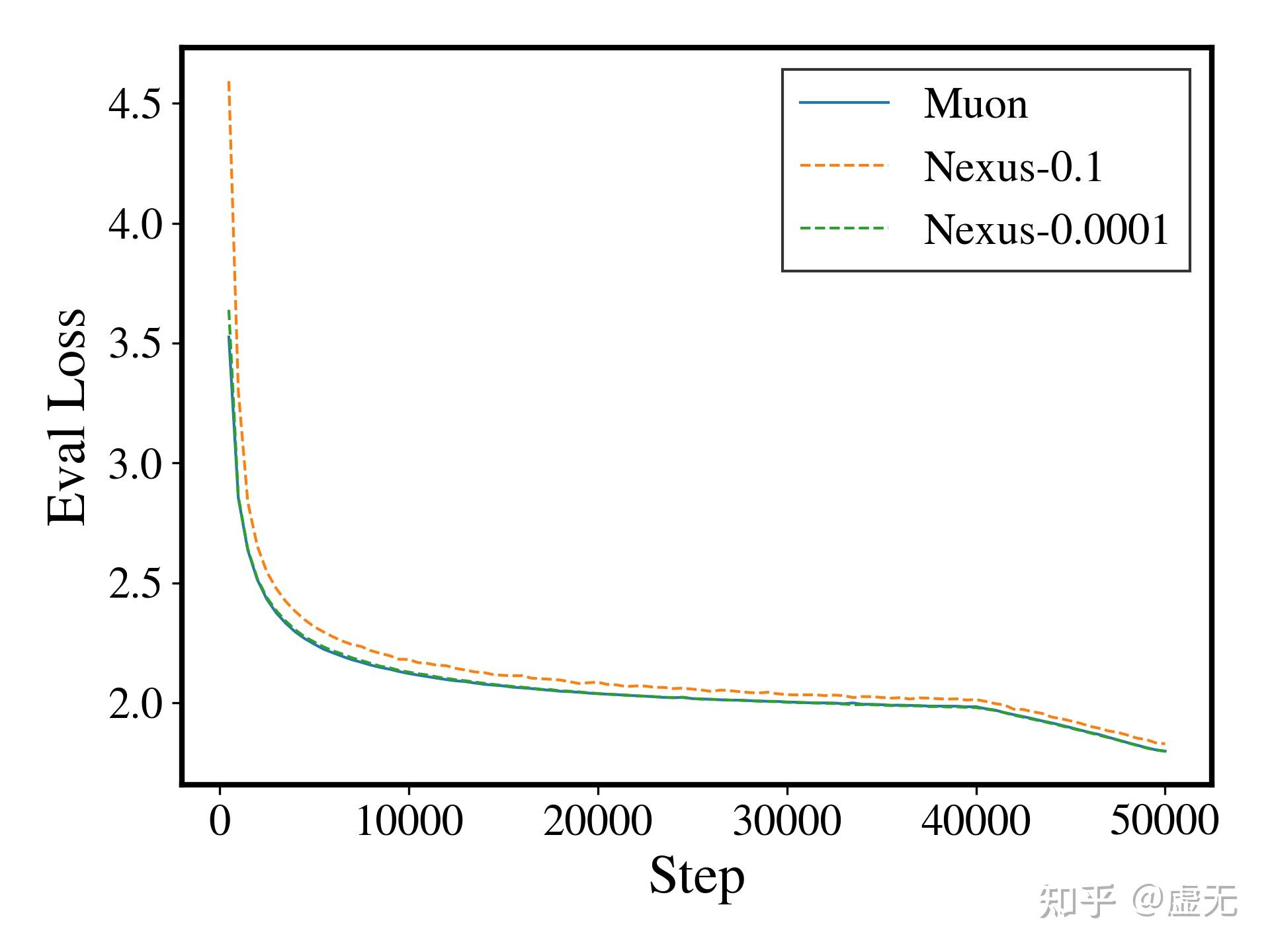
当然,Nexus算法有个比较好的性质,那就是 \gamma\to 0 ,Nexus就会塌缩到baseline上,但是这样也就没有正则化作用了(例如上图的0.0001)。如果我们只能以1:0.0001的方法优化loss和regularizer,那么也就没有任何意义了。
为什么Muon加正则项后会大幅度减速?我觉得这可能需要先回答“momentum orthogonalization何时能加速,何时能减速,以及加速的机理是什么”。Muon正交化相当于丢失了50%的信息,或者说放大了剩下的50%的信息,当且仅当丢失的信息都是无效信息可能才会加速吧,而这件事可能是non-trivial的,可能不是always holds true的。
7. 结语
通过本文的实验和简单的公式可见,除了0阶的pretraining loss之外,1阶的gradient closeness,2阶的flatness/closeness确实很重要!而且是模型越大scale越大越重要!
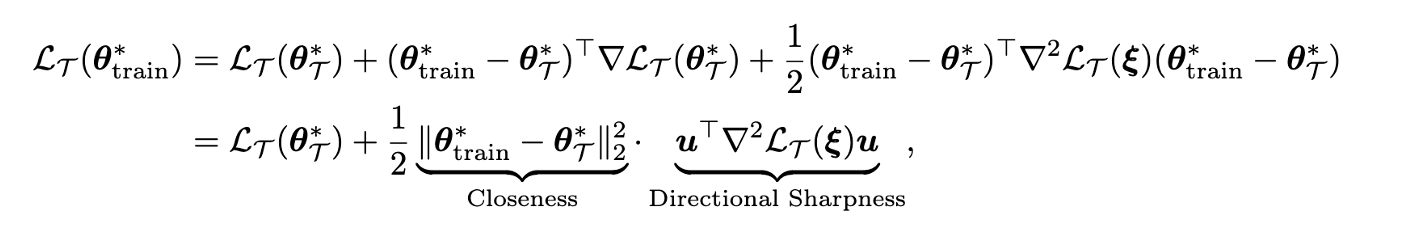
尤其是,当你0阶的pretraining loss已经降低不了的时候,那么这个时候起作用的,很可能就只有1阶2阶的flatness/closeness了。
也非常希望大家来试试我们的pretraining 框架!集成了Adam、Muon、Row-Normalized SGD等optimizer,未来也会持续更新。