
强化学习正在重塑大模型能力边界。OpenAI o3、DeepSeek-R1、Gemini 3 等顶尖模型都在用大规模 RLVR(可验证奖励强化学习)刷新推理任务的天花板。
但所有人都知道,纯监督式训练不可持续。人工标注成本指数级增长,在专业领域获取可靠标注越来越难。当模型能力逼近甚至超越人类专家时,谁来给它打分?
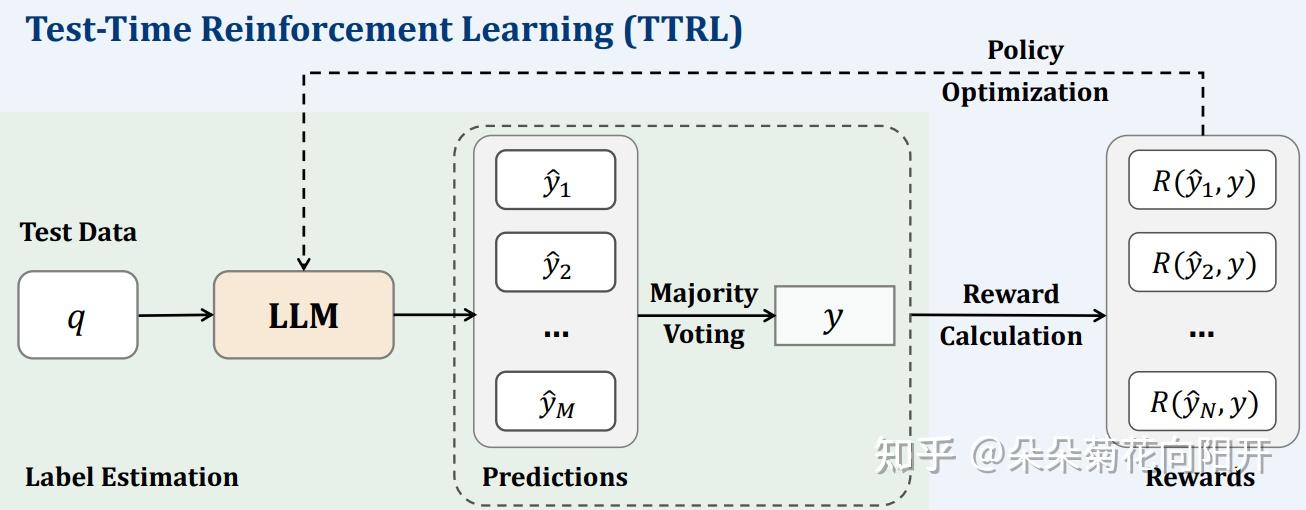
从 TTRL 开始,无监督 RLVR(Unsupervised RLVR)应运而生,让模型在没有人工标注的情况下持续进化。这不仅是降本增效的需求,更是通往超级智能的必经之路。
就像预训练用无标注数据 training 出了 GPT,无监督 RLVR 能否延续这一奇迹?
4月27日(周一)晚8点,青稞Talk 第122期,清华大学博士生何秉翔,将直播分享《从 TTRL 到 URLVR:大模型的无监督强化学习还能走多远?》。
分享嘉宾
何秉翔,清华大学博士生,导师为清华大学刘知远教授。研究方向为大模型对齐与强化学习,曾在 ACL、ICML、NeurIPS 等人工智能国际顶级会议发表论文,谷歌学术引用量超1700次。
主题提纲
从 TTRL 到 URLVR:大模型的无监督强化学习还能走多远?
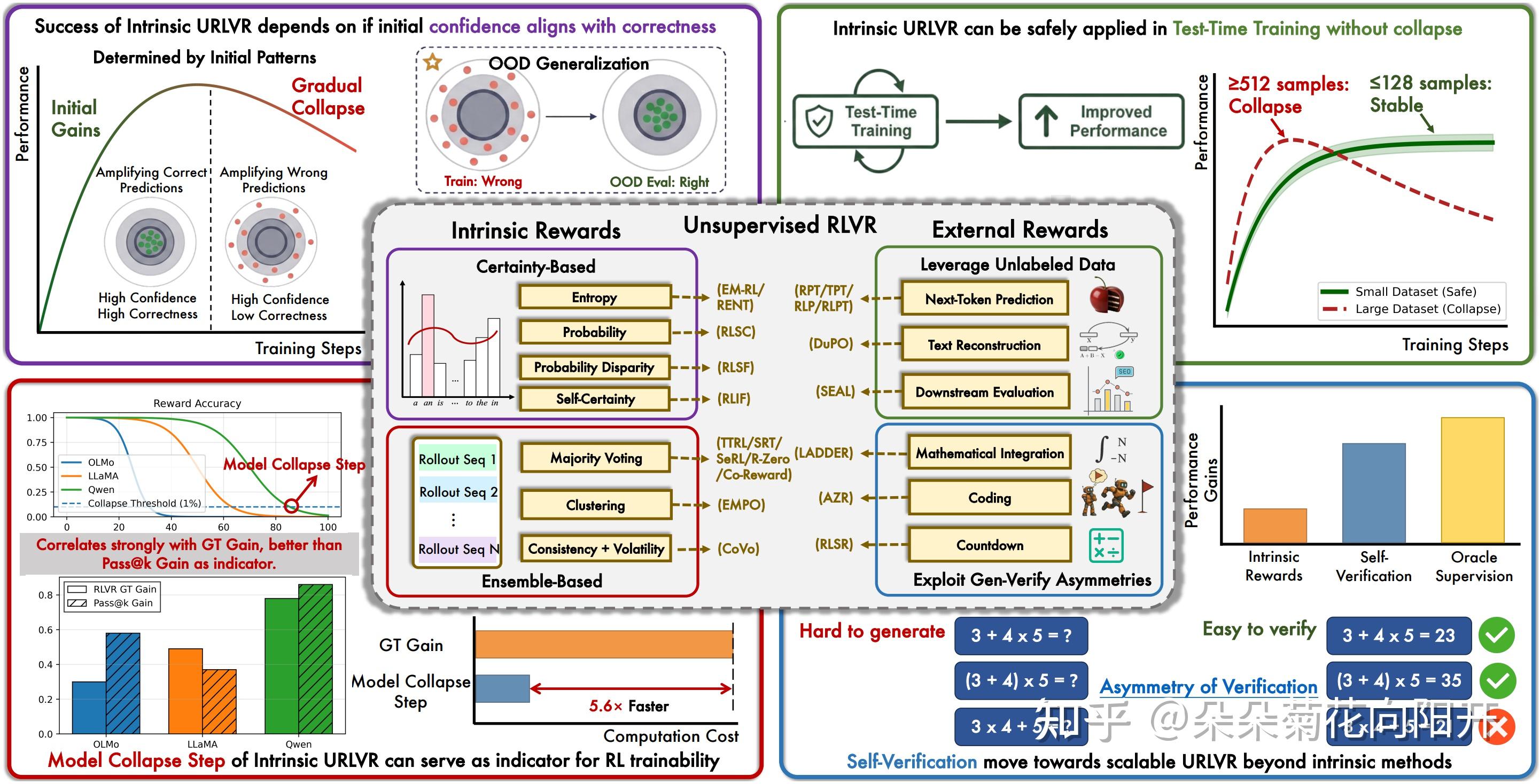
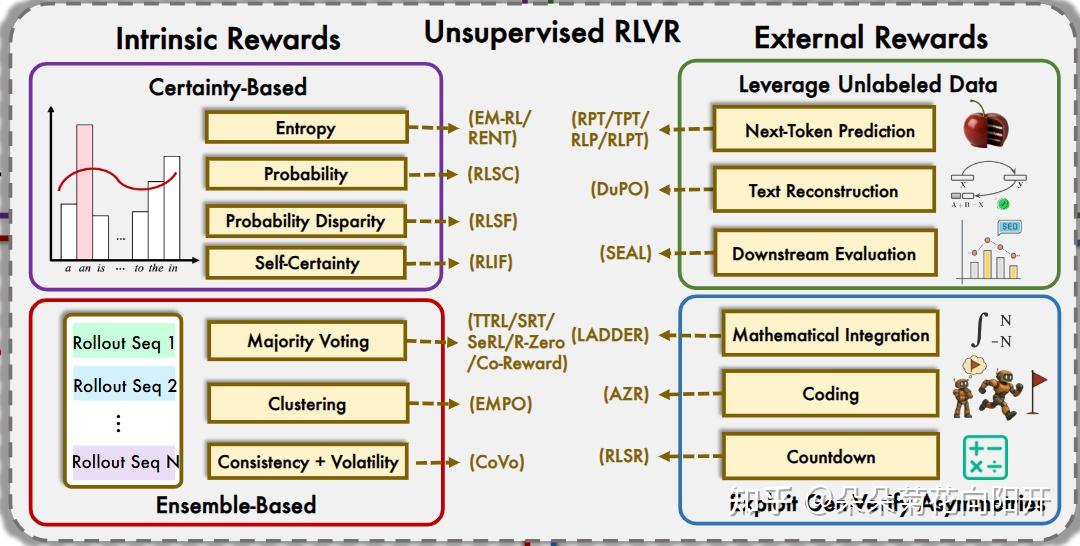
1、无监督 RLVR 全景图:内在 vs 外部奖励分类
2、内在奖励的宿命:rise-then-fall 与置信度陷阱
3、安全区与快速诊断:哪些场景下内在奖励仍然有效?
4、突破天花板:如何走向真正可扩展的无监督 RLVR?
5、AMA(Ask Me Anything)环节
直播时间
10月27日(周一)10:00 - 11:00