作者:dung defender
https://zhuanlan.zhihu.com/p/2019320352367494543
今天主要来分享physical intelligence的最新工作:
标题:RL Token: Bootstrapping Online RL with Vision-Language-Action Models
链接:https://www.pi.website/research/rlt
Motivation
这篇工作主要希望使用VLA模型来处理一些精细操作任务,例如使用螺丝刀拧紧螺丝,插拔插头等等。
这类任务对控制器的输出精确性有很高的要求,而且数据相对而言较难收集。
除此之外还有一个很麻烦的点,就是使用这类任务的操作数据finetune VLA并不trivial。因为我们希望VLA模型是一个尽量泛化的模型,怎么调节VLA的训练recipe使得模型既保持泛化,不overfit到特定的任务上需要精巧设计。
那么一个在控制领域很经典的解法就是,我不指望一个模型直接输出最终解,而是输出一个初始解,让下游的一个模型(NN,model-based opt)来优化这个初始解,得到最终可以使任务成功的解。这是一个很成熟的思路,在传统工作里有大量的相关涉及。
Method
这篇工作的做法也不复杂,基本的思路就是VLA backbone来提供问题的初始解,然后online地用RL学习一个修正policy,得到最终的控制输出,注意这里VLA backbone是freeze,不需要训练的。
既然我们希望这个修正policy可以高效学习,那这个网络结构,以及输入输出最好做的比较compact,所以这篇工作提出一个叫RL token的概念,实际上相当于就是对VLA的输入的hidden state做了压缩,得到一个更加紧凑的表达。
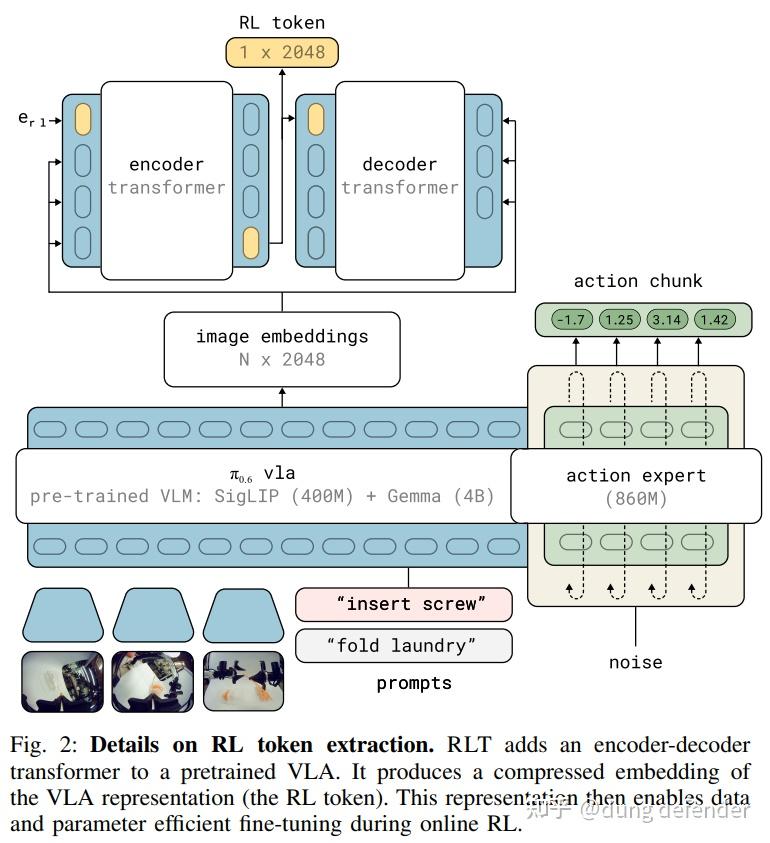
这里我理解哪怕不用这种encoder-decoder的架构也是可以的,只要可以对VLA的state来做高效的压缩即可。
后面就简单了,我们需要用一个RL算法来训练一个外挂的policy,它接收这个RL token以及一些其他信息作为输入,然后输出action来驱动机器人完成任务。这里的问题是我们需要选择什么样的RL算法。
为了可以高效地使用数据,我们最好使用off policy的RL算法,同时我们的输出action是连续的而非离散的。那么一个合理的选择就是使用DDPG之类的RL算法,在本文中作者们使用了TD3来优化policy,在优化稳定性和数据效率里找到一个平衡点。
Discussion
在使用上述方法后,physical intelligence展示了这样子设计训练的policy会让很多manipulation task的执行速度和成功率上升。这个也不出意外,在做良好的工程infra的前提下,这个提升是可以预见的。
接下来聊聊我对这些工作的感受。
在很多实际问题中,人类的解题方式大致可以分为三类:显式求解、优化方法,以及数据驱动方法。
它们本质上并不是对立的,而是一个连续谱。当前很多人对 VLA模型的不信任,很大程度来自其黑箱性——你很难预期它在复杂环境下会输出什么,这种不确定性在真实系统中是有风险的。
但如果换一个视角,其实大多数问题都可以统一为优化问题:无论是语言模型隐式最大化某种 reward,还是控制任务中的轨迹规划,本质都是在寻找最优解。因此,一个自然的思路是让 VLA 模型负责生成一个“初始解”,再通过优化过程进行 refinement,从而兼顾表达能力与可控性。
但这个思路的核心瓶颈在于:优化必须依赖环境,而 VLA 模型处理的是高度非结构化输入(图像、视频、语言),传统 solver 很难直接作用其上。
现实中只有两条路:要么在真实环境中做优化(例如基于 RL 的在线交互),要么构建足够精确的模拟器(例如 video world model)来承载优化过程。问题于是被转化为一个更基础的挑战:我们是否能够建立一个既高保真又可计算的“世界模型”。
这里也有一个常见的认知偏差:很多人习惯性地把显式方法和优化方法称为“rule-based”,甚至带有贬义,但这种说法其实并不准确。Richard Sutton 在 The Bitter Lesson 中强调的是避免过多依赖人为先验,而不是否定建模与优化本身。
事实上,很多所谓的“prior”并非拍脑袋设计,而是来自对问题结构的深刻理解。没有牛顿力学与控制理论,也就不会有 Apollo 11 Moon Landing 这样的工程实践;但反过来,在复杂系统中执着于完全解析建模,同样可能效率低下甚至不可行。
更合理的视角或许是:不同方法各自解决问题的不同侧面。数据驱动方法擅长处理高维感知,优化方法提供稳定性与约束,而显式建模则带来结构与可解释性。关键不在于选择哪一种范式,而在于是否真正理解问题,并据此做出建模与方法上的取舍。
换句话说,工具本身不重要,重要的是如何使用它们。当前一个值得关注的方向,是利用大规模视频数据去弥合 2D 感知与 3D 世界之间的鸿沟,并在此基础上构建更合理的优化与学习体系——这可能是让 VLA 从“看起来很强”走向“真正可用”的关键一步。