作者:梦落花
https://zhuanlan.zhihu.com/p/2017560172977992865
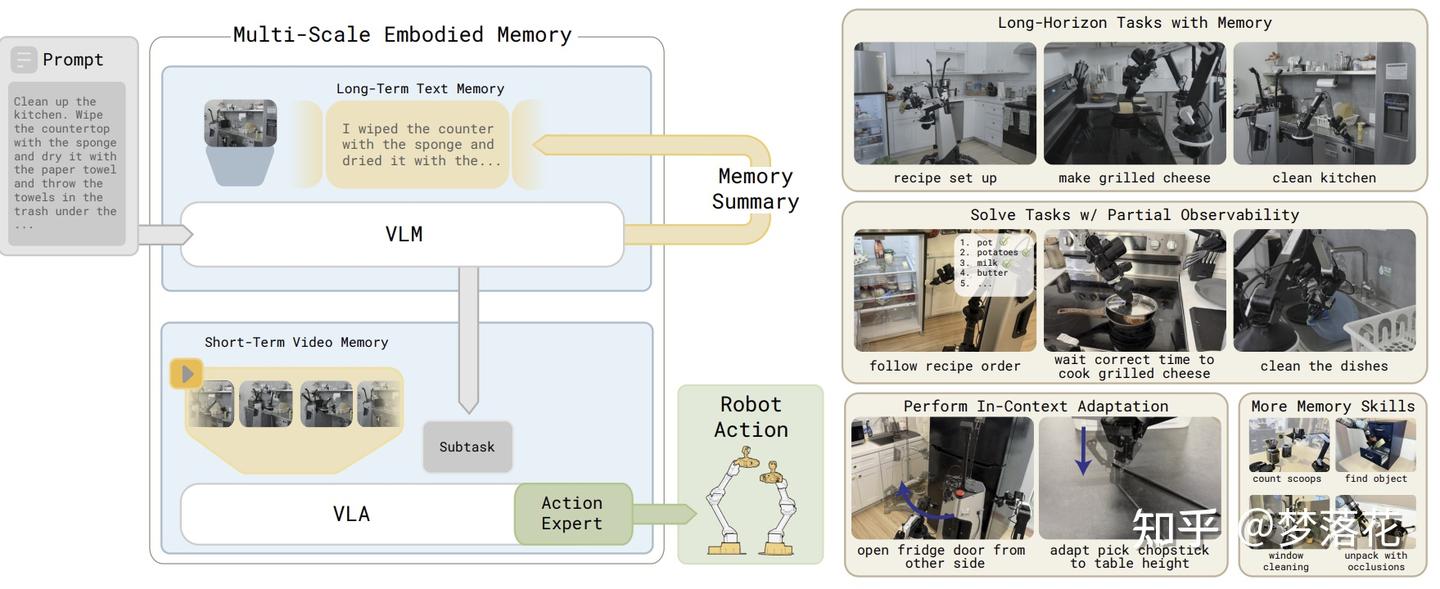
为什么vla需要有记忆?
机器人在运动过程中视线被遮挡时,需要从未被遮挡的历史数据中推断出物品真实位置;而机器人在做饭时需要记住它过去加了哪些食材,顺序是怎么样的。
本文通过这两个例子引出了长短期记忆的重要性,并提出了符合直觉的设计——对于长期记忆,使用文本信息,因为语言能有效地压缩信息;对于短期记忆,使用视觉信息,提供更具体直观的信息来指导动作。
那么,具体应该如何实现呢?
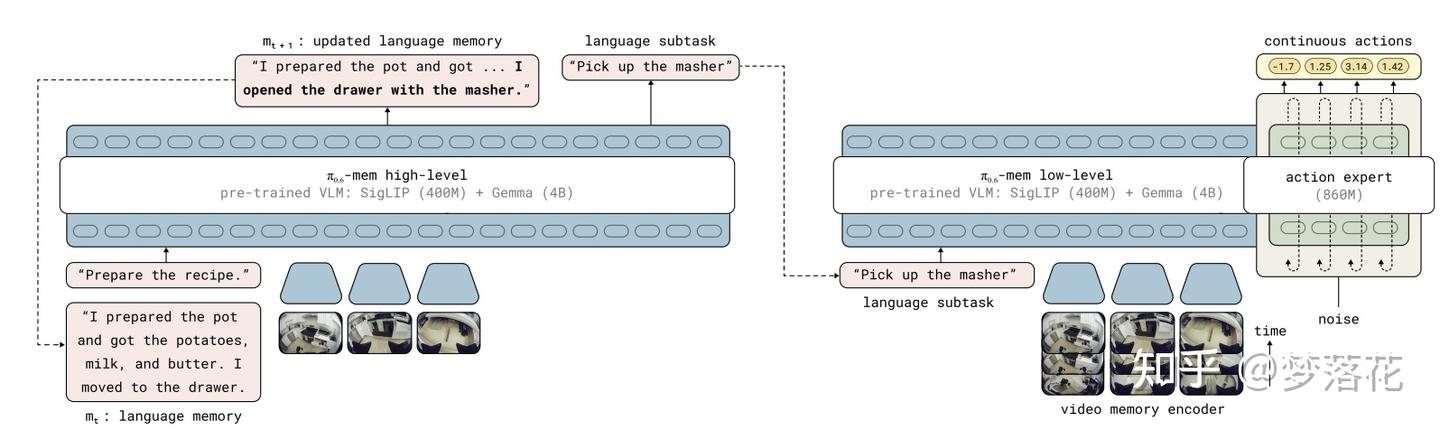
我们先来看比较简单的长期记忆部分,这里的记忆是靠自然语言来实现的,主要思想就是从历史记忆、文本指令、当前状态推断出一个压缩的自然语言总结,用来表示记忆。这个过程可以用以下公式表示
注意这里的 g 代表着全局的任务目标(global),而 l 代表子任务的文本指令,它们都是自然语言。这里就是在\pi_{0.5}所提出的预测子任务的基础上,加上预测下一段记忆 m_{t+1} 的功能。
对应训练数据的构造由llm完成,要求生成的记忆 m 尽可能精简,不包含具体的物品、动作细节,只描述结果。
接下来看短期记忆部分,这一部分会稍微复杂一点,涉及到了对模型结构的改造。
在短期记忆部分,既然已经确定要使用视觉数据,一个比较直观的想法是直接把过去的图像一个个地传递给vla,但这会使推理耗时随着帧数的升高越来越长,在长程任务中完全不可行。
于是,本文使用了一个视觉编码器来进行压缩,用于将历史的视频压缩为单个帧。它是ViT的一个变体,在每 4 层 ViT 后修改该层的注意力机制,不仅对同一帧内的不同patch进行双向的注意力机制融合(传统ViT的做法,利用空间上下文)还对K个历史帧的同一patch进行因果注意力机制融合(利用时间上下文)
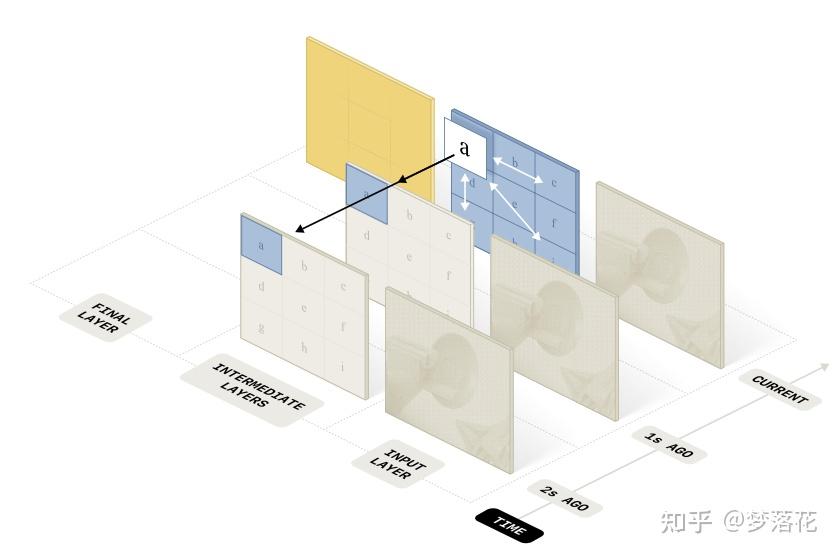
相比于改造ViT的每一层,这样做的时间复杂度低了很多,从 O(n^2 K^2) 降低到了 O(K n^2 + n K^2) 。经过这个编码器后,会丢弃所有的历史帧,仅传递当前帧(通过注意力机制融合了历史帧,实现了“记忆”)。这样的方法能够有效减少推理耗时。
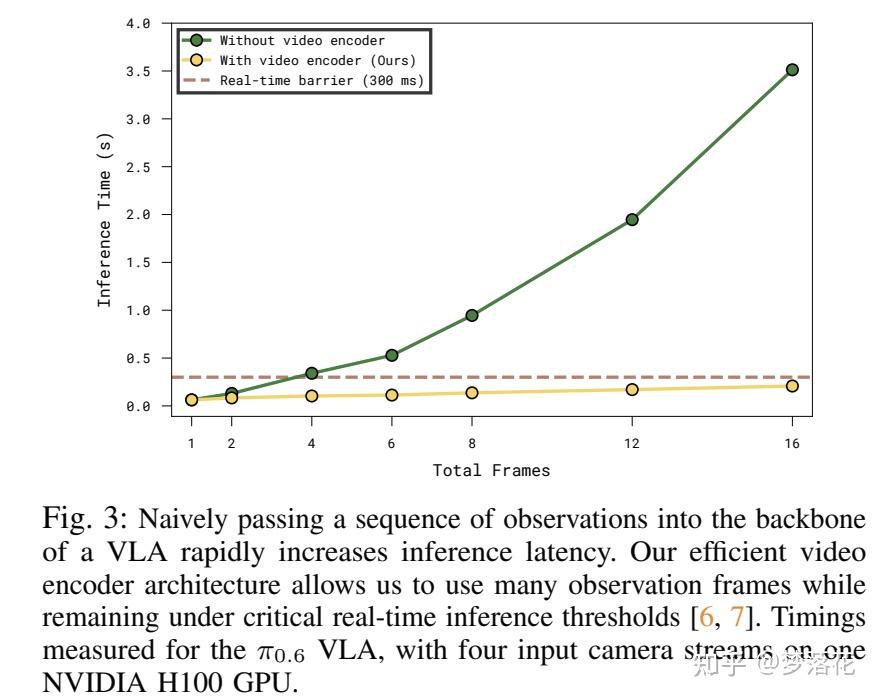
接下来,我们看如何在vla模型中使用MEM机制,以 \pi_{0.6} 为例。原本的 \pi_{0.6} 和 \pi_{0.5} 一样,把状态state(关节角)中的每一维作为token放在文本输入里,但这样在实现记忆时会使得文本输入变得特别长。
于是这里稍微改变了一下,将state先映射到vlm基座的嵌入空间中,再转换为token,这样历史的状态信息只会包含K个状态token。
模型的预训练过程没有太多变化,在原有的预训练基础上,使用当前帧和过去5帧(K=5)的observation进行训练,这几帧每帧间隔1秒。
在后训练阶段,本文发现,可以灵活地调整这个K值(最多可以覆盖54秒的历史),这与Extending context window of large language models via positional interpolation一文的发现类似。
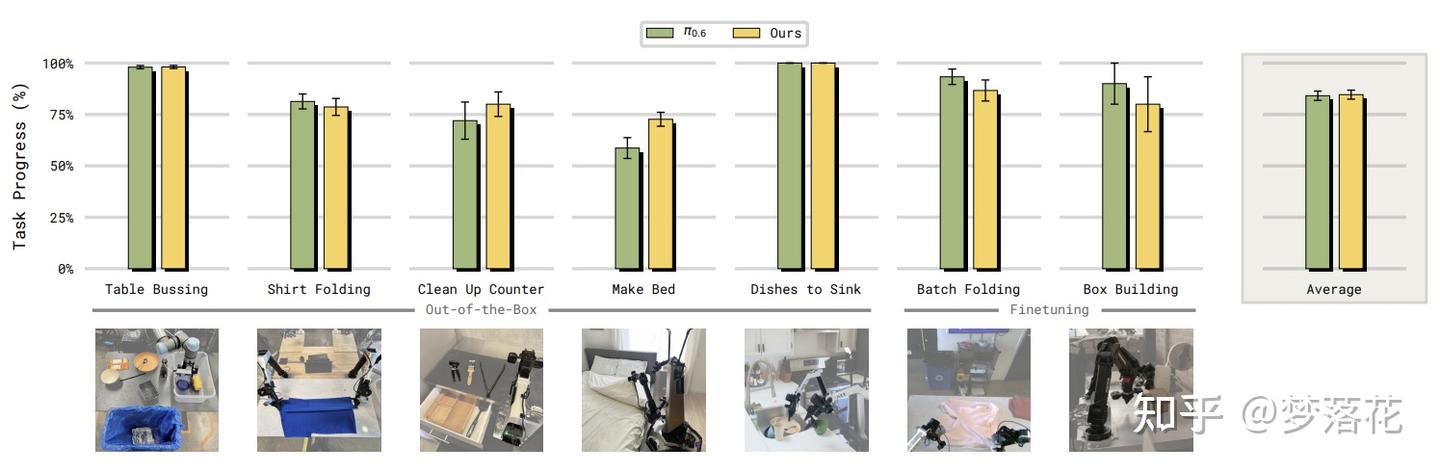
后续通过真机实验,证明了MEM机制可以有效提高vla的性能,并且长期记忆和短期记忆缺一不可。
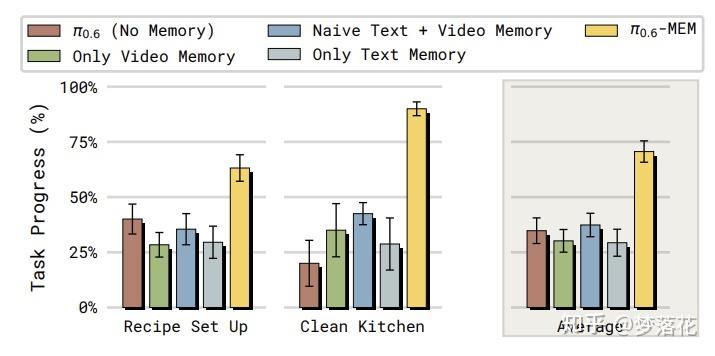
其中的Naive Text的版本不对长期记忆的文本进行压缩,而是单纯将之前的子任务的prompt拼接起来。有意思的一点是,它的表现显著比经过压缩的方法(即MEM)要差。
本文的解释是,在训练时,子任务指令往往只会产生一次;而在推理时,如果一个子任务没有完成,相应的子任务指令会反复生成,导致训练和推理时的记忆不同,产生了分布偏移。
而MEM在子任务失败时不会更新对应的记忆,避免了分布偏移。(个人认为,影响性能的关键不是压缩,而是是否更新记忆,这里naive的方式并不通过当前的状态去更新记忆,因而导致了“记忆混乱”的问题)
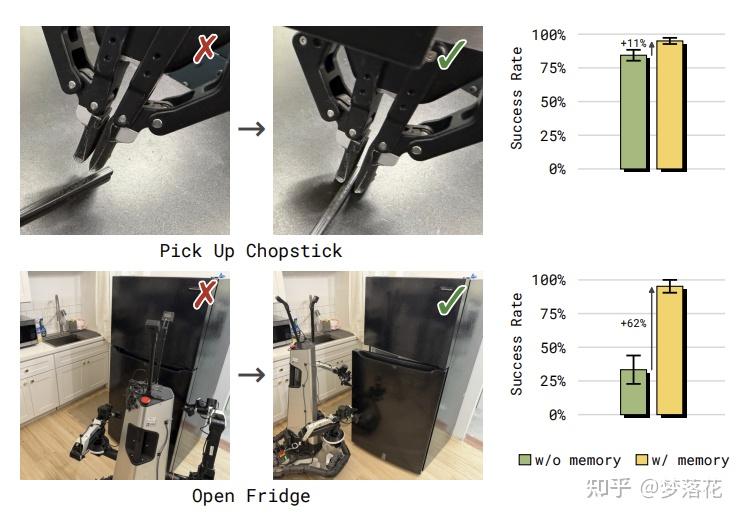
通过消融实验,证明记忆机制可以增强vla的性能,让vla学会“试错”,而不是重复相同的运动轨迹。在打开冰箱的任务中,这一点尤其明显,模型在发现一边开不了之后就会尝试打开另一边。
本文还比较了MEM机制和其他记忆机制,为了确保公平性,这里都没有使用长期记忆,而是仅实现短期记忆。
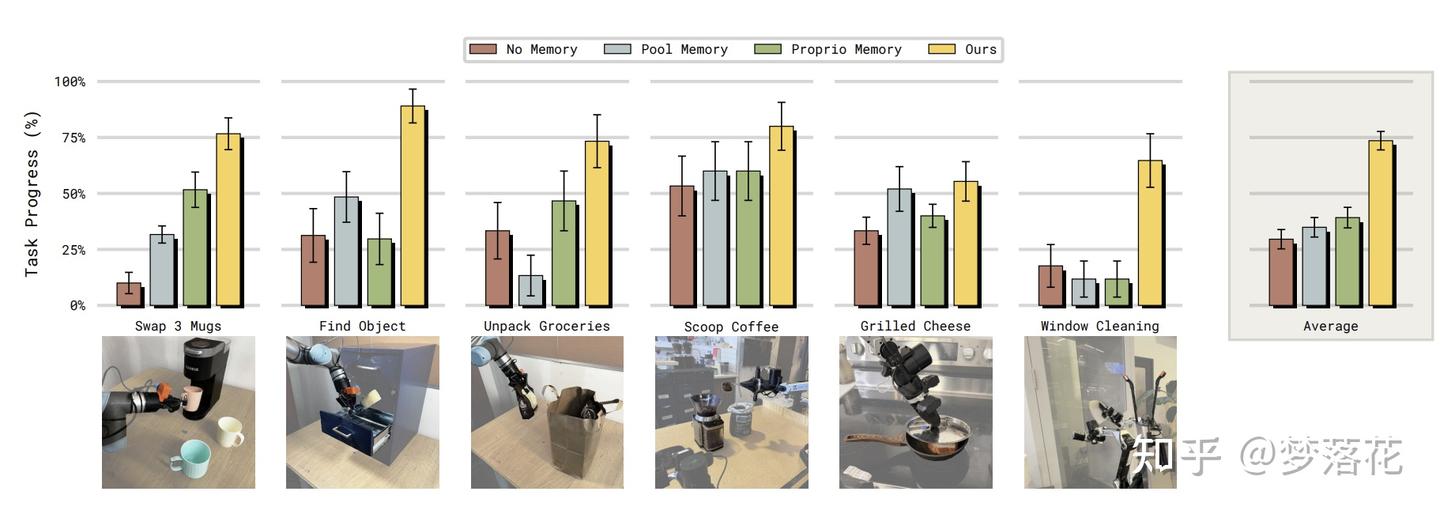
其中,Pool Memory将所有的历史帧通过ViT编码,再进行平均池化,得到一个"memory token",再将它和经过ViT编码的当前帧一起送入VLA主干。
Proprio Memory只使用了机器的状态信息,所有的历史状态信息经过线性投影,再送入VLA主干。
在直觉上比较好理解,Pool Memory的方式太粗暴,平均池化会丢失掉历史帧中关键的信息;
而Proprio Memory只考虑机器的状态信息完全无法应对遮挡等问题,模型难以理解为什么会出错(状态信息只告诉了模型自己怎么运动过来的,不会告诉模型这里视线被挡住/物品从这边打不开)。
而这个对比也印证了本文的另一个结论,不适当的记忆机制会导致模型的性能不升反降。
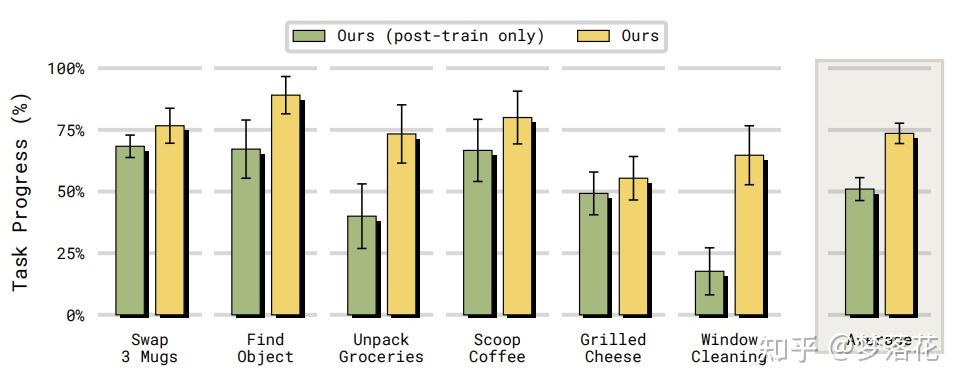
本文同时还证明了,即使在不需要记忆的任务中,带有MEM机制的模型也和原本的模型有着相当的表现。这个也有点意思,说明记忆其实并不总是更好的,它在有的任务上反而导致了性能下降,未来这个记忆机制应该还有很大的优化空间。