作者:李煜东 Yudong
https://zhuanlan.zhihu.com/p/2032080549381190858
写在前面:
LLM 研究的关注重心正在这几年内不断转移,从post train到强化学习再到agentic/harness工作流。这些都体现了技术前沿和社区焦点的演进。对于用户而言,基座模型与LLM使用之间的链路变得越来越长,预训练似乎已不再是最受关注的 LLM 研究话题。
但是我们认为,预训练仍然值得研究,不仅因为它是模型能力形成的基础,一些关键问题也尚未回答,例如数据如何驱动智能,知识如何从大规模语料中涌现。这也是一项需要耐心、经验以及对数据具有 taste 的长期工作。
同时,我们发现近年来技术报告对数据工程细节的披露日益减少,模型预训练是一个重实践经验的方向,要判断哪些做法真正有效,研究的开放性至关重要。大模型研究需要集体智慧,也需要来自真实训练的经验共享,才能推动社区形成更可靠的判断。
这也是我们撰写这篇综述的动机,我们从有限披露的信息和可交叉验证的证据中整理线索,尽可能复原工业级 LLM 预训练数据工程的关键实践。
我们希望这篇综述能够为感兴趣的研究者提供进入该领域的清晰路径,也为本领域的研究者提供关于数据构建、工程取舍与未来研究方向的有价值参考。
本文对原文进行了精简,详细引用和高清图片请参考原文:
https://github.com/ydli-ai/ydli-ai.github.io/blob/main/assets/papers/LLM_pretrain_data_survey_zh.pdf
1. 引言
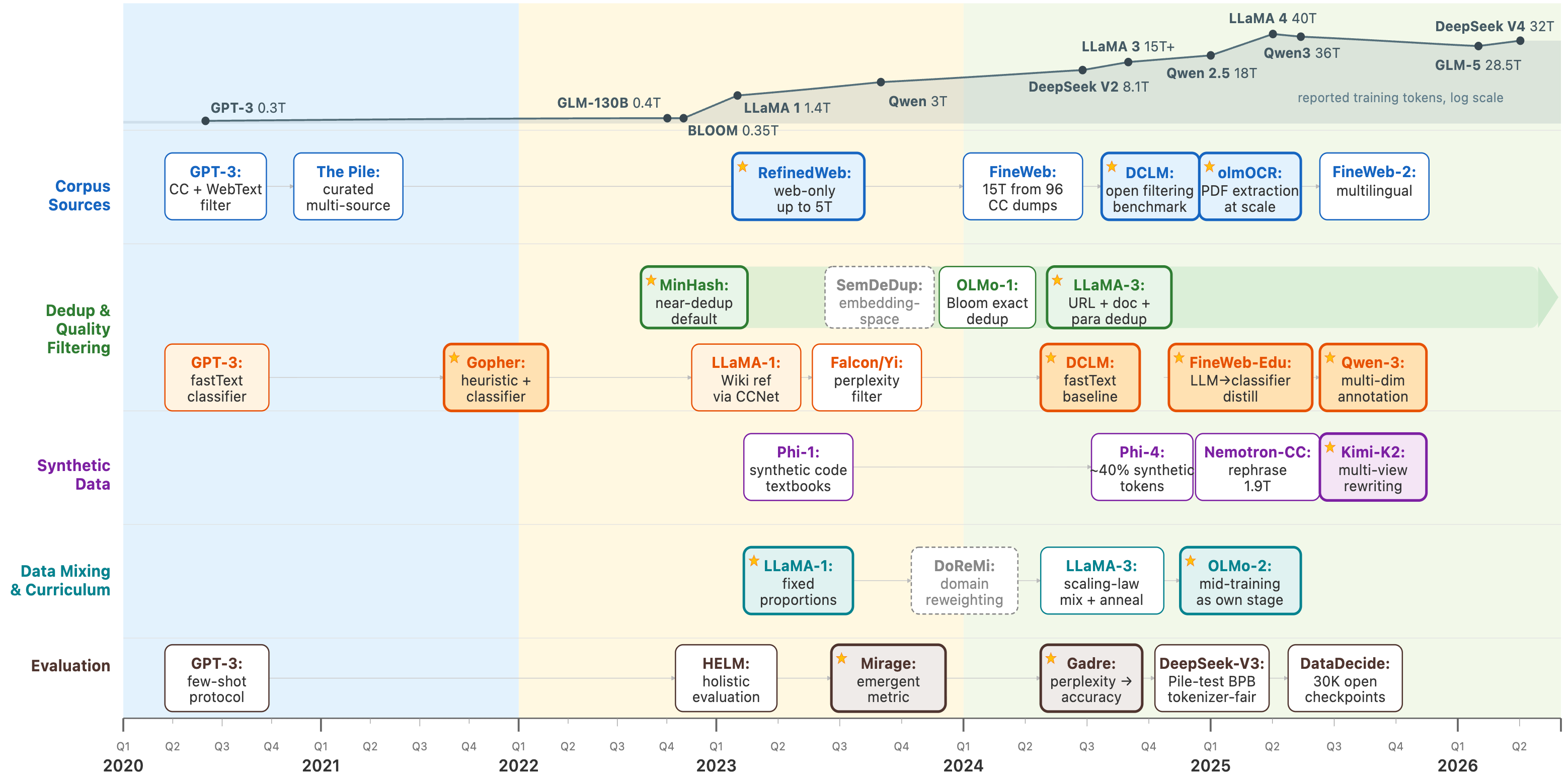
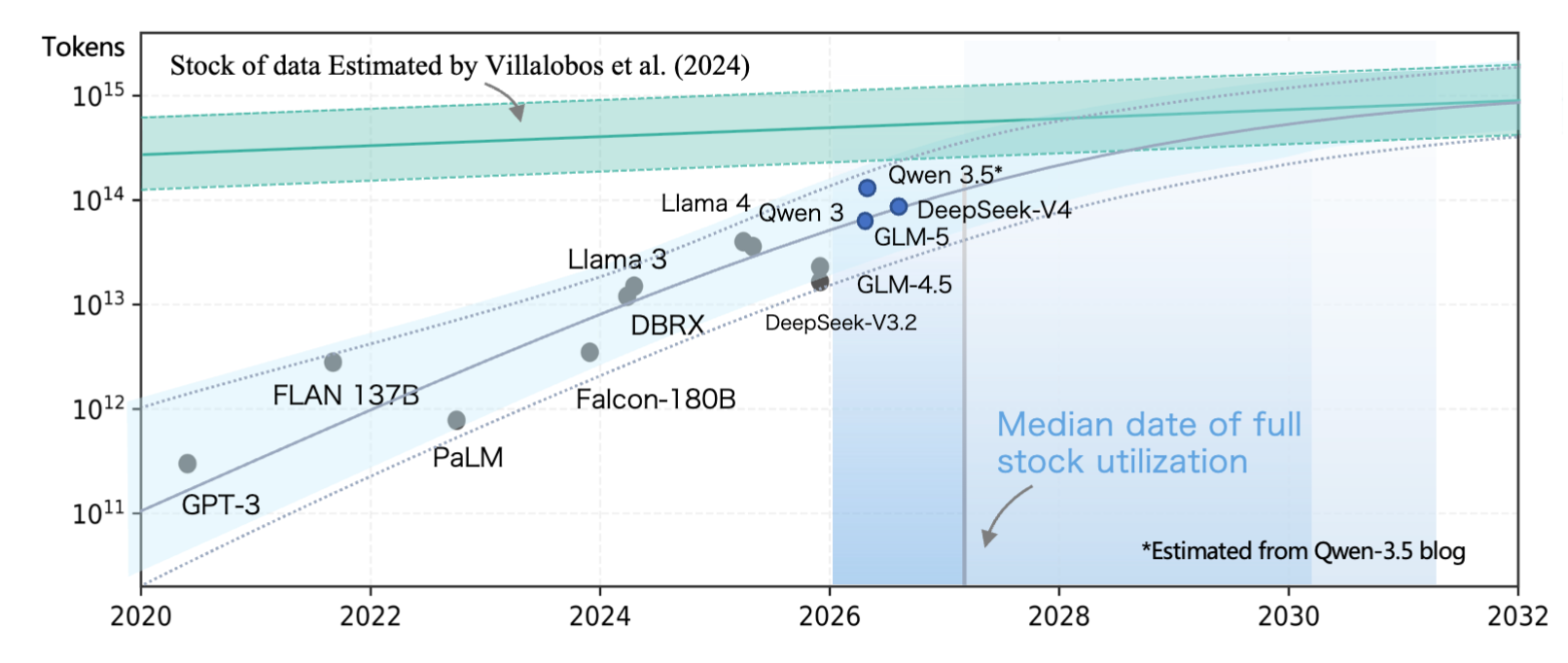
预训练语料的规模在数年内增长了近四个数量级。2020 年 GPT-3 使用约 300B token,至 2024 年 DeepSeek~V3 提升至 14.8T token,LLaMA~3 使用 15.6T token。2025 年的 Qwen~3和 2026 年发布的 GLM-5 、DeepSeek~V4 进一步攀升至 30–40T token 量级。
然而,这一路线正遭遇数据供给瓶颈。当前主流预训练数据集仍高度依赖以 CommonCrawl 为代表的开放网页资源,而其中的高质量内容增量已经放缓,重复与噪声占比持续上升。
Villalobos(2024) 估算了人类产生高质量文本的总量与大模型消耗速率,预测高质量文本将在 2026 至 2032 年间耗尽。在数据增量趋缓的条件下持续提升知识获取效率,已成为预训练研究的关键问题。
面对这一供需矛盾,预训练数据工程,即对训练语料的获取、清洗、筛选、配比与调度,正成为决定模型能力的核心变量。RefinedWeb 证明经过去重和过滤的纯网页数据可以超越多源精选语料。
FineWeb-Edu 和 DCLM 进一步通过更优的过滤策略,在相同计算预算下将模型性能提升至数倍等效数据量的水平。在架构与算力相近的前提下,数据处理质量已成为区分前沿模型的关键因素。
更重要的是,数据问题并不只是供给不足,也在于已有语料尚未被充分转化为模型能力。人类个体一生中接触的文本量远少于当前 LLM 所消耗的数据规模,却能发展出健全的概念体系与推理能力。
这一反差表明,现有预训练范式仍有大量信息利用提升空间。预训练研究的重心因此正从单纯扩大数据规模,转向更高效地利用数据。
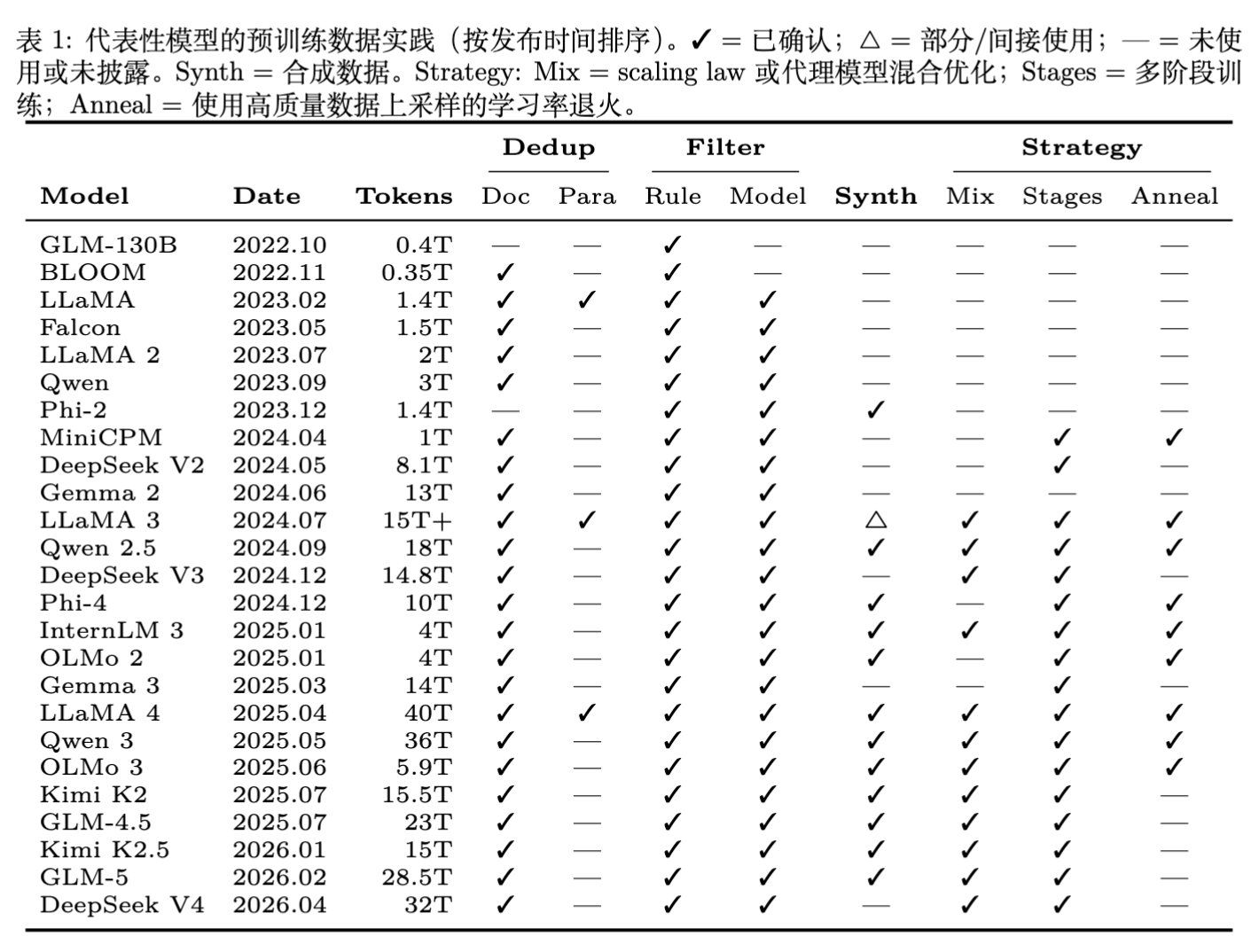
本文聚焦于预训练阶段的数据方法如何影响模型数据效率,并以经大规模训练验证的共识与最佳实践为组织主线。我们以前沿模型的公开技术报告(涵盖 2020 至 2026 年发布的 GPT、LLaMA、Qwen、DeepSeek、Kimi、GLM、OLMo、Phi 等系列)为一手证据,提炼数据工程的通用流程,比较各阶段的方法选择,并标注具有潜力但尚未被规模化验证的新方向。
本文目标是追踪技术共识的演变脉络,并提供一份持续更新的大模型数据工程最佳实践指南。
2. 预训练数据工程技术趋势
2.1 数据规模持续增长
语料规模仍在扩张,但多个独立证据表明,数据处理和课程设计带来的收益已可与规模扩张相当。数据效率正从辅助指标上升为预训练的核心优化目标。
Scaling law 之后,前沿模型的训练数据量持续增长,远超计算最优比例。与此同时,RefinedWeb、FineWeb-Edu 和 DCLM 的实验表明,在相同计算预算下更优的过滤流程可带来数倍等效数据量的性能提升。现有的数据筛选工作大多以逼近既有模型能力为目标,在需要突破已有能力上限的场景下,高效小数据集能否持续优于大规模语料,尚缺乏验证。
规模和效率并非替代关系,而是共同决定模型能力的两个维度。
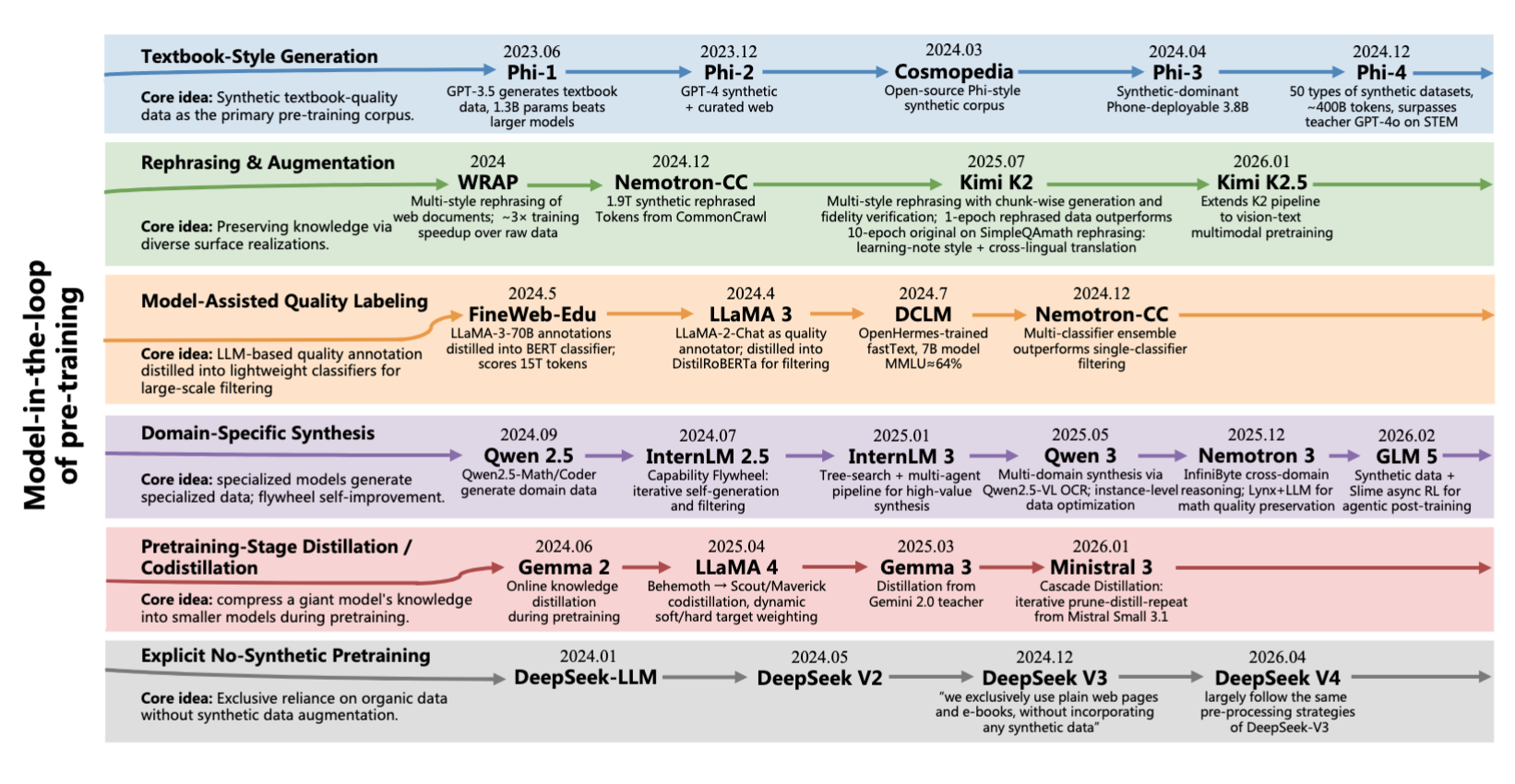
2.2 合成数据已被多数前沿模型采纳
用天然数据控制分布,合成数据提升质量或补强特定领域。Qwen~3、Phi-4、Kimi~K2 是典型代表,DeepSeek~V3 是唯一明确排除合成预训练数据的主流模型。
2023 年 Phi-1 率先在预训练中使用合成数据,至 2025 年多数前沿模型已采用合成数据。在生成方式上各团队选择差异显著,包括重新生成教科书式内容、对已有文本进行风格重述、使用专用模型合成领域数据。合成数据在迭代训练中引发分布收窄和模型坍缩的风险已被理论证明,但尚未在超大规模预训练中被实证评估。
2.3 预训练已细分为多阶段训练
预训练阶段的数据调度正在不断细化,由单阶段固定配比,演变为包含 mid-training、退火等多个阶段的课程结构,逐步向为后训练的准备靠拢。但如何确定阶段边界、领域配比和切换时机,目前没有统一公认方案。
从 LLaMA 1 的固定数据比例,到 LLaMA 3 引入 scaling law 引导的配比搜索与退火阶段,再到 Qwen 3 的三阶段训练,预训练数据投喂从静态配置演变为课程设计。多阶段训练也在 DeepSeek V3/4、Kimi K2 和 GLM-5 中出现。
学术界提出了更精细的领域配比优化方法 (DoReMi,RegMix,DataMixingLaws),但在小规模实验与大规模训练之间的可迁移性尚未验证。公开的工业实践仍采用三到四个粗粒度阶段,而非更细的动态调度。
2.4 数据工程的披露正在减少
开放权重意味着模型架构和参数不可避免地公开,而训练数据的来源、分布和处理细节仍可保留。数据工程因此成为不同模型之间性能差异的核心来源,也是披露最少的环节。
一个明显趋势是,随着模型能力增强和商业价值提高,技术报告中关于预训练数据的披露细节在持续减少。早期报告(如 LLaMA 1、Qwen 1)公开了数据来源比例与具体处理方法。最近的报告在数据细节上的披露大幅减少,Qwen 3 对去重只字未提,LLaMA 4 甚至未发布技术报告。
Kimi K2 提供了一种折中方案,详细披露合成数据管线的方法论,但对数据源与分布保持模糊。Mistral 系列处于另一端,Mistral 7B 、Mixtral 8x7B 以及后续模型几乎不披露任何预训练数据细节。逆流之中,OLMo 系列和 Nemotron-CC 仍坚持完全开放数据、代码和处理流程,为可复现研究提供参照。
透明度的下降说明数据工程已成为预训练的核心竞争环节,这也决定了本综述的调研方式。本文不依赖单篇报告的描述,而是从大量部分披露的证据中交叉验证,提炼重复出现的做法与存在的差异。
3. 语料库构建
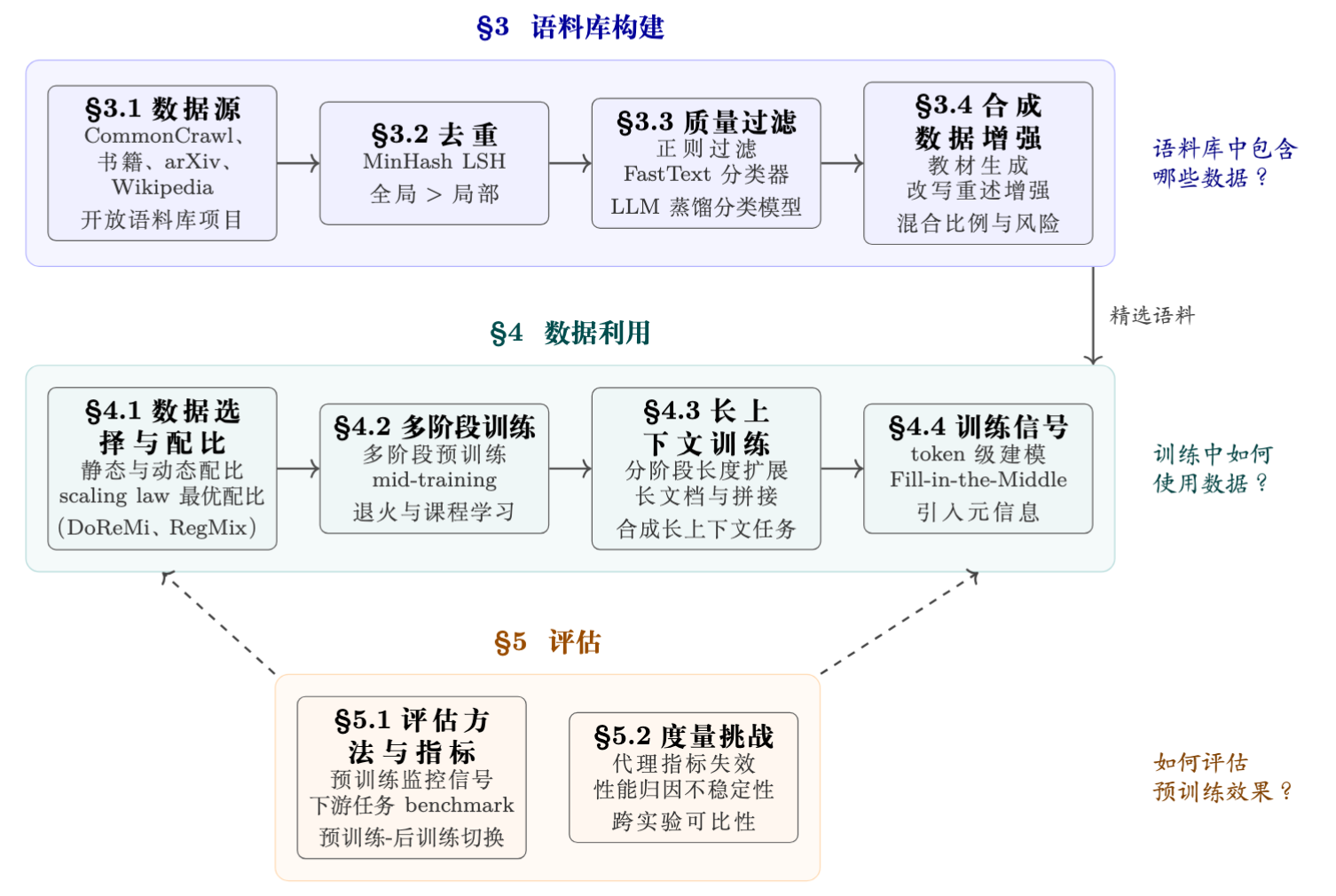
本章涵盖预训练语料库的构建过程。我们首先综述可用的数据来源与开放语料库项目,随后讨论三个核心处理步骤,包括去重、质量过滤、和合成数据增强。
3.1 预训练数据源和公开语料集
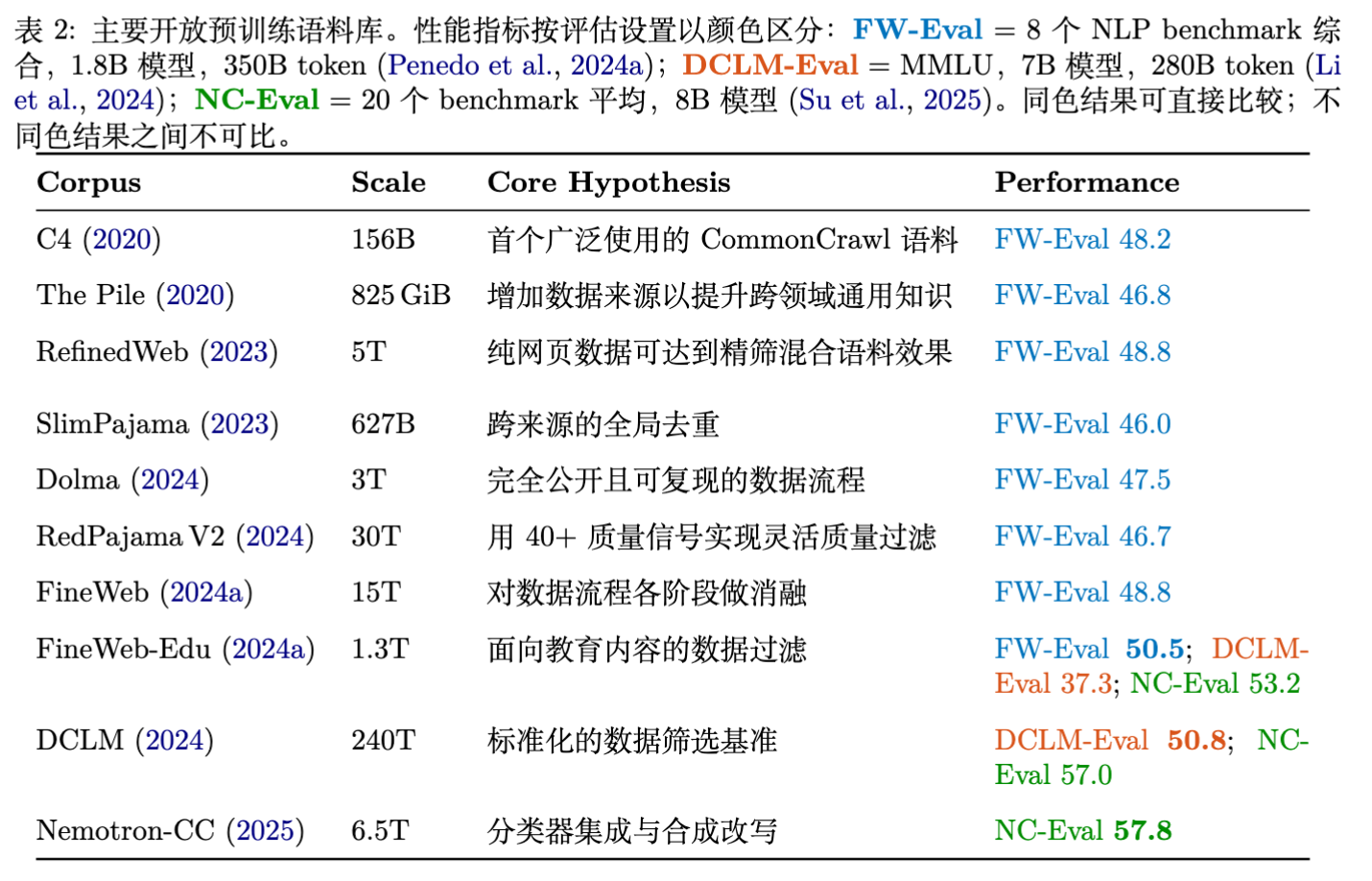
在 BERT 时期(2019–2022 年),预训练数据集的标准做法是混合多种精选来源。The Pile 汇聚了 22 个英文数据源共约 800GB,CLUECorpus2020汇总了 100GB 中文语料,C4 则是最早被广泛使用的 CommonCrawl 过滤流程。
这种多源混合策略在数据需求为数百 GB 到数 TB 时是可行的,但难以支撑后续训练规模的增长。CommonCrawl 每月发布一次网络爬取快照,完整存档跨越十余年,包含数千亿个页面,是目前唯一提供 T token 量级原始文本的公开数据源。
原始网络爬取数据噪声极大,含有大量 HTML 样板代码、广告、近重复页面和机器生成文本,需经多阶段处理才能用于训练。RefinedWeb 首次证明仅经过去重和过滤的 CommonCrawl 即可超越多源混合语料。此后 FineWeb、DCLM 、Dolma 和 Nemotron-CC 进一步验证了这一路线。
如今前沿模型均以处理后的网络爬取数据作为主要来源。
除网页外,代码仓库(GitHub、StackOverflow)、科学文献(arXiv、PubMed)、书籍和百科(Wikipedia)等领域来源也被广泛使用。这些内容在 CommonCrawl 中虽有覆盖,但领域来源受益于同行评审与编辑审核,提供更干净且更结构化的数据。领域数据仅占训练 token 总量的一小部分,却显著影响数学推理与代码生成等能力。
从原始领域数据源构建可用语料涉及爬取、清洗、去重、过滤等完整流程,工程成本高。为降低复现门槛,社区开发了一系列开放语料库,将原始数据转化为可直接使用的训练语料。
互联网爬取并不是高质量内容的唯一入口。教科书、学术论文与纸质书等信息密度较高的文本主要以 PDF 或扫描图像形式存在,传统 OCR 在公式、表格、多栏排版与历史版面上的失误率使其难以直接产出可训练 token。Nougat用端到端 transformer 识别学术 PDF 中的公式与文档结构。MinerU 同时覆盖电子 PDF 与扫描件,支持多语言与多布局。
olmOCR 用一个微调过的 7B VLM 作 page-level 转写,将版面理解与字符识别合并为单一过程,对纸质书与档案资料的恢复质量明显高于 Tesseract 等传统 OCR 流水线。OLMo~3 用 olmOCR 抽取学术与书籍内容并在 mid-training 阶段补充合成 QA,Nemotron 与 Qwen 团队也在技术报告中提及自建 PDF 与扫描解析栈但未公布细节。这一类数据补充了网页中稀缺的长文本数据源。
3.2 去重
去重从训练语料库中移除冗余内容,是所有前沿模型一致采用的预处理步骤。网络爬取中的重复有两个主要来源。一是跨页面冗余,即不同 URL 托管相同或近似的内容。二是时序冗余,即同一页面在每月快照中被重复爬取。这两类冗余高度集中,少数页面被重复数千次,而大多数页面仅出现一次。
重复数据会降低训练效率:Hernandez(2022) 发现仅将 0.1% 的数据重复 100 次,就会使一个 8 亿参数模型的有效容量降至 4 亿参数模型的水平,浪费约一半的训练计算量。
不过,在高质量新数据受限时,重复仍有价值。Muennighoff(2023) 发现重复训练少量 epoch 可以继续提升性能,但收益会很快下降。Carlini(2023)进一步表明,模型逐字复现某训练序列的概率与该序列出现次数呈对数线性增长,因此高频重复还会放大记忆和隐私风险。
去重方法分为精确匹配和模糊匹配两类,实践中通常叠加使用。精确去重通过文档级哈希(如 SHA-256)或 URL 比对移除内容完全相同的文档。OLMo 1通过 Dolma 流程使用 Bloom filter 实现概率性精确去重,以较低的内存成本处理大规模语料。
模糊去重针对仅有细微编辑差异的近重复文档,基于局部敏感哈希(LSH)的 MinHash 是最主流的算法,被 LLaMA、Qwen、DeepSeek、InternLM 等前沿模型采用。MinHash/LSH 的核心优势在于内存占用呈亚线性增长,能够在万亿 token 规模的语料库上保持可行性。
所有模型都采用文档级去重,但在更细粒度上存在差异。LLaMA 3 在三个层级执行去重:URL 级、文档级 MinHash 和行级,从完全重复的页面到导航菜单等样板片段均有覆盖。
DeepSeek V2 跨不同时期的 CommonCrawl 快照应用 MinHash(跨快照去重),专门消除重复爬取同一页面产生的时序冗余,DeepSeek V3 和 V4 沿用了相同做法。
InternLM 2 针对代码增加了领域特定去重,使用仓库级拓扑排序保持文件依赖关系,并公开了具体的 MinHash 超参数(128 个哈希函数、5-gram、Jaccard 阈值 0.7)作为参考配置。
去重的一个潜在风险是过度移除。在大量独立撰写的文档中频繁出现的知识(如常见事实和惯用表达)也可能被模糊匹配捕获,导致对常见话题的自然覆盖被误删。
更深层的问题在于,知识在网络中出现的频率本身可能携带信号,高频内容往往是基础性的、被广泛引用的事实,去重在消除冗余的同时也抹去了这种隐含的重要性权重。目前缺乏将爬取冗余与知识频率信号加以区分的方法,核心困难在于没有 ground truth 也没有公认的标注标准。
在实践中,去重的激进程度仍依赖经验调参,此外往往不可避免地重复使用高质量数据来提升性能。这说明适度重复高质量数据的收益仍大于其风险,也凸显了高质量数据在预训练中的稀缺性。
3.3 质量过滤
质量过滤从训练语料库中移除低质量文档。现有流程通常叠加两类方法,启发式规则负责粗粒度移除,分类器负责精细选择。
规则是最基础的过滤手段。Gopher 规则 对文档长度、词数比例和符号密度设定阈值,被大多数开放语料库和模型作为最低过滤基线。部分流程还加入 perplexity 过滤,用在高质量参考文本上训练的语言模型对文档打分,移除统计异常值。Yi 和 Falcon 都采用了基于 perplexity 的过滤。
分类器过滤的基本思路是训练一个轻量分类器区分高质量正样本与随机网络文本,再将其应用于整个语料库。各方法的核心差异在于如何定义正样本。
GPT-3 以 Reddit 链接页面作为正样本训练 fastText 分类器。LLaMA~1 \citep{llama1} 通过 CCNet 流程以 Wikipedia 作为正样本参考。LLaMA~3 改用 LLaMA~2 生成的质量标签训练 DistilRoBERTa 分类器。
DCLM \citep{li2024dclm} 在 OpenHermes 指令数据上训练 fastText 分类器,7B 模型在 DCLM 过滤数据上达到 MMLU 64\%,相比 LLaMA~3 节省约 6× 计算量。
FineWeb-Edu \citep{fineweb} 引入两阶段方法,先用 Llama-3-70B-Instruct 对 50 万个样本标注教育质量分数,再将标签蒸馏为 BERT 分类器用于规模化部署。这种``强 LLM 标注、轻量分类器部署''的模式已被 Nemotron-CC 与 Qwen~3 沿用。
Nemotron-CC \citep{su2024nemotron} 集成 Mixtral、Nemotron-340B 与 fastText 三个分类器,效果优于任一单一分类器。Qwen~3 进一步将标量质量打分扩展为多维标注,对超过 30T token 沿教育价值、领域等维度标注,再用这些细粒度标签在实例级优化数据混合。
分类器方法的共同优势在于推理成本低,fastText 或 BERT 分类器一旦训练完成,处理数十亿文档的成本相比生成训练标签的 LLM 几乎可以忽略。
现有质量过滤方法存在一个根本局限,即「质量」的定义本身依赖于风格。以 Wikipedia 风格文本训练的分类器偏好百科式写作,以教育内容训练的分类器偏好教科书式表述,两者都会移除其他非正式但信息密度高的文本。
DeepSeek 在实践中发现 V1 过于激进的过滤降低了知识密集型任务的性能,在 V2 中放宽了阈值。Yi 以严格标准精选 3T token 而非宽松过滤 10T token,但这种选择性本身反映了特定的质量判断,并非适用于所有任务。
3.4 合成数据增强
合成数据由现有 LLM 生成,用于在自然高质量文本不足时扩充训练池。前沿模型在合成数据的使用程度上差异显著。DeepSeek V3 的预训练语料库不含合成数据,完全依赖网页与电子书。Phi-4 处于另一极端,合成数据占其预训练数据的 40 %。多数模型介于两者之间。
Phi 系列是最早将合成数据大规模用于预训练的工作。2023 年 Phi-1 使用 GPT-3.5 生成教科书风格数据,此后 Phi 系列以合成数据为核心特征,Phi-4 使用超过 50 类合成数据集共约 400B token。Phi 方案在 140 亿参数以上的有效性尚缺乏验证。其他模型将合成数据的主流用途转向数学与代码等领域。
Qwen~2.5 用专项模型(Qwen2.5-Math、Qwen2.5-Coder)生成合成数学与代码数据。Qwen 3 将做法扩展至数十个领域,用上一代模型以教科书、问答对与代码片段等格式合成数T token。这种 「每一代为下一代生成合成数据」 的迭代模式也被 InternLM 采用。
OLMo 3 遵循类似路径,用 olmOCR 从学术 PDF 中提取文本,并为 mid-training 阶段生成合成问答对。
除生成全新内容外,另一类做法是将已有文本改写为更利于训练的形式。Kimi K2 以多种风格和视角改写源文档,将数学内容转换为学习笔记格式,并通过跨语言翻译增加多样性,每个源文档最多改写两次以限制冗余。Kimi K2 在 SimpleQA 上验证了改写优于在原始文本上重复训练。
Nemotron-CC 在更大规模上应用改写,从 CommonCrawl 生成 1.9T token,并对不同质量层级采用不同策略,低质量文档改写为 Wikipedia 风格以降噪,高质量文档转化为问答对、摘要与知识列表以生成新的独特 token。这些改写方法的共同特点是 LLM 仅用作风格转换而非知识来源,从而避免引入生成模型自身的分布偏差。
合成数据的有效性取决于与自然数据的混合比例。 Kang (2025) 训练了超过 1000 个 LLM,发现纯合成数据并不优于 CommonCrawl,而三分之一合成、三分之二自然数据的混合可将训练效率提升 5–10 倍。一个相关风险是模型坍缩,即在模型生成数据上迭代训练会导致不可逆的分布多样性损失。即便是 Phi-4 和 Qwen 3 也始终将合成数据作为自然文本的补充而非替代。
4. 数据利用
4.1 数据选择与配比
早期模型采用人工设定的静态配比,通常基于数据源规模或经验判断。LLaMA 1 公布了具体的域配比方案(CommonCrawl 67 %、C4 15 %、GitHub 4.5 % 等),是后续模型的常见参考。BLOOM 、Falcon 和 PaLM 同样采用基于经验的固定配比。
PaLM 2 在此基础上提高了多语言与代码数据的比例,并按数据质量分层加权采样,是较早将非英文和领域数据明确写入混合配方的模型。OLMo 1 直接使用 Dolma 数据集的默认比例,未做配比搜索。这种方法实现简单且结果可复现,但配比之间的性能差异只能通过代价高昂的全规模训练验证。
固定配比的局限催生了利用 scaling law 在小规模上预测最优配比的方法论。核心思路是在小模型上系统尝试多组配比,拟合配比与性能之间的定量关系,再将预测的最优配比应用到大规模训练中。
LLaMA 3 报告了使用 scaling law 实验指导配比迭代优化的流程,并在训练过程中根据模型能力的变化动态调整各域权重。Qwen 2.5、Qwen~3 和 DeepSeek V3 都报告使用类似策略。
学术界对此方向提出了多个方案。DoReMi 用一个小型 proxy 模型配合 Group DRO 优化各域权重,在不增加数据量的情况下提升下游性能。Data Mixing Laws 将配比与 loss 之间的关系建模为解析函数,通过拟合少量实验点预测最优配比,声称可节省约 48 % 的训练步数。
RegMix 将配比优化转化为回归问题,仅需 DoReMi 约 10 % 的计算量即可获得相当的配比质量。BiMix 提出双变量混合定律,同时建模配比与训练 token 数量对 loss 的联合影响,在给定计算预算下预测最优的配比与数据量组合。
UtiliMax 将配比优化类比为投资组合优化(Markowitz 模型),利用 LLM 估计各领域数据效用,结合数据集规模约束求解最优分配。
上述方法依赖一个前提假设,即小规模实验得出的最优配比可以迁移到大规模训练。DataDecide 在三万多个 checkpoint 上的实验表明,150M 模型的相对排名在约 80 % 的情况下可迁移到更大规模,为这一假设提供了积极证据。
AutoScale 反向发现小规模最优配比在迁移到大规模时可能失效。BETR进一步揭示最优的过滤严格度随模型规模变化。这些发现对依赖小规模实验做决策的通行做法提出警示,但目前尚无替代方案,因为全规模消融实验的计算成本难以承受。
4.2 多阶段训练
预训练通过在不同阶段切换数据配比来分化训练目标,2024 年之后发布的前沿模型几乎都采用这一结构。基本逻辑是先用大规模通用数据建立基础语言能力,后续阶段用更精选的数据补强特定能力。Qwen 3 采用三阶段方案。S1 阶段使用约 30T token 覆盖 119 种语言与方言的通用世界知识。
S2 阶段消耗约 5T token,主要包括科学、代码、推理与合成数据,目标是提升推理能力。S3 阶段使用数百M token 的高质量长上下文数据将序列长度进一步扩展。GLM-5 与 DeepSeek V3 报告了类似的多阶段切换。LLaMA 3 在跨阶段过渡时同步调整 batch size 与学习率。
近期实践中,配比切换的中间阶段进一步独立为 mid-training,位于通用预训练与后训练之间。OLMo 2 与 OLMo 3 在通用预训练完成后单独划出 mid-training 阶段,向其中注入高质量数学、代码与问答数据来补强推理能力。InternLM 2.5 同样使用专门的 mid-training 阶段强化领域能力。Qwen~3 的 S2 阶段在性质上也属于这一范畴。
多阶段训练的最后通常包含一个退火(annealing)阶段,在训练末期降低学习率的同时将数据分布切换为高质量子集。LLaMA~3 报告退火阶段使 8B 模型在 GSM8K 上提升 24 个百分点,是单阶段最大的性能跳跃之一。
OLMo 3、Phi-4 和 Kimi K2 都在训练末期采用退火。MiniCPM 提出 WSD(Warmup-Stable-Decay)学习率调度,将退火从经验做法提升为可复用的训练范式,并在小规模模型上验证。Kairong 2025 发现学习率与数据质量存在交互效应,高质量数据在学习率较低时对参数的影响更持久,这为退火阶段切换高质量数据提供了一个解释。
GLM-4.5 反向指出 WSD 调度可能导致性能衰减,说明这一范式尚未达到普适。退火与 mid-training 的差异在于退火伴随学习率衰减,而 mid-training 通常在恒定或周期性学习率下持续数百B 至 1T token,目标更接近于补充能力而非为切换到后训练做准备。
多阶段训练的出现说明预训练正在分化为更多具有独立目标和评估方法的精细过程,也意味着预训练与后训练之间的边界正在变得模糊。
当前的多阶段训练在形式上与课程学习相似,两者都在训练过程中改变数据分布。课程学习的经典假设是按难度有序呈现数据可以提升学习效率,Zhang2025curriculum 的实验表明课程策略可减少 18–45 % 的训练步数。前沿模型的多阶段训练则主要按领域和目标能力划分阶段,并不遵循由易到难的顺序。
例如 S2 中常见的代码和推理数据并不只是因为「更难」,而是因为它们更接近下游任务 benchmark 与应用,目标是塑造模型的下游能力,而不只是提升预训练效率。
因此,严格意义上的课程学习策略尚未被前沿模型采纳,主要原因在于训练样本难度缺乏可跨任务、跨领域迁移的通用定义,因此难以在海量的异质语料上建立可靠的全局难度排序。
4.3 长上下文训练
长上下文训练把模型可处理的序列从数 K 扩展到 M 量级,已成为预训练后期的常规步骤。更长的上下文窗口直接影响长文档理解、代码仓库分析、多轮工具调用和 agentic 工作流,因为这些场景需要模型在单次推理中保留更长的任务状态。
LLaMA 3、DeepSeek V3/4、Qwen 3、Kimi K2/2.5 都将长上下文扩展放在基础预训练之后完成。这一阶段涉及两个独立问题:如何规划上下文长度的扩展,以及用什么数据填充扩展后的序列。
分阶段训练不同长度是最普遍的扩展方式。模型先在较短序列上使用大规模通用数据建立基础语言能力,再在后续阶段逐步提高上下文窗口。DeepSeek V3 在第一阶段消耗约 14.8T token,序列长度为 4K。
第二阶段采用 YaRN 将上下文窗口先后扩展到 32K 和 128K。LLaMA 3 采用更细的多步扩展,从 8K 起经过 6 个阶段依次提升至 128K。Kimi K2 沿用类似的分段扩展思路。
长上下文阶段的数据挑战在于,极长自然文档处于长尾分布。现实世界中的网页、问答和社交文本大多较短,CommonCrawl 中超过 32K token 的网页占比极低。书籍、学术论文和代码仓库能够提供更长的连续结构,但它们的总量和领域覆盖有限,仅依赖自然长文不足以支撑长上下文训练。
前沿模型通常采用三类策略:采样长文档源、文档拼接、合成长上下文任务。LLaMA 3 在长上下文阶段提高代码与书籍的占比,DeepSeek V3 同样上采样数学与代码作为长序列。In-Context Pretraining 用最近邻检索将语义相关短文档拼接为长序列,使 ICL 能力提升约 8 %。
Best-fit Packing 通过长度感知组合将文档打包成训练序列减少截断和 padding。Qwen 3 的 S3 阶段使用数百M token 的合成长上下文数据,Kimi K2 与 GLM-5 报告类似做法。这三类策略常常叠加应用,并且主要用于训练后期少量 token,但对长上下文 benchmark 的提升远超其 token 占比。
4.4 训练信号
标准的自回归预训练对序列中每个 token 施加等权重的交叉熵损失,隐含假设是所有 token 对模型学习的贡献均等。然而训练动态分析表明,不同 token 的学习速度并不相同。
RHO-1 提出选择性语言建模,先在高质量语料上训练一个参考模型,再逐 token 比较当前模型与参考模型的 loss,只对超额 loss 较大的 token 反向传播,将训练信号集中于「应该能预测但尚未学会“的位置。Fill-in-the-Middle 在训练时以一定概率将文档的中间片段移至序列末尾,要求模型根据前缀和后缀预测被移除的内容,使自回归模型获得双向条件生成能力。这一策略在代码模型中被 StarCoder、Code~LLaMA、DeepSeek-Coder-V2采用。
FIM 的应用已从代码专用模型扩展到通用模型,DeepSeek V3 和 DeepSeek V4 在通用预训练中继承相同策略,并报告其不损害从左到右的生成能力。
Gemma 2给出了另一条改写训练信号的路线,在预训练中使用大型 teacher 模型的 logits 取代 one-hot 目标,以蒸馏方式向 9B 与 27B 学生模型迁移知识。
除了改进已有训练信号,另一方向是挖掘更多可用于训练的信息。互联网文档除正文外天然包含 URL、域名层级、来源站点与时间戳等字段。这些信号通常在标准预训练中被丢弃,但近期工作表明它们可以作为有效的训练条件。
Physics of LLM 3.1 的实验发现知识能否被模型高效吸收不仅取决于命题本身,也取决于命题出现时的上下文。MeCo 将 URL 等元信息作为前缀拼接到训练序列中,并仅对正文 token 计算 loss,在 600M 到 8B 的规模上都观察到更快收敛,能以约 33\% 更少的数据达到与标准预训练相当的效果。Beyond URLs 表明加速效果不仅来自是否加入元信息,还取决于元信息的粒度,细粒度域名层级通常优于粗粒度主题标签或简单来源标记。
KoCo 进一步将文档元信息映射为知识坐标作为条件输入模型,使元信息从离散标签变为可组合的语境表示。一个可能的解释是,标准语言模型只建模 token 的共现关系,而真实世界中的知识总是在具体语境中产生和传播。
URL、来源标签或知识坐标为模型提供了语境的代理,因而可能提高数据利用效率并减弱低质量文本的干扰。这一方向尚缺乏在前沿模型与更大规模上的公开验证。
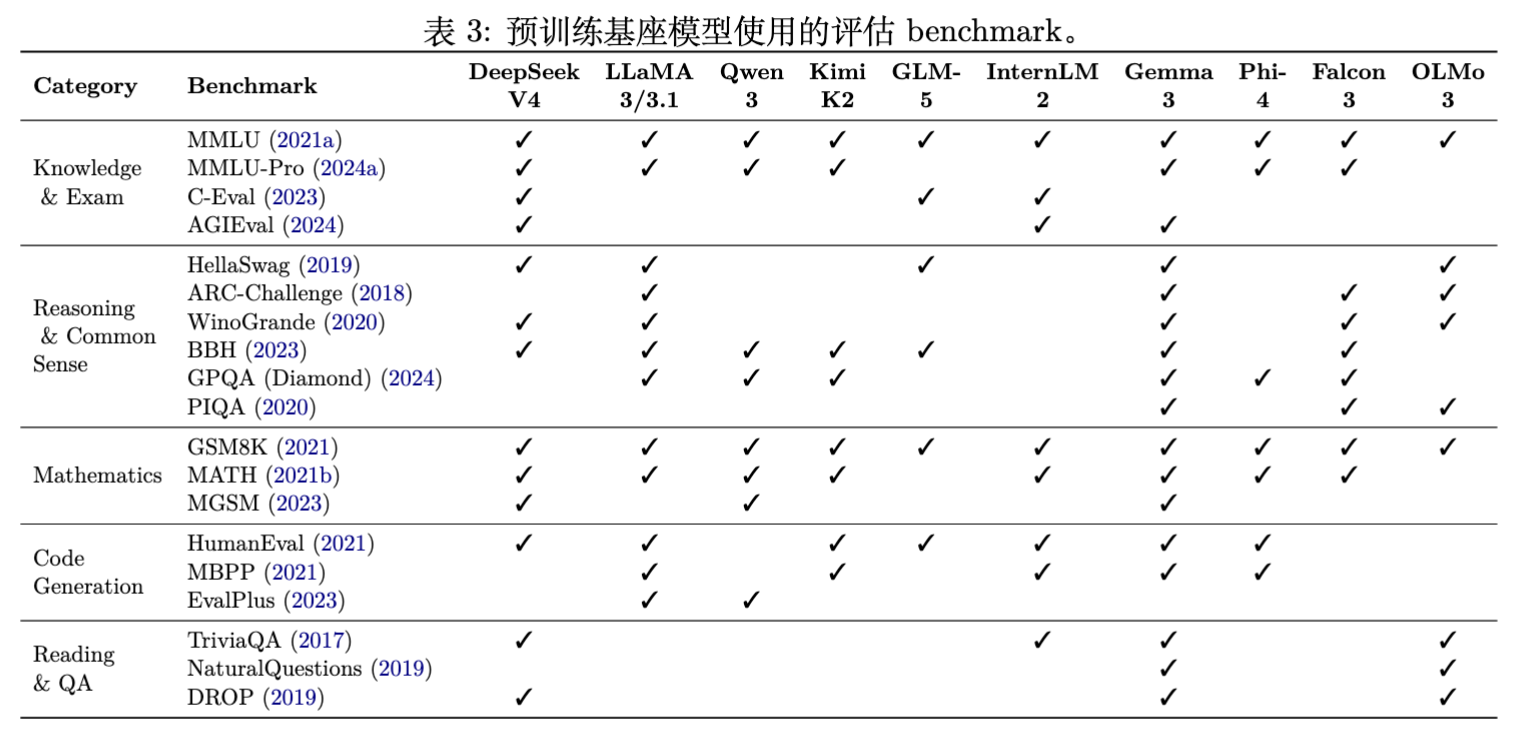
5. 预训练评估
5.1 评估方法与指标
训练 loss 是最基本的监控信号。万亿 token 规模下,loss 的局部 spike、阶梯式 plateau 与缓慢上漂通常是数据异常或数值不稳定的早期指征。
常用的 spike 检测做法是滑动窗口 z-score 或绝对阈值,触发后回滚若干 step 并跳过相关 batch,PaLM 在 540B 训练中报告约 20 次显著 spike 并采用此策略恢复训练。Gradient norm 是与 loss 互补的稳定性信号,往往在 loss 显式爆炸前数百 step 给出预警。
DeepSeek V3 与 Kimi K2 将 grad norm、参数 norm 与 loss 一同作为常规监控量。loss 的绝对值无法跨数据集对齐,因此训练 loss 主要用于同一配置内的纵向监控。
为了在不同数据方案之间提供可比指标,开源模型通常报告下游 benchmark 性能。预训练阶段的评估一般采用 few-shot 设置,因为 base model 缺乏指令遵循能力,需要通过 in-context 示例引导输出格式。
下游任务准确率并不是理想的预训练监控信号。准确率是非线性阈值指标。对于选择题,模型对正确选项的概率必须超过所有其他选项才算正确。对于生成式评估,模型必须逐 token 精确复现完整答案。
因此模型能力的连续改善在跨越阈值之前不可观测,表现为指标长期停留在随机水平后突然跳升。Mirage 给出了直接证据,BIG-Bench 中超过 92% 的涌现能力仅在精确匹配等不连续指标下出现。
当评估指标替换为连续的 Token Edit Distance 或 Brier Score 后,这些能力的增长曲线恢复为平滑幂律,涌现消失。格式敏感性进一步加剧这一问题。Olmes发现 MMLU 在标准的多选字母作答格式下约 400B token 内停留在随机水平。
将评估改为 cloze 格式,即不要求模型生成答案字母,而是分别计算每个选项文本的 log-probability 并取最高者,同一 benchmark 从训练初期即产生清晰的区分信号。这两项发现共同说明,下游任务准确率无法捕捉预训练早期的能力变化。
针对上述缺陷,社区发展出改进的评估方案。Bits-per-byte(BPB)将模型在一段文本上的总 negative log-likelihood 除以该文本的 UTF-8 字节数而非 token 数,消除分词器差异,使不同模型的得分可以直接比较。
DeepSeek V3 和 OLMo 3 都采用 BPB 作为标准报告指标。在 benchmark 层面,Gadre 2025提出不直接比较准确率,而是比较模型对每道题正确答案的 NLL。
NLL 是连续值,随计算量增加而平滑下降,可以用幂律关系外推。在此基础上再通过
将 NLL 映射到准确率。这一方法用 1.4B 过度训练模型即可预测大模型的 benchmark 表现,所需计算量仅为全规模训练的 1/300,被 LLaMA~3 的预训练评估流程采用。
对训练过程中多个 checkpoint 的持续评估可以追踪数据或架构决策的累积效果,例如某一领域数据占比的调整是否带来对应能力的提升或退化。
Phi-4 构建了内部评估集 PhiBench 指导数据混合与超参数决策。纯合成数据模型在 TriviaQA 等知识型任务上的退化信号直接促使团队在数据配比中保留 web 数据。Gemma 3 在预训练过程中使用涵盖科学、代码、事实性、多语言与推理等维度的 benchmark 作为能力探针持续监控各维度得分,同时在验证集上计算 perplexity 来评估架构选择,把架构搜索建立在连续指标之上。
评估信号还用于判断预训练何时结束以及如何过渡到下一阶段。LLaMA 3 将退火阶段的评估增益作为模型成熟度指标,退火阶段上采样高质量数学与代码数据后,8B 模型在 GSM8K 和 MATH 上分别提升 24.0% 和 6.4%,但对 405B 模型的提升可忽略不计。
技术报告将其归因为 405B 模型已在通用预训练阶段习得足够强的上下文学习与推理能力,不再依赖特定领域样本来达到高性能。当退火阶段的高质量数据不再带来增益时,说明模型已从通用数据中充分提取能力,可以切换到后训练。
OLMo~2 将 OLMES 评估任务划分为 development 集与 held-out 集,在 mid-training 阶段通过 development 集上的表现优化退火数据混合比例,最终在 held-out 集上验证增益的泛化性。
OLMo 3 进一步将评估规模扩展到 43 个 benchmark(约为 OLMo 2 的四倍)。这些做法表明,预训练的完成不仅由固定的 token 数量决定,也可以根据评估框架中各能力维度的边际增益来判定。
5.2 度量挑战
已有的评估方法假设下游 benchmark 表现可以作为预训练模型能力的代理指标。但代理指标提供的是相关性而非因果性,benchmark 得分的变化可能源于数据质量的改善,也可能源于格式适应、评估噪声或能力之间的此消彼长。当代理关系不稳定时,基于 benchmark 做出的决策就可能产生误导。
首先是代理指标与实际能力之间的脱钩。现有下游任务并不能完整体现模型在真实使用场景中的能力,agentic 工作流就是一个典型例子。
当前模型往往接入检索、工具调用、代码执行、多轮规划等外部工作流来完成具体任务,而这类 agentic training 所需的交互轨迹和环境反馈在预训练语料中天然不存在。预训练阶段的模型是否已经为后续 agentic training 准备好了可迁移的基础能力,现有 benchmark 很难直接回答这一点。Yi-Lightning 提供了直接证据。
该模型在 Chatbot Arena 上排名第 6,在中文、数学、代码等专项类别中排名第 2 至第 4,但其在 benchmark 上得分与这一排名存在明显落差。技术报告因此质疑 benchmark 作为模型能力代理的可靠性。Ministral~3 进一步表明,同一组 benchmark 在不同训练阶段可能给出矛盾的指导方向。
在预训练蒸馏阶段,从较小的 Mistral Small 3.1 蒸馏的效果优于从更强的 Mistral Medium 3。但进入后训练阶段后规律逆转,更强 teacher 蒸馏的模型反而获得更大增益。
此外,现有 benchmark 衡量的是下游任务的综合表现而非模型的原子能力。以 MMLU 为例,模型同时依赖常识记忆、上下文理解和作答格式遵循三种能力来回答问题,分数的变化难以定位到具体能力。
FineWeb-Edu 的实验发现教育质量过滤使 MMLU 和 ARC 提升,但 HellaSwag 和 PIQA 退化,说明单一维度的数据干预会在不同能力之间引发此消彼长,而聚合指标可能掩盖这种内部结构。
即使某项 benchmark 上的分数提升,也难以验证这一提升是否对应该能力维度的真实改善。这意味着 benchmark 分数作为数据决策的反馈信号存在可靠性风险。
这种可靠性风险在 scaling 研究中进一步放大,因为趋势本身依赖实验设置,且跨实验结果往往不可比。
lourie2025scaling在 gadre2025reliable构建的 46 个下游任务测试集中发现,仅约 39 % 的任务表现出单调的 scaling 行为,其余呈现非单调、突变或无趋势的模式。即便使用相同的预训练语料和下游任务,prompt 格式、few-shot 数量等细节差异也会使 scaling 趋势发生定性改变,而验证语料的选择甚至能翻转结论,例如在 HellaSwag 上使用不同验证集时 C4 与 RedPajama 的优劣关系可以完全逆转。
这种不稳定性在跨实验比较中被进一步放大。不同研究报告除了 benchmark 设置差异外,还涉及模型架构与规模、基线数据集、训练 token 数等更根本的维度差异。例如 FineWeb-Edu 报告的结果基于 1.8B 模型和 350B token,DCLM 的结果基于 7B 模型和 280B token,两者的数字无法直接对比。这一问题直接影响预训练研究的迭代效率。
预训练的核心任务是在数据、算力与架构之间做资源分配决策,而这些决策的验证依赖不同方案之间的公平比较。当实验设置、评估方法与效率度量缺乏标准化时,社区无法可靠判断哪些策略真正带来了进步,哪些仅是实验设置差异造成的偏差。
上述挑战共同反映了现有评估体系的核心问题,即缺乏将模型能力分解为独立维度并逐一测量的手段,而是把多种能力混淆在综合性下游任务中。
Allen-Zhu 的 Physics of Language Models 系列研究朝这一方向做了探索,针对``智能''的每个原子能力分别构建合成数据集,在受控环境中隔离并测量单一能力,以排除数据噪声与能力混淆的干扰。
该系列先后研究了知识的存储与提取条件 (Part 3.1)、知识操纵(分类、比较、反向检索)的固有局限 (Part 3.2)、以及知识容量与模型参数之间的定量关系(Part 3.3)。
这一思路为大模型的能力评估提供了一条噪声更低、归因更清晰的补充路径,本文不直接采用其评估范式,而是把它作为度量代理失效问题的可能解之一。其结论能否推广到大规模预训练仍有待验证。
6. 总结
预训练正在变得更加精细。数据不再只是训练开始前准备好的静态语料库,而是贯穿模型训练全过程的可调变量。研究者开始关心数据来源、质量、配比、阶段切换和训练信号之间的关系。
这些细节会影响模型学到什么,也会影响模型以多高的代价学到。但精细化并不意味着流程越复杂越好。许多经过规模验证的做法仍然遵循``大道至简''的原则。例如去掉明显重复和低质的内容,保留足够广的自然分布,在关键阶段提高高质量数据比例。这些方法并不 fancy,却在大规模训练中反复显示出价值。
如 Ilya Sutskever 所说,LLM 的主线需要回到研究问题本身。未来研究者更需要思考的是,数据究竟以什么方式驱动智能。新的高质量文本越来越难获得,简单扩充数据量的收益正在下降。更关键的问题是,知识是如何从数据中出现的,模型如何从数据中学习建立概念、关系和推理路径。我们正在推进的知识语境系列研究,正是沿着这一问题展开。
标准语言建模把网页、书籍、代码和论文都压成 token 序列,却常常忽略知识产生的条件。人类学习并不是在无来源的信息中完成的,知识总是附着在具体场景中被理解、比较和迁移。我们的工作正尝试把这些被丢弃的语境重新纳入预训练数据工程。
模型预训练是一个重实践经验的方向,要判断哪些做法真正有效,训练细节的开放性至关重要。大模型研究需要集体智慧,也需要来自真实训练的经验分享,才能推动社区形成更可靠的判断。数据工程的细节往往决定模型差异,却也是公开报告中最容易缺失的部分。
这正是本文写作的出发点:我们希望在有限披露的信息中整理可交叉验证的证据,为社区提供一个持续追踪前沿实践的窗口,并随着新的技术报告和开放语料库继续更新。