
4月25日,当 DeepSeek-V4 带着 1.6 万亿参数(Pro版)和百万级上下文窗口的震撼配置横空出世时,整个大模型圈的目光都聚焦在了它极具野心的架构革新上:混合稀疏注意力(CSA+HCA)、流形约束超连接(mHC)以及 FP4 专家权重。
然而,对于广大开发者和企业用户而言,面对如此庞大且复杂的 MoE 模型,最大的疑问往往紧随其后——“如此强悍的模型,到底能不能跑得动?跑得稳?跑得快?”
就在 DeepSeek-V4 发布的同一天,SGLang 就宣布完成对 DeepSeek-V4 的“Day-0”全面支持。这不仅是一次常规的模型接入,更是一场针对底层架构的系统级优化与全栈适配的硬核突围。
DeepSeek-V4 的核心挑战在于其打破了传统 Transformer 的计算范式。为了在百万 Token 的超长上下文中保持高效,V4 引入了极其复杂的混合注意力机制(SWA + C4/C128 压缩)。传统的推理框架在面对这种异构 KV 缓存池时,往往束手无策,前缀缓存效率极低,且显存占用巨大。
SGLang 团队之所以能在首日就实现完美适配,正是源于其对推理系统底层的深度重构。面对 V4 的混合注意力,SGLang 并没有采取简单的兼容策略,而是祭出了“ShadowRadix”这一杀手锏。
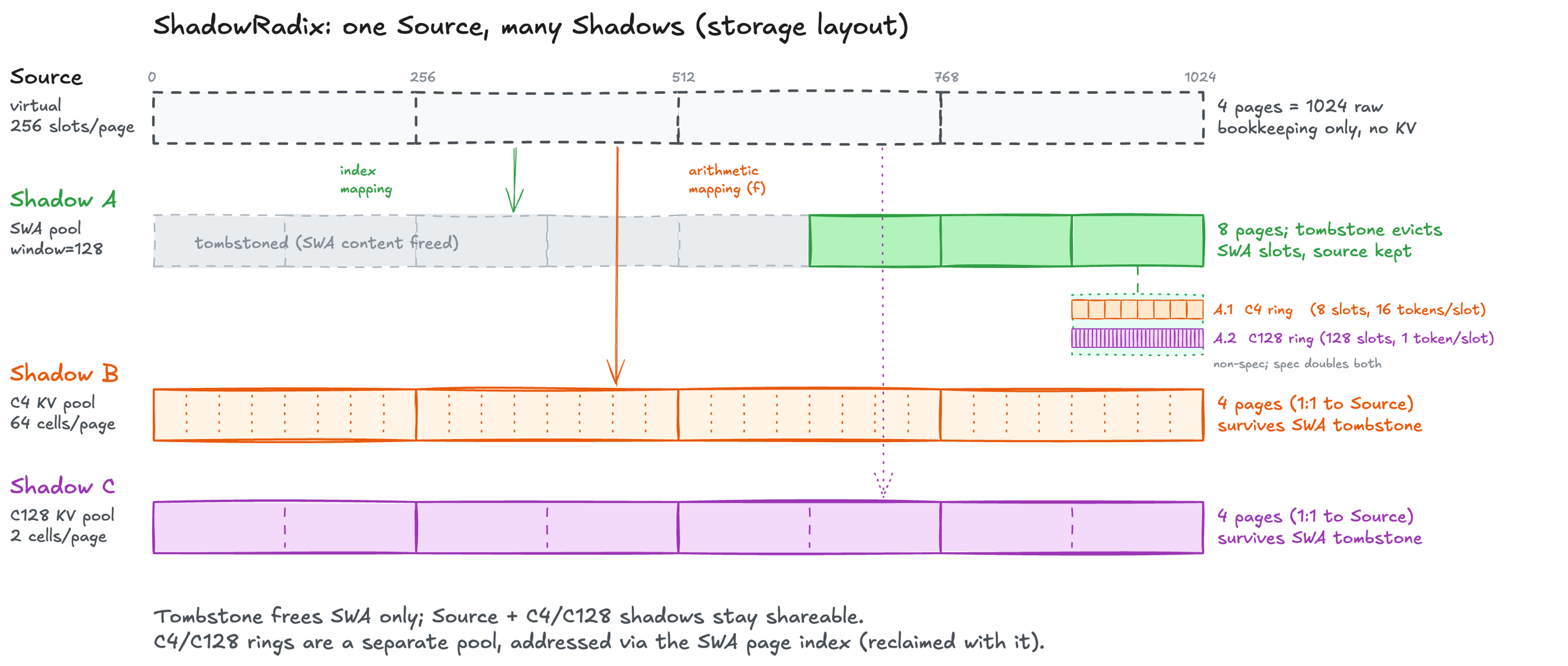
它通过建立统一的虚拟全 Token 槽位坐标系,将 SWA、C4、C128 等异构池进行“阴影”映射,实现了复杂混合注意力下的原生前缀缓存。这意味着,即便面对百万级长文本,系统也能精准复用历史计算结果,极大降低了首字延迟。
此外,针对 V4 引入的 FP4 专家权重和复杂的 MoE 调度,SGLang 深度集成了 FlashInfer TRTLLM-Gen 和 DeepGEMM Mega MoE 等前沿算子,并配合 HiSparse 技术将非活跃 KV 缓存智能卸载至 CPU 内存。
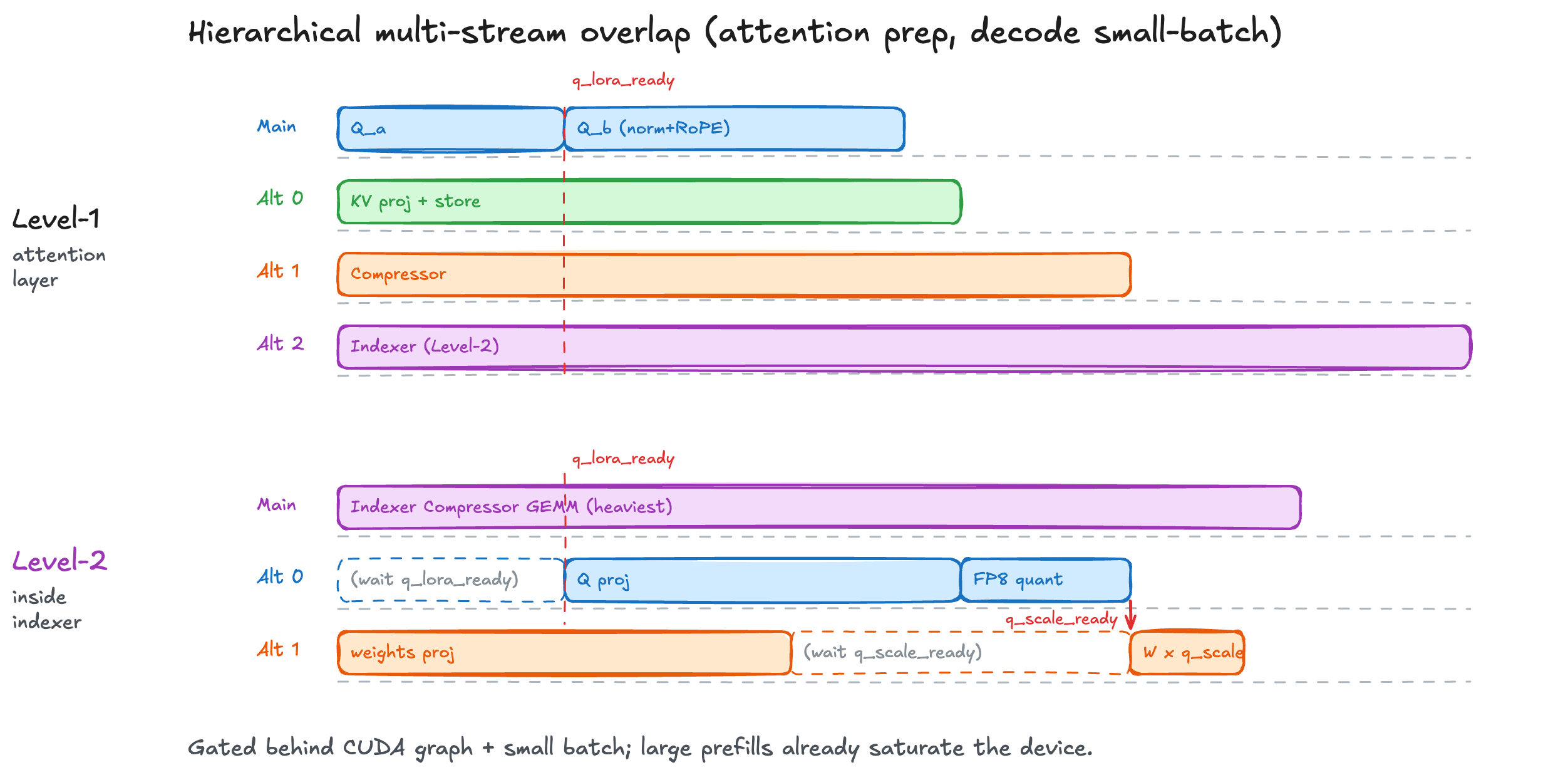
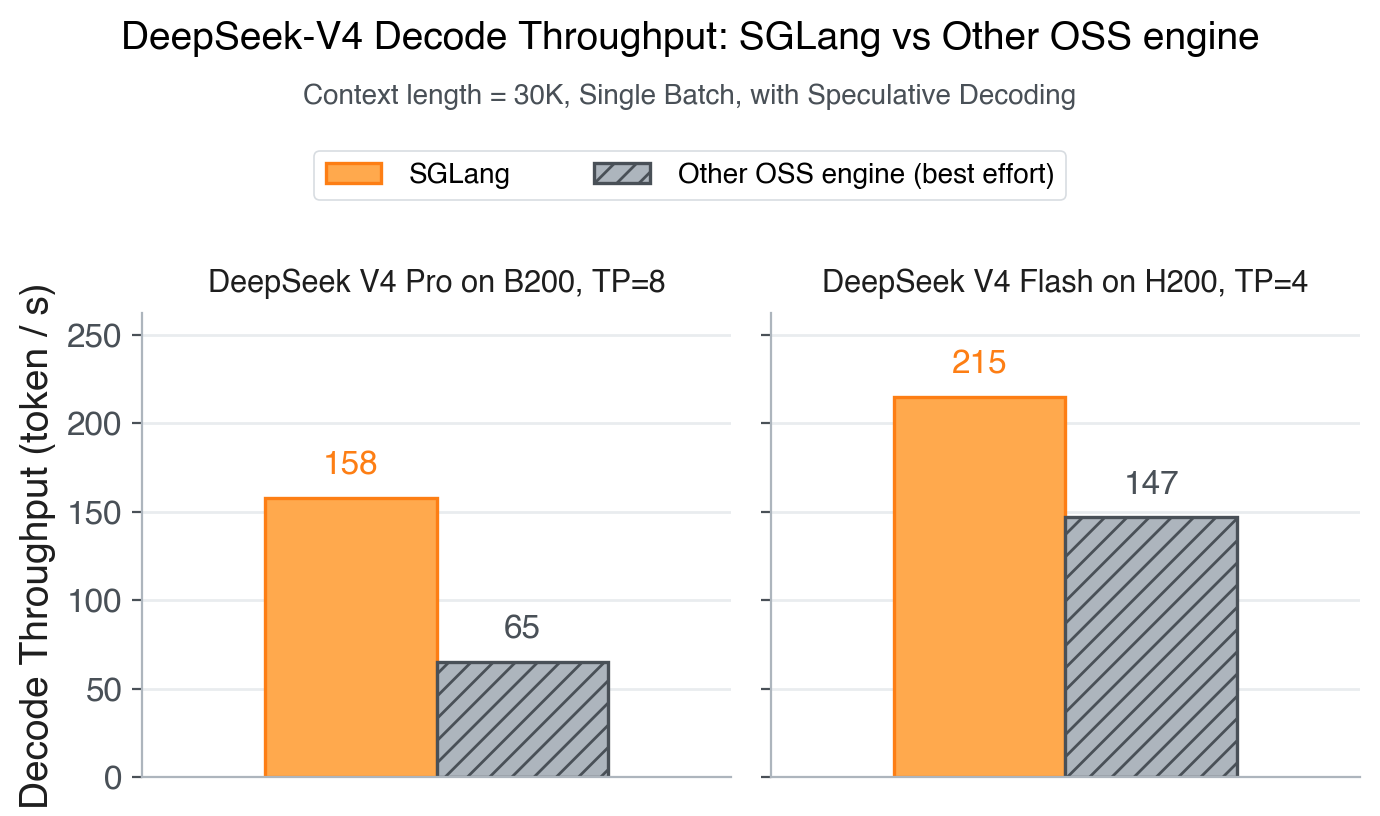
这一系列组合拳,不仅让 DeepSeek-V4 在 Blackwell 等新一代硬件上如虎添翼,更在 Hopper 等主流算力上实现了吞吐量的数倍提升,真正做到了“开箱即用”且“性能拉满”。
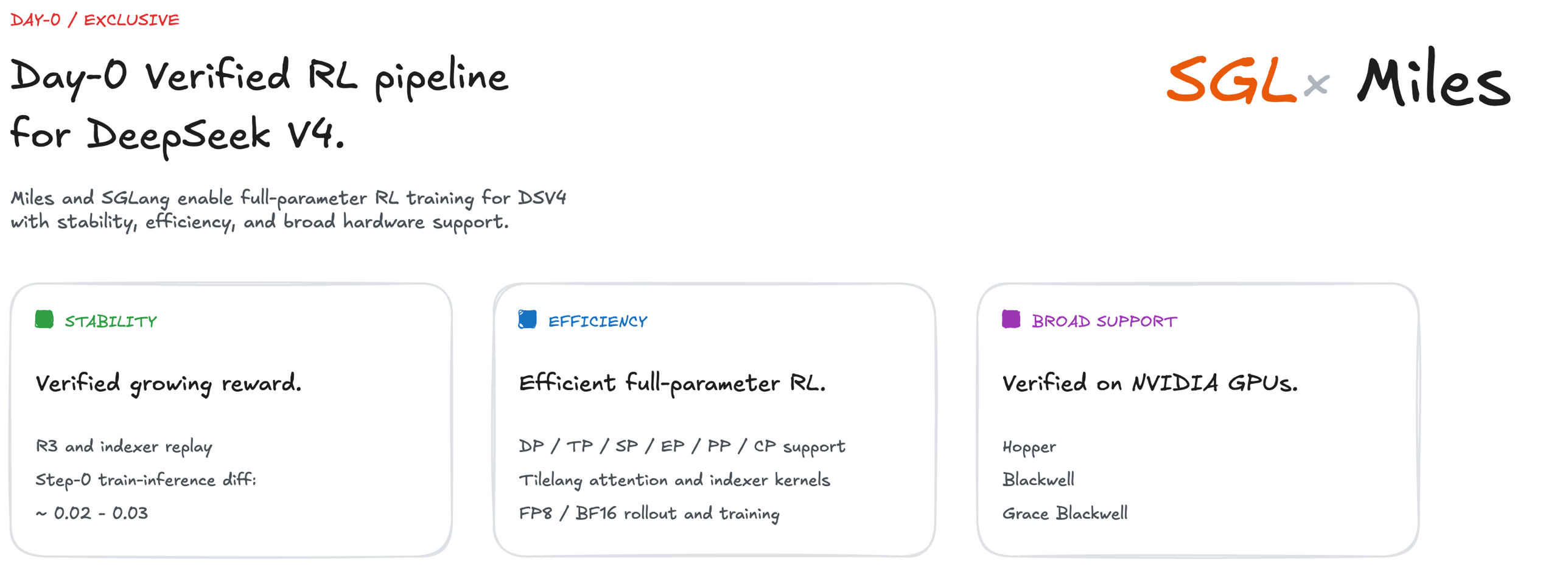
从底层算子的极速融合,到强化学习训练全链路的打通,SGLang 展现了一个顶级推理框架的工程素养。但这背后的技术细节远比我们看到的更加深邃:ShadowRadix 的索引机制究竟如何设计?HiSparse 又是如何在保证精度的前提下实现 3 倍容量提升的?
5 月 9 日(周六)上午 10 点,#青稞Talk 第 123 期,青稞社区特别邀请到了 SGLang 核心开发者和维护者——的张柏舟,带来题为《DeepSeek V4 模型在 SGLang 中的系统级优化与全栈适配》的深度分享。
届时,张柏舟将亲自为你拆解 SGLang 适配 DeepSeek-V4 的幕后故事,从 ShadowRadix 的设计哲学到多流重叠的调度策略,带你领略大模型推理系统最前沿的工程实践。
分享嘉宾
张柏舟,目前就职于 RadixArk,曾本科毕业于北京大学信息科学技术学院,硕士毕业于加州大学圣迭戈分校计算机学院。
作为 SGLang 框架的核心开发者和维护者之一,他曾主导了 SGLang 的 GB300 部署,DSA 模型优化,确定性推理等工作,并贡献了超过 200 个 commit。他也深度参与了 DeepSeek V4 在 SGLang 框架上的 Day 0 适配工作。
主题提纲
DeepSeek V4 模型在 SGLang 中的系统级优化与全栈适配
1、ShadowRadix:针对 V4 混合稀疏注意力架构的系统级设计
2、各种性能优化技巧:
- 投机采样、HiSparse 多级缓存架构
- 算子优化、序列并行、PD 分离
3、不同硬件(Hopper、Blackwell、GB NVL72)的适配及 Benchmark
4、Miles 框架的 DP/TP/CP/EP/PP/SP 全并行能力 & DAPO 训练稳定性
5、未来展望以及 Roadmap
直播时间
5 月 9 日(周六)10:00 - 11:00