作者:吕兴泰@清华-博士生
原文:https://zhuanlan.zhihu.com/p/2040445503150805754
免费为科研人员提供成果宣传支持,如有优秀研究成果分享推广,欢迎投稿联系:aiFreeCode
在标准 MoE 里,每个 token 通常都会激活固定数量的 experts。而Dynamic MoE 可以让 easy tokens 少算一些 expert,从而提升MoE的推理效率。
对于真实部署中的MoE大模型往往已经完成了完整的 post-training,包括 SFT、RL、OPD 等阶段。此时模型的 routing pattern、expert specialization、能力分布都已经被训练流程仔细校准过。
直接改它,很可能不是节省计算,而是破坏能力。
我们的这篇工作想回答的就是这个更实际的问题:一个已经 post-trained 好的 MoE 模型,能不能在不从头训练的情况下,被低成本地迁移成 dynamic MoE,并在推理时跳过一半左右的 expert 计算?
🧪Title: Post-Trained MoE Can Skip Half Experts via Self-Distillation
📝Paper: https://huggingface.co/papers/2605.18643
💻Code: https://github.com/TsinghuaC3I/ZEDA
如果觉得这篇工作不错的话,欢迎点点 upvote 和 star~
前言
这几年,Mixture-of-Experts(MoE)已经成为扩展大语言模型的重要路线:它通过稀疏激活提升模型容量,同时控制每个 token 的计算量。在此基础上,Dynamic MoE 进一步引入 token-level 的动态计算,让模型根据输入内容调整激活专家的数量。
已有研究表明,很多 easy tokens 可以用更少的 experts 处理,而不会明显影响输出质量,因此 Dynamic MoE 被认为是一条很自然的推理加速路径。
但现有 Dynamic MoE 方法大多关注两类场景:要么从头预训练一个 dynamic MoE,要么把 pre-trained base model 适配到某个特定任务上。相比之下,如何迁移一个已经完成完整训练流程的 MoE 模型,仍然缺乏系统探索。
而在真实部署中,MoE 模型通常已经经历了 pre-training、SFT、RL、OPD 等复杂 post-training 流程。对于这类 post-trained MoE,如果能在不重新训练整个模型的前提下,将其转换成更高效的 dynamic MoE,就能直接降低日益增长的推理成本。
但问题在于,dynamic MoE 不是简单“少开几个 expert”就行。尤其是 post-trained MoE,已经经历了完整训练管线,其 router 和 experts 之间的耦合关系非常脆弱。粗暴改变 top-K、直接裁剪 experts、或者强行重新均衡路由,都可能破坏原本已经形成的能力结构。
我们提出Zero-Expert Self-Distillation Adaptation(ZEDA),实现把已经训练好的 post-trained MoE 低成本地迁移成一个更高效的 dynamic MoE。

方法:ZEDA 如何让 MoE “跳过”一半专家?
ZEDA 的整体框架可以概括为两步:
- 1️⃣注入 zero experts;
- 2️⃣通过 SFT + OPD 做 self-distillation。
1. Zero Expert Injection:给 router 一个“什么都不算”的选项
ZEDA 最核心的设计是 zero expert。所谓 zero expert,就是输出恒为 0 的 expert。它没有普通 expert 的 FFN 计算,也不会引入新的参数化变换。它的作用不是提供新的能力,而是给 router 一个新的选择:
如果某个 token 不需要那么多 normal experts,就可以选择 zero experts。
原始 MoE 中,每个 token 从 N 个 normal experts 中选 K 个,输出是 y(h) = \sum_{i \in \mathcal{S}(h)} g_i(h)\, E_i(h) ,其中 E 是expert,g 是对应的权重,S 是被选中的 expert 集合。
ZEDA 会在每个 MoE layer 里额外注入一组共 Nz 个 zero experts,使得 router 的候选池变成:normal experts + zero experts,但 top-K 的选择数量不变。
这样一来,如果某个 token 的 top-K 里包含了 zero experts,那么真正参与计算的 normal experts 就会变少。由于 zero experts 的输出为 0,也不需要专家 FFN 计算,所以这就自然实现了 token-level dynamic computation。
这个设计的好处是,它没有直接删除原来的 experts,也没有强行改变 top-K,而是把“少算一点”的选择权交给 router。
一个很自然的替代方案是 copy expert:不做 FFN 计算,只把输入直接传到输出。它看起来也很省,而且不像 zero expert 那样完全输出 0。但在 post-trained MoE 里,copy expert 反而可能更危险。
原因在于,copy expert 会向 MoE 输出中加入一项与 hidden state 同方向的分量。这可能同时带来 scale mismatch 和 direction mismatch:输出幅度被改变,输出方向也被偏移。对于一个已经完成后训练的 MoE 来说,这种额外输出会扰动原本校准好的 residual scale 和 expert mixture。
相比之下,zero expert 更像是真正的“跳过计算”。它不会凭空引入新的输出方向,也不会主动放大某些 hidden representation。对于 post-trained MoE 的迁移来说,这种改动更温和。
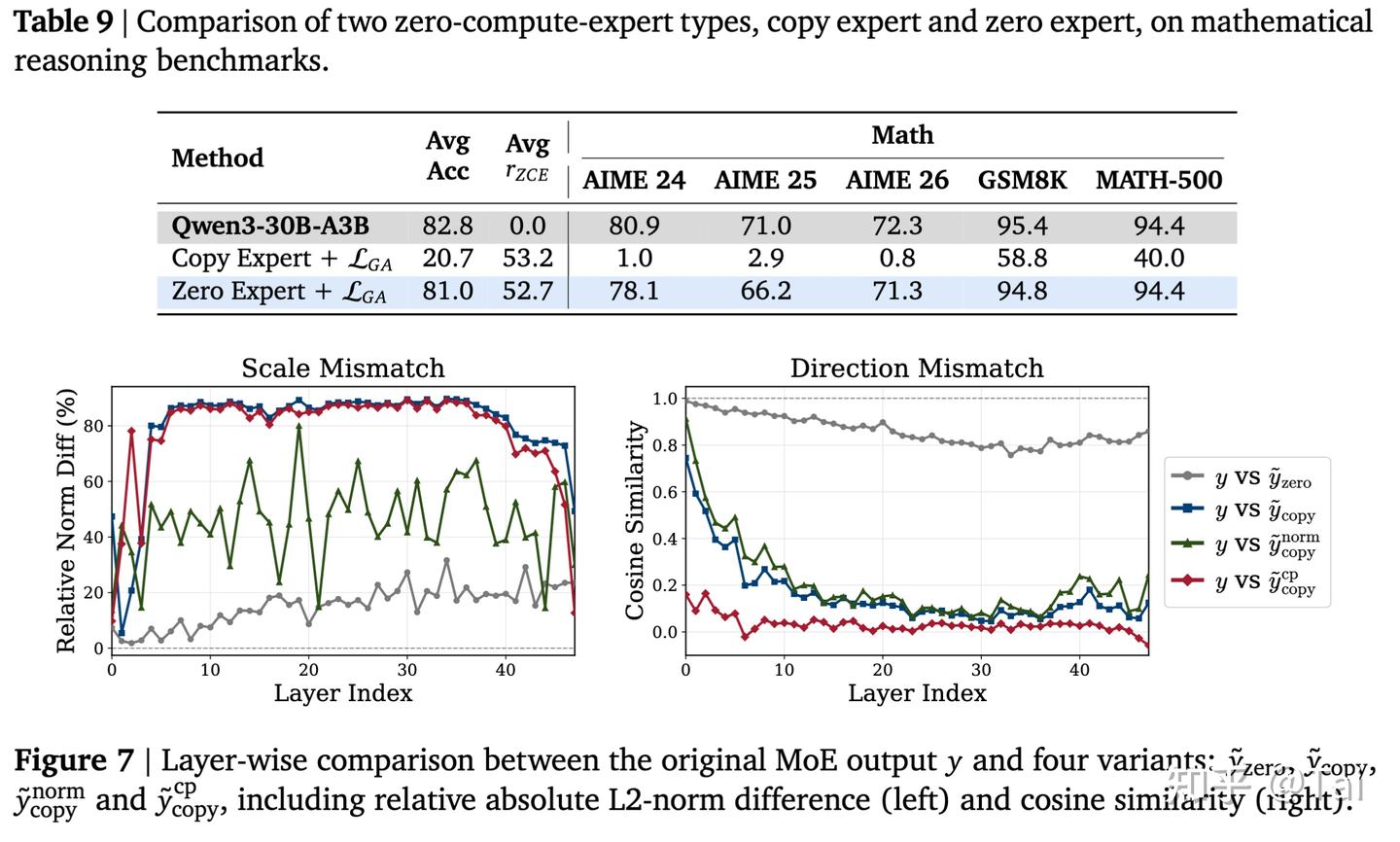
2. Self-Distillation:用原模型教会新模型如何少算
只注入 zero experts 还不够。因为 router 的候选空间变了,模型需要重新适应这个结构变化。ZEDA 采用 self-distillation:把原始 post-trained MoE 固定为 teacher,把注入 zero experts 后的 dynamic MoE 作为 student。整个 adaptation 分为两个阶段:
1、SFT self-distillation。Teacher 先对 prompts 生成 responses,然后 student 学习 teacher 的输出。这个阶段的作用主要是冷启动,让 student 在新结构下先恢复基本生成能力,并初步学会如何使用 zero experts。
2、OPD self-distillation。此时 student 自己 rollout 生成 responses,teacher 在 student 真实访问到的轨迹上提供 token-level 分布监督。这个阶段可以进一步缩小 student 在 on-policy 分布下与 teacher 的差距。
这两个阶段的分工很清楚:SFT 负责稳定迁移,OPD 负责在 student 自己的生成分布上继续对齐。消融实验也支持这一点:单独 SFT 或单独 OPD 都不如完整的 SFT → OPD pipeline。尤其是 OPD alone 效果较差,因为模型还没学会稳定使用 zero experts,就要同时处理动态路由和 on-policy 生成,优化难度会更高。

3. Group Auxiliary Loss:只控制 normal / zero 两组之间的比例
在Self-Distillation阶段,ZEDA除了使用SFT loss和OPD loss之外,还引入了 Group Auxiliary Loss,用来控制 zero expert activation ratio,同时减少对原本训练好的路由分布的影响。
普通 auxiliary loss
其中
B 代表一个batch, \alpha 是loss系数。这个loss会在所有 experts 上做均衡,但这会破坏 post-trained MoE 内部已经形成的 expert routing structure。
因此 ZEDA 不做 expert-level balancing,而是把 experts 分成两组:normal expert group和zero expert group。Group Auxiliary Loss 只调节这两个 group 之间的相对激活频率。
也就是说,它关心的是“zero experts 总体被用了多少”,而不是强迫每个 normal expert 都被均匀使用。
这样做的好处是,ZEDA 可以控制整体计算节省比例,同时尽量保留 normal experts 内部原有的 specialization。
Group Auxiliary Loss的具体公式是:
其中
这里还有一个关键超参数是 zero-expert group weight w。w 越大,模型越倾向于使用 zero experts,推理越省;但如果 w 太大,性能也会下降。实验中 w=2 是一个较好的折中点,对应约 50% 的 zero expert activation ratio。
实验:真的能少算一半 expert 吗?
1. 实验设置:两个 post-trained MoE,11 个 benchmark
我们在两个 post-trained MoE 上验证 ZEDA:Qwen3-30B-A3B,GLM-4.7-Flash。评测覆盖 11 个 benchmark,分为三类:
- 1️⃣数学推理:AIME 24、AIME 25、AIME 26、GSM8K、MATH-500;
- 2️⃣代码生成:LiveCodeBench v5、LiveCodeBench v6、HumanEval+、MBPP+;
- 3️⃣指令遵循:IFEval、IFBench。
这个设置的意义在于,ZEDA 不是只在某一个任务上验证,而是同时考察 reasoning、coding 和 instruction following。对于 post-trained MoE adaptation 来说,这一点很重要,因为我们不希望方法只是把某一类能力保住,而在其他方向上明显退化。
2. 主结果:约跳过一半 expert,平均性能只小幅下降
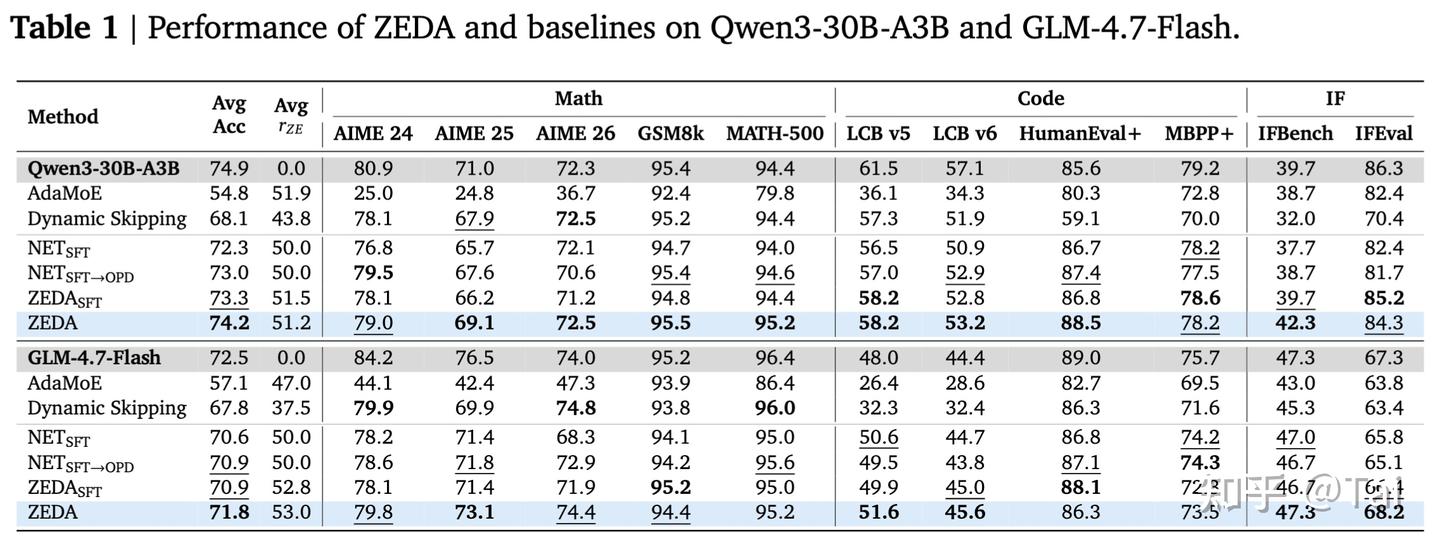
在这两个模型上,ZEDA 都实现了超过一半的 expert 激活由 zero experts 替代,同时平均性能只出现小幅下降。相比 dynamic MoE baselines,ZEDA 的优势也比较明显。在 Qwen 上,ZEDA 相比最强 baseline 平均高 6.1 分;在 GLM 上,平均高 4.0 分。更重要的是,部分 baseline 会出现明显能力不均衡。
例如 AdaMoE 在 hard reasoning 上掉得比较厉害,Dynamic Skipping 在 code generation 上表现不稳定。而 ZEDA 的特点是,在数学、代码和指令遵循三个方向上都相对稳定。
3. 推理速度:FLOPs 下降能否转化成真实加速?
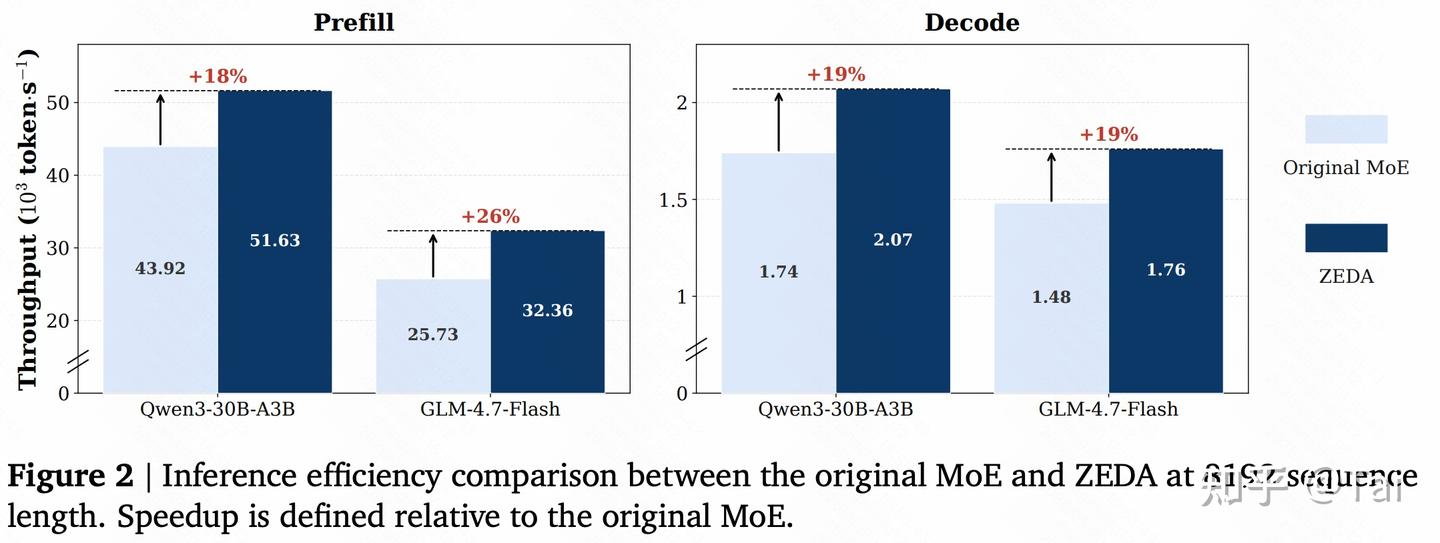
减少 expert FLOPs 不一定等于真实推理加速。因为 MoE inference 还受到并发、通信、kernel 实现、batching、routing overhead 等因素影响。
因此我们进一步在 SGLang 中测试实际 throughput。在 8192 sequence length、max concurrency 32、单张 H200 GPU 的设置下,ZEDA 在两个模型上都带来了约 20% 左右的实际推理加速。
4. 适配成本:不是重新训练,而是低成本迁移
ZEDA 使用 60k prompts 做 self-distillation,其中包括数学、代码和通用聊天数据。在 8 张 H200 GPU 上,完整 ZEDA adaptation 的时间为:
- Qwen3-30B-A3B:约 30.12 小时;
- GLM-4.7-Flash:约 61.37 小时。
相对于一个 MoE 模型从 pre-training 到 post-training 的完整成本,这个 adaptation 成本是较低的。这也是 ZEDA 的实际价值所在:它不是提出一个需要重新训练的新 MoE 架构,而是提供一种对已有 post-trained MoE 进行后处理式转换的方案。
有意思的发现:ZEDA 学到的不是“任务级难度”,而是 token-level 计算分配
除了最终分数和推理加速,我们还想进一步看一个更细的问题:ZEDA 到底是在什么时候选择跳过 experts?
当模型生成一个 response 时,不同 token 的 zero expert activation ratio r_{ZE} 并不完全一样,我们想探究影响这个分布的因素,进而建立模型的计算量分配与可观测指标的关联。
1. 关联因素:teacher-student 差异、Entropy、Response Patten
对于 student 生成的每个 token,我们计算 teacher 和 student 在这个 token 上的 log probability 差异,也就是 teacher-student logp-diff。
结果发现,当这个差异越大时,token 的 r_{ZE} 往往越低。也就是说,当 student 和 teacher 在某个 token 上分布差异较大时,模型倾向于保留更多真实 expert 计算。
这很符合直觉:如果某个位置上 student 和 teacher 分歧很大,说明这个 token 对 student 来说更需要校正、更不稳定,此时模型不应该过度跳过计算。
类似地,我们也观察了 student entropy 和 r_{ZE} 的关系。Entropy 越高,通常说明模型越不确定。实验中也能看到,高 entropy token 往往对应更低的 r_{ZE} ,也就是更多 normal experts 被激活。
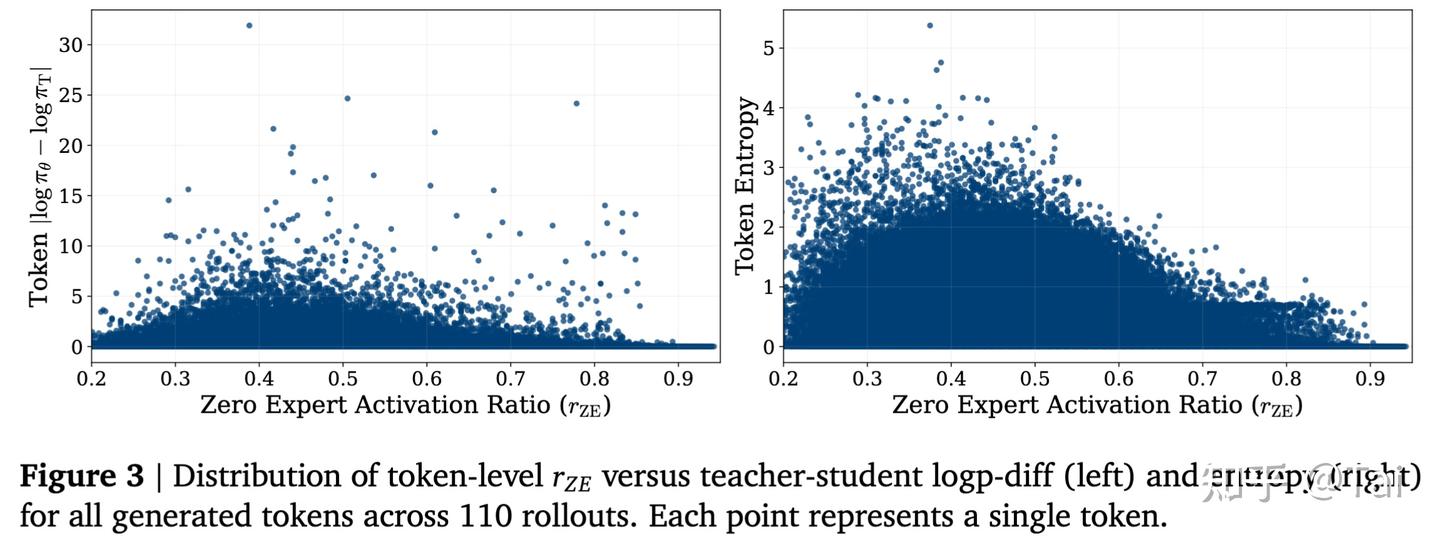
进一步看 response pattern,也能发现很清楚的结构性差异。我们把生成文本和每个 token 的 r_{ZE} 对齐后发现,代码片段、数学表达式、格式化符号这类更加结构化、低熵的 token,通常会有更高的 r_{ZE} 。
也就是说,模型在这些位置上更愿意跳过 normal experts。相比之下,自然语言推理中一些更开放、更不确定的部分,往往会保留更多 normal expert 计算。
这说明 ZEDA 学到的动态性不是一个抽象的“省计算开关”,而是会随着生成内容的局部模式变化:结构化、低不确定性的片段可以少算;分布差异大、不确定性高的片段则需要多算。

2. 无关因素:任务难度
一个很自然的猜测是:既然 dynamic MoE 会动态分配计算,那它是不是在判断“这道题难不难”?但实验结果并不支持这个解释。我们进一步比较了 MATH-500 不同 difficulty levels 以及 AIME24 上的 r_{ZE} 。
结果发现,虽然题目难度在变化,但 r_{ZE} 并没有随难度呈现明显单调变化。这说明 ZEDA 并不是在 sample level 上简单判断“这个任务难,所以多算;这个任务简单,所以少算”。

总而言之,ZEDA 并不是学到了一个粗粒度的任务难度分类器,而是在生成过程中根据 token-level 的分布差异、不确定性和文本模式来动态分配计算。
总结
我们把 dynamic MoE 的问题从“如何从头训练一个更省的架构”,推进到了一个更贴近部署的问题:当一个 MoE 已经训练完了,我们还能不能让它更便宜?
ZEDA 给出的答案是:至少在当前实验范围内,可以。而且这条路线并不依赖重新预训练,而是通过温和的结构注入和自蒸馏,让 post-trained MoE 在保留原能力的基础上学会按 token 分配计算。这可能是未来高效 MoE 部署中非常值得继续探索的一类方向。