作者:VL- Calibration研究团队
免费为科研人员提供成果宣传支持,如有优秀研究成果分享推广,欢迎投稿联系:aiFreeCode
长期以来,大型视觉语言模型(LVLMs)在多模态理解与推理任务中展现了惊人的能力,但它们也面临着一个致命的弱点:经常“非常自信地胡说八道”。
模型不仅会产生严重的幻觉,给出与事实不符的错误回答,而且往往对这些错误回答表现出极高的确定性 。
这种“盲目自信”的现象,使得大型多模态模型在医疗诊断、法律咨询、自动驾驶等高风险、高价值场景中的落地应用举步维艰。
当我们试图将AI引入关键决策闭环时,如何让模型“知之为知之,不知为不知”,准确评估自身的不确定性,已经成为当前大模型发展亟待解决的核心难题。
在这样的背景下,多模态大模型的置信度校准(Confidence Calibration)研究显得尤为重要。它不仅是一个具体的技术指标,更关乎如何建立人类与人工智能之间的信任桥梁。
但从技术角度看,现有的解决方案存在局限。长期以来,学术界普遍借用纯文本大语言模型(LLMs)的校准方法,默认只优化一个全局的单一置信度评分。
然而,这一假设在多模态场景中存在问题。对于视觉语言模型而言,一个错误的预测可能源于两种截然不同的失败:第一种是“看错”,即视觉感知出现了幻觉或遗漏;第二种是“想错”,即虽然看对了图片,但后续的逻辑推理出现了谬误。
针对这一问题,研究团队提出了VL-Calibration。这是一种基于强化学习(RL)的全新校准框架,其核心思想是在生成回答的过程中,显式地将置信度解耦为“视觉置信度”和“推理置信度”。
这让模型在给出最终答案前,能够清晰地表达“我对我看到的东西有多确信”以及“我对我的逻辑推导有多确信”。
目前,该工作已被 ACL 2026 主会接收 。本文作者来自浙江大学。共同第一作者为肖文懿与许鑫驰,指导老师为甘磊磊研究员。

论文标题:VL-Calibration: Decoupled Confidence Calibration for Large Vision-Language Models Reasoning
论文地址: https://arxiv.org/abs/2604.09529v1
代码地址: https://github.com/Mr-Loevan/VL-Calibration
研究背景:单一分数的局限与语言先验的陷阱
近年来,让大模型通过自然语言表达其置信度(Verbalized Confidence)逐渐成为主流。然而,直接将这种方法生搬硬套到多模态模型上,不可避免地遇到了瓶颈。
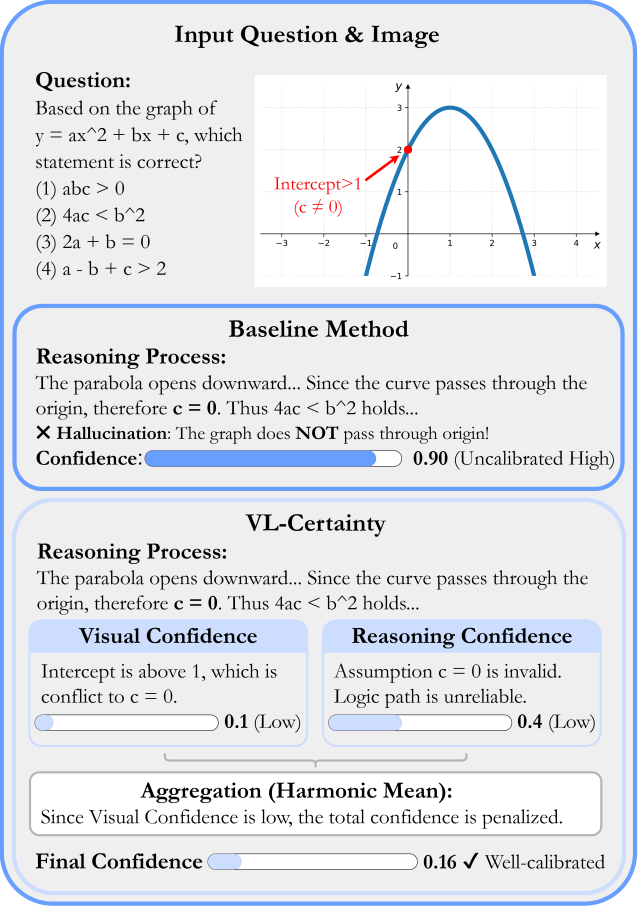
正如图中所示,多模态任务的错误来源是复合的。如果模型给出“我 90% 确信这个答案”,我们无从得知这剩下的10%犹豫是因为图片太模糊,还是因为题目太难。这就好比要求一个学生只给出最终的考试估分,却不允许他分别评估自己在“审题”和“解题”两个环节的把握。
这种粗粒度的评估方式,不仅阻碍了对模型错误的精准定位,还会因为语言模型固有的“过度自信”本能,导致视觉感知的真实置信度被完全掩盖。
核心方法:基于解耦与内在估计的强化学习校准框架
为了打破单一置信度带来的局限,VL-Calibration 提出了一套针对多模态推理的强化学习(RL)校准框架。该框架从生成轨迹的设计到奖励信号的构建,主要由三大核心机制组成:
视觉感知与逻辑推理的显式解耦
长期以来,大模型习惯于输出单一的全局置信度,这掩盖了多模态任务中错误来源的异质性。
为此,VL-Calibration 在模型的生成轨迹中引入了结构化的中间步骤:首先要求模型输出视觉依据及其对应的“视觉置信度(Visual Confidence)”,随后再进行逻辑推演并输出“推理置信度(Reasoning Confidence)”。
在最终置信度的聚合阶段,框架摒弃了简单的算术平均,转而采用调和平均数。调和平均数对低分项更为敏感,这种保守的融合策略能够有效抑制模型仅凭强大的语言先验给出高全局得分,从而逼迫模型暴露出其真实的视觉理解缺陷。
无监督的内在视觉确定性估计
在强化学习的奖励建模中,逻辑推理的正确性可以通过标准答案进行基于规则的评判,但“模型是否真实看清了图像”却缺乏现成的真实标签。为解决这一无监督难题,研究团队创新性地设计了两种基于模型内在分布的评估指标:
- 视觉基础(Visual Grounding):通过对输入图像施加随机掩码扰动,并计算扰动前后模型输出 Logits 的 KL 散度 。若模型在生成过程中高度依赖视觉输入,扰动必将引发显著的分布漂移;反之,若 KL 散度极小,则说明模型可能退化成了纯语言模型的“盲猜”状态。
- 内部确定性(Internal Certainty):利用模型在生成视觉描述过程中的 Token 熵(Entropy)来量化其内在分布的不确定性 。 研究者将这两者结合,构建了对数级的“视觉确定性得分”。这一指标在无需额外人工标注的情况下,为强化学习框架提供了极高质量的伪标签信号,引导模型客观评估自身的视觉感知状态。
细粒度的Token 级优势重加权
传统的组相对策略优化(如 GRPO)等强化学习算法,往往在样本级别对错误进行均匀惩罚 。但在多模态场景下,因“视觉感知彻底失效”引发的幻觉,其严重程度理应高于单纯的“逻辑推导失误”。
为此,团队引入了 TAR 机制,将上述计算出的“视觉确定性”动态引入优势函数的计算中。具体而言,如果在视觉确定性极低的情况下,模型依然给出了高置信度的回答,TAR 会在 Token 级别显著放大对该优势函数的惩罚力度;反之,若视觉感知明确仅是推理出错,则保留常规的优化空间。
这一重加权机制实现了对多模态复合错误的细粒度惩罚,大幅提升了策略优化的效率。
实验结果:打破“诚实与聪明不可兼得”的传统认知
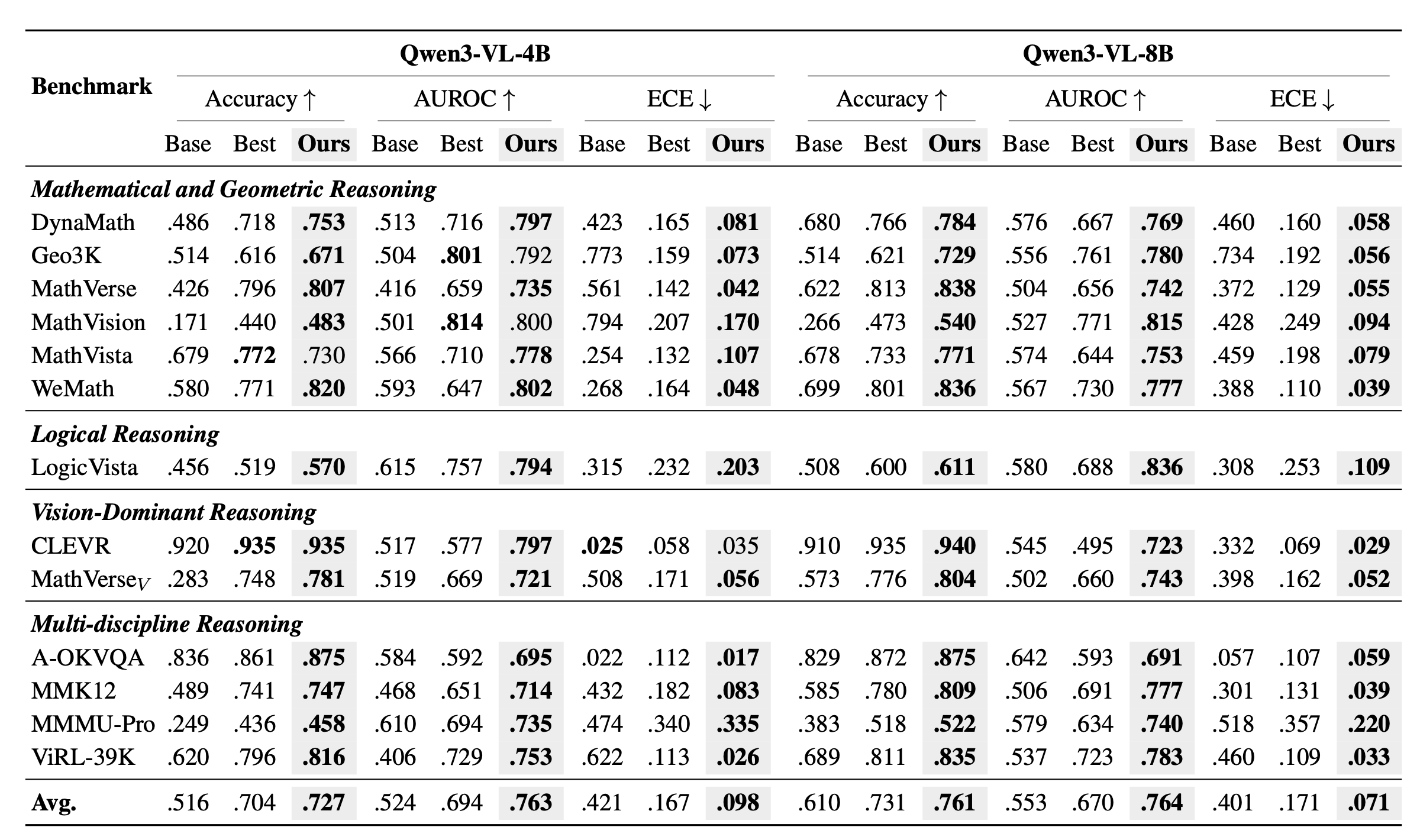
传统认知是“校准往往以牺牲准确率为代价(对齐税)”,而这项工作不仅降低了 ECE,还提升了准确率。该论文在涵盖数学、几何、逻辑推理以及多学科综合理解等领域的13个主流基准测试上进行了极其详尽的实验。
结果表明,VL-Calibration展现出了压倒性的优势:
校准误差断崖式下降:在 Qwen3-VL-4B 模型上,VL-Calibration将期望校准误差(ECE)从基座模型极度糟糕的0.421直接降低至0.098。
这标志着模型预测的确定性终于与其真实的准确率高度吻合。
不仅更准,而且更强:学界普遍认为,提升模型的校准能力往往需要牺牲一定的准确率。然而,VL-Calibration不仅没有退步,反而将4B和8B模型的平均准确率逆势提升2.3%和3.0%。这证明,正确的认知自我边界,反而能促进推理能力的提升。
可靠性图分析:校准误差显著下降与准确率的同步提升
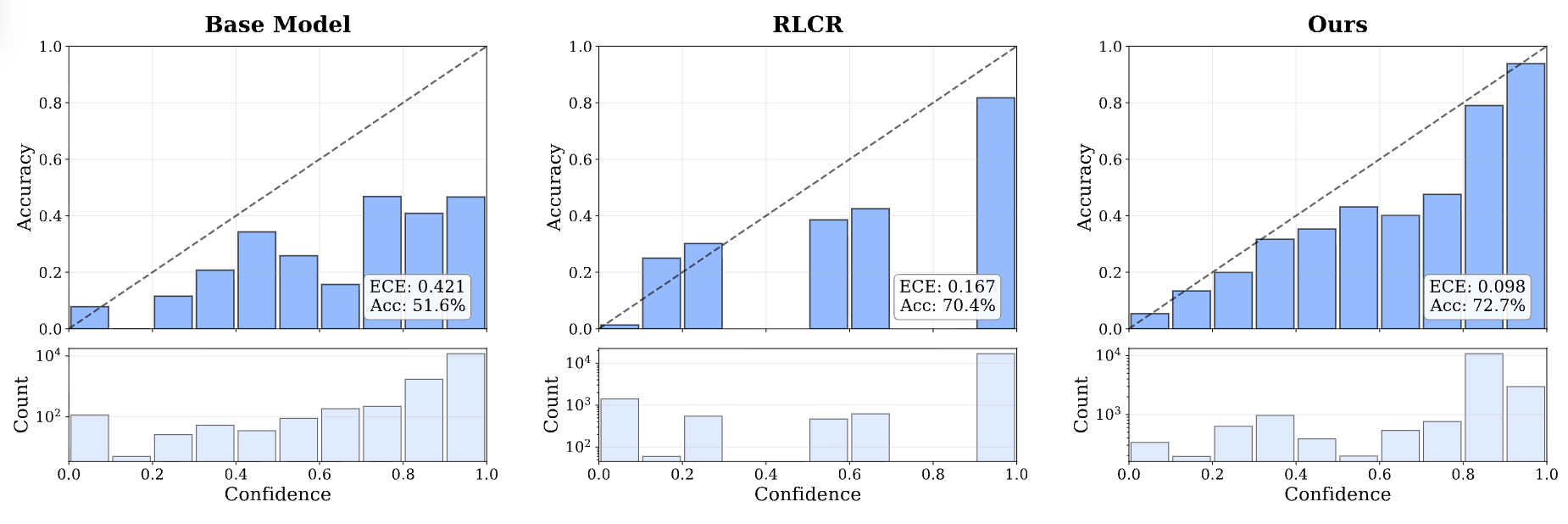
为了直观评估模型的校准效果,我们可以参考论文中的可靠性图(Reliability Diagram,见上图)。在理想的校准状态下,模型的预测置信度应与其真实的准确率严格一致,即图中的对角虚线。
对比图中的三组结果,可以观察到显著的差异:
基座模型(左图):Qwen3-VL-4B 的置信度分布严重偏向高分区间(0.9-1.0区间样本量极大),且代表实际准确率的柱状图明显低于对角线,表现出明显的过度自信。其期望校准误差(ECE)较高,达到 0.421,准确率(Acc)为 51.6%。
RLCR 方法(中图):采用传统的全局强化学习校准后,置信度分布有所改善,ECE 降至 0.167,但置信度分布存在两极分化和明显断层,且仍有一定偏差。
VL-Calibration(右图):采用解耦校准框架后,模型的置信度分布更加平滑,且紧密贴合理想对角线。ECE 降至 0.098,展现了良好的校准能力。
可视化分析:视觉与推理置信度的真实解耦
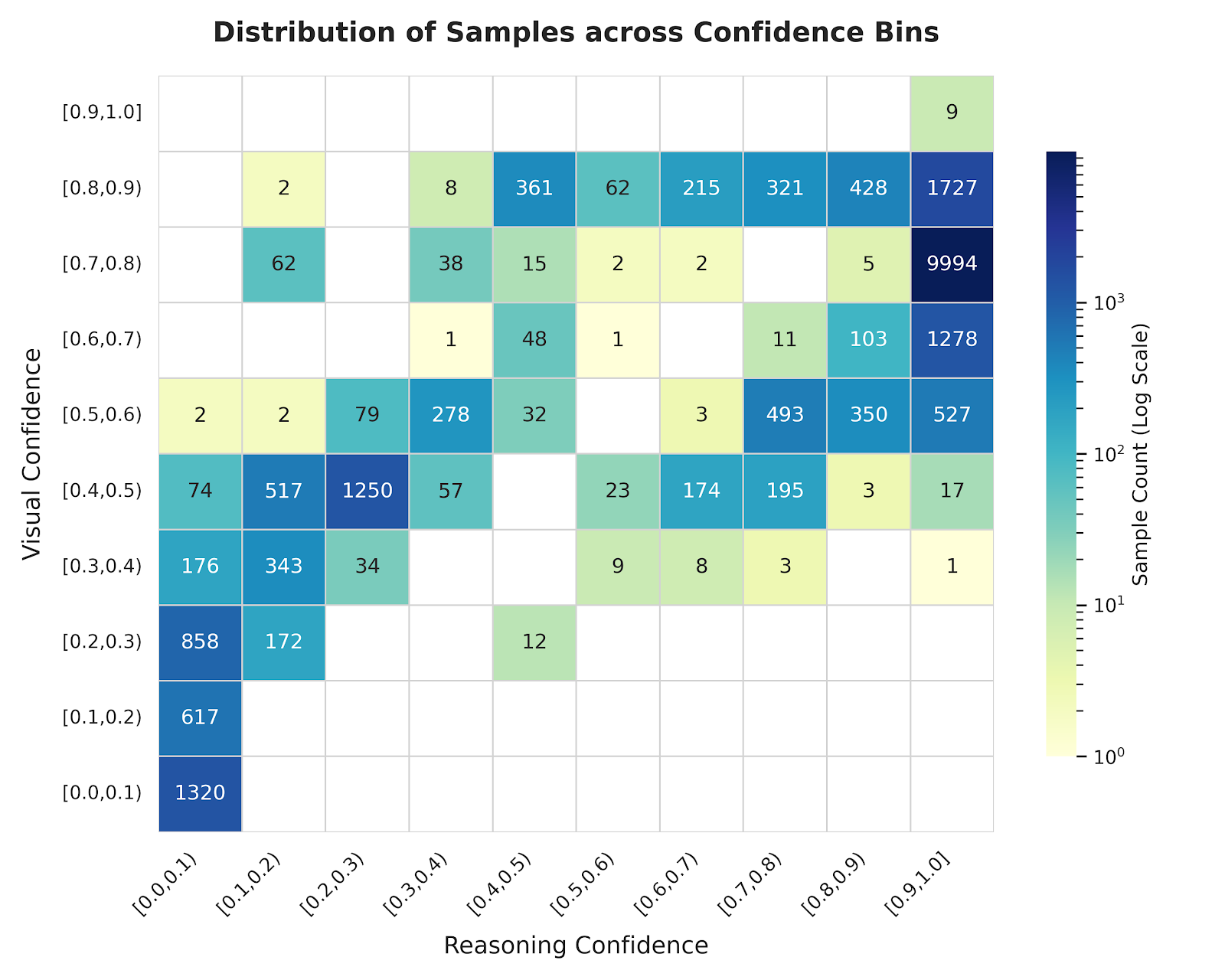
为了验证将置信度解耦的实际意义,研究团队对经过 VL-Calibration 训练后的模型在推理阶段输出的置信度分布进行了可视化分析(见上图)。
热力图的纵轴代表视觉置信度(Visual Confidence),横轴代表推理置信度(Reasoning Confidence)。
如果视觉感知与逻辑推理的置信度是强绑定的(即可以用单一分数合理代替),样本应当紧密集中在图中的对角线上。
然而,热力图呈现出广泛的非对角线分布,这直观地证明了在多模态模型内部,视觉不确定性与推理不确定性确实存在显著的解耦现象:
- 视觉感知明确,但逻辑推理受阻(左上方区域分布):大量样本分布于此,表明模型准确捕捉并识别了图像中的关键视觉元素(视觉置信度偏高),但在应对复杂问题时的逻辑推导过程中遇到了困难(推理置信度偏低)。
- 视觉信息不足,但推理逻辑自洽(右下方区域分布):相反,部分样本的视觉置信度较低(可能源于图像模糊或关键特征缺失),但得益于语言模型强大的先验知识,其在给定条件下的逻辑推理环节仍能给出较高的确定性。
这一分布结果有力地支撑了该研究的核心动机:多模态任务的错误来源是复合且独立的。强行使用单一的全局分数进行评估,必然会导致模型内部真实认知状态的混淆。
VL-Calibration 通过将两者显式剥离,成功让模型能够更透明、更精准地表达其真实的认知过程。
总结与展望
这项工作的核心价值,不仅在于提出了一种有效降低模型校准误差的算法,更在于它重新定义了多模态模型置信度校准的内涵:置信度不应该只是一个事后输出的概率数字,它应该真实反映模型内部的感知状态与推理逻辑的解耦过程。
通过拆解视觉与推理的不确定性,并借助内在确定性估计,VL-Calibration证明了让大模型摆脱“盲目自信”、学会“自省”是可行的。