论文标题: UnityMAS-O: A General RL Optimization Framework for LLM-Based Multi-Agent Systems
论文链接: https://arxiv.org/pdf/2605.26646
代码链接: https://github.com/chenyiqun/UnityMAS-O
核心关键词:Multi-Agent Systems、LLM Reinforcement Learning、Agentic Workflow、Parameter Sharing、Code Agent
作者介绍:陈逸群,中国人民大学高瓴人工智能学院博士研究生,导师为毛佳昕副教授。
主要研究方向包括 LLM-based Multi-Agent Reinforcement Learning、Agentic Search与Information Retrieval。其研究长期关注如何通过强化学习优化复杂智能体系统中的协作、检索、推理与决策过程,相关工作发表于ICML、NeurIPS、WWW、IJCAI等国际会议。近期主要聚焦于Multi-Agent Joint Optimization,探索面 LLM多智能体系统的统一训练与协同优化方法。
近两年,基于大语言模型的 Multi-Agent 系统变得越来越复杂。常见的范式是:由 planner 负责拆解任务,随后调用 tool 获取外部知识,再交给 answerer、coder 或 reflector 继续完成后续步骤。
工作流本身可以被设计得非常丰富,但在优化阶段,许多系统仍然回到了较传统的单模型、单策略训练范式。换言之,多角色协作虽然出现在推理过程中,却尚未真正作为一个统一的系统对象接受训练。
论文《UnityMAS-O: A General RL Optimization Framework for LLM-Based Multi-Agent Systems》关注的正是这一问题。它并不是提出一个新的 agent 角色,而是试图为 LLM 多智能体系统提供一套通用训练框架,使预先定义好的多智能体工作流能够被纳入强化学习优化过程。
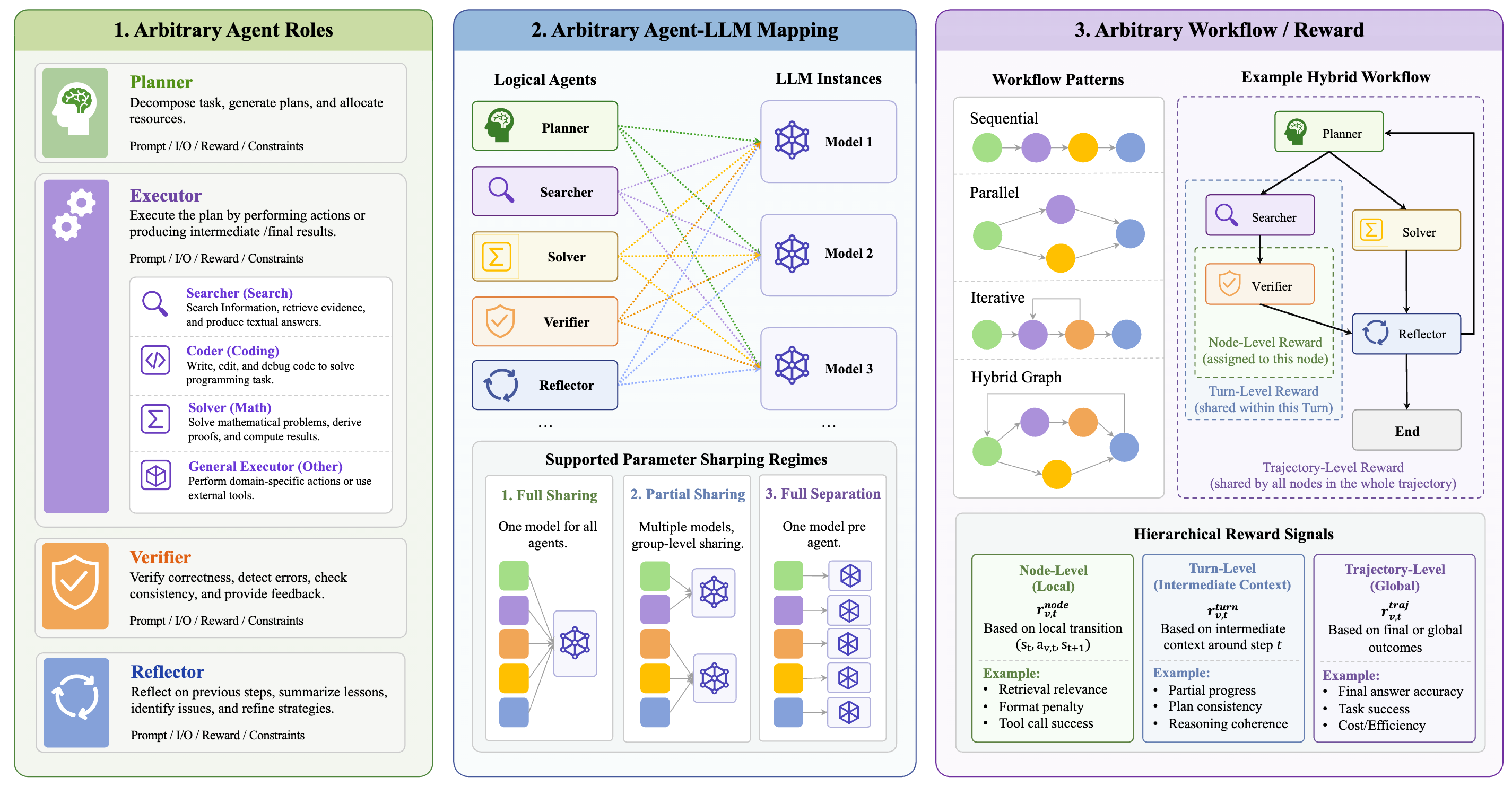
图 1: UnityMAS-O 的核心抽象。用户定义逻辑角色、工作流图、奖励函数,以及角色到物理模型的映射关系。
从“编排流程”到“训练流程”
UnityMAS-O 的基本思想可以概括为:用户首先定义多智能体工作流,框架随后将这套工作流转化为一个可训练的多智能体强化学习问题。
在这一过程中,系统主要围绕四类核心对象展开:逻辑角色、工作流图、角色到物理模型的映射关系,以及基于多智能体轨迹的奖励分配机制。
也就是说,训练目标不再只是判断“某个模型这次回答得如何”,而是进一步关注“这一整套协作过程是如何完成任务的”。
这一设计背后对应着一个实际需求。许多 Multi-Agent 系统在推理阶段可以顺利运行,是因为 prompt、路由规则和角色分工已经由人工事先设定好;但进入训练阶段之后,框架往往难以判断不同角色在最终结果中分别承担了怎样的责任。
一个答案最终正确,贡献来自检索 agent、总结 agent,还是最后生成答案的 agent?如果中间某一步丢失了关键信息,训练信号又应当如何传递回相应角色?传统的单策略训练框架并不擅长处理这类跨角色、跨步骤的信用分配问题。
图结构轨迹:让中间过程进入训练
UnityMAS-O 的做法是将多智能体执行过程记录为图结构轨迹,而不是简单地压缩成普通的输入输出样本。这样,检索结果、工具调用、中间状态、验证反馈、反思修正等信息都可以被纳入训练流程,奖励也可以进一步分配到具体角色和具体轮次。
对于多智能体系统而言,这种建模方式比仅依据最终回答进行优化更贴近真实的协作过程。
角色与模型解耦:同一个workflow,可以有不同训练形态
另一个重要设计是将“逻辑角色”和“物理模型参数”解耦。逻辑角色指的是工作流中的 planner、retriever、coder、reflector等功能模块;物理模型则是底层真正参与生成和训练的 LLM。二者并不必须一一对应:一个模型可以承担多个角色,多个角色也可以由不同模型分别负责。
基于这一设计,框架可以自然支持全共享、全独立和部分共享三类常见设置。对于实际系统构建而言,这一点直接关系到资源成本、角色专门化能力和训练稳定性之间的权衡。
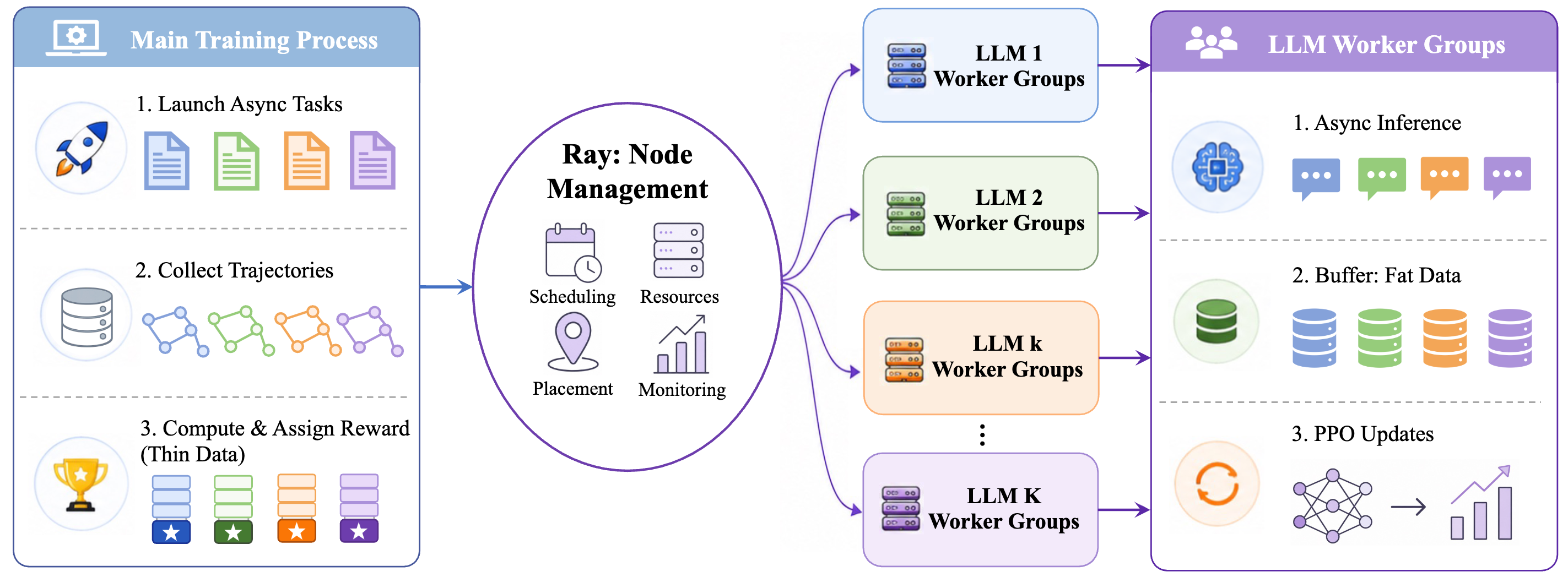
图 2: UnityMAS-O 的分布式训练架构。中央控制器维护工作流执行与奖励计算,本地 worker group 负责模型更新。
系统实现:控制流程与模型更新分离
在系统实现上,UnityMAS-O 采用中心控制器与模型本地 worker group 相结合的结构。
控制器负责执行工作流、调度角色、调用工具、计算与汇总奖励并维护全局状态;worker group 则负责生成、缓存 rollout、计算 advantage,并执行 PPO 模型参数更新。
这样的拆分使工作流控制和模型训练相对独立:前者决定“流程如何运行”,后者决定“模型如何更新”。同时,不同角色到不同物理模型的映射也可以通过配置完成切换,而不需要重写整套pipeline。
从用户使用角度看,这套框架的流程相对清晰:先定义角色,再定义角色之间的执行图;随后指定各个角色由哪些物理模型承担;接着运行工作流、收集轨迹并计算奖励;最后将相应数据路由回对应模型完成更新。
论文在这一层抽象上进行了较系统的设计,因此它既可以支持问答搜索类工作流,也可以扩展到代码生成这类更长链条的闭环任务。
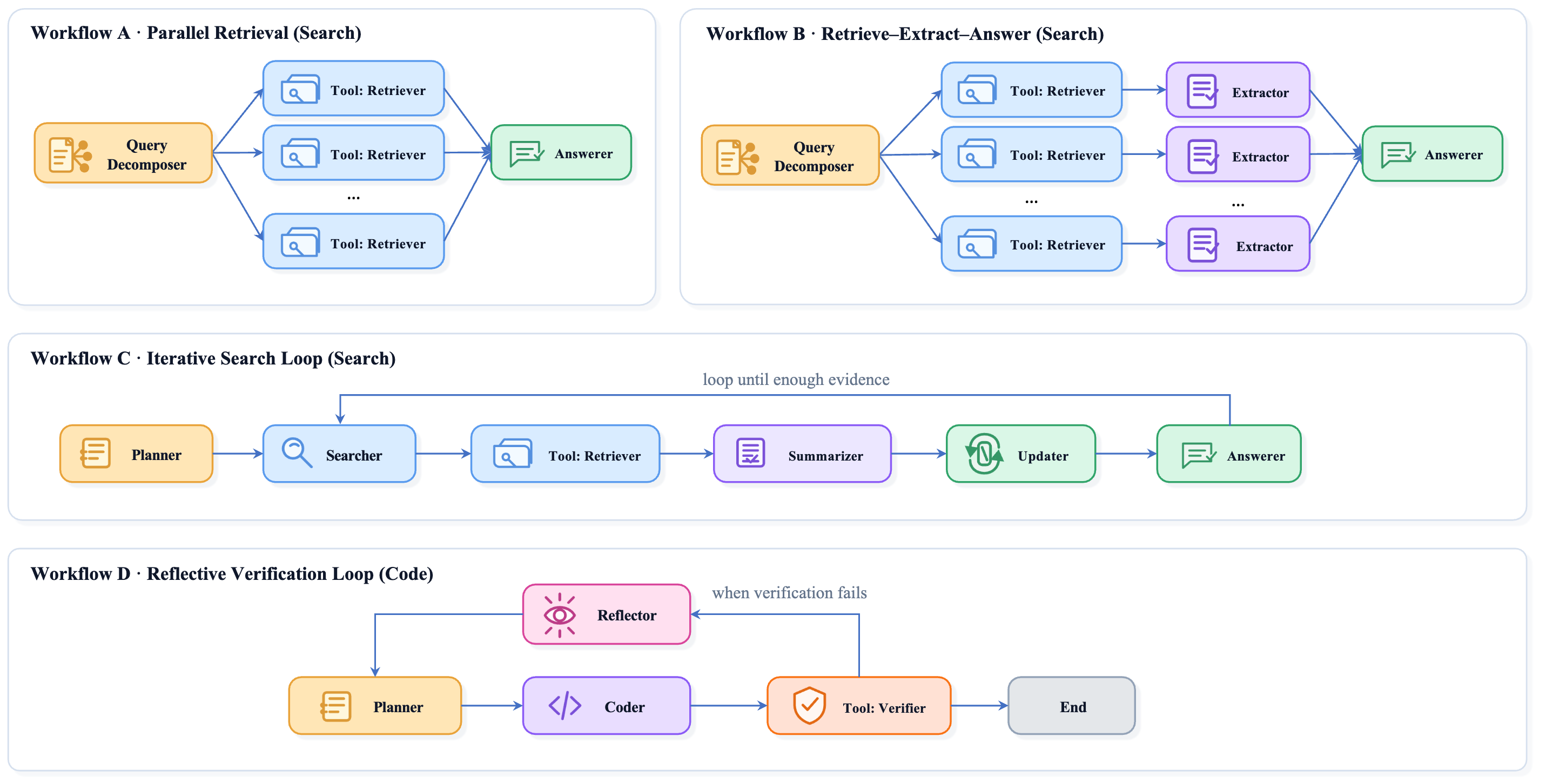
图 3: 论文中用于实验的四类工作流,包括三种搜索/问答流程和一种迭代代码流程。
实验设置:从问答搜索到迭代式代码生成
实验部分主要覆盖两类任务。第一类是检索增强问答和agentic search,使用 Natural Questions和HotpotQA 作为数据集;第二类是迭代式代码生成,采用三轮的Plan->Code->Verify->Reflect工作流,其中验证器会直接执行测试用例,并根据程序是否通过测试给出反馈。
QA与搜索任务:提升来自整个协作链路
在QA和搜索任务上,实验结果显示,经过多智能体强化学习训练后,论文评测的各类工作流在验证集 F1 上均取得提升。这种提升并不局限于某一种模型规模或某一种 workflow。尤其在小模型设置下,训练带来的变化更为明显。
例如在 0.5B 模型规模下,部分工作流在训练前几乎不具备稳定可用性,而训练后能够达到更具实际意义的性能区间。这表明,训练所改善的并不只是最终回答 agent 的输出能力,也包括多角色链路中的协作质量。
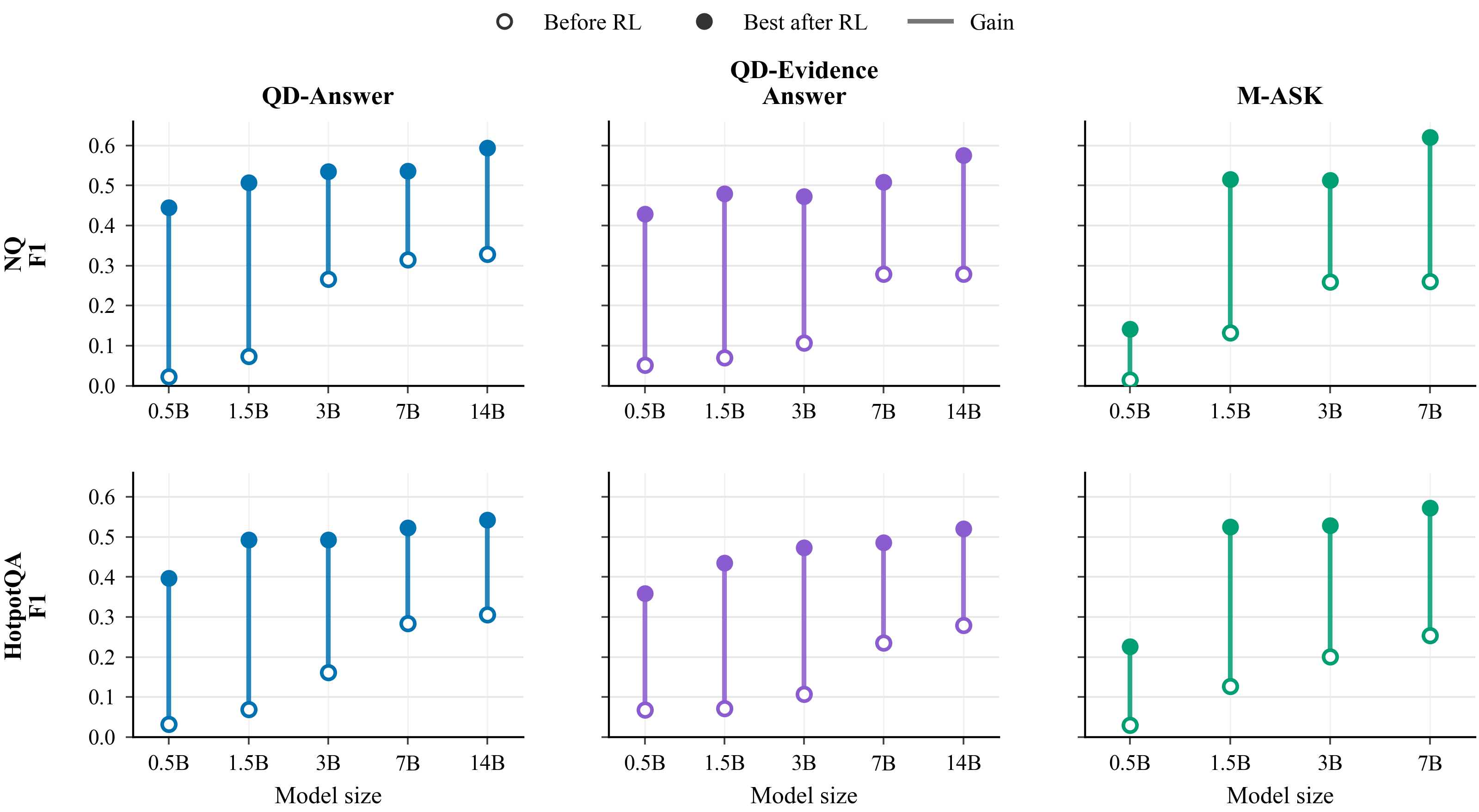
图 4: QA 任务中,多智能体强化学习训练前后在验证集 F1 上的提升。
参数共享:不是每个角色都必须独占一个模型
论文还比较了共享参数与独立参数两种设置。以 HotpotQA 上的 M-ASK(多轮迭代)工作流为例,独立参数版本在收敛速度上略有优势,但共享参数版本最终也能够达到接近的验证F1。
这一结果说明,多智能体工作流并不一定要求每个角色都配备独立模型;在资源受限或希望降低系统复杂度的场景下,参数共享同样可以支持有效训练,并保持较为接近的性能表现。
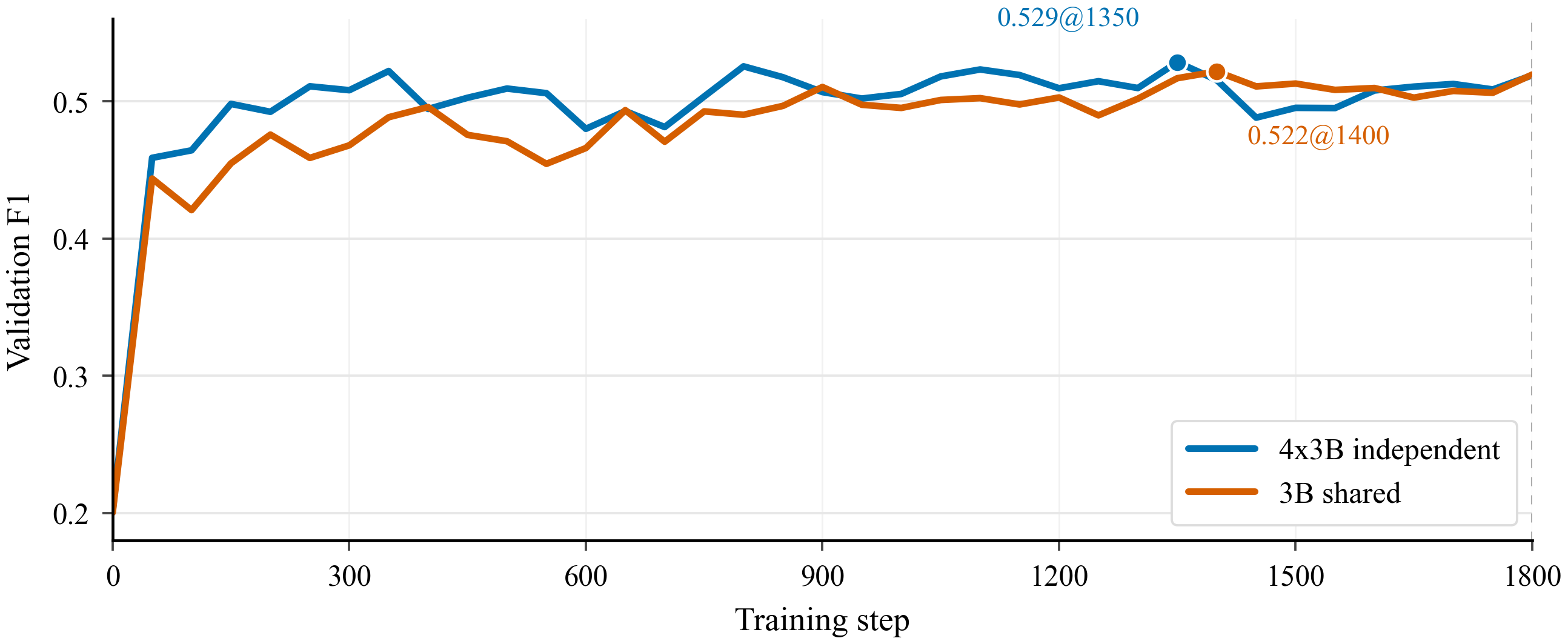
图 5: 在 HotpotQA 的 M-ASK 工作流上,共享参数与独立参数设置的验证 F1 走势接近。
代码任务:用测试通过率检验多轮协作
代码任务的结果进一步展示了该框架在长链条闭环任务中的作用。与基于文本相似度或主观评分的奖励不同,这一任务的评价标准是生成代码能否通过完整测试。论文报告的指标是 held-out test all-passed rate。
在该指标下,3xQwen3-4B 从 0.255 提升到 0.686,3xQwen3-8B 从 0.290 提升到 0.738。这一提升表明,训练带来的收益不仅体现在单轮代码生成能力上,也体现在 planner、coder、reflector 在多轮验证与修正过程中的协作方式上。
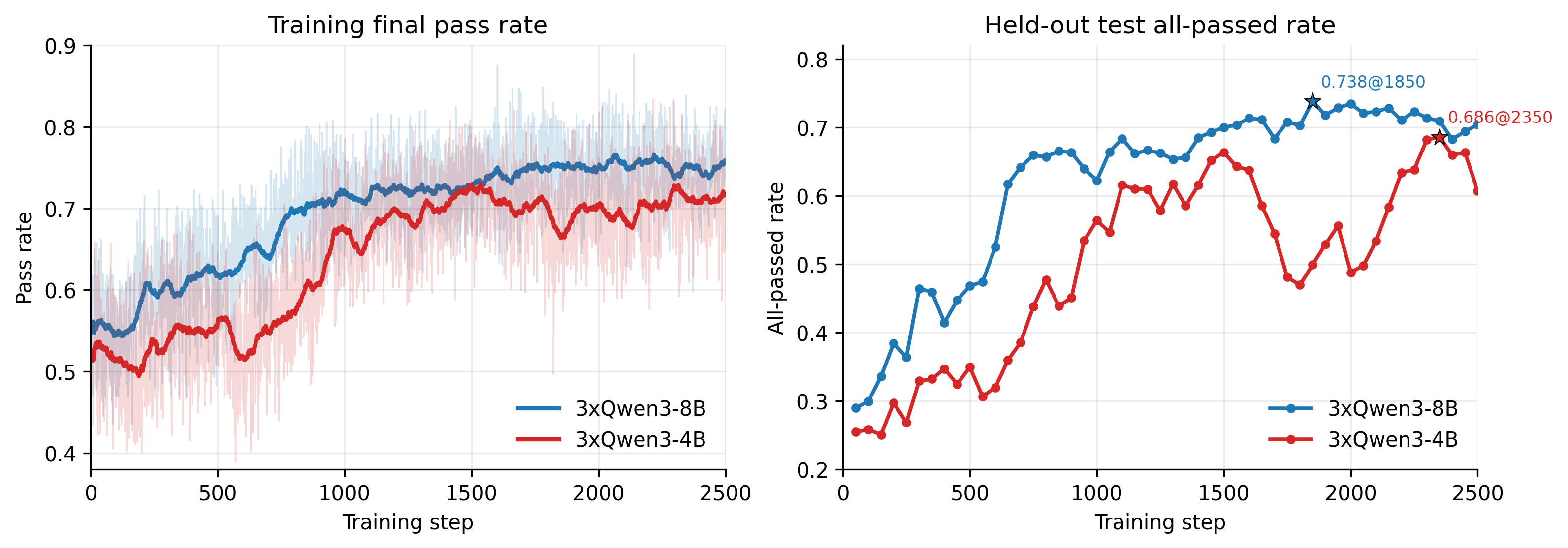
图 6: 迭代式代码工作流的训练动态。
更早通过测试:协作效率也在提升
代码任务中还有一个值得关注的现象。该工作流最多允许三轮验证,如果某一轮已经通过测试,系统就会提前停止。论文结果显示,随着训练推进,平均使用的验证轮次明显下降。这意味着训练后的系统不仅更容易生成正确程序,也能够在更少的反思和修正步骤内完成任务,体现出更高的协作效率。
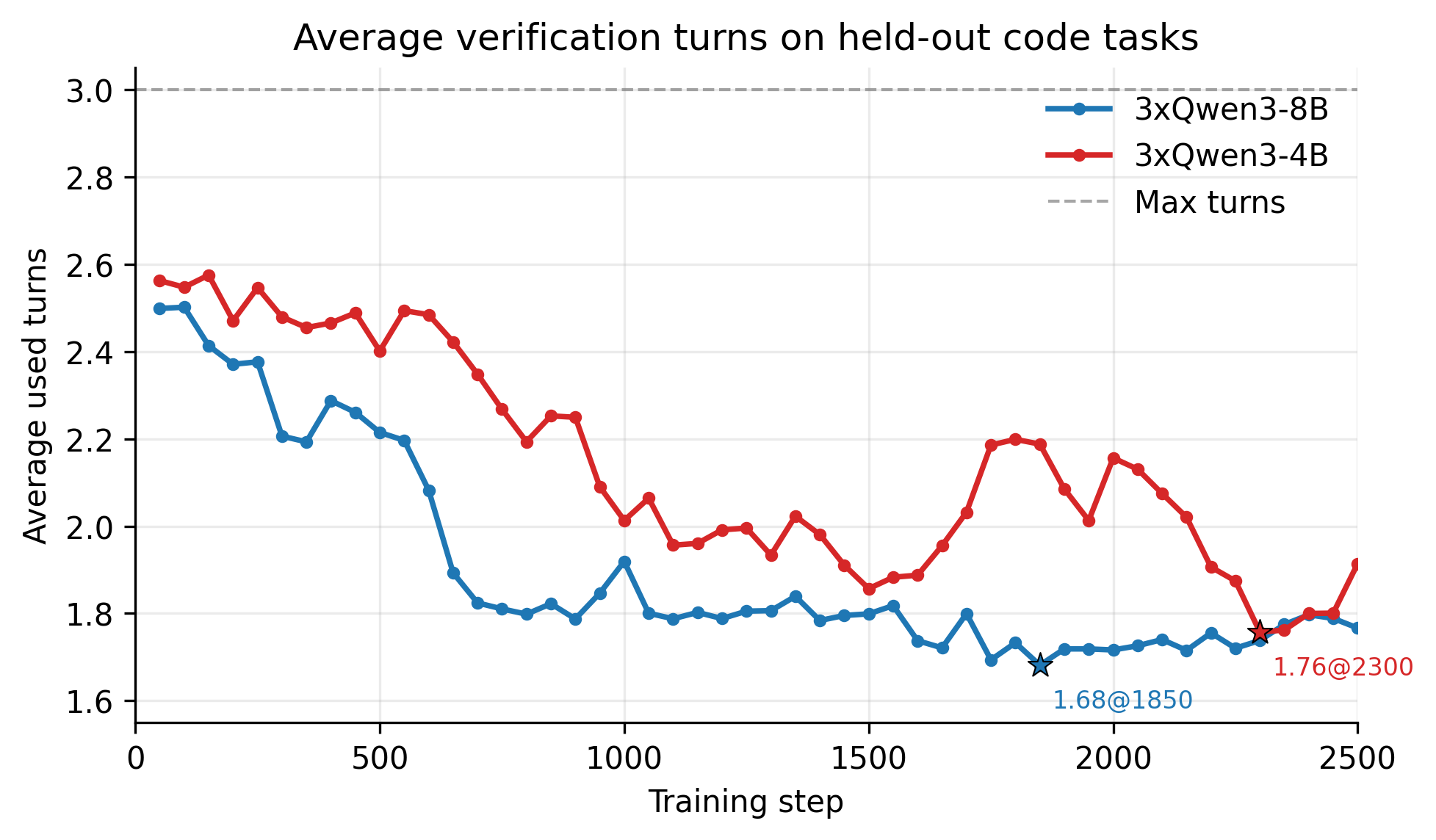
图 7: 训练后,代码工作流平均使用的验证轮次下降。
小结
从更大的研究背景来看,UnityMAS-O 回应的是 LLM 应用形态中的一个重要变化:复杂任务越来越可能由多个角色协同完成,而不是依赖单个大而全的 agent 独立解决。在这种趋势下,训练框架也需要从单一策略优化扩展到对工作流结构、角色关系和信用分配机制的联合建模。
UnityMAS-O 的意义正在于此。它关注的不是如何设计一个更复杂的 agent,而是当用户已经拥有一套多智能体工作流之后,如何将这套工作流系统化地接入强化学习训练;如何比较不同的参数共享方案;以及如何将奖励信号分配给真正影响任务结果的角色和步骤。
从这一角度看,UnityMAS-O更接近于为 LLM 多智能体系统提供一层训练基础设施。
当然,UnityMAS-O 并未解决多智能体训练中的所有问题,但它明确指出了一个关键方向:Multi-Agent 系统不应长期停留在 prompt 编排和人工路由阶段,工作流本身也应当成为可优化对象。
随着多智能体系统在搜索、代码、复杂推理和工具使用等任务中持续发展,如何让这些系统具备可训练、可复用和可扩展的优化能力,将成为后续研究和工程实践中的重要问题。