📄 arXiv: https://arxiv.org/abs/2606.17199
Qwen3、MiMo-V2、GLM-5、DeepSeek-V4——如果你留意过这些模型的技术报告,你会发现它们的post-training pipeline里都有同一个模块:On-Policy Distillation(OPD)。student自己 rollout,teacher逐token给 feedback,既解决exposure bias,又提供比outcome reward更密集的学习信号。OPD已经成为LLM后训练的标配。
但我们实践中发现一个问题:sampled-token OPD训不稳。accuracy前几百步先跌后涨,response length大幅震荡,最终还比full-vocab OPD差了8个点以上。标准反应是加clip、tanh、z-score等reward稳定技术——都是在reward已经爆炸之后做后处理。
我们试图从一个更根本的角度思考:如果从reward shaping的角度看,log-ratio reward 本身,是不是就不该用?
这篇工作 PowerOPD 的回答是:log-ratio 从数学上就有结构性缺陷——它无界。而这个无界性不是后处理能修复的。把log替换成Box-Cox幂变换,得到一族天然有界、符号一致的reward,不仅修复了训练不稳定,还超过了full-vocab OPD,同时省了59.2% 的训练时间和 23.1% 的GPU显存。
在单个 benchmark上,PowerOPD比vanilla OPD最高提升 +16.75Avg@8 / +15.00Pass@8。
东方理工、香港理工大学、上海交通大学、University of Waterloo
先看全貌
在展开公式之前,先把整篇文章的逻辑压缩成五个要点:
- 诊断:vanilla OPD的log-ratio reward无界,产生极端梯度方差,且极端reward集中在rollout早期、贯穿整个训练过程
- Post-hoc 修补无效:clip/tanh在log已经爆炸之后才压缩,太晚;z-score 可能翻转reward符号,比不修还差
- 方法:PowerOPD 用 Box-Cox 幂变换替换 log,reward 天然有界(\in [-1,1])且符号一致,一行公式:r_t^\alpha=\pi_T^\alpha-\pi_\theta^\alpha
- 结果:超vanilla OPD 最高 +6.37 Avg@8/+5.71 Pass@8,超 post-hoc 最高 +3.01/+3.54,超 full-vocab OPD 最高 +2.59/+8.90,同时比full-vocab 省59.2% 时间、23.1% 显存
- \alpha的可解释性:\alpha是概率区域选择器——越大越聚焦高概率token、越抑制低概率噪声,一张 heatmap 一眼看出
OPD = dense-reward RL
OPD 的梯度形式上就是一个 dense-reward policy gradient。这里快速回顾核心推导。
OPD 最大化负 reverse KL:
由于自回归分解,sequence-level log-ratio 拆成 token-level log-ratio 之和。对应的 policy gradient 是:
这一步的关键含义是:从RL的角度看,teacher-student log-ratio是直接乘在 policy gradient 前面的 reward。
所以,如果不从KL估计的角度看,而是从RL的reward shaping角度看,一旦这个 reward 的 shaping 有问题,每一步梯度更新都会被它牵着走。
Vanilla OPD 到底有多不稳?
在讨论reward设计之前,先看一组训练曲线,直观感受vanilla OPD的问题。
在 Qwen3-4B teacher→Qwen3-1.7B student的MATH-500 设置下,vanilla OPD有三个典型症状。
第一,sample efficiency 差。 训练前 300 步,accuracy 不升反降——有了密集的token-level supervision,student居然在变差。直到300步之后才开始恢复。
第二,generation dynamics 不稳定。 看图 2(b) 的 length 曲线:平均 response length 在前 400 步剧烈震荡,说明 student 在训练过程中不断进入不稳定的生成区域,生成忽长忽短的 response。
第三,和 full-vocab OPD 差距巨大。 vanilla OPD 最终只到 54.93% accuracy,而 full-vocab OPD 达到 63.12%,差了 8.19个点。teacher 准确率是 74.89%,vanilla OPD 只恢复了 teacher 能力的 69.44%。
如果只看这些曲线,很容易把问题归因为 "sampled-token estimator 方差大,RL 本来就难训"。
但问题比这更具体——它出在 reward 本身。
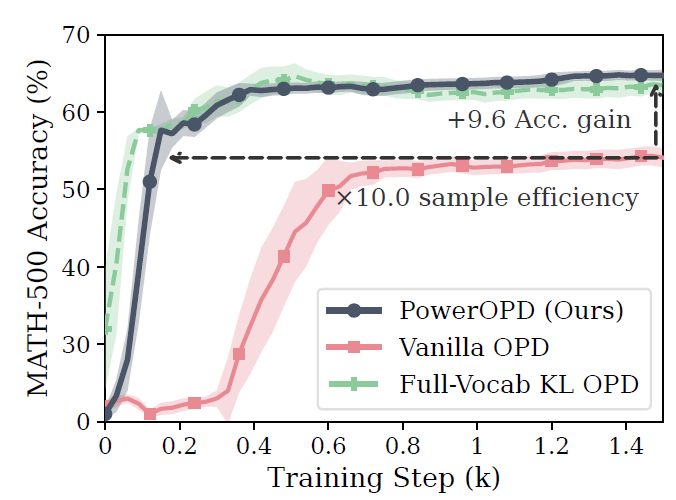
图 1:MATH-500 训练曲线(Qwen3-4B → Qwen3-1.7B)。PowerOPD 比 vanilla OPD 精度高 9.6 个点,达到同等准确率所需 step 少 10 倍。
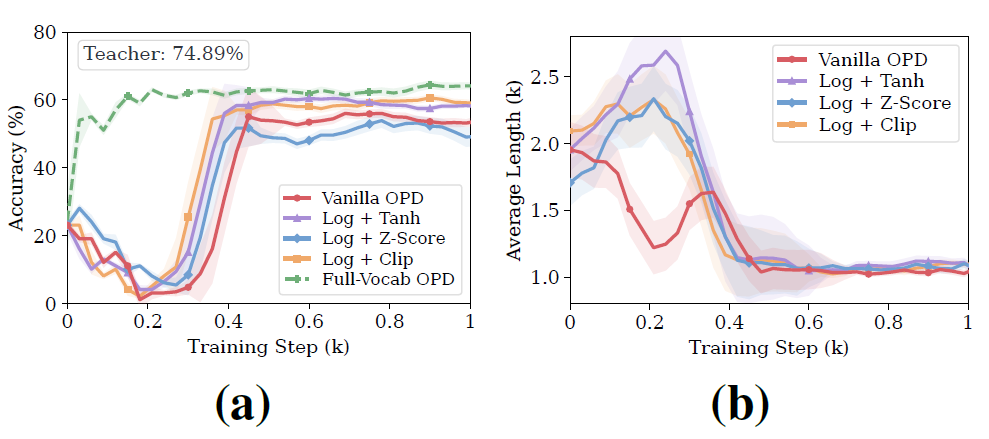
图 2:vanilla OPD 的训练病理。(a) accuracy 先跌后涨,最终落后 full-vocab OPD 8 个点以上;(b) response length 在前 400 步剧烈震荡。clip、tanh、z-score 三种 post-hoc 修补均不能同时解决这两个问题。
log-ratio reward 到底哪里坏了?
"训不稳"不是一个笼统的RL问题。论文直接去看 reward 分布,发现 log-ratio reward 有三个具体的结构性病理。
病理一:reward 方差极大,负尾接近 -50
student 采到自己觉得还行、但 teacher 几乎不认可的token时,\log \pi_T 直接把reward拉到极负。统计发现,reward 负尾接近 -50。一个 token的reward变成-50,它对单次更新的杠杆就是正常token的几十倍。
病理二:极端 reward 集中在 rollout 早期
这些极端值不是均匀分布的——它们大量集中在rollout开头几个token。early token决定后续prefix distribution,一旦被极端 reward 推歪,后面的上下文也被带偏,形成反馈回路:
这解释了为什么vanilla OPD的 response length会大幅震荡——不是简单的长度偏好问题,而是early prefix被高方差reward扰动后整条轨迹漂移了。
病理三:极端reward不会自然消退
如果只是初始化问题,warmup 几百步就好了。但论文显示,极端正负reward贯穿整个训练过程。这不是 transient,而是 log-ratio 的结构性问题。
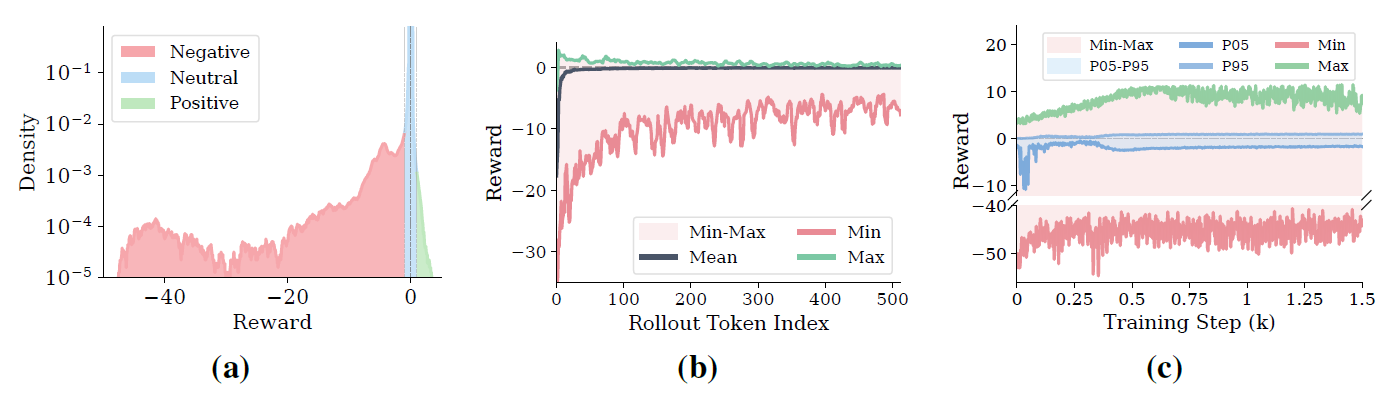
图 3:vanilla OPD 的 reward 病理。(a) reward 分布重负尾,接近 -50;(b) 极端值集中在 rollout 早期 token;(c) 极端值贯穿整个训练过程,不会随训练消退。
为什么 clip、tanh、z-score 没救?
论文比较了三种 post-hoc stabilization:
- Clip:硬截断到 [-1, 1]
- Tanh:平滑压缩到 [-1, 1]
- Z-Score:按 batch 均值方差标准化
结果:全都不能真正解决问题(回看图 2)。
clip 和 tanh 的问题是时序上的——它们在 log-ratio 已经把低概率差异放大成极端数值之后才出手。哪些 token 被 log 变成"高杠杆 token"这件事已经发生了,后面再压缩只是在补救后果。
z-score 的问题更严重:batch 标准化会改变 reward 符号。但在 OPD 里,reward 符号就是学习方向——teacher 概率更高应该是正 reward,student 概率更高应该是负 reward。一旦符号翻转,不是尺度问题,而是直接把学习方向搞反了。
问题不在后处理不够,而在 log 本身。真正需要改的,是从概率到 reward 的映射函数。
诊断清楚了,药方也就清楚了
三个病理都指向同一个根因:log从第一步就不该出现在reward里。我们需要的不是log之后的后处理,而是在概率→reward的映射层面,直接把log换掉。
一个合理的OPD reward至少要满足两条性质:
P1:有界性。 reward不能无界,否则rare sampled token会产生 catastrophic gradient update。
P2:符号一致性。 teacher概率更高→正reward,student概率更高→负reward,相等→零。
vanilla OPD的log-ratio满足P2(log单调递增),但不满足P1(log在0附近发散)。
观察log-ratio的代数结构:\log p - \log q = h(p) - h(q),其中 h = \log。这个 "transform-then-subtract" 结构本身很好——只要h严格单调递增,符号一致性就自动成立。问题只在h = \log把[0,1]映到 (-\infty,0],在0处发散。
修复方案:保留transform-then-subtract结构,把h换成一个在[0,1]上有界且单调递增的函数。Box-Cox 幂变换正好满足:
代入 transform-then-subtract,吸收常数 1/\alpha 进学习率,得到 PowerOPD reward:
直接验证:
- P1:p^\alpha,q^\alpha \in [0,1],所以r_t^\alpha\in [-1, 1]。有界。
- P2:h(x)=x^\alpha严格单调递增,所以 p>q\Rightarrow r_t^\alpha > 0。符号一致。
而vanilla OPD的log-ratio正是 \alpha\to 0 时的退化极限——Taylor 展开 x^\alpha =1 + \alpha\log x+o(\alpha)可以直接验证:
vanilla OPD 不是另一个完全不同的设计,而是 PowerOPD 在 \alpha \to 0 时的无界极限。PowerOPD 把 OPD 从这个退化极限拉回到一族有界、稳定的 reward shaping 函数里。
\alpha:一个概率区域选择器
先看图再讲道理。
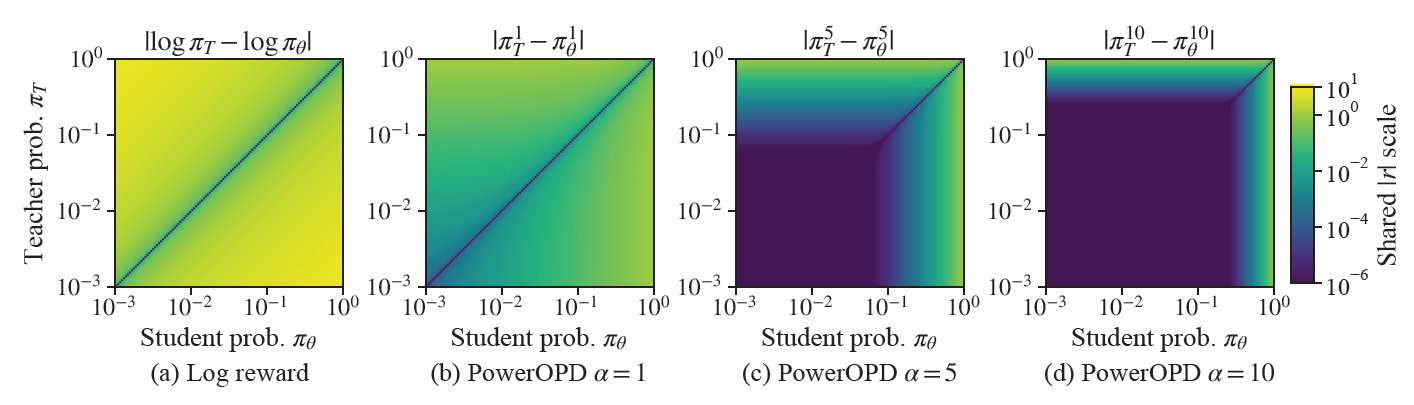
图 4:reward 在 (\pi_T, \pi_\theta) 联合概率空间上的分布。(a) log-ratio 只看比值,低概率区域一样敏感且无界;(b-d) PowerOPD 随 \alpha 增大,低概率区域逐渐变成"死区",reward 集中到高概率 token。这张图一眼看出 PowerOPD 和 log-ratio 的本质区别。
看出来了吗?
log-ratio只看比值\pi_T / \pi_\theta,对绝对概率水平完全盲目。p=0.002, q=0.0001 和 p=0.2, q=0.01,ratio都是20,log给一样大的reward。但前者teacher和student都觉得这个token几乎不可能,只是在极低概率区域有个噪声差异;后者teacher真的认为这个token plausible。
PowerOPD则把reward幅度和绝对概率挂钩:
\alpha越大,"高概率"的门槛越高。\alpha=1 时0.6算高概率,\alpha=10 时0.6^{10}\approx 0.006,已经快被过滤掉了。
所以\alpha是一个"概率区域选择器":
- 小\alpha:保留更宽的 token-level 信号
- 大\alpha:过滤低概率噪声,聚焦高支撑 token
- 极限\alpha\to0:退化回log-ratio,重新暴露无界问题
这也解释了实验中一个非常稳定的趋势:更大的\alpha通常带来更高 accuracy、更短 response、更稳训练。
实验:PowerOPD 不只是更稳,还更强
在四组Qwen3 teacher-student设置(0.6B和1.7B student×4B 和 8B teacher)和六个数学推理 benchmark 上做了全面评估。
第一个结论:PowerOPD 大幅超越 vanilla OPD
跨四组设置的平均提升是 +4.47 Avg@8/+4.06 Pass@8。最大 benchmark-averaged gain 出现在 Qwen3-4B → Qwen3-0.6B 设置:Avg@8 从19.13提升到 25.50(+6.37),Pass@8 从 36.18 提升到41.89(+5.71)。单个benchmark上,最大提升达到 +16.75 Avg@8(AMC23)和 +15.00 Pass@8(AMC23)。
第二个结论:超越所有 post-hoc 修补
最大 benchmark-averaged gain 是 +3.01 Avg@8/+3.54 Pass@8。z-score 甚至在部分设置下比 vanilla OPD 还差,和我们的诊断一致——符号翻转比不修更糟。
第三个结论——这个最反直觉
Sampled-token 方法在传统认知里就是 "便宜但有方差的近似"——比 full-vocab 省计算,但效果一定更差。
但 PowerOPD 说明恰好相反。sampled-token+bounded reward,不仅比full-vocab OPD更快(省 59.2% wall-clock time、23.1%GPU memory),效果还更好:最大提升 +2.59Avg@8/+8.90 Pass@8。
这说明 sampled-token OPD 的瓶颈从来不是 "sampled" 本身,而是 reward shaping 没做好。当 reward 从无界 log-ratio 换成有界 power reward 后,sampled-token OPD反而变成了更高效也更强的训练目标。
\alpha 越大,效果越好、长度越短
在 Qwen3-4B→Qwen3-0.6B 设置下:
- \alpha=0.1:Avg@8= 24.16,Pass@8=39.61,平均长度 2291
- \alpha=500:Avg@8 = 25.50,Pass@8=41.89,平均长度 1875
在 Qwen3-4B→Qwen3-1.7B 设置下,Avg@8 从33.89提升到 36.02,平均长度从1900降到 1579。
和 \alpha 的"概率区域选择器"解释完全一致:大 \alpha 把低概率区域的噪声压掉,模型主要从 plausible token 上学习,训练更稳,response 也更受控。
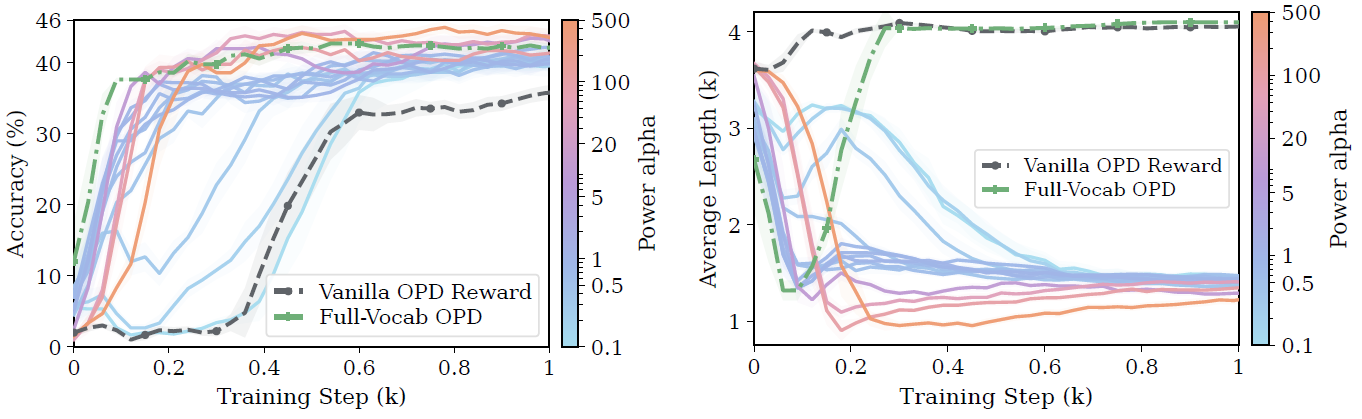
图5:\alphasweep的训练动态(Qwen3-0.6B student,左图 Qwen3-4B teacher,右图 Qwen3-8B teacher)。更大的 \alpha 收敛更快、最终精度更高、response length 更短且更稳定。vanilla OPD(灰色虚线)有明显的 accuracy delay 和 length 失控。
梯度范数:不是感觉更稳,是 3000 倍的差距
PowerOPD 梯度范数始终在 0.25–0.35,而 vanilla OPD 初始 spike 接近 10^3——差了 3000 倍以上。
post-hoc方法也好不到哪去:clip 和 tanh 仍然频繁超过10,z-score 从 3 增长到10以上。
这说明 PowerOPD 的稳定性不是来自偶然调参,而是来自 reward shaping 本身。log-ratio 会把低概率区域的微小差异放大成极端梯度;power reward 则从一开始就把 reward 限制在 [-1, 1],避免 rare sampled token 主导整个 update。
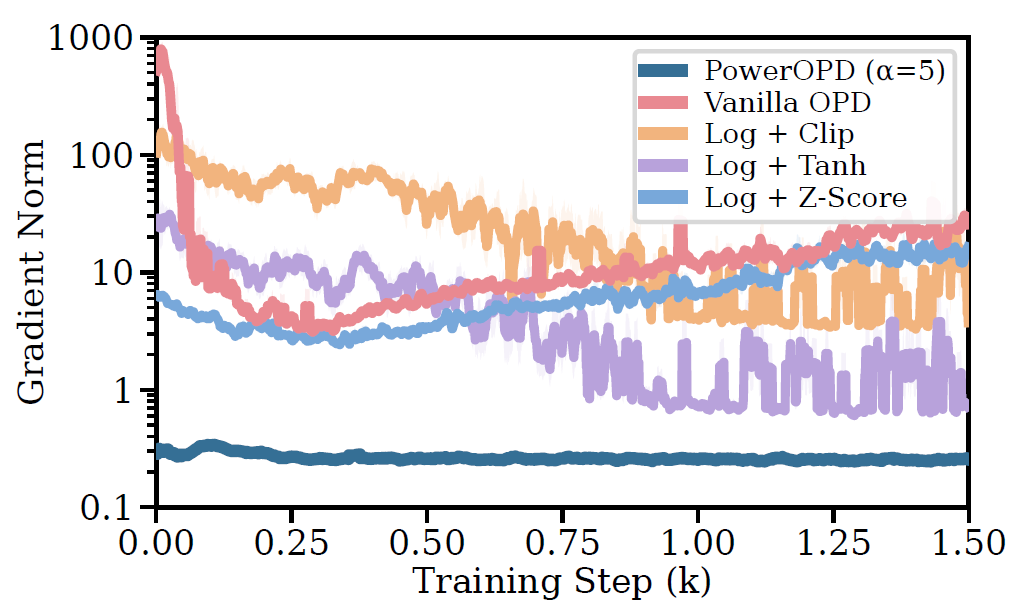
图 6:梯度范数对比(Qwen3-4B → Qwen3-1.7B)。PowerOPD 曲线几乎贴地(~0.3),vanilla OPD 有接近 1000 的初始 spike,后期仍在 20 以上。post-hoc 方法只能部分缓解。
效率:sampled-token 的天然优势
| 指标 | Full-vocab OPD | PowerOPD | 节省 |
|---|---|---|---|
| TFLOPs/update | 402.7 | 346.6 | 13.9% |
| Wall-clock time/step | 22.14s | 9.03s | 59.2% |
| Peak GPU memory | 78.99 GiB | 60.72 GiB | 23.1% |
PowerOPD 不需要计算整个 vocabulary 的 KL,只需要 sampled token 的概率幂次差。这不是近似——而是一个更好的 reward design 恰好也更省计算。
Takeaway
OPD 训练不稳定,不是on-policy本身的问题,也不是RL技巧没调好。
真正的问题是:vanilla OPD把无界 log-ratio直接当reward,于是低概率区域的偶然差异被放大成极端梯度。PowerOPD 的解法很干净——把log换成 bounded power reward,用一个指数 \alpha控制reward聚焦的概率区域。一行公式,drop-in替换,不改rollout、不改teacher scoring、不改policy-gradient框架。
最终效果:更稳(梯度 3000×↓)、更强(Avg@8/Pass@8 显著提升)、更省(59.2%time↓、23.1%memory↓)。
📄 arXiv: https://arxiv.org/abs/2606.17199