当AI Agent开始从“工具调用者”走向“长期协同者”,记忆便成了决定其天花板的关键。然而,现有的记忆方案正面临一个尴尬的悖论:Agent 往往拥有一本厚厚的“交互日记”,却缺乏一套真正的“知识储备”。
近日,由UIUC、清华与微软研究院 联合提出的PlugMem引起了广泛关注。作为一个任务无关的插件式记忆模块,PlugMem的核心贡献在于提出了一套完整的知识抽象框架:它不再盲目追求“记住更多”,而是通过结构化、检索与推理子模块,将低密度的原始日志转化为可跨任务复用的决策资产。
实验结果表明,PlugMem不仅显著提升了 Agent在复杂环境下的决策成功率,更大幅降低了推理过程中的上下文成本。它正带领我们告别那种低效的“压缩版流水账”,开启Agent的高密度知识记忆时代。

告别 Agent 的“压缩版流水账”
在为LLM Agent设计长期记忆时,一个现实问题很快就会浮现出来:原始交互轨迹太长,全部塞进上下文窗口 LLM 不会用,存到记忆系统里噪声太多也不好管理。
因此,社区很早就开始尝试各种“压缩记忆”的方案:从最基础的对话摘要,到向量数据库中的语义检索,再到构建带有关系结构的知识图谱。
这些方法确实缓解了上下文长度的问题,但它们往往只是在形式上压缩信息,而没有真正改变记忆的本质。换句话说,我们只是把一段冗长的行为日志,变成了一段更短的行为日志。
举个例子,用户让Agent帮忙下单一个苹果。真正有用的记忆是“帮用户下单一件商品,要先打开A网站,在搜索框搜索,选择合适的商品,最后加入购物车”这种知识。这个知识可能来源于之前Agent为用户下单一个水杯的记忆:
用户:请帮我下单一个水杯
Agent:要帮用户下单一个水杯,我们先试试A网站……A网站用户没注册账号……试试B网站……成功了!
但如果只是简单地进行摘要,这段记忆会被压缩成:“用户让我下单了一个水杯……我打开了A网站……我打开了B网站”。以知识形式存在的记忆,可以帮助Agent在下单苹果时直接打开B 网站;简单压缩概括得到的记忆,可能只能让 Agent 记得之前做了什么,无法理解要跳过A网站直接打开B网站的逻辑,导致再犯同样的错误。
核心理念:从“记住更多”到“记住更有用的”
PlugMem的出发点正是对这一问题的重新思考:如果Agent的记忆不再只是记录过去,而是提炼有用的经验,会发生什么?
这意味着,系统需要把零散的交互轨迹进一步加工,把它们转化为更抽象、更稳定的知识单元。
为此,作者借鉴了认知科学中关于人类知识的经典划分,将Agent的长期记忆整理为两种高密度的知识形态:
- 事实性知识(Propositional Knowledge):描述世界状态、实体属性或用户特征等知识。例如:“用户对乳制品过敏”“某类网站通常在价格筛选页面提供排序功能”。
- 程序性知识(Prescriptive Knowledge):描述在某种情境下应该采取怎样的行动路径。例如:“在调查商品的价格区间时,可以先按价格从小到大排获得最小值,再按价格从大到小排获得最大值”。
当这些知识被沉淀下来之后,Agent在新的任务环境中就不必再回放冗长的历史记录,而是能够直接调用这些高度抽象的经验结论。这种设计带来的变化是显著的:记忆不再是系统负担,而是逐渐演化为一种可以跨任务复用的决策资产。
工程实践:模块化插件的“解耦”艺术
在工程实现层面,PlugMem采取了一个非常务实的策略:它不是一个新的Agent框架,而是一个可以插拔的记忆插件。
这意味着开发者无需重写现有系统,就可以将 PlugMem嵌入到不同的Agent架构中。其核心思想是把“记忆管理”与“任务执行”彻底解耦,使记忆系统成为一层独立的基础设施。
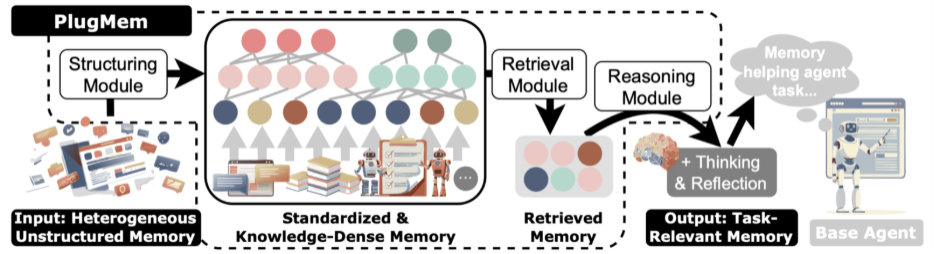
整个模块主要由三个协同工作的子模块组成:
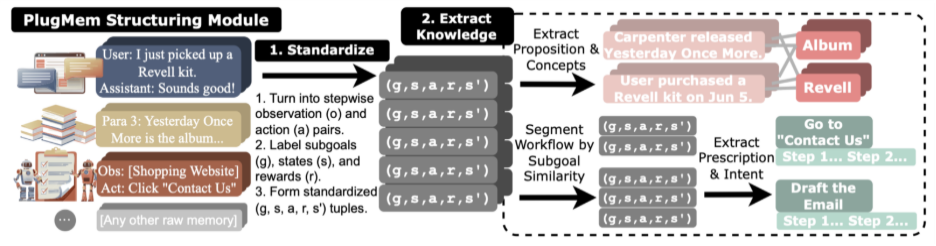
- 结构化(Structuring)模块:首先对原始交互轨迹进行处理,将其拆解为三种不同的知识单元:semantic memory(对应 propositional knowledge)、procedural memory(对应 prescriptive knowledge)、episodic memory(作为前两种知识单元的源头)。这些知识单元随后被组织成一个知识图,供后续使用。
- 检索(Retrieval)模块:当 Agent 进入新的决策状态时,检索模块会根据当前任务,在这张知识图中寻找最有用的知识。它不仅考虑知识内容的相关性,也考虑不同场景下哪种知识最有用。
- 推理(Reasoning)模块:最后一步是对检索到的知识进行整合与过滤,使其与当前任务情境更好地匹配,同时进一步压缩信息量,从而提高整体使用效率。
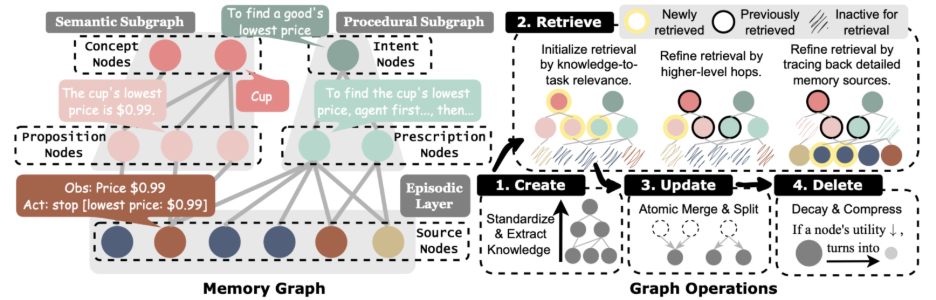
通过消融实验,我们进一步分析了三个子模块是怎么让最后提供给Agent的记忆变得“有用”的:结构化模块提高记忆质量;检索模块保证记忆和当前任务的相关性;推理模块提升效率,并使记忆进一步对齐到当前任务上。
实验验证:当记忆从“历史”变成“经验”
为了验证这种“知识化记忆”的价值,作者把同一套PlugMem模块直接部署到三类完全不同的Agent场景中:
- LongMemEval:考察长期对话中的事实一致性
- HotpotQA:典型的多跳知识推理任务
- WebArena:复杂网页交互环境中的 Agent 决策
这三类任务几乎覆盖了Agent记忆需求的三种典型模式:回忆事实、组合知识、执行操作。
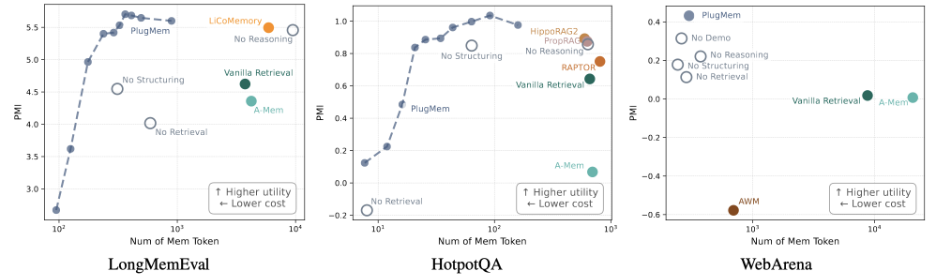
实验结果显示,即使在不进行任务特化修改的前提下,PlugMem依然在三个benchmark上带来了稳定的性能提升。同时,一个更值得注意的变化是:Agent在推理过程中消耗的memory token数量显著下降。
换句话说,PlugMem的优势并不只是“记得更多”,而是单位记忆所携带的信息密度更高。当记忆以知识的形式组织时,Agent往往只需要极少量的关键知识,就能够完成原本需要大量历史上下文才能解决的任务。
论文还提出了一个有意思的评估标准:information density。简单来说,就是衡量“每个memory token为决策带来了多少信息增益”。在这个统一尺度下,PlugMem在三个任务中都表现出更高的信息收益和更低的上下文成本。
进一步地,作者以记忆长度为横轴,以信息增益为纵轴,通过控制PlugMem输出的token数量,绘制出Agent表现随记忆量变化的曲线,得到了一个很符合直觉的结论:
1、一开始记忆量很少,配备PlugMem的 Agent 没有太大优势。
2、此时记忆长度的边际收益很高,稍微增加记忆长度,Agent的表现就能明显提升。
3、随着记忆量不断增加,Agent的表现逐渐饱和,记忆长度的边际收益减少。
4、当记忆长度增加到一定程度后,再增加记忆长度会引入噪声,反而使Agent的表现下降。
写在最后
总的来说,PlugMem这项工作的价值,不在于又发明了一种新的存储格式或者检索算法,而在于它把Agent记忆这件事的讨论方向从“怎么存得更多、查得更快”,转向了“记住什么东西是真的有用的”。
这个区别很关键。过去我们讨论Agent记忆,想的往往还是怎么从海量日志里捞出几句相关的话。但事实是,记忆的价值不取决于它记了多少,而取决于它在关键时刻能帮上多少忙。
PlugMem更像是一个关于记忆的思维框架,而非单纯的技术方案。它把认知科学里语义记忆、程序记忆的划分搬到了Agent身上,让机器也能像人一样,从具体经历里抽出通用经验。