
论文题目:Scoring, Reasoning, and Selecting the Best! Ensembling Large Language Models via a Peer-Review Process
作者信息:Zhijun Chen 1, Zeyu Ji 1, Qianren Mao 2, Hao Wu 3, Junhang Cheng 1, Bangjie Qin 4, Zhuoran Li 1, Jingzheng Li 2, Kai Sun 3, Zizhe Wang 5, Yikun Ban 1, Zhu Sun 6, Xiangyang Ji 5, Hailong Sun 1
(1 北京航空航天大学,2 Zhongguancun Lab, 3 西安交通大学, 4 香港科技大学, 5 清华大学, 6 新加坡科技与设计大学)
论文链接: https://arxiv.org/abs/2512.23213
GitHub:https://github.com/zeyuji/LLM-PeerReview
项目主页:https://zeyuji.github.io/LLM-PeerReview/
TL;DR / 白话总结:
1、" 无监督 LLM Ensemble/Collaboration 问题":如何集成" 从多个不同的 LLM 生成的不同 responses"[1],以得到一份尽可能优质的 response;
2、本文方法 LLM-PeerReview:让模型们针对彼此的回答互相打分(基于 LLM-as-a-Judge,并引入核心的 " 三元翻转" 技巧),随后将多份评分进行聚合推理(averaging or weighted averaging),从而精准锁定“全场最佳”response;
3、方法无监督,无需微调,具有良好的可解释性,同时适用于答案匹配型生成任务与开放型生成任务。
Takeaways/ 你将会获得:
1、基于本文平白的语言,你很容易可以学习到一个简单的 LLM Ensemble/Collaboration 方法,即我们所提出的框架 LLM-PeerReview;
2、欢迎使用我们精心准备的关于 LLM Ensemble 的代码仓库——其中开源了本文所使用到的多个 baselines 和 datasets,或许能成为你研究 LLM Ensemble/Collaboration 的重要材料!(将持续维护,或许也添加新的 baselines 和 datasets):
- 3 种流行任务类型(Fact Recall QA,Math, Instruction Following);
- 4 个常见数据集(TriviaQA、GSM8k、MATH、AlpacaEval);
3、较为丰富的 baselines:
- 模型集合中的各个单一 LLM (比如 Llama-3.1-8B-Instruct、Mistral-7B-Instruct、Qwen2.5-7B-Instruct、Qwen2-7B-Instruct);
- 流行的" 推理后集成方法“Smoothie-Global[2]、Smoothie-Local[2]、Agent-Forest[3];
- 流行的" 推理时集成方法"GaC[4];
- 本文方法的 2 个变体:LLM-PeerReview、LLM-PeerReview-W
4、一行代码运行你所想要跑的 baselines 和 datasets:
bash ./Script/run_baseline.sh --method <METHOD_NAME> --dataset <DATASET_NAME>
那么,快来快速地学习相关的 LLM Ensemble 方法,并且来测评你提出的新 idea 吧!~
1. 背景与方法简介
1.1 背景
近年来,Gemini、GPT、Qwen、Llama 和 DeepSeek 等大模型层出不穷。目前在 Hugging Face 上已有超过 182,000 个模型可用。与此同时,我们可以观察到两个主要方面[1,2,3,4,5,6]:
- 持续存在的性能担忧:尽管 LLMs 可以轻松用于零样本推理,但仍面临准确性有限、幻觉现象以及与人类目标不一致等性能问题;
- LLM 迥异的优缺点:受架构、规模、训练数据、分词方法等差异的影响,不同模型表现出显著的行为差异。针对同一提示词(query/prompt),不同 LLMs 的回答常常表现出明显的差异性。
受集成学习(Ensemble Learning)[7] 的启发,我们认为:针对每个不同的 query/prompt,与其依据公开的模型性能排行榜或其他标准而固定地依赖于某一个 LLM 进行推理,不如同时考虑多个可开箱即用的 LLMs,以综合利用它们的差异化优势。这一概念正是新兴领域"LLM 集成"(LLM Ensemble)的核心关注点 [1]。
LLM Ensemble 领域中的" 推理后集成方法"(Ensemble-after-inference/ Post-hoc ensemble methods)在近些年逐渐流行,并可分为以下两类:
- 先选择后生成(Selection-then-regeneration)方法 (比如,[8][9]):这类方法严重依赖于任务特定的训练数据,且需要微调额外的一个大模型,因此缺乏灵活的泛化性和适应性;
- 基于相似性的选择(Similarity-based selection)方法(比如,[2][3]):这类方法大多是完全无监督的,其核心思想是选择与所有其他 responses 的总相似度最高的那个 response 来作为最终的集成结果。
然而,此类方法的设计仍较为粗糙——主要是因为它们依赖于朴素的基于相似性的选择策略以及较为浅层的相似度度量 (如 BLEU). 总之," 推理后集成" 方法的真正潜力在很大程度上仍未被开发。
当我们重新思考这一研究问题时,我们提出了一个比较根本的问题:在现实世界中,人类会如何从一组候选文本池中选出最理想的那一份,尤其是对于文本质量衡量难度大的场景?
也许最直接且相关的现实案例就是:学术同行评审。受此启发,我们致力于提出一种完全无监督的、尽可能简单的 LLM Ensemble 方法,并提出了具有惊艳实验效果的方法 LLM-PeerReview。
1.2 方法 LLM-PeerReview 简介
1.2.1 方法简介
首先,最重要的,请观察下面所列出的 LLM-PeerReview 示意图(图 1)以及在图片下方的标题和说明部分。
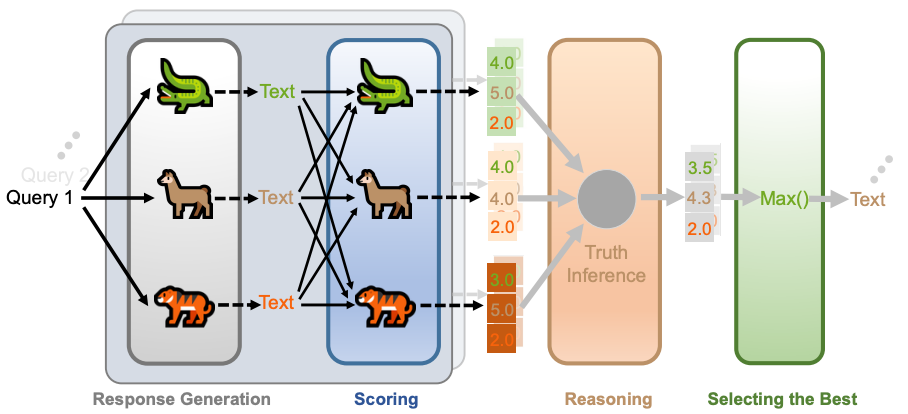
该框架包含三个顺次运行的模块,即 Scoring (评分)、Reasoning (推理)、Selection (选择):
1、评分(Scoring)——每个模型都可以是审稿员:
针对同一 prompt/query 的多个候选 responses,我们复用模型集合中的 LLM 作为评估者(LLM-as-a-Judge),对每个回答打分(如:5.0 表示 Strong Accept)。
为了减少 judge 过程中的固有偏差,我们提出了关键的" 翻转三元评分技术"(Flipped-triple scoring trick)——这是提升整个框架效能的基石。
2、推理(Reasoning)——汇聚多份审稿意见并给出最终分数:
我们将多份评分进行聚合,衍生出两个版本。
- LLM-PeerReview:最直接的简单平均策略(Simple Averaging);
- LLM-PeerReview-W:引入权重感知,根据不同 LLM 的“评审水平”赋予不同的打分权重;
3、选择(Selection)——在一个论文候选池中挑选出得分最高论文:
对于每个 prompt/query,我们只锁定得分最高的那个 response 作为最终集成结果。
1.2.2 更多方法细节
对于 LLM-PeerReview 中的评分 (Scoring)过程,我们首次提出了" 翻转三元评分技术"(Flipped-triple scoring trick)。
在传统的 LLM-as-a-judge 中,常常让模型一个个给回答打分(Point-wise Scoring)虽然简单,但模型往往会有“固定偏见”(尤其是使用中小规模的模型时)。
为此,我们提出了一种全新的 Flipped-triple scoring trick。
具体操作如下:
1、 随机洗牌(Shuffle):针对同一 prompt/queryx^{(i)},将来自不同模型的多个 responses 进行随机洗牌;
2、 三元组翻转滑动评分:对于每个 LLM 评估员M\_{j'},我们按顺序对 response 三元组 [r^{(i,j-1)}, r^{(i,j)}, r^{(i,j+1)}] 进行评分(共需要滑动执行J 次,J 等于“针对每个 prompt/query 的 response 个数”),且在每次新的滑动之前,我们还会对翻转后的 response 三元组(即 [r^{(i,j+1)}, r^{(i,j)}, r^{(i,j-1)}])进行评分。
3、 最终分数计算:通过这种翻转+ 滑动窗口的机制,每个 response 都会从同一位 LLM 评估员那里获得了 6 个分数。我们通过取均值,得到评估员M_{j'} 对 response r^{(i,j)} 的最终评分 y^{(i,j;j')}。
该技术缓解了 LLM-as-a-Judge 中两种偏差[10]:
- 一致性偏差 (Consistent Bias):对于逐点评分,模型是在缺乏多个 responses“参考效应”下评估单个 response,很可能倾向于给出固定分数(例如始终打 1 分);
- 位置偏差 (Position Bias):当一次性展示多个 responses(如两到三个)时,很可能倾向于青睐出现在开头或结尾的 response。
变体 LLM-PeerReview-W
我们的变体方法 LLM-PeerReview-W 采用了加权平均去做推理。这个方法构建在一个图模型的基础上,并且我们对方法进行了一定的适应性改造,以可以处理上述" 翻转三元打分" 后所得到的连续型分数信息。
1.2.3 方法分析
有一句常常流传的话,并且据说是来自于爱因斯坦,“Everything should be made as simple as possible, but not simpler”。(万事万物都应尽可能简洁,但不能过度简化。)
那么:
1、直觉先行:针对同一 query/prompt,从多个回答中挑选“全场最佳”,引入学术同行评审的逻辑是非常合乎直觉且自然的;
2、打破瓶颈与进一步提升:实验发现,如果只是简单地让 LLM 逐个打分(Point-wise),像 7B 这样的中小模型表现很差,使得 LLM-PeerReview 难以超越 baselines。Everything should be made as simple as possible, but not simpler,当使用上所提出的 Flipped-triple scoring trick 后,所得到的 LLM-PeerReview 和 LLM-PeerReview-W 性能已经远超所有 baselines;
3、总而言之,我们认为嵌入了 Flipped-triple scoring trick 的同行评审框架 LLM-PeerReview 是一个超级 simple and effective 的多 LLM 协同/ 集成方法。
方法优势与特点:无监督(且无需微调),框架具有良好的可解释性,既可以应用于 Exact-Match Generation 任务(根据标准答案进行匹配,如 Math),也可以应用于 Open-Ended Generation 任务(如 Code Generation 和 Instruction-Following)。
1.3 其他分析
效率分析:
对于 Scoring 过程,我们当然可以采用模型集合中所有 LLMs 来进行打分。为了提高效率,我们实际上可以减少评审员数量而直接线性地减少 Scoring 过程计算量。
后续,我们也将考虑根据拓扑学而有选择性地来进行减少[11]。LLM-PeerReview 相较于 LLM Collaboration 中经典的基于 debate 的方法[11]会具有更好的计算效率,因为打分仅需要一轮,而 debated 往往需要多轮。
其他理论分析:
我们提供了一些相应的理论证明,以说明当提高评估员的数量或者是增加评估员的差异性时,可以提高最终的集成分数质量。这些理论证明可以指导对于评估员的选择。

1.4 其他备注
LLM-Ensemble 与 LLM Collaboration 的联系。
从广义上讲,LLM Ensemble 可以看作是 LLM Collaboration 这个 topic 的一个子集。另外,LLM Ensemble 与其他 Collaboration 类的方法相比,更强调于所考虑的多个模型都是着眼于端对端地处理 query/prompt,而不是 Collaboration 中主要强调于各个模型进行大量的信息传递以在一个系统中完成协作与竞争等目的。
2 实验
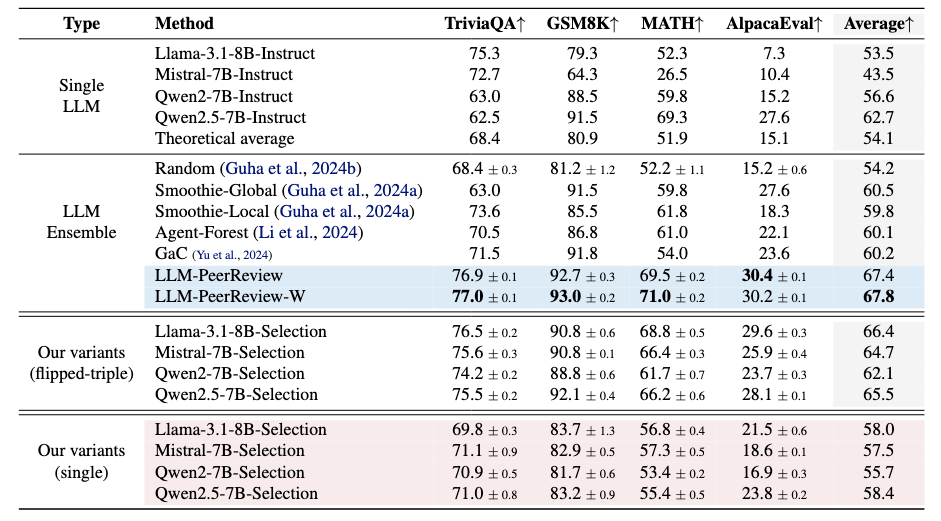
- Single LLM:模型集合中的各个单一 LLM;
- LLM Ensemble:LLM Ensemble baselines;
- Our variants (flipped-triple):单一的 LLM 作为评估员利用所提出的打分方法进行打分,并挑选出最高得分 response;
- Our variants (single):单一的 LLM 作为评估员利用传统的单点打分方法进行打分,并挑选出最高得分 response;
1.核心实验结果分析:
巨大性能提升。所提出的方法 LLM-PeerReview/LLM-PeerReview-W 明显超越了任何单一 LLM 的性能表现,也明显超越了所有 LLM Ensemble baselines;
在平均性能上,以 6.9% 和 7.3% 的优势超越了先进的“推理后集成“方法 Smoothie-Global,以 7.2% 和 7.6% 的优势超越了经典的”推理时集成“方法 GaC;
每个 LLM 在每个数据集上的表现都表现出明显的差异性。我们还在论文中提供了一些图表来分析这些 LLMs 的表现差异;
使用较少的评估员依然可以获得不错结果。当我们使用" 单一的 LLM 作为评估者并挑选最优 response"(即表格中的 our variants (flipped-triple))时,其性能表现也相当不错。我们还在附录中提供了使用 1 个、2 个和 3 个评估员的结果;
加权版 LLM-PeerReview-W 相较于基础 LLM-PeerReview 表现出了一些性能提升。我们考虑在后续工作中对变体方法中的图模型加入先验信息以进一步提高性能;
Flipped-triple scoring trick 是巨大功臣。因为 our variants (flipped-triple)的性能与 our variants (single)实现了大幅度的性能提升(4 个单评审员的提升分别为:8.4%、7.2%、6.4%、7.1%)。在实验中还提供了更多直接的信息说明这一点。
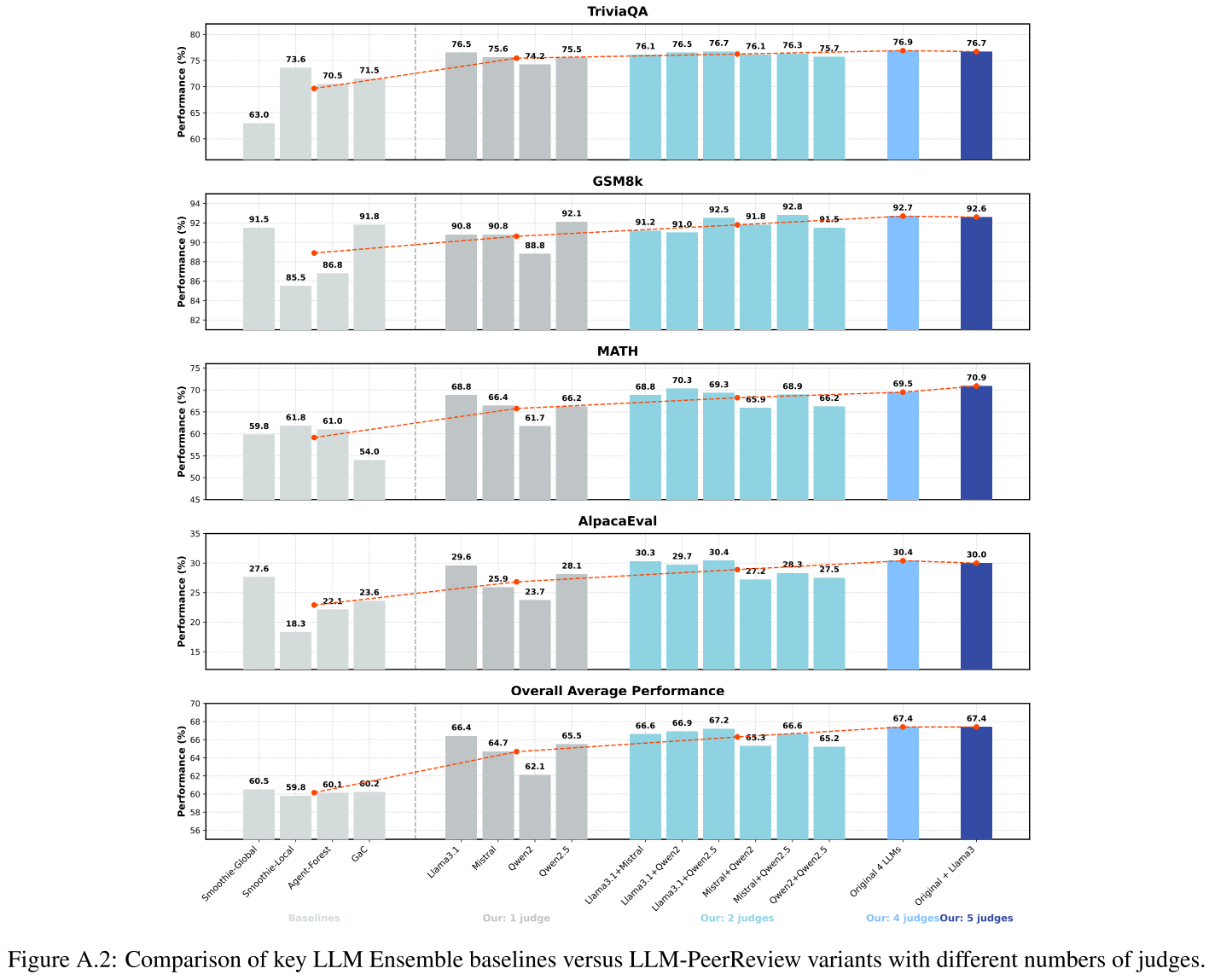
2.其他实验结果分析:
我们还在论文中提供了更多实验分析,如上图。
3 总结
LLM-PeerReview 构建于一种透明且可解释的、模仿同行评审过程的框架之上,其完全无监督的特性为各种任务和数据集提供了灵活的泛化性和适应性。
在框架 LLM-PeerReview 中,我们采用了 LLM-as-a-Judge 技术并再次利用模型集合中的 LLMs 以对各个回复(responses)进行精细化评估(摒弃了基于相似度选择的集成策略以及其中的 BLEU 衡量指标),并提出了关键的 Flipped-triple scoring trick 以减少评分偏差。
此外,我们提供了直接的平均方法和基于图模型的加权方法来聚合评分信息。
实验表明,LLM-PeerReview 显著优于各个 LLM Ensemble baselines 以及模型集合中的任何单个 LLM。
参考文献
[1] Zhijun Chen, et al. Harnessing Multiple Large Language Models: A Survey on LLM Ensemble. arXiv 2025.
https://arxiv.org/abs/2502.18036
[2] Neel Guha, et al. Smoothie: Label free language model routing. NeurIPS, 2024.
https://arxiv.org/abs/2412.04692
[3] Junyou Li, et al. More agents is all you need. arXiv, 2024.
https://arxiv.org/abs/2402.05120
[4] Yao-Ching Yu, et al. Breaking the ceiling of the llm community by treating token generation as a classification for ensembling. arXiv, 2024.
https://arxiv.org/abs/2406.12585
[5] Zehao Chen, et al. LLMBoost: Make Large Language Models Stronger with Boosting. arXiv 2025.
https://arxiv.org/abs/2512.22309
[6] Jiaru Zou, et al. Transformer copilot: Learning from the mistake log in LLM fine-tuning. NeurIPS, 2025.
https://arxiv.org/abs/2505.16270
[7] Zhi-Hua Zhou. Ensemble learning. Machine learning, 2021.
[8] Dongfu Jiang, et al. Llm-blender: Ensembling large language models with pairwise ranking and generative fusion. ACL, 2023.
https://arxiv.org/abs/2306.02561
[9] Bo Lv, et al. Urg: A unified ranking and generation method for ensembling language models. ACL Findings, 2024.
https://aclanthology.org/2024.findings-acl.261/
[10] Peiyi Wang, et al. Large Language Models are Not Fair Evaluators. ACL 2024.
https://arxiv.org/abs/2305.17926
[11] Yunxuan Li, et al. Improving multi-agent debate with sparse communication topology. EMNLP Findings, 2024.
https://arxiv.org/abs/2406.11776