作者:Naiyan Wang
https://zhuanlan.zhihu.com/p/2032931834288419524
在 xLM 席卷虚拟世界的各种应用后,大家谈论的下一个热点自然迁移到 Physical AI(物理世界 AI)。
抛开繁杂的具体技术架构,我们回归第一性原理来思考:一个系统想要在物理世界中完成复杂的交互任务,本质上需要具备哪些能力?
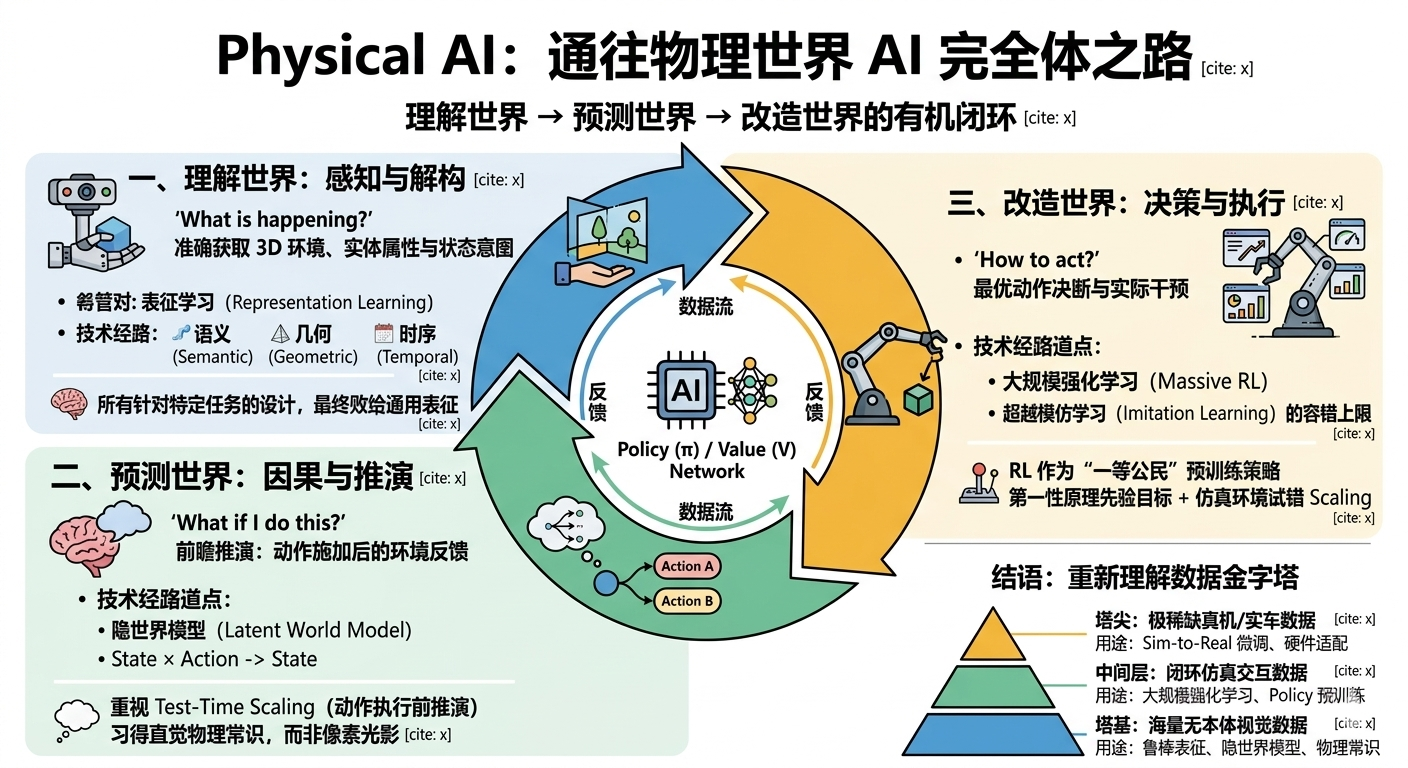
在我看来,这其实是一个由三部分组成的有机闭环:理解世界、预测世界、改造世界。为了对齐接下来的讨论,我们先用大白话明确一下这三个概念在工程语境下的本质:
理解世界(感知与解构): 系统必须准确获取其所处的 3D 环境信息,清楚周围有哪些物理实体、它们具备什么属性、目前处于什么状态以及有何种意图(What is happening?)。当然这样的能力不一定是要显式表示,也可以是通过 feature 隐式表征。
预测世界(因果与推演): 在理解世界的基础上,系统需要具备一种前瞻能力,即推演“如果我对这个世界施加一个具体的动作,物理环境将给出怎样的反馈”(What if I do this?)。
改造世界(决策与执行): 结合对当前的理解和对未来预判的综合考量,系统最终决断出最优的动作输入,去实际干预物理世界,以达成预定的任务目标(How to act?)。
这三者恰恰对应着当前 AI 领域中的三个核心技术方向:表征学习、隐世界模型(Latent World Model)和大规模强化学习。今天借着这个框架,分享一下我们在这些技术方向上的观察与实践。
一、 理解世界:任务和场景泛化的根基
如果说过去 15 年中有什么让我印象深刻的 bitter lesson,那么我一定会讲:所有针对特定任务的设计,最终一定会败给通用表征的进展。
回顾过去无论是 CV 还是 NLP 的发展,反反复复被验证的一个真理便是:在底层表征能力提升之前,过多地对上层任务进行设计,一定是弯路。
以我熟悉的 CV 为例,从最开始的人工设计表征时代,为了适配 SIFT/HOG 这种低抽象特征,不得不引入非常高维度的特征空间,从而做各种极高维分类器的学习;
再到以 ImageNet 为代表的监督学习表征时代,为了解决开集泛化性的问题,做了非常多现在看起来多此一举的设计。CV 在语义任务上的泛化,最终是通过大规模自监督表征学习得以解决的。
但在 Physical AI 面临的物理环境中,目前侧重于语义的表征研究够用吗?个人认为,能支撑 Physical AI 的表征一定要具有以下三个方面的属性:
1、语义表征(Semantic): 研究最为充分,无论是通过自监督学习提取的 DINO,还是语言对齐的 CLIP/SigLip,模型在“认识物体”这一点上已经做得很好了。
2、几何表征(Geometric): 或者叫 3D 表征,这部分的研究方兴未艾。传统的 3D 重建(包括 NeRF/3DGS 这些)或者 SLAM 往往都是基于逐场景的优化。
从 23 年开始,3R 系列工作试图用大模型范式推进 Feed-forward 范式在这些领域的应用;终于在去年,VGGT 赢得 CVPR Best Paper 之后,这个研究方向得到了海量的关注。
这些模型除了可以显式完成重建或者位姿/深度估计这些 3D 相关的任务之外,更重要的价值在于:其隐层的 feature 可以感知到这个物理世界的 3D 结构。 这相比于纯语义的特征表示,有了巨大的进步。
3、时序表征(Temporal): 尚未引起足够重视。即便在多模态大模型中,主流做法仍然是把视频变成单帧的图像 token 化后丢进 Transformer。为什么时序表征如此关键?因为真实物理系统的交互不是单帧静态图片的堆砌,而是连续的传感器数据流。许多关键任务的信息,其实蕴含在帧与帧之间极微小的变化中。
举个自动驾驶中的典型场景:在高速行驶时,右侧应急车道有一辆静止的车辆。只看单帧图像,感知系统很难判断该车是否有起步切入主路的意图。而人类驾驶员往往是通过极其敏锐的动态捕捉——比如观察到车辆底盘由于起步扭矩产生的微小“抬头”,或者是前轮打出的几度转向角,从而提前做出防御性决策。
面对这类问题,目前的 VLM 感知框架是非常吃力的。这并非模型参数量不够,而是输入的表征缺乏对时空联合变化的敏锐度。
表征学习是我们团队预研的重点方向,我们团队联合港大赵恒爽老师在表征层面上推进了几项工作,后续也会持续投入:
- Concerto (NeurIPS 2025): 借鉴 JEPA 的思想,实现了统一的图像与 3D 点云多模态表征,证明了这种底层的协同对特征提取有 1+1>2 的效果。
- Flowseg (NeurIPS 2025): 通过视频流中的运动信息,自监督学习物体级别的表征信息。基于这个想法,我们近期也拓展了一系列工作,证明了其在各种下游 Physical AI 任务中的通用性。
- Utonia (Arxiv 2026): 旨在解决 3D 表征中跨尺度的难题,用单一的 Encoder 统一了从桌面级具身操作到百米级室外自动驾驶的空间表征。
二、 预测世界:基于隐世界模型(Latent World Model)的 Test-Time Scaling
系统对当下环境建立理解后,需要具备预判行动后果的能力。换言之,模型需要知道:当我对物理世界施加某种输入(Action),世界会给出怎样的反馈?
目前行业内对“世界模型”这一概念存在一定程度的泛化甚至误解。很多人将视频生成(如 Sora 等模型)等同于世界模型。但在我的认知框架里,视频生成建模的仅仅是 State -> Next State 的演变过程。
真正的世界模型应当是:State × Action -> State。必须引入行为变量(可以是主体动作,也可以是环境中其他因素的干预),它在机器人或自动驾驶的语境下才具有价值。
不要局限于离线仿真,重视 Test-Time Scaling
目前有部分前沿工作(如 World Action Model 系列工作)开始关注这一点,但他们大多仍将世界模型作为辅助监督,或仅仅用于离线生成仿真数据。我的观点是:可靠的 Physical AI 系统,必须在动作执行环节前推演未来。
我们可以将其类比于大语言模型中的 Test-Time Scaling。早期 ChatGPT 的输出仍可能存在大量事实性错误,但在 OpenAI o1 模型引入思考模式后,通过在生成前使用 CoT(思维链)进行推演,输出可信度大幅上升。在自动驾驶等高危场景下,仅仅依靠模型端到端输出一个动作是非常不可靠的,传统做法是加入大量兜底代码。而真正优雅的解法,是让模型利用其内在的世界模型,在线对未来可能发生的局势进行预演和价值评估。
正如十年前的 AlphaGo 和 AlphaZero,单纯依靠离线模仿学习或强化学习训练给出的只是初始策略(Policy)和 Fast Rollout Network,仅仅依靠这样的原始输出,只能达到业余五段水准。真正使其具备超越顶尖棋手决策能力的,在于它在执行动作前,利用离线习得的 Policy 和 Value,通过 MCTS 在线进行分钟级的搜索推演。
世界模型应当学习Intuitive Physics(直觉物理常识),而不是像素光影
目前的许多视频生成大模型,其大部分算力都被用来拟合逼真的光影反光、复杂的物体纹理和宏大的视角变换。但对于一个真正在物理世界中执行任务的智能体来说,隐世界模型的核心绝不仅是“像素级别的视效渲染”。
我们期望世界模型真正压缩并习得的内容,是一套底层的 Intuitive Physics(直觉物理常识)。就好比一个没上过学的小孩子,他虽然不懂牛顿力学,但通过对日常生活的观察,他能建立起一种本能的直觉:手里拿着一个皮球,松开手球会下落(重力认知);落地后球会弹起(弹性认知);但如果是同样大小的玻璃球,掉在地上则会直接粉碎(脆性认知)。
如果这些最基本的物理运行法则没有被刻印在模型的权重中,那么模型就只能去死记硬背特定任务(比如用特定数据教它叠衣服、抓杯子),一旦脱离特定场景或换了操作对象,其泛化能力就会面临灾难性的崩塌。因此,真正的隐世界模型,其本质应该是物理法则的压缩器。在真正“改造世界”执行动作之前,AI 必须先通过观察,内化这些万物运转的常态。
三、 改造世界:大规模强化学习(RL)作为“一等公民”
完成理解与预测后,最后一步是动作的执行。在这部分,目前自动驾驶和具身智能领域的主流范式是模仿学习(Imitation Learning),即通过人类专家的轨迹逐帧教导模型。但我们在实践中深切体会到了其局限性。在之前的多篇文章中,我也对这个问题进行了深入探讨,这里再简单总结一下。
模仿学习的 OOD 困境
模仿学习的痛点是难以根治的 OOD(Out of Domain)问题。因为专家演示数据(往往是完美的成功样本)难以覆盖真实环境下高维状态空间的各个角落。比如在执行抓取时,一旦发生水杯轻微滑落,模型就很容易崩溃,因为训练集里几乎没有“如何在失败边缘恢复状态”的负反馈脱困数据。
为了解决长尾问题,依靠人类去采集所有高风险的 OOD 数据(例如即将发生碰撞时的极限避让),无论从成本还是安全性上都极不现实。
强化学习的不可替代性
现在不少团队将强化学习作为模仿学习后的一道“微调”工序。但在我们的认知中,强化学习应该在动作训练中作为真正的“一等公民”,甚至是预训练本身。
从使用先验知识和数据的程度来看:
- 传统规划: 完全依赖人工建模与在线优化,难以吃到数据 Scaling 的红利。
- 纯模仿学习: 完全依赖数据拟合,丧失了可解释性,行为边界难以保障。
- 大规模强化学习: 恰好处在两者之间。它是使用大规模算力去 Scaling 本质的“第一性原理”最自然的方式。
我们只需定义基于第一性原理的极少数先验目标(比如安全底线、物理法则),并在仿真环境中通过大规模数据 + 场景的 Domain Randomization(域随机化),让模型成千上万次地自我博弈与试错。它所展现出的容错能力和策略上限,远非纯模仿学习可比。
这一路径极难,主要壁垒在于 高效的训练基础设施(RL Infra) 需要与算法精心协同设计。只要突破了这一点,前景会是一片坦途。
四、 结语:重新理解数据金字塔
结合前面这三部分,我对行业内常提的自动驾驶/具身数据的“数据金字塔”分享一点我们视角的看法:
1、塔基(海量无本体关联的互联网/视觉数据): 这类数据极其丰沛。它的核心用途不是直接去教模型出动作,而是应当在此基于自监督学习,训练出鲁棒的表征与隐世界模型,让系统习得必要的“物理常识”。
2、中间层(闭环仿真的交互数据): 这里应当是基于大规模强化学习的演武场。模型在这里预训练策略(Policy),在安全的闭环内经历大量试错,完成真正动作模型的预训练。
3、塔尖(极稀缺昂贵的真机/实车数据): 其最终的作用,仅仅是用极高效率去弥补最后的 Sim-to-Real 鸿沟(Gap),将数字世界中验证过的知识,快速微调适配到不同的硬件本体上。
通往 Physical AI 完全体的路还有很长,很多问题也还在持续探索中。期待后续能有更多机会与同行探讨交流!