作者:Root
原文:https://zhuanlan.zhihu.com/p/2027548813129267030
前言
On-policy distillation最近在LLM后训练领域非常火,我也一直有在关注OPD/OPSD相关论文的进展。之前,我一直认为这波OPD热潮涌现的一系列方法都可以看成是从 Thinking Machines的On-Policy Distillation(下文简称 ThinkingMachines OPD)派生出来的同一个方法族群。但是,直到这两天才意识到这个表象之下其实存在两种本质不同的方法形态。
于是我将相关调研和思考记录下来,形成了这篇blog:先回到 KL 散度的基本定义,把”前向/反向KL” 在概念和形式上的差异说清楚;然后顺着这条线索,介绍OPD在自回归语言模型时代的两种思路及其相关推广过程中,会穿插回顾近期相关的若干篇论文。
Takeaways:
KL存在两种层面的定义:
- 标签/token层面的KL:可以遍历词表精确计算教师预测分布和学生预测分布之间的距离,和轨迹由谁采样无关;
- 序列层面的KL:只能通过蒙特卡洛近似计算,前向/反向取决于由谁采样的rollout;反向KL要求由学生采样,所以是on-policy的;
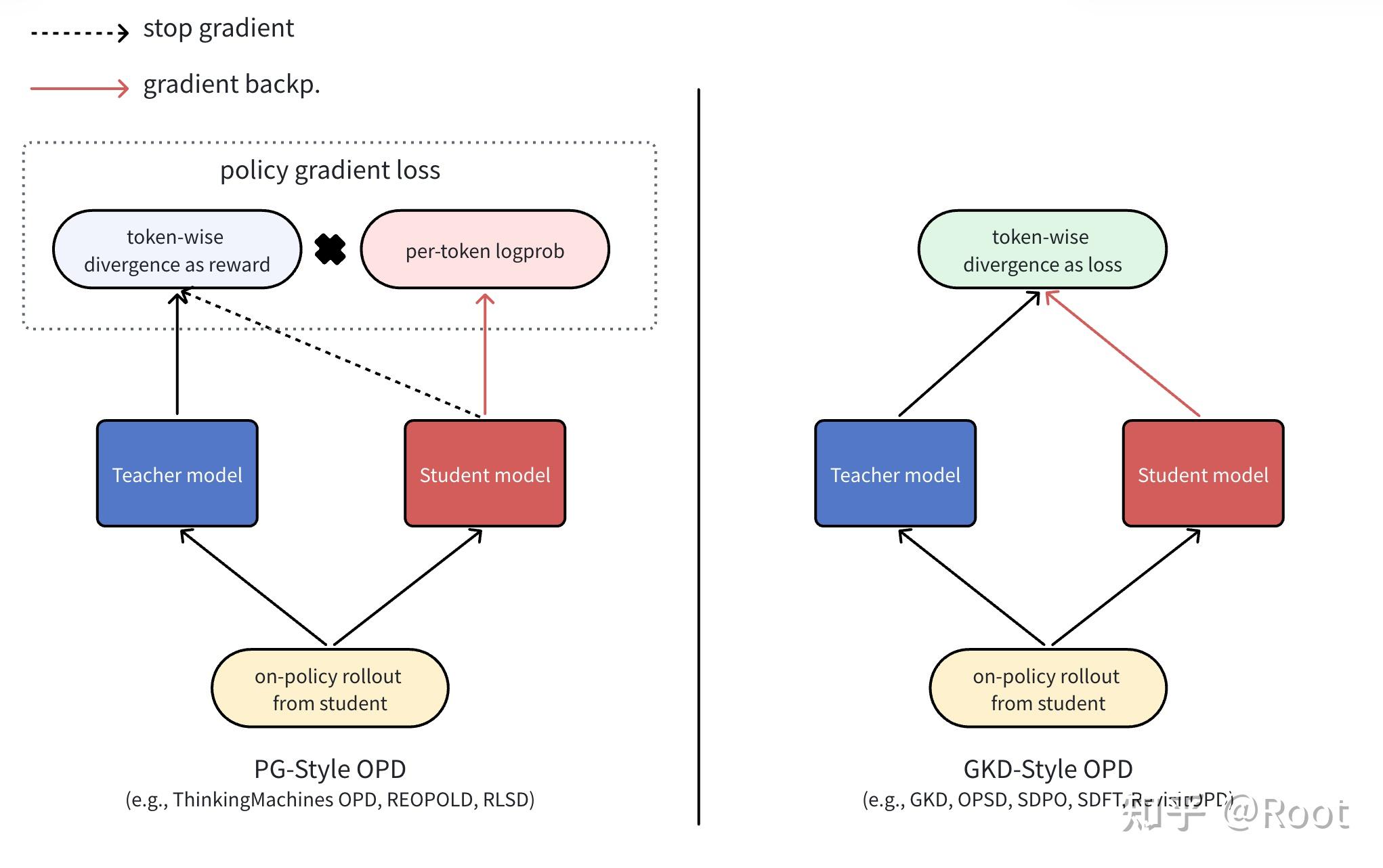
OPD 的两种形态:PG-Style OPD 和 GKD-Style OPD
PG-Style OPD
- 使用散度(如,反向KL)作为奖励,没有梯度从散度回流到学生参数;
- 用策略梯度(PG)方法优化采样策略,让策略学会生成“反向KL”更小的轨迹;
- e.g., ThinkingMachines OPD, REOPOLD, RLSD
GKD-Style OPD
- 使用散度(如,反向KL)作为损失函数,梯度可以直接从散度回流;
- 在每个token位置上,直接最小化两个模型的预测分布的距离;
- e.g.,GKD, OPSD, SDPO, SDFT, RevisitOPD
KL 回顾 1:「标签」时代的 KL
KL 的基本定义
KL散度衡量的是用分布q去逼近分布p时损失了多少信息。写成一个统一的期望形式:
在连续情形下,期望展开成积分形式:
在离散情形下,期望展开成求和形式:
从信息论的角度看,KL散度可以解读为”用编码q去压缩来自分布p的样本时,相对于用最优编码p多付出的平均比特数”。换句话说,它度量的是用q拟合p的额外开销。众所周知的两条特性:第一,KL散度恒非负,且当且仅当p=q时为零;第二,KL不对称——\mathrm{KL}(p\|q)\neq \mathrm{KL}(q\|p),这一点正是后面”前向 / 反向”分歧的来源。
Hinton’s KD 下的 fKL 与 rKL
回到经典的知识蒸馏(Knowledge Distillation, KD)语境下,我们有两个模型预测的分布,假设教师分布为 p_T(y\mid x),学生分布为p_S(y\mid x),”前向 KL”(forward KL,fKL)和”反向KL”(reverse KL,rKL)分别是:
在形式上只是把两个分布的位置换了一下;计算实现上的区别是:fKL是按教师分布p_T加权来度量误差,rKL是按学生分布p_S加权来度量误差。
需要特别澄清的一点是:这里期望符号 \mathbb{E}_{y\sim p_T}在数学上只是”按p_T(y)做加权平均”,它并不要求训练时的标签真的是从教师采样出来。在传统KD的实践中,输入x通常来自真实语料或人类标注集合,硬标签y^*也常常来自人类标注而不是教师模型;教师只是额外提供了一份”软分布”用于指导学生。所以,在这里,”正向”的含义并不是”标签由教师生成”,而仅仅是”在KL函数的两个槽位里,教师分布放在前面”。
学习效果上的差别则常被总结为:fKL是mode-covering(覆盖模式),rKL是mode-seeking(追逐主峰)。直觉上,当教师分布有多个峰时:
- fKL会狠狠惩罚”教师认为重要的地方学生没覆盖到”,因此学生倾向于把概率铺开,去覆盖教师的所有合理模式,在多峰分布上往往学成一个”平均化”的分布。
- rKL关心的则是”学生自己下注的地方教师是否认可”,因此学生倾向于抓住教师最主要的峰、忽略次要峰分布更尖锐、更挑选性。
KL 回顾 2:「自回归语言模型」时代的 KL
上一节的分析有一个隐含前提:y是一个分类标签(或者说,单个token)。一旦y变成一整段自回归 token 序列,情况就会微妙很多。
序列级KL的推导
设prompt为x,输出序列为\tau=(y_1,\dots,y_T),前缀状态为s_t=(x,y_{<t})。教师和学生都是自回归策略:
以序列级反向 KL为例,按定义它是整个输出序列空间上的期望:
利用自回归的链式分解\log\pi(\tau\mid x)=\sum_t \log\pi(y_t\mid s_t),可以重写成每一步token logprob之差的累加:
它还可以进一步写成”前缀访问分布 + 局部token级KL”的形式:
其中d_S^t是”第t步时,学生自己会访问到哪些前缀”的分布。但上面这种”数学期望”形式没办法直接喂给优化器;工程实现中真正使用的是 Monte Carlo 近似:从学生采样 N 条序列\tau^{(i)}\sim\pi_S(\cdot\mid x),然后对每条轨迹上的per-token log-ratio求和再平均:
这个式子已经非常接近OPD类方法中常用的奖励/损失形式了。把同样的推导流程套到前向KL上,就得到下面这张对照表:

深入分析:两个维度
在自回归序列采样的语境里,”正向/反向”这个词其实同时指向了两件事情。把它们解耦成两个独立的维度,有助于理解:
- 维度 A:token-level 分布上计算 KL 的方向——在给定一个前缀s_t的条件下,比较的是 \mathrm{KL}(\pi_T(\cdot\mid s_t)\|\pi_S(\cdot\mid s_t))还是\mathrm{KL}(\pi_S(\cdot\mid s_t)\|\pi_T(\cdot\mid s_t))。
- 维度 B:外层前缀分布是谁——在哪些前缀s_t上做训练?是教师rollout诱导出来的d_T^t,是学生自己 rollout诱导出来的 d_S^t,还是来自真实语料/人类标注的某种d_{\text{data}}^t。
这两个维度在数学实现上的代价也完全不同:维度A决定的只是某个固定前缀上的一个散度计算,只要教师和学生的 logits都能拿到,就可以遍历整个词表做精确求和,没有采样噪声;而维度B需要从某个策略里抽出整条轨迹,只能通过蒙特卡洛近似,因此需要考虑数值估计方差之类的问题。
这个区分还解释了一个很容易被混淆的问题:ThinkingMachines OPD博客和很多OPD相关文献里提到的”反向KL”,通常强调的是维度 B——也就是”外层轨迹分布是学生自己的策略”——这是”序列级反向KL”的蒙特卡洛估计的自然推导结果。而在“蒸馏学习”的术语习惯里,”反向KL”这个词往往更偏向维度A的方向选择。但在OPD的实现里两者常常同时出现,所以不注意就容易混成一谈。
反向 KL 的优势:缓解 exposure bias
自回归语言模型训练最经典的一个”坑”是 exposure bias(也叫 compounding error):训练时学生一直吃的是教师前缀/oracle 前缀,学的是”在老师从不犯错的上下文里下一步该怎么接”;但推理时,学生面对的是自己已经犯过错之后的上下文,早期的任何小偏差都会被自回归的链式结构逐步放大。
在这里,”序列级反向KL”(维度 B 意义下)就派上用场了:它的外层期望天然就是对学生自己的轨迹分布取的,因此训练时所见的前缀分布d_S^t与推理时完全一致——一旦这个外层期望被拿来当优化目标,exposure bias/compounding error 就会在原理上被消解掉。这也是为什么 OPD 系列工作强调”让学生在自己的rollout上拿到教师信号”这件事。
OPD 路线之争
OPD 是什么?
关于OPD(On-Policy Distillation)的描述方式有很多种——有人把它定义为”student rollout+dense token-level reward”,有人强调”教师在每一步提供反馈”,有人把它简单理解成”on-policy版本的knowledge distillation”。抽丝剥茧来看,我认为只要一个方法同时满足以下两个条件,就可以称之为OPD:
- On-Policy:训练时用到的输出轨迹(rollout)是由学生自己当前策略实时采样产生的,而不是来自教师,也不是来自人类或静态数据集预先抽好的离线样本。
- Distillation:教师为学生在 rollout上提供某种形式的监督信号——可以是某种奖励,也可以是软标签。
这个定义刻意留白了”教师提供的信号具体长什么样”以及”这个信号怎么回传到学生参数”——而恰恰是这两个留白处,不同路线之间长出了明显的分歧。下面要介绍的两条路线都满足上述OPD定义,但它们的优化目标和优化方式并不一样(如图1所示)。
PG-Style OPD
PG-Style OPD 的代表是 ThinkingMachines OPD博客。它的核心数学形式是把 per-token 反向 KL 当作密集(token级)奖励信号,然后通过 policy gradient(PG)去更新学生:
其中advantage直接取为反向 KL 的负值:
仔细看这个advantage,它其实就是经典的Schulman K1 近似即用单点log-ratio去近似KL散度的最朴素形式。所以这里的reward本质上就是”教师-学生在某个sampled token上的logprob差”。
观察反向传播时的行为:KL的奖励/优势不负责产生梯度,梯度是经过\log\pi_\theta(y_t\mid s_t)这一项回传的。在实践中,为了配合PPO-clip等稳定化技术,这个”负责梯度回流的因子”通常不直接写成 \log\pi_\theta,而是写成新旧策略的概率比
这里有一个非常容易混淆的细节——整个 loss 里出现了两个 ratio:
- 奖励内部的 ratio:\log\pi_T(y_t\mid s_t)-\log\pi_\theta(y_t\mid s_t),衡量的是教师 vs 学生的分布差(这是”KL-as-reward”);
- 奖励外部的ratio:\pi_\theta(y_t\mid s_t)/\pi_{\theta_{\text{old}}}(y_t\mid s_t),衡量的是新策略 vs 旧策略的分布差(这是”PPO importance ratio”)。
读代码和论文时务必注意分辨,例如,PPO-clip是加在 importance ratio上的,而不是加在KL散度(或教师学生概率比)上的。
相对于传统的RLVR(Reinforcement Learning with Verifiable Rewards),PG-Style OPD的核心优势是天然的token-level奖励:RLVR只在整条轨迹结束后拿到一个标量reward,然后通过广播分配给所有token,无法区分不同位置token的重要性和优劣;而PG-Style OPD在每一个token上都能从教师那里拿到反馈,于是可以从反馈中学习每个token的优劣。
在训练实现上,ThinkingMachines博客的做法里还有一些值得注意的细节:
引入GRPO的组采样轨迹:对同一条 prompt 采样多条 response。但要注意,这里只是借用了”组采样”这一形式,并没有启用 GRPO 里那套组内优势归一化的机制——虽然可以考虑减掉(每个序列或整个batch)所有token的平均奖励。
使用 PPO-clip:在scale训练规模时,PPO的裁剪机制有助于稳定训练。
discount factor=0:博客实现里,advantage 只等于当前 token 的 reverse-KL 信号,而不把未来 token 的 reward 折扣回传——这是一个非常简化的设计选择。
理解PG-Style OPD最关键的一点在于它的优化目标并不是“缩小学生和教师的分布差异”。它真正在优化的是采样策略本身——让学生更倾向于去生成那些”序列级反向 KL 度量更低”的轨迹。
举个例子,假设采样空间里有两条轨迹 A 和 B,我们都能分别算出它们的序列级反向 KL 的采样近似值(也就是 per-token log-ratio 的和)。如果 A 的这个值比 B 低,那么 PG-Style OPD 希望学生策略\pi_\theta未来更倾向于生成轨迹 A。
换句话说,它在重新分配学生策略对不同轨迹的采样概率,而不是直接修改某个前缀上的 token 分布形状。
GKD-Style OPD
GKD-Style OPD 可以追溯到GKD论文所提出的 on-policy 版本。它的数学形式要直接得多:在学生自己采样的前缀上,直接对token-level散度做可微的梯度下降——
其中D(\cdot,\cdot)可以是fKL、rKL、JSD或任何其它可微的分布度量。关键的\operatorname{sg}(stop-gradient) 符号表示:学生的采样过程本身不参与梯度——一旦轨迹\tau采出来,它就被当作一个普通的监督 minibatch 处理。
GKD 论文自己的原话是:
“In contrast to Gu et al. (2024, MiniLLM), our method GKD does not backpropagate through the student’s sampling process. This makes GKD closer to supervised training and typically more stable.”
从优化目标的本质含义来看,GKD-Style OPD 做的事情就是通过梯度回传,直接缩小学生和教师在已访问前缀上的分布差异。它不去操心”学生未来会不会生成这条轨迹”——它只关心”既然已经生成了这条轨迹,那就在这些前缀上把学生的局部 token分布拉向教师的token 分布”。
也就是说,GKD不对学生的采样策略本身进行优化,只是去塑造每个位置的预测分布,因此它更接近传统的监督训练(SFT)——当然,on-policy的采样过程(rollout)本身会被“分布塑造”间接影响。
推广与变体
GKD-Style OPD 的推广
最近的多篇论文都指出:在相同rollout预算下,GKD-Style OPD相对于PG-Style OPD的方差更小、训练更稳定——直觉上不难理解,PG-Style的梯度估计器本质上是 REINFORCE,方差会随着序列长度累积;而GKD-Style 把采样流程stop-gradient掉之后,余下的loss变成了普通的监督学习,梯度估计的方差天然就低得多。也因此,最近这一批如雨后春笋般冒出来的 OPD工作——OPSD、SDPO、SDFT、OPCD、RevisitOPD——不约而同地选择了 GKD-Style 这条路线。
沿着 GKD-Style 的这条路径做推广,最自然的变化轴就是改变”学生 vs 教师的局部度量”。常见的变体包括:
Schulman的K1/K2/K3 近似。K1是 \log\pi_\theta-\log\pi_T 的单点估计;K2是 \tfrac12(\log\pi_\theta-\log\pi_T)^2这样的无偏、恒非负的近似;K3则是r-1-\log r(其中 r=\pi_T/\pi_\theta)这一更稳健的形式。
顺便提一嘴,K2的形式恰好和DeepSeek-R1官方训练方法所使用的参考模型KL惩罚项一致——它既是反向 KL 的一个良好估计,又是一个平滑、恒正、可以直接梯度回传的表达式。
JS 散度(Jensen-Shannon divergence)。JSD 是 fKL 和 rKL 的一个对称化产物,GKD 原论文就把它列为默认选项之一,实验上往往比单纯的 fKL 或 rKL 更稳健。
Full-vocab fKL/rKL。即不只看 sampled token,而是对整个词表做遍历求和。只要教师和学生都能拿到完整的 logits,这一形式就是可以直接精确计算的,不依赖采样。代价是需要存储和搬运完整的词表维 logits,对显存和带宽有一定要求。
这三类变体其实对应着在精确度—显存开销—稳定性之间的不同折衷:K1 便宜但有方差;K2/K3 不花额外开销就能改善一些性质;full-vocab 则是精度最高但成本最贵。
在近期的论文里,也有相当比例把这几种形式混合使用,比如 RevisitOPD就提出了”truncated reverse-KL+top-p采样+special-token masking”的组合,本质上是 full-vocab和sampled形式之间的一个折中。
PG-Style OPD 的推广
PG-Style OPD 走的是 RL 式优化器这条路,所以它的推广和变体路径,和传统的 RLVR/PPO/GRPO社区是共享的技术栈。几种常见的推广方向:
奖励函数替换。既然 advantageA_t的角色就是”一个 token 级奖励信号”,那么把 reward 的具体形式从 Schulman K1换成 K2/K3、JSD、full-vocab fKL/ rKL等,都是完全自然的操作。需要注意的是,这种替换改变的是信号的计算方式,并不影响整个优化器仍然是 advantage × logπ(sampled action) 这个PG surrogate 的事实。
reward-to-go/折扣回报。ThinkingMachines 博客[1]的实现中刻意把discount factor取成0,也就是”每个token只用当前这一步的reverse-KL奖励”——这是一个工程简化。更”数学正确”的做法是把未来token的reward也折扣回传给前面的动作,即A_t=\sum_{u\ge t}\gamma^{u-t} r_u。P.S.,近期阿里Qwen团队的 FIPO在传统 RLVR 领域研究了相同的问题。
与传统 RLVR 奖励的融合。因为PG-Style OPD的核心改动都发生在奖励函数内部,所以把它和传统 RLVR 的可验证奖励(比如 outcome correctness)组合,是很自然的想法。
RLSD就是这一思路的出色工作:它同时保留 RLVR 的 outcome-based reward(负责”可信且一致的更新方向”)和OPD给出的token-level反馈(负责”更新幅度的细粒度分配”),从而同时吃到两种信号的好处。
引入RL社区常见的稳定化技术。包括更精细的 clip 策略、基于熵的 token-level mask(只在模型不确定的token上更新)等。
例如,REOPOLD引入了mixture-based reward clipping、entropy-based token-level dynamic sampling和一个exploration-to-refinement的训练策略。
PG-Style 与 GKD-Style 的混合
当前很多OPD主题的论文实际上(自觉地/不自觉地)考虑了两种loss形式的混合。一个典型的混合形式可以写成:
其中第一项是PG-Style主干(负责重新分配轨迹的采样权重),第二项是直接可微的GKD-Style项(负责在已访问前缀上低方差地对齐分布)。
一个很典型的近期工作是EOPD(Entropy-Aware On-Policy Distillation of Language Models)。EOPD 把loss写成两段拼接:当教师分布的熵较低时,用 PPO-clip 风格的PG-Style反向KL项(也就是把\log\pi_T-\log\pi_\theta当advantage、乘上新旧策略的 importance ratio);当教师分布的熵较高时,额外加上一个直接对top-k词表求和的前向 KL 项——后者是纯粹的GKD-Style 直接微分。
所以EOPD的两项loss恰好一项 PG-Style、一项 GKD-Style,是近期”两线混合”最清晰的一个案例。
事实上,一篇很早期的工作,MiniLLM,也已经考虑了这种混合。MiniLLM的逻辑起点和 ThinkingMachines OPD稍有不同:它是从”序列级反向 KL 的数学期望”的优化目标的理论视角切入,用 policy gradient theorem 推导出基于蒙特卡洛采样的优化形式。
推导出来的具体形式其实非常接近ThinkingMachines OPD,只差了两点工程细节(累计回报、长度归一化)。紧接着,MiniLLM在上面这个”裸PG主干”之上,主动引入了一个可以在词表维度上直接求和的、可微的single-step KL正则项(full-vocab KL 损失)来降低方差、稳定训练。这一项,其实就是本文所说的GKD-Style损失。
抛开更多工程细节上的差异不谈,MiniLLM在三年前就已经完成了OPD的两个重要方向的探索。不得不说,在OPD这个领域里,这是一篇超越时代的工作。当然,OPD的热潮远滞后于MiniLLM也说明另外一个问题,即使数学本质相同或相似,方法提出的时机和可选的技术组件,也是方法有效性和影响力的重要因素。
谈谈别的
总的来说,我很喜欢 OPD 这类工作。就像是把模型的输入输出、优化方法中的数学公式当做乐高积木,拆开来再换个方式拼起来——我能从中感受到科研的乐趣。不过,在LLM研究已经十分普及的现在,这种风格的工作也经常面临一个问题:这些工作往前调研,往往都会发现前人已经研究过相似的方法了。真正的进步,不在于几个人、几个晚上的思维火花,而在于整个社区的持续努力。