作者:王天乐,香港城市大学数据科学系博士生,导师为苗宁教授,研究方向为大语言模型推理。
DeepSeek-R1 的爆火让 RLVR(带验证奖励的强化学习) 再次成为大模型后训练(Post-training)的焦点。然而,复现过 R1-Zero 或类似流程的同学都知道,RLVR 极其昂贵——它不仅需要成千上万个训练步数,而且随着模型思考链(CoT)变长,后期每一步的计算成本都在成倍增加。
我们是否真的需要一步一步地跑完漫长的 RL 训练?
今天介绍一篇刚刚挂出的 ArXiv 论文 《Not All Steps are Informative: On the Linearity of LLMs' RLVR Training》。
这篇工作揭示了一个反直觉的现象:在 RLVR 过程中,LLM 的权重和输出概率竟然呈现出惊人的线性变化!
基于这一发现,我们提出了一种“权重外推”的方法,不用训练,直接“算”出未来的模型,实现了最高 6.1倍 的训练加速。
标题:Not All Steps are Informative: On the Linearity of LLMs' RLVR Training
论文:https://arxiv.org/abs/2601.04537
代码:https://github.com/Miaow-Lab/RLVR-Linearity
01. 反直觉的发现:RLVR 训练是“线性”的?
Transformer 本身是一个高度非线性的复杂系统,直觉上我们认为其参数更新轨迹应该是蜿蜒曲折的。然而我们通过对 DeepSeek-R1-Distill 系列模型在多种 RL 算法(GRPO, Reinforce++, GSPO)下的训练过程分析,发现了一个令人惊讶的事实:
1. 权重的线性变化
随着 RL 训练步数的增加,模型权重的变化与步数 t 呈现极强的线性相关性。在实验中,超过 80% 的参数 R^2 (决定系数)大于 0.7,大部分集中在 0.9 左右。
也就是说,模型在第 1000 步的样子,几乎可以通过第 100 步和第 200 步连一条直线画出来!
2. 输出 Log-Prob 的线性变化
更神奇的是,这种线性不仅存在于参数空间,还直接反映在模型的输出行为上。对于同一个 Prompt,模型生成特定 Token 的 Log-Probability(对数概率)也随训练步数线性变化。
多为连接词(如 "wait", "but"): 概率线性变化。上升代表模型学会了反思和转折等行为;下降代表错误路径。
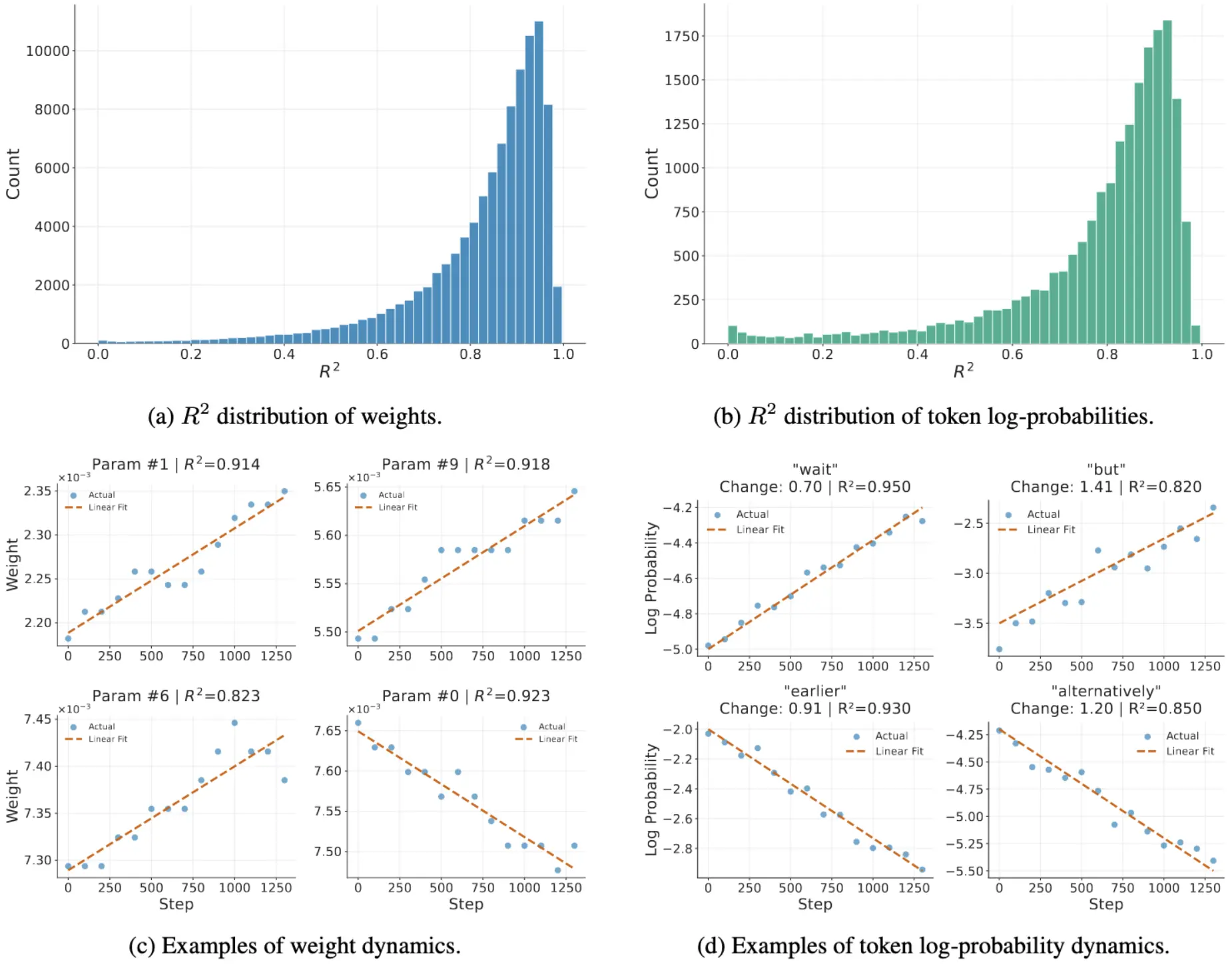
(图注:左图为权重的 R^2 分布,右图为 token 对数概率的变化,可见明显的线性趋势)
这意味着什么?
这暗示了当前的 RLVR 训练可能并没有在后期“不断探索新策略”,而是在训练初期就确定了优化方向,剩下的几千步更多是在简单地放大这个趋势(Amplify)。
02. 为什么会这样?
我们在文中给出了理论解释,简单来说:
- 低学习率 & 大 Batch Size: RLVR 通常使用极小的学习率(< 1e-5)和较大的 Batch Size(加上 Rollout 数量)。
- Adam 优化器特性: 在梯度方向相对稳定的情况下,Adam 优化器倾向于产生恒定的更新步长。
- 一阶主导: 尽管 Transformer 是非线性的,但在参数变化较小的情况下,输出的变化主要由权重的一阶变化项主导(泰勒展开的一阶近似),二阶项(t^2)的影响微乎其微。
这种“线性”本质上说明:RLVR 的大部分计算量,可能都在重复造轮子。
03. 如何利用这一特性?从“外推”到“交替训练”
既然验证了 RL 训练轨迹具有极强的线性特征,我们完全可以大胆一点:跳过那些冗余的中间步骤,直接“计算”出未来的模型。
我们提出了三种利用策略:
1. Logit Extrapolation(Logits 外推)
这是一个无需额外训练即可“预知未来”的技巧。既然验证了 LLM 的训练轨迹是线性的,我们只需选取两个早期检查点(t_0, t_1)的 logits,通过简单的线性公式即可算出未来某一步(t')的输出分布:
其中 \alpha 是放大系数。
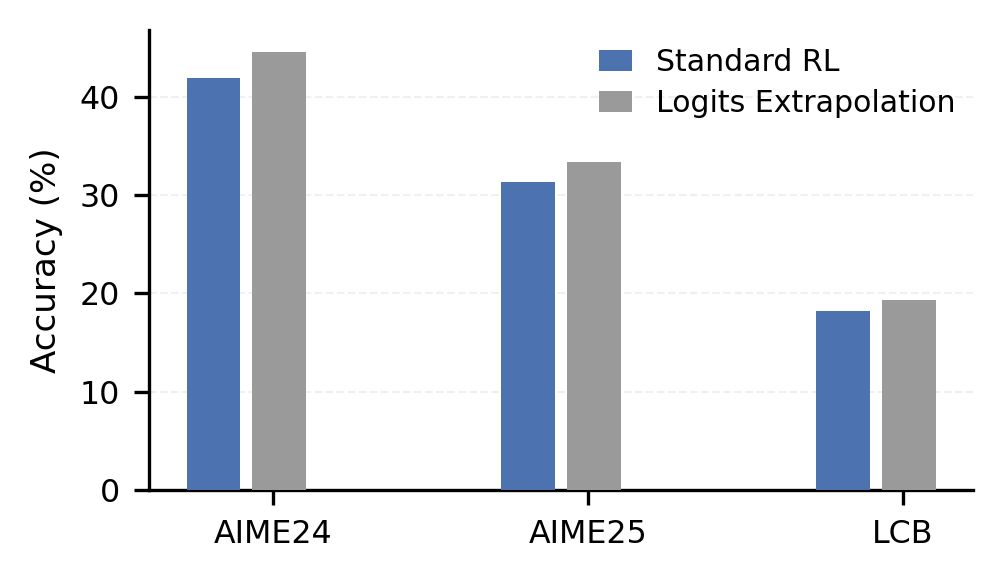
实验发现(惊喜): 这不仅仅是模拟未来,它甚至超越了未来。
实验数据显示,Logits 外推在 AIME 和 LiveCodeBench 上均取得了一致的性能提升。更重要的是,它能有效抑制 RL 训练后期常见的 “熵坍塌(Entropy Collapse)” 和过拟合问题。
简单来说,它帮模型“过滤”掉了后期训练中的噪音,获得了比老老实实跑完训练还要高出 3% 左右的性能。
2. Weight Extrapolation(权重外推)—— 直接预测参数
如果说 Logits 外推是预测结果,那 Weight Extrapolation 就是直接预测模型本体:
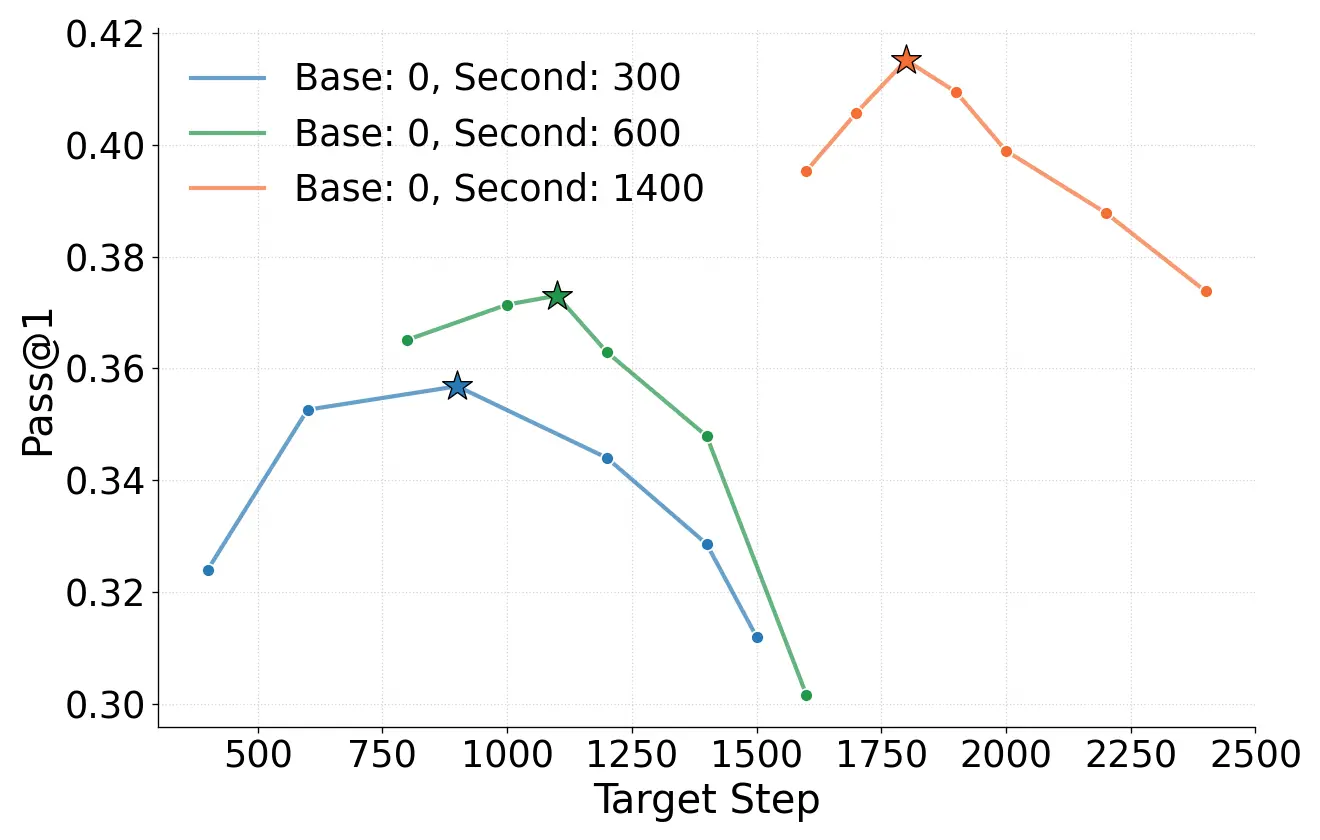
实验发现(倒 U 型曲线):
我们固定早期检查点,尝试向后外推不同步数,发现了一个有趣的 “倒 U 型”现象:
在一定范围内(例如几百步),直接算出来的模型性能完全不输真实训练;但如果步子迈得太大(例如从 step 300 直接推到 step 2000),性能会先升后降。
这说明:虽然大方向是线性的,但模型在长途跋涉中仍需要微调方向,纯粹的线性外推有其极限。
3. RL-Extra(交替式训练)—— 核心大招
为了解决纯外推在长距离下的误差,我们提出 RL-Extra:
“跑几步 RL 校准方向 -> 往后外推一大截 -> 再跑几步 RL 校准 -> 再外推”。
核心理念是:“用少量真实的 RL 训练来校准方向(Grounding),用大量的线性外推来加速赶路。”
这是一个周期性循环的过程(Cycle C = m + n):
- 1.校准阶段(Grounding): 进行 m 步正常的 RL 梯度更新(如 GRPO),确保模型学习到正确的 Reward 信号,修正优化轨迹。
- 2.加速阶段(Extrapolation): 基于刚才确定的方向,直接在权重空间线性外推 n 步。
- 3.循环: 再次回到RL更新,修正方向,再外推。
04. 实验结果:白嫖的算力,一样的效果
在AIME24、MATH-500和LiveCodeBench等权威榜单上,RL-Extra展现了惊人的效率:
- 速度起飞: 在达到相同 AIME24 准确率(例如 38%)的情况下,标准 RL 需要 1100 步,而 RL-Extra (20 RL步 + 100 外推步) 只需要 180 步真实的 RL 计算。
- 综合加速比: 达到了 6.1倍 的 Wall-clock speedup!
- 性能无损: 在各种算力预算下,RL-Extra 的表现均优于或持平于标准 RL 训练。
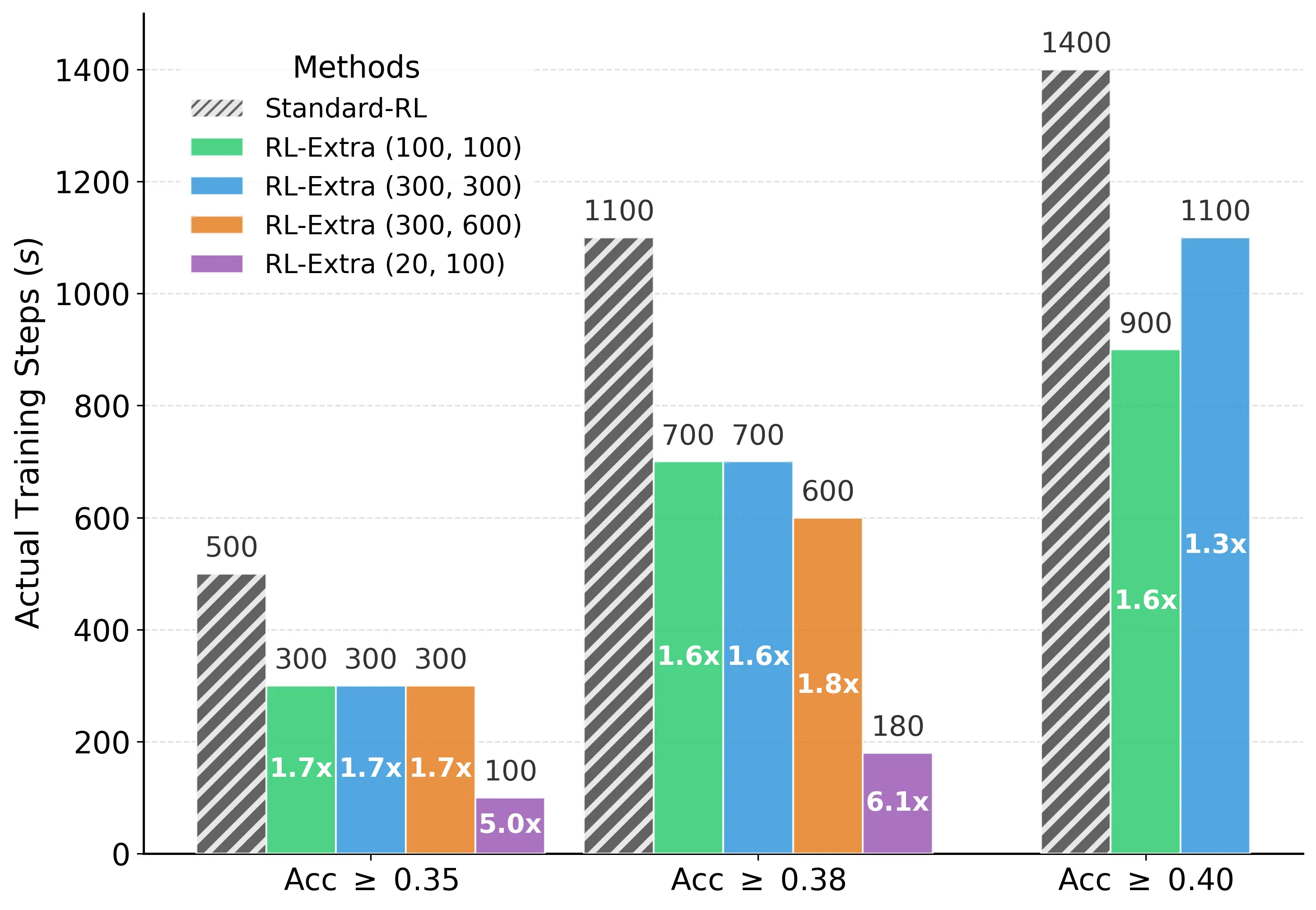
(图注:RL-Extra 在相同训练预算下,性能始终优于标准 RL)
这再次印证了:RL 训练中大量的计算步骤其实只是在“线性重复”,完全可以通过数学外推来替代。
05. 总结与思考
这篇文章不仅提供了一个实用的加速 Trick,更重要的是它让我们重新审视 RLVR 的训练机理。
1.信息密度低: 现有的 RLVR 训练步数中,大部分步骤的信息增量极低,只是在机械地执行既定路线。
2.方向为王: 训练初期的方向探索(Exploration)可能比我们想象的更重要,一旦方向确定,剩下的就是线性的“执行”。
3.普适性: 该结论在 Qwen、Llama、DeepSeek 等多种底座,以及 GRPO、Reinforce++ 等多种算法上均被验证。
对于资源有限、想要尝试复现 DeepSeek-R1 或训练垂直领域 Reasoning 模型的小伙伴来说,RL-Extra 绝对是一个值得尝试的“省钱”方案。
One More Thing:
如果你的显卡在燃烧,不妨试试先把 Checkpoint 拿出来画个图,说不定你的模型也正走在一条笔直的康庄大道上,等着你去“外推”它!