作者:Hao Bai
https://zhuanlan.zhihu.com/p/2006963575110013959
今天来聊一下RL的近期热门问题,涉及Off-policyness,Sample Efficiency与Priviledge Information这些话题,可以理解为SFT+RL的一些宏观动力学。这是我认为高度重要的问题。
Off-policy learning在deep rl时代主要是用来节省rollout开销的,比如在digital agent领域,trajectory collection一般只有在大的academia lab或者frontier industrial lab才能实现。
例如我们的 DigiRL 与 Digi-Q 这条工作线,全部用的是 off-policy RL,来复用rollout data。这主要是因为rollout需要与手机/电脑模拟器交互,造成较大的rollout开销。在大量其他模拟资源需求较大的领域也是如此。
在Agentic RL时代,人们大量使用了off-policyness的扩展概念:它可以不仅限于rollout policy的前几个iteration,也可以泛指比较一个不同于当前policy,但与当前policy解决相似/相同问题的teacher policy。
由于我们希望学习的policy能变强,所以这个teacher policy往往是一个更强的policy,或者是带有priviledge信息的相同policy。
在这种泛化的概念下,off-policyness往往会带来更好的sample efficiency,但同时会伴随着更大的distribution sharpening风险。
一方面,在optimal trajectory上直接SFT会带来最大的off-policyness,以及最大的sample efficiency(因为不需要base policy进行任何on-policy rollout)。
然而off-policy trajectory 的 base policy coverage非常小,会导致部分学到的solution space没法跟base policy的solution space链接起来,进而影响性能。在很多情况下,这会导致performance crash(reward curve大幅下降甚至归零)。
另一方面,使用纯on-policy learning的sample efficiency低的可怜,回到了我们上面说的问题。
在这样的背景下,涌现出了非常多的融合方法。它们尝试寻找一个适中的off-policyness,使得RL training既有较强的sample-efficiency,又有比较好的solution space coverage。
例如TML提出的On-Policy Distillation (OPD),仍然使用base policy的on-policy rollout,但是使用一个teacher policy做token-level reverse KL divergence,来把teacher policy的logits通过这些on-policy rollout提取到base policy中。
这种方法仍然使用base policy的rollout,但是learning signal来自teacher policy的token-level distillation,能够细化监督的粒度。这个方法甚至是reward-free的,所以可以结合一些环境中提供reward的RL算法进行共同优化。
如何对这些融合方法进行分类和思考呢? 这里我们就要提到所谓的priviledge information了。
priviledge information可以指所有能提供signal的信息,这包括一个更强的policy,一个trajectory reward,一个step reward,还有optimal trajectory。
从监督的强度和学习模式来讲,一个更强的policy和optimal trajectory都可以提供较强的监督,且为prior模式,即学习不依赖环境;
而来自环境的reward,包括trajectory-level和step-level的reward,所提供的监督稍弱,且为posterior模式,即学习依赖环境。
用这四种不同的priviledge information,可以千变万化出各种各样的算法,去适应不同问题,不同模态,和不同环境。
例如,如果有optimal solution,可以尝试使用base policy+optimal solution来代替OPD的teacher policy。这是OPSD的想法。这个方法要求有一些optimal trajectory/solution,可以理解为是对SFT的一种控制/减轻off-policyness的改进。
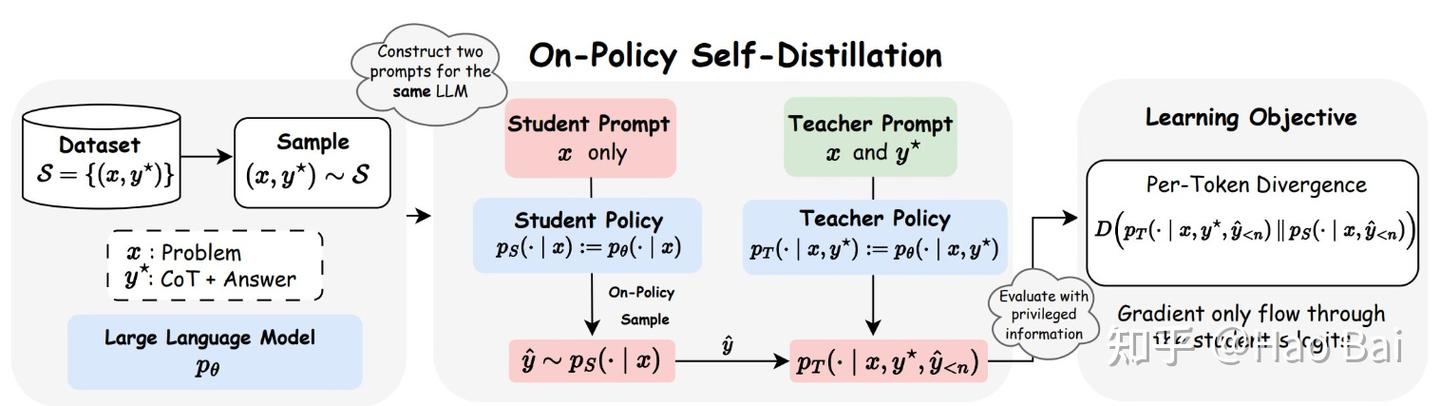
又例如,如果有feedback/reward,可以尝试使用base policy+feedback来代替OPD的teacher policy。这是SDPO的想法。这个方法放宽了限制,不要求有optimal trajectory,但是要求有环境的feedback,因此可以理解为对RL的一种更细粒度signal的改进。

上面两篇文章都不需要一个teacher policy。它们将OPD的teacher policy用base policy+priviledge information替代。
这本质上是一种in-domain adaptation,相比于基于strong teacher policy的distillation,这两种方法更容易学习in-domain的信息,同时也更容易overfit到in-domain tasks上。
上面的方法都是基于OPD的融合方法。思考,privledge information除了直接用来SFT和做OPD,还有什么用法呢?没错,还可以直接用于RL,更具体地说,可以用于guide RL rollout。
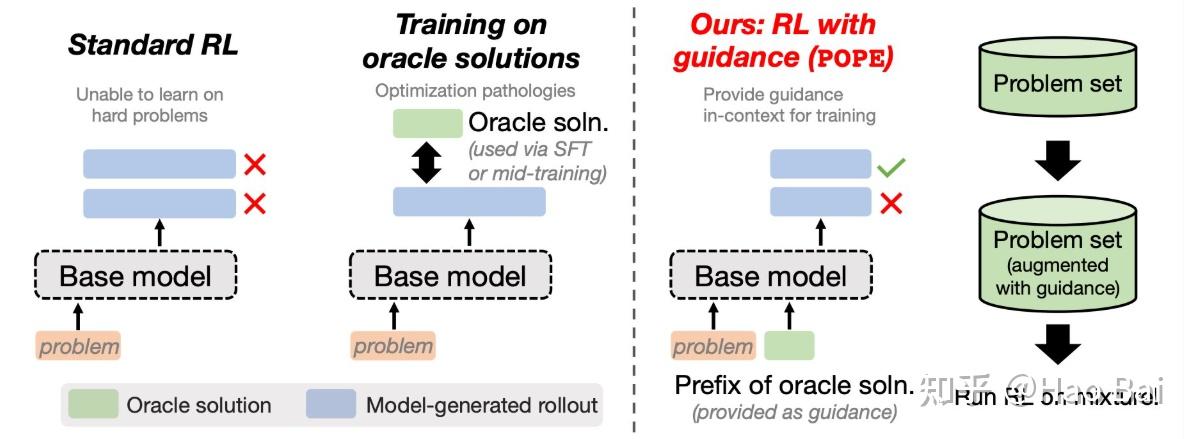
POPE和InT就是这个思路。POPE提出,如果存在optimal trajectory,我们可以使用optimal trajectory作为rollout的prefix。这会使得困难问题难度下降,因为前几步已经被解了。
但是这种方法存在一个隐患,就是rollout仍然包含不属于base policy的optimal trajectory。因此paper中讲到,base policy的学习必须只将prefix作为condition,不能计入loss。在这个限制下,SFT+prefix-guided RL效果最好。
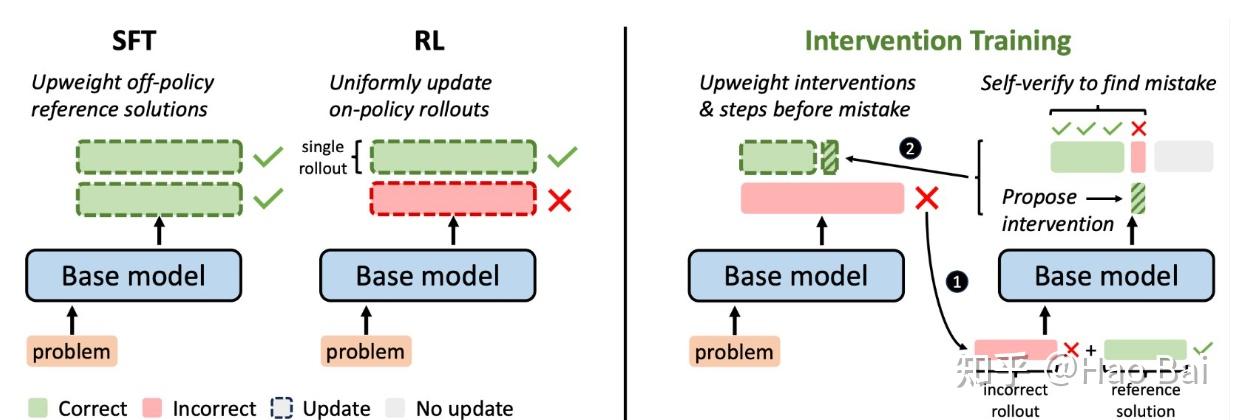
除了prefix,也可以使用intervention的方式将optimal solution介入RL rollout。InT提出,可以将optimal solution丢给base policy,让它identify第一个出现问题的位置,然后修复这一步。
随后,让base policy不带这个priviledge information继续生成。因为我参与了这篇文章,所以在这里具体讲一下这个方法,会包括更多细节,希望大家能发现些有趣的结论。
https://github.com/intervention-training/int
InT 是一种简单的算法。它从策略 π rollout 得到的一条部分正确的 trajectory 开始。然后,将 reference solution 和这条部分正确的 trajectory 提供给 π,让 π 判断哪一步是第一个错误的 step。
π 在该位置进行 intervene,通过查看 reference solution 来纠正该步。接着,π 在不查看 reference solution 的情况下 rollout trajectory 的剩余部分(见上图右侧)。
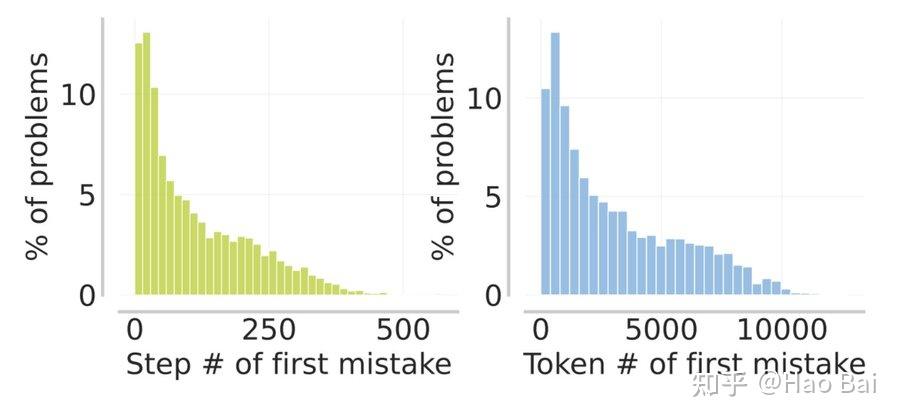
下面是它在数学领域中的一个例子。在数学题里,解题步骤通常用 “\n”(换行符)来分割。我们使用的策略 π 是 Qwen3-4B-Instruct,它通常会在每一行输出解题过程中的一个逻辑步骤。
接着,给定一条部分正确的 trajectory,我们会给每一行分配一个 ID,然后在提供 reference solution 的前提下,让 π 找出第一个错误出现的位置。
随后,π 会生成该步对应的行 ID 以及这一步“应该”正确写出的内容,然后在不再参考 reference solution 的情况下,重新生成后续的所有解题步骤,以避免 off-policyness。

我们通过两个阶段来研究 InT 的有效性:SFT 和 RL。
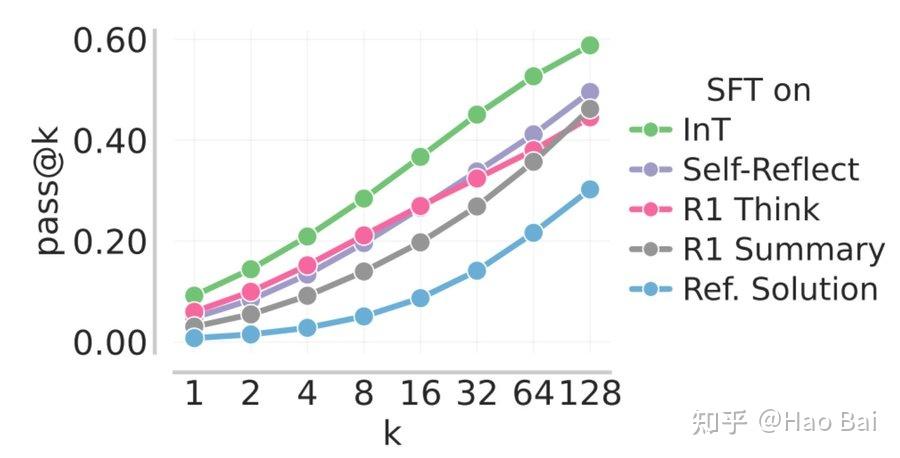
我们先聚焦于 SFT 阶段:在 IMO-Bench、AMO-Bench 和 Apex Shortlist 上,我们将 InT 与以下 baseline 进行比较:Self-Reflect(在给定 reference solution 的情况下重写整个解答)、Ref-Solution(在 reference solution 上进行 SFT)、以及 R1-Think/Summary(在来自 DeepSeek-R1 的 trajectory 的不同部分上进行 SFT)。结果表明,InT 在所有方法以及所有 k 取值下都能稳定取得最高性能。
但这种差异真的可以用 off-policyness 来解释吗?确实如此。我们发现这一点时非常高兴!我们研究了用不同方法训练得到的策略的熵,结果发现:在同一批任务上评估时,InT 在所有方法中引入的熵最低。
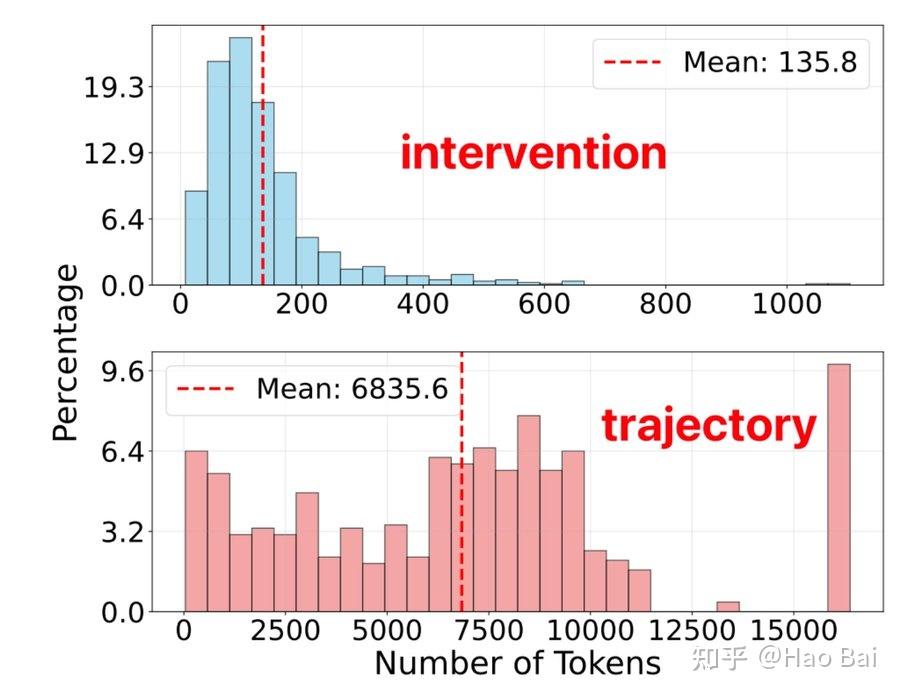
另一个问题是:**这些 intervention 到底有多长?**会不会很长,以至于性能提升其实主要来自 intervention 那一步本身?
并不是这样。intervention-step 的平均 token 数只有 136,而整条 trajectory 的平均 token 数是 6,836。也就是说,这个 intervention 非常轻量、很“短”,既能提供关键信息,又尽量保持后续生成是 on-policy。
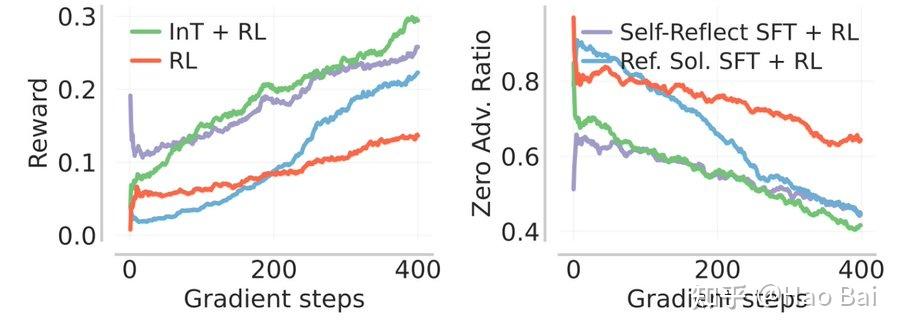
随后,我们在这些初始化的 checkpoints 上进一步研究 RL 阶段的表现。我们观察到:在训练过程中,无论看哪个指标,InT 都带来了最高的 sample efficiency 和最终性能,这两个指标分别是 success rate,以及 zero advantage ratio(指无论 k 多大,策略都始终无法解出的任务所占比例)。
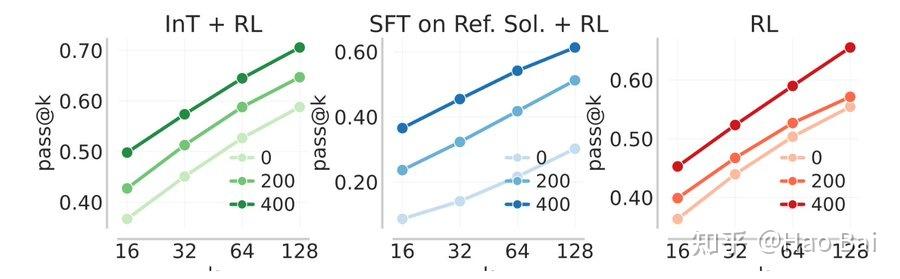
我们还在 holdout evaluation set 上评估了这些经过 RL 的 checkpoints,其中包含以下基准中最难的问题:(1) Polaris,(2) AceReason-Math,(3) Omni-MATH,以及 (4) IMO-AnswerBench。
结果显示,InT+RL 在不同的 gradient steps 以及不同的 k 取值下,都能显著优于其他方法。
随后,我们在标准化的数学基准上评估这些经过 RL 的 checkpoints,例如 AMO-Bench 和 HMMT 2025 Nov。我们观察到,InT+RL 在几乎所有标准化基准上都取得了最高性能,而且这些基准里并不只有难题。这表明:我们在自建训练集里学到的“攻克难题”的能力,确实能有效泛化到更广泛的题目分布中。

希望看完这篇essay的你能有所启发!如果你有什么疑问,欢迎在评论区讨论。