随着多模态大语言模型(Multimodal Large Language Models, MLLMs)不断向文档理解、OCR、图表分析与高分辨率真实场景理解等细粒度任务拓展,高分辨率图像输入正在逐渐成为主流配置。
然而,更高的视觉分辨率也带来了急剧增长的视觉 token 数量,使得视觉编码本身逐渐成为 MLLM 中不可忽视的计算瓶颈。
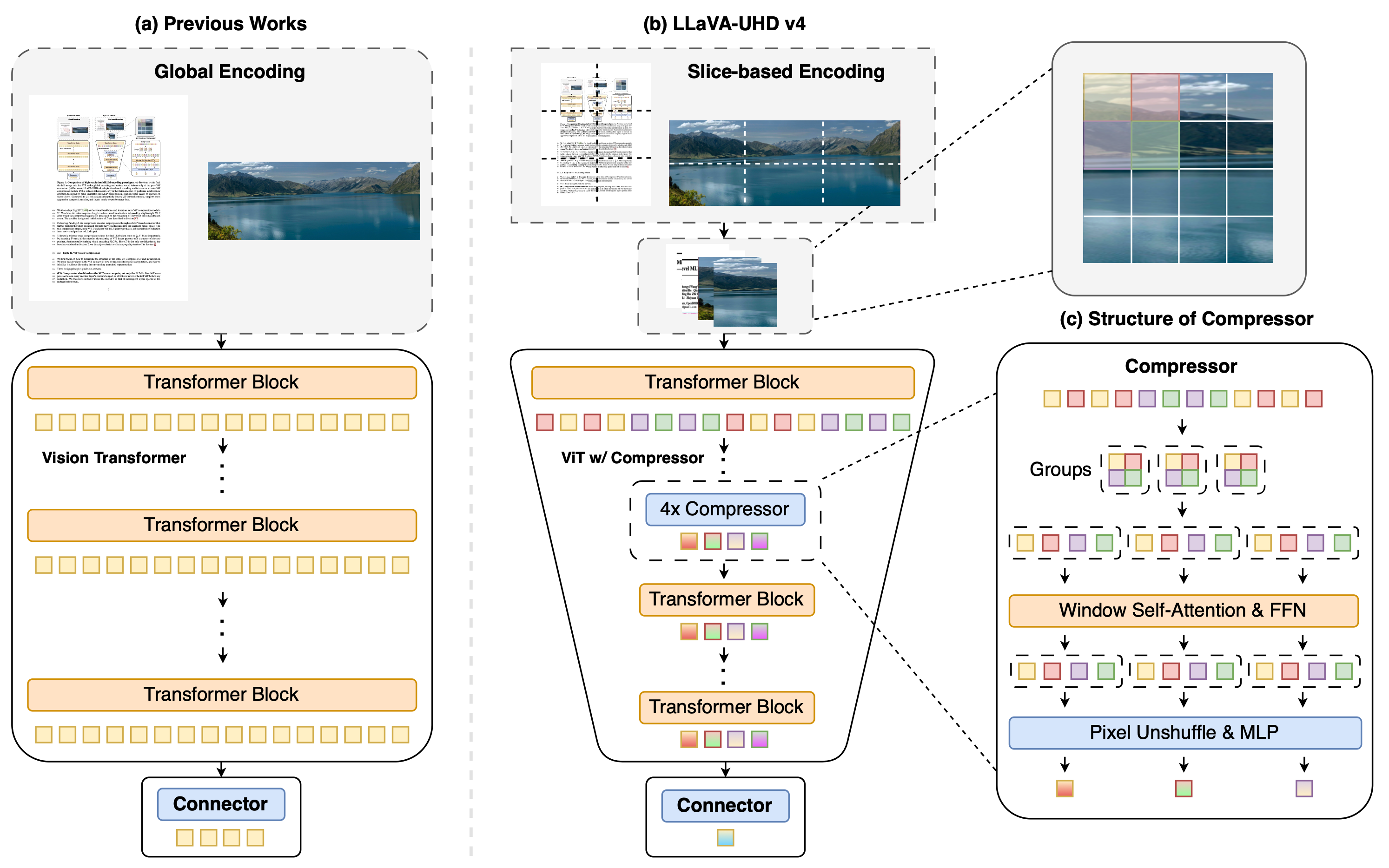
当前常见方案通常采用全局编码(global encoding)+视觉编码器后压缩(post-ViT compression)的范式:先将完整高分辨率图像送入视觉编码器(Vision Transformer, ViT),再在编码完成后压缩 token 数量。
然而已有范式的问题在于,token 压缩发生得太晚,无法减少 ViT 内部已经产生的高昂计算开销。
针对这一核心问题,团队提出 LLaVA-UHD v4,重新审视高分辨率 MLLM 的视觉编码设计,并给出一条更加高效的路径:以切片编码(slice-based encoding)替代全局编码,以ViT内部早期压缩(intra-ViT early compression)替代仅在 ViT 后压缩。
论文表明,LLaVA-UHD v4 在保持甚至略优于视觉编码器后压缩基线(post-ViT baseline)下游性能的同时,将视觉编码 FLOPs 降低55.75%,为高分辨率 MLLM 提供了一种兼顾效率与效果的实用架构。

论文地址:https://arxiv.org/abs/2605.08985
GitHub 仓库:https://github.com/THUMAI-Lab/LLaVA-UHD-v4
为什么现有高分辨率视觉编码还不够高效?
现有高分辨率 MLLM 通常沿用两项默认选择:
1.全局编码(global encoding):将整张图像直接输入视觉编码器,保留完整的全局上下文;
2.视觉编码器后压缩(post-ViT compression):在视觉编码完成后,再通过 connector 压缩视觉 token,减轻后续 LLM 的负担。
这一范式虽然看似自然,却隐藏着一个结构性效率问题。post-ViT 压缩只能减少 LLM 的输入 token,却无法减少视觉编码器自身的计算量。
当输入分辨率升高时,ViT 仍需在完整 token 序列上执行全局自注意力,计算成本随视觉 token 数量急剧上升。也就是说,当前方法缓解的是 LLM 看到太多 token 的问题,却没有真正解决视觉编码本身效率的问题。
LLaVA-UHD v4 的核心出发点正是直接削减视觉编码器内部的计算,而不能只在 ViT 之后进行压缩。
LLaVA-UHD v4 核心特点
重新审视高分辨率编码范式:切片编码优于全局编码
社区长期以来普遍认为,全局编码能够保留完整上下文、支持任意 patch 间交互,因此是更直接无损的高分辨率方案。相比之下,切片编码(slice-based encoding)常被视为一种为了计算可承受而做出的折中。
但论文中的受控实验给出了一个不同结论:在相同训练数据、相同 LLM、相同 token 预算下,切片编码在多个设置中一致优于全局编码。
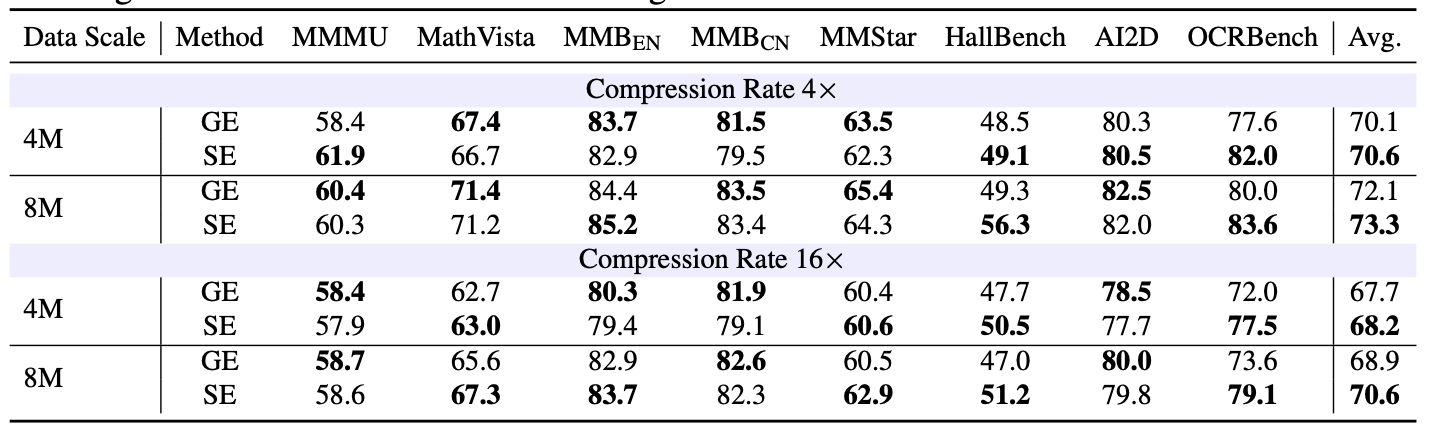
在 SigLIP 2 backbone 下,切片编码在 4× 与 16× 压缩率、4M 与 8M 数据规模的四组设置中,平均性能均优于全局编码,优势在 +0.5 到 +1.7 之间。
论文进一步通过两组额外的鲁棒性实验表明,即使更换视觉骨干或提高切片分辨率预算,切片编码相较全局编码的优势依然稳定存在。
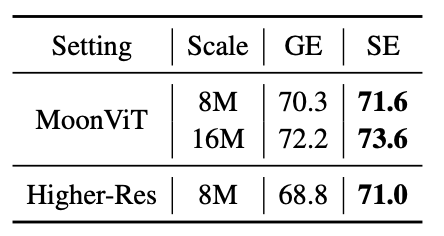
这些结果说明,在本文研究的高分辨率设置下,保留局部细节的切片式编码并非计算妥协,反而能够成为更有效的视觉表征方式。论文将其归因于两者不同的归纳偏置:切片编码让模型在空间上连贯的局部区域内建模细节,而全局编码则会让细粒度信息与全局上下文在固定 token 预算下相互竞争。
明确视觉编码后压缩的局限:真正的瓶颈在视觉编码器内部
即使采用切片编码,高分辨率图像仍会产生大量视觉 token,因此连接视觉编码器与 LLM 的压缩模块依然重要。论文首先系统比较了两类常见 connector:
- Query-based Resampler:通过少量可学习查询(learnable queries)对视觉 token 进行注意力聚合;
- Pixel-Unshuffle + MLP:将邻近 patch 的空间结构折叠到通道维度,再进行轻量投影。
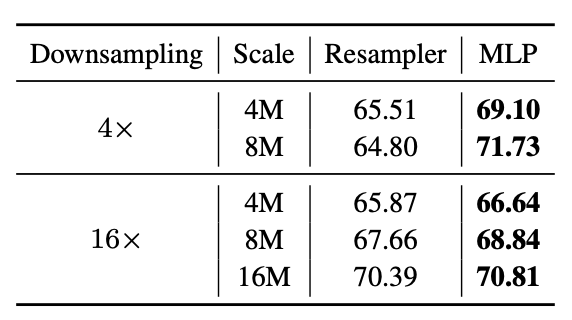
实验显示,Pixel-Unshuffle-based MLP connector 在所有比较设置下均优于 resampler。论文认为,关键差异不在于参数量,而在于 MLP 的空间合并方式显式保留了局部空间结构,而 resampler 依赖全局learnable queries进行聚合,容易弱化局部 token 与空间位置之间的对应关系。
提出 intra-ViT early compression:在视觉编码过程中提前压缩 token
LLaVA-UHD v4 在视觉编码器的浅层完成 4× 降采样。随后,视觉编码器的深层仅需处理原始 token 数量的 1/4,从根源上显著降低视觉编码成本。
- 以往方法:Global Encoding→完整 ViT编码→post-ViT compression
- LLaVA-UHD v4:Slice-based Encoding→浅层 ViT→intra-ViT compression→深层 ViT→post-ViT compression
最终,LLaVA-UHD v4 采用两阶段压缩。视觉编码器内部 4× 压缩,编码器后 MLP connector 4× 压缩,合计得到端到端 16× 的 token 压缩。与传统 post-ViT compression 基线相比,LLaVA-UHD v4 改变的关键就在于,将其中一部分压缩从 ViT 后移动到了 ViT 内部。
结构化压缩模块:在压缩前先完成局部信息整合
将 token 压缩提前到视觉编码器内部后,一个关键问题随之出现:如何在减少 token 数量的同时,尽量保留高分辨率图像中的细节信息。
如果只是简单地丢弃 token 或直接平均相邻 token,虽然可以降低计算量,但也可能损失局部区域中的重要视觉线索。
为此,LLaVA-UHD v4 设计了一个结构化的 intra-ViT compressor,使压缩过程不再是简单的 token 缩减,而是在合并前先完成必要的局部信息整合。该模块主要由两部分组成:
1.Local Window Attention:在每个(2\times2) 局部窗口内进行自注意力计算,使即将被合并的相邻 token 先交换局部上下文信息;
2.Pixel-Unshuffle+MLP Fusion:将窗口内的多个token沿通道维度折叠,并通过MLP进一步融合,得到更紧凑的视觉表示。
通过这种设计,early compressor 在降低 token 数量之前,已经先让局部区域内的视觉信息完成交互与融合。换言之,LLaVA-UHD v4减少的并不是有效视觉信息本身,而是高分辨率输入中冗余的 token表达。这样既能够显著降低后续 ViT 层的计算开销,也有助于维持压缩后视觉特征的表达质量。
参数复用初始化:让新模块从一开始就贴近预训练视觉编码器的表示流形
将压缩模块前移到 ViT 内部,意味着模型需要在预训练视觉编码器的中间层插入一个新的结构。相比于传统的 post-ViT compression,这一设计虽然能够显著降低后续 ViT 层的计算量,但也带来了新的挑战:新插入的模块必须在压缩 token 的同时,尽可能保持与原有预训练特征分布的兼容性。
如果直接采用随机初始化,压缩模块在训练初期产生的特征可能与后续 ViT 层所熟悉的输入分布存在明显偏差,从而破坏预训练模型中已经形成的表示结构,并增加后续微调的优化难度。
为此,LLaVA-UHD v4 提出了参数复用初始化(parameter-reuse initialization)。该策略并不让压缩模块从零开始学习,而是复用其前一层 ViT block 中已经训练好的参数,使新模块在初始化阶段就能够更接近原始视觉编码器的表示状态。
具体而言,压缩模块中的 window attention 与 LayerNorm 参数直接继承自前一层 ViT block;MLP 部分则被构造为近似对(2\times2)patch 窗口内的 token 分别进行特征变换,并在此基础上完成平滑融合。
通过这种方式,新插入的 early compressor 不仅承担了降低 token 数量的作用,也在训练初期尽量维持了与预训练 ViT 表示流形的一致性。换言之,LLaVA-UHD v4 的关键并不只是“更早地压缩 token”,更在于以一种与预训练视觉编码器兼容的方式,将压缩过程自然嵌入到 ViT 的特征流中。
大幅降低 FLOPs,同时保持下游性能
在主实验中,LLaVA-UHD v4 将基线中的 4× 压缩前移到 ViT 内部,使后续 ViT 层仅处理 25% 的 token。结果显示,视觉编码 FLOPs 从 3555.1G 降至 1573.1G,在多个训练数据规模下,LLaVA-UHD v4 与 post-ViT 基线的平均分差始终控制在 ±0.8 以内,平均偏差仅为 −0.29。
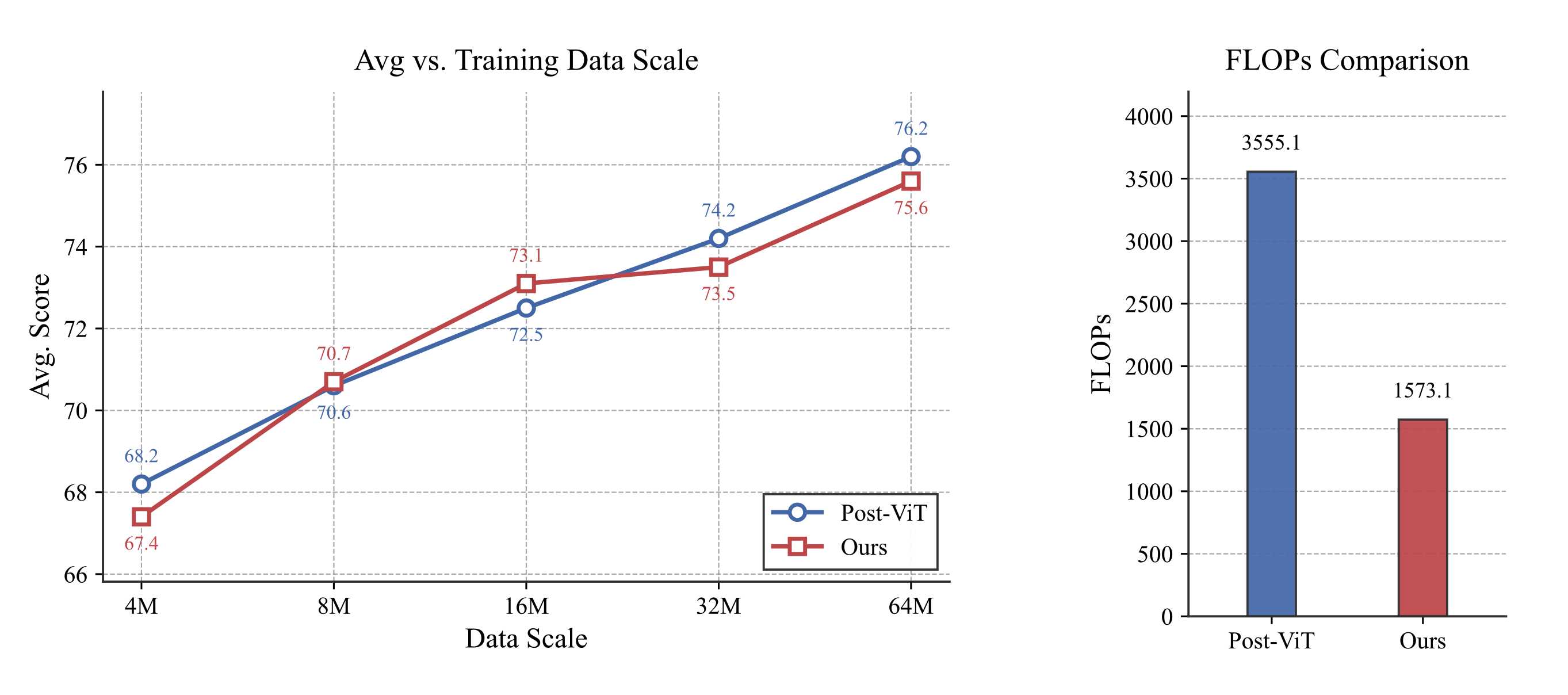
观察训练数据从 4M 扩展到 64M 时的趋势,发现:post-ViT 基线的平均分从 68.2 上升到 76.2,LLaVA-UHD v4 的平均分从 67.4 上升到 75.6。两者差距并没有随数据规模扩大而持续恶化。
这说明,在论文覆盖的数据规模范围内,intra-ViT early compression 并未引入明显的 scaling 瓶颈。
总结
LLaVA-UHD v4从高分辨率 MLLM 的核心效率矛盾出发,系统性回答了两个长期被默认却未被充分检验的问题:
1.高分辨率图像一定要采用全局编码吗?论文表明,切片编码不仅更高效,在多个设置下还表现得更好。
2.视觉 token 压缩只能放在 ViT 之后吗?论文表明,将压缩前移到 ViT 内部,并通过结构化设计保障表示兼容性,可以在几乎不损失性能的情况下,大幅削减视觉编码开销。
通过将 slice-based encoding 与 intra-ViT early compression 结合,LLaVA-UHD v4 在 16× token 压缩 下实现了 55.75% 的视觉编码 FLOPs 降幅,同时维持与强 post-ViT 基线相当甚至更优的下游表现。
高分辨率 MLLM 的效率优化,不应只关注如何减少送入 LLM 的 token,更应关注如何在视觉编码器内部更早、更稳健地降低计算负担。