作者:潜龙勿用
https://zhuanlan.zhihu.com/p/2030982954617414764
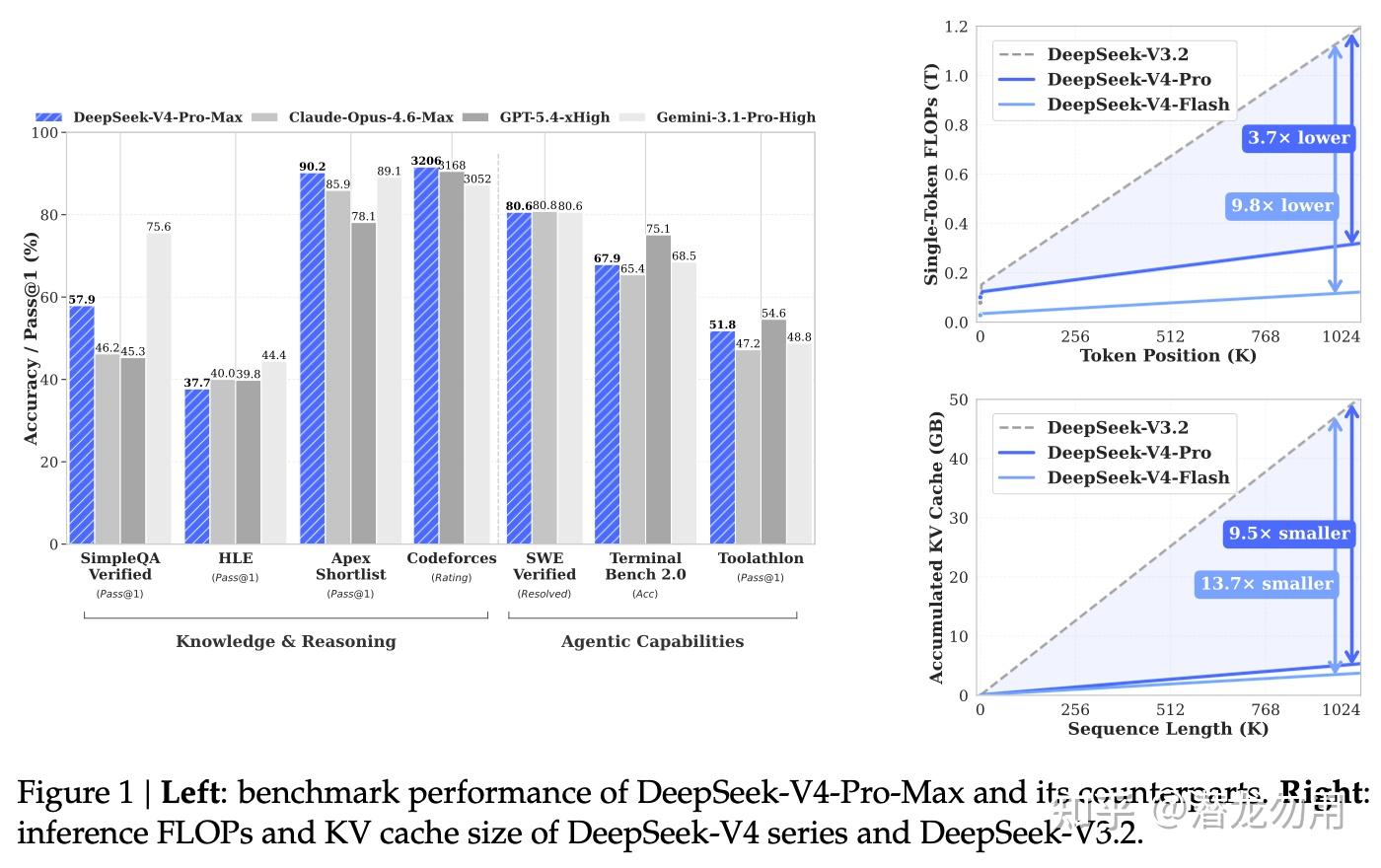
这份技术报告发布了 DeepSeek-V4 系列的 preview 版本,包含两个 MoE 模型:DeepSeek-V4-Pro(总参数 1.6T,激活 49B)与 DeepSeek-V4-Flash(总参数 284B,激活 13B),二者原生支持 1M token 上下文。
相较 DeepSeek-V3.2,DeepSeek-V4-Pro 在 1M context 下单 token 推理 FLOPs 只需 27%、KV cache 只需 10%;V4-Flash 更激进,只需 10% FLOPs 和 7% KV cache。
在公开基准上,最大推理模式 DeepSeek-V4-Pro-Max 在开源模型中全面登顶 SimpleQA-Verified(57.9 vs. Kimi-K2.6 的 36.9),Codeforces Rating 达到 3206,与 GPT-5.4-xHigh 基本持平,在 CodeForces 人类选手榜上排名第 23 位
如果把 V3/R1 的主题词概括为 " MoE + 推理 RL",那 V4 的主题词是 长上下文基础设施重构——架构、infra、训练、后训练、数据、rollout、沙箱围绕 1M context 和 agent 轨迹整体重写一遍。下面先给研究者一份速览
核心亮点速览
效果
- 百万上下文从“能跑”变成“可用”:1M context 下,V4-Pro 仅需 V3.2 的 27% single-token FLOPs、10% KV cache;V4-Flash 进一步降到 10% FLOPs、7% KV cache。
- 开源模型进入闭源前沿区间:V4-Pro-Max 在 Codeforces 达到 3206 rating,SWE Verified 达到 80.6,MCPAtlas Public 达到 73.6。
- Reasoning Effort 显著影响能力:Non-think / Think High / Think Max 在困难任务上差距明显,应用侧应按任务复杂度和成本预算动态调度。
Infra
- Agent 训练依赖可执行轨迹:DSec 沙箱支持 Function Call / Container / microVM / fullVM,并记录全序 trajectory log;agent 数据的关键是可执行、可评分、可复现。
- 大规模 RL 需要可恢复 rollout:Token 级 WAL、preemptible rollout service、deterministic kernels 共同解决抢占、重跑和 batch 变化带来的训练偏差。
- 长上下文瓶颈在 KV cache 管理:分层 KV cache 和 on-disk SWA 策略说明,长上下文部署不只是 attention 算法问题,还包括 cache layout、prefix reuse 和外存管理。
- 工具调用链路也要工程化:DSML XML tool-call schema 降低 JSON escaping 错误;Quick Instruction 复用 KV cache 执行搜索判断、query 生成等前置任务,降低 TTFT。
算法
- CSA + HCA 是长上下文注意力折中方案:CSA 负责压缩后 top-k 稀疏检索,HCA 负责重压缩后的全局 dense 记忆,SWA 补局部细节。
- mHC 用约束残差提升深层稳定性:将残差变换矩阵约束到 doubly stochastic 流形,通过 Sinkhorn-Knopp 投影控制谱范数。
- Muon 仍需稳定性技巧配合:Muon 是主优化器,但 trillion-scale MoE 仍依赖 Anticipatory Routing 和 SwiGLU Clamping 控制 loss spike。
- Specialist + OPD 替代 mixed RL:先分别训练 math/code/agent/IF 专家,再用 full-vocabulary OPD 蒸馏回统一 student,降低多能力混训干扰。
- Actor-as-GRM 面向难验证任务:用 rubric-guided data 和 Generative Reward Model 替代传统 scalar reward model,适合开放式写作、办公和 agent 任务。
一、动机
大模型发展到 2026 年,出现了几个明显的趋势:
1、推理模型催生测试时扩展(test-time scaling):从 o 系列、DeepSeek-R1 到 GPT-5/Claude/Gemini,模型在回答前 " 想得更久 " 几乎变成标配。更长的思考意味着更长的上下文
2、Agent 任务崛起:代码 Agent、多轮浏览、长文档分析,都需要在单次会话里吞掉数十万甚至百万 token
标准注意力的二次复杂度是拦路虎:在 1M token 的场景下,vanilla attention 的 FLOPs 和 KV cache 都会炸掉
DeepSeek-V4 的核心叙事就是:要把 1M context 变成日常可用。这不是做一个 " 顶到 1M" 的能力演示,而是让 1M token 的单 token FLOPs 与 KV cache 能被实际推理服务承担。这背后需要架构、infra、训练、后训练全链条的协同重构
二、架构创新
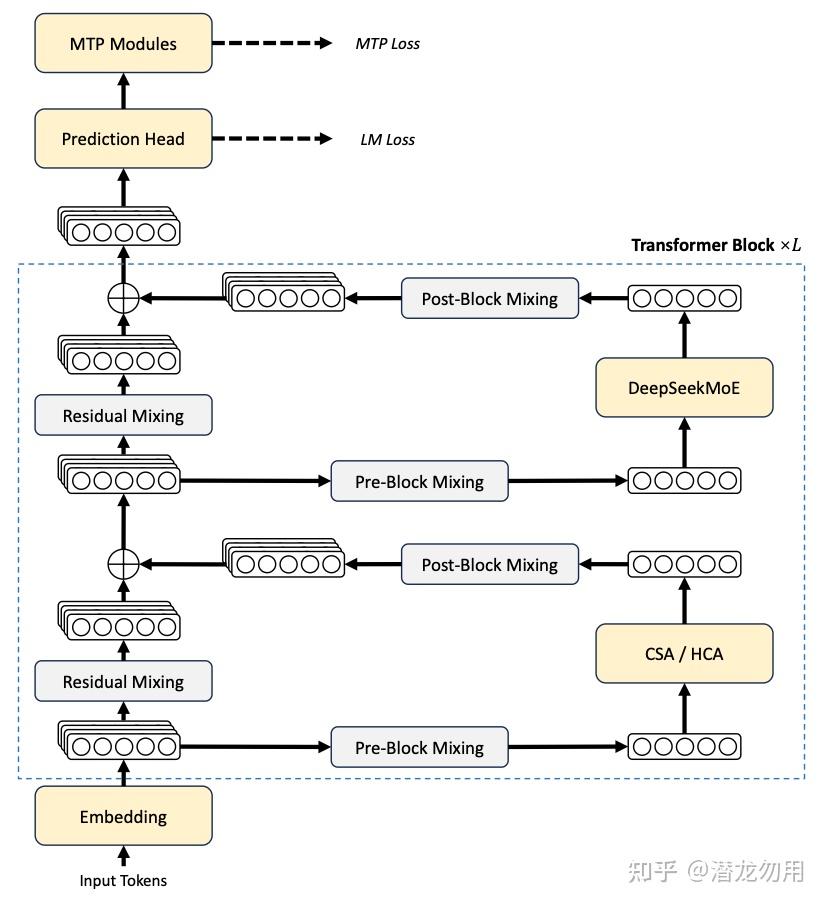
DeepSeek-V4 延续了 DeepSeekMoE + MTP 的骨架,但在三个关键位置做了替换:
- 残差连接:Residual → Manifold-Constrained Hyper-Connections (mHC)
- 注意力层:MLA → CSA(Compressed Sparse Attention)+ HCA(Heavily Compressed Attention)混合注意力
- 优化器:AdamW → Muon(仅部分模块仍用 AdamW)
2.1 mHC:约束到 Birkhoff 多胞形的残差连接
常规 residual 是 X_{l+1} = X_l + F_l(X_l)。Hyper-Connections(HC)把残差流沿宽度方向扩展 n_{hc} 倍,引入三个线性映射 A_l, B_l, C_l:
HC 的优势是在不改动内部层的情况下,给残差增加了一个正交的扩展维度。但实践中发现堆叠多层 HC 时训练数值不稳定,难以 scale。
mHC 的核心创新:把残差变换矩阵 B_l 约束到双随机矩阵(doubly stochastic)流形(即 Birkhoff 多胞形)上:
这个约束保证 \|B_l\|_2 \leq 1(非扩张映射),前向/反向都数值稳定;且 \mathcal{M} 在矩阵乘法下闭合,深堆叠依然稳。输入映射 A_l、输出映射 C_l 则通过 Sigmoid 压到非负有界。
工程上,B_l 的投影用 Sinkhorn-Knopp 迭代:先对 \tilde B_l 取 exp 保证正,然后交替行/列归一化,迭代 t_{\max}=20 次收敛
DeepSeek-V4 两款模型都把 n_{hc} 设为 4
2.2 混合注意力:CSA + HCA
这是 V4 最硬核的改动。核心思路:
对于超长上下文,压缩 KV cache 比硬算稀疏 top-k 更根本地降低 FLOPs 与访存。但纯压缩会牺牲精度,因此引入两种压缩率的层交错,再叠加稀疏选择
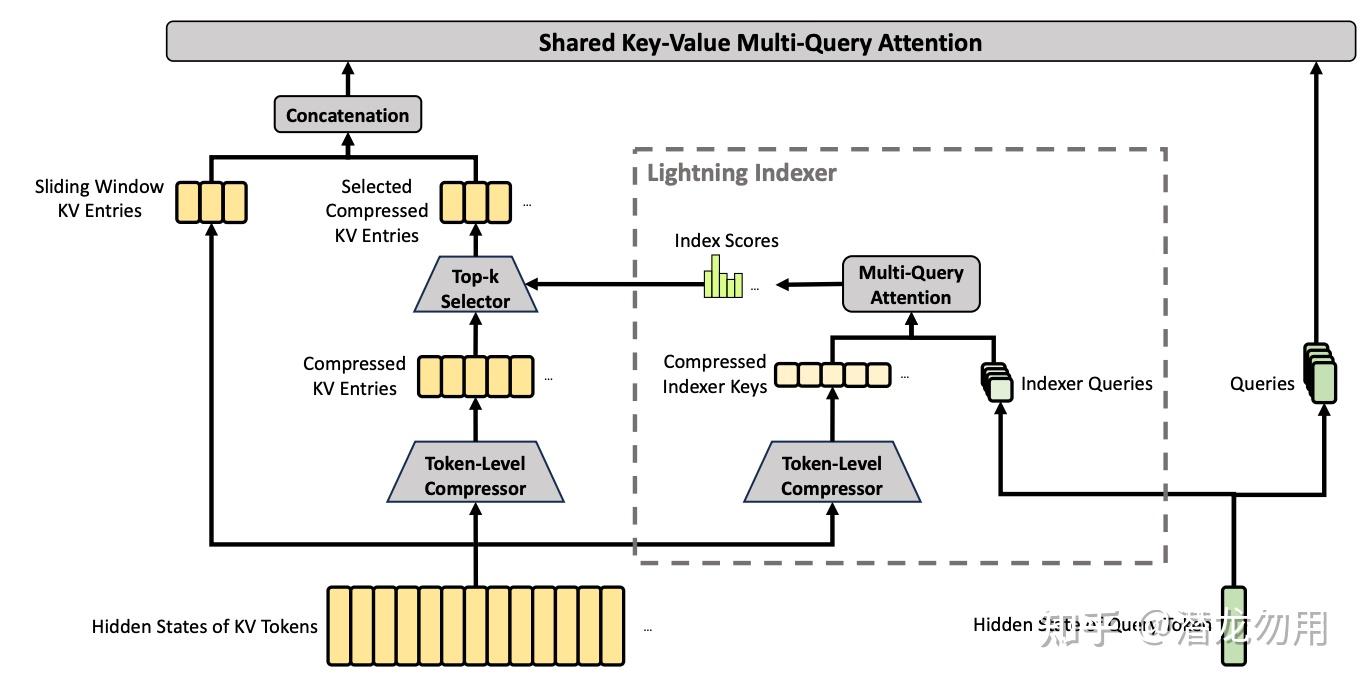
CSA(Compressed Sparse Attention):压缩率 m=4,每 4 个 token 的 KV 压成 1 个 entry,再在压缩后的 entries 上跑 DeepSeek Sparse Attention(DSA)——每个 query 通过 lightning indexer 选 top-k 个压缩 entry 做 attention(V4-Pro 取 k=1024)。
压缩过程用两条独立的 KV 序列 C^a, C^b 配合 softmax 归一化的门控权重做加权合并,相邻两个压缩块共享 C^a 与 C^b 的部分索引,形成重叠压缩
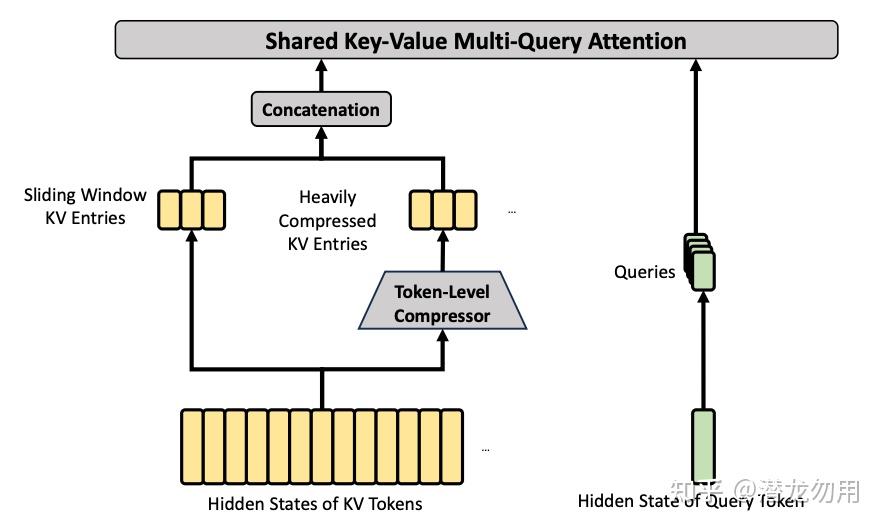
HCA(Heavily Compressed Attention):压缩率 m'=128,每 128 个 token 的 KV 压成 1 个 entry,但不做稀疏选择,直接 dense attention。由于长度已经压到原本的 1/128,dense attention 的开销也很小
交错配置:前两层用 SWA 或 HCA,后面 CSA 与 HCA 交替排布。从架构层面就把 " 能粗看的层粗看、需要精看的层精看 " 落实下来
Lightning Indexer:为了让 sparse 选择本身不拖后腿,CSA 设计了一个低秩、低精度的 indexer:query 走下投影得到 c^Q_t,再上投影出多头 indexer query;indexer 的 QK 直接用 FP4 计算。indexer 与 main attention 共享 c^Q_t,避免重复投影
Sliding Window 补丁:压缩会丢失块内局部依赖。CSA 和 HCA 都额外挂一条 n_{\text{win}}=128 的滑窗 attention 分支,把最近 128 个未压缩 token 的 KV 也塞进 core attention。另有 attention sink(可学习的分母加项)允许 head 把总 attention score 调到远小于 1
Grouped Output Projection:query 头数 n_h 很大(Pro 是 128),直接从 c n_h 投回 d 维代价太高。V4 先分 g 组降维到 d_g,再拼起来投到 d,大幅削减输出投影的参数与 FLOPs
效率账:以 BF16 GQA8(head dim 128)为基准,V4 系列 1M context 下 KV cache 可压到基准的 约 2%;即便相比本就高效的 V3.2,V4-Pro 的 1M 单 token FLOPs 只要 27%,KV 只要 10%
 '' \gg m),直接与 Sliding Window KV Entries 一起送入 Shared KV MQA,无稀疏选择步骤)" />
'' \gg m),直接与 Sliding Window KV Entries 一起送入 Shared KV MQA,无稀疏选择步骤)" />
2.3 Muon 优化器(Hybrid Newton-Schulz
V4 抛弃了传统的 AdamW 作为主优化器,主体参数用 Muon,只有 embedding、prediction head、RMSNorm 权重、mHC 的静态偏置这些元素级参数还保留 AdamW。
Muon 的关键一步是对梯度做 Newton-Schulz 迭代,把矩阵近似正交化(即把 M = U\Sigma V^T 近似到 UV^T)。V4 改进为两阶段混合 NS 迭代:
- 前 8 步用 (a,b,c)=(3.4445, -4.7750, 2.0315),激进收敛奇异值到 1 附近
- 后 2 步用 (a,b,c)=(2, -1.5, 0.5),稳定锁定在 1
另一个细节:V4 的 attention 架构允许直接对 Q 和 KV entries 做 RMSNorm,从而不再需要 QK-Clip,attention logits 天然不会炸
2.4 DeepSeekMoE 的微调整
MoE 架构沿用 V3:细粒度 routed expert + shared expert + 无辅助 loss 负载均衡。V4 做了几处小调:
- 亲和度分数的激活函数从 Sigmoid(·) 改为 Sqrt(Softplus(·))
- 去掉对路由 node 数的约束,重新设计并行策略维持效率
- 前 3 个 MoE 层用 Hash routing(按 token ID 的哈希函数决定 expert),不再走 token-wise gating
后面在训练稳定性一节会看到,V4 对 MoE 的 outlier 问题做了大量专门处理
三、Infra 技术栈
这是 V4 报告中被严重低估的部分。相比 V3,V4 的 infra 几乎是重写了一遍:
3.1 MegaMoE:一个超融合 EP kernel
MoE 的瓶颈是 EP 的 All-to-All 通信。V4 的方案是把通信与计算融成一个 kernel,进一步把 expert 拆成 wave,让 " 计算当前 wave + 发送上一 wave + 接收下一 wave " 三股并行:
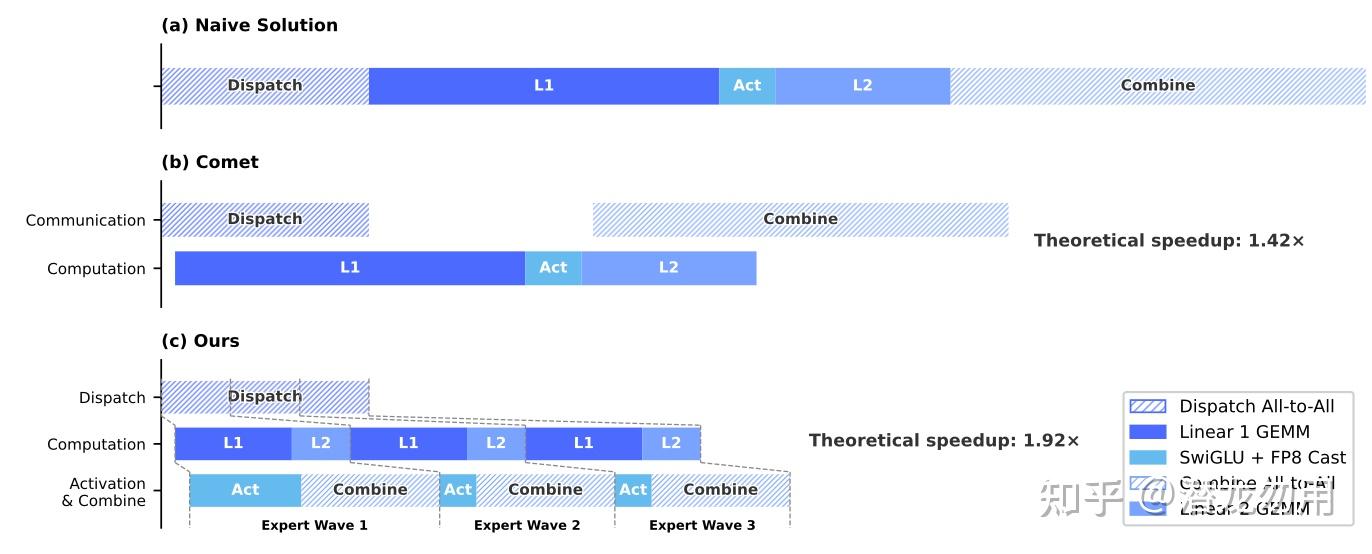
和 Comet(只做 Dispatch↔L1、L2↔Combine 两段重叠)比,V4 的 wave 级 pipeline 在 V4-Flash 架构下理论加速 1.92×,实测在 NVIDIA GPU 和华为 Ascend NPU 上都有 1.5–1.73× 的 speedup,RL rollout 这类长尾小 batch 场景能到 1.96×
代码已开源为 MegaMoE(DeepGEMM 的一部分)。
作者顺手给硬件厂商提了几点观察:
- Compute/Bandwidth 比值才是真正决定能否完全 overlap 的指标。按 V4-Pro 的数据,每 6.1 TFLOP/s 的算力对应 1 GBps 带宽就够了,再加带宽是边际收益递减
- 建议未来硬件给功耗留足余量(极致融合 kernel 会同时拉满算 + 存 + 网)
- 建议把 SwiGLU 换成无 exp / 无 division 的 element-wise 激活——同参数预算下能加大中间维度 d,进一步降低带宽压力
3.2 TileLang:SMT 加持的 kernel DSL
V4 复杂架构下手写 kernel 不现实,遂采用 TileLang DSL。两个亮点:
- Host Codegen:把 Python 运行时检查移到生成的 host 代码,调用开销从数十微秒降到 < 1 微秒。这对小而高频的 kernel(attention、mHC)影响巨大。
- Z3 SMT solver 融入代数系统:把 TileLang 的整数表达式转成 QF_NIA(无量词非线性整数算术),借 Z3 求解。于是 layout 推断、内存 hazard 检测、边界分析都能用形式化验证来解锁更激进的向量化。编译时间仍控制在几秒内
3.3 Batch-Invariant & Deterministic Kernels
为保证训练/推理比特位一致,V4 造了一整套 batch-invariant + deterministic kernel 库:
- Attention:放弃 split-KV,用双 kernel 策略解决 wave-quantization(第一个 kernel 在单 SM 上算完整序列,第二个 kernel 用多 SM 处理最后一个 partial wave,两者 accumulation 顺序严格一致)
- Matmul:从 cuBLAS 全面替换为 DeepGEMM,放弃 split-k(一些优化弥补 split-k 带来的性能损失)
- Attention Backward:给每个 SM 分配独立 accumulation buffer,跨 buffer 做确定性求和,消除 atomicAdd
- MoE Backward:token 顺序预处理 + buffer 隔离
- mHC 的小输出维度 matmul:独立输出各 split 后在后续 kernel 做确定性 reduce
代价:可能损失一点点吞吐;收益:loss spike 时能精准定位数值原因,debug 效率直线上升
3.4 FP4 QAT(MXFP4)
V4 在预训练后期引入 FP4 量化感知训练,覆盖两个关键路径:
- MoE expert 权重(占 GPU 内存大头)
- CSA indexer 的 QK 路径(attention 评分计算的热点)
还把 index score 从 FP32 量化到 BF16,top-k selector 提速 2×,KV recall 仍保 99.7%。
工程上有个巧妙设计:FP4 → FP8 是无损反量化。FP8(E4M3)比 FP4(E2M1)多 2 位 exponent,只要 128×128 FP8 块内的 FP4 子块(1×32)scale 比值不超过阈值,细粒度 scale 信息可被 FP8 的动态范围完全吸收。
于是整个 QAT pipeline 可以直接复用 FP8 训练框架,梯度对 FP8 权重求并直接回传 FP32 master weights(相当于对量化操作用 STE)。RL rollout 和推理阶段则直接用真正的 FP4 权重,保证训练与部署行为一致
3.5 KV Cache 层级:On-Disk Prefix Reuse
V4 的 KV cache 分成两部分:
- State Cache:SWA 的 n_{\text{win}} token + CSA/HCA 不足压缩块的尾部 token
- Classical KV Cache:CSA/HCA 压缩后的 entries,按 lcm(m, m') = 128 对齐分块
为了让长前缀请求(典型 Agent 场景)能复用计算,V4 把 CSA/HCA 的压缩 KV 直接存到磁盘。SWA 的 KV 不压缩、占用大(约 8× 压缩 KV 的量),给出了三个 trade-off 策略:
- Full SWA Caching:全存,无重算但写密集、写放大严重
- Periodic Checkpointing:每 p token 做一次 checkpoint,按需加载 + 部分重算
- Zero SWA Caching:不存 SWA,利用已存的 CSA/HCA KV 只需重算最后 n_{\text{win}} \cdot L 个 token 就能还原
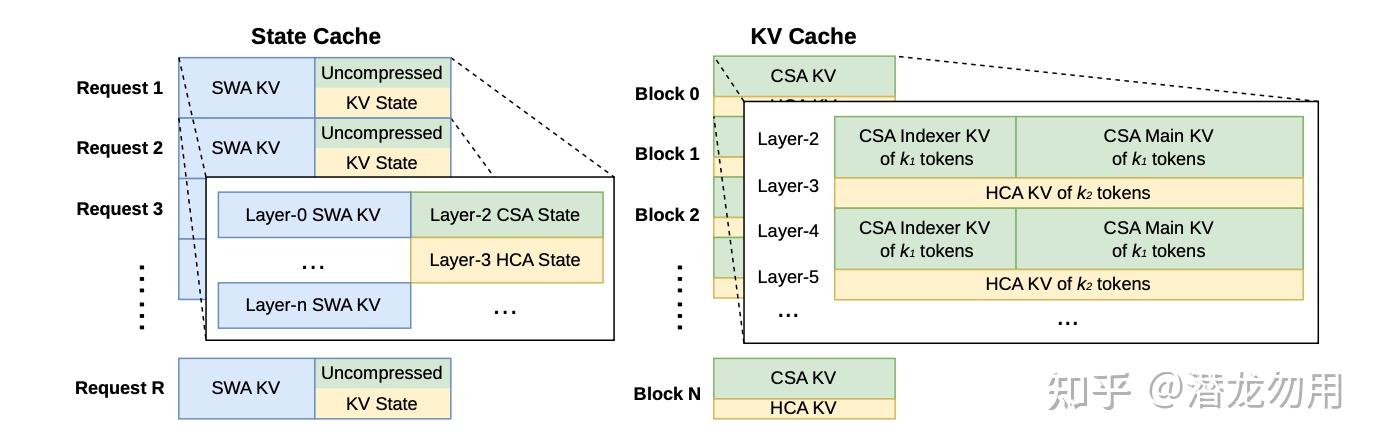 '') 个原始 token,产生 k_1 = \text{lcm}(m,m)/m 个 CSA 压缩 token 和 k_2 = \text{lcm}(m,m)/m 个 HCA 压缩 token,Layer 间交替 CSA Indexer KV / CSA Main KV / HCA KV" />
'') 个原始 token,产生 k_1 = \text{lcm}(m,m)/m 个 CSA 压缩 token 和 k_2 = \text{lcm}(m,m)/m 个 HCA 压缩 token,Layer 间交替 CSA Indexer KV / CSA Main KV / HCA KV" />
四、预训练
4.1 数据构建
在 V3 数据管线之上做了四个方向的加强:
- Web 数据去批量自动生成与模板化内容(应对 model collapse 风险)
- 编码与数学 仍是核心;中训阶段加入 agentic data 增强编码能力
- 多语言语料扩大,强化长尾文化知识
- 长文档重点策展:优先科学论文、技术报告等高学术密度材料。这里有个被很多解读忽视的关键点——V4 追求的不是 " 凑出 1M token 的长文本 " 而是 long effective context:文档内部必须存在真实的长程依赖(跨章节引用、定理到证明的跨段落调用、长函数调用链等),否则模型即便 " 看到 " 了长文本也学不到长程 reasoning 模式
最终 pre-training 语料超过 32T tokens。Tokenizer 仍是 V3 的 128K 词表,外加若干上下文构建的 special token。Packing 策略沿用(多个样本拼进同一序列以提高 GPU 利用率),但因为拼接会让跨样本 token 意外地落进同一 attention window,V4 启用 sample-level attention mask 做硬隔离(V3 没有这一步)——在长序列高打包率下这一步对防止 " 跨样本泄漏 " 变得重要
4.2 模型/训练超参
| 配置 | DeepSeek-V4-Flash | DeepSeek-V4-Pro |
|---|---|---|
| Layers | 43 | 61 |
| d_{\text{hidden}} | 4096 | 7168 |
| Experts | 1 shared + 256 routed | 1 shared + 384 routed |
| Activated experts | 6 | 6 |
| Query headsn_h | 64 1 | 28 |
| CSA attention top-k | 512 | 1024 |
| MTP depth | 1 | 1 |
| Total / Activated | 284B / 13B | 1.6T / 49B |
| Training tokens | 32T | 33T |
序列长度 Curriculum:4K → 16K → 64K → 1M 稀疏化 Curriculum:先用 dense attention 预热 1T tokens,在 64K 序列长度处引入稀疏(先 warmup lightning indexer,再正式训练),然后稀疏注意力陪伴剩余训练
Muon 配置:momentum 0.95、weight decay 0.1、update RMS rescale 到 0.18(为复用 AdamW learning rate)。AdamW 仅用于 embedding/head/RMSNorm 等
4.3 训练稳定性:两把救火钥匙
训练 T 级 MoE 模型必然遇到 loss spike。V4 发现 spike 与 MoE 层的 outlier 强相关,而路由机制又会放大 outlier。两招:
① Anticipatory Routing:把 backbone 和 routing 的参数更新解耦。第 t 步用 \theta_t 算特征,但用 \theta_{t-\Delta t} 的历史参数来算 routing index。工程上,提前在第 t-\Delta t 步读取第 t 步的数据、一起算 routing index 并 cache,流水线和 EP 通信重叠后,wall-time 开销约 +20%。更妙的是动态触发:只有检测到 loss spike 才回滚并激活 Anticipatory Routing,稳定一段时间后再回归标准训练。总开销可忽略
② SwiGLU Clamping:经验性发现把 SwiGLU 的 linear 分量 clamp 到 [-10, 10]、gate 分量上限 10,能有效消除 outlier。机制尚不清楚,但效果显著
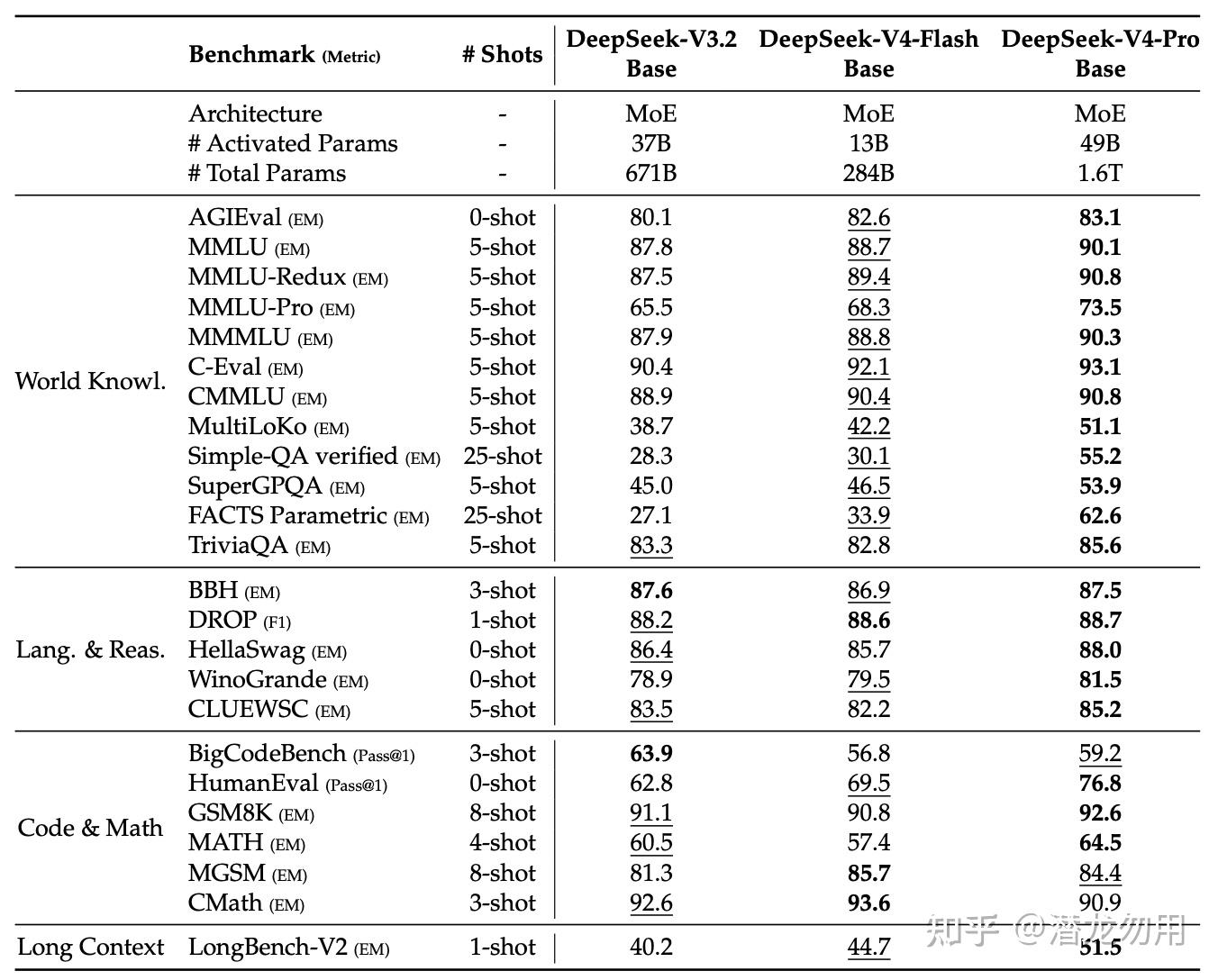
4.4 Base 模型评估
V4-Flash-Base(13B 激活)在绝大多数 benchmark 上反超 V3.2-Base(37B 激活),尤其世界知识和长上下文任务。V4-Pro-Base 再上一个台阶:
- SimpleQA-Verified 55.2 vs V3.2 的 28.3
- FACTS Parametric 62.6 vs V3.2 的 27.1
- MMLU-Pro 73.5 vs V3.2 的 65.5
- LongBench-V2 51.5 vs V3.2 的 40.2
Base 阶段的领先为后训练奠定了基础
五、后训练:Specialist + OPD 两阶段
V4 的后训练范式相比 V3.2 有一个方法学级别的替换:把原先的 mixed RL 阶段整个换成 On-Policy Distillation (OPD)。
整体流程:
1、Specialist Training:针对 math / code / agent / instruction following 等每个域,独立训练一个 expert 模型(SFT + GRPO RL)
O
2、n-Policy Distillation:学生模型在自己采样的 trajectory 上,从 10+ teacher 的全词表 logits 分布拟合 reverse KL
5.1 Specialist Training
每个 expert 都走 SFT → GRPO 的标准流程,但有几个值得展开的新设计。
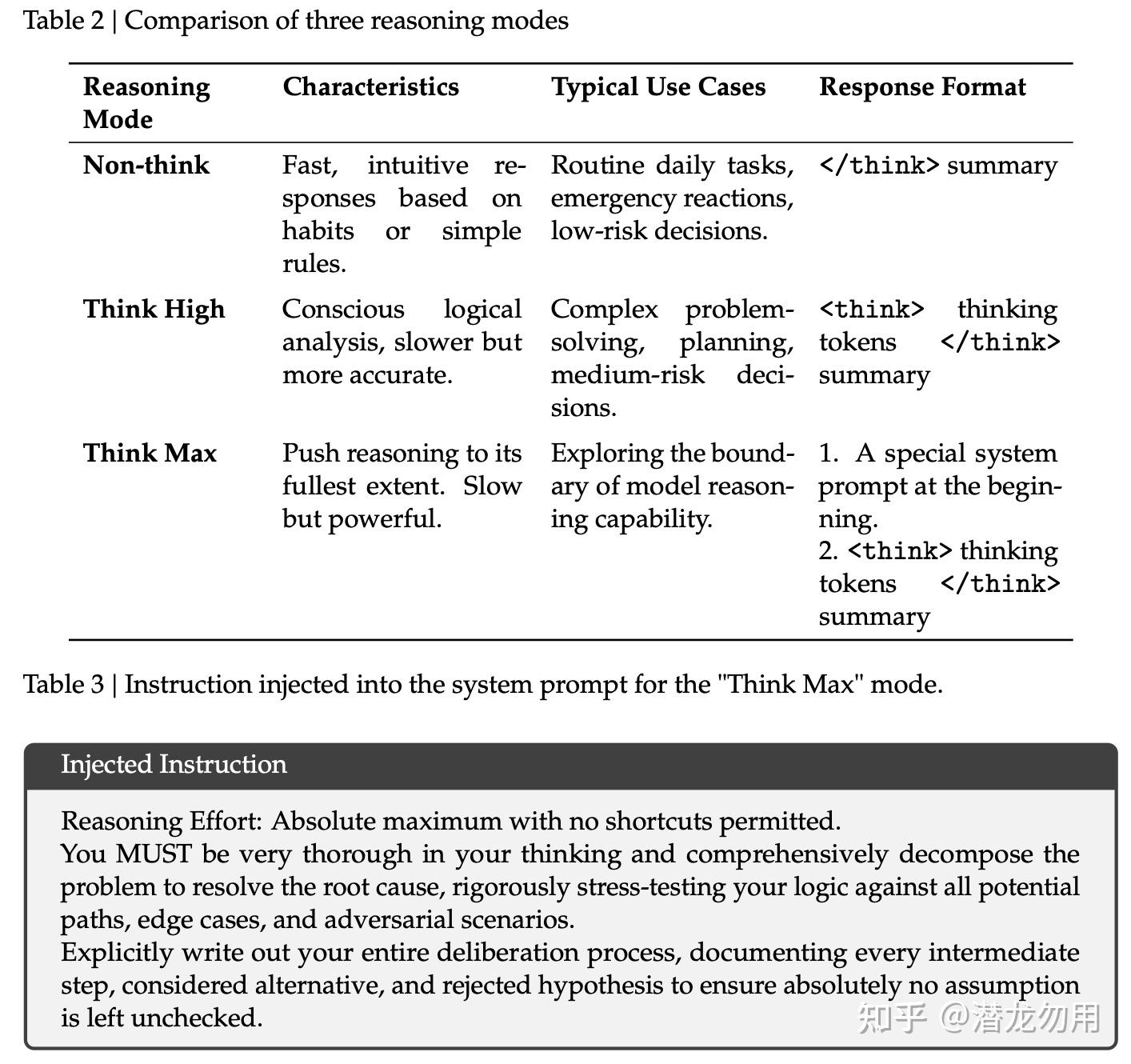
三档推理强度(Reasoning Effort):V4 显式训练三种模式共存
| 模式 | 特点 | 响应格式 |
|---|---|---|
| Non-think | 快速直觉响应 | </think> summary |
| Think High | 自觉的逻辑分析,较慢但准确 | <think> thinking </think> summary |
| Think Max | 推至极限的思考 | 先注入特定 system prompt,再<think> ... </think> |
 ""Reasoning Effort: Absolute maximum with no shortcuts permitted ...)" />
""Reasoning Effort: Absolute maximum with no shortcuts permitted ...)" />
每个模式用不同的 length penalty + context window 做 RL 训练。Max 模式的 system prompt 直接要求模型 " 不走捷径、完全展开思考、写出所有中间步骤 "
Generative Reward Model(GRM):硬核创新在这里。
对 " 难验证 " 的任务(不是那种有 test case 或 rule-based verifier 的简单任务),传统做法是做 scalar reward model(走 RLHF 路线,需要大量人工标注)。V4 完全舍弃 scalar reward model,改用:
- rubric-guided RL data(带评分 rubric 的数据)
- 让 actor 网络本身兼任 GRM,直接用 RL 优化 GRM
这样做的收益是让模型的 " 评判能力 " 和 " 生成能力 " 在同一参数空间里共同进化——评判时可以调用自身的推理能力,生成时又能内化评判标准。只需要少量多样化的人工标注,模型靠自身逻辑泛化到复杂任务
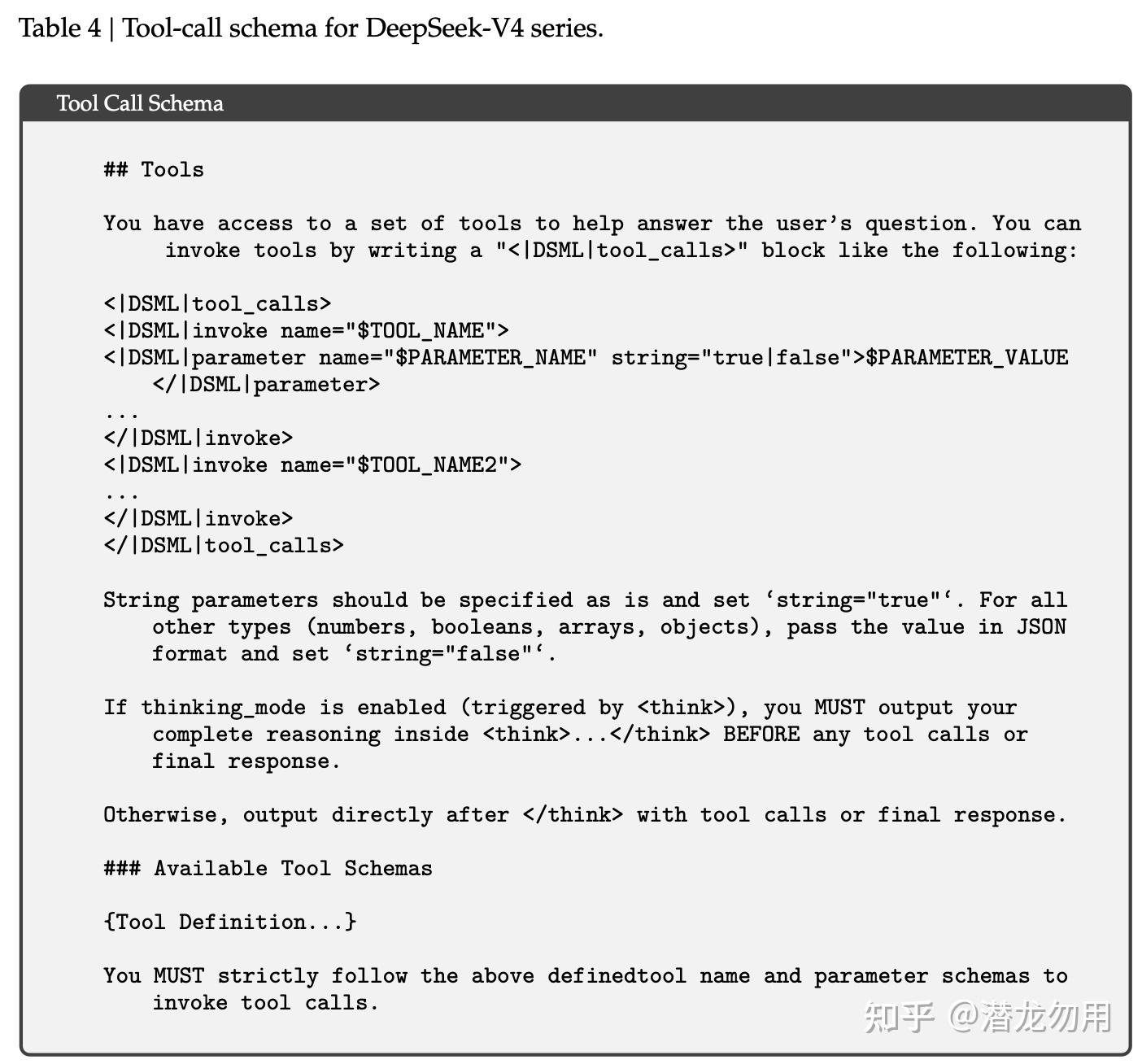
Tool-call Schema:引入 |DSML| 特殊 token + XML 格式,替代 V3.2 的 JSON 格式。XML 实验显示显著减少 escaping 失败和工具调用错误
Interleaved Thinking 改版:V3.2 在新用户消息到来时会丢掉所有 reasoning trace;V4 在工具调用场景下全程保留 reasoning,跨 user turn 也不丢。这对长程 Agent 任务尤其关键——模型能维护一条累积的 chain-of-thought,不必每轮重建思考上下文
Quick Instruction 特殊 token:chatbot 里有很多前置轻任务(判断要不要搜索、生成 title、识别 domain、判断 URL 是否要抓取)。V4 给每个任务分配一个 special token(<|action|>、<|query|>、<|title|>、<|authority|>、<|domain|>、<|extracted_url|>、<|read_url|>),直接复用已算的 KV cache,避免再起一个小模型做 prefill。多个 Quick Instruction 还能并行,显著降低 TTFT
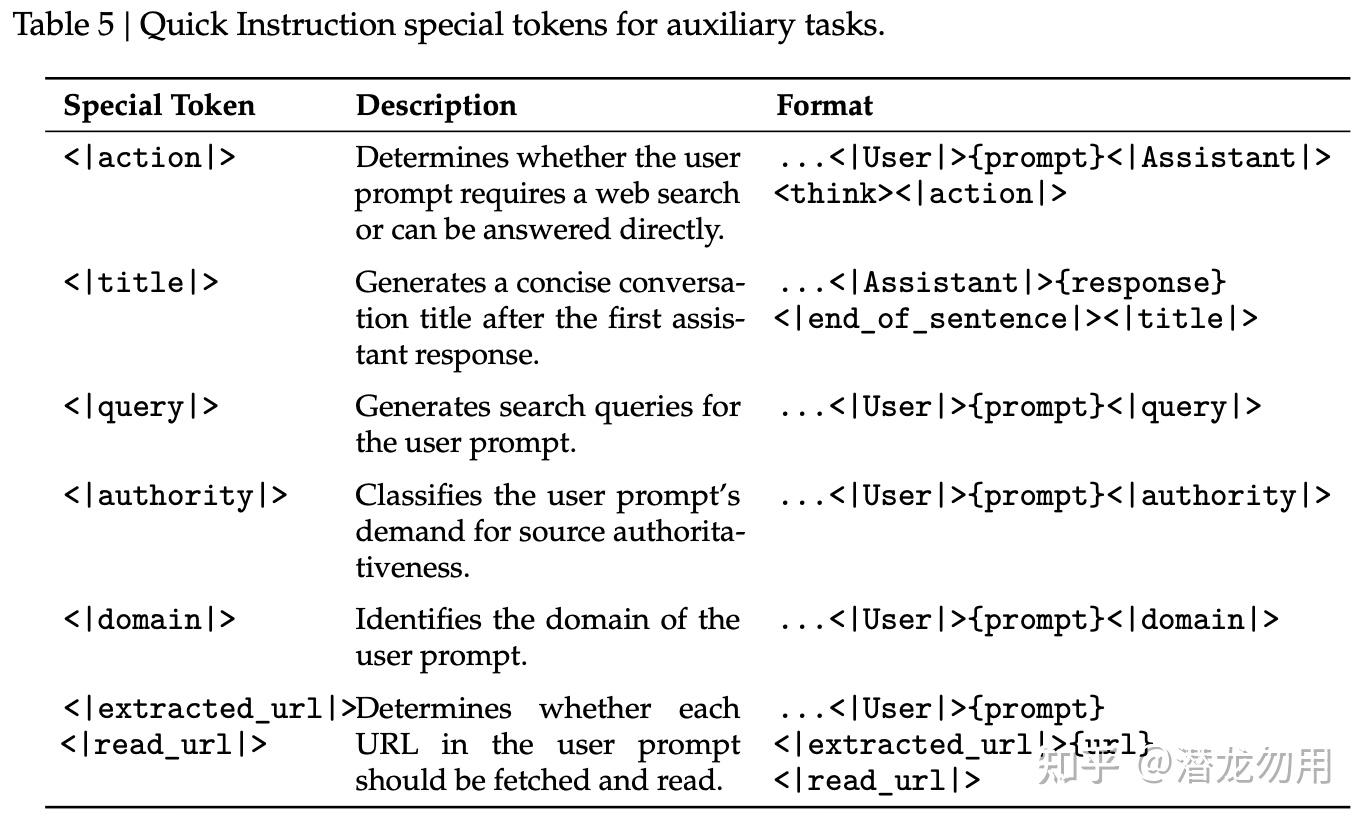 <<|title| 在 assistant 响应后生成会话标题、|query| 在 user prompt 后生成搜索 query)" />
<<|title| 在 assistant 响应后生成会话标题、|query| 在 user prompt 后生成搜索 query)" />
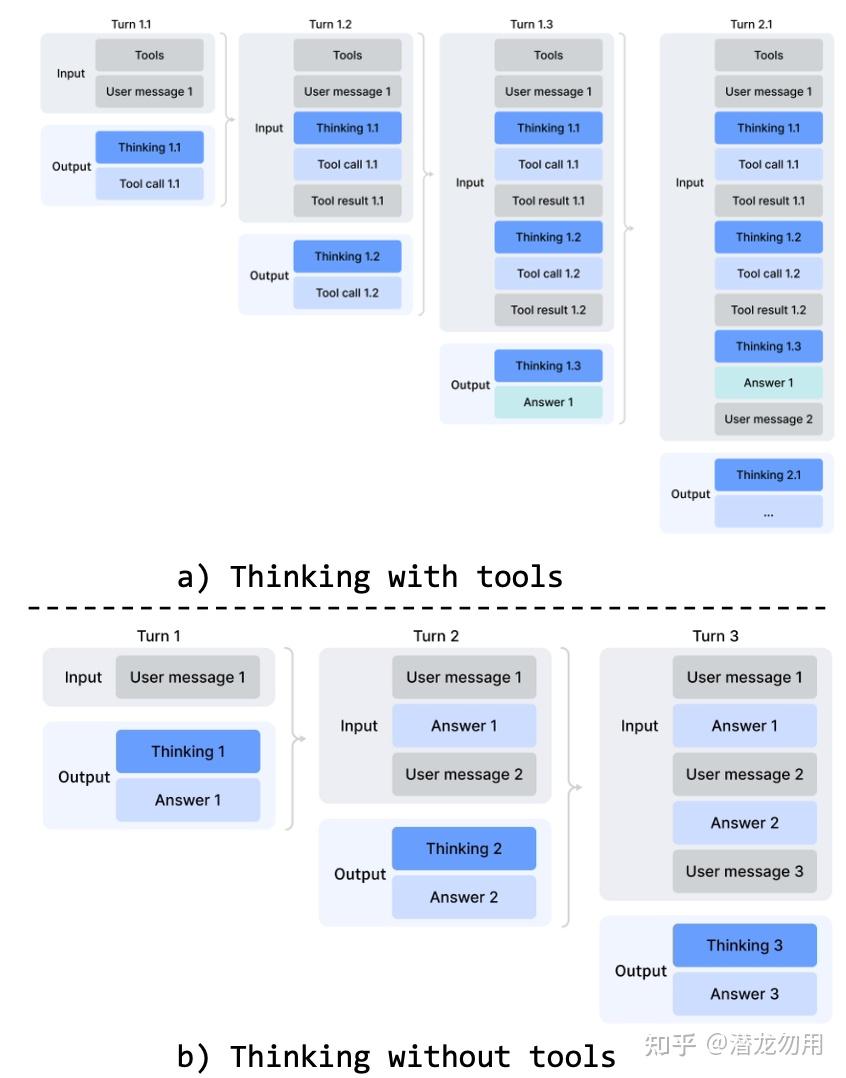 <<think 块;(b) 普通对话场景:新 user message 到来时丢弃之前的 thinking 内容" />
<<think 块;(b) 普通对话场景:新 user message 到来时丢弃之前的 thinking 内容" />
5.2 On-Policy Distillation:用 Full-Vocabulary Logits 蒸馏 10+ 老师
对 #N# 个 expert 模型 \{\pi_{E_1}, ..., \pi_{E_N}\} ,学生 \pi_\theta 的目标是:
关键点:
- 是 reverse KL,轨迹从学生自己采样(保持 on-policy)
- 学生会 " 选择性 " 地靠近相关任务的 teacher(数学题靠向数学 teacher,代码题靠向代码 teacher)
- 相比传统 weight merging / mixed RL,在 logits 级对齐更稳,能有效避免 " 能力抵消 "
为什么要 full-vocabulary 而不是 per-token KL 估计? 之前很多工作把 full KL 退化成 token-level estimate(用 \log(\pi_{E_i}/\pi_\theta) 当 advantage 塞进 policy loss 复用 RL 框架)。省资源但梯度方差高、训练不稳。V4 坚持做 full-vocab KL,代价是工程难度陡增。
工程实现亮点:
- Teacher 权重集中存在分布式存储,forward pass 时按需用 ZeRO-like 参数分片加载,缓解 I/O 与 DRAM 压力
- 词表 |V| > 100k,所有 teacher logits 显式物化到显存 / 磁盘都吃不消。V4 只缓存 最后一层 hidden states,训练时再通过对应的 prediction head 现场算 logits,用一个特制 TileLang kernel 做精确 KL
- 按 teacher index 排序训练样本,保证每个 mini-batch 里每个 teacher head 只加载一次、同时最多只有一个 teacher head 驻留显存
- teacher 参数、hidden states 的 load/offload 全异步
5.3 Agent 能力是如何 " 训 " 出来的
这是我最关心的问题。V4 没有用像 PF-LLM 那样把 agent 数据合成流程写成详细菜谱,但把几条线索拼起来可以看清楚脉络:
① 中训阶段注入 agentic data:预训练数据构建中明确 " 通过在 mid-training 阶段加入 agentic data 进一步强化编码能力 "——这意味着 base 模型已经见过大量工具调用轨迹
② Specialist 阶段做 agent 专门训练:agent 与 math、code、IF 一起作为独立 domain,有自己的 SFT 数据 + GRPO RL。V4 没披露具体的 trajectory 合成方法,但提了两类关键反馈信号:
- 易验证任务:rule-based verifier 或 test case(例如代码能否跑通、命令输出是否匹配)
- 难验证任务:rubric + GRM(actor 自己同时充当评分者)
③ DSec:production-grade 沙箱支撑 rollout
这是 V4 agent 能力的底座基础设施。DeepSeek Elastic Compute(DSec)是一套 Rust 写的沙箱平台,由 API gateway、per-host agent、cluster monitor 三个组件组成,跑在 3FS 分布式文件系统上。单集群管理数十万并发 sandbox 实例。
DSec 暴露一套统一 Python SDK(libdsec),底下支持四种执行 substrate:
| 类型 | 用途 | 技术栈 |
|---|---|---|
| Function Call | 无状态轻量调用,走预热 container 池,消除冷启动 | 自研容器池 |
| Container | 完整 Docker 兼容 | EROFS on-demand loading |
| microVM | VM 级隔离,安全敏感高密度 | Firecracker |
| fullVM | 支持任意 Guest OS | QEMU |
四种方式共享相同的 API(命令执行、文件传输、TTY 访问),参数一改就能切换。
Fast Image Loading:Container 的 base image 和文件系统 commit 都存为 3FS-backed 只读 EROFS 层,元数据本地 mount,数据块按需拉。microVM 用 overlaybd 磁盘格式,基层只读共享、写走 copy-on-write,支持链式快照,毫秒级恢复。
Trajectory Logging:每个 sandbox 有全序的 trajectory log,持久记录每条命令及其结果。这个 log 有三用:
- Client fast-forwarding:训练被抢占时沙箱资源保留,恢复时 replay 已完成命令的 cached 结果,避免非幂等操作再执行出错
- Fine-grained provenance:每个状态变化可追溯来源
- Deterministic replay:任何历史 session 可从 trajectory 完整复现
把这些串起来看,V4 的 agent 数据合成最可能的流程是:
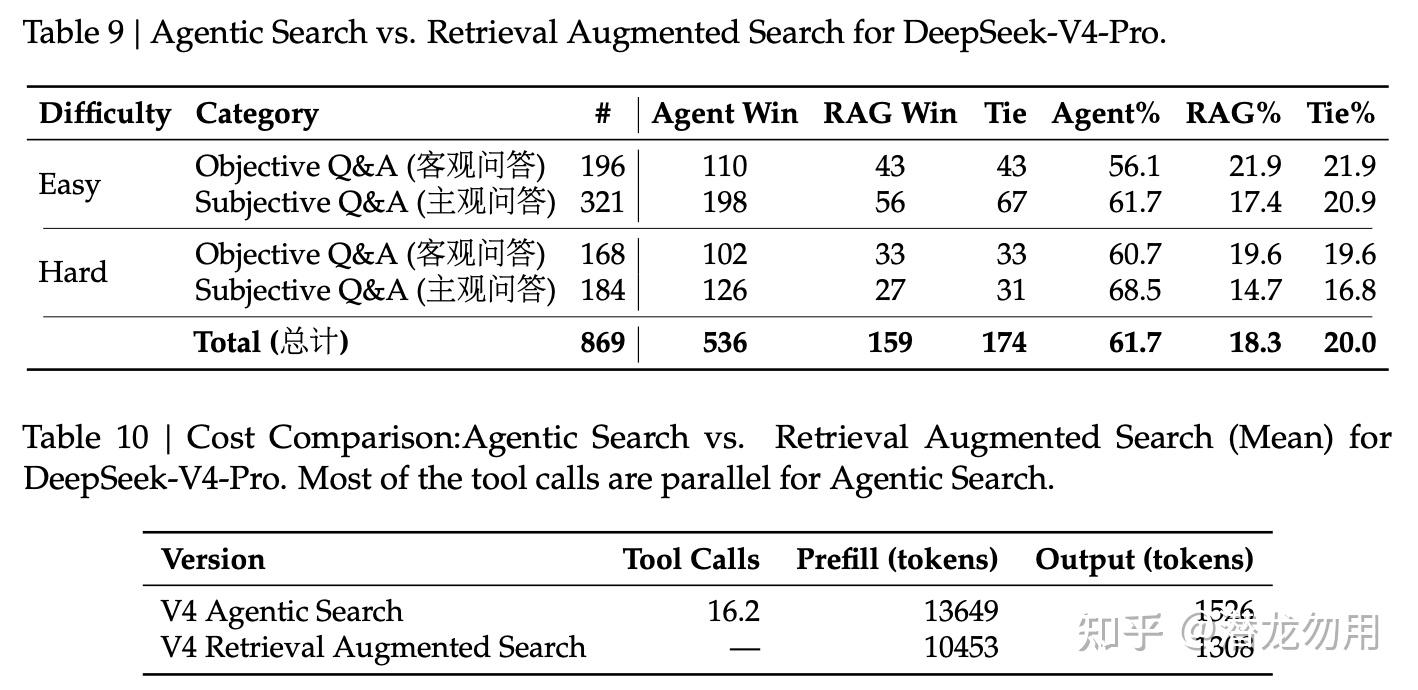
- Specialist 的 RL 阶段,让 expert 在 DSec 沙箱里自由执行(code agent 就跑真 repo,search agent 就调真 search API)
- 沙箱的 trajectory log 天然就是高保真训练数据
- 任务结果用 rule-based verifier(跑测试、检查文件状态)或 rubric-GRM(actor 自评)给 reward
- GRPO 对整条轨迹做 group-relative policy update
- OPD 阶段,code/agent expert 作为一个 teacher 进入 full-vocab 蒸馏
- Preemptible rollout service + token 级 WAL 保证长轨迹不因为调度中断而浪费
④ RL 框架为百万 token 上下文专项优化:rollout data 被拆成 metadata + 重 per-token field,后者走 shared-memory loader 避免节点内重复、用完立刻释放。on-device mini-batch 数动态调节,平衡吞吐与 I/O。token 粒度 WAL 保证重启不 regeneration from scratch(否则有 length bias——短响应更容易存活会让模型偏向短输出)
换句话说,V4 没有完全披露 agent 数据合成的具体 prompt/task/reward 细节,但它把 agent 训练变成了一个 infra 问题:只要沙箱足够多、足够快、trajectory 可追溯、reward 可获取(rule 或 GRM),specialist + OPD 的范式就能把 agent 能力蒸进统一模型
一个隐含的方法论:V4 反复强调 agent 能力的核心不是 " 模型会不会调用工具 "(SFT 阶段已经能把 tool-call schema 学得很好),而是 " 能不能稳定地生成高质量多步轨迹 "。后者的决定性因素是基础设施而不是数据配方——也是为什么 V4 把如此大的篇幅花在 DSec、WAL rollout、MegaMoE 上
把 DSec + trajectory log + preemptible rollout 这三块拼起来看,V4 事实上定义了 agent 训练基础设施的 四根支柱,研究者可以把这套框架直接迁移到自己的 agent pipeline:
1、执行真实性(Execution Authenticity):沙箱必须能执行真实命令、真实网络调用、真实文件系统操作。Function Call 池消除冷启动,microVM/fullVM 支撑需要完整 guest OS 的场景(如跑浏览器 agent)
2、打分可用性(Reward Accessibility):reward 必须能机器化生成。简单任务靠 rule-based verifier(test case、文件 hash 检查);难验证任务靠 rubric + actor-as-GRM
3、轨迹可复现性(Trajectory Reproducibility):全序 trajectory log + overlaybd 毫秒级快照,使得任何历史 rollout 都能在任意时刻完整重放,这是 debug 和长程 RL 的必要条件
4、能力可融合性(Capability Mergeability):specialist 的 agent 能力必须能通过 OPD 蒸回 unified model 而不被其它 domain 的 teacher 抵消——这要求 reverse KL 的 full-vocabulary 精度以及对 teacher 组合权重的精细控制
5.4 其他 infra 值得一提
FP4 贯穿 rollout 和 teacher/reference forward:rollout 直接走 native FP4 权重,训练步走 FP4→FP8 无损反量化,无需改后向管线
Preemptible & fault-tolerant rollout service:每请求 token 粒度 WAL,抢占时暂停引擎存 KV cache,恢复时继续 decode;硬件故障时 WAL token 重放 prefill 重建 KV
六、效果
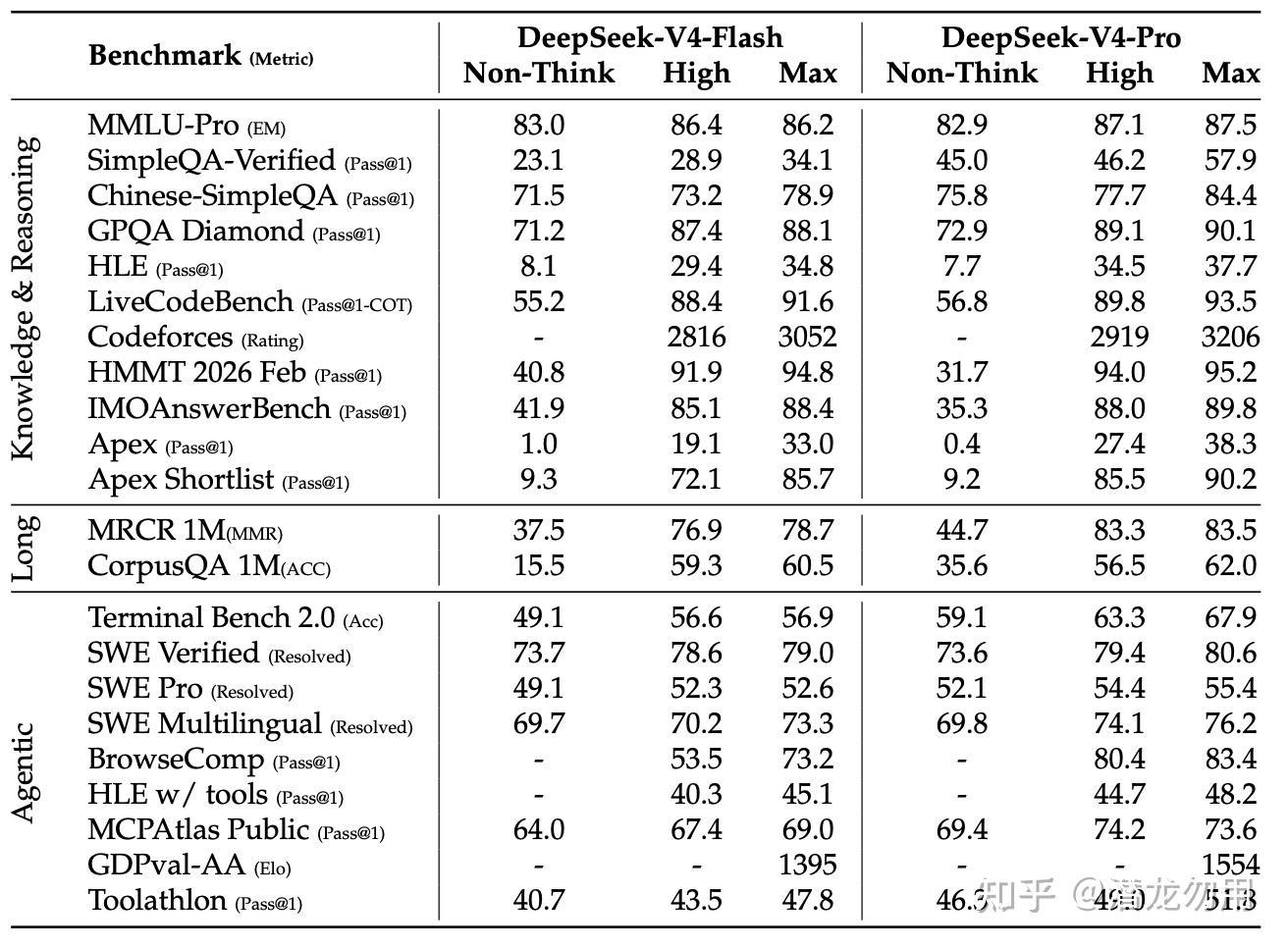
6.1 主榜对比
!【DeepSeek-V4-Pro-Max vs Opus-4.6-Max / GPT-5.4-xHigh / Gemini-3.1-Pro-High / K2.6-Thinking / GLM-5.1-Thinking 在 22 项 benchmark 上的完整对比(Knowledge & Reasoning、Long Context、Agentic 三大类)】(https://pic3.zhimg.com/v2-00b9b74541f0cce22aca45811fd360da_1440w.jpg)
知识:V4-Pro-Max 在 SimpleQA-Verified 上拿到 57.9,开源第一并领先次席 20 个百分点(Kimi-K2.6 的 36.9、GLM-5.1 的 38.1),但仍明显落后于 Gemini-3.1-Pro 的 75.6。中文知识(Chinese-SimpleQA)同样开源第一(84.4),甚至超过 Opus-4.6-Max(76.4)和 GPT-5.4-xHigh(76.8)。MMLU-Pro / GPQA / HLE 则稍微低于 Gemini/GPT-5.4
推理:
- Codeforces Rating 3206,与 GPT-5.4-xHigh 的 3168 大致持平,在真实 Codeforces 人类选手榜上排第 23。这是开源模型第一次与闭源前沿在竞赛编程上打平
- LiveCodeBench 93.5,领先所有榜上模型
- HMMT 2026 Feb 95.2;IMOAnswerBench 89.8;Apex Shortlist 90.2
- 形式化数学:Putnam-200 Pass@8 下 V4-Flash-Max 拿到 81.0(Seed-1.5-Prover 只有 26.5);Putnam-2025 下 V4 拿到 120/120 的满分,与 Axiom 并列
!【Formal reasoning 双栏对比。左栏 Practical Regime(Putnam-200 Pass@8,最小工具 + bounded sampling)柱状图:Seed-1.5-Prover 26.50、Gemini-3-Pro 26.50、Seed-2.0-Pro 35.50、DeepSeek-V4-Flash-Max 81.00;右栏 Frontier Regime(Putnam-2025,hybrid formal-informal + 大算力):Aristotle 100/120、Seed-1.5-Prover 110/120、Axiom 120/120、DeepSeek-V4 120/120】(https://pic3.zhimg.com/v2-4ef3e838f3cfda6cd890657f5e1cc284_1440w.jpg)
Agent:SWE-Verified 80.6、Terminal Bench 2.0 67.9、BrowseComp 83.4、MCPAtlas Public 73.6。整体与 Kimi-K2.6、GLM-5.1 在同一梯队,略逊于 Opus-4.6-Max / GPT-5.4。值得关注的是 MCPAtlas 和 Toolathlon 这两个不依赖内部 harness 的公共评测里 V4-Pro 表现优于 Opus-4.6-Max,说明其泛化到外部工具栈的能力不弱
长上下文:MRCR 1M MMR 83.5(开源第一,超过 Gemini-3.1-Pro 的 76.3,略逊 Opus-4.6-Max 的 92.9);CorpusQA 1M ACC 62.0(超过 Gemini-3.1-Pro 的 53.8)
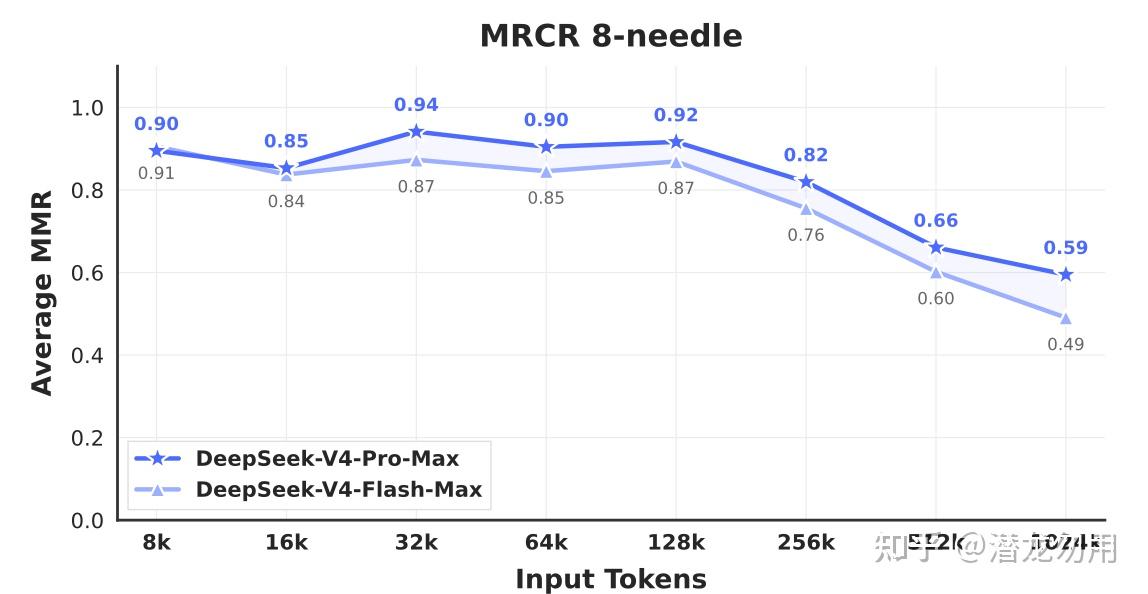
6.2 Flash vs Pro 与推理强度
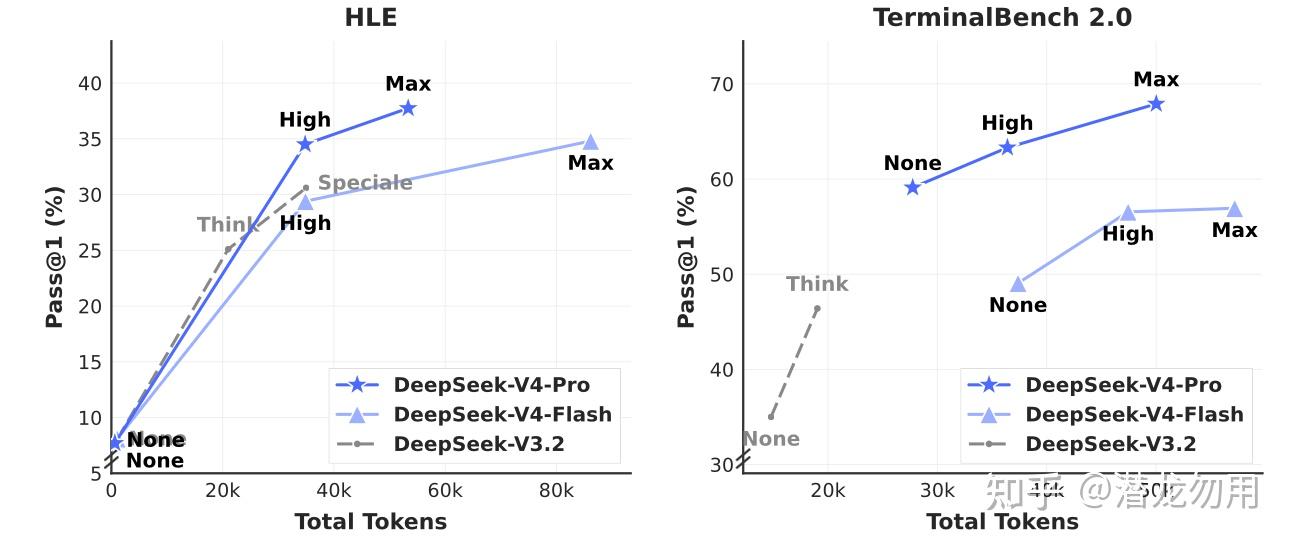 "" 准确率 vs 总 token 数 散点图,对比 V3.2、V4-Flash、V4-Pro 在 None / High / Max / Speciale 四档的 Pareto 前沿,直观展示 V4 Max 模式相较 V3.2 用更少 token 做到更高分 的 token-efficiency 提升" />
"" 准确率 vs 总 token 数 散点图,对比 V3.2、V4-Flash、V4-Pro 在 None / High / Max / Speciale 四档的 Pareto 前沿,直观展示 V4 Max 模式相较 V3.2 用更少 token 做到更高分 的 token-efficiency 提升" />
几个规律:
- 更高 reasoning effort 单调涨分,Max 模式在最难任务上显著优于 High
- V4-Flash-Max 在推理类任务上能赶上 Pro-High,甚至部分场景接近 Pro-Max;但世界知识上和 Pro 差距明显(参数体量限制)
- Agent 任务(尤其 Terminal Bench)Flash 明显不如 Pro
6.3 真实任务的体感
中文写作:功能写作 V4-Pro vs Gemini-3.1-Pro 胜率 62.7% vs 34.1%;创意写作在指令遵循上 60.0%,写作质量 77.5%。在高复杂约束 + 多轮场景上仍输给 Claude Opus 4.5(45.9% vs 52.0%)
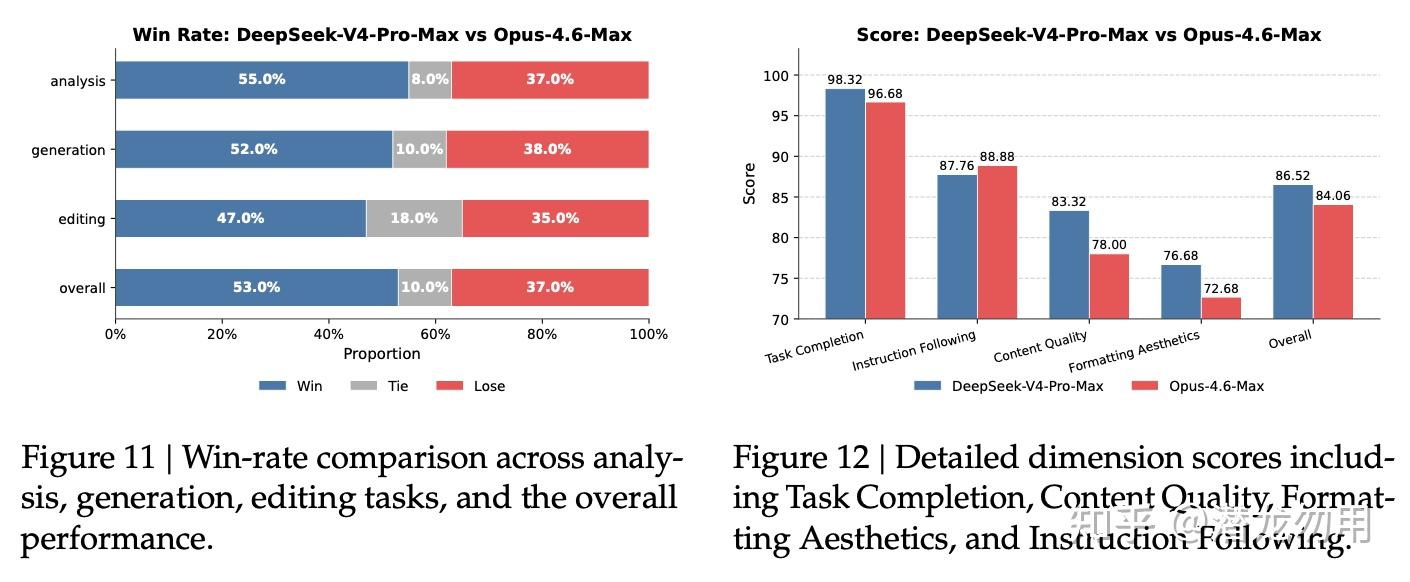
白领任务:30 项中文专业任务、13 个行业,人工盲评四维打分。V4-Pro-Max vs Opus-4.6-Max 非负率 63%;在 Task Completion 和 Content Quality 维度领先,但 Instruction Following 稍逊、PPT 美观度还有差距
内部代码 Agent 评测(200 真实 R&D 任务中精选 30 个):V4-Pro-Max Pass Rate 67%,介于 Sonnet 4.5(47%)与 Opus 4.5(70%)之间。85 名 DeepSeek 内部开发者调研:52% 直接把 V4-Pro 当默认代码模型,39% 倾向于 yes,< 9% 说 no

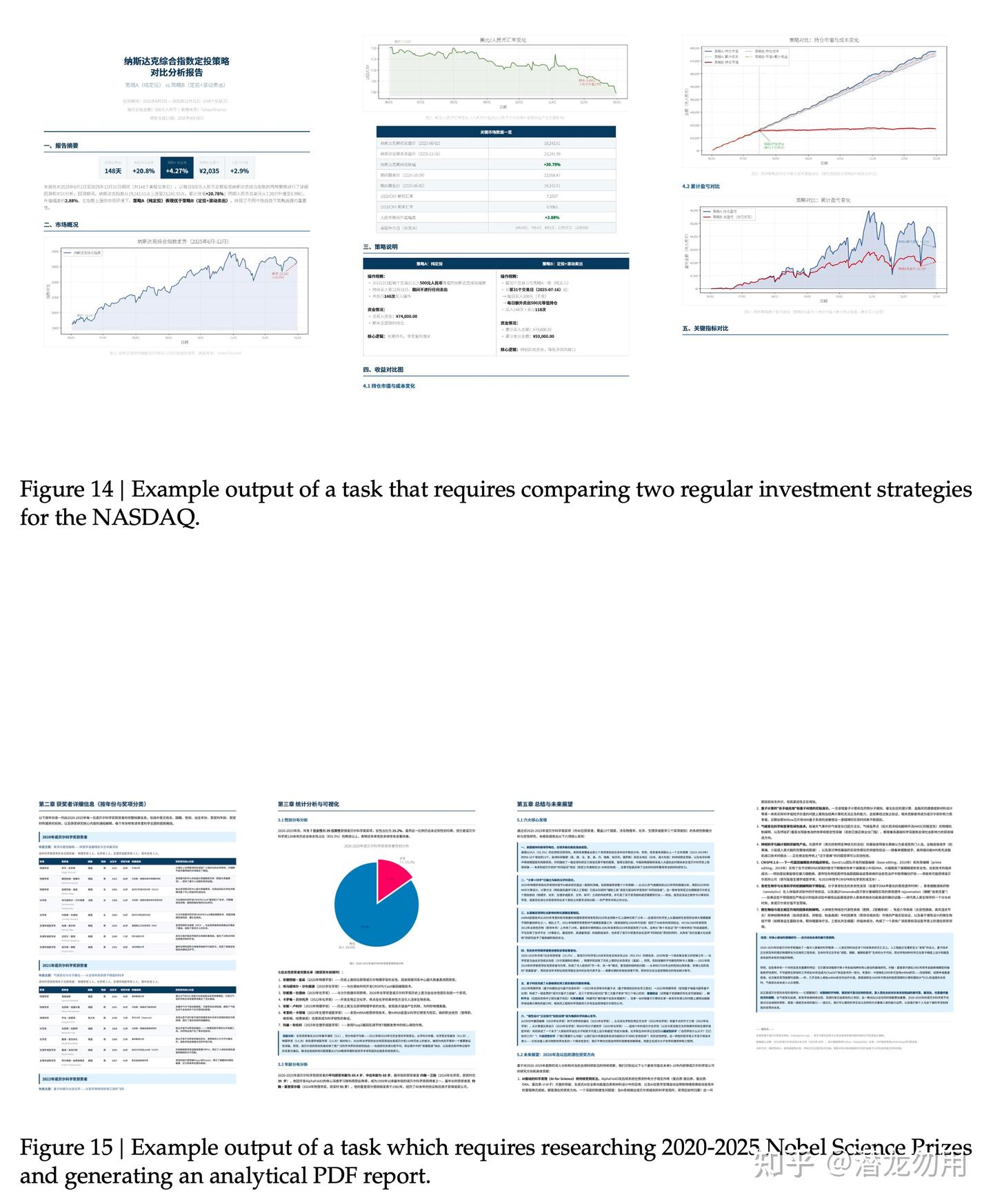
白领任务的三个 case 展示(示例包含中文联名营销方案、跨行业企业分析等),由于输出过长只展示部分页面
七、一些讨论
1. 为什么是 " 压缩 + 稀疏 " 混合,而不是纯稀疏?
纯稀疏(DSA / NSA 类)top-k 本身已经能显著降 FLOPs,但 KV cache 大小没变。对 1M context 而言,KV 显存占用才是上限天花板,尤其涉及 RL rollout 和大 batch serving。CSA 把 " 压缩 KV " 和 " 稀疏选择 " 叠起来,一次攻克显存和算力两个瓶颈
2. mHC 与 nGPT / DeepNorm / LayerNorm 之类残差稳定技术的关系
mHC 不是做 " 让 output norm 不爆炸 ",而是让每条残差通路本身的谱半径 ≤ 1,并保证跨层可组合。这背离了 " 残差越宽越好 " 的直觉,但换来了超深堆叠的数值稳定。代价是 Sinkhorn-Knopp 迭代(20 步)以及动态参数生成,在 forward/backward 都要插进去
3. Specialist + OPD 范式 vs 单一 unified RL
V3.2 用的是 mixed RL(所有域混一起训),V4 换成了 specialist + OPD。背后可能的逻辑:
- 不同域的 reward model / verifier 差异极大,混合 RL 容易被 " 某个域的 reward hack" 拖累其它域
- specialist 阶段每个 expert 可以用最适合自己的 reward(例如数学用 rule-based,code 用 test case,写作用 rubric-GRM),互不干扰
- OPD 的 reverse KL 让学生 " 选择性 " 靠拢相关 teacher,而不是把所有 teacher 的偏好无差别平均——这更像 " 按需组合专家 "
4. GRM 的自举问题
actor-as-GRM 的风险是:弱模型自评得出弱 reward,policy 再被弱 reward 引向错误方向。报告说 " 少量多样化人工标注 + 模型自身逻辑泛化 " 就能 work,但细节不足。可能的保险是:rubric 本身就是锚点(模型只需按 rubric 评分,不必凭空判断好坏),外加部分易验证任务的 ground truth 约束 GRM 不跑偏
5. V4 的底层公设:infra 是算法的一部分
把 V4 所有改动按贡献排序:
- 硬件效率贡献:CSA+HCA、MegaMoE、FP4 QAT、on-disk KV cache(直接决定 1M context 能不能用)
- 训练稳定贡献:mHC、Muon、Anticipatory Routing、SwiGLU Clamp、bitwise 确定性 kernel
- 能力上限贡献:specialist + OPD + GRM、Interleaved Thinking、DSec 沙箱
前两类是 " 让 V4 能跑起来 ",后一类才是 " 让 V4 值得跑 "。V4 让我印象最深的是:DSec 这种级别的沙箱 infra,本身就是 agent 模型的核心训练资产。它决定了你能在多大规模 / 多高保真度下生成 agent trajectory——而这个能力一旦建立,data 和 reward 就成了可重复的副产品
换一个角度:在 PF-LLM 时代大家比拼的是 " 谁的 SFT + RL 数据合成链更精巧 ";到 V4 这里,比拼的重心转到 " 谁的沙箱/WAL rollout/full-vocab OPD 的工程体系更稳健 "。Agent 能力的核心竞争力已经从 " 数据菜谱 " 转向 " 基础设施 "——这是 V4 留给后来者最值得警惕、也最值得学习的一条经验
6. 局限与未来方向
报告自评的遗留问题:
- 架构 " 稳妥起见 " 保留了很多已验证的组件和 trick,复杂度偏高,未来会做架构精简
- Anticipatory Routing 和 SwiGLU Clamping 效果确凿但机制未解
- Flash 在 agent 高难度任务上仍与 Pro 拉开差距,说明参数体量仍是 agent 能力的硬约束
- 白领任务 Instruction Following、PPT 美观度、长文总结仍有提升空间
- 多模态能力尚未纳入
整体看,V4 preview 是 " 长上下文实用化 + 能力对齐闭源前沿 " 的一次系统化推进,方法学上的标志性换代在于把后训练的 mixed RL 替换成 specialist + 全词表 OPD、以及把 agent 训练当成 infra 问题来解。
下一代 V4 正式版值得期待的点会是:更精简的架构、更清晰的稳定性理论、多模态、以及 agent trajectory 合成的更细致披露