

6月30日(周二)晚8点,青稞Talk 第134期,清华大学人工智能学院博士生方科晨,将直播分享《DPA & LLaVA-HUD v4:多模态大模型的深度预对齐与高效视觉编码优化》。
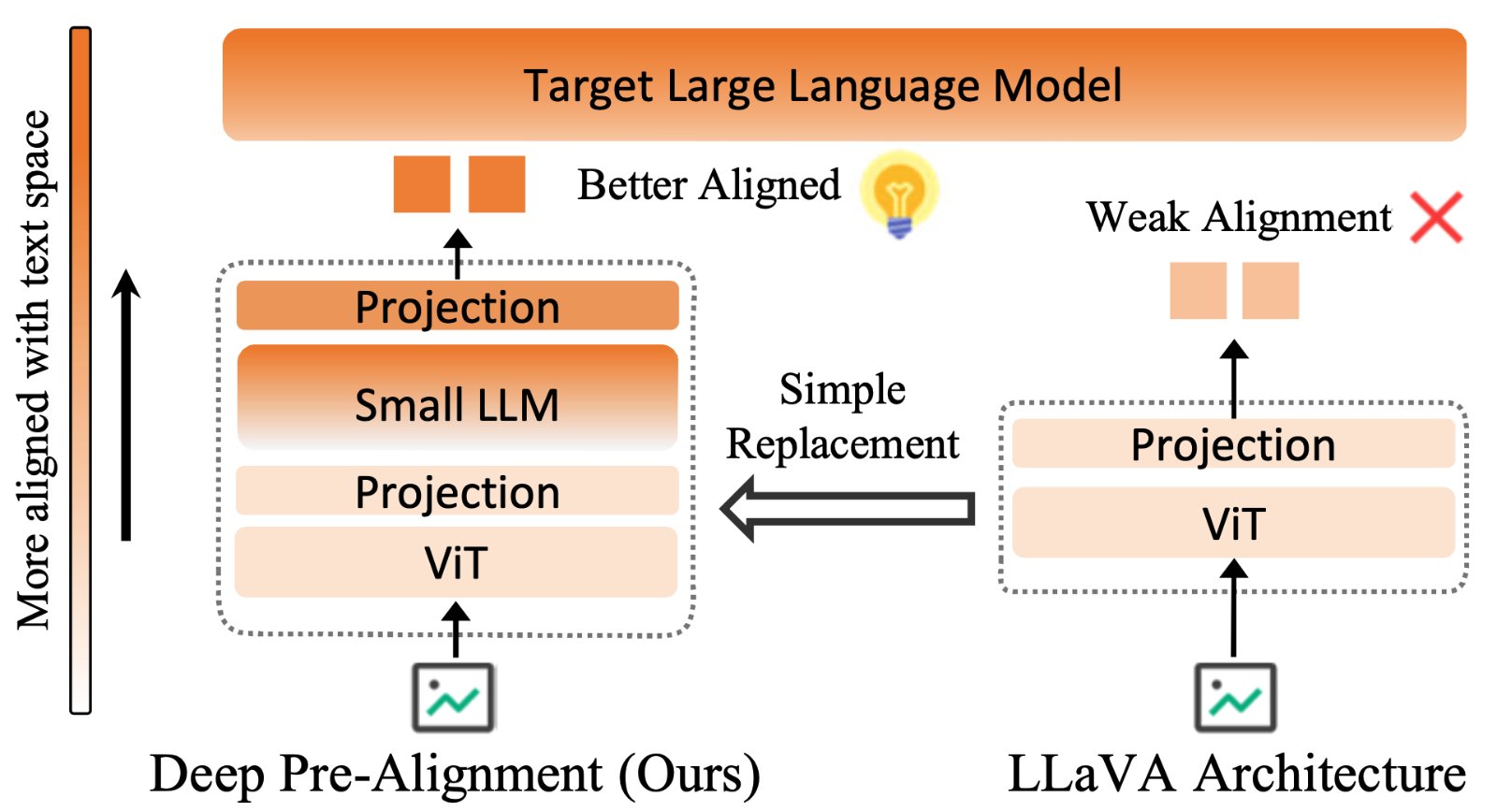
DPA 提出一种新的视觉语言模型架构:在视觉特征进入目标 LLM 前,引入小型 perceiver VLM 进行深度预对齐,使视觉表示更接近文本空间。
论文:https://arxiv.org/abs/2605.15300
代码:https://github.com/THUMAI-Lab/Deep-Pre-Alignment
该方法可无缝接入现有训练流程,在提升多模态理解与推理能力的同时,缓解文本能力遗忘,并几乎不增加推理开销。
清华最新提出全新 VLM 架构 DPA:让多模态大模型先“对齐”,再“理解”!
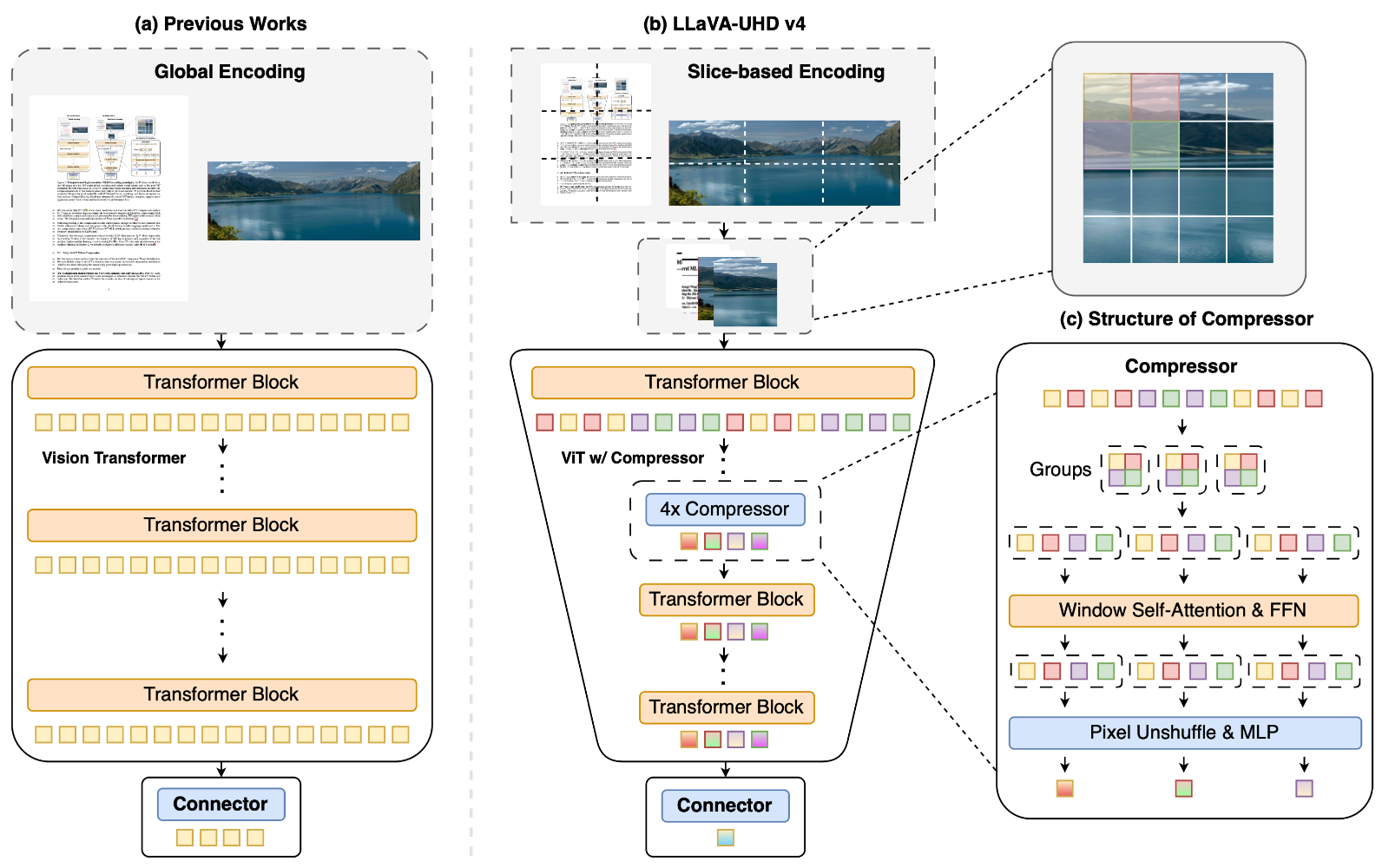
LLaVA-UHD v4 面向高分辨率多模态大模型的视觉编码效率瓶颈,结合切片编码与 ViT 内部早期压缩,在保持下游性能接近甚至优于基线的同时,将视觉编码 FLOPs 降低 55.75%,提升高分辨率理解的实用效率。
论文:https://arxiv.org/abs/2605.08985
代码:https://github.com/THUMAI-Lab/LLaVA-UHD-v4UHD-v4
视觉 FLOPs 减半!清华最新成果 LLaVA-UHD v4,突破高分辨率多模态大模型的视觉编码效率瓶颈
分享嘉宾
方科晨,清华大学人工智能学院一年级博士生,研究方向为高效多模态大语言模型。
主题提纲
1、多模态大模型的研究现状及核心瓶颈
2、新的视觉语言模型架构 DPA:重新思考视觉语言对齐
3、LLaVA-UHD v4:高分辨率视觉编码效率优化
4、多模态大模型的未来趋势探讨
5、AMA (Ask Me Anything)环节
直播时间
6月30日(周二)20:00 - 21:00
如何观看
Talk 将在青稞社区【视频号:青稞 AI】上进行进行直播,欢迎预约观看!