本工作由中国科学院软件研究所中文信息处理实验室与快手科技联合完成。中科院软件所方面来自孙乐、韩先培团队,主要作者包括陈嘉伟、徐若曦、曹博希、陆垚杰及林鸿宇;快手方面主要作者包括潘若彤、吴翔宇等。中科院软件所中文信息处理实验室长期聚焦大模型知识机制、知识能力增强及应用研究。
让大模型模拟真实人类行为,正成为 AI 领域备受关注的重要研究方向。在推荐系统中,它可用于离线验证新策略;在电商和广告场景中,它能够提前预估转化与流失;在智能体研究中,它是社会仿真、产品测试和人机交互评估的重要基础设施。
但这一切成立的前提是:被模拟的“用户”必须足够真实。
现实中的用户行为并不是一次点击、一轮对话或某个孤立 session。一次购买决策,可能源于几天前刷到的一条视频,也可能由一次搜索、一场直播和一次广告曝光共同推动;一次客服投诉背后,往往沉淀着更长时间的消费经历与情绪积累。
这正是现有用户模拟评测的核心短板:数据往往局限于单一场景,行为类型有限、轨迹较短,甚至依赖合成数据。这样的 benchmark 难以判断大模型是否真正理解真实用户行为。
为了解决这一问题,中国科学院软件研究所中文信息处理实验室、快手等机构推出了 OmniBehavior,一个面向真实世界用户行为模拟的 benchmark:不再让大模型只在“理想化、短序列、单一场景”的数据上做预测,而是把它放进真实平台行为流中,检验其是否具备真实用户的建模能力。目前,完整数据和评估代码均已开源。

主页:https://OmniBehavior.github.io
GitHub: https://github.com/icip-cas/OmniBehavior
HuggingFace: https://huggingface.co/datasets/jiawei-ucas/OmniBehavior
论文: https://arxiv.org/abs/2604.08362
从真实工业日志出发:212 万条交互,覆盖用户行为全链路链路
_page-0001.jpg)
OmniBehavior 基于快手真实工业日志构建,包含长序列、跨场景和行为异构三个核心特征。
在长序列方面,研究团队首先收集了 3500 名真实用户在 2025 年 9 月 1 日至 11 月 30 日三个月内的交互日志,将不同场景下的原始行为按精确时间戳统一排序,形成连续的超长用户行为序列;
在跨场景方面,它覆盖了视频浏览、直播、电商、广告、搜索等主站场景,打破单一场景局限并完整串联起用户的全局活动轨迹;
在行为异构方面,每条交互记录对应的 22 类用户动作包含了二分类、连续值以及文本预测三种任务范式。
在此基础上,团队进一步从中采样出 200 名代表性用户作为 benchmark 核心评测对象,最终形成了包含 212 万条真实用户的交互日志,能够为评估大语言模型在真实环境中模拟人类跨场景长期决策逻辑的能力,提供极具保真度的可靠测试基准。
这些日志既包含观看、点赞、评论、关注等内容消费行为,也包含搜索、加购、购买、客服对话等主动决策行为。它们按照时间顺序串联起来,将原本孤立的动作构成接近真实平台环境的连续行为链条。在这个设定下,传统评估范式迎来了转变,模型需要完成的任务不再是简单判断用户会不会点击,而是:
给定用户画像、历史行为轨迹和当前场景上下文,预测用户接下来在该场景中的真实行为。
这些行为可以是二分类动作,例如点赞、分享、购买;也可以是连续值,例如观看时长;还可以是文本输出,例如用户在客服对话中的下一句回复。
这使 OmniBehavior 更接近真实应用中的用户模拟问题:模型必须同时理解用户长期偏好、短期意图、场景上下文和行为之间的潜在因果关系。
为什么需要跨场景:单一场景会造成画像偏差
如果只看单一场景,能不能理解用户?答案是否定的。
真实用户的兴趣和需求通常分散在不同产品场景中。一个用户在视频场景中可能表现出对乡村生活的兴趣,在广告场景中体现出家庭健康需求,在直播场景中暴露出价格敏感和购物偏好,在搜索场景中主动表达即时意图。单看任何一个场景,都只能得到局部画像。

定量分析也支持了这一点。随着更多场景被纳入,用户兴趣类别和关键词覆盖率持续上升,引入新场景通常能带来约 20%—30% 的兴趣覆盖增益。
_page-0001.jpg)
因此,OmniBehavior 的第一个关键价值在于:它不是把用户行为切割成孤立片段,而是保留了跨场景行为之间的互补信息。
为什么需要长序列:真实决策往往跨越多天、跨场景
用户行为是否真的需要长历史?
文中抽取了 180 个高价值转化事件,并追踪这些事件之前的关键行为链。结果显示,超过 60% 的决策依赖 3 天以前的行为线索;同时,81.8% 的转化链条跨越多个场景。
_page-0001.jpg)
论文中还展示了一个典型案例:用户最早搜索“小米发布会”,随后在直播、视频、广告、电商等场景中持续接触“小米 17 Pro Max”相关内容,最终在 12 天后完成购买。
_page-0001.jpg)
这表明了用户模拟的一个难点是如何识别长跨度内哪些行为真正影响了当前决策。如果只保留短 session,就会切断真实决策链条;如果只保留单一场景,就会丢失跨场景因果关系。
为什么需要真实数据:合成用户缺少真实行为的动态性
文中进一步讨论了能不能用合成数据替代真实用户轨迹?通过对真实用户数据和合成用户数据进行了对比。结果显示,两者在兴趣演化模式上存在明显差异。
真实用户的兴趣变化更连续、更随机,多个兴趣主题会交织出现,并随时间缓慢增强或衰退。合成用户则更像任务脚本驱动,兴趣常常突然出现、快速达到峰值,然后迅速消失。

合成数据难以复现真实用户偏好随时间变化的复杂变化,用户模拟不只是生成一个合理画像,而是复现用户行为中的迟疑、跳变、稀疏性及长尾分布,这也是 OmniBehavior 选择真实工业日志的重要优势。
当前 LLM 距离真实用户模拟仍有明显差距
评测共包含 6000 个行为预测任务,覆盖视频浏览、直播、广告、电商等场景,以及二分类行为、连续观看时长和客服文本回复等任务类型。
-Wufs.png)
即使同期表现最好的 Claude-Opus-4.5,整体得分也只有 44.55。大多数模型集中在 32 到 41 分之间。
这意味着当前 LLM 虽然具备强大的语言理解和生成能力,但在用户模拟任务上仍存在明显能力缺口。它们难以同时处理长序列、跨场景依赖、稀疏行为、长尾偏好和个体差异。
长上下文并不等于长序列理解
既然用户轨迹很长,一个自然想法是:直接把更多历史交给模型,是否就能提升效果?
实验结果并不支持这个假设。
团队在 16K 到 128K 不同上下文窗口下测试模型表现。结果显示,随着上下文变长,性能并没有稳定提升:模型能够接收更长输入,并不意味着它能够有效利用这些历史信息。
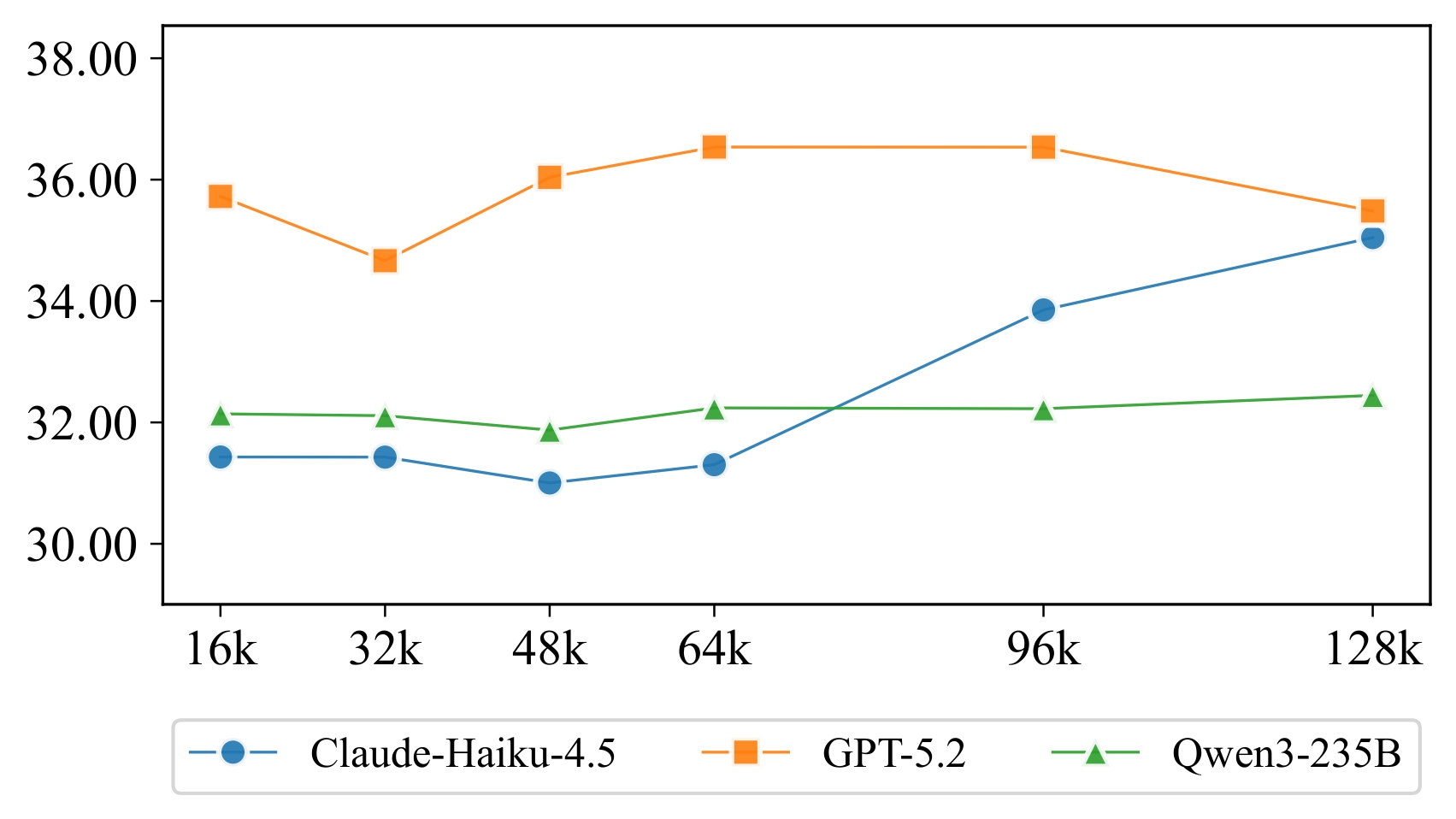
_page-0001.jpg)
团队还比较了截断、RAG、Summary 等常见记忆管理策略。结果显示,这些方法只能带来有限改进。
因此,用户模拟真正需要的不是简单扩大上下文窗口,而是更加结构化的记忆管理机制。
结构性偏差:LLM 倾向于生成“积极平均人”
论文进一步探究了模型存在稳定的结构性偏差问题,并将其称为 positivity-and-average bias。可以理解为 LLM 倾向于把真实用户模拟成更积极、更礼貌、更平均的人。这一偏差主要体现在三个方面。
过度活跃:高估用户正向行为
真实用户行为天然稀疏。大多数时候,用户只是浏览、跳过、沉默,并不会频繁点赞、评论、加购或购买。
但 LLM 往往显著高估正向行为。在视频、直播、广告、电商等场景中,模型预测的正向互动概率普遍高于真实用户。
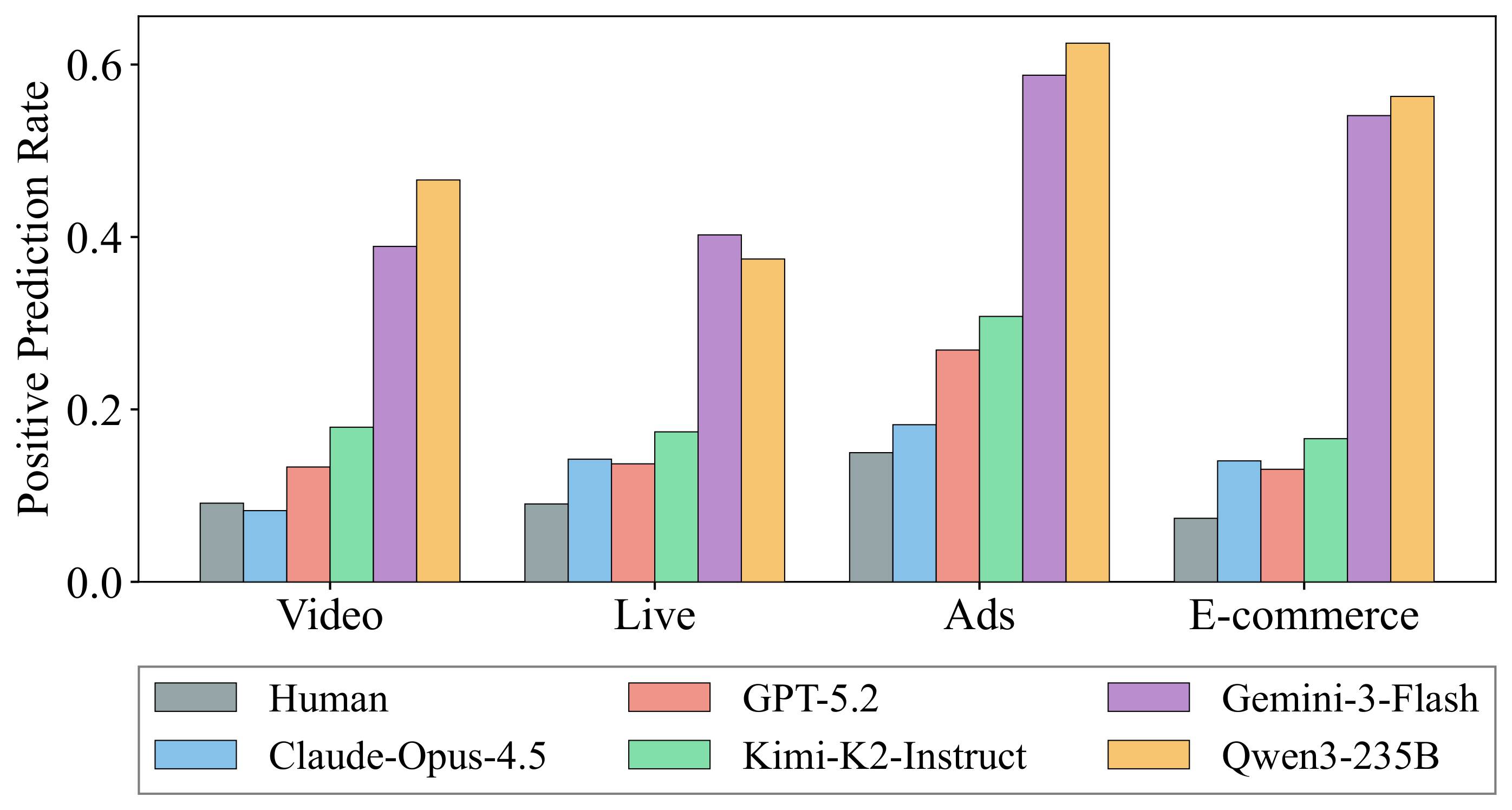
这一偏差会直接影响实际应用。如果用于评估推荐、广告或电商策略,系统可能会高估用户参与度和转化率。
过度礼貌:低估真实交互中的负面情绪
在电商客服场景中,真实用户经常表达不满、催促、质疑甚至愤怒。尤其在售后、物流、质量问题中,用户语言往往直接且带有情绪。
但 LLM 生成的用户回复更集中于中性和正向情绪,并更倾向于使用礼貌、缓和、避免冲突的表达,难以模拟真实平台中的高摩擦场景,例如售后争议、危机沟通和强负面反馈。
人格同质化:抹平个体差异和长尾行为
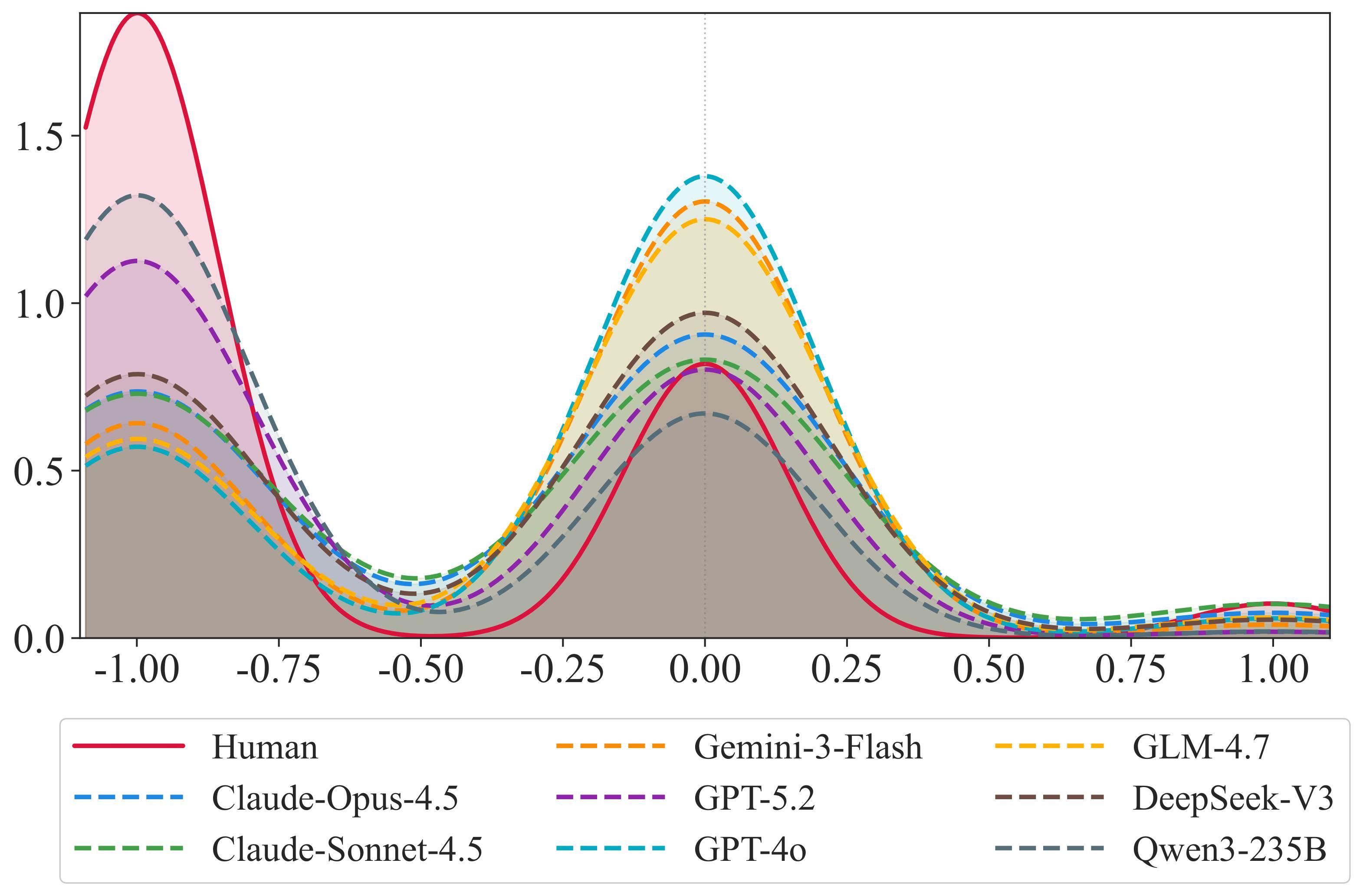
真实用户之间存在显著差异。有人高频互动,有人长期沉默;有人冲动消费,有人极度谨慎;有人表达委婉,有人非常直接。
但 LLM 模拟用户之间的差异明显缩小。
文中为每个用户基于其行为特征构建相应的特征向量,比较真实用户与模拟用户的行为距离。真实用户具有明显的个体间差异,而 LLM 模拟用户的分布高度重叠,更接近一群“平均用户”。说明当前模型不只是预测错误,而是在系统性地丢失真实用户生态中的长尾行为、负反馈和个体差异。
_page-0001.jpg)
目前,OmniBehavior 仓库已完全开源,欢迎研究者与行业用户体验、使用并提出宝贵建议。