作者:sheriyuo
https://zhuanlan.zhihu.com/p/2009946011120971848
近年来,随着 Agentic RL 的兴起,LLM 逐渐从“单次问答器”转变为能够在推理(Reasoning)与外部工具调用(Tool-use)之间反复交互(multi-turn)的智能体系统。
从 Search-R1 到 ToolRL、SkyRL,一条清晰的技术路线正在形成:模型不仅要会“想”,还要会“查”“算”“调 API”,并在多步轨迹中通过 RL 不断自我改进。
然而,这类方法几乎都建立在一个隐含假设之上:推理能力与工具使用能力可以在同一套共享参数空间中被联合优化,而且这种联合训练应当带来协同增益。
Reasoning and Tool-use Compete in Agentic RL: From Quantifying Interference to Disentangled Tuning
链接:https://arxiv.org/abs/2602.00994
本文所讨论的工作,对这一假设提出了系统性的挑战。作者通过严格的实证分析表明,在 Agentic RL 中,推理与工具使用之间并非天然协同,而是普遍存在显著的负向交互效应。
换言之,当模型在共享参数上同时学习“如何推理”和“如何调用工具”时,往往会出现一种跷跷板现象:提升工具使用能力往往以牺牲推理能力为代价,反之亦然。
这一现象并非个别任务或小模型的偶然结果,而是在不同数据集与不同规模模型上稳定复现的普遍规律。这种负向交互的根源并不在于数据或奖励设计本身,而是隐藏在优化动力学之中。
通过分析 token 级别的梯度发现,来自推理 token 的梯度更新方向与来自工具调用 token 的梯度更新方向几乎正交,夹角接近 90 度。
这意味着两种能力在参数空间中追求的是截然不同的最优解。当它们被迫在同一套参数上联合更新时,优化过程只能走向一个“折中方向”,该方向对任何一方而言都是次优解。由此,Agentic RL 的性能上限被一种结构性的梯度冲突所限制。
Q1:为什么会观察到梯度正交现象?
从线性代数角度看,在高维空间中,任意两个随机向量几乎必然是正交的。更严格地说,如果向量维度为 d,随机采样两个向量 \mathbf{g}_1, \mathbf{g}_2,则它们的夹角分布会高度集中在 90^\circ 附近。这是高维几何的基本现象:
在 Agentic RL 中,推理 token 与工具调用 token 对应的是两类不同的数据分布和目标函数,它们在参数空间中诱导出的梯度方向本身就接近“随机向量”。因此,从几何上看,梯度接近正交并不奇怪,而是高维空间中的常态。
设推理梯度为 \mathbf{g}_r,工具梯度为 \mathbf{g}_a。联合训练时实际更新方向是 \mathbf{g} = \mathbf{g}_r + \mathbf{g}_a。如果两者正交,则更新方向并不是任何一方的最优方向,而是落在一个“折中子空间”中。对推理任务而言, \mathbf{g}_a 相当于噪声;对工具任务而言, \mathbf{g}_r 也是噪声。
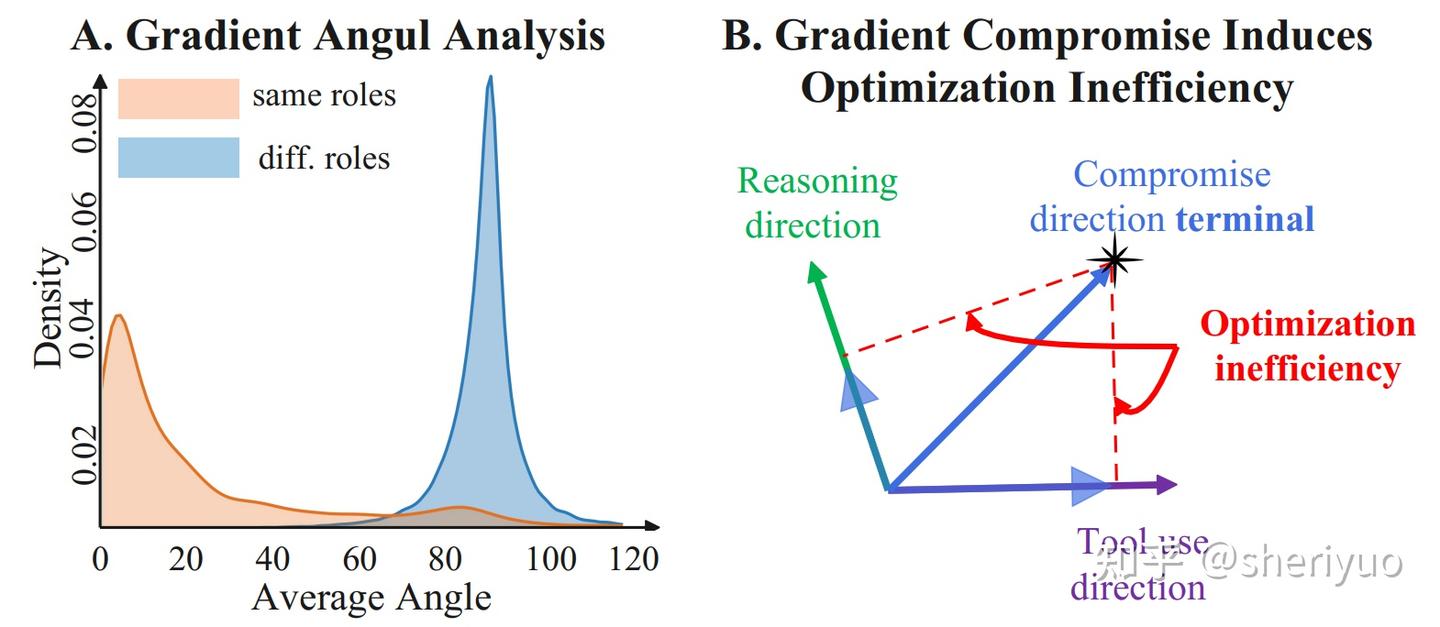
Q2:既然多任务学习也有不同梯度,为什么 LLM 预训练没有这么严重的问题?
因为 pre-training 和 post-training 处在完全不同的几何 regime。当多任务学习在参数空间中的最优子空间差异很大,且被强制投影到同一子空间时,才会出现显著冲突。
在预训练阶段,目标是最大化语言建模似然,各种任务(翻译、问答、数学、代码)仍然共享“语言建模”这一核心结构,梯度虽然来自不同数据,但大多指向相似的低层表征改进方向(词法、语法、语义),因此它们在参数空间中并非随机,而是存在较强的 Alignment。
而在 Agentic RL 的 post-training 阶段,推理 token 的目标是“更好地构造思维链”,工具 token 的目标是“更好地产生 API 调用与控制流决策”, 两者的最优表示结构差异极大,一个偏向内部推理轨迹,一个偏向外部动作选择。此时梯度来源不再是统一的语言建模目标,而是两个语义上不同的控制目标,几何上自然更容易呈现正交甚至冲突。
为了不只是停留在直觉层面的解释,作者提出了一个诊断框架 LEAS(Linear Effect Attribution System),用以定量刻画不同能力之间的协同或干扰关系。
其核心思想是将模型的能力拆解为若干二元变量,并引入交互项刻画“联合训练”的效应,再通过构造多种模型变体来解一个线性方程组,从而得到每一类交互系数的符号与大小。当交互系数为负时,意味着两种能力在联合优化时存在干扰。
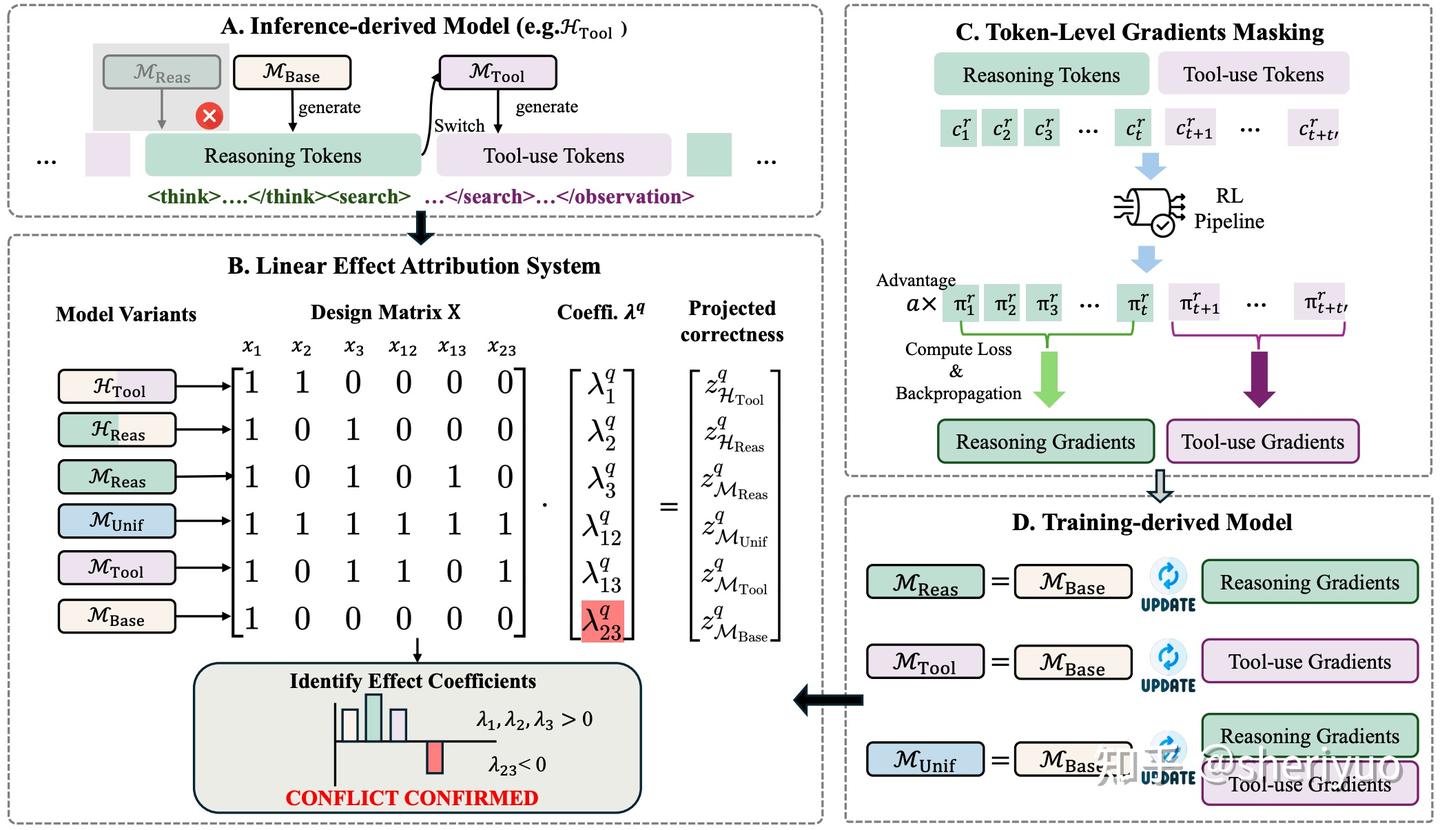
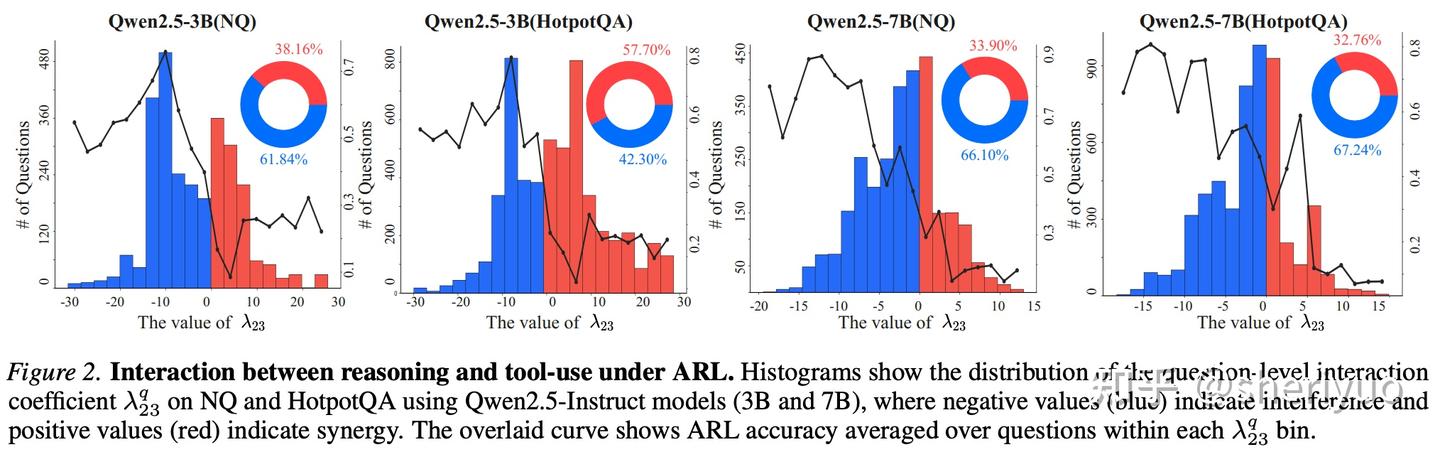
实验结果表明,在 NQ 与 HotpotQA 等多工具问答任务中,推理与工具使用的交互项几乎在所有问题上都是负的,这直接推翻了“共享参数必然带来协同”的经验假设。
更耐人寻味的是,干扰最严重的区域,恰恰对应那些真正需要多步推理与工具交互的问题。这说明,Agentic RL 在最核心、最具挑战性的场景中,反而最容易触发参数竞争,从而限制模型潜力。
在确认干扰现象的普遍性之后,作者进一步提出了一种极为直接但有效的解决方案:与其在共享参数中强行调和冲突,不如在参数空间层面将两种能力解耦。这一方法被命名为 DART(Disentangled Action-Reasoning Tuning)。
其基本做法是冻结原有 backbone 参数,在其上为推理能力与工具使用能力分别引入一套独立的 LoRA 适配器,并通过 token 级路由机制决定当前 token 的梯度应当流向哪一个子空间。推理 token 只更新推理 LoRA,工具 token 只更新工具 LoRA,从而在训练阶段实现显式的梯度隔离。
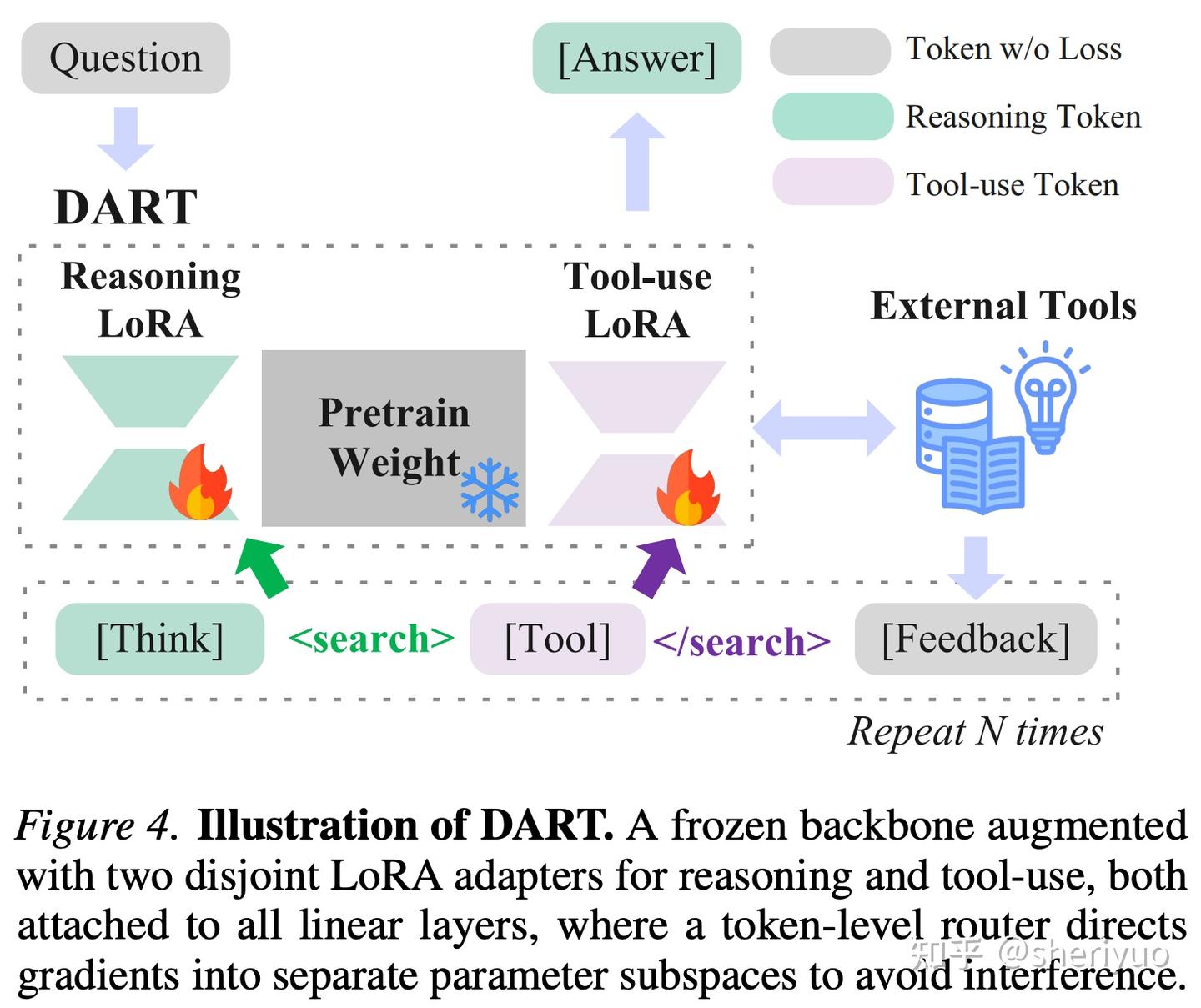
这种设计与传统多任务学习中通过损失加权或梯度投影来“缓和冲突”的思路截然不同。DART 并不试图在共享空间中寻找一个折中解,而是承认不同能力需要不同的参数子空间,让它们在各自的低秩空间中独立进化。形式上,前向传播只是在原始权重之外叠加一个由路由器选择的 LoRA 分支,但在优化层面,推理与行动已经被彻底分流。

实验结果显示,这种解耦策略在多个工具增强问答基准上带来了稳定而显著的提升。在 3B 模型规模上,DART 相比 Search-R1-GRPO 在平均 EM 分数上提升超过 6%,而在多跳推理任务上,相对提升幅度接近 30%。
更重要的是,当作者在固定检索结果的条件下比较推理能力时,DART 仍然明显优于联合训练模型,这说明性能提升并非来自更好的检索,而是来自推理能力本身没有被联合优化所“拖累”。
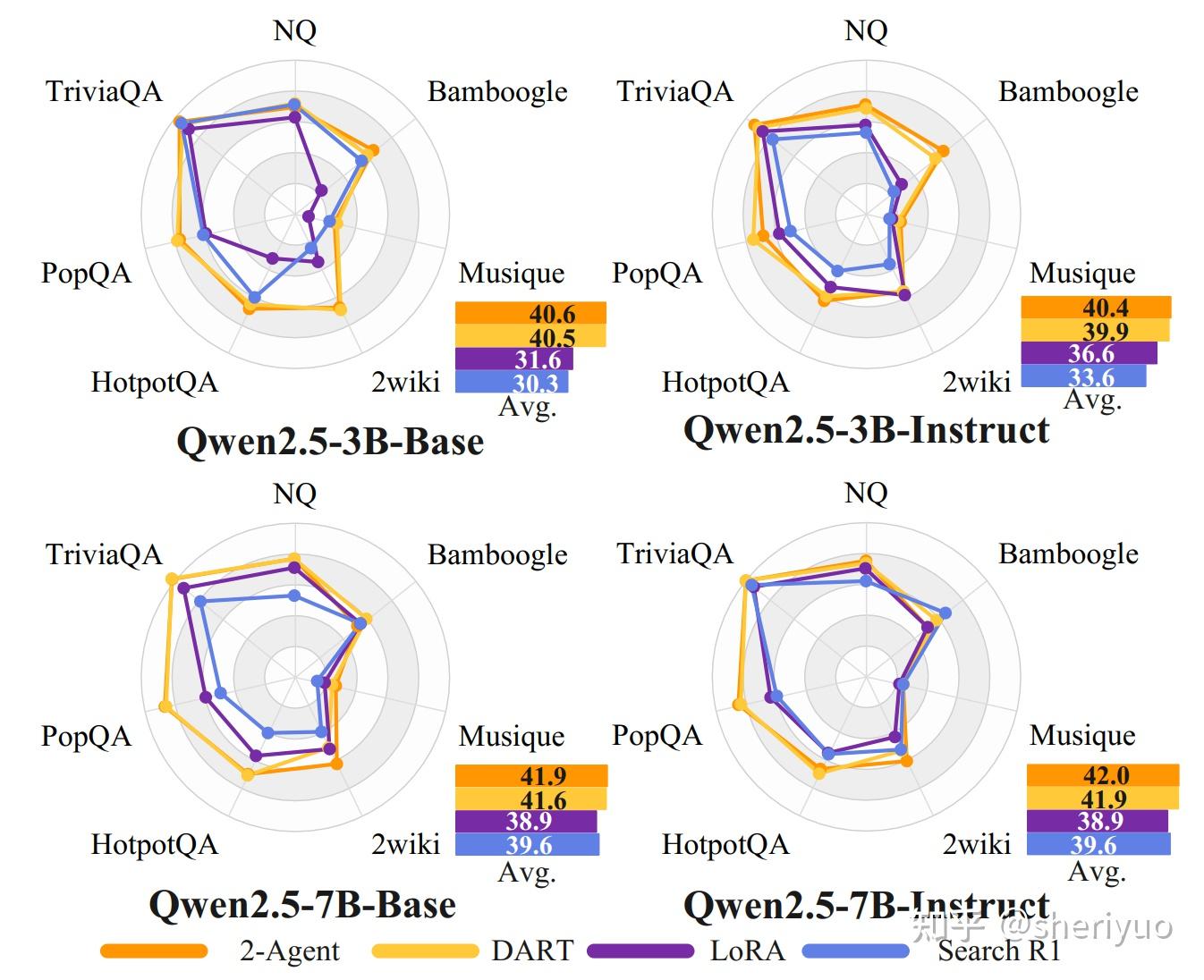
作者还将 DART 与2-Agent 系统进行对比。后者使用一个独立模型负责推理,一个独立模型负责工具决策,理论上不存在梯度冲突,是一种性能上界。
结果表明,DART 在单模型结构下复现了大部分 2-Agent 的性能优势,同时避免了多模型系统在显存占用、上下文切换和 KV-cache 重建方面的巨大工程成本。
这一点对真实部署尤为关键,因为它意味着能力解耦不必以推理效率为代价。
Q3:DART 为什么有效?用线性代数怎么理解?
DART 的本质是给不同能力分配不同的参数子空间
这相当于人为构造两个近似正交的低秩子空间,让
从几何上看,就是避免了 \mathbf{g}_r + \mathbf{g}_a 被投影到同一参数空间中相互干扰,而是让它们在各自的子空间中独立收敛。
这也是为什么 DART 能在单模型中逼近 2-Agent 系统的性能上界。
从更广泛的视角来看,这项工作的意义并不仅限于一个具体方法。它揭示了一个在 Agent 系统设计中长期被忽视的原则:并非所有能力都适合在共享参数空间中联合训练。
当不同能力在梯度几何上存在系统性冲突时,参数解耦往往比复杂的奖励设计或梯度修正更加直接有效。DART 同时也重新定义了 LoRA 的角色,使其不再只是参数高效微调的工具,而成为能力模块化与结构化解耦的载体。
总体而言,这项研究为 Agentic RL 提供了一个新的思考维度:性能瓶颈未必来自模型规模或奖励函数,而可能源于能力之间的结构性冲突。
通过在参数空间中显式解耦推理与行动,模型得以在单一架构内同时保持两种能力的独立最优性。这一思想不仅对工具增强问答具有启发意义,也为更一般的多能力大模型训练提供了新的范式。