作者:硝基苯
https://zhuanlan.zhihu.com/p/2019875354538428076
写在前面
从过年一直到现在,World Action Model这个概念很火,学术界有很多工作(Cosmos Policy, DreamZero, Motus, LingBot-VA, FastWAM)。
感觉在短期的未来可能也是大家的交流话题,在组内和网上学到了很多,这里记录一下信息,也希望能帮助想要了解World Action Model的朋友们。
什么是World Action Model?
首先,什么是World Action Model,它跟我们常说的World Model有什么区别吗?我们常说的World Model其实准确描述应该叫Action Conditioned World Model (AC-WM),输入当前时刻的状态 s_t 和将要执行的动作 a_t,AC-WM会预测出下一时刻的状态 s_{t+1}。这样的建模方式中,动作 a_t 是 AC-WM 的一个输入(即一个condition)。
对于World Action Model(后文简称为WAM)来说,只需要输入当前状态 s_t ,WAM会同时输出对应的动作 a_t 和执行这个动作之后对应的状态 s_{t+1} 。
所以简单来说,AC-WM和WAM的区别为:动作到底是作为模型的输入,还是输出。
World Action Model和VLA的区别与联系
对于一个模型来说,如果能输出动作,其实就可以算一个policy了。目前作为policy的模型,大多数是VLA架构,这里我们又谈到了WAM也可以做policy,那么这两者有什么区别和联系呢?
VLA:充分利用VLM基础模型的能力 + Action Expert
WAM:充分利用Video Generation Model基础模型的能力 + Action Expert
VLA这条路比较好理解,VLM就类似人的大脑,有了思考能力,现在接个身体 (Action Expert) 让它控制。WAM这边利用Video Generation Model的能力生成动作,其实也有一定的道理,因为WAM在训练的时候,可以用未来帧做密集监督,学习世界演变的知识,可能更有利于控制身体。
可能有的同学就要问了,那能不能同时利用VLM和Video Generation Model的能力,构建一个更好的policy?好问题,感觉之后确实会形成VLA+World Model的统一架构。
WAM的经典工作简介和几种范式
最近有很多WAM的工作,这里选取几篇扫过的大致给大家介绍一下。
Motus: A Unified Latent Action World Model
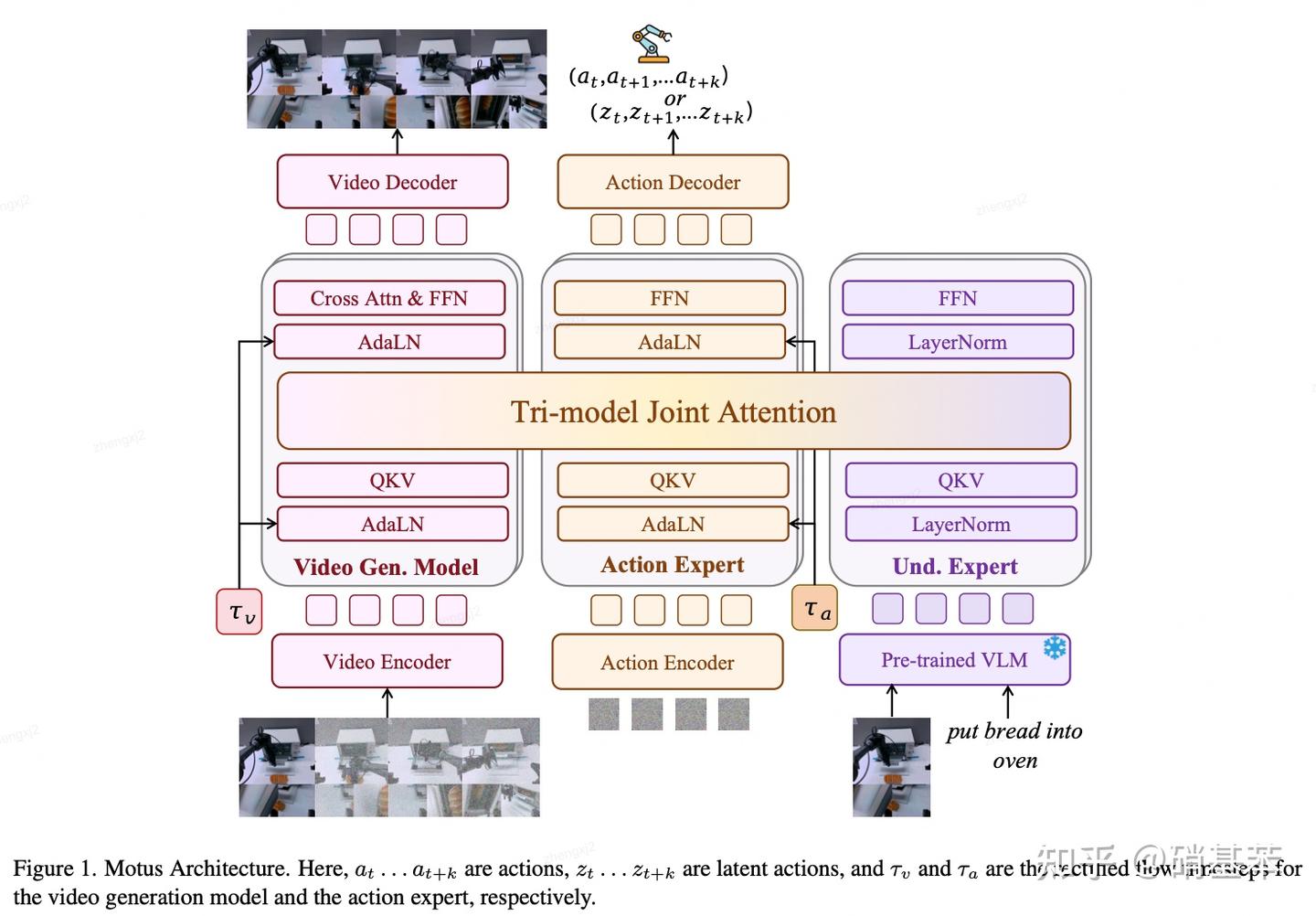
架构很简单,使用了Mixture-of-Transformer将Video Generation Model、Action Expert以及Understanding Model三个模型进行结合。
训练/推理的时候,Video Gen Model输入一段视频的第一帧和加噪声的之后的帧;Action Expert输入纯噪声;Understanding Model输入第一帧和文本。最终实现Video Generation Model预测未来帧,同时Action Expert输出对应的动作。
Cosmos Policy
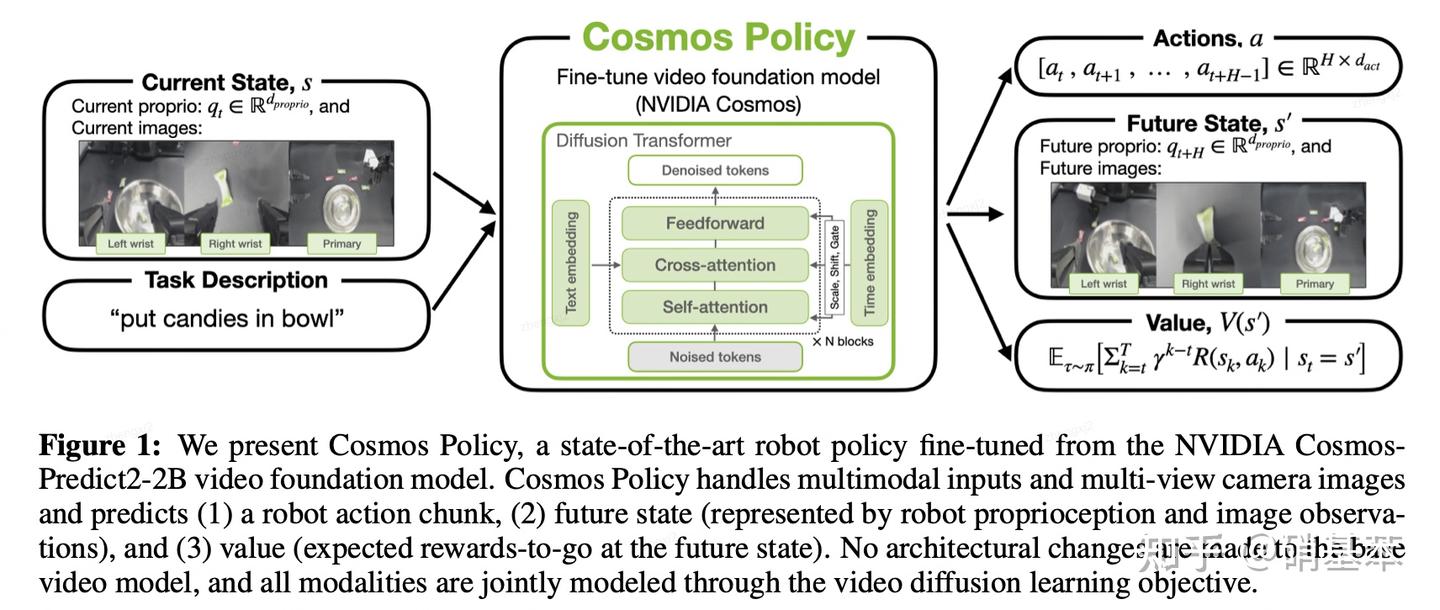
cosmos policy最有意思的一点是它没有在cosmos-predict (英伟达的视频生成模型)的架构上做很大的变化,充分利用了基础模型的能力,然后最后除了生成视频外还能生成动作,以及生成这个动作对应的价值 (Value)!
这个价值就加得很妙呀!对于world model来说,其实不会考虑收集数据的时候,任务本身是成功还是失败,反正有video就能训练。但是一旦一个模型成为了policy,如果做监督学习的话,训练数据就只能是专家示例数据了,失败的数据很难用(除非上强化学习)。但是这里加上value,相把数据集中的video数据的“成功”和“失败”这个标签给一起学进去了,这样失败的数据就能利用起来。
最后生成动作的时候,可以生成多条,最后选择一条价值最大的。
LingBot-VA
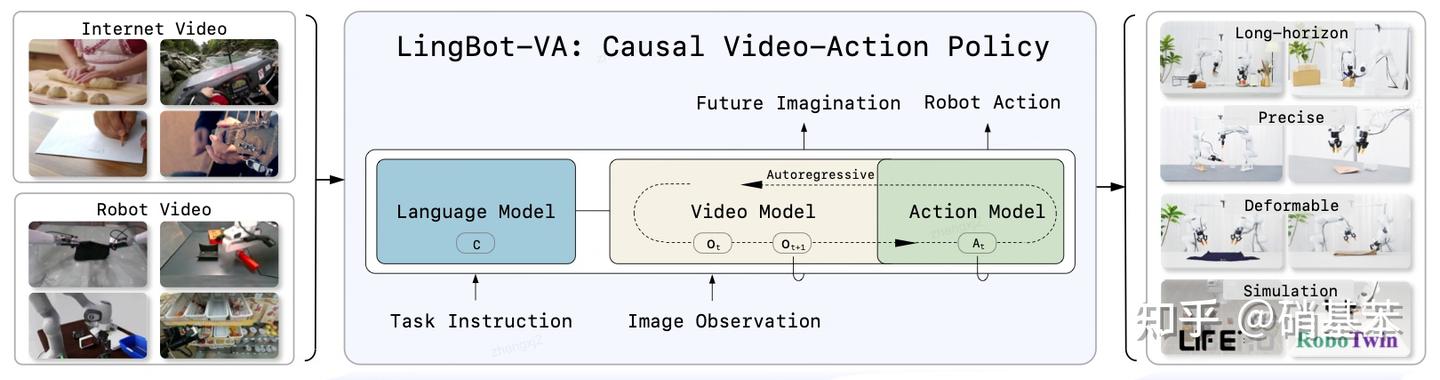
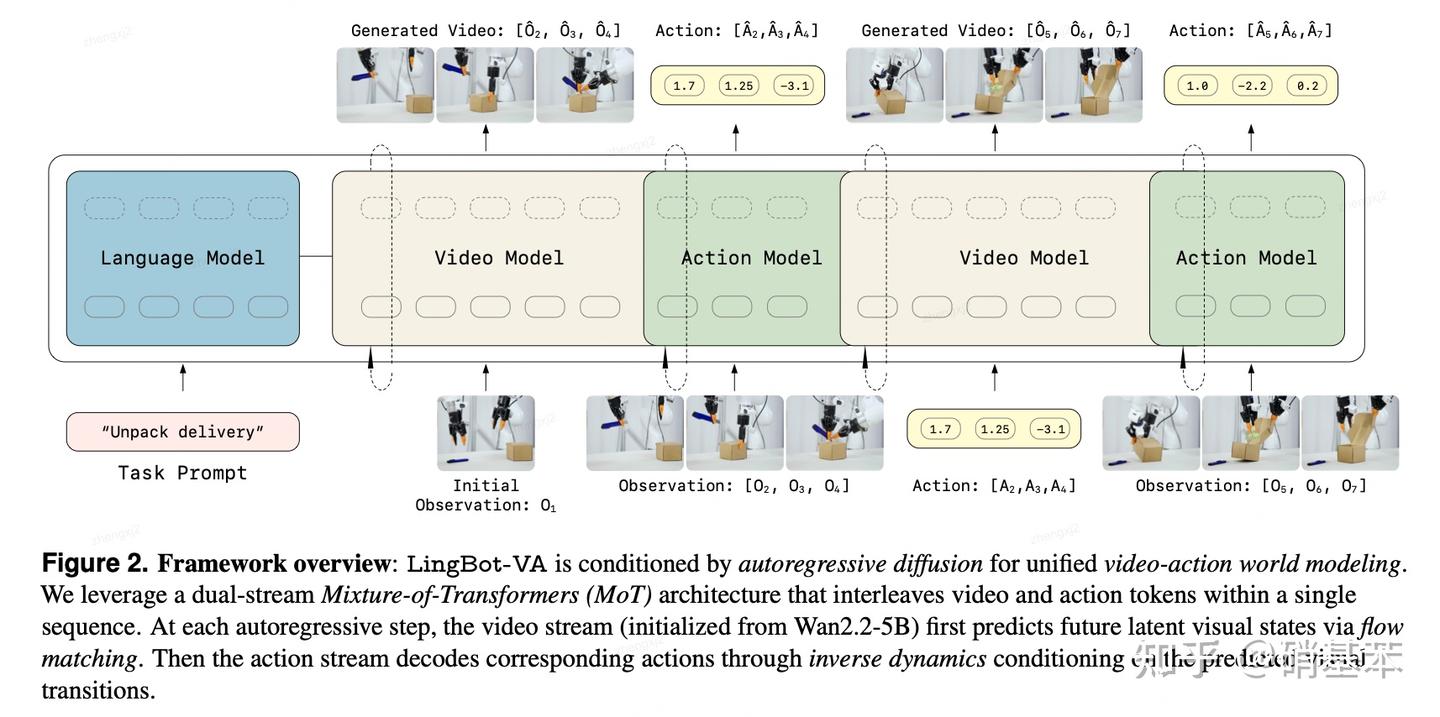
之前的Motus和Cosmos Policy,它们输出预测video和action的时候,基本上是同时输出的(joint denoise)。LingBot-VA这里做了个自回归的输出。什么是自回归的输出呢?一句话解释的话,就是video和action不是同时输出的,是video model先预测未来的视觉状态表征 (对应上图 \hat{O2}, \hat{O3}, \hat{O4}),这些表征作为action model的condition (inverse dynamics condition,感觉类似IDM的感觉),最终实现解码出action。
详细的图示可以看上图:当生成一个action chunk之后 (\hat{A2}, \hat{A3}, \hat{A4} )之后,在真机上执行,又会得到新的观测数据 (O2, O3, O4)。观测数据又可以作为video model的输入,以此类推,从而完成长程的任务。
通过这样的方式预测的视频,天然就不会有很大的误差累积!因为输出的action能作用于真实世界并将得到的观测又重新输入给模型。而AC-WM只能基于初始帧和给的的动作序列生成视频,中间没有任何提示,误差累积就会越来越大。
DreamZero
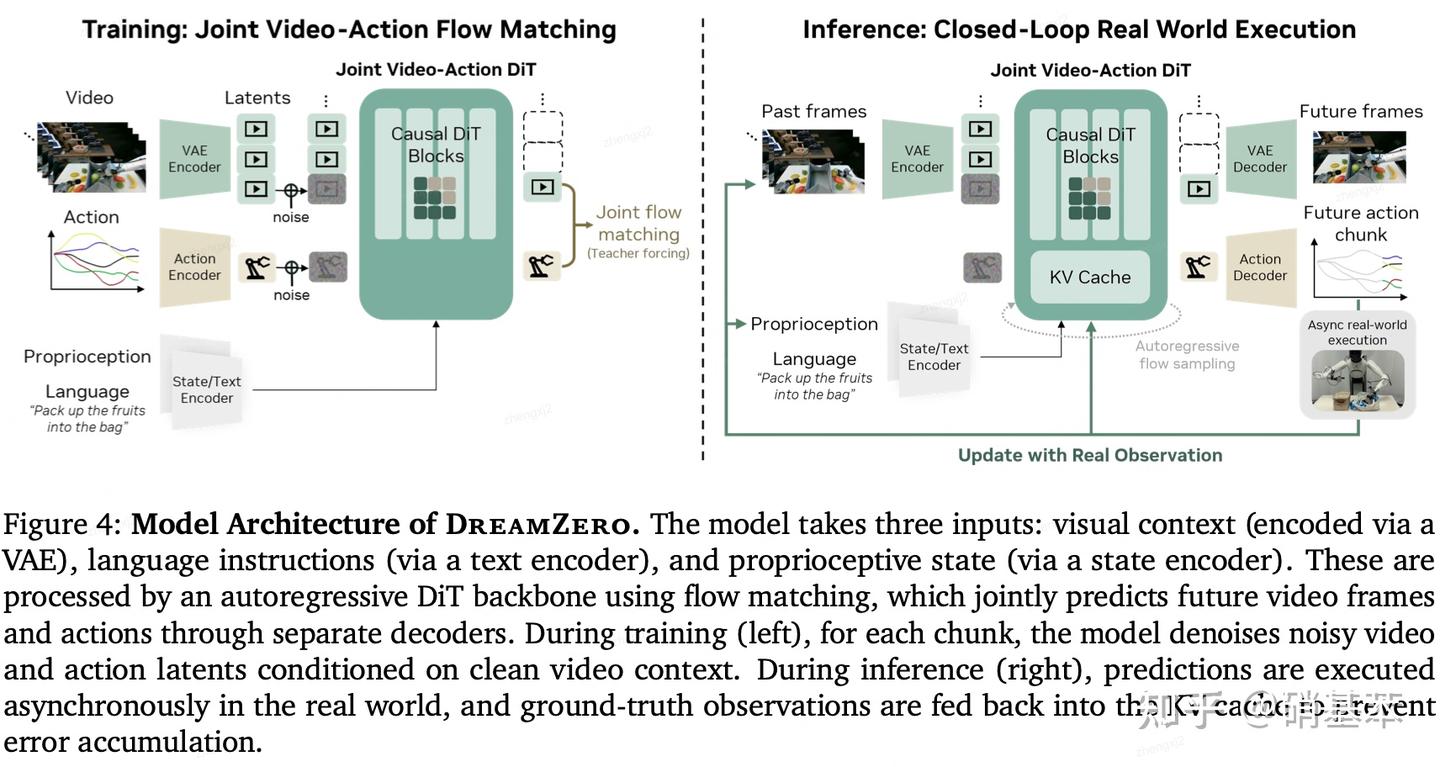
训练的时候输入视频前几帧+带噪声的后几帧 (未来帧),动作+噪声,以及文本信息,输出降噪之后的未来帧预测和动作预测。推理的时候就能实现输入当前观测,同时输出未来帧的预测和动作了。感觉跟前面的Motus和Cosmos Policy的大致思路比较类似(但从输出输出来看)。
FastWAM
前不久有篇知乎文章提出了这样一个问题:既然WAM是作为一个policy,那推理的时候输出动作不就够了吗?为什么还要预测未来的视频?这个视频在部署的时候又不能用到,不能直接砍掉吗?
感觉文章写的很不错,可以看看:Fast-WAM: 关于WAM核心能力来源的思考
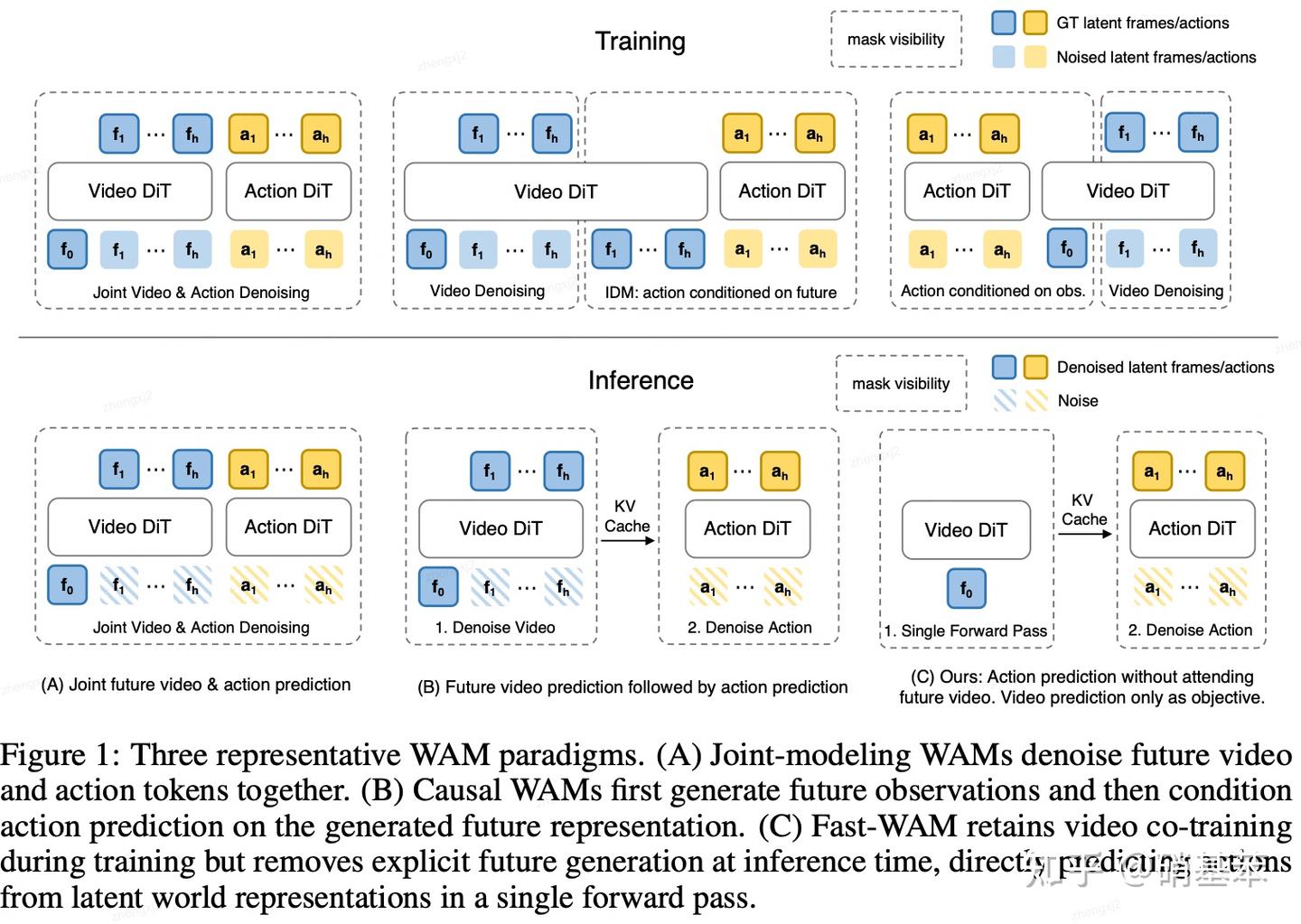
将近期的WAN分成了三种范式,
- (A) 联合建模式WAM (Fast-WAM-Joint),同时对video和action的token降噪,对应我们上面讲的Motus,Cosmos Policy和DreamZero;
- (B) 因果式WAM (Fast-WAM-IDM),会先生成未来观测,再基于未来观测作为条件,预测未来对应的动作,对应我们上面讲的Lingbot-VA;
- (C) FastWAM,未来动作生成的条件不是未来预测了,而是当前帧,这样在推理的时候就根本不需要输出预测的视频,直接生成动作就好。
在做实验的时候,他们做了一组实验:把训练过程中video预测loss置零,看看world modeling这个任务是不是真的能让模型学会更好的policy,并把这组实验叫Fast-WAN-no-cotrain。
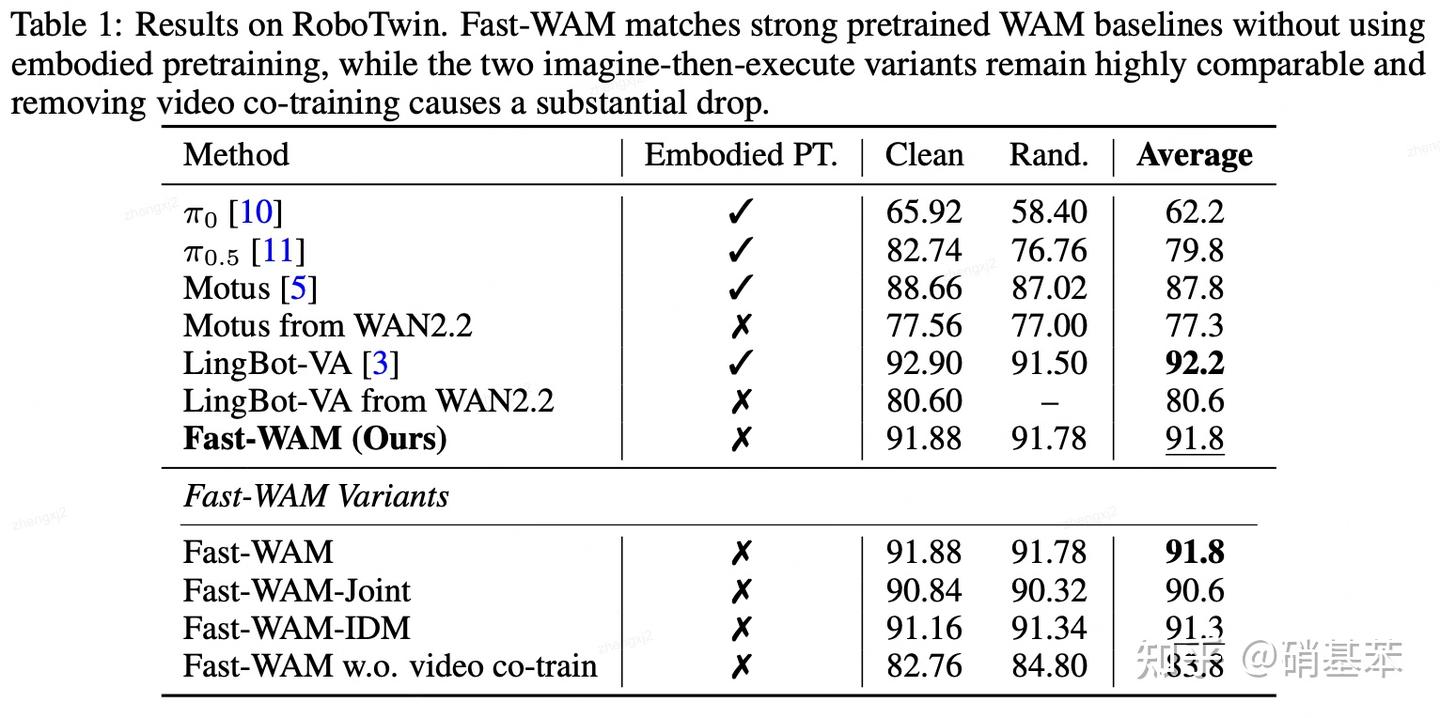
他们在RoboTwin上做的实验,看最后四行结果的初步结论为:联合建模式WAM和因果式WAM其实没啥显著区别,而且其实推理时去掉预测未来视频的head对结果也没啥影响(甚至还会变好一些!)。
但是在训练的时候,如果去掉world modeling这个任务,模型的性能就会巨幅下降!这也说明了world action model起作用的核心,还是在于利用好了视频预测模型的能力。
AC-WM和WAM各自的特点分析
上面我们把WAM和VLA做了对比,这里再把WAM和AC-WM做个对比。
这部分特点分析,主要参考了X上Anirudha Majumdar老师的博文
数据利用,反事实推理
首先从数据利用层面来说,传统的world model (AC-WM),其实不太关心你做一个任务到底是成功还是失败,因为训练目标不是最大化成功率,而是学会物理世界中尽可能多的状态推演,和物理变化相关的知识,数据越多样效果会越好(甚至失败数据会更好,比如杯子被摔碎的视频能让模型学会“玻璃从高处摔下来会碎掉”这样的物理现象)。
但是对于WAM来说,目标就变化了,WAM的目标是尽可能学一个好的policy,成功率越高越好。所以训练的时候,尽可能要使用成功的数据(使用失败的会让模型也做失败的动作)。当然也有解决方案,比如上面讲到的Cosmos Policy,最后增加一个value head,就可以同时使用成功和失败数据训练了。
还有一个点是反事实推理 (counterfactual reasoning) 的能力。
gemini老师对此的解释是:
不仅能在训练集覆盖的“常态”下给出准确预测,还能在给定一个与其行为策略(Behavior Policy)截然不同的罕见动作时,推演出符合物理规律的未来。
对于AC-WM来说,只要<视频,动作>数据对越多,模型拟合的分布越能涵盖物理世界的状态转移分布,总能具有反事实推理的能力。但是对于WAM来说,因为最后要生成动作,训练目标就是成功率更高,因此WAM可能并不会有反事实推理的能力(因为动作从输入变成输出了)。
基座模型利用
对于AC-WM和WAM来说,基座模型都是video generation model。谁能更好的利用基座模型 (架构上的调整更小),在相同的训练数据上,谁就很可能有更高的效果。
传统的video generation model,条件注入的模态一般就是文本,不会注入动作,所以AC-WM往往会对基座模型的架构做比较大的调整,而且是输入的部分,这很可能在一定程度上会应该基座模型的效果。
但是对于WAM来说,动作变成了输出,只需要在输出的时候接一个action head,从而避免了对基座模型架构和预训练参数进行较大调整。
Cosmos Policy论文中甚至说“no architectural modifications”,基座模型的能力得到了最大程度的保留。
In this work, we introduce CosmosPolicy, a simple approach for adapting a large pretrained video model (Cosmos-Predict2) into an effective robot policy through a single stage of post-training on the robot demonstration data collected on the target platform, with no architectural modifications.
问题的难度
然后从问题的难度来看,AC-WM输入动作和状态,输出未来状态;WAM输入状态,输出未来状态和对应动作。
WAM只要知道这个状态下的最优动作怎么做,以及对应的未来状态是什么就可以了;
AC-WM需要知道所有动作在当前状态下执行,得到的下一个状态是什么。
这两个问题的难度不一样,AC-WM要解决的问题比WAM要难得多。
其实可以跟强化学习中 Q(s, a) 和 V(s) 联系起来看,V(s) 只需要给出当前策略在这个状态下执行,最后得到的价值平均值,或者期望就行;
而 Q(s, a) 需要给出当前策略在提供的动作下执行,最后得到的价值平均值,或者期望。
后者多了一个输入,多了一个限制条件,问题也会更难(所以现在用VLA做RL,似乎训练critic都还是用的 V(s),因为简单一些)。
功能
这个其实比较明显,AC-WM是用来做simulator的,WAM是用来做policy的。当然这两种也可以结合一下,把AC-WM作为WAM在做RL时的环境,实现RL的闭环。
推理时的误差累积【修正后】
因为 WAM 的输出同时包含动作和未来状态(目前大多数以视频的形式呈现),因此我们这里需要将“误差累积”拆分为两个独立的维度来探讨。在此前的版本中,我将这两个维度混淆了,认为 Feedback 的引入能直接消除误差累积,但事实并非如此。
1. 从输出视频的角度(视觉误差放大): AC-WM 作为一个世界模型,在预测长序列时本质上是“开环”的,只能依靠自回归生成视频。这种情况下,前面帧的预测瑕疵会作为后面帧的输入,导致画面质量像滚雪球一样逐渐崩溃。
而 WAM 最大的范式改变在于它实现了“闭环”的视频生成——由于同时生成了动作并在物理环境中执行,WAM 可以不断获取真实的观测作为下一步的输入。这种真实物理世界的 Feedback 确实能打断“视觉层面的滚雪球”,有效避免了长程视频生成的画质崩坏。
2. 从输出动作的角度(策略累积误差): 从控制的视角来看,WAM 作为一个 Policy,本质上跟 VLA 区别不大,部署时都是闭环的。在大规模预训练后,模型在训练集覆盖的专家分布内表现很好。
但在真实的物理世界中,只要遇到与训练集不一致的情况,微小的动作偏差就会导致下一步的观测偏离预期。对于长程任务来说,这些小错逐步叠加,最终会将模型推到它从未见过的 OOD (Out-of-Distribution) 状态,从而导致控制崩溃。这就是经典的误差累计问题。
引用评论区俞扬老师非常精辟的总结:
有没有feedback与累积误差没有关系,策略看到了“真实”的状态,并不代表策略走到了“正确”的状态。
确实,就算闭环系统让策略看到了完美、高清的“真实”状态,只要这个状态对模型来说是 OOD 的,控制依然会崩溃。
WAM 确实将“开环”的未来预测升级成了“闭环”的实时验证,保证了观测的真实性。但在具身智能(Robotics)领域,我们目前面临的最大瓶颈依然是 Policy 本身的鲁棒性。Feedback 解决了“看到的东西糊不糊”的问题,但并不能凭空消除“该怎么做”的策略漂移问题。
再次感谢评论区的@俞扬 老师和@Zikang Zhou老师的专业指正与交流!🌹
关于未来发展的展望
如果从Sutton's bitter lesson的角度考虑 (人在模型上做一些小聪明式的创新反而会限制模型自己从数据中学习),AC-WM的训练,可以利用任何policy产生的数据,甚至是policy在自己self play时候产生的数据,而且不需要任何标签。而
这对于WAM来说很难,当然可能也会有一些训练方法能缓解,比如Cosmos Policy输出value,但是需要训练数据提供reward标签。
所以这样看来AC-WM似乎长期的上限会更高,但WAM作为一个中间的过渡是没问题的,甚至之后两者可能结合?输入state action,输出state action?
这就需要各位研究者的继续探索了~
总结
这篇文章主要对近几个月热门的World Action Model进行了简单的介绍,梳理了各自工作的特点,把World Action Model和VLA与Action-condition World Model进行了对比,并借鉴和融合了互联网上很多优秀研究者的思考和回答,感谢大大们的分享,也希望这篇文章也能帮助大家更好的了解World Action Model~
本文写的比较仓促,可能也存在错误,欢迎一起讨论交流~